Привет, Хабр! Меня зовут Денис Копырин, и сегодня я хочу рассказать о том, как мы решали проблему бэкапа по требованию на macOS. На самом деле интересная задача, с которой я столкнулся в институте, выросла в итоге в большой исследовательский проект по работе с файловой системой. Все подробности – под катом.

Не буду начинать издалека, скажу только, что началось все с проекта в МФТИ, который я разрабатывал вместе с моим научным руководителем на базовой кафедре Acronis. Перед нами стояла задача организации удаленного хранения файлов, а точнее – поддержки актуального состояния их резервных копий.
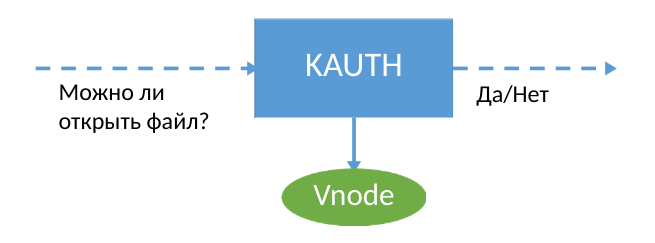
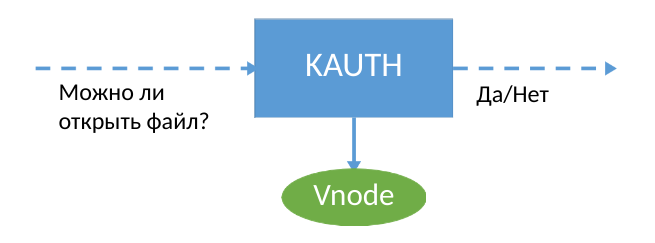
Для обеспечения сохранности данных мы используем расширение ядра macOS, которое собирает информацию о событиях в системе. В KPI для разработчиков имеется интерфейс KAUTH API, который позволяет получать нотификации об открытии и закрытии файла – и только. Если использовать KAUTH, необходимо полностью сохранять файл при открытии на запись, потому что события записи в файл оказываются недоступны разработчикам. Для наших задач такой информации было недостаточно. Ведь чтобы перманентно дополнять резервную копию данных, нужно понимать, куда именно пользователь (или вредонос :) записал новые данные в файл.
Но кого из разработчиков пугали ограничения ОС? Если API ядра не позволяет получить информацию об операциях записи, значит нужно придумать свой способ перехвата через другие средства ядра.
Сначала мы не хотели патчить ядро и его структуры. Вместо этого попробовали создать целый виртуальный том, который позволил бы нам перехватывать все запросы на чтение и запись, проходящие через него. Но при этом выяснилась одна неприятная особенность работы macOS: операционная система считает, что у нее не 1, а 2 USB-флешки, два диска и так далее. И от того, что второй том меняется при работе с первым, macOS начинает некорректно работать с накопителями. Проблем с этим методом оказалось настолько много, что от него пришлось отказаться.
Несмотря на ограничения KAUTH, этот KPI позволяет получить нотификацию об использовании файла для записи еще до всех операций. Разработчикам предоставляется доступ к BSD-абстракции файла в ядре — vnode. Как ни странно, оказалось, что пропатчить vnode проще, чем использовать фильтрацию тома. В структуре vnode имеется таблица функций, которые обеспечивают работу с реальными файлами. Поэтому у нас возникла идея подменить эту таблицу.
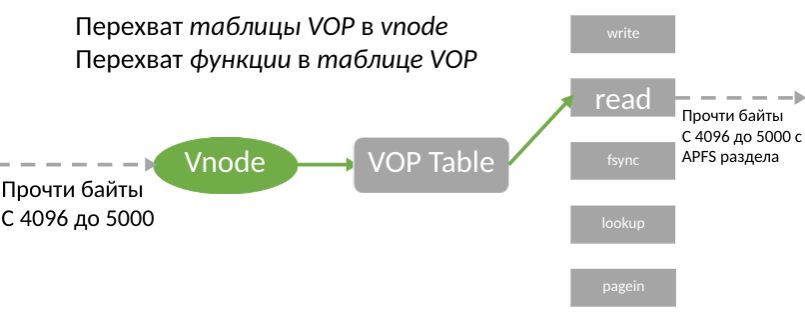
Идею сразу расценили как хорошую, но для ее реализации нужно было найти саму таблицу в структуре vnode, так как Apple нигде не документирует ее расположение. Для этого потребовалось изучить машинный код ядра, а также разобраться, можно ли писать в данный адрес так, чтобы система после этого не умерла.
Если таблица найдена, мы просто копируем ее в память, подменяем указатель и вставляем ссылку на новую таблицу в существующий vnode. Благодаря этому все операции с файлами будут проходить через наш драйвер, и мы сможем регистрировать все запросы пользователя, включая read и write. Поэтому поиск заветной таблицы стал нашей основной целью.
Учитывая, что Apple не очень-то хочет этого, для решения задачи нужно пытаться “угадать” расположение таблицы, используя эвристики для относительного расположения полей, или брать уже известную функцию, дизассемблировать ее и искать смещение из этой информации.
Как искать смещение: простой способ
Простейший способ нахождения смещения таблицы в vnode является эвристика, которая основывается на расположении полей в структуре (ссылка на Github).
Воспользуемся тем предположением, что нужное нам поле v_op удалено ровно на 8 байт от v_mount. Значение последнего можно получить при помощи публичного KPI (ссылка на Github):
Зная значение v_mount, начнем искать “иголку в стоге сена” – будем воспринимать значение указателя на vnode ‘vp’ как uintptr_t*, значение vnode_mount(vp) как uintptr_t. Далее следуют итерации до “разумного” значения i, пока не выполнится условие ‘haystack[i]==needle’. И если предположение о расположении полей верно, смещение v_op равно i-1.
Как искать смещение: дизассемблирование
Несмотря на свою простоту, первый способ обладает существенным недостатком. Если Apple поменяет порядок полей в структуре vnode, простой метод сломается. Более универсальный, но менее тривиальный метод состоит в динамическом дизассемблировании ядра.
Например, рассмотрим дизассемблированную функцию ядра VNOP_CREATE (ссылка на Github) в macOS 10.14.6. Интересные для нас инструкции помечены стрелкой ->.
Будем сканировать ассемблерные инструкции для нахождения сдвига в vnode dvp. “Целью” ассемблерного кода является вызов функции из таблицы v_op. Для этого процессор должен проделать следующие шаги:
Если с шагами 2-4 все ясно, то с первым шагом возникают сложности. Как понять в какой регистр был загружен dvp? Для этого использовался метод эмуляции функции, который наблюдает за перемещениями нужного указателя. Согласно конвенции вызовов System V x86_64, первый аргумент передается в регистре rdi. Поэтому мы решили следить за всеми регистрами, которые содержат rdi. В моем примере это регистры rbx и rdi. Также копия регистра может быть сохранена в стеке, что встречается в debug-версии ядра.
Зная, что регистры rbx и rdi хранят dvp, мы узнаем, что в строке 23 производилось разыменование vnode для получения v_op. Так получаем предположение, что смещение в структуре равно 0xd0. Для подтверждения верного решения продолжаем сканирование и убеждаемся, что функция вызвана корректно (строки 24 и 26).
Данный метод является более безопасным, но, к сожалению, и он обладает недостатками. Нам приходится полагаться на то, что паттерн функции (а именно 4 шага, о которых мы говорили выше) будет таким же. Впрочем, вероятность изменения паттерна функции на порядок меньше, чем вероятность изменения порядка полей. Так что мы решили остановиться на втором методе.
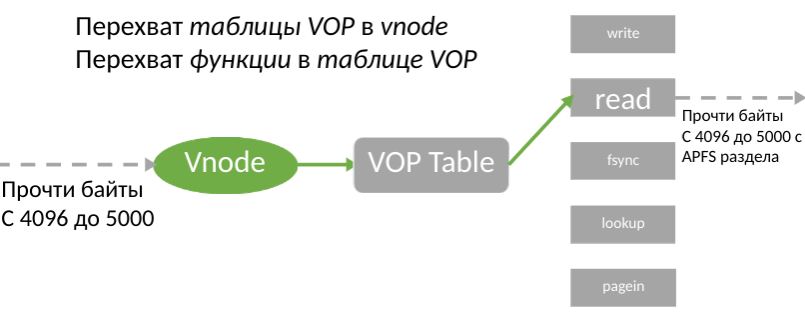
После нахождения v_op возникает вопрос, как использовать этот указатель? Есть два различных способа — перезаписать функцию в таблице (третья стрелка на картинке) или перезаписать таблицу в vnode (вторая стрелка на картинке).
Сначала кажется, что первый вариант выгоднее, ведь нам всего-лишь необходимо подменить один указатель. Однако этого подхода есть 2 существенных недостатка. Во-первых, таблица v_op является одинаковой для всех vnode данной файловой системы (v_op для HFS+, v_op для APFS, …), поэтому нужна фильтрация по vnode, что может быть очень дорого – отсеивать лишние vnode придется на каждой операции записи. Во-вторых, таблица записана на Read-Only странице. Это ограничение можно обойти, если использовать запись через IOMappedWrite64, минуя проверки системы. Также если kext с драйвером файловой системы будет отгружен, то будет сложно понять, как убрать патч.
Второй вариант оказывается более точечным и безопасным – перехватчик будет вызываться только для необходимой vnode, а память vnode изначально разрешает операции Read-Write. Так как производится замена всей таблицы, необходимо выделять чуть больше памяти (80 функций вместо одной). А поскольку количество таблиц обычно равно количеству файловых систем, ограничение по памяти оказывается и вовсе ничтожным.
Именно поэтому в kext используется второй способ, хотя, повторюсь, на первый взгляд кажется, что этот вариант хуже.
В итоге наш драйвер работает по следующей схеме:
На сегодняшний день у нас есть экспериментальный модуль, который является расширением ядра macOS и учитывает любые изменения файловой системы на гранулярном уровне. Стоит отметить, что в macOS 10.15 Apple ввел новый фреймворк (ссылка на EndpointSecurity) для получения нотификаций об изменениях файловой системы, который планируется для использования в Active Protection, поэтому описанное в статье решение объявлено deprecated.

Не буду начинать издалека, скажу только, что началось все с проекта в МФТИ, который я разрабатывал вместе с моим научным руководителем на базовой кафедре Acronis. Перед нами стояла задача организации удаленного хранения файлов, а точнее – поддержки актуального состояния их резервных копий.
Для обеспечения сохранности данных мы используем расширение ядра macOS, которое собирает информацию о событиях в системе. В KPI для разработчиков имеется интерфейс KAUTH API, который позволяет получать нотификации об открытии и закрытии файла – и только. Если использовать KAUTH, необходимо полностью сохранять файл при открытии на запись, потому что события записи в файл оказываются недоступны разработчикам. Для наших задач такой информации было недостаточно. Ведь чтобы перманентно дополнять резервную копию данных, нужно понимать, куда именно пользователь (или вредонос :) записал новые данные в файл.
Но кого из разработчиков пугали ограничения ОС? Если API ядра не позволяет получить информацию об операциях записи, значит нужно придумать свой способ перехвата через другие средства ядра.
Сначала мы не хотели патчить ядро и его структуры. Вместо этого попробовали создать целый виртуальный том, который позволил бы нам перехватывать все запросы на чтение и запись, проходящие через него. Но при этом выяснилась одна неприятная особенность работы macOS: операционная система считает, что у нее не 1, а 2 USB-флешки, два диска и так далее. И от того, что второй том меняется при работе с первым, macOS начинает некорректно работать с накопителями. Проблем с этим методом оказалось настолько много, что от него пришлось отказаться.
Поиск другого решения
Несмотря на ограничения KAUTH, этот KPI позволяет получить нотификацию об использовании файла для записи еще до всех операций. Разработчикам предоставляется доступ к BSD-абстракции файла в ядре — vnode. Как ни странно, оказалось, что пропатчить vnode проще, чем использовать фильтрацию тома. В структуре vnode имеется таблица функций, которые обеспечивают работу с реальными файлами. Поэтому у нас возникла идея подменить эту таблицу.
Идею сразу расценили как хорошую, но для ее реализации нужно было найти саму таблицу в структуре vnode, так как Apple нигде не документирует ее расположение. Для этого потребовалось изучить машинный код ядра, а также разобраться, можно ли писать в данный адрес так, чтобы система после этого не умерла.
Если таблица найдена, мы просто копируем ее в память, подменяем указатель и вставляем ссылку на новую таблицу в существующий vnode. Благодаря этому все операции с файлами будут проходить через наш драйвер, и мы сможем регистрировать все запросы пользователя, включая read и write. Поэтому поиск заветной таблицы стал нашей основной целью.
Учитывая, что Apple не очень-то хочет этого, для решения задачи нужно пытаться “угадать” расположение таблицы, используя эвристики для относительного расположения полей, или брать уже известную функцию, дизассемблировать ее и искать смещение из этой информации.
Как искать смещение: простой способ
Простейший способ нахождения смещения таблицы в vnode является эвристика, которая основывается на расположении полей в структуре (ссылка на Github).
struct vnode
{
...
int (**v_op)(void *); /* vnode operations vector */
mount_t v_mount; /* ptr to vfs we are in */
...
}
Воспользуемся тем предположением, что нужное нам поле v_op удалено ровно на 8 байт от v_mount. Значение последнего можно получить при помощи публичного KPI (ссылка на Github):
mount_t vnode_mount(vnode_t vp);
Зная значение v_mount, начнем искать “иголку в стоге сена” – будем воспринимать значение указателя на vnode ‘vp’ как uintptr_t*, значение vnode_mount(vp) как uintptr_t. Далее следуют итерации до “разумного” значения i, пока не выполнится условие ‘haystack[i]==needle’. И если предположение о расположении полей верно, смещение v_op равно i-1.
void* getVOPPtr(vnode_t vp)
{
auto haystack = (uintptr_t*) vp;
auto needle = (uintptr_t) vnode_mount(vp);
for (int i = 0; i < ATTEMPTCOUNT; i++)
{
if (haystack[i] == needle)
{
return haystack + (i - 1);
}
}
return nullptr;
}
Как искать смещение: дизассемблирование
Несмотря на свою простоту, первый способ обладает существенным недостатком. Если Apple поменяет порядок полей в структуре vnode, простой метод сломается. Более универсальный, но менее тривиальный метод состоит в динамическом дизассемблировании ядра.
Например, рассмотрим дизассемблированную функцию ядра VNOP_CREATE (ссылка на Github) в macOS 10.14.6. Интересные для нас инструкции помечены стрелкой ->.
_VNOP_CREATE:
1 push rbp
2 mov rbp, rsp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 0x48
9 mov r15, r8
10 mov r12, rdx
11 mov r13, rsi
-> 12 mov rbx, rdi
13 lea rax, qword [___stack_chk_guard]
14 mov rax, qword [rax]
15 mov qword [rbp+-48], rax
-> 16 lea rax, qword [_vnop_create_desc] ; _vnop_create_desc
17 mov qword [rbp+-112], rax
18 mov qword [rbp+-104], rdi
19 mov qword [rbp+-96], rsi
20 mov qword [rbp+-88], rdx
21 mov qword [rbp+-80], rcx
22 mov qword [rbp+-72], r8
-> 23 mov rax, qword [rdi+0xd0]
-> 24 movsxd rcx, dword [_vnop_create_desc]
25 lea rdi, qword [rbp+-112]
-> 26 call qword [rax+rcx*8]
27 mov r14d, eax
28 test eax, eax
….errno_t
VNOP_CREATE(vnode_t dvp, vnode_t * vpp, struct componentname * cnp, struct vnode_attr * vap, vfs_context_t ctx)
{
int _err;
struct vnop_create_args a;
a.a_desc = &vnop;_create_desc; a.a_dvp = dvp; a.a_vpp = vpp;
a.a_cnp = cnp; a.a_vap = vap; a.a_context = ctx;
_err = (*dvp->v_op[vnop_create_desc.vdesc_offset])(&a;);
…
Будем сканировать ассемблерные инструкции для нахождения сдвига в vnode dvp. “Целью” ассемблерного кода является вызов функции из таблицы v_op. Для этого процессор должен проделать следующие шаги:
- Загрузить dvp в регистр
- Разыменовать его для получения v_op (строка 23)
- Получить vnop_create_desc.vdesc_offset (строка 24)
- Вызвать функцию (строка 26)
Если с шагами 2-4 все ясно, то с первым шагом возникают сложности. Как понять в какой регистр был загружен dvp? Для этого использовался метод эмуляции функции, который наблюдает за перемещениями нужного указателя. Согласно конвенции вызовов System V x86_64, первый аргумент передается в регистре rdi. Поэтому мы решили следить за всеми регистрами, которые содержат rdi. В моем примере это регистры rbx и rdi. Также копия регистра может быть сохранена в стеке, что встречается в debug-версии ядра.
Зная, что регистры rbx и rdi хранят dvp, мы узнаем, что в строке 23 производилось разыменование vnode для получения v_op. Так получаем предположение, что смещение в структуре равно 0xd0. Для подтверждения верного решения продолжаем сканирование и убеждаемся, что функция вызвана корректно (строки 24 и 26).
Данный метод является более безопасным, но, к сожалению, и он обладает недостатками. Нам приходится полагаться на то, что паттерн функции (а именно 4 шага, о которых мы говорили выше) будет таким же. Впрочем, вероятность изменения паттерна функции на порядок меньше, чем вероятность изменения порядка полей. Так что мы решили остановиться на втором методе.
Подменяем указатели в таблице
После нахождения v_op возникает вопрос, как использовать этот указатель? Есть два различных способа — перезаписать функцию в таблице (третья стрелка на картинке) или перезаписать таблицу в vnode (вторая стрелка на картинке).
Сначала кажется, что первый вариант выгоднее, ведь нам всего-лишь необходимо подменить один указатель. Однако этого подхода есть 2 существенных недостатка. Во-первых, таблица v_op является одинаковой для всех vnode данной файловой системы (v_op для HFS+, v_op для APFS, …), поэтому нужна фильтрация по vnode, что может быть очень дорого – отсеивать лишние vnode придется на каждой операции записи. Во-вторых, таблица записана на Read-Only странице. Это ограничение можно обойти, если использовать запись через IOMappedWrite64, минуя проверки системы. Также если kext с драйвером файловой системы будет отгружен, то будет сложно понять, как убрать патч.
Второй вариант оказывается более точечным и безопасным – перехватчик будет вызываться только для необходимой vnode, а память vnode изначально разрешает операции Read-Write. Так как производится замена всей таблицы, необходимо выделять чуть больше памяти (80 функций вместо одной). А поскольку количество таблиц обычно равно количеству файловых систем, ограничение по памяти оказывается и вовсе ничтожным.
Именно поэтому в kext используется второй способ, хотя, повторюсь, на первый взгляд кажется, что этот вариант хуже.
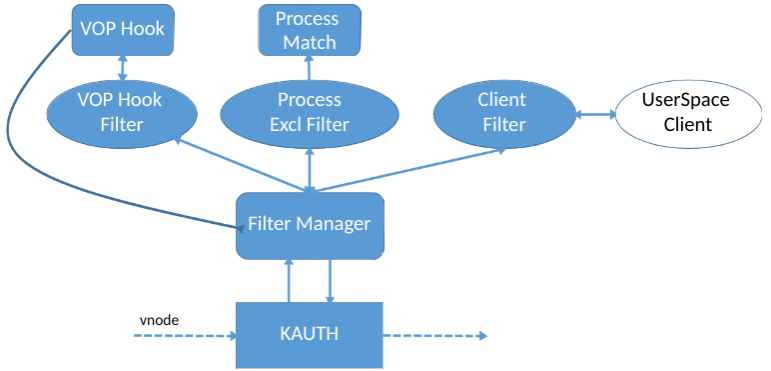
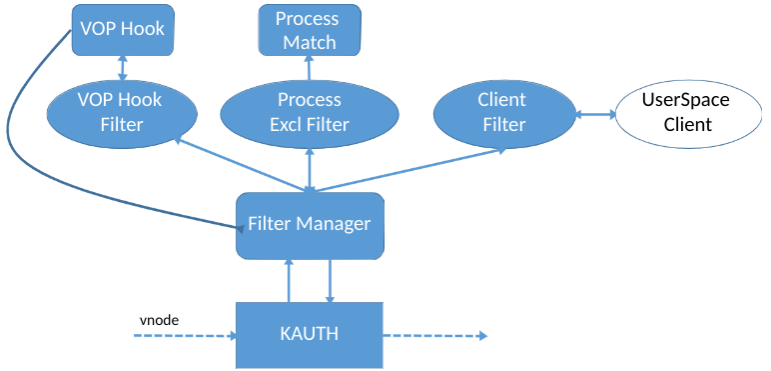
В итоге наш драйвер работает по следующей схеме:
- KAUTH API предоставляет vnode
- Мы производим подмену таблицы vnode. Если требуется, перехватываем операции только для “интересных” vnode, например пользовательских документов
- При перехвате проверяем, какой именно процесс производит запись, отсеиваем “своих”
- Отправляем синхронный запрос UserSpace клиенту, который принимает решение о том, что именно нужно сохранить.
Что получилось
На сегодняшний день у нас есть экспериментальный модуль, который является расширением ядра macOS и учитывает любые изменения файловой системы на гранулярном уровне. Стоит отметить, что в macOS 10.15 Apple ввел новый фреймворк (ссылка на EndpointSecurity) для получения нотификаций об изменениях файловой системы, который планируется для использования в Active Protection, поэтому описанное в статье решение объявлено deprecated.
