Привет, Хабр! Меня зовут Роман, и я хочу рассказать сегодня о том, как мы в университете Иннополис разрабатывали тестовый стенд и сервис для системы Acronis Active Restore, которая скоро должна стать частью продуктовой линейки компании. Всех, кому интересно, как строятся взаимоотношения университета с индустриальными партнерами, приглашаю проследовать под кат.

Разработка Active Restore началась внутри компании Acronis, но мы, как студенты университета Иннополис, приняли участие в этом процессе в рамках учебного индустриального проекта. О самой идее, а также об архитектуре мой куратор (а теперь и коллега) Даулет Тумбаев уже написал в своем посте. Я же сегодня расскажу о том, как мы готовили сервис со стороны Иннополиса.
Все началось еще летом, когда нам сообщили, что в первом семестре к нам приедут ИТ-компании и будут предлагать свои идеи для практической работы. И вот, в декабре 2018 нам представили 15 разных проектов, и в конце месяца мы расставили приоритеты, разобрались, кому что больше нравится.
Все магистранты заполнили форму, где нужно было выбрать четыре проекта, в которых мы хотели участвовать. Нужно было мотивировать, почему именно я, и почему именно эти проекты. Я, например, указал, что у меня уже есть опыт в системном программировании и разработке на языках C/C++. Но главное, что проект позволял мне развить свои навыки и продолжать рост.
Через две недели нас распределили, и с начала II семестра началась работа над проектами. Команда была сформирована, на первой встрече мы оценили сильные и слабые стороны друг друга и распределили роли.
Первые две недели нам нужно было запускать процесс. Мы установили контакты с заказчиком, формализовали требования к проекту, запустили итерационный процесс, настроили окружение для работы.
Кстати, работа с заказчиком у нас действительно закипела, когда у нас начались элективы. Дело в том, что Acronis ведет в университете Иннополис (и не только) предметы по выбору. И Алексей Костюшко, ведущий разработчик из Kernel команды, преподает два курса на постоянной основе: Reverse Engineering и Windows Kernel Architecture and Drivers. Насколько я знаю, в будущем планируется также курс по системному программированию и многопоточным вычислениям. Но главное, что все эти курсы построены таким образом, чтобы помочь студентам справиться с индустриальными проектами. Они серьезно прокачивают в понимании предметной области и тем самым упрощают работу над проектом.
За счет этого мы стартовали бодрее других команд, да и само взаимодействие с Acronis стало более плотным. Алексей Костюшко выступал для нас в роли Product Owner, от него мы получали необходимые знания в предметной области. Благодаря его элективам, наши hard-скиллы и компетенции очень сильно прокачались, мы стали действительно готовы выполнить задачу, которая перед нами стояла.
Первый месяц для всех команд был максимально тяжелым. Все были потерянными, не знали с чего начать – может быть, с документов или, наоборот, нырять в код. От кураторов и менторов в университете и представителей компании первое время приходили противоречивые комментарии.
Когда все встало на свои места (по крайней мере в моей голове), стало понятно, что менторы от университета помогали нам выстроить внутренние отношения в команде, вести подготовку документов. Но реальной точкой прорыва стал приезд Даулета в марте. Мы просто сели и все выходные работали над проектом. Тогда мы переосмыслили суть проекта, перезагрузились, перераспределили приоритеты задач и быстро полетели вперед. Мы поняли, что нужно делать для запуска эксперимента (о нем чуть ниже) и разработки сервиса. С этого момента общее представление превратилось в четкий план. Началась реальная разработка кода, и за 2 недели мы разработали первый вариант тестового стенда, включающий виртуальные машины, необходимые сервисы и код для автоматизации эксперимента и сбора данных.
Стоит отметить, что параллельно с индустриальным проектом шли учебные курсы, которые помогали нам выстроить грамотную архитектуру для своих проектов и организовать Quality Management. Поначалу на эти задачи уходило 70-90% времени в неделю, но, как оказалось, временные затраты были необходимы, чтобы избежать проблем в процессе разработки. Цель университета заключалась в том, чтобы мы научились грамотно выстраивать процесс разработки, а компании, как заказчики, были больше заинтересованы в результате. Это, конечно, вносило немало суматохи, но зато помогло соединить теоретические и практические навыки. Достаточная сложность и нагрузка обеспечили наличие мотивации, что и вылилось в успешный проект.
Изначально два человека в нашей команде занимались чисто разработкой, один человек взял на себя документы, а еще один погрузился в настройку окружения. Однако, позже к нам присоединились еще трое бакалавров, с которыми мы стали единой командой. Университет решил запустить тестовый индустриальный проект для студентов третьего года обучения. Расширение команды с 4 до 7 человек сильно ускорило процесс, потому что наши бакалавры могли легко выполнять задачи, связанные с разработкой. Екатерина Левченко помогала с написанием python кода и batch скриптов для тестового стенда. Ансат Абиров и Руслан Ким выступали в роли разработчиков, они занимались выбором и оптимизацией алгоритмов.
В таком формате мы работали до конца мая, когда был налажен эксперимент. В этот момент закончился индустриальный проект для бакалавров. Двое из них начали стажировку Acronis и продолжили работать с нами. Поэтому после мая мы работали уже как одна команда в составе из 6 человек.
Перед нами был III семестр, который в Иннополисе свободен от академических активностей. У нас было всего 2 электива, а все остальное время уходило на индустриальный проект. Именно в III семестре работа по сервису пошла интенсивно. Процесс разработки полноценно встал на рельсы, демо и отчеты стали регулярными. В таком формате мы проработали 1,5 месяца, и в конце июля практически закончили девелоперскую часть работы.
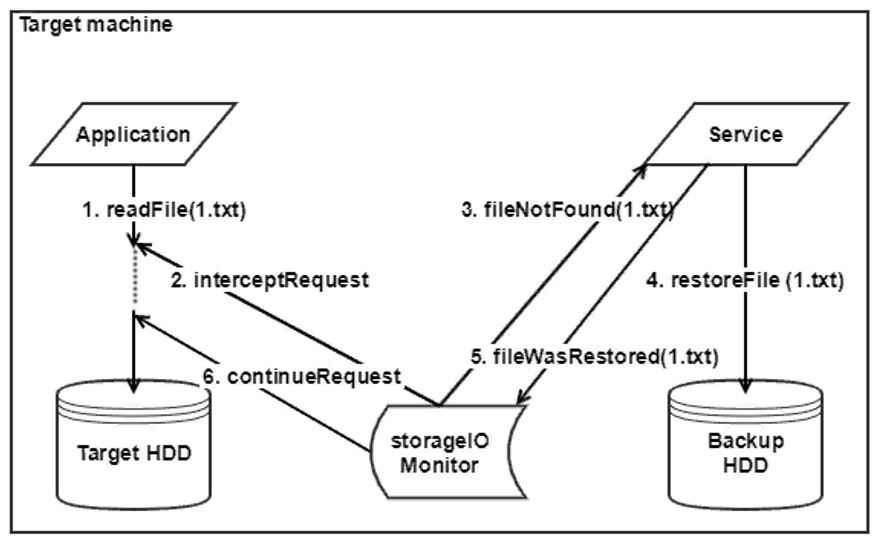
Сначала были сформулированы требования к сервису, который должен адекватно взаимодействовать с минифильтр-драйвером файловой системы (что это, можно почитать тут) и продумана его архитектура. С прицелом на простоту дальнейшей поддержки кода мы сразу предусмотрели модульный подход. В состав нашего сервиса входит несколько менеджеров, агентов и хендлеров, и еще до начала кодинга была заложена возможность работать параллельном режиме.
Однако, после обсуждения архитектуры на встрече с ребятами из Acronis было принято решение сначала провести эксперимент, а потом уже заняться самим сервисом. В результате на разработку ушло всего 2,5 месяца. Все остальное время мы проводили эксперимент, чтобы найти минимальный достаточный список файлов, на которых можно было бы запустить Windows. В реальной системе данный набор файлов формируется с помощью драйвера, однако, мы решили найти этот сет эвристически, методом половинного деления, чтобы проверить работу драйвера.
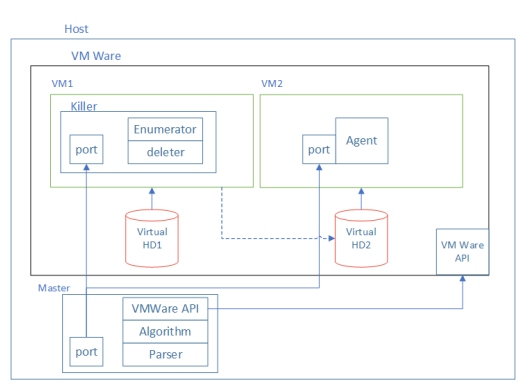
Стенд эксперимента.
Для этого мы собрали стенд на Python из двух виртуальных машин. Одна из них работала на Linux, а вторая загружала Windows. Для них было сконфигурировано два диска: Virtual HD1 и Virtual HD2. Оба диска были подключены к VM1, на которой был установлен Linux. На данной виртуалке на HD1 было установлено приложение Killer, которое “повреждало” HD2. Под повреждением имеется ввиду удаление части файлов с диска. HD2 был загрузочным диском для VM2, которая работало под системой Windows. После “повреждения” диска мы пытались запустить VM2. Если это удавалось сделать, то удаленные с диска файлы относились к ненужным для запуска.
Для того, чтобы автоматизировать этот процесс, мы постарались удалять файлы не случайным образом, а в рамках заранее продуманного подхода. Алгоритм состоял из 3 шагов:
Для начала мы решили промоделировать работу алгоритма. Предположим в файловой системе 1000000 файлов. В таком случае, наиболее эффективно поиск критических файлов происходил в случаях, когда критических файлов было около 15% от общего количества.

Метод половинного деления.
Сначала проблем с экспериментом было очень много. Недели за 2-3 был готов тестовый стенд. И еще 1-1,5 месяца пришлось ловить баги, дописывать код и применять различные ухищрения, чтобы заставить стенд работать.
Самое сложное было отловить баг, который был связан с кэшированием операций с диском. Эксперимент работал в течение 2 дней и выдал очень оптимистичные результаты, которые в разы опережали симуляции. Однако, тест критических файлов провалился, система не запустилась. Оказалось, что при принудительном выключении виртуальной машины, операции удаления, которые кэшировались файловой системой, не исполнялись, и, соответственно, диск не был полностью очищен. В итоге алгоритм получал неверные результаты, а мы пару дней напрягали все свои извилины, чтобы во всем этом разобраться.
В определенный момент мы заметили, что при продолжительной работе алгоритм закапывался в одном из сегментов файловой системы и начинал попытки удалить одни и те же файлы (в надежде на новый результат). Это случалось в моменты, когда алгоритм упирался в регионы, где большая часть была нужными, при этом выбрав неудачный интервал для удаления. В этот момент мы решили добавить решафл списка файлов. То есть раз в несколько итераций список файлов перемешивался. Это помогло выбивать алгоритм из подобных залипаний.
Когда все было готово, мы запустили эти две ВМ на 3 суток. Всего прошло около 600 итераций, среди которых было больше 20 успешных запусков. Стало ясно, что этот эксперимент можно запустить надолго, а также на более мощных машинах, чтобы найти оптимальный объем файлов для запуска Windows. Также работу алгоритма можно распределить на несколько машин, чтобы еще сильнее ускорить данный процесс
В нашем случае на диске кроме Windows был только Python и наш сервис. За три дня нам удалось сократить количество файлов с 70 тысяч до 50 тысяч. Список файлов был сокращен всего на 28%, но зато стало понятно, что такой подход – рабочий, и он позволяет определить минимальный набор файлов, необходимых для загрузки ОС.
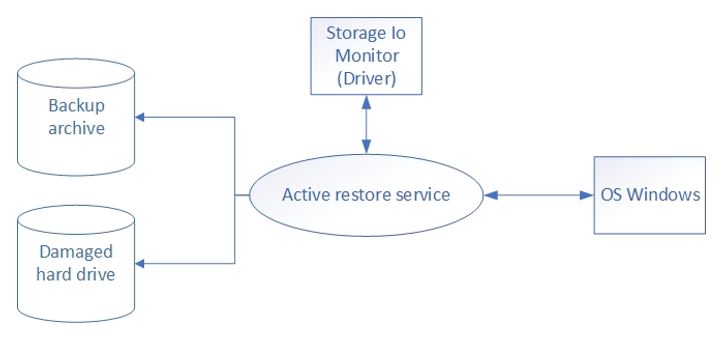
Коснемся немного структуры сервиса. Основной модуль сервиса – это менеджер очереди. Поскольку мы получаем список файлов от драйвера, нужно восстанавливать файлы по этому списку. Для этого мы создавали свою очередь с приоритетами.

У нас есть список файлов, которые восстанавливаются по очереди. И если появляются новые запросы на доступ, срочно понадобившиеся файлы восстанавливаются в приоритете. Благодаря этому в начале очереди будут находиться те файлы, которые реально нужны пользователю сейчас, а в её конце – те файлы, которые, возможно, понадобятся в будущем. Но при активной работе пользователя может сформироваться “очередь из внеочередных объектов”, а также список файлов, которые восстанавливаются прямо сейчас. К тому же, операция поиска должна была применяться ко всем этим очередям сразу. Увы, мы не нашли такую реализацию очереди, которая могла бы выставлять несколько приоритетов файлов, при этом поддерживая поиск, а также изменение приоритетов “на лету”. Подстраиваться под существующие структуры данных мы не хотели, и поэтому нам пришлось написать собственную и настроили возможность работы с ней.
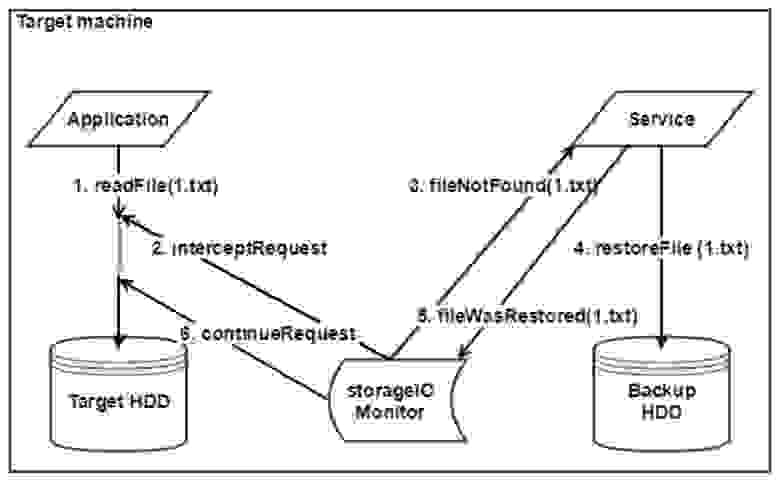
Наш сервис должен будет коммуницировать сначала с драйвером, над которым работал Даулет, а после этого – с компонентами, отвечающий за восстановление файлов… Поэтому для начала мы решили сделать свой небольшой эмулятор системы восстановления, который мог бы выдавать файлы с внешнего диска, чтобы их можно восстанавливать и тестировать сервис.
Всего было предусмотрено два режима работы – нормальный и режим восстановления. В нормальном режиме драйвер отправляет нам список файлов, затронутых при старте ОС. Далее во время работы системы драйвер следит за всеми операциями с файлами и отправляет уведомления нашему сервису, а он в свою очередь изменяет список файлов. В режиме восстановления, драйвер уведомляет сервис, что необходимо восстановление системы. Сервис выстраивает очередь файлов, запускает программных агентов, запрашивающих файлы из бэкапа, и начинает процесс восстановления.
Когда сервис был готов и протестирован, у нас осталась последняя активность по проекту. Необходимо было актуализировать и структурировать все артефакты, что у нас накопились, а также представить свои результаты заказчику и университету. Для компании это стало очередным шагом на пути к реализации проекта, для университета нашей выпускной дипломной работой.
По итогам презентации студентам было сделано предложение. И я уже через несколько недель выхожу на работу в Acronis. Результаты проекта навели разработчиков на мысль, что можно сделать сервис более эффективным, опустив его на уровень Native Windows Application. Но об этом в следующей статье.

Разработка Active Restore началась внутри компании Acronis, но мы, как студенты университета Иннополис, приняли участие в этом процессе в рамках учебного индустриального проекта. О самой идее, а также об архитектуре мой куратор (а теперь и коллега) Даулет Тумбаев уже написал в своем посте. Я же сегодня расскажу о том, как мы готовили сервис со стороны Иннополиса.
Все началось еще летом, когда нам сообщили, что в первом семестре к нам приедут ИТ-компании и будут предлагать свои идеи для практической работы. И вот, в декабре 2018 нам представили 15 разных проектов, и в конце месяца мы расставили приоритеты, разобрались, кому что больше нравится.
Все магистранты заполнили форму, где нужно было выбрать четыре проекта, в которых мы хотели участвовать. Нужно было мотивировать, почему именно я, и почему именно эти проекты. Я, например, указал, что у меня уже есть опыт в системном программировании и разработке на языках C/C++. Но главное, что проект позволял мне развить свои навыки и продолжать рост.
Через две недели нас распределили, и с начала II семестра началась работа над проектами. Команда была сформирована, на первой встрече мы оценили сильные и слабые стороны друг друга и распределили роли.
- Роман Рыбкин — Python/C++ разработчик.
- Евгений Ишутин — Python/C++ разработчик, ответственный за взаимодействие с компанией.
- Анастасия Родионова — Python/C++ разработчик, ответственная за написание документации.
- Брэндон Акоста — настройка окружения, подготовка стенда для экспериментов и тестирования.
Первые две недели нам нужно было запускать процесс. Мы установили контакты с заказчиком, формализовали требования к проекту, запустили итерационный процесс, настроили окружение для работы.
Кстати, работа с заказчиком у нас действительно закипела, когда у нас начались элективы. Дело в том, что Acronis ведет в университете Иннополис (и не только) предметы по выбору. И Алексей Костюшко, ведущий разработчик из Kernel команды, преподает два курса на постоянной основе: Reverse Engineering и Windows Kernel Architecture and Drivers. Насколько я знаю, в будущем планируется также курс по системному программированию и многопоточным вычислениям. Но главное, что все эти курсы построены таким образом, чтобы помочь студентам справиться с индустриальными проектами. Они серьезно прокачивают в понимании предметной области и тем самым упрощают работу над проектом.
За счет этого мы стартовали бодрее других команд, да и само взаимодействие с Acronis стало более плотным. Алексей Костюшко выступал для нас в роли Product Owner, от него мы получали необходимые знания в предметной области. Благодаря его элективам, наши hard-скиллы и компетенции очень сильно прокачались, мы стали действительно готовы выполнить задачу, которая перед нами стояла.
От раздумий к проекту
Первый месяц для всех команд был максимально тяжелым. Все были потерянными, не знали с чего начать – может быть, с документов или, наоборот, нырять в код. От кураторов и менторов в университете и представителей компании первое время приходили противоречивые комментарии.
Когда все встало на свои места (по крайней мере в моей голове), стало понятно, что менторы от университета помогали нам выстроить внутренние отношения в команде, вести подготовку документов. Но реальной точкой прорыва стал приезд Даулета в марте. Мы просто сели и все выходные работали над проектом. Тогда мы переосмыслили суть проекта, перезагрузились, перераспределили приоритеты задач и быстро полетели вперед. Мы поняли, что нужно делать для запуска эксперимента (о нем чуть ниже) и разработки сервиса. С этого момента общее представление превратилось в четкий план. Началась реальная разработка кода, и за 2 недели мы разработали первый вариант тестового стенда, включающий виртуальные машины, необходимые сервисы и код для автоматизации эксперимента и сбора данных.
Стоит отметить, что параллельно с индустриальным проектом шли учебные курсы, которые помогали нам выстроить грамотную архитектуру для своих проектов и организовать Quality Management. Поначалу на эти задачи уходило 70-90% времени в неделю, но, как оказалось, временные затраты были необходимы, чтобы избежать проблем в процессе разработки. Цель университета заключалась в том, чтобы мы научились грамотно выстраивать процесс разработки, а компании, как заказчики, были больше заинтересованы в результате. Это, конечно, вносило немало суматохи, но зато помогло соединить теоретические и практические навыки. Достаточная сложность и нагрузка обеспечили наличие мотивации, что и вылилось в успешный проект.
Изначально два человека в нашей команде занимались чисто разработкой, один человек взял на себя документы, а еще один погрузился в настройку окружения. Однако, позже к нам присоединились еще трое бакалавров, с которыми мы стали единой командой. Университет решил запустить тестовый индустриальный проект для студентов третьего года обучения. Расширение команды с 4 до 7 человек сильно ускорило процесс, потому что наши бакалавры могли легко выполнять задачи, связанные с разработкой. Екатерина Левченко помогала с написанием python кода и batch скриптов для тестового стенда. Ансат Абиров и Руслан Ким выступали в роли разработчиков, они занимались выбором и оптимизацией алгоритмов.
В таком формате мы работали до конца мая, когда был налажен эксперимент. В этот момент закончился индустриальный проект для бакалавров. Двое из них начали стажировку Acronis и продолжили работать с нами. Поэтому после мая мы работали уже как одна команда в составе из 6 человек.
Перед нами был III семестр, который в Иннополисе свободен от академических активностей. У нас было всего 2 электива, а все остальное время уходило на индустриальный проект. Именно в III семестре работа по сервису пошла интенсивно. Процесс разработки полноценно встал на рельсы, демо и отчеты стали регулярными. В таком формате мы проработали 1,5 месяца, и в конце июля практически закончили девелоперскую часть работы.
Технические детали
Сначала были сформулированы требования к сервису, который должен адекватно взаимодействовать с минифильтр-драйвером файловой системы (что это, можно почитать тут) и продумана его архитектура. С прицелом на простоту дальнейшей поддержки кода мы сразу предусмотрели модульный подход. В состав нашего сервиса входит несколько менеджеров, агентов и хендлеров, и еще до начала кодинга была заложена возможность работать параллельном режиме.
Однако, после обсуждения архитектуры на встрече с ребятами из Acronis было принято решение сначала провести эксперимент, а потом уже заняться самим сервисом. В результате на разработку ушло всего 2,5 месяца. Все остальное время мы проводили эксперимент, чтобы найти минимальный достаточный список файлов, на которых можно было бы запустить Windows. В реальной системе данный набор файлов формируется с помощью драйвера, однако, мы решили найти этот сет эвристически, методом половинного деления, чтобы проверить работу драйвера.
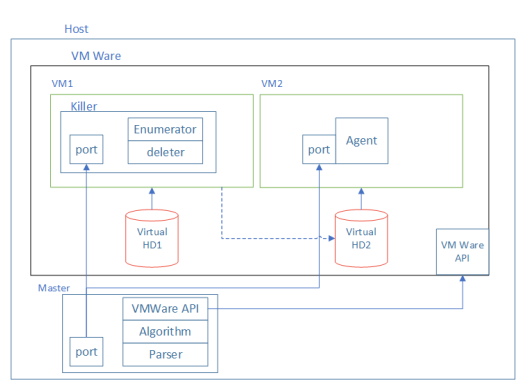
Стенд эксперимента.
Для этого мы собрали стенд на Python из двух виртуальных машин. Одна из них работала на Linux, а вторая загружала Windows. Для них было сконфигурировано два диска: Virtual HD1 и Virtual HD2. Оба диска были подключены к VM1, на которой был установлен Linux. На данной виртуалке на HD1 было установлено приложение Killer, которое “повреждало” HD2. Под повреждением имеется ввиду удаление части файлов с диска. HD2 был загрузочным диском для VM2, которая работало под системой Windows. После “повреждения” диска мы пытались запустить VM2. Если это удавалось сделать, то удаленные с диска файлы относились к ненужным для запуска.
Для того, чтобы автоматизировать этот процесс, мы постарались удалять файлы не случайным образом, а в рамках заранее продуманного подхода. Алгоритм состоял из 3 шагов:
- Поделить список файлов пополам.
- Удалить одну из половин файлов.
- Попытаться запустить систему. Если система запустилась, то добавляем удаленные файлы в список ненужных. В противном случае возвращаемся к шагу 1.
Для начала мы решили промоделировать работу алгоритма. Предположим в файловой системе 1000000 файлов. В таком случае, наиболее эффективно поиск критических файлов происходил в случаях, когда критических файлов было около 15% от общего количества.
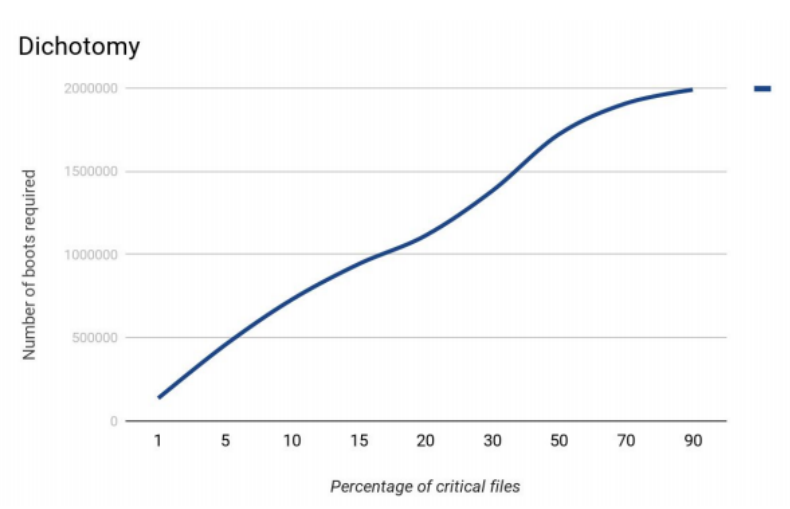
Метод половинного деления.
Сначала проблем с экспериментом было очень много. Недели за 2-3 был готов тестовый стенд. И еще 1-1,5 месяца пришлось ловить баги, дописывать код и применять различные ухищрения, чтобы заставить стенд работать.
Самое сложное было отловить баг, который был связан с кэшированием операций с диском. Эксперимент работал в течение 2 дней и выдал очень оптимистичные результаты, которые в разы опережали симуляции. Однако, тест критических файлов провалился, система не запустилась. Оказалось, что при принудительном выключении виртуальной машины, операции удаления, которые кэшировались файловой системой, не исполнялись, и, соответственно, диск не был полностью очищен. В итоге алгоритм получал неверные результаты, а мы пару дней напрягали все свои извилины, чтобы во всем этом разобраться.
В определенный момент мы заметили, что при продолжительной работе алгоритм закапывался в одном из сегментов файловой системы и начинал попытки удалить одни и те же файлы (в надежде на новый результат). Это случалось в моменты, когда алгоритм упирался в регионы, где большая часть была нужными, при этом выбрав неудачный интервал для удаления. В этот момент мы решили добавить решафл списка файлов. То есть раз в несколько итераций список файлов перемешивался. Это помогло выбивать алгоритм из подобных залипаний.
Когда все было готово, мы запустили эти две ВМ на 3 суток. Всего прошло около 600 итераций, среди которых было больше 20 успешных запусков. Стало ясно, что этот эксперимент можно запустить надолго, а также на более мощных машинах, чтобы найти оптимальный объем файлов для запуска Windows. Также работу алгоритма можно распределить на несколько машин, чтобы еще сильнее ускорить данный процесс
В нашем случае на диске кроме Windows был только Python и наш сервис. За три дня нам удалось сократить количество файлов с 70 тысяч до 50 тысяч. Список файлов был сокращен всего на 28%, но зато стало понятно, что такой подход – рабочий, и он позволяет определить минимальный набор файлов, необходимых для загрузки ОС.
Структура сервиса
Коснемся немного структуры сервиса. Основной модуль сервиса – это менеджер очереди. Поскольку мы получаем список файлов от драйвера, нужно восстанавливать файлы по этому списку. Для этого мы создавали свою очередь с приоритетами.
У нас есть список файлов, которые восстанавливаются по очереди. И если появляются новые запросы на доступ, срочно понадобившиеся файлы восстанавливаются в приоритете. Благодаря этому в начале очереди будут находиться те файлы, которые реально нужны пользователю сейчас, а в её конце – те файлы, которые, возможно, понадобятся в будущем. Но при активной работе пользователя может сформироваться “очередь из внеочередных объектов”, а также список файлов, которые восстанавливаются прямо сейчас. К тому же, операция поиска должна была применяться ко всем этим очередям сразу. Увы, мы не нашли такую реализацию очереди, которая могла бы выставлять несколько приоритетов файлов, при этом поддерживая поиск, а также изменение приоритетов “на лету”. Подстраиваться под существующие структуры данных мы не хотели, и поэтому нам пришлось написать собственную и настроили возможность работы с ней.
Наш сервис должен будет коммуницировать сначала с драйвером, над которым работал Даулет, а после этого – с компонентами, отвечающий за восстановление файлов… Поэтому для начала мы решили сделать свой небольшой эмулятор системы восстановления, который мог бы выдавать файлы с внешнего диска, чтобы их можно восстанавливать и тестировать сервис.
Всего было предусмотрено два режима работы – нормальный и режим восстановления. В нормальном режиме драйвер отправляет нам список файлов, затронутых при старте ОС. Далее во время работы системы драйвер следит за всеми операциями с файлами и отправляет уведомления нашему сервису, а он в свою очередь изменяет список файлов. В режиме восстановления, драйвер уведомляет сервис, что необходимо восстановление системы. Сервис выстраивает очередь файлов, запускает программных агентов, запрашивающих файлы из бэкапа, и начинает процесс восстановления.
Диплом, приглашение на работу и новые проекты
Когда сервис был готов и протестирован, у нас осталась последняя активность по проекту. Необходимо было актуализировать и структурировать все артефакты, что у нас накопились, а также представить свои результаты заказчику и университету. Для компании это стало очередным шагом на пути к реализации проекта, для университета нашей выпускной дипломной работой.
По итогам презентации студентам было сделано предложение. И я уже через несколько недель выхожу на работу в Acronis. Результаты проекта навели разработчиков на мысль, что можно сделать сервис более эффективным, опустив его на уровень Native Windows Application. Но об этом в следующей статье.
