Оценка звонков – ключевая часть контроля качества для колл-центров. Она позволяет организациям тонко подстраивать рабочий процесс, чтобы операторы могли выполнять работу быстрее и эффективнее, а также избегать бессмысленной рутины.
Памятуя о том, что колл-центр должен быть эффективным, мы работали над автоматизацией оценки звонков. В итоге мы придумали алгоритм, который обрабатывает звонки и распределяет их на две группы: подозрительные и нейтральные. Все подозрительные звонки сразу же отправлялись в команду оценки качества.

За образцы мы взяли 1700 аудиофайлов, на которых и тренировали сеть. Так как изначально нейронка не знала, что считать подозрительным, а что нейтральным, мы вручную пометили все файлы соответствующим образом.
В нейтральных образцах операторы:
В подозрительных образцах операторы часто делали следующее:
Когда алгоритм завершил обработку файлов, он пометил 200 файлов как невалидные. Эти файлы не содержали ни подозрительные, ни нейтральные признаки. Мы выяснили, что было в этих 200 файлах:
Когда мы удалили эти файлы, мы разделили оставшиеся 1500 на тренировочные и тестовые примеры. В дальнейшем мы использовали эти датасеты для обучения и тестирования глубокой нейронной сети.
Высокоуровневое извлечение признаков играет важную роль в machine learning, т.к. оно напрямую влияет на эффективность алгоритма. После анализа всех возможных источников, мы отобрали следующие признаки:
Кепстральные коэффициенты тональной частоты и вектор насыщенности чувствительны к длине входного сигнала. Мы могли бы извлекать их из целого файла за раз, однако делая так, мы бы упускали развитие признака во времени. Так как нам не подходил такой метод, мы решили делить сигнал на «окна» (временные блоки).
Чтобы улучшить качество признака, мы разбивали сигнал на чанки, которые частично накладывались друг на друга. Далее, мы извлекали признак последовательно для каждого чанка; поэтому матрица признака была вычислена для каждого аудиофайла.
Размер окна – 0,2 с; шаг окна – 0,1 с.
Наш первый подход к решению задачи – определять и обрабатывать каждую фразу в потоке по отдельности.
Первым делом мы сделали диаризацию и вычленили все фразы, используя библиотеку LIUM. Входные файлы были низкого качества, поэтому на выходе мы также применили сглаживание и адаптивное определение порога (adaptive thresholding) для каждого файла.
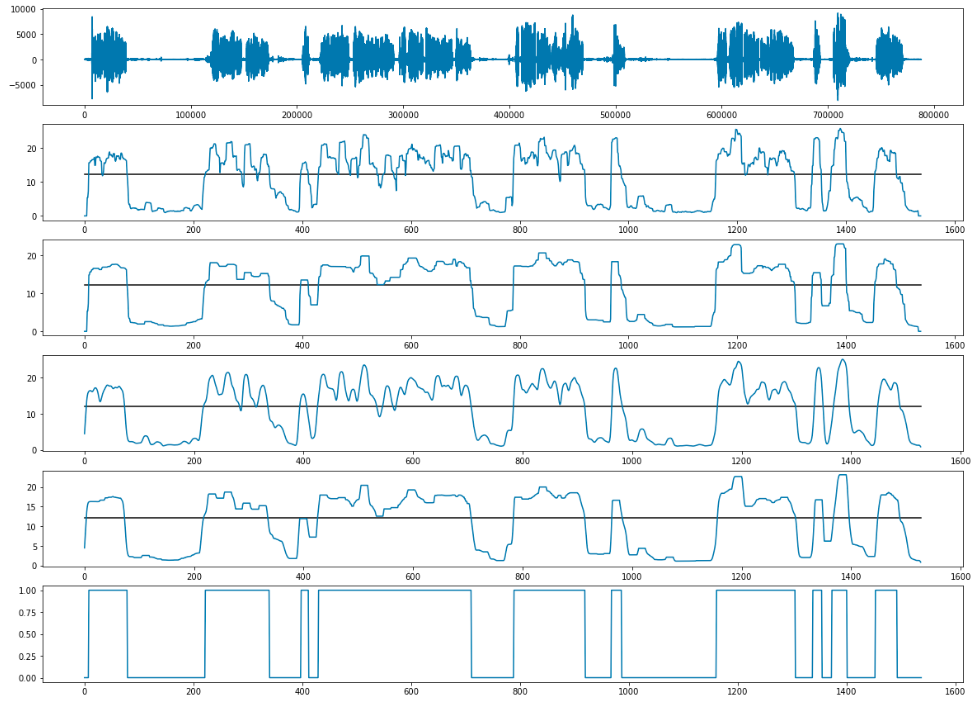

Когда мы определили временные лимиты для каждой фразы (как клиента, так и оператора), мы наложили их друг на друга и выявили случаи, когда оба человека говорят одновременно, а также случаи, когда оба молчат. Оставалось только определить величину порога. Мы условились, что если 3 и более секунд участники говорят одновременно, то это считается перебиванием. Для тишины был выставлен порог в 3 секунды ровно.
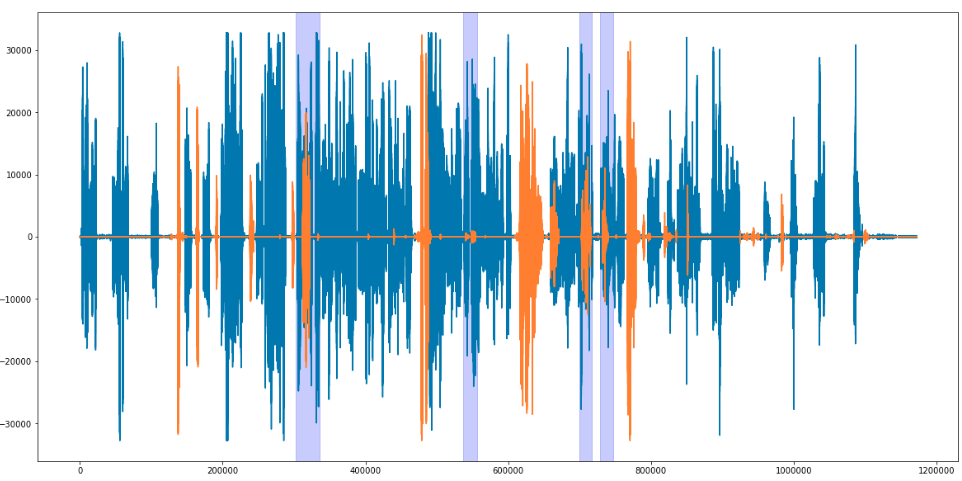

Соль в том, что у каждой фразы – своя длина. Следовательно, количество извлекаемых признаков у каждый фразы свое.
Нейронная сеть LSTM могла справиться с этой проблемой. Сети такого рода не только могут обрабатывать последовательности разной длины, но они также могут содержать фидбэк, что дает вам возможность сохранять информацию. Эти фичи очень важны, потому что фразы, произнесенные ранее, содержат информацию, которая влияет на фразы, сказанные после.
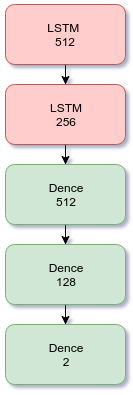
Затем мы натренировали нашу LSTM-сеть определять интонацию каждой фразы.
В качестве тренировочного сета мы взяли 70 файлов с 30 фразами в среднем (по 15 фраз для каждой стороны).
Главной целью была оценка фраз оператора колл-центра, поэтому мы не использовали клиентскую речь для тренировки. Мы использовали 750 фраз было задействовано как тренировочный датасет, а 250 фраз как тест. В итоге, нейронка научилась классифировать речь с точностью в 72%.
Но, в конце концов, мы не были удовлетворены производительностью LSTM-сети: работа с ней заняла слишком много времени, при этом результаты далеки от совершенства. Поэтому было решено использовать другой подход.
Настала пора рассказать, как мы определяли тон голоса, используя XGBoost плюс комбинацию LSTM и XGB.
Мы отмечали файлы как подозрительные, если в них была хоть одна фраза, нарушающая правила. Таким образом мы пометили 2500 файлов.
Чтобы извлекать признаки, мы использовали тот же метод и ту же ANN-архитектуру, но с одним отличием: мы масштабировали архитектуру, чтобы она подходила под новые размеры признаков.
С оптимальными параметрами, нейронная сеть выдавала точность в 85%.
Модель XGBoost требует фиксированного количества признаков для каждого файла. Чтобы удовлетворить это требование, мы создали несколько сигналов и параметров.


Были использована следующая статистика:
Все показатели высчитывались отдельно для каждого сигнала. Общее количество признаков – 36, за исключением длины записи. В итоге, у нас было по 37 числовых признаков для каждой записи.
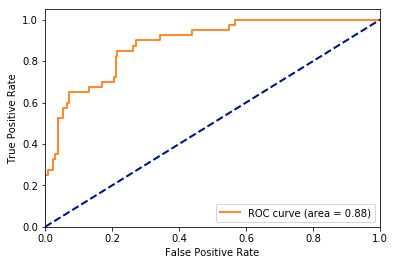
Точность предсказания у этого алгоритма равна 0,869.
Чтобы объединить классификаторы, мы скрестили эти две модели. На выходе это увеличило точность на 2%.
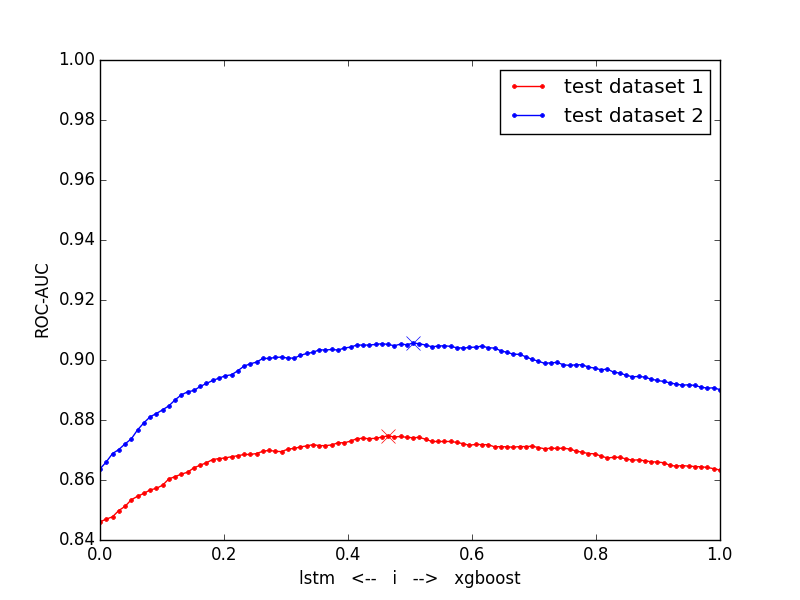
То есть нам удалось повысить точность предсказания до 0,9 ROC – AUC (Area Under Curve).
Мы протестировали нашу глубокую нейронную сеть на 205 файлах (177 нейтральные, 28 подозрительные). Сеть должна была обрабатывать каждый файл и решать, к какой группе он принадлежит. Ниже приведены результаты:
Чтобы оценить процентное соотношение правильных/ложных результатов, мы использовали Матрицу ошибок в виде таблицы 2х2.

Нам не терпелось попробовать этот подход для распознавания слов и фраз в аудиофайлах. Целью было найти файлы, в которых оператора колл-центра не представлялись клиентам в первые 10 секунд разговора.
Мы взяли 200 фраз со средней длиной 1,5 секунды, в которых операторы называют свое имя и название компании.
Поиск таких файлов вручную занимал много времени, т.к. приходилось слушать каждый файл, чтобы проверить, если ли в нем нужные фразы. Чтобы ускорить последующее обучение, мы «искусственно» увеличили датасет: каждый файл мы по 6 раз изменяли случайным образом – добавляли шумы, меняли частоту и/или громкость. Так мы получили датасет в 1500 файлов.
Мы использовали первые 10 секунд ответа оператора для тренировки классификатора, потому что именно в этом промежутке произносилась нужная фраза. Каждый такой отрывок делился на окна (длина окна – 1,5 с, шаг окна – 1 с) и обрабатывался нейронной сетью как входной файл. В качестве файла вывода мы получали вероятность произнесения каждой фразы в выбранном окне.
Мы прогнали через сеть еще 300 файлов, чтобы выяснить, произносилась ли нужная фраза в первые 10 секунд. Для этих файлов точность составила 87%.
Автоматическая оценка звонков помогает определять четкие KPI для операторов колл-центра, выделять best practices и следовать им, а также увеличивать производительность колл-центра. Но стоит отметить, что софт для распознавания речи можно применять и для более широкого круга задач.
Ниже несколько примеров, как распознавание речи может помогать организациям:
Памятуя о том, что колл-центр должен быть эффективным, мы работали над автоматизацией оценки звонков. В итоге мы придумали алгоритм, который обрабатывает звонки и распределяет их на две группы: подозрительные и нейтральные. Все подозрительные звонки сразу же отправлялись в команду оценки качества.

Как мы тренировали глубокую нейронную сеть
За образцы мы взяли 1700 аудиофайлов, на которых и тренировали сеть. Так как изначально нейронка не знала, что считать подозрительным, а что нейтральным, мы вручную пометили все файлы соответствующим образом.
В нейтральных образцах операторы:
- не повышали голос;
- выдавали клиентам всю запрошенную информацию;
- не реагировали на провокации со стороны клиента.
В подозрительных образцах операторы часто делали следующее:
- использовали нецензурную лексику;
- повышали голос или кричали на клиентов;
- переходили на личности;
- отказывались консультировать по вопросам.
Когда алгоритм завершил обработку файлов, он пометил 200 файлов как невалидные. Эти файлы не содержали ни подозрительные, ни нейтральные признаки. Мы выяснили, что было в этих 200 файлах:
- клиент бросал трубку сразу после того, как ему ответил оператор;
- клиент ничего не говорил после того, как ему ответили;
- было слишком много шума на стороне клиента либо оператора.
Когда мы удалили эти файлы, мы разделили оставшиеся 1500 на тренировочные и тестовые примеры. В дальнейшем мы использовали эти датасеты для обучения и тестирования глубокой нейронной сети.
Шаг 1: извлечение признаков
Высокоуровневое извлечение признаков играет важную роль в machine learning, т.к. оно напрямую влияет на эффективность алгоритма. После анализа всех возможных источников, мы отобрали следующие признаки:
Статистика по времени
- Скорость изменения знака (zero-crossing rate): скорость, с которой сигнал меняется с «плюса» на «минус» и наоборот.
- Медианная энергия фрейма: сумма сигналов, возведенная в квадрат и нормализованная соответствующей длиной фрейма.
- Энтропия энергии субфреймов: энтропия нормализованной энергии субфреймов. Ее можно интерпретировать как меру резких изменений.
- Среднее/медианное/стандартное отклонение фрейма.
Спектральная статистика (с частотными интервалами)
- Спектральный центроид.
- Спектральное распределение.
- Спектральная энтропия.
- Спектральное излучение.
- Спектральное затухание.
Кепстральные коэффициенты тональной частоты и вектор насыщенности чувствительны к длине входного сигнала. Мы могли бы извлекать их из целого файла за раз, однако делая так, мы бы упускали развитие признака во времени. Так как нам не подходил такой метод, мы решили делить сигнал на «окна» (временные блоки).
Чтобы улучшить качество признака, мы разбивали сигнал на чанки, которые частично накладывались друг на друга. Далее, мы извлекали признак последовательно для каждого чанка; поэтому матрица признака была вычислена для каждого аудиофайла.
Размер окна – 0,2 с; шаг окна – 0,1 с.
Шаг 2: определяем тон голоса в отдельных фразах
Наш первый подход к решению задачи – определять и обрабатывать каждую фразу в потоке по отдельности.
Первым делом мы сделали диаризацию и вычленили все фразы, используя библиотеку LIUM. Входные файлы были низкого качества, поэтому на выходе мы также применили сглаживание и адаптивное определение порога (adaptive thresholding) для каждого файла.
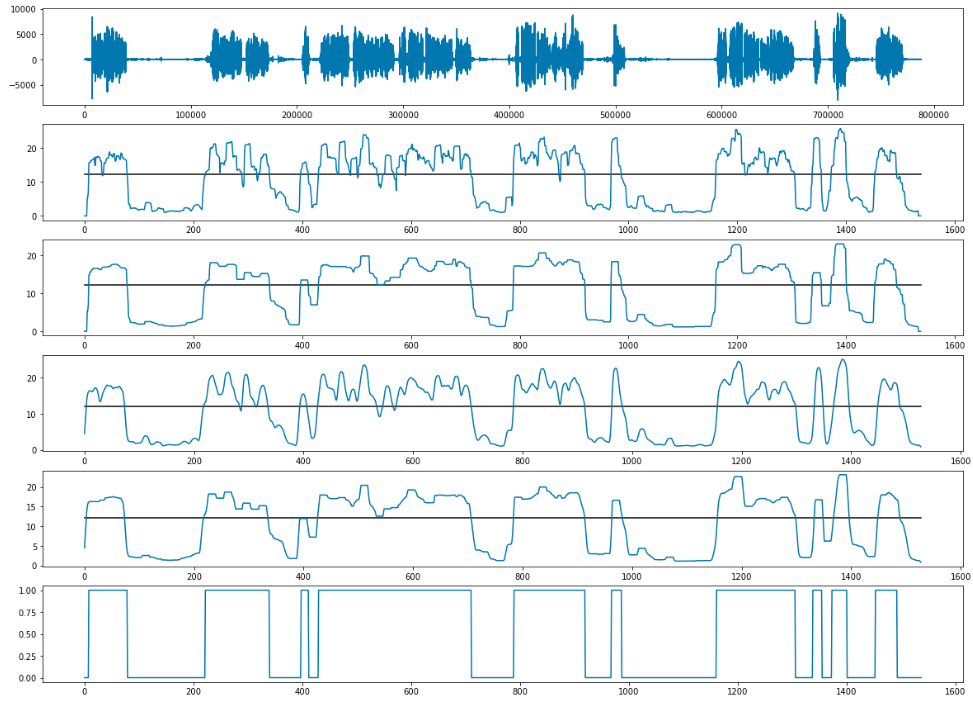
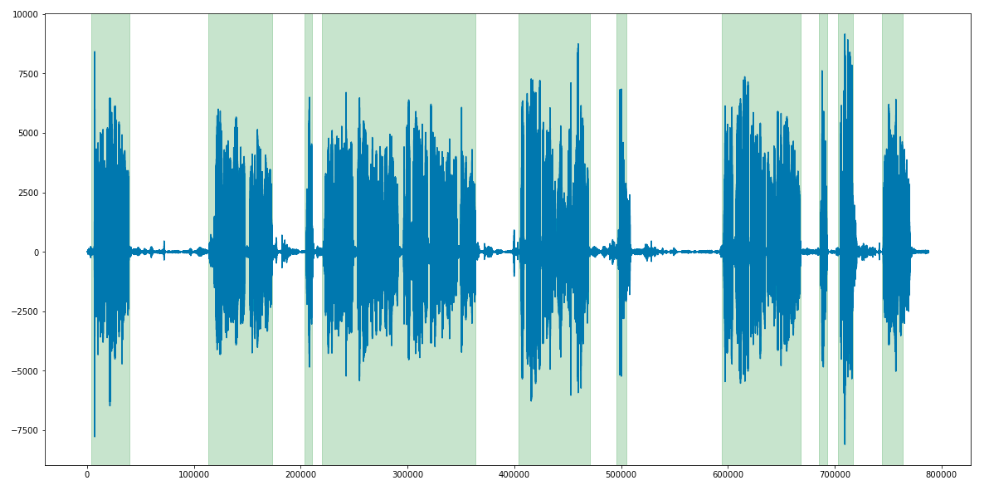
Обработка перебиваний и долгой тишины
Когда мы определили временные лимиты для каждой фразы (как клиента, так и оператора), мы наложили их друг на друга и выявили случаи, когда оба человека говорят одновременно, а также случаи, когда оба молчат. Оставалось только определить величину порога. Мы условились, что если 3 и более секунд участники говорят одновременно, то это считается перебиванием. Для тишины был выставлен порог в 3 секунды ровно.
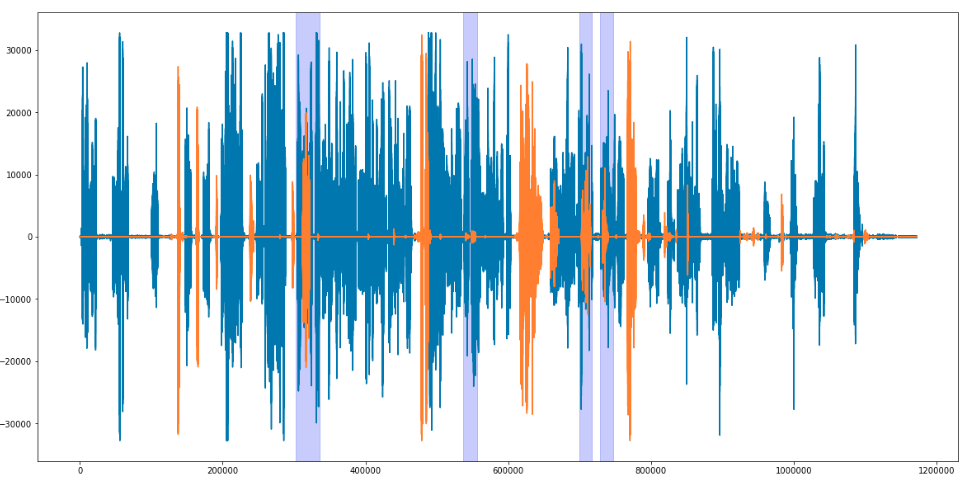

Соль в том, что у каждой фразы – своя длина. Следовательно, количество извлекаемых признаков у каждый фразы свое.
Нейронная сеть LSTM могла справиться с этой проблемой. Сети такого рода не только могут обрабатывать последовательности разной длины, но они также могут содержать фидбэк, что дает вам возможность сохранять информацию. Эти фичи очень важны, потому что фразы, произнесенные ранее, содержат информацию, которая влияет на фразы, сказанные после.

Затем мы натренировали нашу LSTM-сеть определять интонацию каждой фразы.
В качестве тренировочного сета мы взяли 70 файлов с 30 фразами в среднем (по 15 фраз для каждой стороны).
Главной целью была оценка фраз оператора колл-центра, поэтому мы не использовали клиентскую речь для тренировки. Мы использовали 750 фраз было задействовано как тренировочный датасет, а 250 фраз как тест. В итоге, нейронка научилась классифировать речь с точностью в 72%.
Но, в конце концов, мы не были удовлетворены производительностью LSTM-сети: работа с ней заняла слишком много времени, при этом результаты далеки от совершенства. Поэтому было решено использовать другой подход.
Настала пора рассказать, как мы определяли тон голоса, используя XGBoost плюс комбинацию LSTM и XGB.
Определяем тон голоса для файла целиком
Мы отмечали файлы как подозрительные, если в них была хоть одна фраза, нарушающая правила. Таким образом мы пометили 2500 файлов.
Чтобы извлекать признаки, мы использовали тот же метод и ту же ANN-архитектуру, но с одним отличием: мы масштабировали архитектуру, чтобы она подходила под новые размеры признаков.
С оптимальными параметрами, нейронная сеть выдавала точность в 85%.

XGBoost
Модель XGBoost требует фиксированного количества признаков для каждого файла. Чтобы удовлетворить это требование, мы создали несколько сигналов и параметров.
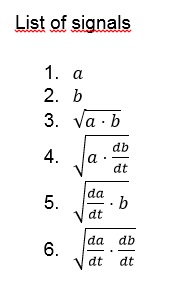

Были использована следующая статистика:
- Среднее значение сигнала.
- Среднее значение первых 10 секунд сигнала.
- Среднее значение последних 3 секунд сигнала.
- Среднее значение локальных максимумов в сигнале.
- Среднее значение локальных максимумов в первых 10 секундах сигнала.
- Среднее значение локальных максимумов в последних 3 секундах сигнала.
Все показатели высчитывались отдельно для каждого сигнала. Общее количество признаков – 36, за исключением длины записи. В итоге, у нас было по 37 числовых признаков для каждой записи.
Точность предсказания у этого алгоритма равна 0,869.
Комбинация LSTM и XGB
Чтобы объединить классификаторы, мы скрестили эти две модели. На выходе это увеличило точность на 2%.

То есть нам удалось повысить точность предсказания до 0,9 ROC – AUC (Area Under Curve).
Результат
Мы протестировали нашу глубокую нейронную сеть на 205 файлах (177 нейтральные, 28 подозрительные). Сеть должна была обрабатывать каждый файл и решать, к какой группе он принадлежит. Ниже приведены результаты:
- 170 нейтральных файлов были определены верно;
- 7 нейтральных файлов были определены как подозрительные;
- 13 подозрительных файлов были определены верно;
- 15 подозрительных файлов были определены как нейтральные.
Чтобы оценить процентное соотношение правильных/ложных результатов, мы использовали Матрицу ошибок в виде таблицы 2х2.

Находим конкретную фразу в разговоре
Нам не терпелось попробовать этот подход для распознавания слов и фраз в аудиофайлах. Целью было найти файлы, в которых оператора колл-центра не представлялись клиентам в первые 10 секунд разговора.
Мы взяли 200 фраз со средней длиной 1,5 секунды, в которых операторы называют свое имя и название компании.
Поиск таких файлов вручную занимал много времени, т.к. приходилось слушать каждый файл, чтобы проверить, если ли в нем нужные фразы. Чтобы ускорить последующее обучение, мы «искусственно» увеличили датасет: каждый файл мы по 6 раз изменяли случайным образом – добавляли шумы, меняли частоту и/или громкость. Так мы получили датасет в 1500 файлов.
Итог
Мы использовали первые 10 секунд ответа оператора для тренировки классификатора, потому что именно в этом промежутке произносилась нужная фраза. Каждый такой отрывок делился на окна (длина окна – 1,5 с, шаг окна – 1 с) и обрабатывался нейронной сетью как входной файл. В качестве файла вывода мы получали вероятность произнесения каждой фразы в выбранном окне.
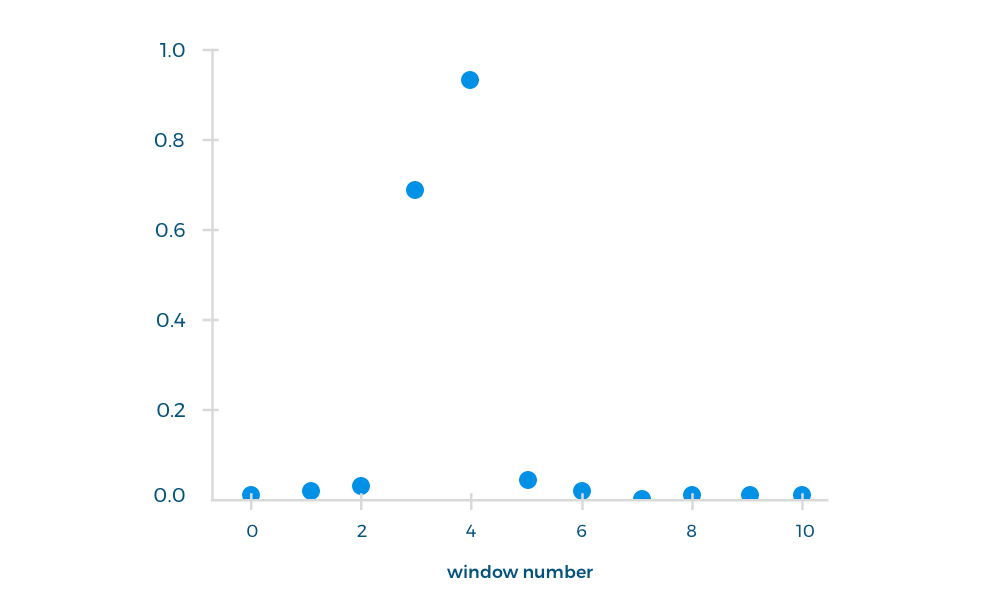
Мы прогнали через сеть еще 300 файлов, чтобы выяснить, произносилась ли нужная фраза в первые 10 секунд. Для этих файлов точность составила 87%.
Собственно, для чего все это нужно?
Автоматическая оценка звонков помогает определять четкие KPI для операторов колл-центра, выделять best practices и следовать им, а также увеличивать производительность колл-центра. Но стоит отметить, что софт для распознавания речи можно применять и для более широкого круга задач.
Ниже несколько примеров, как распознавание речи может помогать организациям:
- собирать и анализировать данные, чтобы улучшать голосовой UX;
- анализировать записи звонков, чтобы выявлять связи и тенденции;
- узнавать людей по голосу;
- находить и определять эмоции клиентов для улучшения пользовательской удовлетворенности;
- увеличивать среднюю выручку за звонок;
- снижать отток;
- и многое другое!
