
Введение в проблематику
В своей практике работы с разными типами заказчиков – от крупных международных компаний до небольших фирм или даже ИП – мы наблюдаем схожие проблемы при попытке системно работать с уязвимостями.
Пока компания относительно небольшая, достаточно иметь один или несколько сканеров уязвимостей и одного специалиста, который будет проводить периодическую проверку всей инфраструктуры, закрывая наиболее очевидные или простые в устранении проблемы.
На практике же когда компания растет, растет число устройств в сети, используются новые информационные системы, включая нестандартные, простого подхода уже не хватает, поскольку бизнес хочет получить ответы на вопросы:
- А с какими уязвимостями из отчета сканера (их может быть тысячи и десятки тысяч) надо работать и почему?
- А сколько стоит исправление этих уязвимостей?
- А точно ли кто-то может ими воспользоваться, чтобы провести атаку?
- А чем я рискую, если не буду ничего исправлять?
- А как убедиться, что все исправлено?
Не у каждого безопасника и системного администратора с ходу найдется внятный ответ на все эти вопросы. Также не стоит забывать, что само по себе управление уязвимостями – это достаточно сложный процесс, и имеется много факторов, влияющих на принятие решений:
- высокие риски стать жертвой массовой или таргетированной атаки, если вовремя не устранить уязвимости (особенно это касается внешнего периметра);
- высокая стоимость устранения для многих уязвимостей, особенно, если нет готового патча или уязвимости подвержено большое количество распределенных устройств (зачастую это является стоп-фактором, и в итоге проблемы сохраняются);
- если за разные типы оборудования отвечают разные люди или даже компании, не всегда обладающие необходимой квалификацией для правильной оценки обнаруженных уязвимостей, процесс устранения может крайне затянуться во времени или не начаться вовсе;
- если используется специализированное оборудование или SCADA-системы, то высока вероятность отсутствия необходимых патчей от производителя или невозможность обновления системы в принципе.
Из-за всего этого процесс управления уязвимостями, реализуемый бессистемно, не выглядит эффективным и понятным в глазах бизнеса.
Учитывая потребности бизнеса и понимая специфику работы с уязвимостями информационной безопасности, мы в Акрибии придумали отдельную услугу.
Что же мы придумали?
Мы посчитали, что к управлению уязвимостями нужно подходить системно, как и к любому процессу. А это именно процесс, причем непрерывный и итеративный, состоящий из нескольких стадий.
Подключение клиента
Мы берем на себя заботу о предоставлении, настройке и поддержке всех необходимых инструментов. От клиента требуется только выделить виртуальный или физический сервер (возможно, несколько, если сеть большая и распределенная). Мы сами установим все необходимое и настроим для корректной работы.
Инвентаризация и профилирование активов
Если вкратце, смысл в том, чтобы выявить все устройства в сети, разбить их на однотипные группы (уровень детализации такого разбиения может варьироваться в зависимости от масштабов сети клиента или наличия большого числа специфических устройств), выбрать группы, в отношении которых оказывается услуга, узнать лиц, ответственных за выбранные группы.

Важно не просто разово провести эту процедуру, а выделить паттерны, чтобы в любое время понимать, что происходит в сети, находить новые устройства, находить старые устройства, которые переехали, находить новые подтипы внутри групп и прочее. Это важно. Инвентаризация происходит постоянно с заданной периодичностью. Мы в своей практике пришли к тому, что без понимания структуры активов эффективное управление уязвимостями нереализуемо.
Мы долго работали над алгоритмом профилирования активов, каждый раз добавляли новые условия или вообще переделывали все заново. Не будем раскрывать все технические детали и приводить строки кода, реализующего наш алгоритм, приведем лишь общую последовательность действий:
- Клиент предоставляет IP-план сети.
- При помощи сетевого сканера для каждого устройства формируется отпечаток на основании открытых сетевых портов и ОС.
- Профили объединяются по устройству и типу (например, Cisco Catalyst 2960 \ Сетевое оборудование).
- При появлении нового устройства ищется максимально похожий профиль.
- Если точность недостаточная, то тип устройства уточняется у клиента.
- Периодически проводится повторное сетевое сканирование для актуализации данных и поиска новых устройств и типов.
В случае отсутствия точного IP-плана сети (например, при использовании DHCP или «человеческом факторе») возможен вариант оперативного профилирования на основании нескольких известных IP-адресов. Далее определяются похожие устройства в пределах типа, и профиль модернизируется.
Такой подход позволяет нам определять тип устройства с точностью около 95%, но всегда хочется большего. Мы открыты к новым идеям, комментариям и замечаниям. Если есть что-то, что мы не учли, готовы подискутировать в комментариях.
Расписание сканирования
Когда у нас уже есть вся необходимая информация о сети клиента, мы составляем план-график сканирования на уязвимости с учетом требуемой периодичности проверок каждого из типов устройств. Периодичность может быть любой – от 1 дня до 1 года. Периодичность с одной стороны зависит от того, насколько оперативно и как часто клиент готов работать с уязвимостями того или иного оборудования, с другой стороны влияет на цену услуги.
Например, план может выглядеть так:

Важно отметить, что внешний периметр сети мы настоятельно рекомендуем проверять ежедневно, для максимального снижения риска эксплуатации 1-day (только что опубликованных) уязвимостей. Та же рекомендация касается и публичных Web-ресурсов клиента.
Собственно, сканирование
За неделю до плановой даты старта сканирования групп устройств мы связываемся с ответственным за группу, информируем его о датах сканирования и высылаем полный перечень устройств, которые будем проверять. На этом этапе можно скорректировать (при необходимости) область проверки. Это делается, чтобы минимизировать риски неправильного распознавания устройств в сети.
После завершения сканирования ответственный также информируется. Т.е. заинтересованные лица ВСЕГДА в курсе происходящего.
Мы используем несколько разных сканеров, в том числе отдельные инструменты для поиска уязвимостей в web-системах. Так мы получаем больше информации для анализа и можем найти больше потенциальных проблем.
Для оптимизации затрат мы можем не сканировать всю группу однотипных устройств целиком, а ограничиться репрезентативной выборкой, например, 30-50% случайно выбранных устройств из группы или 30-50% устройств из каждого территориально распределенного офиса. При нахождении критичных уязвимостей на выборочных устройствах запускается поиск по конкретным уязвимостям уже на всех устройствах группы. Так мы получаем наиболее полный охват за меньшее время.
Важно отметить, что есть отдельные уязвимости, которые не определяются стандартными инструментами. Когда мы начинаем сканировать определенный тип устройств, мы проверяем все публичные уязвимости и убеждаемся, что наши сканеры умеют их находить. Если мы понимаем, что стандартного инструментария не хватает, то отдельные уязвимости мы ищем вручную или разрабатываем собственные инструменты для проверки.
И самое главное, когда в публичном пространстве появляется информация о новой опасной уязвимости, мы не будем ждать планового сканирования. Все клиенты, которые потенциально могут пострадать от только что найденной уязвимости будут оперативно оповещены о проблеме, и мы произведем внеплановую проверку.
В целом подробное описание применяемой нами технологии поиска уязвимостей несколько выходит за рамки этой статьи, но ознакомиться с ней можно по презентации, которую мы делали на SOC-Forum в 2017 году.
Анализ результатов сканирования
Если вы когда-нибудь запускали сканер уязвимостей в корпоративной сети из 100+ хостов, то вы наверняка помните то самое чувство, которое возникает при виде километрового списка однотипных записей, из содержания которых на первый взгляд мало что понятно. Без специальных знаний затруднительно адекватно оценить, что оставить как есть, а что надо исправить, и в каком порядке действовать.
Этот шаг мы берем на себя, мы смотрим на результаты, выбираем действительно критичные проблемы, которые могут нанести реальный ущерб бизнесу клиента.
Мы оцениваем такие параметры как:
- доступность уязвимого устройства/сервиса для потенциального нарушителя;
- наличие публичного эксплойта;
- сложность эксплуатации;
- потенциальный риск для бизнеса;
- не является ли ложным срабатыванием;
- сложность устранения;
- и прочее.
После обработки «проверенные и одобренные» нами уязвимости публикуются в системе управления инцидентами (о ней расскажем отдельно), где сотрудники клиента могут их посмотреть, задать вопросы, взять в работу или отклонить в случае принятия рисков.
По необходимости мы также назначаем консультацию с ответственным за уязвимые устройства и подробно рассказываем, что найдено, чем это грозит и какие варианты минимизации рисков есть.
После передачи уязвимости в работу, мячик переходит на сторону клиента, а мы переходим к сканированию следующей группы устройств.
Но процесс для первой группы на этом не заканчивается.
Контроль устранения уязвимостей
В системе для каждой опубликованной уязвимости можно поставить статус и предельный срок устранения. Мы отслеживаем изменение статусов, а также приближение предельного срока.
Если уязвимость закрыта клиентом, мы это видим и запускаем проверку, чтобы убедиться, что уязвимости действительно больше нет. Т.к. проверка запускается только на одну уязвимость, то она не занимает много времени, результат можно получить за день для сотни тысяч хостов или даже за секунды для маленькой группы устройств.
Если уязвимость действительно закрыта, мы это подтверждаем. Если уязвимость на всей или части устройств из группы сохранилась, тогда мы возвращаем на доработку.
Цикл работы с каждой уязвимостью заканчивается только тогда, когда нами будет подтверждено, что на всех уязвимых устройствах её больше нет.
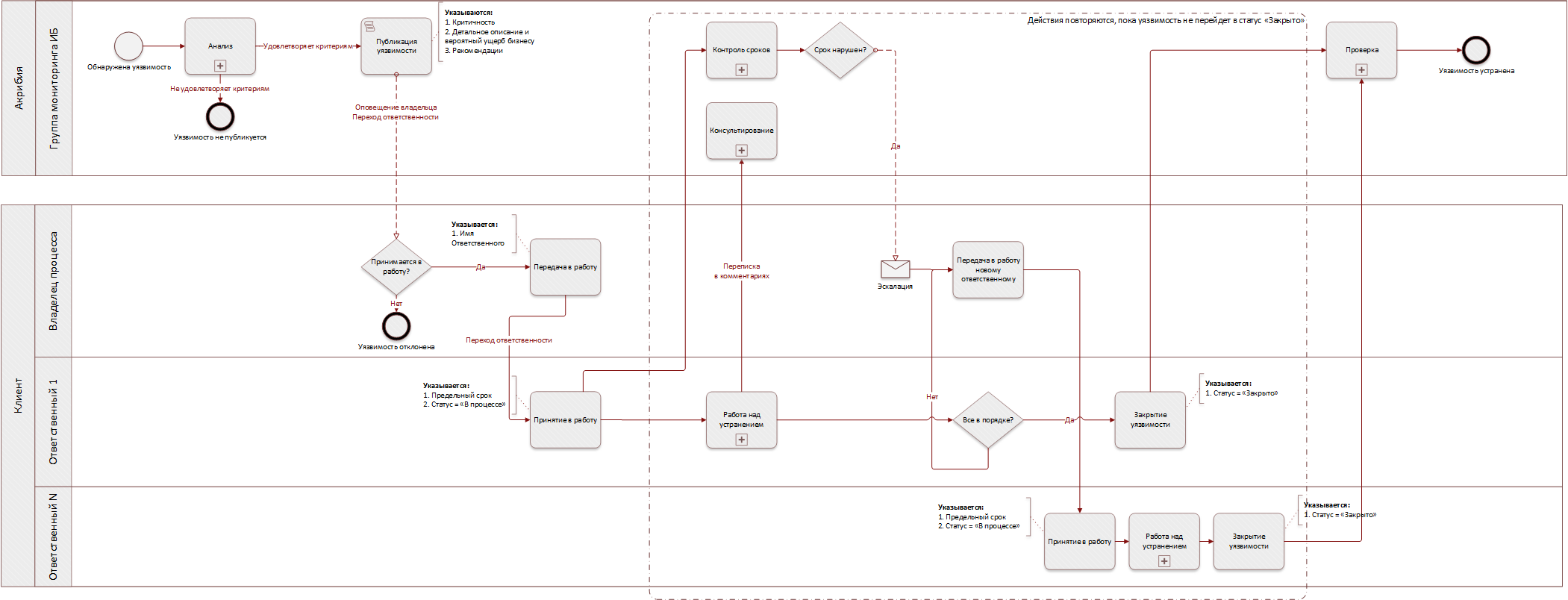
Общая схема примерно выглядит таким образом:

В процессе контроля устранения уязвимостей можно выделить 2 вспомогательных подпроцесса: контроль сроков и работа с ответственными за закрытие уязвимости со стороны клиента.
Контроль сроков
Повторюсь, для каждой уязвимости должен быть назначен предельный срок ее устранения. Этот параметр задается клиентом самостоятельно, т.е. мы не диктуем, насколько быстро должны работать ответственные сотрудники клиента, но мы отслеживаем достижение целей. Если задачи просрочены, об этом уведомляется держатель процесса управления уязвимостями со стороны клиента. Информация об уязвимостях, закрытых в срок или просроченных, отражается нами в периодических отчетах с указанием имен, так сказать, «отличников» и «двоечников». Также нами считается такой показатель, как средняя скорость устранения уязвимостей. Так у клиента собирается необходимая информация для планирования сроков, загрузки ответственных, а также об их достижениях или упущениях.
Работа с ответственными
Иногда по отдельным уязвимостям возникает потребность в назначении нескольких ответственных, передаче всей или части работы по задаче иному лицу или просто в смене ответственного, потому что первый не справился, ушел в отпуск, на больничный и пр. Все это позволяет реализовать наша система.
На картинке ниже приведена схема работы сервиса в разрезе одной уязвимости.
Эффективность
Вот так мы выстроили процесс работы и видим в нашем подходе ряд преимуществ и возможностей, которые помогут более эффективно работать с уязвимостями и в то же время решают обозначенные в первой части статьи проблемы:
- Мы берем на себя не только задачу по запуску сканеров для поиска уязвимостей в сети, но и по анализу результатов их работы. Мы отсеиваем лишнее и на выходе получается конечный список уязвимостей, с которыми можно и нужно работать.
- Оформляя этот список и презентуя его ответственным специалистам заказчика, мы всегда пишем 2 вещи: детальное описание смысла уязвимости и того негативного влияния на бизнес, которое она в себе несет, и рекомендации по устранению или минимизации рисков. Таким образом, всегда можно понять, а что будет, если ничего не делать, и можно оценить время и стоимость реализации рекомендованных мероприятий.
- Если все еще есть сомнения или аргументов в пользу устранения определенной уязвимости недостаточно, мы дополнительно можем проверить возможность проэксплуатировать эту уязвимость в реальных условиях или приближенных к реальным. После проведения такого «мини-пентеста» будет видно, насколько возможно и сложно потенциальному злоумышленнику будет провести атаку.
- Наконец, когда работы по устранению уязвимости завершены, мы всегда это проверяем. Таким образом, можно исключить риск ошибок или недоработок.
А клиент в свою очередь получает на наш взгляд ценные возможности и может:
- сосредоточиться на действительно важных группах устройств и отслеживать их состояние чаще;
- сосредоточиться на действительно опасных уязвимостях, которые могут принести реальный ущерб;
- контролировать работу над каждой уязвимостью, отслеживать изменение статуса и сроки;
- получать индивидуальные консультации по закрытию уязвимостей;
- высвободить время своих сотрудников, необходимое на запуск и обработку результатов сканирований, а также на настройку и поддержку всех необходимых инструментов;
- ну и как бонус для финансового директора – перевести капитальные затраты на покупку собственных инструментов для сканирования в операционные на оплату услуг экспертов.
Интересно? В разделе услуги на нашем сайте вы можете посмотреть цены, а также заказать тестирование услуги на специальных условиях.
