Продолжаем тему информационной безопасности и публикуем перевод статьи Coussement Bruno.
Добавить шум к существующим данным, добавить шум только к результатам операций над данными или генерация синтетических данных? Доверимся интуиции?

Компании растут и их нормативные требования к информационной безопасности становятся строже, старшие архитекторы осваивают актуальные тенденции… Всё это приводит к тому, что потребность (или обязательство) уменьшить риски, связанные с конфиденциальностью и утечкой информации, только усиливается для субъектов обработки данных.
В таком случае широко используются методы анонимизации или токенизации данных, хотя и они допускают возможность разглашения частной информации (см. эту статью, чтобы понять, почему так происходит).
Генерация синтетических данных
Синтетические данные имеют принципиальное отличие. Цель состоит в том, чтобы создать генератор данных, который показывает ту же глобальную статистику, что и исходные данные. Отличить оригинал от полученного результата должно быть трудно для модели или человека.
Давайте проиллюстрируем вышесказанное, сгенерировав синтетические данные на Covertype dataset с использованием модели TGAN.

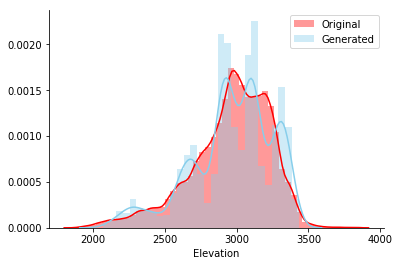
Обучив модель на этой таблице, я сгенерировал 5000 строк и построил гистограмму столбца Elevation исходного и сгенерированного набора. Кажется, обе линии зрительно совпадают.
Чтобы проверить взаимосвязь между парами столбцов, показан парный график всех непрерывных столбцов. Форма, которую образуют сине-зеленые точки (сгенерированные), должна визуально соответствовать форме красных точек (исходная). Так и получилось, круто!

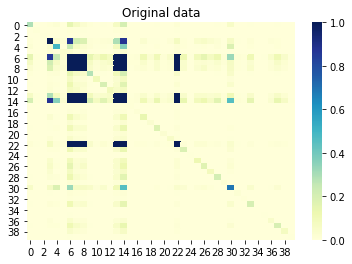
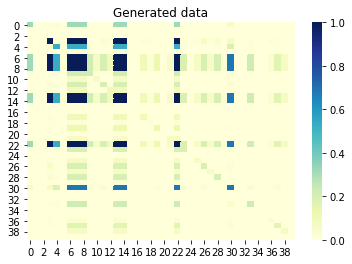
Если теперь мы посмотрим на взаимную информацию (также известную как корреляция без знака) между столбцами, то столбцы, которые коррелируют друг с другом, также должны быть коррелированы в сгенерированном наборе. И наоборот, столбцы без корреляции в исходном наборе не должны коррелироваться в сгенерированном наборе. Значение, близкое к 0, означает отсутствие корреляции, а значение, близкое к 1, означает идеальную корреляцию. Отлично, так и есть!
Mutual information between columns original set:
Mutual information between columns generated set:
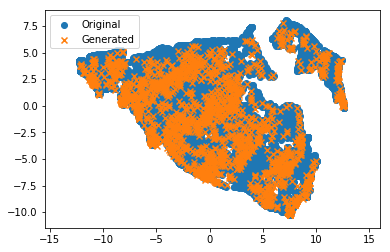
В качестве последнего теста я хотел обучить метод нелинейного понижения размерности (UMAP) на исходном наборе и спроецировать исходные точки в 2D-пространство. Я ввожу в этот же проектор сгенерированный набор. Оранжевые крестики (сгенерированные) должны находиться в синих облаках точек исходного набора данных. Так и есть! Отлично!
OK, экспериментировать с данными — весело!
Для более серьезных случаев есть 2 основных подхода:
- Генерация стохастических данных на основе правила: пользователь указывает распределения выборки и конкретные правила для выборки.
Например:
— столбец A: должен содержать женские имена,
— столбец B: должен содержать название европейской страны,
— столбец C: должен быть целым числом с равномерной выборкой от 1 до 100, если страна в столбце B — «Франция», иначе — константа.
Хорошие фреймворки: Faker, Trumania.
- Глубокие генеративные модели: могут использоваться для изучения статистического распределения, из которого предположительно были взяты реальные данные. Если у вас есть аппроксимация к этому распределению, из него можно произвольно брать выборку синтетического набора данных произвольного размера. Именно этим сейчас занимаются все крутые ребята.
Стоит обратить внимание на такие инициативы, как Synthetic data vault, Gretel.AI, Mostly.ai, MDClone, Hazy.
Сегодня вы уже можете написать доказательство концепции (proof-of-concept) с использованием синтетических данных для решения одной из следующих распространенных проблем, с которыми сталкиваются ИТ-организации:
- Нет полезных данных в среде разработки
Допустим, вы работаете над data-продуктом ( это может быть что угодно), где интересующие вас данные находятся в производственной среде с очень строгой политикой доступа. К сожалению, у вас есть доступ только к среде разработки без интересных данных.
- Режим бога — права доступа для инженеров и специалистов по обработке данных
Допустим, вы специалист по обработке данных, и внезапно сотрудник департамента информационной безопасности ограничил ваши столь нужные привилегии в отношении доступа к производственным данным. Как вы можете продолжать качественно выполнять работу в таких жестких, ограниченных условиях?
- Передача конфиденциальных данных недоверенному (untrusted) внешнему партнеру
Вы являетесь частью компании X. Организация Y хотела бы продемонстрировать свой последний классный data-продукт (это может быть что угодно).
Они просят вас извлечь данные, чтобы показать продукт вам.
Какое отношение имеют синтетические данные к дифференциальной приватности?
Главное свойство синтетической генерации данных заключается в том, что независимо от пост-обработки или добавления сторонней информации, никто никогда не сможет узнать, содержится ли объект в исходном наборе, а также не сможет получить свойства этого объекта. Это свойство является частью более широкой концепции, которая называется “дифференциальная конфиденциальность” (DP).
Глобальная и локальная дифференциальная конфиденциальность
DP разделяют на 2 разновидности.
Часто интерес представляет только результат конкретной задачи (например, обучение модели на основе не подлежащих разглашению данных пациентов из разных больниц, вычисление среднего числа людей, которые когда-либо совершали преступление и т. д.), тогда следует обратить внимание на глобальную дифференциальную конфиденциальность.
В этом случае недоверенный пользователь никогда не увидит конфиденциальные данные. Вместо этого он или она сообщает доверенному куратору (с механизмами глобальной дифференциальной конфиденциальности), имеющему доступ к конфиденциальным данным, какие операции следует выполнить.
Недоверенному пользователю сообщается только результат. Рекомендую Pysyft и OpenDP, если вам нужна дополнительная информация о подобных инструментах.
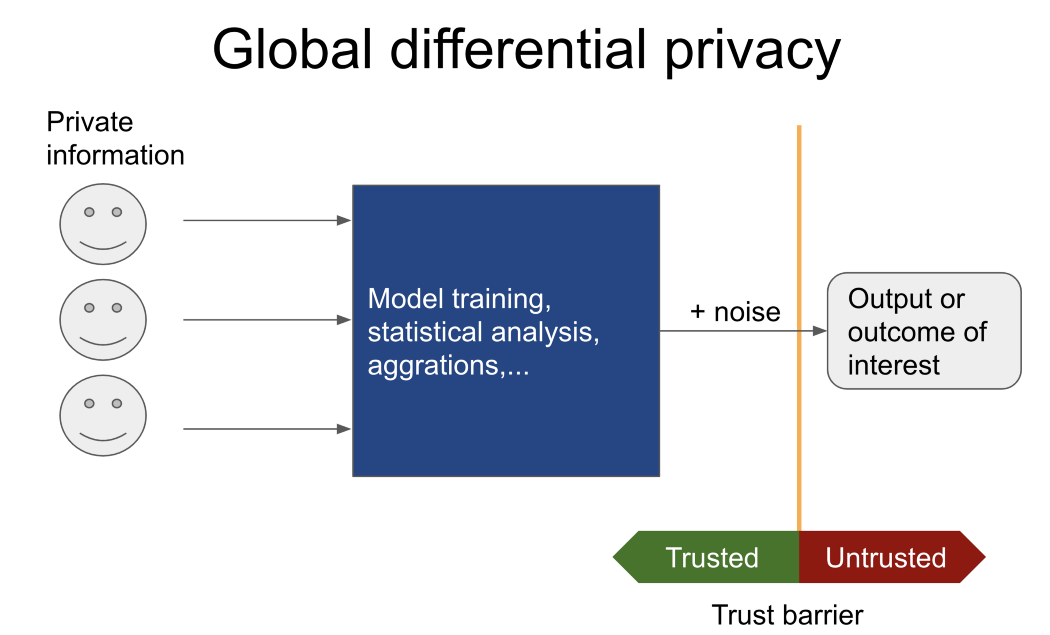
Напротив, если данные должны быть переданы недоверенной стороне, в игру вступают принципы локальной дифференциальной конфиденциальности. Традиционно это достигается путем добавления шума к каждой строке таблицы или базы данных. Количество добавляемого шума зависит от:
- необходимого уровня конфиденциальности (знаменитый эпсилон в литературе по DP),
- размера набора данных (бо’льший набор данных требует меньше шума для достижения того же уровня конфиденциальности),
- типа данных столбца (количественный, категориальный, порядковый).

Теоретически для равного уровня конфиденциальности механизм глобальной DP (добавление шума к результату) будет показывать более точные результаты, чем локальный механизм (шум на уровне строк).
Таким образом, методы генерации синтетических данных можно рассматривать как форму локальной DP.
Чтобы получить более подробную информацию по этим темам, я советую обратиться к следующим источникам:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Рекомендация
Давайте теперь рассмотрим более конкретный пример. Вы хотите поделиться таблицей, содержащей личную информацию, с недоверенной стороной.
Прямо сейчас вы можете либо добавить шум к строкам существующих данных (локальная DP), настроить и использовать надежную систему (глобальная DP), либо сгенерировать синтетические данные на основе оригинала.
Следует добавить шум в строки существующих данных, если
- вы не знаете, какая операция будет выполнена с данными после публикации,
- вам необходимо периодически делиться обновлением исходных данных (= иметь этот рабочий процесс как часть стабильного периодического процесса),
- вы и владельцы данных доверяете человеку / команде / организации, которые добавят шум к исходным данным.
Здесь рекомендую начать с инструментов OpenDP.
Наиболее известным случаем дифференциальной конфиденциальности являются данные переписи населения США (см. databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondents).
Эти данные пересчитываются и обновляются каждые три года. В основном это числовые данные, которые объединяются и публикуются на нескольких уровнях (округ, штат, общенациональный уровень).
Следует установить и использовать доверенную систему, если
- заданная вами система поддерживает задачи и операции, которые будут выполняться над ней,
- базовые данные хранятся в разных местах и не могут покинуть их (например, в разных больницах),
- вы и владельцы данных на самом деле доверяете текущей системе и человеку / команде / организации, которые ее настраивают.
Как пользователь конфиденциальных данных, вы получите более точные результаты по сравнению с первым подходом.
Многие фреймворки на данный момент не обладают всеми необходимыми функциями, чтобы развернуть это чудовище безопасным, масштабируемым и доступным для аудита способом. Здесь требуется еще много инженерной работы.
Но по мере того, как их внедрение будет расти, DP может стать хорошей альтернативой для крупных организаций и коммерческих объединений.
Советую начать здесь с OpenMined.
Можно сгенерировать синтетические данные, если
- исходная таблица относительно мала (<1 млн строк, <100 столбцов),
- достаточно ad-hoc генерации (периодическая генерация не требуется),
- вы и владельцы данных доверяете человеку / команде / организации, которая будет генерировать для вас синтетические данные.
Как и в случае с небольшим экспериментом, описанным выше, результаты многообещающие. Здесь также не требуется превосходное знание систем DP. Вы можете начать сегодня, если нужно, дать ему обучаться всю ночь и, так сказать, подготовить разделяемый синтетический набор к завтрашнему утру.
Самым большим недостатком является то, что эти сложные модели могут стать дорогими в обучении и обслуживании, если объем данных увеличивается. Каждая таблица также требует собственного полного обучения модели (переносное обучение здесь не подойдет). Не получится масштабировать до сотен таблиц даже при значительном бюджете на вычислительные ресурсы.
В противном случае, вам не повезло.
Вывод
Поскольку сейчас конфиденциальность данных важнее, чем когда-либо, нам доступны отличные методы для генерации синтетических данных или для добавления шума к существующим данным. Однако все они по-прежнему имеют свои ограничения. Помимо нескольких нишевых случаев, еще не создан масштабируемый и гибкий инструмент корпоративного уровня, который позволял бы передавать данные, содержащие личную информацию, недоверенным сторонам.
Владельцы данных по-прежнему должны доверять установленным методам или системам, что требует от них большого доверия. Это самая большая проблема!
А пока, если вы хотите попробовать (для проверки концепции, просто потестировать), откройте любую из упомянутых выше ссылок.
