
Потоковая передача данных — один из наиболее актуальных терминов в сфере технологий для создания масштабируемых приложений реального времени в облаке и инновационных бизнес-моделей. Какие топ-5 тенденций потоковой передачи данных ждут нас в 2023? В статье разберем это и расскажем, какую роль в движении данных играет Apache Kafka. Узнайте о децентрализованной сети передачи данных, облачном лейкхаусе, совместном использовании данных и расширенном управлении данными.
Потоковая передача данных с помощью Apache Kafka — это приключение и эволюция для приведения данных в движение. Тенденции меняются с течением времени, но основная ценность масштабируемой инфраструктуры реального времени как основного центра обработки данных остается неизменной.

Главные стратегические технологические тренды Gartner на 2023 год
Исследовательская и консалтинговая компания Gartner каждый год определяет главные стратегические технологические тренды. На этот раз тенденции больше сосредоточены на конкретных нишевых концепциях. На высоком уровне всё сводится к оптимизации, масштабированию и новаторству. Вот что ожидает Gartner на 2023 год:

Что забавно: прогнозы Gartner перекрывают и дополняют пять тенденций, на которых фокусируются в области потоковой передачи данных с Apache Kafka на 2023 год. Kai Waehner исследует, как именно потоковая передача данных позволяет быстрее выходить на рынок за счёт децентрализованным оптимизированным архитектурам, облачной инфраструктуре для эластичного масштабирования и новаторским вариантам использования для создания ценных информационных продуктов.
Итак, вот топ-5 тенденций в области потоковой передачи данных на 2023 год.
Топ-5 тенденций потоковой передачи данных на 2023 год
Следующие темы все чаще всплывают в разговорах с клиентами, потенциальными клиентами и более широким сообществом Kafka по всему миру:
Облачные Lakehouse
Децентрализованная сеть передачи данных
Обмен данными в режиме реального времени
Улучшенный опыт разработчиков и пользователей
Усовершенствованное управление данными и применение политики
В следующих разделах распишем о каждой тенденции подробнее. В конце статьи приведена полная подборка слайдов. Тенденции актуальны для различных сценариев. Независимо от того, используете ли вы Apache Kafka с открытым исходным кодом, коммерческую платформу или полностью управляемый облачный сервис, такой как Confluent Cloud.
Kafka как структура данных для облачной Lakehouse
Сегодня многие поставщики платформ обработки данных предлагают концепцию Lakehouse. Это та же история, что и с datalake в эпоху Hadoop, но с несколькими новыми нюансами. Поместите все свои данные в единое хранилище данных, чтобы спасти мир и решить все проблемы и варианты использования:

За последние десять лет большинство предприятий поняли, что эта стратегия не работает. Datalake подходит для создания отчетов и пакетной аналитики, но не подходит для решения каждой проблемы. Кроме технических проблем, возникли новые: управление данными, вопросы соответствия требованиям, конфиденциальность данных и так далее.
Применение корпоративной архитектуры для анализа данных в режиме реального времени и пакетной обработки с использованием подходящего инструмента для каждой задачи — более гибкий и ориентированный на будущее подход:
Платформы обработки данных, такие как Databricks, Snowflake, Elastic, MongoDB, BigQuery и т.д., имеют свои плюсы и минусы.
Потоковая передача данных чаще становится основой передачи данных в реальном времени между всеми платформами обработки данных и другими бизнес-приложениями, использующими архитектуру Kappa вместо ориентированной на пакетную обработку архитектуры Lamba.
Децентрализованная сеть передачи данных с ценными информационными продуктами
Сосредоточение внимания на ценности бизнеса путем создания информационных продуктов в независимых областях с использованием различных технологий — ключ к успеху. Datamesh пришел на помощь и стал шаблоном проектирования следующего поколения вместо сервис-ориентированных архитектур и микросервисов.
У поставщиков есть два основных предложения по созданию сети передачи данных: Интеграция данных с потоковой передачей данных позволяет создавать полностью децентрализованные бизнес-продукты. С другой стороны, виртуализация данных обеспечивает централизованные запросы:

Централизованные запросы просты, но не обеспечивают чистой архитектуры и несвязанных доменов и приложений. Это сработает для решения одной проблемы в проекте. Но рекомендуем создать децентрализованную сетку передачи данных с потоковой передачей данных для разделения приложений, особенно для стратегических корпоративных архитектур.
Сотрудничество внутри организаций и между ними в режиме реального времени
Сотрудничество внутри организации и за ее пределами с совместным использованием данных с использованием открытых API, потоковый обмен данными и объединение в кластеры позволяют использовать множество инновационных бизнес-моделей:

Разница между потоковой передачей данных в базу данных, хранилище данных или озеро данных имеет решающее значение: все эти платформы позволяют обмениваться данными в режиме покоя. Данные сохраняются на диске до того, как они будут реплицированы и переданы совместно внутри организации или партнерам. Это не происходит в реальном времени. Вы не можете подключить потребителя в режиме реального времени к данным в состоянии покоя.
Однако данные в реальном времени превосходят медленные данные. Следовательно, обмен в режиме реального времени с платформами потоковой передачи данных, такими как Apache Kafka или Confluent Cloud, позволяет получать точные данные, как только происходят изменения. Потоковый обмен данными приводит их в движение внутри организации или для обмена данными в формате B2B и бизнес-моделей с открытым API.
Спецификация асинхронного API для схем Apache Kafka API
Async API позволяет разработчикам определять интерфейсы асинхронных API. Это не зависит от протокола. Особенности включают в себя:
спецификацию контрактов Open API, то есть схемы в мире потоковой передачи данных;
документацию по API;
генерацию кода для многих языков программирования;
руководство данными и многое другое.
Недавно Confluent Cloud добавила функцию для создания спецификации асинхронного API для кластеров Apache Kafka.
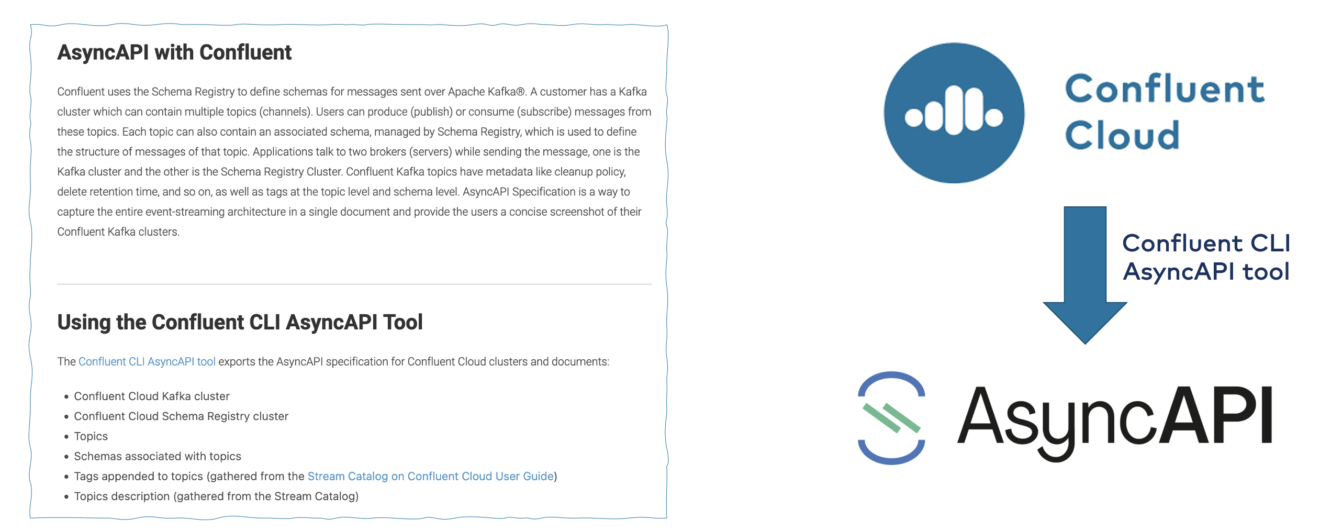
Мы пока не знаем, куда движется рынок. Станет ли Asynch Api стандартом для открытого API в потоковой передаче данных? Может быть. Определенно есть растущий спрос на эту спецификацию со стороны заказчиков. Давайте рассмотрим состояние Asynch API через несколько кварталов или лет, у этого есть потенциал.
Улучшенный опыт работы разработчиков с инструментами с low-code/ no-code для Apache Kafka
Многие аналитики и поставщики предлагают инструменты low-code/no-code. В визуальном кодировании нет ничего нового. Существуют сложные, мощные и простые в использовании решения для сторонних или облачных приложений. Преимущество таких решений — время выхода на рынок для разработки приложений и упрощение обслуживания. По крайней мере, теоретически.
Эти инструменты поддерживают различных людей, таких как разработчики, гражданские интеграторы и специалисты по обработке данных. По крайней мере, теоретически.
Реальность такова, что:
Код — это король
Развитие — это эволюция
Выигрывают открытые платформы
Low code / no-code отлично подходит для некоторых сценариев и персонажей.
Но это — один вариант из многих. Давайте рассмотрим несколько альтернатив для создания приложений, основанных на Kafka:

У этих технологий, основанных на Kafka, есть свои компромиссы. Например, Confluent Stream Designer идеально подходит для построения потоковых конвейеров ETL между различными источниками данных и приемниками. Просто щелкните на конвейер и преобразования вместе. Затем разверните конвейер передачи данных в масштабируемое, надежное и полностью управляемое потоковое приложение. Отличие от отдельных инструментов, таких как Apache Nifi, заключается в том, что сгенерированный код выполняется на одной и той же платформе потоковой передачи, то есть в одной сквозной инфраструктуре. Это делает обеспечение SLA и требований к задержке намного более управляемым, а весь конвейер передачи данных — более экономичным.
Но чем проще инструмент, тем он менее гибкий. Независимо от того, на какой продукт или поставщика вы смотрите — это верно не только для инструментов, созданных на базе Kafka.
И вы гибко подходите к выбору инструмента в зависимости от проекта или бизнес-задачи. Добавьте в стек свой любимый движок потоковой обработки, отличный от Kafka, например, Apache Flink. Или используйте отдельное промежуточное программное обеспечение iPaaS, такое, как Dell Boomi или SnapLogic.
Доменно-ориентированный дизайн с dumb pipes и smart endpoints
Реальным преимуществом потоковой передачи данных является свобода выбора вашей любимой технологии Kafka, платформы потоковой обработки с открытым исходным кодом или облачного промежуточного программного обеспечения iPaaS.
Выберите подходящую библиотеку, инструмент или SaaS для вашего проекта. Потоковая передача данных обеспечивает несвязанный дизайн, управляемый доменом, с dumb pipes и endpoints:
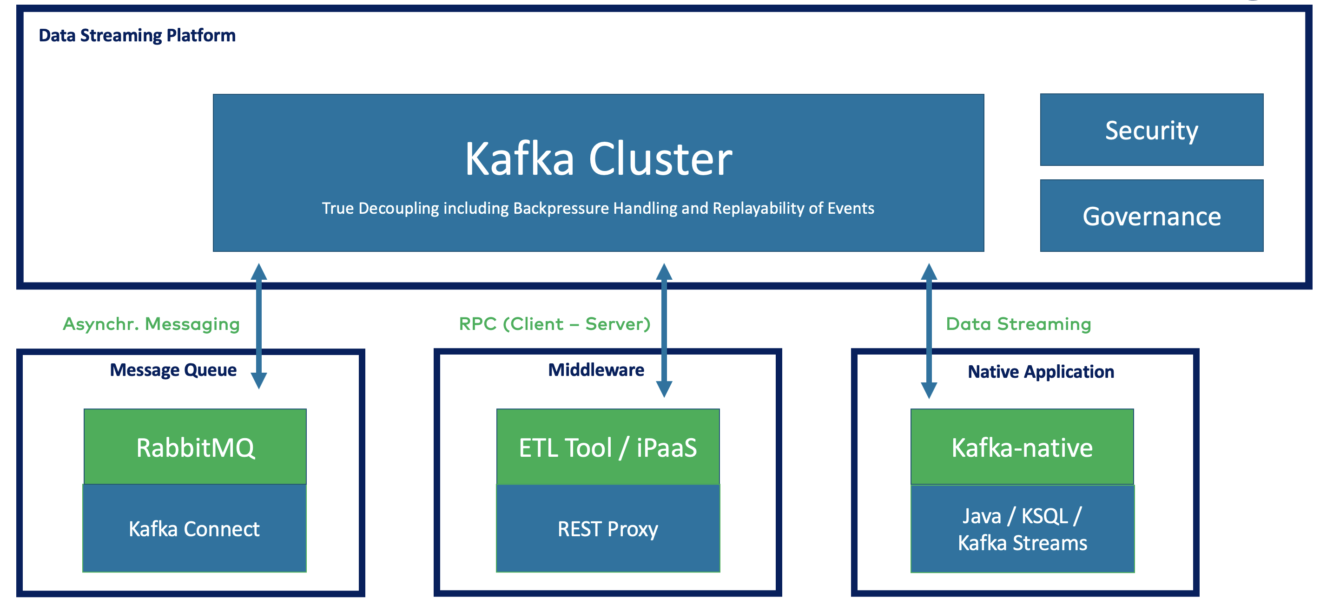
Потоковая передача данных с помощью Apache Kafka идеально подходит для доменно-ориентированного проектирования (DDD). Напротив, двухточечная микросервисная архитектура HTTP/REST web service или основанные на push брокеры сообщений, такие как RabbitMQ, создают сильные зависимости между приложениями.
Управление данными по всему конвейеру потоковой передачи данных
Корпоративная архитектура, основанная на потоковой передаче данных, обеспечивает легкий доступ к данным в режиме реального времени. Многие предприятия используют Apache Kafka в качестве центральной нервной системы между всеми источниками и приемниками данных.
Следствием возможности легкого доступа ко всем данным в разных бизнес-областях являются два противоречивых давления на организации: разблокировка данных для обеспечения инноваций и блокировка данных для обеспечения их безопасности.
Обеспечение управления данными во всех сквозных потоках данных с помощью компоновки данных, отслеживания событий, применения политик и перемещения во времени для анализа исторических событий имеет решающее значение для стратегической потоковой передачи данных в корпоративной архитектуре. Управление данными поверх потоковой платформы необходимо для обеспечения сквозной видимости, соответствия требованиям и безопасности:
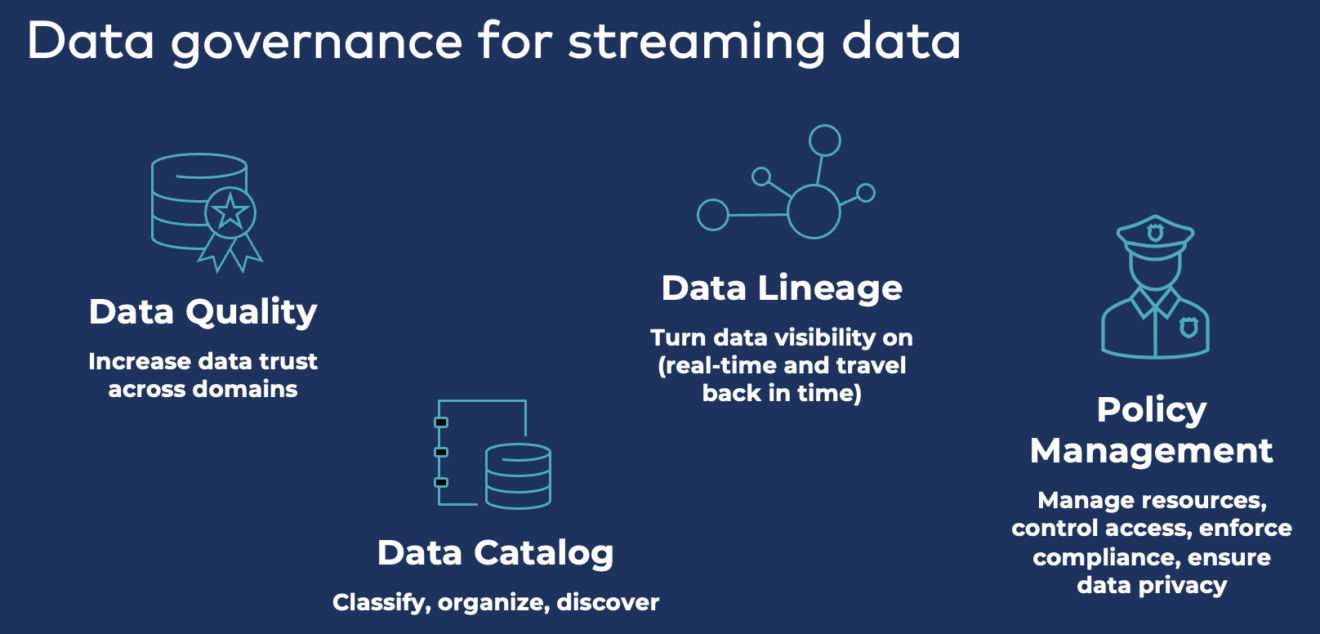
Применение политики с помощью схем и контрактов API
Основой управления данными является управление контрактами API — так называемые схемы в платформах потоковой передачи данных, таких как Apache Kafka. Решения, вроде Confluent, обеспечивают применение схем по всему конвейеру передачи данных, включая производителя данных, сервер и потребителя:

На этом фундаменте построены дополнительные инструменты управления данными, такие как data lineage, catalog или police enforcement. Рекомендация для любого серьезного проекта потоковой передачи данных — использовать schema с самого начала. Для первого конвейера в этом нет необходимости. Но следующие производители и потребители нуждаются в надежной среде с принудительными политиками для создания децентрализованной архитектуры сети передачи данных с независимыми, но подключенными продуктами передачи данных.
Слайды и видео для примеров использования потоковой передачи данных в 2023 году
Вот подборка слайдов из презентации по этой теме:

А еще есть видеозапись по запросу.
Кривая зрелости потоковой передачи данных повысится в 2023 году
На большинстве предприятий потоковая передача данных все еще находится на ранней стадии. Но обсуждение выходит за рамки таких вопросов, как «Когда использовать Kafka?» или «Какой облачный сервис использовать?». В 2023 году большинство предприятий столкнутся со задачами, связанными с их многочисленными проектами потоковой передачи данных. Для этого понадобятся знания и навыки в области Apache Kafka.

Новые тенденции часто связаны друг с другом. Сетка данных позволяет создавать независимые информационные продукты, ориентированные на ценность бизнеса. Совместное использование данных является фундаментальным требованием для сети передачи данных. Новые персонажи получают доступ к потоку данных. Часто гражданским разработчикам или специалистам по обработке данных нужны простые инструменты для запуска новых проектов. Корпоративная архитектура требует и обеспечивает управление данными по всему конвейеру в целях обеспечения безопасности, соответствия требованиям и конфиденциальности.
Масштабируемость и эластичность должны быть «из коробки». Полностью управляемая потоковая передача данных — это блестящая возможность начать работу в 2023 году и продвинуться по кривой зрелости от отдельных проектов к центральной нервной системе данных в режиме реального времени.
