
Привет, читатели Хабра! В прошлой статье мы рассказали о простом средстве катастрофоустойчивости в системах хранения AERODISK ENGINE – о репликации. В этой статье мы погрузимся в более сложную и интересную тему – метрокластер, то есть средство автоматизированной защиты от катастроф для двух ЦОД-ов, позволяющее работать ЦОД-ам в режиме active-active. Расскажем, покажем, сломаем и починим.
Как обычно, в начале теория
Метрокластер – это кластер, разнесенный на несколько площадок в пределах города или района. Слово «кластер» нам явно намекает на то, что комплекс автоматизирован, то есть переключение узлов кластера в случае сбоев (failover) происходит автоматически.
Именно тут кроется основное отличие метрокластера от обычной репликации. Автоматизация операций. То есть в случае тех или иных происшествий (отказ ЦОД-а, обрыв каналов и т.п.) система хранения самостоятельно выполнит необходимые действия для того, чтобы сохранить доступность данных. При использовании же обычных реплик эти действия выполняются полностью или частично вручную администратором.
Для чего это нужно?
Основная цель, которую преследуют заказчики, используя те или иные реализации метрокластера – минимизировать RTO (Recovery Time Objective). То есть минимизировать время восстановления ИТ-услуг после сбоя. Если использовать обычную репликацию, то время восстановления будет всегда больше времени восстановления при метрокластере. Почему? Очень просто. Администратор должен быть на рабочем месте и переключить репликацию руками, а метрокластер это делает автоматически.
Если у вас нет выделенного дежурного админа, который не спит, не ест, не курит и не болеет, а 24 часа в сутки смотрит на состояние СХД, то и нет возможности гарантировать, что администратор будет доступен для ручного переключения во время сбоя.
Соответственно RTO в случае отсутствия метрокластера или бессмертного админа 99-ого уровня дежурной службы администраторов будет равным сумме времени переключения всех систем и максимальному промежутку времени, через который администратор гарантированно начнет работать с СХД и смежными системами.
Таким образом приходим к очевидному выводу, что метрокластер нужно использовать в случае, если требование к RTO – минуты, а не часы или дни.То есть, когда в случае самого страшного падения ЦОД-а ИТ-департамент должен обеспечить бизнесу время восстановления доступа к ИТ-услугам в течение минут, а то и секунд.
Как это работает?
На нижнем уровне метрокластер использует механизм синхронной репликации данных, который мы описали в предыдущей статье (см. ссылка). Поскольку репликация синхронная, то и требования к ней соответствующие, а точнее:
- оптоволокно в качестве физики, 10 гигабитный Ethernet (или выше);
- расстояние между ЦОД-ами не более 40 километров;
- задержка канала оптики между ЦОД-ами (между СХД) до 5 миллисекунд (оптимально 2).
Все эти требования носят рекомендательный характер, то есть работать метрокластер будет, даже если эти требования соблюдены не будут, но надо понимать, что последствия несоблюдения этих требований равны замедлению работы обеих СХД в метрокластере.
Итак, для передачи данных между СХД используется синхронная реплика, а каким образом реплики автоматически переключаются и самое главное, как избежать split-brain? Для этого на уровне выше используется дополнительная сущность — арбитр.
Как работает арбитр и в чем его задача?
Арбитр представляет из себя небольшую виртуальную машину, либо аппаратный кластер, который надо запустить на третьей площадке (например, в офисе) и обеспечить доступ к СХД по ICMP и SSH. После запуска арбитру следует установить IP, а потом уже со стороны СХД указать его адрес, плюс адреса удаленных контроллеров, которые участвуют в метрокластере. После этого арбитр готов к работе.
Арбитр выполняет постоянный мониторинг всех СХД в метрокластере и в случае недоступности той или иной системы хранения он, после подтверждения недоступности от ещё одного участника кластера (одной из «живых» СХД), принимает решение о запуске процедуры переключения правил репликации и о маппинге.
Очень важный момент. Арбитр всегда должен находится на площадке, отличной от тех, на которых находятся СХД, то есть ни в ЦОД-е 1, где стоит СХД 1, ни в ЦОД-е 2, где установлена СХД 2.
Почему? Потому что только так арбитр с помощью одной из выживших СХД может однозначно и безошибочно определить падение любой из двух площадок, где установлены СХД. Любые другие способы размещения арбитра, могут привести к split-brain-у.
Теперь погрузимся в детали работы арбитра
На арбитре запущены несколько служб, которые постоянно опрашивают все контроллеры СХД. Если результат опроса отличается от предыдущего (доступен/недоступен), то он записывается в небольшую базу данных, которая работает также на арбитре.
Рассмотрим логику работы арбитра более подробно.
Шаг 1. Определение недоступности. Событием-сигналом об отказе СХД является отсутствие пинга с обоих контроллеров одной СХД в течение 5 секунд.
Шаг 2. Запуск процедуры переключения. После того, как арбитр понял, что одна из СХД недоступна, он отправляет запрос на «живую» СХД с целью удостовериться, что «мертвая» СХД, действительно, умерла.
После получения такой команды от арбитра, вторая (живая) СХД дополнительно проверяет доступность упавшей первой СХД и, если её нет, отправляет арбитру подтверждение его догадки. СХД, действительно, недоступна.
После получения такого подтверждения арбитр запускает удаленную процедуру переключения репликации и поднятия маппинга на тех репликах, которые были активны (primary) на упавшей СХД, и отправляет команду на вторую СХД сделать эти реплики из secondary в primary и поднять маппинг. Ну а вторая СХД, соответственно, эти процедуры выполняет, после чего обеспечивает доступ к потерянным LUN-ам с себя.
Зачем нужна дополнительная проверка? Для кворума. То есть большинство из общего нечетного (3) количества участников кластера должны подтвердить падение одного из узлов кластера. Только тогда это решение будет точно верным. Это нужно для того, чтобы избежать ошибочного переключения и, соответственно, split-brain-а.
Шаг 2 по времени занимает примерно 5 — 10 секунд, таким образом, с учетом времени, необходимого на определение недоступности (5 секунд), в течение 10 – 15 секунд после аварии LUN-ы c упавшей СХД будут автоматически доступны для работы с живой СХД.
Понятное дело, что для того чтобы избежать разрыва соединения с хостами, нужно также позаботиться о корректной настройке тайм-аутов на хостах. Рекомендуемый тайм-аут составляет не менее 30 секунд. Это не даст возможности хосту разорвать соединение с СХД во время переключения нагрузки при аварии и сможет гарантировать отсутствие прерывания ввода-вывода.
Секундочку, получается, если с метрокластером так все хорошо, зачем вообще нужна обычная репликация?
На самом деле все не так-то просто.
Рассмотрим плюсы и минусы метрокластера
Итак, мы поняли, что очевидными плюсами метрокластера по сравнению с обычной репликацией являются:
- Полная автоматизация, обеспечивающая минимальное время восстановления в случае катастрофы;
- И всё :-).
А теперь, внимание, минусы:
- Стоимость решения. Хотя метрокластер в системах Аэродиск не требует дополнительного лицензирования (используется та же лицензия, что и на реплику), стоимость решения будет все равно ещё выше, чем с использованием синхронной репликации. Потребуется реализовать все требования для синхронной реплики, плюс требования для метрокластера, связанные с дополнительной коммутацией и дополнительной площадкой (см. планирование метрокластера);
- Сложность решения. Метрокластер устроен значительно сложнее, чем обычная реплика, и требует значительно больше внимания и трудозатрат на планирование, настройку и документирование.
В итоге. Метрокластер – это, безусловно, очень технологичное и хорошее решение, когда вам реально нужно обеспечить RTO в секунды или минуты. Но если такой задачи нет, и RTO в часы – это для бизнеса ОК, то нет смысла стрелять из пушки по воробьям. Достаточно обычной рабоче-крестьянской репликации, поскольку метрокластер вызовет дополнительные расходы и усложнение ИТ-инфраструктуры.
Планирование метрокластера
Этот раздел не претендует на всеобъемлющее пособие по проектированию метрокластера, а лишь показывает основные направления, которые следует проработать, если вы решили построить подобную систему. Поэтому при реальном внедрении метрокластера обязательно привлекайте для консультаций производителя СХД (то есть нас) и других смежных систем.
Площадки
Как указано выше, для метрокластера необходимо минимум три площадки. Два ЦОД-а, где будут работать СХД и смежные системы, а также третья площадка, где будет работать арбитр.
Рекомендуемой расстояние между ЦОД-ами – не более 40 километров. Большее расстояние с высокой вероятностью вызовет дополнительные задержки, которые в случае метрокластера крайне нежелательны. Напомним, задержки должны быть до 5 миллисекунд, хотя желательно уложиться в 2.
Задержки рекомендуется проверять также в процессе планирования. Любой более или менее взрослый провайдер, предоставляющий оптоволокно между ЦОД-ами, качественную проверку может организовать довольно быстро.
Что касается задержек до арбитра (то есть между третьей площадкой и двумя первыми), то рекомендуемый порог задержек до 200 миллисекунд, то есть подойдет обычное корпоративное VPN-соединение поверх сети Интернет.
Коммутация и сеть
В отличии от схемы с репликацией, где достаточно соединить между собой СХД с разных площадок, схема с метрокластером требует соединения хостов с обеими СХД на разных площадках. Чтобы было понятнее, в чем отличие, обе схемы указаны ниже.
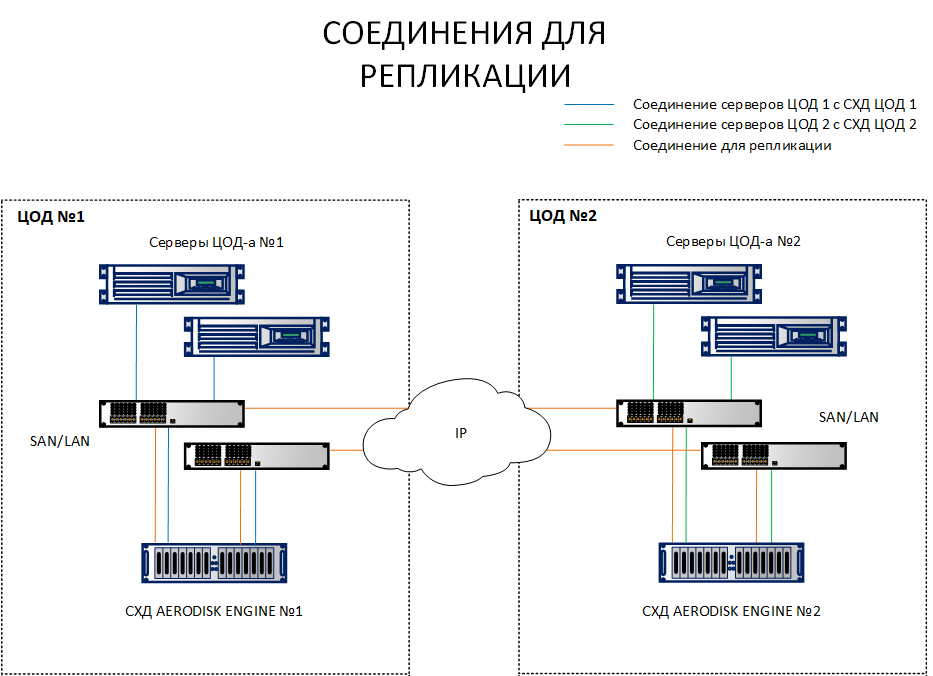

Как видно из схемы, у нас хосты площадки 1 смотрят и на СХД1, и на СХД 2. Также наоборот, хосты площадки 2 смотрят и на СХД 2 и на СХД1. То есть каждый хост видит обе СХД. Это обязательное условие работы метрокластера.
Само собой, нет надобности каждый хост тянуть оптическим шнурком в другой ЦОД, никаких портов и шнурков не хватит. Все эти соединения должны выполнятся через коммутаторы Ethernet 10G+ или FibreChannel 8G+ (FC только для соединения хостов и СХД для IO, канал репликации пока доступен только по IP (Ethernet 10G+).
Теперь пару слов о топологии сети. Важным моментом является правильная конфигурация подсетей. Необходимо сразу определить несколько подсетей для следующих типов трафика:
- Подсеть для репликации, по которой будут синхронизироваться данные между СХД. Их может быть несколько, в данном случае не имеет значения, все зависит от текущей (уже реализованной) топологии сети. Если их две, то, очевидно, должна быть настроена маршрутизация между ними;
- Подсети хранения данных, через которые хосты будут получать доступ к ресурсам СХД (если это iSCSI). Таких подсетей должно быть по одной в каждом ЦОД-е;
- Управляющие подсети, то есть три маршрутизируемые подсети на трех площадках, из которых осуществляется управление СХД, а также там расположен арбитр.
Подсети для доступа к ресурсам хостов мы тут не рассматриваем, поскольку они сильно зависят от задач.
Разделение разного трафика по разным подсетям крайне важно (особенно важно отделить реплику от ввода-вывода), поскольку если смешать весь трафик в одну «толстую» подсеть, то этим трафиком будет невозможно управлять, а в условиях двух ЦОД-ов это ещё может вызвать различные варианты сетевых коллизий. В этот вопрос мы в рамках этой статьи сильно погружаться не будем, поскольку о планировании растянутой между ЦОД-ами сети можно почитать на ресурсах производителей сетевого оборудования, где это очень подробно описано.
Конфигурация арбитра
Арбитру необходимо обеспечить доступ ко всем управляющим интерфейсам СХД по протоколам ICMP и SSH. Также следует подумать об отказоустойчивости арбитра. Тут есть нюанс.
Отказоустойчивость арбитра очень желательна, но необязательна. А что произойдёт, если не вовремя грохнется арбитр?
- Работа метрокластера в штатном режиме не изменится, т.к. арбтир на работу метрокластера в штатном режиме не влияет абсолютно никак (его задача — вовремя переключить нагрузку между ЦОД-ами)
- При этом если арбитр по той или иной причине упадёт и «проспит» аварию в ЦОД-е, то никакого переключения не произойдёт, потому что некому будет отдать нужные команды на переключение и организовать кворум. В этом случае метрокластер превратится в обычную схему с репликацией, которую придется во время катастрофы переключать руками, что повлияет на RTO.
Что из этого следует? Если реально нужно обеспечить минимальный показатель RTO, требуется обеспечить отказоустойчивость арбитра. Для этого есть два варианта:
- Запустить виртуалку с арбитром на отказоустойчивом гипервизоре, благо все взрослые гипервизоры поддерживают отказоустойчивость;
- Если на третьей площадке (в условном офисе)
лень ставить нормальный кластернет существующего кластера гиперивозоров, то мы предусмотрели аппаратный вариант арбитра, который выполнен в коробке 2U, в которой работают два обычных x-86 сервера и который может пережить локальный отказ.
Мы настоятельно рекомендуем обеспечить отказоустойчивость арбитра несмотря на то, что в штатном режиме он метрокластеру не нужен. Но как показывает и теория, и практика, если строить действительно надежную катастрофоустойчивую инфраструктуру, то лучше перестраховаться. Лучше защитить себя и бизнес от «закона подлости», то есть от выхода из строя одновременно и арбитра, и одной из площадок, где стоит СХД.
Архитектура решения
Учитывая требования выше, мы получаем следующую общую архитектуру решения.

LUN-ы следует равномерно распределять по двум площадкам, чтобы избегать сильной перегрузки. При этом при сайзинге в обоих ЦОД-ах следует закладывать не только двойной объем (который необходим для хранения данных одновременно на двух СХД), но и двойную производительность в IOPS и MB/s, чтобы не допускать деградации приложений в условиях отказа одного из ЦОД-ов.
Отдельно отметим, что при должном подходе к сайзингу (то есть, при условии, что мы предусмотрели должные верхние границы IOPS и MB/s, а также необходимые ресурсы CPU и RAM) при отказе одной из СХД в метрокластере не будет серьезной просадки производительности в условиях временной работы на одной СХД.
Это объясняется тем, что в условиях работы одновременно двух площадок, работающая синхронная репликация «съедает» половину производительности при записи, поскольку каждую транзакцию нужно записывать на две СХД (аналогично RAID-1/10). Так, при отказе одной из СХД, влияние репликации временно (пока не поднимется отказавшая СХД) пропадает, и мы получаем двукратный прирост производительности на запись. После того, как LUN-ы отказавшей СХД перезапустились на работающей СХД, этот двукратный прирост пропадает за счёт того, что появляется нагрузка с LUN-ов другой СХД, и мы возвращаемся к тому же уровню производительности, который у нас был до «падения», но только в рамках уже одной площадки.
С помощью грамотного сайзинга можно обеспечить условия, при которых отказ целой СХД пользователи не почувствуют совсем. Но ещё раз повторимся, это требует очень внимательного сайзинга, за которым, кстати, можно бесплатно к нам обратиться :-).
Настройка метрокластера
Настройка метрокластера очень похожа на настройку обычной репликации, которую мы описали в предыдущей статье. Поэтому сосредоточимся только на отличиях. Мы настроили в лаборатории стенд, основанный на архитектуре выше, только в минимальном варианте: две СХД, соединённые по 10G Ethernet между собой, два коммутатора 10G и один хост, который смотрит через коммутаторы на обе СХД портами 10G. Арбитр работает на виртуальной машине.

При настройке виртуальных IP (VIP) для реплики следует выбрать тип VIP – для метрокластера.

Создали две репликационные связи для двух LUN-ов и распределили их по двум СХД: LUN TEST Primary на СХД1 (связь METRO), LUN TEST2 Primary для СХД2 (связь METRO2).

Для них мы настроили два одинаковых таргета (в нашем случае iSCSI, но поддерживается и FC, логика настройки та же).
СХД1:

СХД2:

Для репликационных связей сделали маппинги на каждой СХД.
СХД1:

СХД2:

Настроили multipath и презентовали на хост.


Настраиваем арбитра
С самим арбитром особо делать ничего не надо, его нужно просто включить на третьей площадке, задать ему IP и настроить к нему доступ по ICMP и SSH. Сама же настройка выполняется с самих СХД. При этом настройку арбитра достаточно выполнить один раз на любом из контроллеров СХД в метрокластере, эти настройки будут распространены на все контроллеры автоматически.
В разделе Удаленная репликация>> Метрокластер (на любом контроллере)>> кнопка «Сконфигурировать».
Вводим IP арбитра, а также управляющие интерфейсы двух контроллеров удаленной СХД.

После этого нужно включить все службы (кнопка «Всё перезапустить»). В случае перенастройки в будущем службы нужно обязательно перезапускать, чтобы настройки вступили в силу.

Проверяем, что все службы запущены.

На этом настройка метрокластера завершена.
Краш-тест
Краш-тест в нашем случае будет достаточно простой и быстрый, поскольку функционал репликации (переключение, консистентность и пр.) был рассмотрен в прошлой статье. Поэтому для испытания надежности именно метрокластера нам достаточно проверить автоматизацию обнаружения аварии, переключения и отсутствие потерь при записи (остановки ввода-вывода).
Для этого мы эмулируем полный отказ одной из СХД, физически выключив оба её контроллера, запустив предварительно копирование большого файла на LUN, который должен активироваться на другой СХД.

Отключаем одну СХД. На второй СХД видим алерты и сообщения в логах о том, что пропала связь с соседней системой. Если настроены оповещения по SMTP или SNMP мониторинг, то админу придут соответствующие оповещения.

Ровно через 10 секунд (видно на обоих скриншотах) репликационная связь METRO (та, что была Primary на упавшей СХД) автоматически стала Primary на работающей СХД. Задействовав существующий мапинг, LUN TEST остался доступен хосту, запись немного просела (в пределах обещанных 10 процентов), но не прервалась.


Тест завершен успешно.
Подводим итог
Текущая реализация метрокластера в системах хранения AERODISK Engine N-серии в полной мере позволяет решать задачи, где требуется исключить или минимизировать время простоя ИТ-услуг и обеспечить их работу в режиме 24/7/365 с минимальными трудозатратами.
Можно сказать, конечно, что все это теория, идеальные лабораторные условия и так далее… НО у нас есть ряд реализованных проектов, в которых мы реализовали функционал катастрофоустойчивости, и системы работают отлично. Один из наших довольно известных заказчиков, где используются как раз две СХД в катастрофоустойчивой конфигурации, уже дал согласие на публикацию информации о проекте, поэтому в следующей части мы расскажем о боевом внедрении.
Спасибо, ждем продуктивной дискуссии.
