В настоящее время flash накопители все прочнее занимают нишу носителей информации в Enterprise сегменте. Этому способствует как значительное снижение их стоимости, так и увеличение емкости отдельных накопителей. Там, где еще недавно использовались только механические жесткие диски, сейчас активно эксплуатируют SSD. Причем речь идет не только о внутренних накопителях в клиентских системах, но и о дисковой подсистеме серверов и систем хранения данных. И в этом сегменте отдельное место занимают конфигурации систем хранения, где в качестве носителей используется только SSD. Это — так называемые All Flash системы.

Прежде всего, необходимо понять для себя, что же такое All Flash система хранения. Понятно, что из названия вытекает использование в ней только Flash накопителей. Однако, не все All Flash системы одинаковы. Условно их можно разделить на три подвида.
1. Традиционные СХД с использованием SSD
На самом деле, это – самый многочисленный вид All Flash систем хранения. Потому что для производителя нет ничего проще, чем укомплектовать свою уже существующую СХД SSD накопителями. Конечно же ведущие вендоры помимо переклеивания шильдиков (СХД All Flash) занимаются еще и дополнительной оптимизацией прошивки для удобства работы именно с SSD, а также повышения скорости работы системы в целом. Но есть и те, которые особо не заморачиваются и просто предлагают бандлы, состоящие из обычной СХД и набора SSD. В результате на рынке можно встретить предложения, начиная от All Flash NAS Qnap (оставим за рамками обсуждение целесообразности данного решения, но, ведь, действительно All Flash – не придерешься!) до монструозных многоловых Netapp FAS.
Главным достоинством такого решения является прежде всего умеренная стоимость. Конечно, у каждого вендора есть своя доплата за бренд, но в целом цена All Flash системы (речь про «голову» с контроллерами) по сравнению с классической СХД отличается не сильно (на фоне стоимости SSD так вообще «копейки»).
Минусом же является невысокая итоговая производительность решения. Все подобные All Flash системы, имеющие внутри современное «железо», выдают на запись порядка 300K IOPS (4K, 100% random, рассматриваем режим записи по той причине, что он гораздо тяжелее для СХД, нежели чтение. Показатели чтения, разумеется, значительно выше). Сильное отрицательное отклонение от этой величины скорее является серьезной недоработкой прошивки, а более высокие показатели производительности говорят о лучших алгоритмах кэширования и/или оптимизации прошивки под конкретные модели SSD. В любом случае «насыщение» происходит уже при количестве дисков ~10-20. Поэтому дальнейшее добавление дисков позволит лишь увеличить доступный объем хранения, но не скорость работы.
Основной причиной такого ограничения в производительности является использование классических алгоритмов RAID. Данные алгоритмы были разработаны достаточно давно для работы с механическими жесткими дисками и абсолютно не учитывают особенности работы твердотельных накопителей. Ведь SSD в отличие от HDD не может просто так перезаписать блок данных. Ему требуется перезаписать всю страницу, содержащую изменяемый блок, в новое место, а старое место освободить для последующей новой записи. Эти обстоятельства в дополнение к стандартным RAID penalty дают огромный overhead для операций перезаписи.
2. All Flash массивы с проприетарным «железом»
Для преодоления узких мест традиционных СХД необходимо использовать абсолютно другую архитектуру аппаратного и программного обеспечения. Примером таких решений являются продукты Pure storage или IBM Flash System. В них нет ни RAID в привычном понимании (parity конечно же есть и отказоустойчивость имеется), ни как таковых SSD (вместо них – свои «накопители»). Результатом является просто сумасшедшая производительность и особенно низкие показатели latency. Но стоимость… Действительно, как крыло от самолета.
3. Software defined storage
Особняком от всего этого «зоопарка» All Flash массивов стоят программно-определяемые хранилища (Software Defined Storage, SDS). SDS – это программное обеспечение, работающее на обычном x86 «железе» и выполняющее «эмуляцию» СХД. Мы не зря употребили этот термин в кавычках, т.к. в настоящее время граница между аппаратными и программными контроллерами весьма условна, в отличие от былых времен. Современные СХД чаще всего используют стандартную x86 архитектуру под управлением Linux подобных операционных систем. Да, могут использоваться дополнительные контроллеры с поддержкой offload для некоторых операций. Но основное отличие от SDS – это закрытость как «железа», так и ПО для пользователя. SDS же, напротив, позволяет использовать практически любое рекомендуемое аппаратное обеспечение и производить умеренные модификации в программных компонентах.
Однако, если использовать SDS не просто в качестве СХД, а как All Flash массив, то давать возможность пользователю свободно выбирать серверную платформу и производить самостоятельную установку ПО неверно. Основная причина – невозможность гарантировать заданные показатели производительности (собственно, основную причину выбора All Flash), а также сложность поддержки широкого списка оборудования. Поэтому на рынке присутствуют так называемые appliance – законченные решения, состоящие из серверной платформы с предустановленным и настроенным ПО и укомплектованные необходимым количеством SSD, что в целом обеспечивает заданную производительность.
Представителями именно такого типа решения (SDS appliance) и являются герои нашего обзора – All Flash массивы компании AccelStor.
AccelStor – собственный взгляд на работу All Flash
Компания AccelStor была образована как startup в 2014 году. Ключевым инвестором (по сути – владельцем этого проекта) является широко известный IT гигант Toshiba. Еще до коммерческого запуска компания обращала на себя внимание, получая высшие награды на различных мероприятиях, посвященных Flash технологиям. Одна из топ-наград в их списке получена на весьма известном и престижном мероприятии Flash Memory Summit (2016).

Награды AccelStor
Все эти награды были получены за инновационный подход по работе с flash памятью, реализованного в фирменной технологии FlexiRemap, которой обладают все массивы AccelStor NeoSapphire.
Технология FlexiRemap представляет собой специальный алгоритм для работы с SSD так, чтобы избавиться от узких мест в плане производительности, а также максимально увеличить срок службы накопителей. Основной идеей является преобразование случайных запросов на запись в последовательные цепочки. Т.е. поступившие блоки данных объединяются в цепочки, кратные «страницам», и только потом записываются на SSD. В результате такой подход к записи новых данных является с точки зрения накопителей последовательным, что в итоге позволяет добиться высоких показателей производительности.
В процессе работы алгоритм FlexiRemap ведет учет востребованности всех блоков данных. В соответствии с частотой использования данные автоматически ранжируются при перезаписи так, чтобы все «горячие» данные располагались максимально близко друг к другу. Тогда в процессе изменения блоков эти данные будут также перемещаться в новые «страницы» совместно, что опять же позволит пользоваться более производительным последовательным режимом записи на SSD по сравнению с традиционным подходом. Этот механизм похож на этакий виртуальный тиринг, который помимо прочего также ускоряет работу Garbage Collection, т.к. «сборщик мусора» также будет выполнять свою работу в последовательном режиме.
Несмотря на то, что RAID здесь не применяется, данные все равно находятся под защитой. Для этого все SSD делятся на две симметричные группы. Весь ввод/вывод равномерно распределяется по обоим группам (stripe). В каждой группе помимо данных хранятся контрольные суммы так, чтобы была возможность продолжать работу в случае отказа одного накопителя. Суммарно массив может выдержать отказ двух SSD, что в сравнении с RAID эквивалентно уровню RAID 50 из двух групп.

Организация массива данных
При записи применяется механизм round robin, благодаря которому данные максимально равномерно распределяются по всем дискам. Помимо этого, у каждого SSD есть собственный коэффициент веса, который зависит от его текущего ресурса записи. Поэтому если какой-либо диск изношен сильнее остальных, он будет реже получать новые данные до тех пор, пока показатели ресурса не сравняются. По сравнению с традиционным методом в RAID, технология FlexiRemap позволяет значительно увеличить срок службы накопителей за счет их равномерного использования.

FlexiRemap против RAID
Особо стоит отметить механизм сохранности данных в случае отказа какого-либо диска. В этом случае та группа, в которой отказал SSD автоматически переводится в режим «только для чтения». Делается это для максимально быстрого выполнения процесса ребилда на диск hot spare. Как только группа восстановится, она может снова участвовать во всех типах операций. Причем автоматически сработает описанный ранее механизм выравнивания ресурса записи.
Говоря о SDS appliance, нужно понимать, что это по сути сервер с предустановленным ПО. Поэтому он априори одноконтроллерный, выражаясь в терминологиях СХД. И хотя ряд задач позволяет не прибегать к резервированию контроллеров системы хранения, все вендоры СХД уже давно приучили нас, что «правильная» СХД – это СХД с двумя (или даже более) контроллерами. У AccelStor на это также есть свой ответ – технология Shared Nothing для работы двух нод в кластере.
Модели AccelStor NeoSapphire с двумя нодами могут быть как в едином корпусе (на базе twin серверов), так и в виде двух отдельных серверов. Последние можно разнести на расстояние до 100м друг от друга для создания disaster recovery. В любом случае для синхронизации данных между нодами используется внешнее соединение через InfiniBand 56G с дополнительной проверкой «пульса» через Ethernet.

Организация синхронизации между нодами
В отличие от привычной двухконтроллерной СХД здесь дублируются не только сами контроллеры (ноды) с обязательной обвязкой в виде модулей охлаждения и блоков питания, но и сами данные. Каждая нода в AccelStor NeoSapphire абсолютно независима и содержит полную копию данных благодаря непрерывной синхронной репликации. Обе ноды работают в режиме Symmetric Active-Active без применения передачи запросов друг другу (ALUA), как в классических СХД. Поэтому время переключения в случае сбоя со стороны AccelStor реально стремится к нулю. А наличие двух копий данных позволяет значительно повысить надежность системы по сравнению с традиционной архитектурой.
Продолжая тему надежности, стоит отметить, что массивы Accelstor не кэшируют данные при операциях записи, т.к. работают в синхронном режиме. Все промежуточные действия над данными алгоритмом FlexiRemap выполняются в оперативной памяти контроллера. Но массив выдаст подтверждение хосту об успешном завершении операции только после физической записи на SSD. Поэтому в All Flash массивах Accelstor нет батарей/конденсаторов из-за отсутствия необходимости в них.
Помимо уникальных технологий All Flash массивы AccelStor NeoSapphire обладают и стандартным для рынка Enterprise функционалом: Thin Provisioning, снапшоты по технологии Redirect-on-Write с возможностью их бэкапа и восстановления через внешние CIFS/NFS папки, асинхронная репликация, компрессия и дедупликация. Отдельно стоит отметить функцию Free Clone по созданию копий томов, которые физически не занимают места, т.к. являются по сути ссылками на исходный том. Данная функция может быть очень полезна, например, в VDI.
Разумеется, присутствует поддержка всех современных операционных систем и платформ виртуализации. Имеется plug-in для VMware vSphere Web Client с возможностью управления томами и в полной мере реализующий функционал Free Clone.
Важным преимуществом Accelstor NeoSapphire как Software Defined Storage является возможность работы на обычном «железе» x86 с совершенно стандартными SSD. Да, производитель не предоставляет вольностей по выбору аппаратной платформы: это он выполняет за вас. Делается это прежде всего для гарантированно предсказуемой производительности решения, а также с целью исключить проблемы совместимости. Все All Flash массивы Accelstor собираются под конкретного заказчика в нужной ему конфигурации и проходят тщательное тестирование перед отправкой. Стандартная гарантия на все массивы 3 года NBD с опережающей заменой запчастей. Т.к. вендор присутствует на территории России, техподдержка имеется в том числе и на русском языке.

При заказе All Flash массива Accelstor NeoSapphire можно гибко выбирать необходимый объем. Причем этот объем – то, что реально доступно хостам для работы независимо от физической организации дискового пространства. Необходимо учитывать, что все модели поставляются полностью заполненные дисками. Свободных слотов нет – добавить диски не получится. Это делается все из-за тех же упомянутых ранее требований по производительности и надежности. Если в будущем понадобится увеличить объем, это можно сделать при помощи полок расширения (доступно для старших моделей). Также заранее необходимо определиться, сколько нод (контроллеров) будет в массиве, т.к. апгрейд на текущий момент до двухнодового режима не предусмотрен.
В качестве интерфейсов для всех моделей доступен выбор 10G iSCSI или 16G Fibre Channel. Опционально может быть также 56G InfiniBand. Для iSCSI моделей помимо блочного доступа бонусом идет поддержка файловых протоколов CIFS и NFS. Количество портов определяется заданной производительностью системы так, чтобы они не были узким местом (обычно 2-6 портов на ноду).
В качестве накопителей используются стандартные SSD Enterprise класса. Чаще всего с интерфейсом SATA, т.к. работы с двумя контроллерами не требуется. Имеются также модели All Flash массивов на базе NVMe дисков.
Использование стандартных серверных платформ и SSD позволяет заметно оптимизировать стоимость решения в целом. При этом AccelStor обеспечивает сервис от своего имени на все решение целиком независимо от того, комплектующие какого производителя входят в состав массива.
И, да, крайне важный момент: никаких платных лицензий! Весь функционал доступен сразу «из коробки». Более того, в случае расширения функционала новые возможности будут доступны при обновлении прошивки.
Проверка в деле
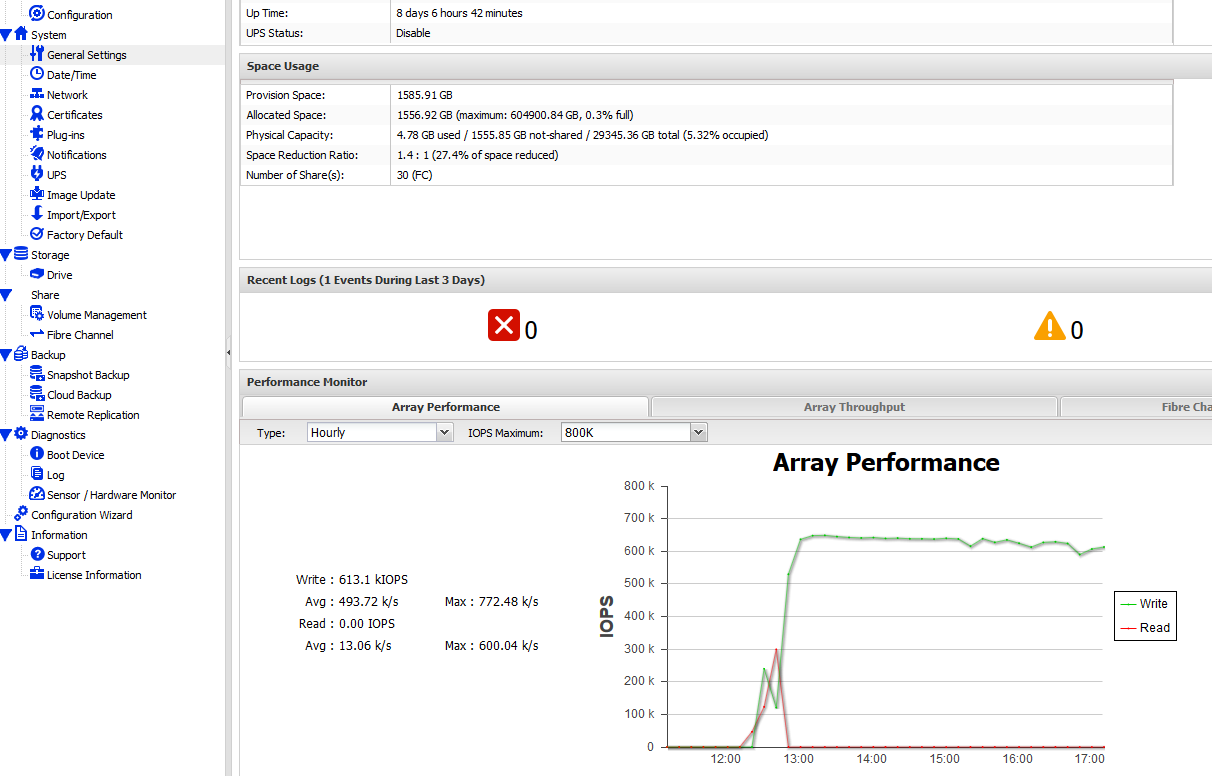
У AccelStor имеется широкая номенклатура моделей с различной заявленной производительностью. Минимальная модель NeoSapphire 3401 с 8 SSD способна обеспечить 300K IOPS@4K. А топовая P710 с 24 SSD выдает уже 700K IOPS@4K. Что же касается NVMe моделей, то тот же показатель в 700K IOPS@4K достигается в NeoSapphire P310 всего при 8 SSD! И заметьте, что указанные значения производительности – это запись в устоявшемся режиме (чтение и всякие пиковые значения выше), т.е. в самом тяжелом для массива режиме работы.
Мы провели тестирование двухнодовой системы NeoSapphire H710 с 48 SSD (по 24 SSD в каждой ноде) с доступной емкостью 27ТБ. Accelstor декларирует производительность для этой модели не ниже 600K IOPS 4K, random write. Тестирование производилось в IOmeter с трех серверов, подключенных через Fibre Channel.

В синтетических тестах All Flash массив оказался даже лучше, чем обещано в спецификации, что, по нашему мнению, является только плюсом в сегменте рынка, где любые показатели подвергаются сомнению (спасибо оторванным от реальности маркетологам за это!).
Важно отметить, что одним из основных преимуществ алгоритма FlexiRemap является высокая производительность в режиме записи без деградации с течением времени. Т.е. достигнутый показатель в устоявшемся режиме будет таким же и через 10мин/час/… непрерывной работы. Для подтверждения этого факта мы запустили тест IOmeter (4K, 100% random write) на несколько часов (использовался один хост). Да, это действительно так: производительность практически не меняется с течением времени.
Вердикт
Выбирая All Flash массив, большинство пользователей по умолчанию предпочитают рассматривать в качестве кандидатов традиционные СХД, укомплектованные SSD. И если производительность ~280K IOPS (4K, random write) вас устроит, то вы мыслите в правильном направлении. Вот только задачи бизнеса все чаще требуют, чтобы оборудование работало на все 146%. И с обычной СХД выше головы, увы, не прыгнут, а какой-нибудь IBM Flash System стоит заоблачных денег. И вот здесь All Flash массивы AccelStor будут как нельзя кстати. Достойная производительность, высокая надежность, гибкий выбор конфигурации и адекватная техподдержка – это далеко не полный перечень достоинств данных массивов. Добавьте к этому полное отсутствие скрытых платежей за лицензии и более длительный срок использования SSD — и вы получите не просто интересный продукт, а достойный инструмент в работе вашего бизнеса.
Так что уже занятое AccelStor место «под солнцем» на рынке сверхбыстрых массивов будет неминуемо расширяться. И, как знать, каких вершин они смогут достичь.
