Мы уже рассказывали вам об интересных статистиках текстов, делали обзор статей применений автокодировщиков в анализе текстов, удивляли нашими свежими алгоритмами поиска переводных заимствований и парафраза. Я решил продолжить нашу корпоративную традицию и, во-первых, начать статью с «Т», а во-вторых, рассказать:

В 2005 году ректор одного из крупных московских вузов пришел к нам в компанию Forecsys за решением очень серьезной проблемы — в учебных заведениях студенты сдавали тотально списанные дипломы и курсовые работы. Мы взяли несколько сотен работ отличников и поискали их в сети простыми запросами. Больше половины«отличников» оказались жуликами, которые скачали диплом из интернета и заменили только титульную страницу. Больше половины отличников, Карл! Что происходило с обычными студентами — сложно даже представить. Проще всего работа искалась по запросу, содержащему слова с «очепятками». Нам стали понятны масштабы бедствия. Надо было срочно что-то решать. Зарубежные англоязычные вузы к тому времени уже пользовались решениями по поиску заимствований, но работы на русском языке почему-то не проверял никто.
Зарубежные игроки не захотели тогда адаптировать свои решения под русский язык. В результате 17 марта 2005 года стартовала разработка первой отечественной системы поиска заимствований. Само слово «Антиплагиат» было придумано чуть позже, а домен antiplagiat.ru зарегистрирован 28 апреля 2005 года. Мы планировали выпустить сайт к 1 сентября 2005 года, но, как это часто бывает с программистами, немного не успели. Официальный день рождения нашей компании — это день, когда antiplagiat.ru принял первых пользователей, а именно 4 сентября. Знаете, я даже этому рад, поскольку во время корпоратива по случаю дня рождения компании все могут спокойно праздновать, а не переживать за первый школьный день у своих детей.
Но что-то я отвлекся. В 2005 году мы создали своеобразный поисковик, в котором, в отличии от Яндекса и Гугла, запросом выступает не два-три слова, а целый текст, состоящий из нескольких предложений. Поэтому разумно использовать «Антиплагиат», если у вас есть текст от 1000 знаков (это примерно полстраницы).
Во время разработки сервиса был сделан прототип на php (web-часть) и Microsoft SQL Server (поисковый движок). Сразу же стало понятно, что это не взлетит и будет медленно работать уже на нескольких миллионах документов. Поэтому пришлось пилить свой поисковый движок. Сейчас система написана на C# и python, использует PostgreSQL и MongoDB (на самом деле много чего еще, но об этом в следующей статье). Поисковый движок у нас по-прежнему полностью собственной разработки.Ставьте лайки Пишите в комментариях, если хотите узнать об истории развития системы, смене процессов работы компании и железе, на котором «Антиплагиат» работал в разные моменты своей жизни, и работает сейчас.
Слово, давшее название компании, сейчас стало уже нарицательным. Часто в поисковике можно встретить такие выражения как «проверить на антиплагиат», «повысить антиплагиат». Все, кто так или иначе связан с областью поиска заимствований в России и ближнем зарубежье, пытаются использовать слово «антиплагиат» для поднятия в поисковой выдаче. Нас часто спрашивают про другие «антиплагиаты». Так вот, «Антиплагиат» — один, это торговая марка и название нашей компании.
В самом начале реализации сервиса поиска заимствований мы решили, что будем работать с текстом как с последовательностью символов. Сразу были отвергнуты различные семантические построения из текстов, поиск смыслов, разбор предложений и т.д. Выбранное нами решение дает два огромных преимущества — высокую скорость поиска и относительно небольшой объем поисковых индексов.
К настоящему моменту есть три продукта в нашей линейке. Они отличаются функциональностью, но содержат в своей основе один и тот же принцип работы поиска заимствований. В этой статье я расскажу о том, как устроен наш классический поиск заимствований — функционал, ставший основой сервиса с самого начала и концептуально не поменявшийся до сих пор. Схема поиска заимствований, как вы видите на изображении, проста и незамысловата, как рисование совы. Сначала мы получаем документ от пользователя, затем мы извлекаем из него текст. Дальше ищем заимствования в этом тексте, получаем «ревизии» (так мы называем отчет по одному модулю поиска) и, наконец, собираем ревизии в один большой отчет, который и показываем в итоге пользователю.
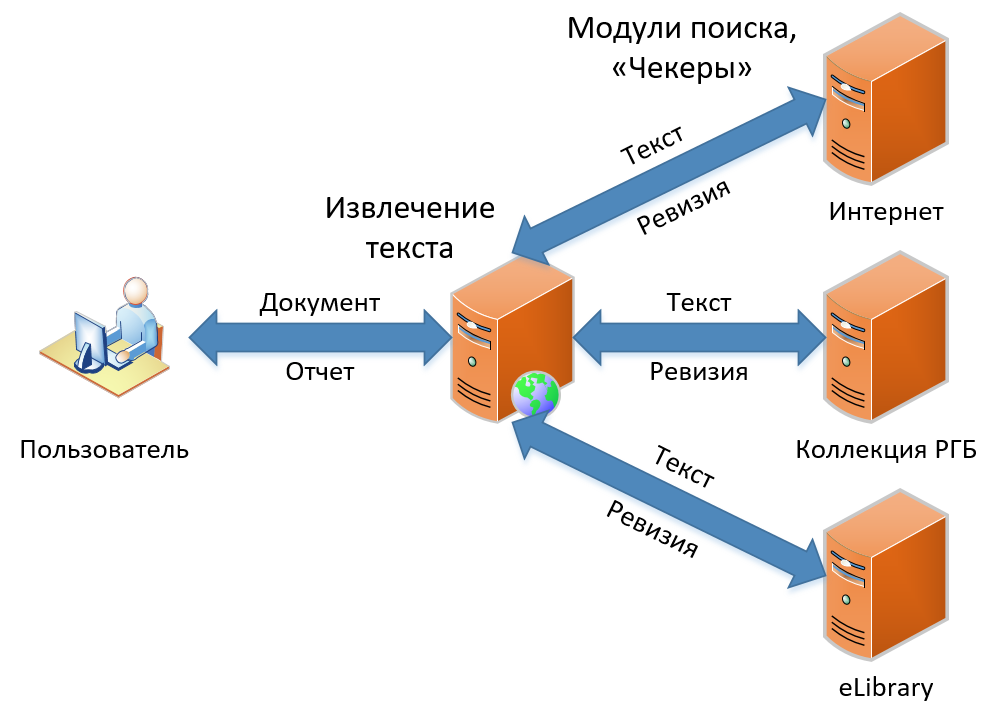
Давайте посмотрим, как все это происходит в деталях.
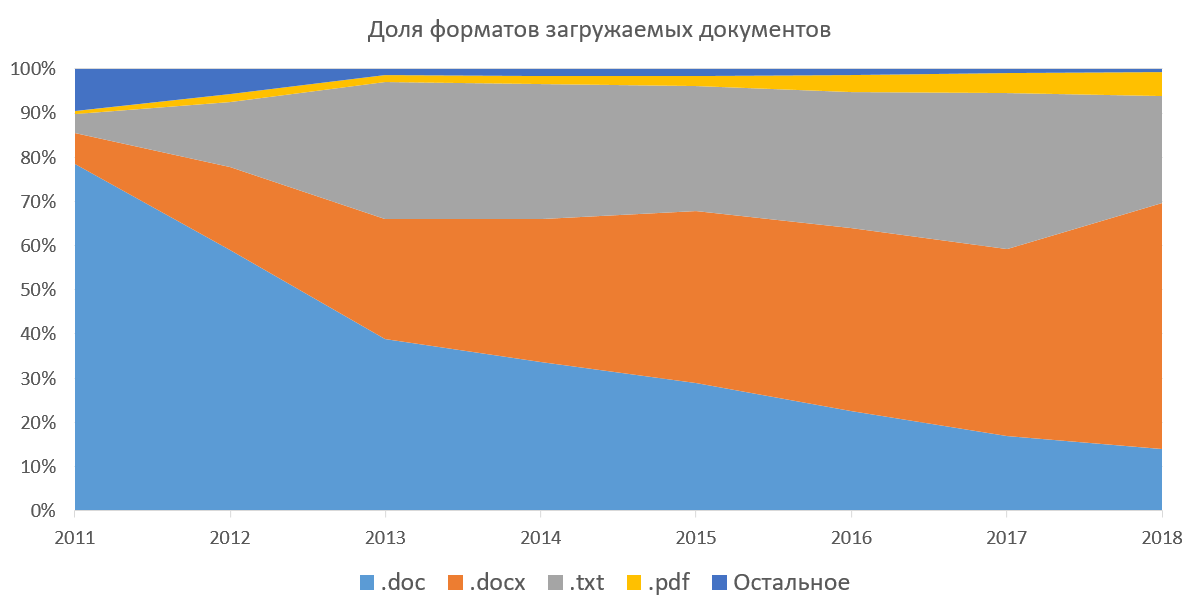
Прежде всего, «Антиплагиат» является сервисом поиска только текстовых заимствований, а значит, из всех документов нам нужно извлечь текст, чтобы дальше с ним работать. Система поддерживает возможность загрузки документов в docx, doc, txt, pdf, rtf, odt, html, pptx и еще нескольких (никогда не использовавшихся) форматах. Также все эти документы вы можете загружать в архивах (7z, zip, rar). Такой способ был популярен, когда у нас не было возможности загружать сразу несколько документов через веб-интерфейс. Ниже приведен график популярности форматов загружаемых документов в корпоративной части нашей системы. На нем видно, как за несколько лет doc вытесняется docx, и постепенно растет доля pdf. Если не рассматривать txt (извлечение текста для него тривиально), то для нас наиболее приятным является pdf. За рубежом pdf является стандартом де-факто, в нем публикуются статьи, готовятся студенческие работы. Согласно нашей статистике, pdf постепенно набирает популярность в России и странах СНГ. Мы и сами продвигаем этот формат в массы, рекомендуя загружать документы именно в нем.
Мы ограничили форматы загрузки документов для частных клиентов до pdf и txt, и именно поэтому сократили потребление ресурсов, уменьшили затраты на поддержку бесплатного сервиса. Вам ведь надо проверить текст, а не протестировать систему? Так какая разница в каком формате его загружать?
Следующим по простоте извлечения текста идет docx, т.к., по сути, это zip-архив с xml внутри, его достаточно просто обрабатывать, и многое можно сделать на низком уровне.
Самым сложным для нас является doc. Этот формат долгое время был закрытым, и сейчас существует куча его реализаций. Последний Microsoft Word, который не поддерживал .docx (пусть и через Microsoft Office Compatibility Pack), выпускался аж 20 лет назад и входил в Microsoft Office 97. Формат использует внутри себя OLE, позже выросшее в COM и ActiveX, все бинарное, местами не совместимое между версиями. В общем, ужасный сон современного программиста. Хорошо, что .doc-формат постепенно сходит со сцены. Думаю, настало время и нам помочь ему выйти на пенсию. Скоро мы станем целенаправленно предупреждать пользователей о том, что этот формат устарел.

Итак, вернемся к отчету. Мы получили файл и начали извлекать текст. Вместе с текстом система извлекает и позиции слов на страницах, чтобы в дальнейшем иметь возможность показывать нашим пользователям разметку отчета о заимствовании на самом документе. Кроме того, на этом же этапе мы ищем технические обходы «Антиплагиата».
Как только появился «Антиплагиат», показывающий процент оригинальности, появились и желающие пройти проверку на заимствование с минимальными усилиями, а также люди, предлагающие такую услугу за деньги. Проблема в том, что числовой параметр так и просится стать оценкой. Ведь это так просто — вместо чтения работы с использованием системы в качестве инструмента, не читать ее, а оценить по проценту оригинальности! Именно эта беда и породила такое направление, как тюнинг работ (изменение в тексте с целью увеличить процент оригинальности работы). Подробнее о проблемах в вузовских процессах читайте в статье «О практике обнаружения заимствований в российских вузах».
В зарубежных системах поиска проблемы обнаружения технических обходов и противодействия им, практически, не стоит. Дело в том, что за обнаруженный «финт ушами» последует очень жесткое наказание — отчисление, и несмываемое пятно на научной репутации, несовместимое с дальнейшей карьерой. У нас же ситуация до комичного проста: «Ой, это система что-то напортачила!», «Ой, это не я, оно само!». Студента скорее всего отправят переделывать. Дело в том, что списать, увы, не является чем-то зазорным.
Но опять отвлекся. Еще одним способом извлечения текста является OCR. Мы печатаем документ на виртуальном принтере, а потом распознаем его. Подробнее об этом написано в статье «Распознавание изображений на службе у «Антиплагиата»».
Теперь немного нашей истории об извлечении текстов. Сначала мы извлекали тексты с помощью IFilter'ов. Они медленные, только под Windows, и не возвращают информацию о форматировании (непонятно, где белый текст на белом фоне, нельзя потом сделать разметку блоков заимствования прямо в документе пользователя). Мы думали, что эти проблемы решатся, если начать использовать платные библиотеки, но и тут обнаружили ограничения: по-прежнему под Windows, не видят формул, иногда падают на специально подготовленных документах (разные библиотеки на разных!). Следующая идея была в том, чтобы OCR'ить все входящие документы, но этот подход очень ресурсозатратен (обработка всего 10-и страниц в минуту на одном ядре), и местами текст извлекается не точно.
Серебряной пули мы не нашли, хотя пару раз думали, что вот оно, Счастье. Однако потом, немного пожив с этим, понимали, что это снова Опыт. Извлечение текста балансирует на тонкой грани между производительностью (надо извлекать текст из сотни документов в минуту), надежностью (надо извлекать текст из всего), функциональностью (форматирование, обходы, вот это вот все). Сейчас у нас работает все вышеперечисленное и еще немножко. Мы постоянно экспериментируем с этой областью и продолжаем искать свое Счастье.
Текст извлечен, обходы найдены и частично устранены, отправляемся искать заимствования!
Идея, реализованная в процедуре поиска, была предложена Ильей Сегаловичем и Юрием Зеленковым (прочитать можно, например, в статье: Сравнительный анализ методов определения нечетких дубликатов для Web-документов). Расскажу, как это работает у нас. Возьмем, для примера, предложение: «Указ Президента РФ от 7 мая 2012 г. N 596 „О долгосрочной государственной экономической политике“».

Теперь для поиска нам нужна магическая функция, которая по такому списку хешей превращает документы, отранжированные по убыванию числа совпавших хешей, в документ-источник. Эта функция должна работать быстро, т.к. мы хотим искать в миллиардах документов. Для того, чтобы быстро находить такой набор, нам нужен обратный индекс, который по хешу возвращает список документов, в которых этот хеш есть. У нас реализована такая гигантская хеш-таблица. В отличии от наших старших братьев-поисковиков, мы храним эту таблицу на ssd, а не в памяти. Нам вполне хватает такой производительности. Поиск по индексу занимает малую часть времени от всего цикла обработки документа. Смотрите как проходит поиск:
Этап 1. Поиск по индексу
Для каждого хеша текста-запроса мы получаем список идентификаторов документов-источников, в которых он встречается. Дальше ранжируем список идентификаторов документов-источников по числу встретившихся хешей из текста-запроса. Получаем ранжированный список документов-кандидатов на источник заимствования.
Этап 2. Построение ревизии
Для большого текста-запроса кандидатов может быть порядка 10 тыс. Это все равно много для сравнения каждого документа с текстом-запросом. Действуем жадно, но решительно. Берем первый документ-источник, делаем сравнение с текстом-запросом и исключаем из всех остальных кандидатов те хеши, которые уже были в этом первом документе. Удаляем из списка кандидатов тех, у которых остался ноль хешей, пересортируем кандидатов по новому числу хешей. Берем первый документ из нового списка, сравниваем с текстом-источником, удаляем хеши, удаляем нулевых кандидатов, пересортируем кандидатов. Делаем так раз 10-20, обычно этого хватает, чтобы список иссяк или в нем остались только те документы, у которых есть совпадение по нескольким хешам.
Использование хешей слов позволяет нам проводить операции сравнения быстрее, экономить на памяти и хранить не тексты документов-источников, а их цифровые слепки (TextSpirit, как мы их ласково называем), полученные при индексации, тем самым не нарушая авторских прав. Выделение конкретных фрагментов заимствования делается с помощью суффиксного дерева.
В результате проверки одним модулем поиска получаем ревизию, в которой находится список источников, их метаданные и координаты блоков заимствований относительно текста-запроса.
Кстати, а что делать, если один из 10-15 модулей не ответил вовремя? Мы ищем по коллекциям РГБ, eLibrary и Гаранта. Эти модули поиска расположены на территории сторонних организаций, и не могут быть перенесены на нашу площадку по соображениям авторского права. Точкой отказа тут всегда может быть канал связи и различные форс-мажоры в дата центрах, не управляемых нами. С одной стороны, заимствование может быть найдено в любом модуле поиска, с другой, если один из компонентов системы недоступен, то можно ухудшить качество поиска, но отдать большую часть результата, предупредив при этом пользователя, что результат по некоторым модулям поиска пока не готов. Какой вариант применили ли бы вы? Мы применяем оба этих варианта в зависимости от обстоятельств.

Наконец, все ревизии получены, начинаем сборку отчета. Здесь используется подход аналогичный подготовке одной ревизии. Вроде бы ничего сложного, но и тут есть интересные задачи. У нас есть заимствования двух типов. Зеленым обозначаются «Цитирования» — корректно оформленные (по ГОСТу) цитаты из модуля «Цитирование», выражения типа «что и требовалось доказать» из модуля «Общеупотребительных выражений», нормативно правовые документы из баз Гаранта и Лекспро. Оранжевым отмечаются все остальные заимствования. Зеленые имеют приоритет над оранжевыми, если только не входят целиком в оранжевый блок.
В результате отчет можно сравнить с лежащим на столе распечатанным на бумаге текстом, поверх которого набросаны разноцветные полоски (блоки заимствований и цитирований), причудливо перекрывающие друг друга. То, что мы видим сверху, и есть отчет. У нас есть два показателя для каждого источника:
Доля в отчете — отношение объема заимствований, которое учитывается из данного источника, к общему объему документа. Если один и тот же текст был найден в нескольких источниках, то учитывается он только в одном из них. При изменении конфигурации отчета (включении или отключении источников) данный показатель источника может меняться. В сумме дает процент заимствований и цитирований (в зависимости от цвета источника).
Доля в тексте — отношение объема, заимствованного из данного источника текста к общему объему документа. Доли в тексте по источникам суммировать нет смысла, легко получится 146% или даже больше. Данный показатель не изменяется при изменении отчета.
Естественно, отчет можно редактировать. Это специальная функция для того, чтобы эксперт, проверяющий работу, отключил заимствования собственных работ автора (при этом может открыться, что данный фрагмент есть не только в собственной работе автора, но и где-то еще) и отдельные блоки заимствования, изменил тип источника с заимствования на цитирование. В результате редактирования отчета эксперт получает реальное значение заимствований. Любую работу для проверки надо прочитать. Это удобно делать, просматривая исходный вид документа, в котором размечены блоки заимствования, и сразу же, по мере прочтения, редактировать отчет. К сожалению, это вполне логичное действие не всеми совершается, многие довольствуются процентом оригинальности, даже не заглядывая в отчет.
Однако вернемся на шаг назад и узнаем, что же попадает в индекс модуля поиска по интернету, созданный Антиплагиатом.
Антиплагиат в значительной степени ориентирован на студенческие работы, научные публикации, выпускные квалификационные работы, диссертации и т.п. Интернет мы индексируем направлено — ищем большие скопления научных текстов, рефератов, статей, диссертаций, научных журналов и т.п. Индексация происходит так:
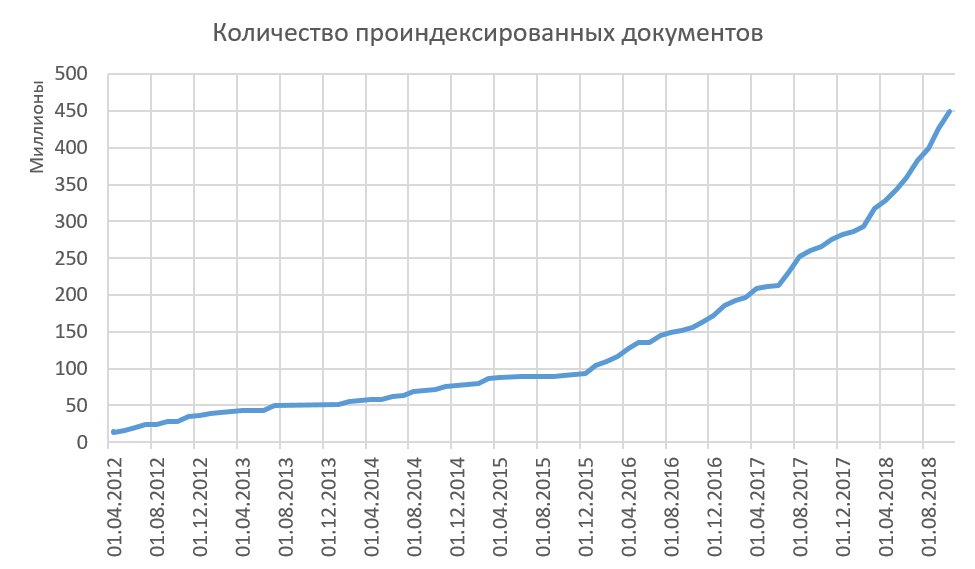
Таким образом мы индексируем качественные тексты, и все проиндексированные тексты у нас существенно различны. Рост объема проиндексированного в интернете показан на рисунке ниже. Сейчас в среднем мы добавляем в индекс по 15-20 млн документов в месяц.

Заметили, что нигде не описана процедура удаления из индекса? А ее и нет! Мы принципиально не удаляем документы из индекса. Мы считаем, что если нам удалось увидеть что-то в интернете, то и другие люди могли видеть этот текст и использовать его тем или иным способом. В связи с этим появляется интересная статистика того, что когда-то было в интернете, а теперь уже больше там нет. Да, представьте себе, выражение «Попавшее в интернет останется там навсегда», — не верно! Что-то исчезает из интернета навсегда. Интересно ли вам узнать о нашей статистике по этому вопросу?
Удивительно, как технические решения, принятые больше 10 лет назад, до сих пор остаются актуальными. Мы сейчас готовим к выпуску 4 версию индекса, она быстрее, технологичнее, лучше, однако в ее основе лежат всё те же решения. Появились новые направления поиска — переводные заимствования, перефразирование, но и там находит применение наш индекс, выполняя пусть и малую, но важную часть работы.
Уважаемые читатели, что вам было бы интересно узнать о нашем сервисе ещё?
- как быстро найти абзац текста среди сотен миллионов статей;
- во что превращается документ после загрузки в систему Антиплагиат, и что с этим делать дальше;
- как формируется отчет, который почти никто не смотрит, а стоило бы;
- как проиндексировать не все, но достаточно.

Как все начиналось
В 2005 году ректор одного из крупных московских вузов пришел к нам в компанию Forecsys за решением очень серьезной проблемы — в учебных заведениях студенты сдавали тотально списанные дипломы и курсовые работы. Мы взяли несколько сотен работ отличников и поискали их в сети простыми запросами. Больше половины
Зарубежные игроки не захотели тогда адаптировать свои решения под русский язык. В результате 17 марта 2005 года стартовала разработка первой отечественной системы поиска заимствований. Само слово «Антиплагиат» было придумано чуть позже, а домен antiplagiat.ru зарегистрирован 28 апреля 2005 года. Мы планировали выпустить сайт к 1 сентября 2005 года, но, как это часто бывает с программистами, немного не успели. Официальный день рождения нашей компании — это день, когда antiplagiat.ru принял первых пользователей, а именно 4 сентября. Знаете, я даже этому рад, поскольку во время корпоратива по случаю дня рождения компании все могут спокойно праздновать, а не переживать за первый школьный день у своих детей.
Но что-то я отвлекся. В 2005 году мы создали своеобразный поисковик, в котором, в отличии от Яндекса и Гугла, запросом выступает не два-три слова, а целый текст, состоящий из нескольких предложений. Поэтому разумно использовать «Антиплагиат», если у вас есть текст от 1000 знаков (это примерно полстраницы).
Во время разработки сервиса был сделан прототип на php (web-часть) и Microsoft SQL Server (поисковый движок). Сразу же стало понятно, что это не взлетит и будет медленно работать уже на нескольких миллионах документов. Поэтому пришлось пилить свой поисковый движок. Сейчас система написана на C# и python, использует PostgreSQL и MongoDB (на самом деле много чего еще, но об этом в следующей статье). Поисковый движок у нас по-прежнему полностью собственной разработки.
Слово, давшее название компании, сейчас стало уже нарицательным. Часто в поисковике можно встретить такие выражения как «проверить на антиплагиат», «повысить антиплагиат». Все, кто так или иначе связан с областью поиска заимствований в России и ближнем зарубежье, пытаются использовать слово «антиплагиат» для поднятия в поисковой выдаче. Нас часто спрашивают про другие «антиплагиаты». Так вот, «Антиплагиат» — один, это торговая марка и название нашей компании.
В самом начале реализации сервиса поиска заимствований мы решили, что будем работать с текстом как с последовательностью символов. Сразу были отвергнуты различные семантические построения из текстов, поиск смыслов, разбор предложений и т.д. Выбранное нами решение дает два огромных преимущества — высокую скорость поиска и относительно небольшой объем поисковых индексов.
К настоящему моменту есть три продукта в нашей линейке. Они отличаются функциональностью, но содержат в своей основе один и тот же принцип работы поиска заимствований. В этой статье я расскажу о том, как устроен наш классический поиск заимствований — функционал, ставший основой сервиса с самого начала и концептуально не поменявшийся до сих пор. Схема поиска заимствований, как вы видите на изображении, проста и незамысловата, как рисование совы. Сначала мы получаем документ от пользователя, затем мы извлекаем из него текст. Дальше ищем заимствования в этом тексте, получаем «ревизии» (так мы называем отчет по одному модулю поиска) и, наконец, собираем ревизии в один большой отчет, который и показываем в итоге пользователю.
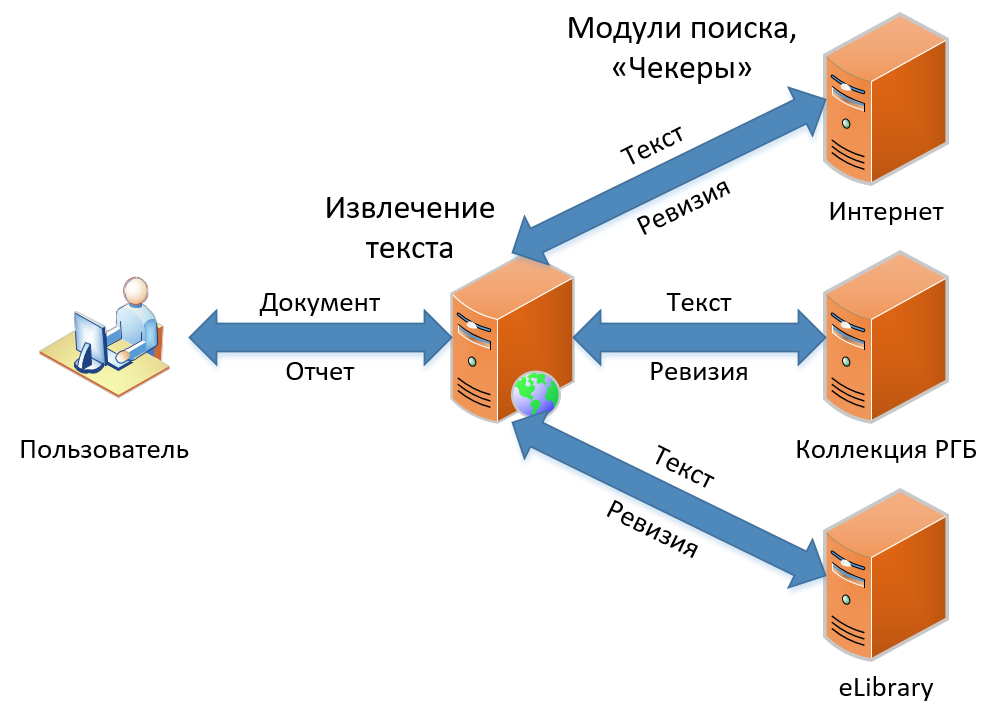
Давайте посмотрим, как все это происходит в деталях.
Извлечение текста
Прежде всего, «Антиплагиат» является сервисом поиска только текстовых заимствований, а значит, из всех документов нам нужно извлечь текст, чтобы дальше с ним работать. Система поддерживает возможность загрузки документов в docx, doc, txt, pdf, rtf, odt, html, pptx и еще нескольких (никогда не использовавшихся) форматах. Также все эти документы вы можете загружать в архивах (7z, zip, rar). Такой способ был популярен, когда у нас не было возможности загружать сразу несколько документов через веб-интерфейс. Ниже приведен график популярности форматов загружаемых документов в корпоративной части нашей системы. На нем видно, как за несколько лет doc вытесняется docx, и постепенно растет доля pdf. Если не рассматривать txt (извлечение текста для него тривиально), то для нас наиболее приятным является pdf. За рубежом pdf является стандартом де-факто, в нем публикуются статьи, готовятся студенческие работы. Согласно нашей статистике, pdf постепенно набирает популярность в России и странах СНГ. Мы и сами продвигаем этот формат в массы, рекомендуя загружать документы именно в нем.
Мы ограничили форматы загрузки документов для частных клиентов до pdf и txt, и именно поэтому сократили потребление ресурсов, уменьшили затраты на поддержку бесплатного сервиса. Вам ведь надо проверить текст, а не протестировать систему? Так какая разница в каком формате его загружать?
Следующим по простоте извлечения текста идет docx, т.к., по сути, это zip-архив с xml внутри, его достаточно просто обрабатывать, и многое можно сделать на низком уровне.
Самым сложным для нас является doc. Этот формат долгое время был закрытым, и сейчас существует куча его реализаций. Последний Microsoft Word, который не поддерживал .docx (пусть и через Microsoft Office Compatibility Pack), выпускался аж 20 лет назад и входил в Microsoft Office 97. Формат использует внутри себя OLE, позже выросшее в COM и ActiveX, все бинарное, местами не совместимое между версиями. В общем, ужасный сон современного программиста. Хорошо, что .doc-формат постепенно сходит со сцены. Думаю, настало время и нам помочь ему выйти на пенсию. Скоро мы станем целенаправленно предупреждать пользователей о том, что этот формат устарел.
Итак, вернемся к отчету. Мы получили файл и начали извлекать текст. Вместе с текстом система извлекает и позиции слов на страницах, чтобы в дальнейшем иметь возможность показывать нашим пользователям разметку отчета о заимствовании на самом документе. Кроме того, на этом же этапе мы ищем технические обходы «Антиплагиата».
Как только появился «Антиплагиат», показывающий процент оригинальности, появились и желающие пройти проверку на заимствование с минимальными усилиями, а также люди, предлагающие такую услугу за деньги. Проблема в том, что числовой параметр так и просится стать оценкой. Ведь это так просто — вместо чтения работы с использованием системы в качестве инструмента, не читать ее, а оценить по проценту оригинальности! Именно эта беда и породила такое направление, как тюнинг работ (изменение в тексте с целью увеличить процент оригинальности работы). Подробнее о проблемах в вузовских процессах читайте в статье «О практике обнаружения заимствований в российских вузах».
В зарубежных системах поиска проблемы обнаружения технических обходов и противодействия им, практически, не стоит. Дело в том, что за обнаруженный «финт ушами» последует очень жесткое наказание — отчисление, и несмываемое пятно на научной репутации, несовместимое с дальнейшей карьерой. У нас же ситуация до комичного проста: «Ой, это система что-то напортачила!», «Ой, это не я, оно само!». Студента скорее всего отправят переделывать. Дело в том, что списать, увы, не является чем-то зазорным.
Но опять отвлекся. Еще одним способом извлечения текста является OCR. Мы печатаем документ на виртуальном принтере, а потом распознаем его. Подробнее об этом написано в статье «Распознавание изображений на службе у «Антиплагиата»».
Теперь немного нашей истории об извлечении текстов. Сначала мы извлекали тексты с помощью IFilter'ов. Они медленные, только под Windows, и не возвращают информацию о форматировании (непонятно, где белый текст на белом фоне, нельзя потом сделать разметку блоков заимствования прямо в документе пользователя). Мы думали, что эти проблемы решатся, если начать использовать платные библиотеки, но и тут обнаружили ограничения: по-прежнему под Windows, не видят формул, иногда падают на специально подготовленных документах (разные библиотеки на разных!). Следующая идея была в том, чтобы OCR'ить все входящие документы, но этот подход очень ресурсозатратен (обработка всего 10-и страниц в минуту на одном ядре), и местами текст извлекается не точно.
Серебряной пули мы не нашли, хотя пару раз думали, что вот оно, Счастье. Однако потом, немного пожив с этим, понимали, что это снова Опыт. Извлечение текста балансирует на тонкой грани между производительностью (надо извлекать текст из сотни документов в минуту), надежностью (надо извлекать текст из всего), функциональностью (форматирование, обходы, вот это вот все). Сейчас у нас работает все вышеперечисленное и еще немножко. Мы постоянно экспериментируем с этой областью и продолжаем искать свое Счастье.
Текст извлечен, обходы найдены и частично устранены, отправляемся искать заимствования!
Поиск заимствований
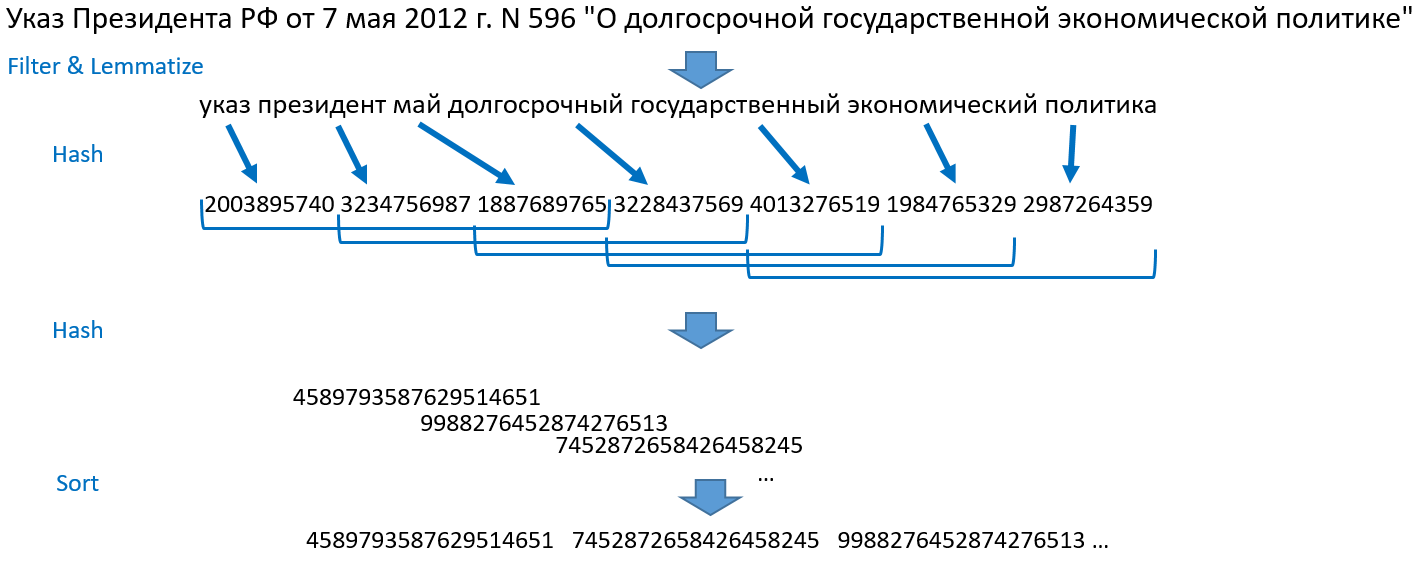
Идея, реализованная в процедуре поиска, была предложена Ильей Сегаловичем и Юрием Зеленковым (прочитать можно, например, в статье: Сравнительный анализ методов определения нечетких дубликатов для Web-документов). Расскажу, как это работает у нас. Возьмем, для примера, предложение: «Указ Президента РФ от 7 мая 2012 г. N 596 „О долгосрочной государственной экономической политике“».
- Разбиваем предложения на слова, выкидываем числа, знаки препинания, стоп-слова. Лемматизируем (приводим в нормальную форму) все слова.
- Превращаем слова в целые числа путем хеширования, получаем массив чисел.
- Берем первую тройку хешей, затем 2, 3, 4-ый хеш, затем 3, 4, 5-ый и так до конца массива хешей. Это и есть шинглы — черепички. Свое название такой способ получил из-за такого черепичного перекрытия наборов. Каждую черепичку сливаем в один объект и хешируем еще раз.
- Сортируем полученные числа, получаем упорядоченный массив целых чисел. Это и есть основа для поиска.
Теперь для поиска нам нужна магическая функция, которая по такому списку хешей превращает документы, отранжированные по убыванию числа совпавших хешей, в документ-источник. Эта функция должна работать быстро, т.к. мы хотим искать в миллиардах документов. Для того, чтобы быстро находить такой набор, нам нужен обратный индекс, который по хешу возвращает список документов, в которых этот хеш есть. У нас реализована такая гигантская хеш-таблица. В отличии от наших старших братьев-поисковиков, мы храним эту таблицу на ssd, а не в памяти. Нам вполне хватает такой производительности. Поиск по индексу занимает малую часть времени от всего цикла обработки документа. Смотрите как проходит поиск:
Этап 1. Поиск по индексу
Для каждого хеша текста-запроса мы получаем список идентификаторов документов-источников, в которых он встречается. Дальше ранжируем список идентификаторов документов-источников по числу встретившихся хешей из текста-запроса. Получаем ранжированный список документов-кандидатов на источник заимствования.
Этап 2. Построение ревизии
Для большого текста-запроса кандидатов может быть порядка 10 тыс. Это все равно много для сравнения каждого документа с текстом-запросом. Действуем жадно, но решительно. Берем первый документ-источник, делаем сравнение с текстом-запросом и исключаем из всех остальных кандидатов те хеши, которые уже были в этом первом документе. Удаляем из списка кандидатов тех, у которых остался ноль хешей, пересортируем кандидатов по новому числу хешей. Берем первый документ из нового списка, сравниваем с текстом-источником, удаляем хеши, удаляем нулевых кандидатов, пересортируем кандидатов. Делаем так раз 10-20, обычно этого хватает, чтобы список иссяк или в нем остались только те документы, у которых есть совпадение по нескольким хешам.
Использование хешей слов позволяет нам проводить операции сравнения быстрее, экономить на памяти и хранить не тексты документов-источников, а их цифровые слепки (TextSpirit, как мы их ласково называем), полученные при индексации, тем самым не нарушая авторских прав. Выделение конкретных фрагментов заимствования делается с помощью суффиксного дерева.
В результате проверки одним модулем поиска получаем ревизию, в которой находится список источников, их метаданные и координаты блоков заимствований относительно текста-запроса.
Сборка отчета
Кстати, а что делать, если один из 10-15 модулей не ответил вовремя? Мы ищем по коллекциям РГБ, eLibrary и Гаранта. Эти модули поиска расположены на территории сторонних организаций, и не могут быть перенесены на нашу площадку по соображениям авторского права. Точкой отказа тут всегда может быть канал связи и различные форс-мажоры в дата центрах, не управляемых нами. С одной стороны, заимствование может быть найдено в любом модуле поиска, с другой, если один из компонентов системы недоступен, то можно ухудшить качество поиска, но отдать большую часть результата, предупредив при этом пользователя, что результат по некоторым модулям поиска пока не готов. Какой вариант применили ли бы вы? Мы применяем оба этих варианта в зависимости от обстоятельств.

Наконец, все ревизии получены, начинаем сборку отчета. Здесь используется подход аналогичный подготовке одной ревизии. Вроде бы ничего сложного, но и тут есть интересные задачи. У нас есть заимствования двух типов. Зеленым обозначаются «Цитирования» — корректно оформленные (по ГОСТу) цитаты из модуля «Цитирование», выражения типа «что и требовалось доказать» из модуля «Общеупотребительных выражений», нормативно правовые документы из баз Гаранта и Лекспро. Оранжевым отмечаются все остальные заимствования. Зеленые имеют приоритет над оранжевыми, если только не входят целиком в оранжевый блок.
В результате отчет можно сравнить с лежащим на столе распечатанным на бумаге текстом, поверх которого набросаны разноцветные полоски (блоки заимствований и цитирований), причудливо перекрывающие друг друга. То, что мы видим сверху, и есть отчет. У нас есть два показателя для каждого источника:
Доля в отчете — отношение объема заимствований, которое учитывается из данного источника, к общему объему документа. Если один и тот же текст был найден в нескольких источниках, то учитывается он только в одном из них. При изменении конфигурации отчета (включении или отключении источников) данный показатель источника может меняться. В сумме дает процент заимствований и цитирований (в зависимости от цвета источника).
Доля в тексте — отношение объема, заимствованного из данного источника текста к общему объему документа. Доли в тексте по источникам суммировать нет смысла, легко получится 146% или даже больше. Данный показатель не изменяется при изменении отчета.
Естественно, отчет можно редактировать. Это специальная функция для того, чтобы эксперт, проверяющий работу, отключил заимствования собственных работ автора (при этом может открыться, что данный фрагмент есть не только в собственной работе автора, но и где-то еще) и отдельные блоки заимствования, изменил тип источника с заимствования на цитирование. В результате редактирования отчета эксперт получает реальное значение заимствований. Любую работу для проверки надо прочитать. Это удобно делать, просматривая исходный вид документа, в котором размечены блоки заимствования, и сразу же, по мере прочтения, редактировать отчет. К сожалению, это вполне логичное действие не всеми совершается, многие довольствуются процентом оригинальности, даже не заглядывая в отчет.
Однако вернемся на шаг назад и узнаем, что же попадает в индекс модуля поиска по интернету, созданный Антиплагиатом.
Индексация интернета
Антиплагиат в значительной степени ориентирован на студенческие работы, научные публикации, выпускные квалификационные работы, диссертации и т.п. Интернет мы индексируем направлено — ищем большие скопления научных текстов, рефератов, статей, диссертаций, научных журналов и т.п. Индексация происходит так:
- Наш робот приходит, представляется и, руководствуясь robots.txt (у нас хороший робот), загружает документы с разумной нагрузкой на каждый хост (в работе одновременно сотни сайтов, поэтому мы можем и подождать некоторое время между загрузками страниц);
- Робот передает документ и его метаданные в очередь на обработку, из документа извлекается текст;
- Текст анализируется на «качество» — как вы помните из статьи про свалку, мы умеем определять жанр документа, добавляем сюда простые эвристики на объем и понимаем, годный текст к нам пришел или какая-то белиберда;
- Качественный текст проходит дальше и превращается в хеши. Хеши и метаданные отправляются в основной индекс интернета;
- Мы сравниваем пришедший текст с ранее проиндексированными нами текстами. Новичок добавляется, только если он реально новый, т.е. 90% его хешей не содержится целиком в каком-то другом уже проиндексированном тексте. Если же документ уже есть у нас, мы добавляем url этого документа в атрибуты нашего архива.
Таким образом мы индексируем качественные тексты, и все проиндексированные тексты у нас существенно различны. Рост объема проиндексированного в интернете показан на рисунке ниже. Сейчас в среднем мы добавляем в индекс по 15-20 млн документов в месяц.
Заметили, что нигде не описана процедура удаления из индекса? А ее и нет! Мы принципиально не удаляем документы из индекса. Мы считаем, что если нам удалось увидеть что-то в интернете, то и другие люди могли видеть этот текст и использовать его тем или иным способом. В связи с этим появляется интересная статистика того, что когда-то было в интернете, а теперь уже больше там нет. Да, представьте себе, выражение «Попавшее в интернет останется там навсегда», — не верно! Что-то исчезает из интернета навсегда. Интересно ли вам узнать о нашей статистике по этому вопросу?
Заключение
Удивительно, как технические решения, принятые больше 10 лет назад, до сих пор остаются актуальными. Мы сейчас готовим к выпуску 4 версию индекса, она быстрее, технологичнее, лучше, однако в ее основе лежат всё те же решения. Появились новые направления поиска — переводные заимствования, перефразирование, но и там находит применение наш индекс, выполняя пусть и малую, но важную часть работы.
Уважаемые читатели, что вам было бы интересно узнать о нашем сервисе ещё?
