Привет, Хабр! Сегодня мы хотим рассказать, чем занимается лаборатория методов ядерно-физических экспериментов, входящая в JetBrains Research.
Где JetBrains и где ядерная физика, спросите вы. Мы сошлись на почве любви к Kotlin, хотя в данном посте о нем речи не пойдет. Наша группа ориентируется на развитие методик анализа данных, моделирования и написание софта для ученых, и поэтому ориентирована на сотрудничество и обмен знаниями с IT-компаниями.
В этой статье мы хотим поговорить о популяризуемом нами методе статистической регуляризации, предложенном В.Ф.Турчиным в 70-х годах XX века, и его реализации в виде кода на Python и Julia.
Изложение будет достаточно подробным, поэтому те, кому все очевидно с обратными задачами, могут сразу переходить к примерам, а теорию прочитать в этой статье.
Если достаточно абстрагироваться, любое измерение в эксперименте можно описать следующим образом: есть некий прибор, который фиксирует спектр или сигнал какого-либо процесса и по результатам измерения показывает какие-то цифры. Наша задача как исследователей, глядя на эти цифры и зная устройство прибора, понять какой был измеряемый спектр или сигнал. То есть на лицо то, что называется обратной задачей. Если представить это математически, получим вот такое уравнение (которое, кстати, называется уравнением Фредгольма первого рода): , которая действует на исследуемый спектр или иной входной сигнал
, которая действует на исследуемый спектр или иной входной сигнал  , в результате чего исследователь наблюдает выходной сигнал
, в результате чего исследователь наблюдает выходной сигнал  . Цель исследователя — восстановить сигнал по известным и . Также можно сформулировать это выражение в матричной форме, заменив функции векторами и матрицами:
. Цель исследователя — восстановить сигнал по известным и . Также можно сформулировать это выражение в матричной форме, заменив функции векторами и матрицами:
Важно, что всякое реальное измерение имеет погрешность, поэтому мы немного испортим наш результат, добавив нормальный шум, дающий пятипроцентную ошибку измерения.
Восстанавливать сигнал мы будем методом наименьших квадратов:
Собственно, на этом можно было бы закончить статью, в очередной раз убедившись в беспомощности идеалистических методов математики перед лицом суровой и безжалостной физической реальности, и пойти раскуривать паяльники.
Но давайте сначала разберемся, из-за чего сия неудача постигла нас? Очевидно дело в ошибках измерений, но на что же они влияют? Дело в том, что еще Жак Адамар (тот самый, который добавил черточку в формулу Коши — Адамара) разделил все задачи на корректно поставленные и некорректно.
Вспомнив классиков: «Бессмыслица — искать решение, если оно и так есть. Речь идет о том, как поступать с задачей, которая решения не имеет. Это глубоко принципиальный вопрос…» — мы не будем говорить о корректных задачах и сразу возьмемся за некорректные. Благо мы уже встретили такую: написанное выше уравнение Фредгольма является некорректной обратной задачей — даже при бесконечно малых флуктуациях во входных данных (а уж наши ошибки измерения далеко не бесконечно малые) решение уравнения, полученное точным аналитическим образом, может сколь угодно отличаться от истинного.
Доказательство этого утверждения вы можете прочитать в первой главе классического труда академика А.Н. Тихонова «Методы решения некорректных задач». В этой книге есть советы о том, что делать с некорректными задачи, однако изложенная там методика имеет ряд недостатков, которые устранены в методе Турчина. Но для начала опишем общие принципы работы с некорректными задачами: что же делать, если вам попалась такая задача?
Поскольку сама задача не может нам ничего предложить, придется пойти на небольшое преступление: дополнить задачу данными так, чтобы она стала корректной, иначе говоря, ввести какую-то *дополнительную априорную информацию о задаче* (этот процесс называется регуляризацией задачи). В отличие от классического метода Тихонова, основанного на введении параметризованных регуляризирующих функционалов, метод Турчина заходит с другой стороны, используя байесовские методы.
Сформулируем нашу задачу в терминах математической статистики: по известной реализации (которую мы измеряем в эксперименте) нам нужно оценить значение параметра . Функционал
(которую мы измеряем в эксперименте) нам нужно оценить значение параметра . Функционал  вычисляющий на основе мы будем называть стратегией. Для того чтобы определить, какие стратегии более оптимальны, введем квадратичную функцию потерь. Реальная функция потерь может быть любой, почему же мы выбираем именно квадратичную? Потому что любая функция потерь вблизи своего минимума может быть аппроксимирована квадратичной функцией:
вычисляющий на основе мы будем называть стратегией. Для того чтобы определить, какие стратегии более оптимальны, введем квадратичную функцию потерь. Реальная функция потерь может быть любой, почему же мы выбираем именно квадратичную? Потому что любая функция потерь вблизи своего минимума может быть аппроксимирована квадратичной функцией:
 — наилучшее решение. Тогда потери для выбранной нами стратегии задаются функцией риска:
— наилучшее решение. Тогда потери для выбранной нами стратегии задаются функцией риска:
 определяет плотность вероятности нашего ансамбля, по которому производится усреднение потерь. Этот ансамбль образован гипотетическим многократным повторением измерений при заданном . Таким образом, — это та самая известная нам плотность вероятности , полученная в эксперименте.
определяет плотность вероятности нашего ансамбля, по которому производится усреднение потерь. Этот ансамбль образован гипотетическим многократным повторением измерений при заданном . Таким образом, — это та самая известная нам плотность вероятности , полученная в эксперименте.
Согласно байессовскому подходу, предлагается рассмотреть как случайную переменную с априорной плотностью вероятности  , выражающую достоверность различных решений нашей задачи. определяется на основе информации, существующей до проведения эксперимента. Тогда выбор оптимальной стратегии основывается на минимизации апостериорного риска:
, выражающую достоверность различных решений нашей задачи. определяется на основе информации, существующей до проведения эксперимента. Тогда выбор оптимальной стратегии основывается на минимизации апостериорного риска:
 определяется по теореме Байеса:
определяется по теореме Байеса:
. Можем ли мы сказать что-либо о том мире функций  , который задается априорной плотностью?
, который задается априорной плотностью?
Если ответ на этот вопрос отрицательный, то мы должны будем принять все возможные равновероятными и вернуться к нерегуляризованному решению. Таким образом, мы должны ответить на этот вопрос положительно.
Именно в этом и заключается метод статистической регуляризации — регуляризация решения за счет введения дополнительной априорной информации о. Если исследователь уже обладает какой-либо априорной информацией (априорной плотностью  ), он может просто вычислить интеграл и получить ответ.
), он может просто вычислить интеграл и получить ответ.
В случае если такой информации нет, в следующем параграфе описывается, какой минимальной информацией может обладать исследователь и как ее использовать для получения регуляризованного решения.
Как показали британские ученые, во всем остальном мире любят дифференцировать. Причем, если математик будет задаваться вопросами о правомерности этой операции, то физик оптимистично верит, что законы природы описываются «хорошими» функциями, то есть гладкими.
Иначе говоря, он назначает более гладким более высокую априорную плотность вероятности. Так давайте попробуем ввести априорную вероятность, основанную на гладкости. Для этого вспомним, что введение априорной информации — это некоторое насилие над миром, принуждающее законы природы выглядеть удобным для нас образом.
Это насилие следует свести к минимуму, и, вводя априорную плотность вероятности, необходимо, чтобы информация Шеннона относительно, содержащаяся в , была минимальной. Формализуя вышесказанное, выведем вид априорной плотности, основанной на гладкости функции. Для этого мы будем искать условный экстремум информации:
Первый случай нам мало интересен. Во втором случае мы должны посчитать вот такой вот страшненький интеграл:
Также следует отметить, что мы нигде пока не использовали, что — это оператор гладкости. На самом деле мы можем использовать здесь любой другой оператор (или их линейную комбинацию), просто гладкость функции — это наиболее очевидный вид априорной информации, который мы можем использовать.
— это оператор гладкости. На самом деле мы можем использовать здесь любой другой оператор (или их линейную комбинацию), просто гладкость функции — это наиболее очевидный вид априорной информации, который мы можем использовать.
Мы говорили о функциях, но любой реальный прибор не может измерить не то что континуальное, но даже счетное множество точек. Мы всегда проводим измерение в конечном наборе точек, поэтому вынуждены проводить процедуры дискретизации и перехода от интегрального уравнения к матричному. В методе статистической регуляризации мы поступаем следующим образом: будем раскладывать по некоторой системе функций  :
:
 , который является вектором в функциональном пространстве.
, который является вектором в функциональном пространстве.
В качестве функционального пространства можно взять гильбертово пространство, а можно, например, пространство полиномов. Причем выбор базиса в этих пространствах ограничен только вашей фантазией (мы пробовали работать с тригонометрическим рядом Фурье, полижандрами и кубическими сплайнами).
Тогда элементы матрицы вычисляются как:
вычисляются как:
 — точки, в которых производились измерения. Элементы матрицы будем вычислять по формуле:
— точки, в которых производились измерения. Элементы матрицы будем вычислять по формуле:
 и
и  — границы интервала, на котором определена функция .
— границы интервала, на котором определена функция .
Для перерасчета ошибок следует использовать формулу дисперсии линейной комбинации случайных величин:
к поиску вектора и в следующем разделе найдем-таки его.
Случай, когда ошибки в эксперименте распределены по Гауссу, замечателен
тем, что можно получить аналитическое решение нашей задачи. Поскольку априорная информация и ошибки имеют гауссов вид, то и их произведение тоже имеет гауссов вид, и тогда тот страшненький интеграл, который мы писали выше, легко берется. Решение и его ошибка будут иметь следующий вид:
 — ковариационная матрица многомерного распределения Гаусса,
— ковариационная матрица многомерного распределения Гаусса,  — наиболее вероятное значение параметра
— наиболее вероятное значение параметра  , которое определяется из условия максимума апостериорной плотности вероятности:
, которое определяется из условия максимума апостериорной плотности вероятности:
Этому будет посвящена вторая часть статьи, а пока обозначим суть проблемы.
Основная проблема в том, что этот страшный интеграл, во-первых многомерный, а во-вторых в бесконечных пределах. Причем он сильно многомерный, вектор спокойно может иметь размерность  , а сеточные методы вычисления интегралов имеют сложность типа
, а сеточные методы вычисления интегралов имеют сложность типа  , поэтому малоприменимы в данном случае. При взятии многомерных интегралов хорошо работает интегрирование методами Монте-Карло.
, поэтому малоприменимы в данном случае. При взятии многомерных интегралов хорошо работает интегрирование методами Монте-Карло.
Причем поскольку у нас пределы бесконечные, мы должны использовать метод существенной выборки (important sampling), однако тогда нам потребуется подбирать функцию для сэмплирования. Что бы сделать все более автоматизированным следует использовать Markov Chain Monte Carlo (MCMC), который может самостоятельно адаптировать семплирующую функцию под вычисляемый интеграл. Про применение MCMC мы поговорим в следующей статье.
Первая реализация метода статистической регуляризации была написана еще в 70-х на Алголе и успешно использовалась для расчетов в атмосферной физике. Несмотря на то, что у нас остались рукописные исходники алгоритма, мы решили добавить немного модернизма и сделать реализацию на Python, а затем и на Julia.
Устанавливаем через
или качаем исходный код.
В качестве примера рассмотрим, как использовать модуль
Импортируем нужные научные пакеты.
Определяем истинный сигнал, который будем восстанавливать.
Определим ядро и операцию свертки функций (Примечание:
Генерируем измеренные данные и зашумляем их с помощью нормального распределения:
Импортируем решатель и вспомогательный класс для дискретизации:
Как функциональный базис для дискретизации мы используем кубические сплайны, причем в качестве дополнительного условия мы укажем, что функция принимает на края нулевые значения.
Решаем уравнение:
Строим график решения:
Импортируем решатель и вспомогательный класс для дискретизации:
Для получения матриц, мы используем наш функциональный базис, но понятно дело матрицы могут быть получены каким угодно путем.
Решаем матричное уравнение:
Строим график:
Как мы упоминали, для дальнейшего развития методики требуется продвинутое Монте-Карло интегрирование. Мы могли бы использовать какой-либо модуль на Python (например, мы работали с PyMC3), однако мы, помимо прочего, участвуем в совместном проекте с институтом Макса Планка в Мюнхене.
Этот проект называется Bayesian Analysis Toolkit. Его цель — создание фреймворка с инструментами для байесовских методов анализа, в первую очередь включая инструменты для MCMC. Сейчас команда работает над второй версией фреймворка, которая пишется на Julia (первая написана на плохом C++). Одна из задач нашей группы — продемонстрировать возможности этого фреймворка на примере статистической регуляризации, поэтому мы написали реализацию на Julia.
На этот раз используем другое ядро, будем брать не интегрирующую ступеньку, а свертку с гауссом, которая фактическим наводит некий «блюр» на наши данные:
Аналогично возьмем базис сплайнов с закрепленными концами:
В качестве примера анализа реальных данных мы восстановим спектр рассеяния электронов на водородно-дейтериевой смеси. В опыте измерялся интегральный спектр (то есть число электронов выше определенной энергии), а нам нужно восстановить дифференциальный спектр. Для этих данных первоначально был восстановлен спектр с помощью фитирования, так что у нас есть основа для проверки корректности нашего алгоритма.
Вот так выглядит исходный интегральный спектр:
А так — результат восстановления:
Анализ с помощью фита имеет три основных недостатка:
Статистическая регуляризация позволяет избежать всех этих проблем и обеспечивает модельнонезависимый результат с ошибками измерения. Решение, полученное регуляризацией, хорошо согласуется с фитирующей кривой. Обратите внимание на два маленьких пика при 25 и 30 эВ. Известно, что пик при 25 эВ образуется при двойном рассеянии, и он был восстановлен фитом, поскольку в фитирующей функции он был явно задан. Пик 30 эВ может быть статистической аномалией (ошибки довольно велики в этой точке), или, возможно, указывает на наличие дополнительного диссоциативного рассеяния.
Мы рассказали вам о полезной методике, которую можно адаптировать под многие задачи анализа данных (в том числе машинного обучения), причем получить честную «подгонку» ответа — наиболее рациональное решение уравнение в условиях неопределенности, вызванной ошибками измерения. Как приятный бонус мы получаем значения для ошибки решения. Желающие участвовать в развитии или применять метод статистической регуляризации, могут внести свой вклад в виде кода на Python, Julia или на чем-нибудь еще.
В следующей части мы поговорим о:
Автор статьи: Михаил Зелёный, исследователь лаборатории методов ядерно-физических экспериментов в JetBrains Research.
Где JetBrains и где ядерная физика, спросите вы. Мы сошлись на почве любви к Kotlin, хотя в данном посте о нем речи не пойдет. Наша группа ориентируется на развитие методик анализа данных, моделирования и написание софта для ученых, и поэтому ориентирована на сотрудничество и обмен знаниями с IT-компаниями.
В этой статье мы хотим поговорить о популяризуемом нами методе статистической регуляризации, предложенном В.Ф.Турчиным в 70-х годах XX века, и его реализации в виде кода на Python и Julia.
Изложение будет достаточно подробным, поэтому те, кому все очевидно с обратными задачами, могут сразу переходить к примерам, а теорию прочитать в этой статье.
- Возникновение проблемы: зачем вообще кого-то регуляризировать?
- Теоретическое описание статистической регуляризации
- Практические примеры на:
- Заключение
Возникновение проблемы: зачем вообще кого-то регуляризировать?
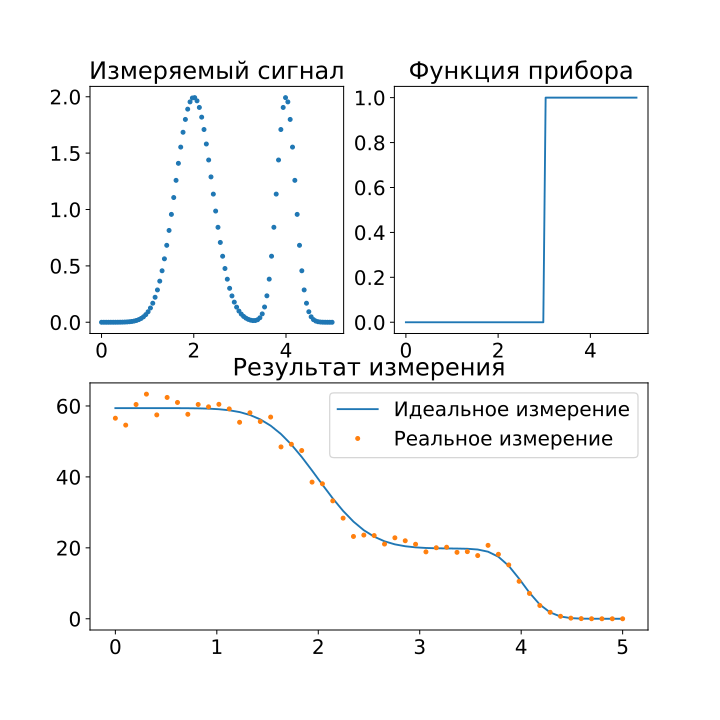
Если достаточно абстрагироваться, любое измерение в эксперименте можно описать следующим образом: есть некий прибор, который фиксирует спектр или сигнал какого-либо процесса и по результатам измерения показывает какие-то цифры. Наша задача как исследователей, глядя на эти цифры и зная устройство прибора, понять какой был измеряемый спектр или сигнал. То есть на лицо то, что называется обратной задачей. Если представить это математически, получим вот такое уравнение (которое, кстати, называется уравнением Фредгольма первого рода):

, которая действует на исследуемый спектр или иной входной сигнал , в результате чего исследователь наблюдает выходной сигнал . Цель исследователя — восстановить сигнал по известным и . Также можно сформулировать это выражение в матричной форме, заменив функции векторами и матрицами:



Важно, что всякое реальное измерение имеет погрешность, поэтому мы немного испортим наш результат, добавив нормальный шум, дающий пятипроцентную ошибку измерения.
Восстанавливать сигнал мы будем методом наименьших квадратов:


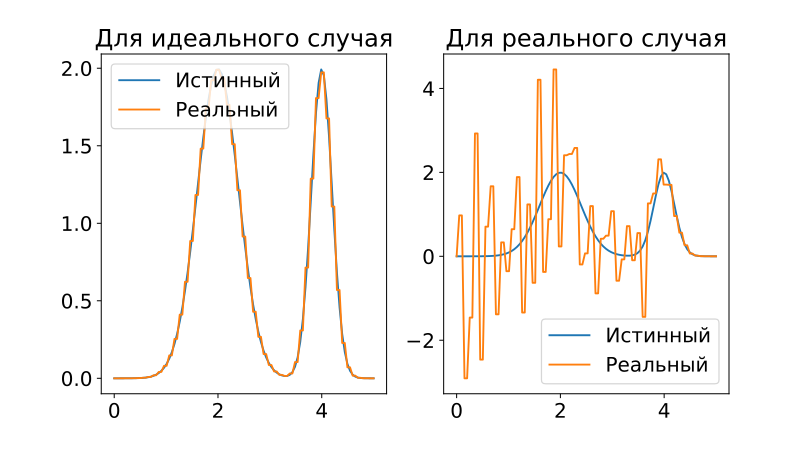
Собственно, на этом можно было бы закончить статью, в очередной раз убедившись в беспомощности идеалистических методов математики перед лицом суровой и безжалостной физической реальности, и пойти раскуривать паяльники.
Но давайте сначала разберемся, из-за чего сия неудача постигла нас? Очевидно дело в ошибках измерений, но на что же они влияют? Дело в том, что еще Жак Адамар (тот самый, который добавил черточку в формулу Коши — Адамара) разделил все задачи на корректно поставленные и некорректно.
Вспомнив классиков: «Бессмыслица — искать решение, если оно и так есть. Речь идет о том, как поступать с задачей, которая решения не имеет. Это глубоко принципиальный вопрос…» — мы не будем говорить о корректных задачах и сразу возьмемся за некорректные. Благо мы уже встретили такую: написанное выше уравнение Фредгольма является некорректной обратной задачей — даже при бесконечно малых флуктуациях во входных данных (а уж наши ошибки измерения далеко не бесконечно малые) решение уравнения, полученное точным аналитическим образом, может сколь угодно отличаться от истинного.
Доказательство этого утверждения вы можете прочитать в первой главе классического труда академика А.Н. Тихонова «Методы решения некорректных задач». В этой книге есть советы о том, что делать с некорректными задачи, однако изложенная там методика имеет ряд недостатков, которые устранены в методе Турчина. Но для начала опишем общие принципы работы с некорректными задачами: что же делать, если вам попалась такая задача?
Поскольку сама задача не может нам ничего предложить, придется пойти на небольшое преступление: дополнить задачу данными так, чтобы она стала корректной, иначе говоря, ввести какую-то *дополнительную априорную информацию о задаче* (этот процесс называется регуляризацией задачи). В отличие от классического метода Тихонова, основанного на введении параметризованных регуляризирующих функционалов, метод Турчина заходит с другой стороны, используя байесовские методы.
Теоретическое описание статистической регуляризации
Стратегия
Сформулируем нашу задачу в терминах математической статистики: по известной реализации
(которую мы измеряем в эксперименте) нам нужно оценить значение параметра . Функционал вычисляющий на основе мы будем называть стратегией. Для того чтобы определить, какие стратегии более оптимальны, введем квадратичную функцию потерь. Реальная функция потерь может быть любой, почему же мы выбираем именно квадратичную? Потому что любая функция потерь вблизи своего минимума может быть аппроксимирована квадратичной функцией:![$L(\varphi,\hat{S}[f]) = ||\hat{\varphi}-\hat{S}[f])||_{L_2},$](https://habrastorage.org/getpro/habr/formulas/c06/b83/c36/c06b83c361047c16bbb3ea93dfddd737.svg)
— наилучшее решение. Тогда потери для выбранной нами стратегии задаются функцией риска:![$R_{\hat{S}[f]}(\varphi) \equiv E[L(\varphi,\hat{S}[f])] = \int L(\varphi,\hat{S}[f])P(f|\varphi)df.$](https://habrastorage.org/getpro/habr/formulas/bb5/f2b/595/bb5f2b595557e2e54de0d9ac2abb64db.svg)
определяет плотность вероятности нашего ансамбля, по которому производится усреднение потерь. Этот ансамбль образован гипотетическим многократным повторением измерений при заданном . Таким образом, — это та самая известная нам плотность вероятности , полученная в эксперименте.Согласно байессовскому подходу, предлагается рассмотреть
как случайную переменную с априорной плотностью вероятности , выражающую достоверность различных решений нашей задачи. определяется на основе информации, существующей до проведения эксперимента. Тогда выбор оптимальной стратегии основывается на минимизации апостериорного риска:![$r_{\hat{S}}(\varphi) \equiv E_{\varphi}E_{f}[L(\varphi,\hat{S}[f])|\varphi]$](https://habrastorage.org/getpro/habr/formulas/0c2/4c3/b21/0c24c3b2128acf4fc019feb11d3c0fa7.svg)
![$\hat{S}[f] = E[\varphi|f] = \int \varphi P(\varphi|f)d\varphi,$](https://habrastorage.org/getpro/habr/formulas/7da/62c/7e3/7da62c7e3ca8f1043f5ad6a0dd6771dc.svg)
определяется по теореме Байеса:
][\varphi(x_2) - \hat{S}[f](x_2)]$](https://habrastorage.org/getpro/habr/formulas/1e5/7aa/369/1e57aa369887f170ac087cd0608eac3b.svg)
. Можем ли мы сказать что-либо о том мире функций , который задается априорной плотностью? Если ответ на этот вопрос отрицательный, то мы должны будем принять все возможные
равновероятными и вернуться к нерегуляризованному решению. Таким образом, мы должны ответить на этот вопрос положительно. Именно в этом и заключается метод статистической регуляризации — регуляризация решения за счет введения дополнительной априорной информации о
. Если исследователь уже обладает какой-либо априорной информацией (априорной плотностью ), он может просто вычислить интеграл и получить ответ. В случае если такой информации нет, в следующем параграфе описывается, какой минимальной информацией может обладать исследователь и как ее использовать для получения регуляризованного решения.
Априорная информация
Как показали британские ученые, во всем остальном мире любят дифференцировать. Причем, если математик будет задаваться вопросами о правомерности этой операции, то физик оптимистично верит, что законы природы описываются «хорошими» функциями, то есть гладкими.
Иначе говоря, он назначает более гладким
более высокую априорную плотность вероятности. Так давайте попробуем ввести априорную вероятность, основанную на гладкости. Для этого вспомним, что введение априорной информации — это некоторое насилие над миром, принуждающее законы природы выглядеть удобным для нас образом. Это насилие следует свести к минимуму, и, вводя априорную плотность вероятности, необходимо, чтобы информация Шеннона относительно
, содержащаяся в , была минимальной. Формализуя вышесказанное, выведем вид априорной плотности, основанной на гладкости функции. Для этого мы будем искать условный экстремум информации:![$I[P(\vec{\varphi})] = \int \ln{P(\vec{\varphi})} P(\vec{\varphi}) d\vec{\varphi} \to min $](https://habrastorage.org/getpro/habr/formulas/f85/32a/c26/f8532ac266b6015f4ebbf21849dde989.svg)
- Условие на гладкость . Пусть — некоторая матрица, характеризующая гладкость функции. Тогда потребуем, чтобы достигалось определенное значение функционала гладкости:
Внимательный читатель должен задать вопрос об определении значения параметра
 . Ответ на него будет дан далее по тексту.
. Ответ на него будет дан далее по тексту.
- Нормированность вероятности на единицу:

При этих условиях доставлять минимум функционалу будет следующая функция:
Параметр связан с , но поскольку у нас нет информации о конкретных значениях функционала гладкости, выяснять, как именно он связан, бессмысленно. Что же тогда делать с , спросите вы. Здесь перед вами раскрываются три пути:
связан с , но поскольку у нас нет информации о конкретных значениях функционала гладкости, выяснять, как именно он связан, бессмысленно. Что же тогда делать с , спросите вы. Здесь перед вами раскрываются три пути:
- Подбирать значение параметра вручную и тем самым фактически перейти к регуляризации Тихонова
- Усреднить (проинтегрировать) по всем возможным , предполагая все возможные равновероятными
- Выбрать наиболее вероятное по его апостериорной плотности вероятности
 . Этот подход верен, поскольку дает хорошую аппроксимацию интеграла, если в экспериментальных данных содержится достаточно информации об .
. Этот подход верен, поскольку дает хорошую аппроксимацию интеграла, если в экспериментальных данных содержится достаточно информации об .
- Подбирать значение параметра
Первый случай нам мало интересен. Во втором случае мы должны посчитать вот такой вот страшненький интеграл:

Также следует отметить, что мы нигде пока не использовали, что
— это оператор гладкости. На самом деле мы можем использовать здесь любой другой оператор (или их линейную комбинацию), просто гладкость функции — это наиболее очевидный вид априорной информации, который мы можем использовать.Дискретизация
Мы говорили о функциях, но любой реальный прибор не может измерить не то что континуальное, но даже счетное множество точек. Мы всегда проводим измерение в конечном наборе точек, поэтому вынуждены проводить процедуры дискретизации и перехода от интегрального уравнения к матричному. В методе статистической регуляризации мы поступаем следующим образом: будем раскладывать
по некоторой системе функций :
, который является вектором в функциональном пространстве.В качестве функционального пространства можно взять гильбертово пространство, а можно, например, пространство полиномов. Причем выбор базиса в этих пространствах ограничен только вашей фантазией (мы пробовали работать с тригонометрическим рядом Фурье, полижандрами и кубическими сплайнами).
Тогда элементы матрицы
вычисляются как:
— точки, в которых производились измерения. Элементы матрицы будем вычислять по формуле:
и — границы интервала, на котором определена функция .Для перерасчета ошибок следует использовать формулу дисперсии линейной комбинации случайных величин:
![$D[\varphi(x)] = D[\sum \limits_n \varphi_n T_n(x)] = \sum\limits_{i,j} \varphi_i\varphi_j cov(T_i(x), T_j(x)).$](https://habrastorage.org/getpro/habr/formulas/e06/48f/b69/e0648fb69a2f1cd751f20360b1625832.svg)
к поиску вектора и в следующем разделе найдем-таки его.Случай гауссовых шумов
Случай, когда ошибки в эксперименте распределены по Гауссу, замечателен
тем, что можно получить аналитическое решение нашей задачи. Поскольку априорная информация и ошибки имеют гауссов вид, то и их произведение тоже имеет гауссов вид, и тогда тот страшненький интеграл, который мы писали выше, легко берется. Решение и его ошибка будут иметь следующий вид:


— ковариационная матрица многомерного распределения Гаусса, — наиболее вероятное значение параметра , которое определяется из условия максимума апостериорной плотности вероятности: 
А если у меня не гауссовы ошибки?
Этому будет посвящена вторая часть статьи, а пока обозначим суть проблемы.
Основная проблема в том, что этот страшный интеграл, во-первых многомерный, а во-вторых в бесконечных пределах. Причем он сильно многомерный, вектор
спокойно может иметь размерность , а сеточные методы вычисления интегралов имеют сложность типа , поэтому малоприменимы в данном случае. При взятии многомерных интегралов хорошо работает интегрирование методами Монте-Карло. Причем поскольку у нас пределы бесконечные, мы должны использовать метод существенной выборки (important sampling), однако тогда нам потребуется подбирать функцию для сэмплирования. Что бы сделать все более автоматизированным следует использовать Markov Chain Monte Carlo (MCMC), который может самостоятельно адаптировать семплирующую функцию под вычисляемый интеграл. Про применение MCMC мы поговорим в следующей статье.
Практическая часть
Первая реализация метода статистической регуляризации была написана еще в 70-х на Алголе и успешно использовалась для расчетов в атмосферной физике. Несмотря на то, что у нас остались рукописные исходники алгоритма, мы решили добавить немного модернизма и сделать реализацию на Python, а затем и на Julia.
Python
Установка
Устанавливаем через
pip:pip install statregили качаем исходный код.
Примеры
В качестве примера рассмотрим, как использовать модуль
stareg для восстановление данных для матричного и интегрального уравнения.Импортируем нужные научные пакеты.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.integrate import quad
%matplotlib inlineОпределяем истинный сигнал, который будем восстанавливать.
a = 0
b = 5
# Восстанавливаемый сигнал
phi = lambda x: 4*norm.pdf(x-2, scale=0.4) + 2*norm.pdf(x-4, scale = 0.5)
x = np.linspace(a, b,100)
plt.plot(x, phi(x));
Определим ядро и операцию свертки функций (Примечание:
np.convolution определенно для массивов):kernel = lambda x,y : np.heaviside(x-y, 1) # Ядро уравнения
convolution = np.vectorize(lambda y: quad(lambda x: kernel(x,y)*phi(x), a,b)[0])Генерируем измеренные данные и зашумляем их с помощью нормального распределения:
y = np.linspace(a, b, 50)
ftrue = convolution(y)
sig = 0.05*ftrue +0.01 # Ошибка измерения
f = norm.rvs(loc = ftrue, scale=sig)
plt.errorbar(y, f, yerr=sig);
Решаем интегральное уравнение
Импортируем решатель и вспомогательный класс для дискретизации:
from statreg.model import GaussErrorUnfolder
from statreg.basis import CubicSplinesКак функциональный базис для дискретизации мы используем кубические сплайны, причем в качестве дополнительного условия мы укажем, что функция принимает на края нулевые значения.
basis = CubicSplines(y, boundary='dirichlet')
model = GaussErrorUnfolder(basis, basis.omega(2))Решаем уравнение:
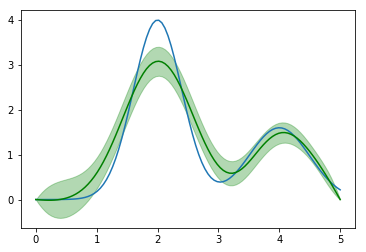
phi_reconstruct = model.solve(kernel, f, sig, y)Строим график решения:
plt.plot(x,phi(x))
phir = phi_reconstruct(x)
phiEr = phi_reconstruct.error(x)
plt.plot(x, phir, 'g')
plt.fill_between(x, phir-phiEr, phir + phiEr, color='g', alpha=0.3);
Решаем матричное уравнение
Импортируем решатель и вспомогательный класс для дискретизации:
from statreg.model import GaussErrorMatrixUnfolder
from statreg.basis import CubicSplinesДля получения матриц, мы используем наш функциональный базис, но понятно дело матрицы могут быть получены каким угодно путем.
cubicSplines = CubicSplines(y, boundary='dirichlet')
omega = cubicSplines.omega(2)
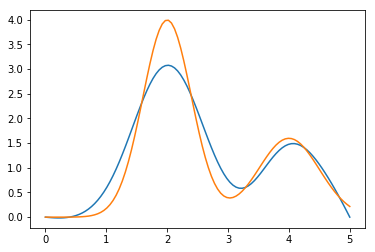
Kmn = cubicSplines.discretizeKernel(kernel,y)Решаем матричное уравнение:
model = GaussErrorMatrixUnfolder(omega)
result = model.solve(Kmn, f, sig)Строим график:
phir = lambda x: sum([p*bf(x) for p, bf in zip(result.phi,cubicSplines.basisFun)])
plt.plot(x,phir(x))
plt.plot(x,phi(x));
Julia
Как мы упоминали, для дальнейшего развития методики требуется продвинутое Монте-Карло интегрирование. Мы могли бы использовать какой-либо модуль на Python (например, мы работали с PyMC3), однако мы, помимо прочего, участвуем в совместном проекте с институтом Макса Планка в Мюнхене.
Этот проект называется Bayesian Analysis Toolkit. Его цель — создание фреймворка с инструментами для байесовских методов анализа, в первую очередь включая инструменты для MCMC. Сейчас команда работает над второй версией фреймворка, которая пишется на Julia (первая написана на плохом C++). Одна из задач нашей группы — продемонстрировать возможности этого фреймворка на примере статистической регуляризации, поэтому мы написали реализацию на Julia.
using PyCall
include("../src/gauss_error.jl")
include("../src/kernels.jl")
a = 0.
b = 6.
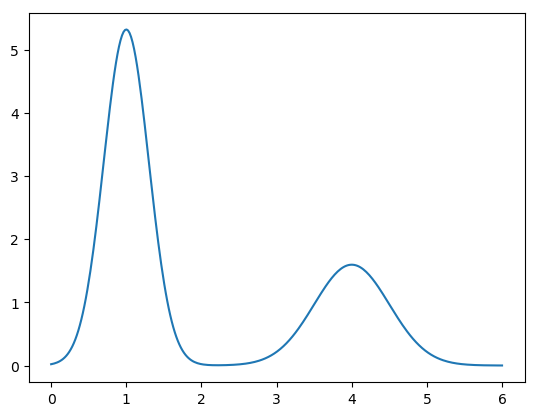
function phi(x::Float64)
mu1 = 1.
mu2 = 4.
n1 = 4.
n2 = 2.
sig1 = 0.3
sig2 = 0.5
norm(n, mu, sig, x) = n / sqrt(2 * pi*sig^2) * exp(-(x - mu)^2 / (2 * sig^2))
return norm(n1, mu1, sig1, x) + norm(n2, mu2, sig2, x)
end
x = collect(range(a, stop=b, length=300))
import PyPlot.plot
myplot = plot(x, phi.(x))
savefig("function.png", dpi=1000)
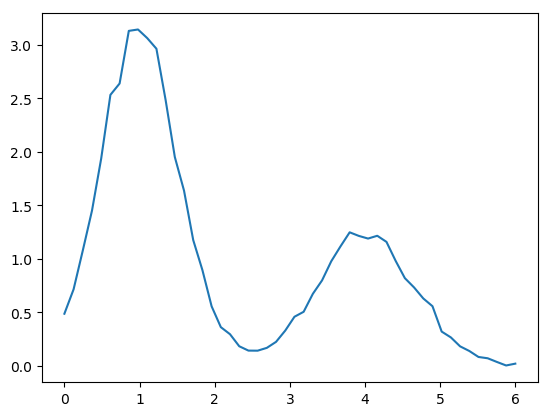
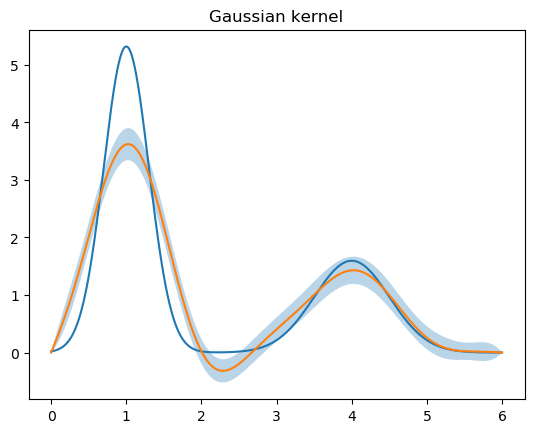
На этот раз используем другое ядро, будем брать не интегрирующую ступеньку, а свертку с гауссом, которая фактическим наводит некий «блюр» на наши данные:
function kernel(x::Float64, y::Float64)
return getOpticsKernels("gaussian")(x, y)
end
convolution = y -> quadgk(x -> kernel(x,y) * phi(x), a, b, maxevals=10^7)[1]
y = collect(range(a, stop = b, length=50))
ftrue = convolution.(y)
sig = 0.05*abs.(ftrue) +[0.01 for i = 1:Base.length(ftrue)]
using Compat, Random, Distributions
noise = []
for sigma in sig
n = rand(Normal(0., sigma), 1)[1]
push!(noise, n)
end
f = ftrue + noise
plot(y, f)
Аналогично возьмем базис сплайнов с закрепленными концами:
basis = CubicSplineBasis(y, "dirichlet")
Kmn = discretize_kernel(basis, kernel, y)
model = GaussErrorMatrixUnfolder([omega(basis, 2)], "EmpiricalBayes", nothing, [1e-5], [1.], [0.5])
result = solve(model, Kmn, f, sig)
phivec = PhiVec(result, basis)
x = collect(range(a, stop=b, length=5000))
plot(x, phi.(x))
phi_reconstructed = phivec.phi_function.(x)
phi_reconstructed_errors = phivec.error_function.(x)
plot(x, phi_reconstructed)
fill_between(x, phi_reconstructed - phi_reconstructed_errors, phi_reconstructed + phi_reconstructed_errors, alpha=0.3)
Пример на реальных данных
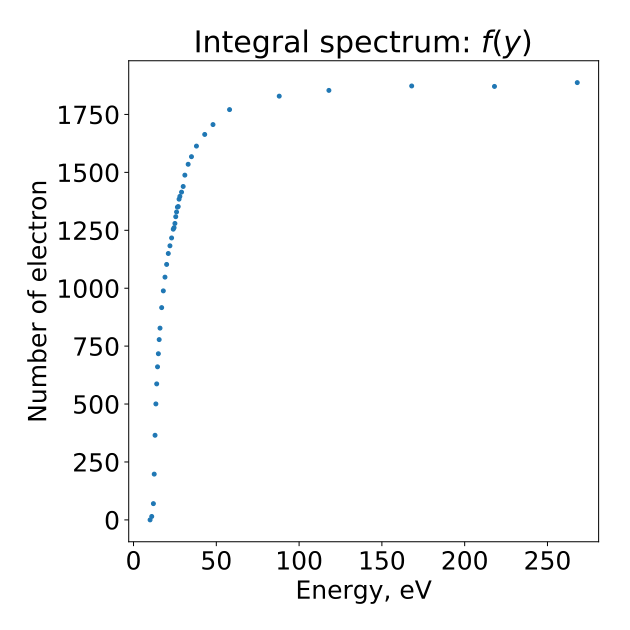
В качестве примера анализа реальных данных мы восстановим спектр рассеяния электронов на водородно-дейтериевой смеси. В опыте измерялся интегральный спектр (то есть число электронов выше определенной энергии), а нам нужно восстановить дифференциальный спектр. Для этих данных первоначально был восстановлен спектр с помощью фитирования, так что у нас есть основа для проверки корректности нашего алгоритма.
Вот так выглядит исходный интегральный спектр:

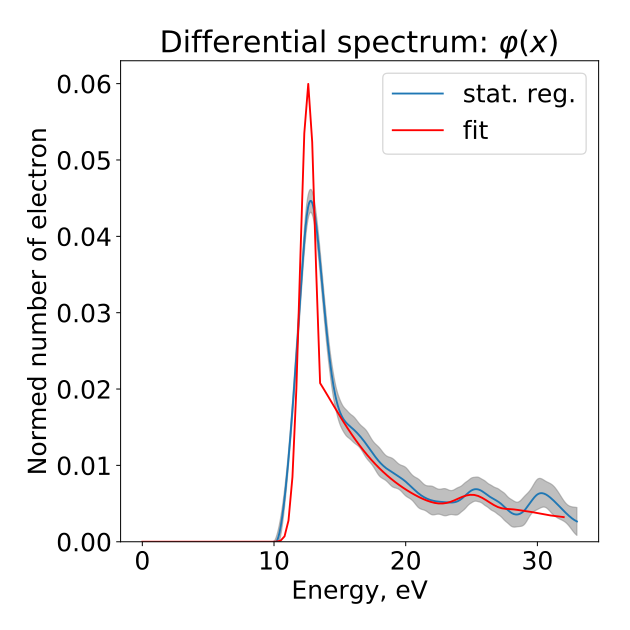
А так — результат восстановления:

Анализ с помощью фита имеет три основных недостатка:
- Параметрическая форма для подгонки не имеет достаточной физической основы, поэтому результат является субъективным в отношении параметризации.
- Выбранная параметризация имеет слишком много параметров и дает очень тесные корреляции между параметрами, делая результаты подгонки нестабильными.
- Не существует четкого способа определения ошибок для любой заданной точки восстановленной функции.
Статистическая регуляризация позволяет избежать всех этих проблем и обеспечивает модельнонезависимый результат с ошибками измерения. Решение, полученное регуляризацией, хорошо согласуется с фитирующей кривой. Обратите внимание на два маленьких пика при 25 и 30 эВ. Известно, что пик при 25 эВ образуется при двойном рассеянии, и он был восстановлен фитом, поскольку в фитирующей функции он был явно задан. Пик 30 эВ может быть статистической аномалией (ошибки довольно велики в этой точке), или, возможно, указывает на наличие дополнительного диссоциативного рассеяния.
Выводы и анонс следующей части
Мы рассказали вам о полезной методике, которую можно адаптировать под многие задачи анализа данных (в том числе машинного обучения), причем получить честную «подгонку» ответа — наиболее рациональное решение уравнение в условиях неопределенности, вызванной ошибками измерения. Как приятный бонус мы получаем значения для ошибки решения. Желающие участвовать в развитии или применять метод статистической регуляризации, могут внести свой вклад в виде кода на Python, Julia или на чем-нибудь еще.
В следующей части мы поговорим о:
- Использовании MCMC
- Разложении Холецкого
- В качестве практического примера рассмотрим применение регуляризации для обработки сигнала с модели орбитального детектора протонов и электронов
Ссылки
- Оригинальная работа Турчина
- Диссертация по применению регуляризации в атмосферной физике
- Наша публикация посвященная применению статистической регуляризации
- Реализация на Python
- Реализация на Julia
- Реализация на АЛГОЛ-60, для любителей археологии
- Bayesian analysis toolkit
Автор статьи: Михаил Зелёный, исследователь лаборатории методов ядерно-физических экспериментов в JetBrains Research.
