Привет, Хабр!
 В конце прошлой недели вышел долгожданный «мажорный» релиз инновационного баг-трекера YouTrack 4.0 с возможностью управления Agile-процессами. Об этом функционале мы и хотим вам рассказать немного подробнее.
В конце прошлой недели вышел долгожданный «мажорный» релиз инновационного баг-трекера YouTrack 4.0 с возможностью управления Agile-процессами. Об этом функционале мы и хотим вам рассказать немного подробнее.
YouTrack пользуется популярностью среди разработчиков благодаря развитому использованию клавиатурных шорткатов, эффективных поисковых запросов и командного синтаксиса, а также полностью настраиваемых рабочих процессов и атрибутов ишью.
В YouTrack 4.0 добавлен совершенно новый, независимый модуль для управления Agile-процессами, который без проблем подстроится под особенности реализации Scrum методологии или Kanban-процесса в вашей команде. Если же вы еще только осваиваете Agile-процессы, данный модуль станет прекрасным подспорьем в ознакомлении с ними, а также позволит комбинировать наиболее удобные для вас элементы каждого процесса.
В YouTrack 4.0 реализована ключевая функциональность управления Agile-процессами:
1) Доски задач (Agile Board)
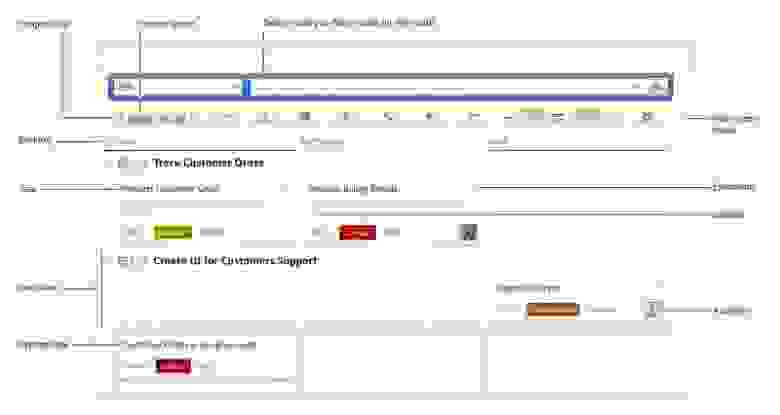
Scrum
Kanban
2) Управление бэклогом
Создайте бэклог для продукта (product backlog) или релиза (release backlog), чтобы удобно планировать и приоритезировать свои задачи в рамках всего проекта, релиза или итерации. Приоритезируйте пользовательские истории или задачи в бэклоге простым перетаскиванием. Используйте шорткаты для упорядочивания и изменения бэклога на лету.
3) Поддержка нескольких проектов на доске
Вы можете вести сразу несколько проектов на доске в рамках одной итерации. Всё, что для этого нужно, это общий набор значений версий для этих проектов.
4) Ваша персональная доска
Используйте расширенные поисковые запросы, чтобы отфильтровать задачи (карточки) на доске точно так же, как вы всегда делали это в YouTrack. Например, отфильтруйте никому не назначенные ишью (#unassigned) или те, которые были назначены вам (for:me).
YouTrack также остается верен поддержке расширенных клавиатурных шорткатов. Используйте шорткаты, чтобы передвигать задачи (карточки) по доске, добавлять, редактировать и удалять «плавательные дорожки» и задачи, и т.п.
Кроме этого, в YouTrack 4.0 добавлено следующее:
Настроив почтовые и jabber-уведомления «под себя», вы можете контролировать, чтО именно следует сообщать вашим пользователям в уведомлении, когда создан новый ишью, когда он был обновлен, прокомментирован или переназначен. Добавьте собственный заголовок, поменяйте язык, переделайте текст сообщения, и многое другое с помощью шаблонов Freemarker.
Теперь вы можете создавать подзадачи для любой задачи (issue). Просто добавьте родительскую или подчиненную ссылку к нужной задаче, либо в режиме Tree-View определите ее место в общей иерархии задач/подзадач простым перетаскиванием на нужный уровень.
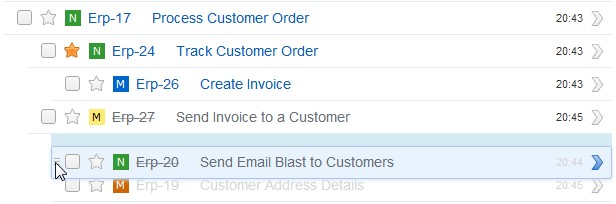
Просто перетаскивайте задачи в общем списке (Issues List), если хотите изменить их порядок, включая порядок результатов поиска или сохраненных запросов. Сохраните результаты поиска, чтобы поделиться ими с членами своей команды.
Работайте с YouTrack в своем персональном контексте. Выбирайте любой сохраненный поиск, тэг или проект в контекстном выпадающем списке и работайте в нем, пока не захотите переключиться в другой контекст. Если вам понадобится отфильтровать задачи сразу во всех проектах в YouTrack, просто выберите в качестве контекста Everything. Используйте боковую панель для закрепления и открепления проектов, тэгов и сохраненных поисков, чтобы сохранить компактный вид этого списка.
Импортируйте в YouTrack пользователей и проекты из AgileZen с пользовательскими историями и их задачами. По умолчанию, история импортируется как фича (feature), а ее задачи (tasks) – как подзадачи (subtasks) к ней.
Нет необходимости добавлять пользователя в список следящих за ишью, чтобы послать ему единственное уведомление. Теперь вы можете уведомить пользователя, просто упомянув его username в комментарии к ишью.
Иногда избыток уведомлений раздражает пользователей или членов команды. Теперь вы можете применять команды без отправки каких-либо уведомлений.
Конечно, это не полный список улучшений, которые мы внедрили, чтобы сделать вашу работу c YouTrack легче, быстрее и эффективнее. Все детали релиза вы можете найти на странице What’s new.
Попробовать YouTrack можно совершенно бесплатно. Загрузите бесплатный пакет на 10 пользователей либо зарегистрируйте YouTrack InCloud, размещенный в облаке JetBrains (предлагается бесплатный план на 9 пользователей).
Благодарим за внимание!
Разрабатывайте с удовольствием!
 В конце прошлой недели вышел долгожданный «мажорный» релиз инновационного баг-трекера YouTrack 4.0 с возможностью управления Agile-процессами. Об этом функционале мы и хотим вам рассказать немного подробнее.
В конце прошлой недели вышел долгожданный «мажорный» релиз инновационного баг-трекера YouTrack 4.0 с возможностью управления Agile-процессами. Об этом функционале мы и хотим вам рассказать немного подробнее.YouTrack пользуется популярностью среди разработчиков благодаря развитому использованию клавиатурных шорткатов, эффективных поисковых запросов и командного синтаксиса, а также полностью настраиваемых рабочих процессов и атрибутов ишью.
В YouTrack 4.0 добавлен совершенно новый, независимый модуль для управления Agile-процессами, который без проблем подстроится под особенности реализации Scrum методологии или Kanban-процесса в вашей команде. Если же вы еще только осваиваете Agile-процессы, данный модуль станет прекрасным подспорьем в ознакомлении с ними, а также позволит комбинировать наиболее удобные для вас элементы каждого процесса.
В YouTrack 4.0 реализована ключевая функциональность управления Agile-процессами:
1) Доски задач (Agile Board)
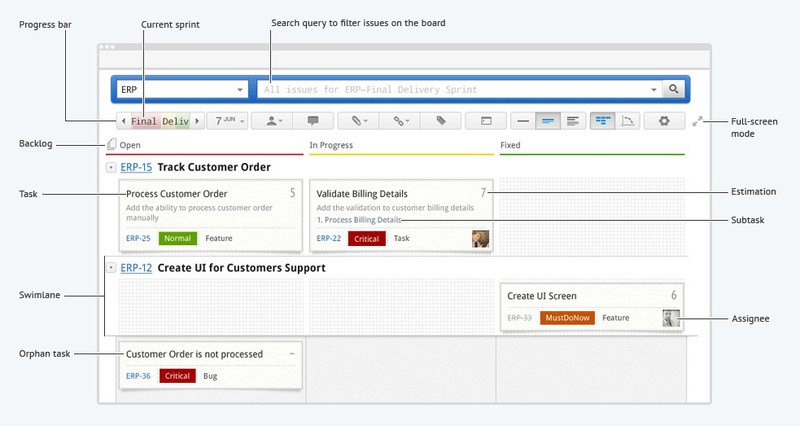
Scrum
- Используйте доску, чтобы визуализировать свою дневную активность. Группируйте ваши задачи, связанные с реализацией каждой пользовательской истории (user story), через создание swimlanes – «плавательных дорожек». Оценивайте и перемещайте задачи по доске, отражая таким образом прогресс команды в течение спринта.
- Создавайте спринты (итерации в scrum) и определяйте продолжительность каждого из них. Планируйте спринт, перетаскивая пользовательские истории (user stories) из бэклога (backlog) на доску.
- Используйте диаграмму сгорания задач (burndown chart) для наглядного представления о прогрессе команды во время спринта.
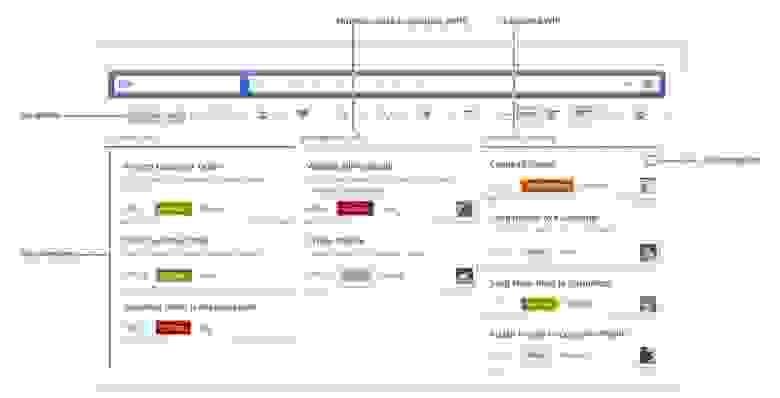
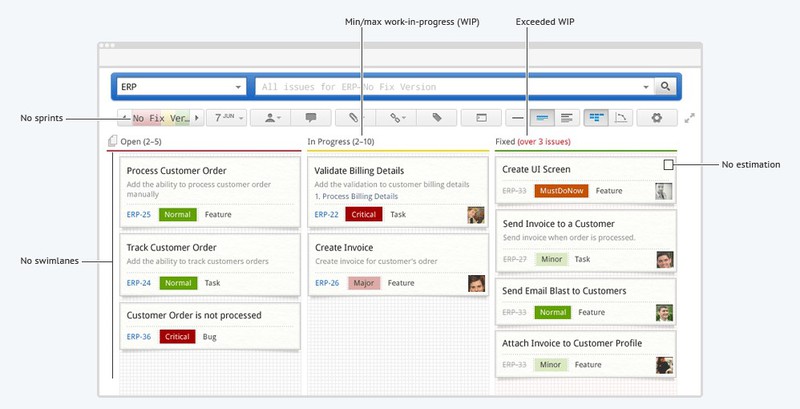
Kanban
- Создавайте разные колонки на Kanban-доске для представления различных стадий вашего процесса разработки. Передвигайте ваши задачи по доске по ходу работы над ними.
- Задайте минимальное и максимальное количество «выполняющейся в данный момент работы» (work-in-progress) для каждой колонки, чтобы контролировать количество задач на любой стадии разработки.
- Используйте Cumulative Flow график для выявления потенциальных узких мест (bottlenecks).
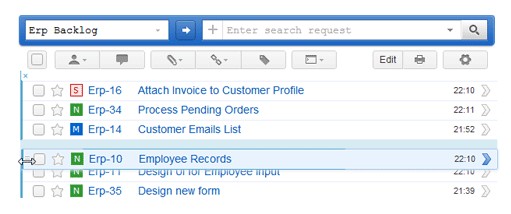
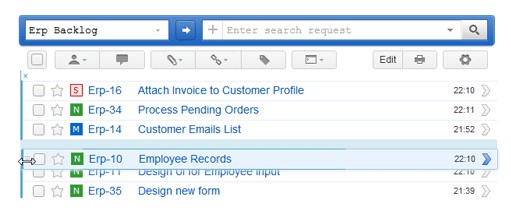
2) Управление бэклогом
Создайте бэклог для продукта (product backlog) или релиза (release backlog), чтобы удобно планировать и приоритезировать свои задачи в рамках всего проекта, релиза или итерации. Приоритезируйте пользовательские истории или задачи в бэклоге простым перетаскиванием. Используйте шорткаты для упорядочивания и изменения бэклога на лету.
3) Поддержка нескольких проектов на доске
Вы можете вести сразу несколько проектов на доске в рамках одной итерации. Всё, что для этого нужно, это общий набор значений версий для этих проектов.
4) Ваша персональная доска
Используйте расширенные поисковые запросы, чтобы отфильтровать задачи (карточки) на доске точно так же, как вы всегда делали это в YouTrack. Например, отфильтруйте никому не назначенные ишью (#unassigned) или те, которые были назначены вам (for:me).
YouTrack также остается верен поддержке расширенных клавиатурных шорткатов. Используйте шорткаты, чтобы передвигать задачи (карточки) по доске, добавлять, редактировать и удалять «плавательные дорожки» и задачи, и т.п.
Кроме этого, в YouTrack 4.0 добавлено следующее:
- Настраиваемые шаблоны уведомлений
Настроив почтовые и jabber-уведомления «под себя», вы можете контролировать, чтО именно следует сообщать вашим пользователям в уведомлении, когда создан новый ишью, когда он был обновлен, прокомментирован или переназначен. Добавьте собственный заголовок, поменяйте язык, переделайте текст сообщения, и многое другое с помощью шаблонов Freemarker.
- Произвольное упорядочивание задач, поддержка подзадач
Теперь вы можете создавать подзадачи для любой задачи (issue). Просто добавьте родительскую или подчиненную ссылку к нужной задаче, либо в режиме Tree-View определите ее место в общей иерархии задач/подзадач простым перетаскиванием на нужный уровень.

Просто перетаскивайте задачи в общем списке (Issues List), если хотите изменить их порядок, включая порядок результатов поиска или сохраненных запросов. Сохраните результаты поиска, чтобы поделиться ими с членами своей команды.
- Глобальный и персональный контекст
Работайте с YouTrack в своем персональном контексте. Выбирайте любой сохраненный поиск, тэг или проект в контекстном выпадающем списке и работайте в нем, пока не захотите переключиться в другой контекст. Если вам понадобится отфильтровать задачи сразу во всех проектах в YouTrack, просто выберите в качестве контекста Everything. Используйте боковую панель для закрепления и открепления проектов, тэгов и сохраненных поисков, чтобы сохранить компактный вид этого списка.
- Импорт из AgileZen
Импортируйте в YouTrack пользователей и проекты из AgileZen с пользовательскими историями и их задачами. По умолчанию, история импортируется как фича (feature), а ее задачи (tasks) – как подзадачи (subtasks) к ней.
- Уведомление пользователей через комментарии
Нет необходимости добавлять пользователя в список следящих за ишью, чтобы послать ему единственное уведомление. Теперь вы можете уведомить пользователя, просто упомянув его username в комментарии к ишью.
- «Тихие» команды
Иногда избыток уведомлений раздражает пользователей или членов команды. Теперь вы можете применять команды без отправки каких-либо уведомлений.
Конечно, это не полный список улучшений, которые мы внедрили, чтобы сделать вашу работу c YouTrack легче, быстрее и эффективнее. Все детали релиза вы можете найти на странице What’s new.
Попробовать YouTrack можно совершенно бесплатно. Загрузите бесплатный пакет на 10 пользователей либо зарегистрируйте YouTrack InCloud, размещенный в облаке JetBrains (предлагается бесплатный план на 9 пользователей).
Благодарим за внимание!
Разрабатывайте с удовольствием!
