
Привет, Хабр! Меня зовут Стас, и я отвечаю за направление Common Libraries в компании ABBYY. Недавно мы выложили на GitHub созданную нами библиотеку для машинного обучения NeoML.
NeoML — это кроссплатформенная C++ библиотека, позволяющая организовать полный цикл разработки ML-моделей. Основной фокус в ней сделан на простом и эффективном запуске готовых моделей на различных платформах. Даже если эти модели созданы другими фреймворками.
Вы спросите: зачем нужна еще одна библиотека машинного обучения?
Ниже я отвечу на этот вопрос, расскажу, как мы создавали нашу библиотеку, с какими сложностями столкнулись и что в итоге получилось. И в конце приведу результаты сравнительных замеров производительности.
С чего все началось
ML так или иначе давно использовалось в различных проектах компании. Со временем стало ясно, что работу с ML нужно унифицировать. Мы начали думать, как это сделать. Практически весь технологический код в компании написан на C++ — значит, нам нужно С/С++ решение. Единого С++ фреймворка, удовлетворяющего всем нуждам, не было. Были отдельные библиотеки, реализующие различный функционал. Например, Liblinear, XGBoost, Scikit-learn, Libsvm, Caffe, TensorFlow и т. д. Мы начали анализировать их возможности.
Большинство библиотек подходило для исследовательских целей, но не для продакшена. Их код требовал существенного пересмотра: логирования, обработки ошибок, управления памятью. Кроме того, много лишней функциональности, разные системы сборки, дополнительные зависимости. Не у всех был С++ интерфейс. Библиотеки развивались и быстро менялись, причем не всегда предсказуемо; их производительность и стабильность вызывала вопросы, поддержку тоже никто не обещал. В общем, на тот момент эти проекты были сыроваты, и использовать их в коммерческой разработке было бы по меньшей мере смело. Нам ничего не оставалось, кроме как начать собственную разработку. И так мы решили создать свою библиотеку, собрав в нее все, что нужно именно нам, и сами определять её дальнейший путь.
Классические алгоритмы
Все началось с классических алгоритмов. Хорошим подспорьем были уже существовавшие на тот момент open-source библиотеки Liblinear, Libsvm, Scikit-learn и XGBoost. Проанализировав их опыт, мы реализовали аналогичные идеи без ненужного нам функционала и добавили несколько оптимизаций. Например, мы работаем только с выборками, помещающимися в память, только на CPU и без низкоуровневых оптимизаций. Скорость работы классических алгоритмов не является узким местом в наших задачах, поэтому серьезных усилий по их оптимизации мы не прикладывали, однако скорость работы перечисленных выше аналогов удалось превзойти.
Унификация дала хорошие результаты: обучение стало быстрее, а качество выше. Увеличилась и скорость разработки. Каждому программисту больше не нужно изобретать велосипед — можно просто использовать дефолтные настройки и сразу получить результат, на который раньше пришлось бы потратить как минимум пару дней экспериментов.
Так в библиотеке появились методы решения задач классификации, регрессии и кластеризации.

Реализация классических алгоритмов была, на мой взгляд, не очень сложной задачей, интереснее обстояло дело с нейронными сетями.
Нейронные сети
Классические алгоритмы по сути представляют собой набор независимых методов, использующих общие примитивы. А вот реализация нейронных сетей гораздо более сложная задача. В ней помимо математических и алгоритмических задач, возникают еще и неочевидные архитектурные и низкоуровневые оптимизационные задачи.
Посмотрев существовавшие на тот момент C++ библиотеки Caffe и TensorFlow, мы решили, что нам ближе идеи Caffe. Именно поэтому у нас данные представляются blob’ами, а не tensor’ами. Нам хотелось оперировать более высокоуровневыми понятиями, модифицировать сеть во время обучения, уметь доучивать ее в процессе использования и организовывать вычисления на GPU прозрачно для пользователя.
В NeoML сеть представляет собой направленный граф, вершины которого обозначают слои, а рёбра обозначают передачи данных от выходов одних слоёв на входы других. Слой же — это элемент, выполняющий некоторую операцию. Операцией может быть что угодно от изменения формы входных данных или вычисления простой математической функции до свёртки или LSTM. Слои можно добавлять и удалять из сети в любой момент. Все данные в сети — входы, выходы и данные, передаваемые между слоями — представлены в виде блобов. Блоб — это непрерывный участок памяти. Библиотека работает с памятью блобов не напрямую, а через специальный платформо-независимый интерфейс. Таким образом достигается независимость алгоритмической части от устройства, на котором непосредственно производятся вычисления. Например, реализовав этот интерфейс с помощью CUDA, можно вычислять на GPU. Эти реализации мы называем «вычислительными движками».
Если говорить об архитектуре сетей, мы начали со сверточных сетей, добавили различные сверточные слои, пулинги, полносвязные слои, активации и функции потерь. В качестве оптимизатора был использован простой градиентный спуск.
Чуть позже поддержали рекуррентные сети LSTM и GRU, продвинутые оптимизаторы, еще больше активаций и функций потерь, CTC, CRF и т. д.
На текущий момент в библиотеке около 100 различных типов слоев, что позволяет реализовать практически все современные архитектуры сетей.
Мы стараемся расширять функционал по мере того, как новая архитектура доказывает свою эффективность на наших задачах.
Дальше началась борьба за эффективность.
Вычисления на CPU
Нейронная сеть — это чаще всего огромный объем вычислений, и без низкоуровневых оптимизаций здесь никуда. В первую очередь, мы занялись оптимизацией под x86-процессоры для ОС Windows — это наша основная платформа, и на ней нам хотелось быть максимально успешными.
Большинство операций в нейронных сетях так или иначе сводятся к BLAS (Basic Linear Algebra Subprograms), а лучший BLAS для x86 — это, конечно, Intel MKL. Его мы и начали использовать. Остальные операции пришлось реализовывать самостоятельно с помощью SIMD. Мы использовали только SSE инструкции, были эксперименты и с AVX/AVX2, но на наших операциях большого выигрыша они не давали, и мы решили отказаться от них, чтобы сократить стоимость поддержки. Когда Intel выпустил MKL-DNN, мы обрадовались: наконец-то можно все это не писать самим! Но, к сожалению, сравнения показали, что наши свертки работают примерно на 20% быстрее, и от этой идеи пока пришлось отказаться.
На текущий момент NeoML достаточно прилично работает на x86, но ещё есть большой простор для оптимизации, чем и планируем заняться в будущих релизах.
Вычисления на GPU
Для нас вычисления на GPU — это главным образом обучение. Обучение чаще всего проходит внутри компании или в нашем облаке. Здесь мы можем выбирать оборудование, на котором будем это делать, и это упрощает жизнь: например, не нужно обязательно поддерживать SSE на случай, если у клиента нет AVX. Поэтому вычислительный движок для GPU решили реализовывать с использованием CUDA и вести расчеты на поддерживающих его видеокартах Nvidia. Такое решение мы приняли в том числе из-за наличия специализированных библиотек: cuDNN, cuBLAS, cuSparse и т. д. Хотя в дальнейшем мы отказались от cuDNN в пользу собственных реализаций из-за постоянных ошибок и неэффективной работы. Остальные библиотеки показывают себя очень неплохо, написать собственные ядра лучше у нас не получилось.
Результат от внедрения GPU был заметен сразу. Обучение многих сетей ускорилось на порядок. Благодаря этому разработка пошла быстрее, а качество моделей улучшилось.
Получив достойные результаты на основной платформе и наладив эффективное обучение, мы задумались о распространении библиотеки на другие платформы.
Cross-platforms
Основная разработка в ABBYY ведется на Windows, сервера для обучения и тестирования также на Windows, в связи с чем первые версии библиотеки работали только для этой ОС. Однако продукты компании работают и на других платформах, и вскоре мы начали переносить нашу библиотеку на Linux и macOS. Перенос дался достаточно легко, так как единственная необходимая нам зависимость Intel MKL имела версии для этих ОС, а обучение с поддержкой CUDA переносить не было необходимости. Единственными сложностями были различия в компиляторах Microsoft Visual Studio с gcc и Clang, но они не отняли много времени.
Сейчас мы активно используем Linux-версию библиотеки для проведения сравнительных замеров с конкурентами, т.к. поддержка Windows у них часто оставляет желать лучшего. Кроме того, появились задачи по обучению сетей в облаке. Поэтому в ближайших релизах у нас появится версия NeoML, поддерживающая CUDA на Linux.
Mobile platforms
ABBYY занимается разработкой и продажей SDK для обработки изображений и распознавания текста, работающих в том числе и на телефонах. Поэтому с появлением в этих SDK нейронных сетей встал вопрос об их эффективном запуске на мобильных платформах. В этот момент мы еще раз задумались, не использовать ли всё-таки стороннее решение. Оценив возможность интеграции TensorFlow Lite для Android и Core ML для iOS, мы пришли к выводу, что работать с несколькими фреймворками одновременно будет неоправданно дорого, и лучше доработать свой, пусть даже он будет уступать по эффективности.
И мы начали работы по созданию «вычислительного движка» для ARM. Заменив SSE на NEON, а MKL на Eigen, мы за пару недель сделали первую версию библиотеки, работающую на ARM CPU. Оказалось, что полученное решение нас полностью устраивает по эффективности; оно даже превосходило по скорости аналоги. Конечно, с тех пор и TF Lite и Core ML сильно шагнули вперед, но и мы провели ряд существенных оптимизаций, большинство из которых пересекались с x86-версией и не были сильно затратными. Однако были и специфичные для ARM оптимизации. Самая серьезная из них — собственное умножение матриц, благодаря которому мы превзошли скорость библиотеки Eigen примерно на 20%, и в итоге отказались от ее использования.
На текущий момент, NeoML работает на CPU примерно одинаково по сравнению с аналогами, что нас полностью устраивает.
Также для упрощения запуска готовых моделей на iOS и Android мы добавили инференс-обертки для языков ObjectiveC и Java.
Mobile GPUs
Почти все современные телефоны под управлением Android и iOS оснащены отдельным GPU. Интересно, подумали мы и начали изучать, как нам начать его использовать. Первые эксперименты делались с RenderScript и не дали абсолютно никаких результатов, все было ужасно медленно… Однако эксперименты с OpenCL, Vulkan и Metal показали хорошие результаты. На больших сетях GPU могло давать преимущества в 5-7 раз. На маленьких — CPU был все равно быстрее из-за накладных расходов; да и не каждое GPU давало выгоду даже на больших сетях, хорошо работали только дорогие чипы на топовых моделях. К тому же оказалось, что под разные семейства GPU надо писать разный код: например, шейдеры, оптимизированные для Adreno, вовсе не обязательно будут так же хорошо работать на Mali. В общем говоря, сейчас для нас тема использования GPU в мобильных устройствах неоднозначная, но потенциально очень перспективная. На текущий момент мы реализовали вычислительные движки, работающие на Vulkan и Metal, и используем их в ограниченном количестве задач, параллельно продолжая работу над их развитием. Надо сказать, что вычисления на мобильном GPU достаточно емкая тема, во многом отличающаяся от вычисления на десктопных аналогах, и рассказ об этом достоин отдельной статьи.
ONNX
Итак, у нас получился вполне самодостаточный фреймворк. С его помощью мы учим собственные сети, легко интегрируем их в десктопные приложения и без дополнительных расходов переносим на мобильные платформы. Остается одна проблема: читая новые статьи, исследуя новые архитектуры и примеры их использования, наши data scientist’ы постоянно сталкиваются с другими фреймворками. И чтобы разработать модель для решения какой-либо задачи, удовлетворяющую по качеству и скорости, им нужно уметь конвертировать модели из сторонних фреймворков в наш.
Тут приходит на помощь новый формат ONNX. И хотя формат еще молодой и поддержка его во многих фреймворках пока оставляет желать лучшего, он активно развивается, и мы считаем его лучшим решением этой задачи на сегодняшний день. Мы поддержали возможность загрузки нейросетевых моделей из ONNX в нашу библиотеку. Конечно, мы поддержали не весь формат: у него достаточно большая спецификация и несколько версий, но это не главное. Семантика его использования разная в разных фреймворках. Например, одна и та же модель может выглядеть совершенно по-разному, если ее выгрузить в ONNX разными фреймворками. Мы решили ориентироваться в этом вопросе на PyTorch. ONNX модели других, конечно, тоже будут работать, но, возможно, не так эффективно.
В итоге, процесс разработки модели может выглядеть, например, так: первые эксперименты с моделью делаются на PyTorch, далее модель сохраняется в ONNX, из ONNX загружается в NeoML, NeoML-модель дообучается, измеряется ее скорость и качество, и далее модель идет либо на доработку, либо в продакшен.
Теперь у нас есть все, что нужно для поддержки полного цикла разработки ML-моделей.
Open source
Что делать дальше? Мы решили сделать библиотеку open source.
Это новый шаг в развитии библиотеки. Мы делимся своими наработками с сообществом, а в ответ нам хотелось бы получить замечания и предложения, чтобы сделать нашу библиотеку еще быстрее и удобнее.
Библиотека уже сейчас обладает несколькими уникальными особенностями и может стать эффективным средством запуска моделей в различных приложениях на различных платформах. Мы надеемся, что разработчики, имеющие аналогичные нашим сценарии, по достоинству оценят NeoML, и, возможно, в ближайшем будущем присоединятся к работе над библиотекой.
Сравнительные замеры
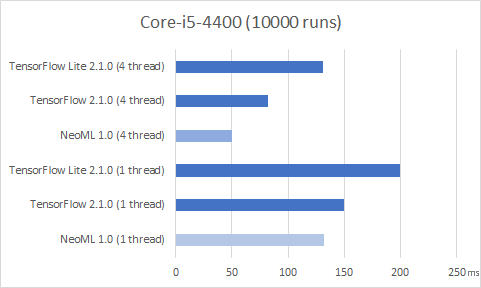
Мы стараемся регулярно сравнивать эффективность нашей библиотеки на своих задачах с аналогами (чаще всего это TensorFlow), чтобы понимать наш текущий уровень. Здесь же для примера приведу сравнения скорости прямого прохода общедоступной сети из пакета TorchVision архитектуры MobileNetV2, обученной для классификации датасета ImageNet. Размеры входа сети 224х224х3. Замеры выполнены на CPU десктопа и нескольких мобильных телефонах, имеющихся сейчас у меня под рукой (как понимаете, пост создавался во время самоизоляции).
На ПК с процессором Core-i5-4400 под управлением Ubuntu 20.04 имеем следующие результаты на 10000 запусков сети:
Потребление памяти при этом следующее:

На телефонах c ОС Android на 10000 запусков результаты следующие:


На телефонах c iOS:


Стоит отметить, что замеры времени работы на телефонах — дело неблагодарное. При желании можно намерить практически любой результат, а замеры на нескольких потоках еще менее показательны (поэтому тут не приведены). Но общую картину при достаточно большом количестве запусков увидеть все-таки можно.
Для детального анализа и оптимизации мы обычно используем различные счетчики процессора, такие как: cpu_cycles, cpu_instructions, cache_access, cache_miss, branch_count, branch_miss, bus_cycles и т. д. По ним также можно увидеть, что обе библиотеки работают примерно одинаково.
Что дальше
Подводя итог, можно сказать, что у нас получилось достойное решение, позволяющее организовать полный цикл разработки и внедрения ML-моделей. На данный момент, NeoML используется практически во всех продуктах компании и каждый день доказывает свою эффективность.
ML является одним из главных приоритетов для компании ABBYY. Мы планируем развивать нашу библиотеку, регулярно выпуская новые версии. В ближайших релизах хотим добавить Python-обертку, поддержать новые архитектуры сетей, расширить поддержку формата ONNX и, конечно, поработать над увеличением производительности.
Если в вашей работе встречаются аналогичные нашим сценарии, то заходите к нам на гитхаб и попробуйте на них NeoML. Будем рады любым отзывам. Также пишите в комментариях, как выглядит ваш пайплайн и с какими проблемами вы в нем сталкиваетесь!
