Привет! Меня зовут Артемий Окулов, я lead центра компетенций CI/CD в X5 Group.
То, чем мы с командой занимаемся, можно отнести к области под названием Developer Experience. В какой-то момент ИТ в компании достигает такой зрелости, что появляются tools team, enabling team и инициативы, направленные на повышение developer experience. Одной из таких инициатив мы и занимаемся. Если вкратце, мы хотим упростить старт новых продуктов в компании за счет предоставления шаблонов.
В X5 Group много web-сервисов, и с переходом на продуктовый подход виден рост количества команд, которые все чаще прибегают к их созданию. Конечно, каждая команда должна быть кросс-функциональной, чтобы успех реализации продукта зависел в большей степени от самой команды. Но часто мы сталкиваемся с тем, что найти инженера с ролью devops в команду — это задача нескольких месяцев. А терять столько времени на старте — непозволительная роскошь. Поэтому в компании ведутся работы по созданию “стартовых наборов”, решающих задачу минимум — быстрого старта разработки и создания dev-окружения силами самих разработчиков.
В поставку такого “стартового набора” входит и CI/CD pipeline. В этой статье, в частности, мы бы хотели поделиться подходом шаблонизации GitLab Pipelines, который мы стараемся продвигать у себя в компании, и рассказать про инструмент, который для этого разработали.

Польза от шаблонизации
Зачем вообще что-то шаблонизировать?
Шаблонизация позволяет нам:
ускорить старт разработки — использовать преднастроенные компоненты на начальных этапах проще;
снизить порог входа на старте — создать из шаблона сервис в кластере kubernetes может разработчик без знания kubernetes;
собрать хорошие практики за счет вклада в общий шаблон всеми заинтересованными;
повысить качество — то, что используется многими и открыто к доработкам, быстрее будет улучшено за счет бОльшего потока обратной связи и предложений в виде merge requests;
создавать стандарты — мы накапливаем в шаблонах хорошие практики, из которых потом могут родиться стандарты, проверенные временем и опытом.
Все, что вы можете представить в виде кода, можно шаблонизировать и переиспользовать.
Мы выделили пять точек для шаблонизации:
кодовая база — задаст нам структуру проекта с хорошими практиками, включенными линтерами, с продуманными healthcheck, метриками “4 golden signals” и прочим сопутствующим кодом. Позволит вначале сконцентрироваться на реализации логики, а не на интеграции с инфраструктурой;
базовые образы докер — помогут писать свои образы, не задумываясь, например, о корпоративных сертификатах (они там будут уже включены) или о безопасности (они будут проверены);
kubernetes манифесты — дадут основную базу, позволяющую быстро развернуться в кластер kubernetes. А за счет возможности быстрого создания kubernetes-кластера во внутреннем облаке мы может получить dev-кластер с нашим приложением и довольно быстро начать работу над кодом;
шаблоны инфраструктуры – сюда относятся дополнения в kubernetes-кластере (контроллеры, мониторинги, сборщики логов и т.д.), а также все, до чего мы можем дотянутся с помощью ansible, terraform и других инструментов, позволяющих представить инфраструктуру в виде кода;
ну и, наконец, шаблонизация CI/CD pipeline как то, что проходит зеленой нитью через все вышеописанное.

Для реализации шаблонизации в каждой из этих точек необходимы свои подходы и свои инструменты. Но есть два принципа, которых мы хотим придерживаться независимо от того, что мы шаблонизируем:
все имеющиеся шаблоны в компании доступны для использования всем желающим;
каждый может внести правки в имеющийся шаблон или предложить новый (innersource).
Для реализации этих принципов мы планируем свести все шаблоны в единую Internal Developer Platform (IDP), где будет возможность как быстро создать из шаблона что-то, так и разместить свой шаблон. Здесь мы пока в начале пути и с радостью поделимся знаниями и опытом, когда такую платформу запустим.
А пока давайте рассмотрим, как можно разбить CI/CD pipeline на переиспользуемые единицы.
Зачем шаблонизировать CI/CD?
Для того чтобы делать более сложные конструкции в бОльшем объеме, можно идти по пути создания слоев абстракций.
Примером могут служить языки разработки. Раньше писали на assembler и зависели от типа процессора, сейчас мы пишем на python и почти не задумываемся об операционной системе.

Да, возможно мы теряем в контроле и скорости исполнения, но мы приобретаем в простоте и скорости реализации.
Но в области CI/CD почему-то предпочитают гнуть “pipelines” с нуля, вместо того чтобы собирать их из типовых элементов, соединяя их между собой.

CI/CD тоже нуждается в таких абстракциях. Сегодня я хочу рассказать про внутренний продукт Gitlab Actions, который позволяет превратить pipeline на базе GitLab в набор шаблонных и переиспользуемых шагов (да-да, название и идею мы нагло позаимствовали у GitHub).
Способы переиспользования кода в GitLab CI
У нас в компании достаточно большой ИТ-ландшафт и как минимум четыре платформы для размещения: платформа виртуализации, openshift, кластер kubernetes на bare-metal и приватное облако с возможностью поднять managed-kubernetes. И все чаще новые команды для реализации своих продуктов выбирают web-сервисы, упакованные в docker-образы и опубликованные в kubernetes.
Для хранения образов используется Jfrog Artifactory, а для реализации CI/CD pipeline — GitLab. Так как эти сервисы в компании у нас представлены как централизованные сервисы DevSecOps-платформы и предоставляются по моделям SaaS/PaaS, то нет ничего проще для новой команды, чем начать их использовать. Наличие таких централизованных инструментов приводит к тому, что в pipeline сервисов появляются одинаковые шаги, например, шаг с заливкой docker-образа в artifactory.
В целом, если команда работает над несколькими web-сервисами, их pipeline в большей степени будут похожи. И часто в рамках одной команды реализовано переиспользование pipeline. Но способ, которым это переиспользование достигается, не позволяет реализовать это на уровне выше — между несколькими командами или на уровне компании.
Давайте посмотрим, какие есть способы переиспользования pipeline.
Метод “copy-paste”
Дорогой читатель, думаю ты, как и любой ИТ-шник, освоил этот метод на экспертном уровне! Возможно, сейчас у тебя гримаса отвращения на лице, но вспомни те славные дни, когда ты открывал stackoverflow и копировал заветные кусочки кода, которые делали тебя в глазах твоих коллег круче (как ты думал)!
Алгоритм действий для воспроизведения этого метода ты знаешь достаточно хорошо.
Но давай взглянем правде в глаза: насколько бы ни был данный метод прост и банален, если у тебя десять однотипных web-микросервисов, то это рабочий вариант быстрого создания CI/CD pipeline.
Плюсы:
быстро;
минимум усилий.
Минусы:
нарушаем DRY (Don’t Repeat Yourself);
внесение изменений необходимо проводить во всех проектах, где нажал Ctrl+V.
Основная проблема в том, что этот метод не масштабируется. Если вдруг ты допустил ошибку в оригинальной pipeline, ошибку придется исправлять во всех проектах, что может быть накладно.
Метод общего проекта
Хорошо, мы можем решить проблему предыдущего метода, выделив отдельный проект в GitLab, в который помещаем весь код pipeline. Далее дело техники, в каждом проекте мы пользуемся конструкцией include и получаем тот же pipeline, но уже в своем проекте.
include:
- project: py-libs/infra/gitlab-ci
file: .gitlab-ci-base.yml
- project: py-libs/infra/gitlab-ci
file: .gitlab-ci-default.yml
Проблема здесь в том, что мы начинаем сильно зависеть от другого проекта. В такой конфигурации любое изменение в оригинальном проекте pipeline влияет на все, где он используется. Если там внесли ошибку — мы ее быстро получим и воспроизведем! Внес изменение в одном месте — сломал десять проектов сразу, страйк!
Это, конечно, решает проблему копипасты, но как минимум требует, чтобы человек, поддерживающий pipelines этих проектов, был в гармонии с собой и оставался очень внимательным! Безусловно, о масштабировании этого оригинального проекта на уровне компании и речи нет. Нанести пользу всему ИТ в компании не получится.
А что, если...
А что, если взглянуть на наш pipeline не как на монолитную структуру, а как на набор шагов, каждый из которых является объектом для переиспользования?

Теперь мы можем взять предыдущий способ, применить его не ко всему pipeline, а к отдельному job и немного доработать.
Мы берем и каждый job помещаем в отдельный GitLab проект. Каждый такой проект имеет свой жизненный цикл, релизность, версионирование и тестирование. Тем самым у нас формируется каталог таких проектов, которые уже можно переиспользовать на уровне компании.

Далее, наши пайплайны мы уже формируем из таких переиспользуемых единиц.

Именно такой подход мы решили применить у себя в масштабах компании. Такие переиспользуемые единицы мы назвали Actions.
Что такое action?
Идея не нова, мы позаимствовали ее у GitHub.
Каждый action можно воспринимать как черный ящик, скрывающий сложности выполнения какой-то одной задачи.
На входе такого черного ящика мы имеем переменные окружения, которые влияют на логику исполнения action. На выходе мы также получаем переменные окружения, которые можно передать в последующие actions, соединяя логику их исполнения в цепочку.

Переменные окружения на входе мы задаем с помощью блока variables в GitLab Job, а переменные окружения на выходе можем передавать в последующие job с помощью механизма dotenv artifacts.
Сам action представляет из себя шаблонный GitLab Job, который может вести себя как обычный job, исполняясь в pipeline, так и порождать цепочку исполнения других job (child pipeline). При этом цепочка job может быть как статически определена в виде шаблона, так и сгенерирована в зависимости от входных параметров (dynamic child pipeline).
Чего не хватает в GitLab, чтобы реализовать идею GitHub Actions?
С точки зрения технической реализации GitHub Workflow очень похож на GitLab Pipeline.

Помимо этого, в GitLab есть такие механизмы как include, extends, reference, позволяющие реализовать механику переиспользования job.
Разница в двух вещах — это платформа и сообщество.
Платформа — то, что дает нам возможность на базе чего-то уже готового быстро и просто строить что-то новое.
Сообщество — то, что порождает новые инструменты, хорошие практики по использованию этих инструментов и их поддержку.
На данный момент GitHub Actions быстро набирает популярность и сообщество уже породило более 11 тысяч actions, которые вы можете найти в marketplace.
Следовательно, чтобы переиспользовать идею GitHub Actions на базе GitLab, нам не хватает нескольких вещей:
runtime для action, который бы предоставлял готовую среду исполнения и общие для всех actions функции (например, валидация входящих параметров, взаимодействие с GitLab Api и прочее);
шаблон для быстрого создания нового action и публикации их в marketplace;
marketplace, в который можно будет опубликовать новый actions, чтобы любой желающий мог его найти, прочитать документацию и использовать в своем проекте.
Сначала нас посетила идея воспользоваться уже существующими GitHub Actions, написав транслятор из GitHub Actions в GitLab Actions. Но ввиду технической сложности реализации, а также большой хрупкости решения (из-за зависимости от GitHub Actions), эту идею мы оставили в пользу идеи реализации недостающих элементов самостоятельно.
Итак, давайте пройдемся по каждому из недостающих нам элементов.
GitLab Actions Runtime
По сути, каждый GitLab Action представлен в виде следующих компонентов:
шаблонный GitLab job;
скрипт с логикой исполнения — bash скрипт, шаблонизированный с помощью Jinja, или python code;
docker-образ, содержащий все необходимые бинарники и зависимости для исполнения скрипта или python-кода, а также код runtime-среды;
документация для пользователей;
тесты (unit-tests и тесты action в pipelines);
pipeline для запуска тестов и релиза action.
Шаблонный GitLab job
Вот так выглядит шаблонный job, который запускает линтинг dockerfile:
.hadolint:
image: docker-base-images-prod.x5.ru/actions/hadolint:v2.2.2
dependencies: []
variables:
X5_ACTION_LOGLEVEL: "INFO"
X5_ACTION_TYPE: "template" # "template" or "code"
X5_ACTION_TEMPLATE: "/app/command.jinja" # path to command template file
X5_HADOLINT_DOCKERFILE: "Dockerfile"
X5_HADOLINT_DOCKERFILE_REQUIRED: "true"
X5_HADOLINT_CONFIG_FILE: ""
X5_HADOLINT_TRUSTED_REGISTRIES: ""
X5_HADOLINT_TRUSTED_REGISTRIES_REGEX: '^(\\S+)(,\\s*\\S+)*$'
X5_HADOLINT_IGNORED_RULES: ""
X5_HADOLINT_IGNORED_RULES_REGEX: '^(..\\d{4,4})(,\\s*..\\d{4,4})*$'
script:
- source /app/run.sh
artifacts:
reports:
dotenv: .env
Здесь мы видим определение входных переменных в виде блока variables. Переменные можно поделить на два типа:
те, что начинаются с X5_ACTION, предназначены для конфигурирования самого runtime исполнения action;
те, что начинаются с X5_HADOLINT, специфичные именно для данного action входные параметры.
Вы можете заметить, что помимо самой переменной и ее значения по умолчанию, мы имеем ряд дополнительных переменных с постфиксами. С помощью таких вспомогательных переменных мы можем задавать простую валидацию прямо через шаблонный job. На данный момент у нас поддерживаются следующие постфиксы:
_REQUIRED — задает обязательность переменной;
_REGEX — проводит валидацию значения переменной по регулярному выражению;
_TYPE — задает тип переменной. Тип используется для проверки соответствия значения переменной и для приведения к типу python в runtime framework.
В блоке script вы можете видеть вызов shell-скрипта. Данный скрипт производит запуск runtime, который в зависимости от типа action исполняет те или иные действия по запуску исполнения самой логики action.
Мы специально оставили возможность пользователям определять блоки before_script и after_script, чтобы у них была возможность расширить функциональность исполнения action за счет подготовительных и финализирующих действий.
Для того чтобы исключить автоматический запуск job после его включения в конечный pipeline с помощью include, его имя в шаблоне начинается с точки (GitLab игнорирует job с такими именами). Включение же job происходит с помощью явного описания другого job, который наследуется от шаблонного через механизм extends.
myjob:
extends: .hadolint
variables:
X5_HADOLINT_DOCKERFILE: "./Dockerfile"
X5_HADOLINT_CONFIG_FILE: ".hadolint.yaml"
X5_HADOLINT_TRUSTED_REGISTRIES: "localhost:5000, hub.docker.com"
X5_HADOLINT_IGNORED_RULES: "DL3000,DL3006"
Скрипт исполнения
Обратите внимание на переменную X5_ACTION_TYPE. Эта переменная задает тип GitLab Action. Мы реализовали поддержку нескольких типов. Для нас было важно, чтобы создавать action могли как инженеры с опытом разработки, так и инженеры с опытом скриптования. Поэтому мы дали возможность создавать action как с использованием python так и с использованием bash, шаблонизированным через jinja template.
На данный момент переменная X5_ACTION_TYPE поддерживает два значения:
template — action данного типа реализованы как шаблонизированный с помощью Jinja template bash скрипт. Путь к jinja шаблону задается в переменной X5_ACTION_TEMPLATE и по умолчанию он располагается по пути /app/command.jinja внутри контейнера action. Для исполнения данного action сначала происходит render шаблона с помощью движка jinja, затем выполнение полученного скрипта в блоке script gitlab job. Контекст исполнения передается в jinja engine, что позволяет из шаблона читать переменные окружения. На самом деле, мы немного расширили функциональность jinja-движка, но об этом как-нибудь в другой раз.
Пример jinja шаблона, для запуска hadolint:
{% if action.X5_HADOLINT_TRUSTED_REGISTRIES %} {%- set trusted_registries = action.X5_HADOLINT_TRUSTED_REGISTRIES.split(',') -%} {% endif %} {% if action.X5_HADOLINT_IGNORED_RULES %} {%- set ignored_rules = action.X5_HADOLINT_IGNORED_RULES.split(',') -%} {% endif %} hadolint \ {% if action.X5_HADOLINT_CONFIG_FILE %}--config "{{ action.X5_HADOLINT_CONFIG_FILE }}" {% endif -%} {% for registry in trusted_registries %}{% if registry|trim %}--trusted-registry "{{registry|trim}}" {% endif %}{% endfor -%} {% for rule in ignored_rules %}{% if rule|trim %}--ignore "{{rule|trim}}" {% endif %}{% endfor -%} "{{ action.X5_HADOLINT_DOCKERFILE }}"code — action данного типа подразумевает исполнение кода, написанного на python в специальном runtime. По факту, код такого action — это реализация функции, которая на вход принимает контекст: объект определенного типа со всей необходимой информацией об окружении, где код запущен. В этом же контексте есть ряд объектов-менеджеров, позволяющих управлять процессом исполнения (прерывать его, взаимодействовать с GitLab Api, читать и писать переменные, выводить логи и отладочную информацию и так далее).
Пример такой функции:
from action.context import GitlabActionContext def run_action(context: GitlabActionContext): try: # EXAMPLE CODE # you can read input variables msg = context.variables.get_value("X5_TEST_MESSAGE", default=None) if not msg: # you can fail action with message and exit_code context.lifecycle.fail_action("Stop action, because X5_TEST_MESSAGE variable is undefined", exit_code=111) # you can print messages with different levels context.message.info(f"Get variable X5_TEST_MESSAGE with value {msg}") context.message.debug(f"Just debug example") # triggers sentry false error: # context.message.error(f"Just error example") if context.is_debug: # you can execute shell command context.exec.execute_command("echo $X5_TEST_MESSAGE") # you can set output variables context.output.set_variable("OUTPUT_VARIABLE", msg) except Exception as err: context.message.debug(str(err)) context.lifecycle.fail_action()
В итоге мы дали возможность быстрого создания простых actions, не требующих написания кода, путем шаблонизации через jinja, но в тоже время сохранили возможность реализации сложной логики исполнения, используя всю силу языка python.
Образ
Также в шаблонном job обязательно определяется image, который будет использован при запуске GitLab Runner типа docker executor.
Данный образ должен содержать в себе все необходимое для исполнения скрипта job. В нашем примере с hadolint образ должен содержать бинарный файл самого hadolint.
FROM docker-base-images-prod.x5.ru/actions/action-base:v3.2
ARG X5_ACTION_NAME="hadolint"
ENV X5_ACTION_NAME={X5_ACTION_VERSION}
ARG X5_ACTION_MAINTAINER="artemy.okulov@x5.ru"
ENV X5_ACTION_MAINTAINER={X5_ACTION_REPO}
COPY --from=hadolint/hadolint /bin/hadolint /bin/
Все image должны наследоваться от базового образа, который мы назвали совсем не оригинально — action-base.
Action-base содержит в себе все необходимо для запуска action runtime и сам этот runtime. Так как runtime у нас представлен в виде python кода, то все, что нам необходимо в таком образе, это:
python interpreter;
jinja template engine;
сертификаты корпоративного УЦ, установленные в доверенные системные корневые сертификаты.
Весь бутерброд будет выглядеть следующим образом:

Документация для пользователя
Каждый action должен иметь как минимум одну страницу документации, в которой описано, какую задачу решает данный action, какие параметры конфигурирования он принимает на входе и какие переменные отдает на выходе.
Документация пишется в формате markdown, который затем конвертируется в html с помощью mkdocs и собирается в единый каталог, расположенный в нашем internal developer portal на базе Backstage от Spotify.

Чтобы коллеги, создающие action, не забывали писать документацию, мы в шаблон для создания нового action кладем преднастроенные файлы с начальной структурой документации. О том, как мы создаем actions из шаблона, читайте далее в статье.
Pipeline для релиза action
Каждый action, созданный из шаблона, включает в себя преднастроенный pipeline, который выполняет:
линтинг jinja template и python-кода;
запуск тестов;
сборку и публикацию docker image;
автоматическое версионирование (semver autobump);
генерацию changelog и публикацию его в telegram-канал;
выпуск релиза.
Для автоматического версионирования и генерации changelog мы используем уже имеющиеся actions, то есть, pipeline каждого action использует другие actions.
Для всех actions мы используем семантическое версионирование, и для каждого релиза выпускаем следующий набор тегов:
v1.2.3 — новый уникальный тег;
v1.2 — минорный тег, который передвигается на последнюю сборку;
v1 — мажорный тег, который также передвигается на последнюю сборку;
latest — тег, всегда указывающий на последний стабильный релиз, не зависимо от его версии.
Таким образом, мы даем пользователю выбор — снижать риски за счет полной фиксации и ручного обновления версии используемого action, либо же риcковать, завязываясь на тегах v1.2 или v1, но получать последние обновления автоматически. Тег latest мы используем только в сценариях тестирования и не рекомендуем для пользователей, так как он может приводить к несовместимым изменениям.
include:
- project: boilerplates/actions/get-vault-secrets
ref: v1 # последняя стабильная мажорная версия, автоматически получаем фиксы и новые обратно-совместимые фичи
file: '/template.yaml'
- project: boilerplates/actions/hadolint
ref: v0.1 # последняя стабльиная минорная версия, автоматически получаем только фиксы
file: '/template.yaml'
- project: boilerplates/actions/anchore
ref: v0.1.12 # полная фиксация версии, изменения не прилетают совсем
file: '/template.yaml'
- project: boilerplates/actions/release
ref: v1.2b # использование beta версии, возможно прилетят ломающие изменения
file: '/template.yaml'
- project: boilerplates/actions/artifactory-cleanup
ref: latest # прилетают все изменения после каждого релиза
file: '/template.yaml'
Обычно оптимальный вариантом является фиксация на мажорной версии: таким образом мы будем получать последние исправления и доработки, не ломающие обратную совместимость.
Шаблон для создания нового action
Для того чтобы создание нового action было простой процедурой, исключающей рутинные действия, мы с командой подготовили шаблон.
За основу взяли cookiecutter. В итоге получили шаблон, который на входе принимает следующие данные:
имя action;
краткое описание;
maintainer info.
На выходе имеем:
преднастроенный проект в GitLab, созданный в специальной группе;
кодовую базу будущего action;
преднастроенный pipeline.
Все, что остается сделать творцу нового action, это наполнить его логику в заранее отведенных для этого файлах.
Весь процесс создания мы реализовали на базе internal developer portal - backstage.
Вот как это выглядит:
Будущий maintainer заходит на страницу каталога имеющихся шаблонов в компании и выбирает необходимый — Gitlab Action template.

Далее ему предлагается пройтись по простому wizard и заполнить необходимые данные.

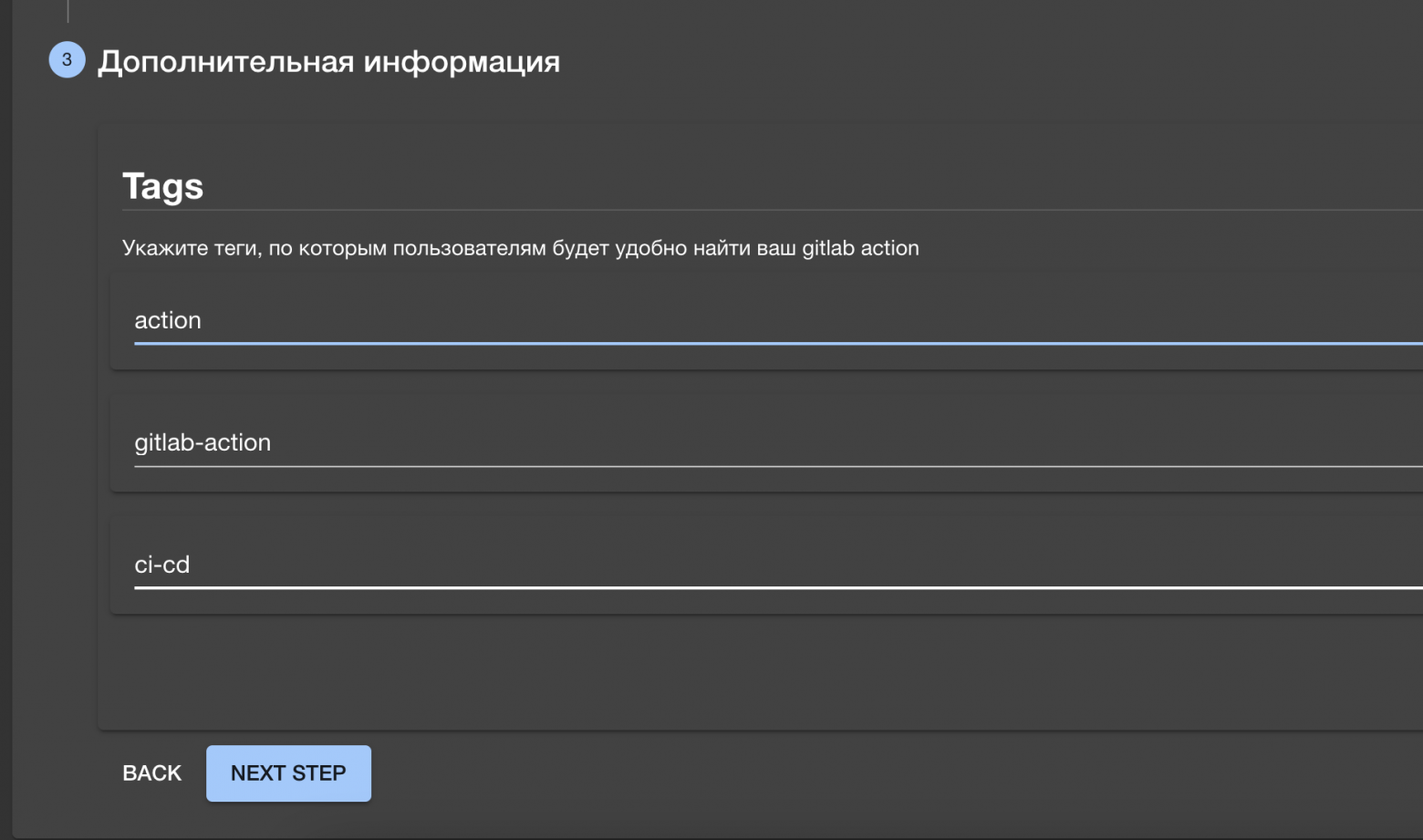
Он также задает теги, по которым потом его action будет проще найти.
Затем запускается процесс, который создает проект в GitLab, преднастраивает его, генерирует из сookiecutter-шаблона кодовую базу и заливает ее в созданный GitLab project.
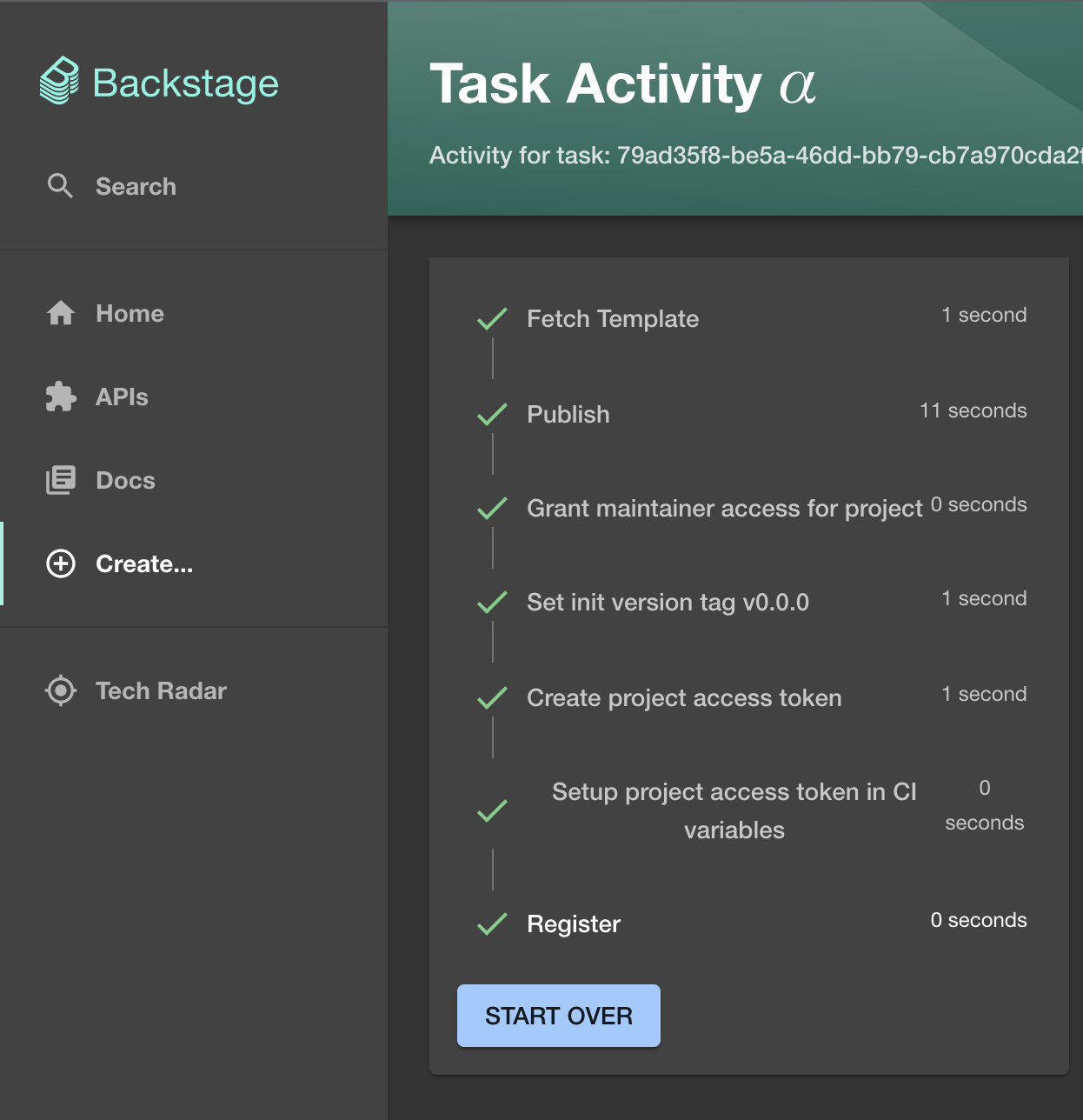
По завершении мы имеем GitLab проект, в котором инициатор числится как maintainer, и зарегистрированный в общем каталоге actions новый компонент (об этом читайте в разделе marketplace).



Теперь любой желающий может найти этот action (правда, на данный момент он числится как experimetal, что не рекомендует его к использованию), а создатель нового action идет и клонирует себе проект с целью наполнения его логикой.
Marketplace
Как я уже упомянул выше, после создания action автоматически регистрируется в нашем каталоге actions внутри компании.
На данный момент для создания такого каталога мы используем backstage. Backstage позволяет нам реализовать каталог, с функциями поиска по ключевым словам и тегам, а также фильтровать actions по их lifecycle (experimetal, deprecated, production).

Сама карточка action в этом каталоге включает всю необходимую информацию:
описание actions и его теги;
ссылка на проект;
документация;
информация о contributer’ах;
changelog.
Также мы включили в эту карточку небольшой snippet, позволяющий быстро подключить этот action к себе в pipeline путем копирования структуры include и job (да-да, как бы мы ни старались, все свелось к применению copy-paste для использования, но, надеюсь, в скором времени придумаем более элегантное решение).

Конечно, это далеко не marketplace. Но backstage — модульная система, и позволяет расширять ее за счет добавления новых компонентов на react. Мы планируем дополнить карточку и каталог actions-информацией о статистике использования, возможностью ставить like и предлагать идеи (обсуждение вокруг активности по развитию action).
На самом деле, у GitLab сейчас есть активность по созданию UI для отображения actions (у них они называются extensions). Мы общались с коллегами из GitLab и показывали идею, описанную в данной статье, на что получили очень хороший положительный отзыв (и это чертовски приятно, получить его от них) и информацию о том, что они планируют поддерживать подобные процессы создания шаблонных pipeline. Так что, возможно, в ближайшем будущем мы сможем переехать на их UI, встроенный в сам GitLab.
Ну а пока мы продолжаем развивать идею использования backstage для этих целей и для создания internal developer portal. На данный момент мы уже используем backstage для создания сервиса из frontend boilerplate и планируем перевести еще пару шаблонов-сервисов для python и java-стека.
Что нам это дает?
Во-первых, такую единицу можно переиспользовать в масштабах компании, так как каждый action делает одно действие,и вероятность того, что это действие потребуется в других проектах, велика. Например, проверка кода с помощью sonarqube может быть полезна практически в каждом проекте.
Хорошим примером использования action для распространения практик на уровне компании может служить инициатива “shift-left” от наших security-инженеров. У ребят есть экспертиза в выборе инструментов и их настройки. Далее они оборачивают сценарий запуска инструмента в action и предоставляют его для использования. Для них GitLab Action выступает точкой распространения практик, а для нас как пользователей — это возможность включить в pipeline security-составляющую без дополнительных затрат на изучение инструмента. На данный момент таким образом мы распространяем практики статического сканирования кода и репозиториев, сканирование docker images на наличие CVE.
Во-вторых, за счет того что у каждого action есть свой жизненный цикл, включающий тестирование и версионирование, мы снижаем риск того, что “сломаем” все проекты сразу. У каждого action есть maintainer, который проведет code review, если прилетел Merge Request от коллег. И, кстати, это хорошая точка развития innersource в компании. Каждый action — это отдельный, пусть и маленький, но продукт внутри компании, поэтому важно соблюдать все требования к его качеству. Воспринимая это как продукт коллективного творчества, мы можем дорабатывать его по модели “нужно самому — доработал — сделал добро всем”. Например, можно сделать основную функциональность и запустить action как MVP, после чего придут коллеги, применившие его в своем pipeline и доработают его логи, чтобы было красиво и информативно.

В-третьих, это отличная возможность для инкапсуляции сложной логики в простой сценарий использования. Мы создаем новый слой абстракции — action, под капотом которого может быть иcполнение bash-скрипта или сложного python-кода. Мы можем в шаблонный job с простым интерфейсом подключения уместить сложную логику исполнения, и обращение к сторонним сервисам.
Например, у нас есть action, который ходит в hashicorp vault и получает оттуда секреты, формируя из них environment variables для GitLab job. C точки зрения использования — это всего лишь один include и job c extends, в котором мы описываем, из какого vault и какие секреты хотим получить.
myjob:
extends: .get-vault-secrets
variables:
X5_VAULT_URL: "<https://vault-addr>"
X5_VAULT_ROLE_NAME: "some-role"
X5_VAULT_AUTH_PATH: "jwt-gitlab"
X5_VAULT_IGNORE_READ_ERRORS: "False"
# далее перечислены переменные, значения которых необходимо получить из vault
PASSWORD_1: vault-secret:kv1:mount_point/path/path/password#key
PASSWORD_2: vault-secret:mount_point/path/path/password#ke—
В-четвертых, это дает нам возможность легкой интеграции с платформенными сервисами. У нас в компании есть ряд централизованных сервисов, которые мы называем DevSecOps платформой. В них входят и сервисы полезные для использования в CI/CD pipelines, такие как sonarqube, hashicorp vault, artifactory, defectdojo. По аналогии, как разработчики сервисов поставляют client-sdk, команда, поставляющая централизованные сервисы, может поставлять GitLab Actions для интеграции с их сервисами. На данный момент у нас есть actions под все перечисленные сервисы, позволяющие отправлять и получать данные в api этих систем.
В-пятых, actions позволяет собирать статистику по запускам в pipelines. На сегодняшний день в runtime action’а реализована отправка события запуска и завершения action в sentry. Таким образом, мы видим, в каких проектах какие actions с какими параметрами запускались и результат их исполнения. Что нам это дает? Помимо сбора статистики по популярности тех или иных actions я могу привести два сценария использования этих данных.
Сценарий первый: security команда смотрит процент внедрения security actions в команды. Таким образом они могут реализовать метрику успешности внедрения подхода “shift-left”. Помимо этого они могут наблюдать, в каких командах систематически игнорируются результаты сканирования, требующие внимания.
Сценарий второй: у нас есть команда, занимающаяся сбором цифрового следа. На данный момент они не могут на уровне автоматизации сделать, казалось бы, простую вещь — отличить job, который производит deploy в production-среду, от других job. Дело в том, что у нас нет стандарта именования job, помимо этого инструменты деплоя могут быть разными, и не все пользуются блоком environment в job, что затрудняет его идентификацию как deploy-job. Если бы все pipeline строились исключительно из actions, мы могли бы не только отличить deploy job от остальных, но и реализовать автоматическую оценку зрелости CI/CD команды.
Примеры GitLab Actions которые мы используем
На данный момент я бы сказал, что мы находимся в начале пути по наполнению корпоративного каталога actions, у нас их 26 штук, и большинство сделано нашей же командой. Для того чтобы ускорить процесс наполнения каталога, необходима вовлеченность коллег, которой очень не хватает. Здесь требуется работа по культурному сдвигу, чтобы инженеры хотели делиться своими наработками, использующимися в их pipelines, превращая их в actions. Мне кажется, сейчас это самая сложная задача для нас.
Здесь я кратко приведу примеры самых интересных actions, которые используются у нас в компании:
changelog-generator — на основе коммитов соответствующих conventional commits генерирует changelog.md файл и кладет его в корень репозитория. Также на основе changelog делает autobump версии по схеме семантического версионирования;
changes2telegram — берет последние изменения из changelog и публикует в канал в телеграмме. Мы сами используем его в pipelines каждого actions, таким образом мы реализуем новостную ленту изменений по нашим actions;
artifactory-cleanup-action — позволяет производить очистку репозитория в artifactory. Удобно использовать для удаления временных артефактов после выполнения pipeline, а также по расписанию для реализации ротации, что не позволяет репозиторию artifaсtory “разбухнуть”;
release — даёт возможность создавать gitlab release из commit, на котором запущен.
Остальные:
Actions для сборки container images — kaniko, docker-buildx;
Actions для манипуляции container images — image-size-check, delete-docker-image, docker-tagger;
Actions для доставки — helmfile, kubectl-apply;
Actions для реализации security проверок — bandit, trufflelhog, defectdojo-integration, sonarqube, anchore, sast-scan;
Actions для линтинга — hadolint, kubeval, jinja-linter.
Нам есть, что еще рассказать
Конечно, в рамках одной статьи рассказать все у нас не получилось, постараемся детали реализации и моменты которые не удалось уместить в эту статью рассказать в отдельной статье.
А напоследок, немного планов по развитию.
В ближайших планах у нас создание рекомендованной релизной модели, оформления ее в виде переиспользуемого шаблона, который можно подключить к любому проекту. И, конечно же, мы хотим, чтобы эта модель строилась на базе actions.
Мы планируем поставлять не только actions, как минимальный переиспользуемый компонент pipeline, но и логические цепочки из actions, которые будут решать общую задачу. Для этого мы идем по пути создания нового типа action — Composite Action, который будет оберткой над цепочкой actions.
Мы также подумали, что помимо template и code actions, мы бы хотели поддерживать еще один тип — ansible actions, позволяющий писать логику исполнения, описывая ее с помощью ansible playbook. Это дало бы бОльшие возможностьи по сравнению с jinja template, но при этом все еще не требовало бы погружения в python-код. Ansible знаком многим инженерам у нас в компании.
У actions есть своя специфика, это разовая задача, которая принимает на вход всю необходимую информацию и на ее основе делает какую-то разовую работу. Но в наших планах есть и развитие экосистемы ботов вокруг GitLab. Бот — это то, что будет иметь постоянный запущенный процесс и постоянное хранилище. Поэтому мы посматриваем в сторону реализации аналога GitHub App.
А в перспективе мы бы хотели видеть в компании Pipeline as a Service. Ведь сейчас мы поставляем только шаблоны, которые исполняются на GitLab Runner’ах конечных потребителей. Но есть все технические возможности предоставлять исполнение actions на наших runner’ах и отдавать только результат. Пока это только идея, по которой мы не делали никаких шагов, но кто знает, может быть у нас появится своя платформенная команда.
У нас есть желание открыть исходный код Gitlab Actions для использования его всеми желающими, так как инструмент завязан только на GitLab, и каждый, кто использует GitLab, может его к себе разместить и использовать. Будем вести работы в эту сторону.
