
Источник изображения:www.nikonsmallworld.com
Антиплагиат – это специализированный поисковик, о чем уже писали ранее. А любому поисковику, как ни крути, чтобы работать быстро, нужен свой индекс, который учитывает все особенности области поиска. В своей первой статье на Хабре я расскажу о текущей реализации нашего поискового индекса, истории его развития и причинах выбора того или иного решения. Эффективные алгоритмы на .NET — это не миф, а жесткая и продуктивная реальность. Мы погрузимся в мир хеширования, побитового сжатия и многоуровневых кешей с приоритетами. Что делать, если нужен поиск быстрее, чем за O(1)?
Если кто-то еще не знает, где на этой картинке шинглы, добро пожаловать…
Шинглы, индекс и зачем их искать
Шингл — это кусочек текста, размером в несколько слов. Шинглы идут внахлёст друг за другом, отсюда и название (англ., shingles — чешуйки, черепички). Конкретный их размер — секрет Полишинеля — 4 слова. Или 5? Well, it depends. Впрочем, даже эта величина мало что даёт и зависит от состава стоп-слов, алгоритма нормализации слов и прочих подробностей, которые в рамках настоящей статьи не существенны. В конце концов, мы вычисляем на основании этого шингла 64-битный хэш, который в дальнейшем и будем называть шинглом.
По тексту документа можно сформировать множество шинглов, число которых сопоставимо с числом слов в документе:
text:string → shingles:uint64[]
При совпадении нескольких шинглов у двух документов будем считать, что документы пересекаются. Чем больше шинглов совпадает, тем больше одинакового текста в этой паре документов. Индекс занимается поиском документов, обладающих наибольшим количеством пересечений с проверяемым документом.

Источник изображения:Википедия
Индекс шинглов позволяет выполнять две основные операции:
Индексировать в себе шинглы документов с их идентификаторами:
index.Add(docId, shingles)
Искать в себе и выдавать ранжированный список идентификаторов пересекающихся документов:
index.Search(shingles) → (docId, score)[]
Алгоритм ранжирования, я считаю, достоин вообще отдельной статьи, поэтому мы о нем здесь писать не будем.
Индекс шинглов сильно отличается от известных полнотекстовых собратьев, таких как Sphinx, Elastic или более крупных: Google, Yandex и т.д… С одной стороны, он не требует никакого NLP и прочих радостей жизни. Вся текстовая обработка вынесена наружу и не влияет на процесс, как и порядок следования шинглов в тексте. С другой — поисковым запросом является не слово или фраза из нескольких слов, а до нескольких сотен тысяч хэшей, которые имеют значение все в совокупности, а не по отдельности.
Гипотетически можно использовать полнотекстовый индекс как замену индексу шинглов, но различия слишком велики. Проще всего задействовать какое-нибудь известное key-value-хранилище, об этом будет упоминание ниже. Мы же пилим свою велосипед реализацию, которая так и называется — ShingleIndex.
Для чего нам так заморачиваться? А вот зачем.
- Объёмы:
- Документов много. Сейчас их у нас порядка 650 млн., и в этом году их явно будет больше;
- Число уникальных шинглов растет как на дрожжах и уже достигает сотен миллиардов. Ждём триллиона.
- Скорость:
- За сутки, во время летней сессии, по системе «Антиплагиат» проверяют более 300 тыс. документов. Это немного по меркам популярных поисковиков, но держит в тонусе;
- Для успешной проверки документов на уникальность число проиндексированных документов должно быть на порядки больше проверяемых. Текущая версия нашего индекса в среднем может наполняться на скорости более чем 4000 средних документов в секунду.
И это всё на одной машине! Да, мы умеем реплицировать, постепенно подходим к динамическому шардингу на кластер, но с 2005 года и по сей день индекс на одной машине при бережном уходе способен справляться со всеми вышеперечисленными трудностями.
Странный опыт
Однако это сейчас мы такие опытные. Как ни крути, но мы тоже взрослели и по ходу роста пробовали разные штуки, о которых сейчас забавно вспоминать.
Источник изображения:Википедия
Первым делом неискушённый читатель захотел бы задействовать SQL-базу данных. Не вы одни так думаете, SQL-реализация исправно служила нам несколько лет для реализации очень маленьких коллекций. Тем не менее нацеленность была сразу на миллионы документов, так что пришлось идти дальше.
Велосипеды, как известно, никто не любит, а LevelDB ещё не была достоянием общественности, так что в 2010 году взор наш пал на BerkeleyDB. Все круто — персистентная встраиваемая key-value-база с подходящими методами доступа btree и hash и многолетней историей. Всё с ней было замечательно, но:
- В случае hash-реализации при достижении объёма в 2ГБ она просто падала. Да, мы тогда ещё работали в 32-битном режиме;
- B+tree-реализация работала стабильно, но при объёмах более нескольких гигабайт скорость поиска начинала значительно падать.
Придется признать, что мы так и не нашли способа подстроить её под нашу задачу. Может быть, проблема в .net-биндингах, которые ещё приходилось допиливать. BDB реализация в итоге использовалась как замена SQL в качестве промежуточного индекса перед заливкой в основной.
Время шло. В 2014 году пробовали LMDB и LevelDB, но не внедряли. Ребята из нашего Отдела исследований в Антиплагиате в качестве индекса задействовали для своих нужд RocksDB. На первый взгляд, это была находка. Но медленное пополнение и посредственная скорость поиска даже на небольших объёмах свела всё на нет.
Все вышеперечисленное мы делали, параллельно развивая свой собственный кастомный индекс. В итоге он стал настолько хорош в решении наших задач, что мы отказались от предыдущих «затычек» и сосредоточились на его совершенствовании, который сейчас у нас и используется в продакшене повсеместно.
Слои индекса
В итоге что мы сейчас имеем? Фактически, индекс шинглов представляет собой несколько слоёв (массивов) с элементами постоянной длины — от 0 до 128 бит, — которая зависит не только от слоя и не обязательно кратна восьми.
Каждый из слоёв играет определённую роль. Какой-то делает поиск быстрее, какой-то экономит место, а какой-то никогда не используется, но очень нужен. Мы попробуем их описать в порядке увеличения их суммарной эффективности при поиске.

Источник изображения:Википедия
1. Массив индекса
Без потери общности будем сейчас считать, что документу ставится в соответствие единственный шингл,
(docId → shingle)
Поменяем элементы пары местами (инвертируем, ведь индекс-то на самом деле «инвертированный»!),
(shingle → docId)
Отсортируем по значениям шинглов и сформируем слой. Т.к. размеры шингла и идентификатора документа постоянны, то теперь любой, кто понимает бинарный поиск, сможет найти пару за O(logn) чтений файла. Что много, чертовски много. Но это лучше, чем просто O(n).
Если шинглов у документа несколько, то таких пар от документа тоже будет несколько. Если существует несколько документов с одинаковыми шинглами, то это тоже мало чего изменит — будет несколько идущих подряд пар с одинаковым шинглом. В этих обоих случаях поиск будет идти за сопоставимое время.
2. Массив групп
Аккуратно разобьём элементы индекса из предыдущего шага на группы любым удобным образом. Например, чтобы они влезали в сектор кластер блок allocation unit (читай, 4096 байт) с учётом числа бит и прочих хитростей и сформируем эффективный словарь. У нас получится простой массив позиций таких групп:
group_map(hash(shingle)) → group_position.
При поиске шингла будем теперь сначала искать позицию группы по этому словарю, а затем выгружать группу и искать прямо в памяти. Вся операция требует два чтения.
Словарь позиций групп занимает на несколько порядков меньше места, чем сам индекс, его часто можно просто выгрузить в память. Тем самым чтений будет не два, а одно. Итого, O(1).
3. Фильтр Блума
На собеседованиях кандидаты часто решают задачки, выдавая уникальные решения с O(n^2) или даже O(2^n). Но мы глупостями не занимаемся. Есть ли O(0) на свете, вот в чём вопрос? Давайте попробуем без особой надежды на результат...
Обратимся к предметной области. Если студент молодец и написал работу сам, либо просто там не текст, а белиберда, то значительная часть его шинглов будет уникальна и в индексе встречаться не будет. В мире отлично известна такая структура данных как фильтр Блума. Перед поиском проверим шингл по нему. Если шингла в индексе нет, дальше можно не искать, в ином случае идём дальше.
Сам по себе фильтр Блума достаточно прост, но задействовать вектор хэш-функций при наших объёмах бессмысленно. Достаточно использовать одну: +1 чтение из фильтра Блума. Это даёт -1 или -2 чтений из последующих стадий, в случае если шингл уникальный, и в фильтре не было ложноположительного срабатывания. Следите за руками!
Вероятность ошибки фильтра Блума задаётся при построении, вероятность неизвестного шингла определяется честностью студента. Несложными расчётами можно прийти к следующей зависимости:
- Если мы будем доверять честности людей (т.е.по факту документ оригинален), то скорость поиска уменьшится;
- Если документ явно стыренный, то возрастет скорость поиска, но нам потребуется много памяти.
С доверием к студентам у нас действует принцип «доверяй, но проверяй», и практика показывает, что профит от фильтра Блума всё-таки есть.
С учётом того, что эта структура данных также меньше самого индекса и может быть закэширована, то в лучшем случае она позволяет отбрасывать шингл вообще без обращений к диску.
4. Тяжёлые хвосты
Есть шинглы, которые встречаются почти везде. Доля их от общего числа мизерная, но, при построении индекса на первом шаге, на втором могут получиться группы размером в десятки и сотни МБ. Запомним их отдельно и будем сразу выбрасывать из поискового запроса.
Когда впервые в 2011 году задействовали этот тривиальный шаг, размер индекса сократился вдвое, ускорен был и сам поиск.
5. Прочие хвосты
Даже несмотря на это, на шингл может приходиться много документов. И это нормально. Десятки, сотни, тысячи… Хранить их внутри основного индекса становится накладно, в группу они тоже могут не влезть, от этого объём словаря позиций групп раздувается. Вынесем их в отдельную последовательность с более эффективным хранением. Как показывает статистика, такое решение более чем оправдано. Тем более что различные побитовые упаковки позволяют и количество обращений к диску снизить, и объём индекса уменьшить.
В итоге для удобства обслуживания запечатаем все эти слои в один большой файл — chunk. Всего слоёв в нём таких десять. Но часть не используется при поиске, часть совсем небольшие и всегда хранятся в памяти, часть активно кэшируются по мере необходимости/возможности.
В бою чаще всего поиск шингла сводится к одному-двум случайным чтений файла. В худшем случае приходится делать три. Все слои — суть эффективно (иногда побитово-) упакованные массивы элементов постоянной длины. Такая вот нормализация. Время на распаковку незначительно в сравнении с ценой итогового объёма при хранении и возможностью получше прокэшировать.
При построении размеры слоёв преимущественно вычисляются заранее, пишутся последовательно, так что процедура эта достаточно быстрая.
Как пришли туда, не знали куда
С двойным угрызением совести в 2010 году почитывал на форуме заявления недовольных студентов о том, что мы слишком часто пополняем индекс и они не могут найти подходящий сайт с левыми рефератами. Суть была в том, что основной индекс полноценно не обновлялся уже как пару лет. К счастью, руки дошли и до этой проблемы.
Источник изображения:Википедия
Изначально индекс у нас состоял из двух частей — постоянной, описанной выше, и временной, в роли которой выступал либо SQL, либо BDB, либо свой журнал обновлений. Эпизодически, например, раз в месяц (а иногда и год), временный сортировался, фильтровался и сливался с основным. В результате получался объединённый, а два старых удалялись. Если временный не мог влезть в оперативную память, то процедура шла через внешнюю сортировку.
Процедура эта была довольно хлопотная, запускалась в полу-ручном режиме и требовала фактического переписывания всего файла индекса с нуля. Перезапись сотни гигабайт ради пары миллионов документов – ну так себе удовольствие, скажу я вам…
Это были времена первых и довольно дорогих SSD. До сих пор в дрожь берёт от воспоминаний, как 31 декабря отвалился единственный SSD на продакшене и судорожно пришлось в новогоднюю ночь писать wcf-балансировщик и распределять нагрузку на наши девелоперские машины. Пот схлынул, но балансировщик тот до сих пор жив и отлично работает. Впрочем, мы отвлеклись.Чтобы и SSD не особо напрягался, и индекс актуализировался почаще, в 2012 году задействовали цепочку из нескольких кусков, chunk'ов по следующей схеме:

Здесь индекс состоит из цепочки однотипных чанков, кроме самого первого. Первый, addon, представлял из себя append-only-журнал с индексом в оперативной памяти. Последующие chunk'и увеличивались в размере (и в возрасте) вплоть до самого последнего (нулевого, основного, корневого, ...).
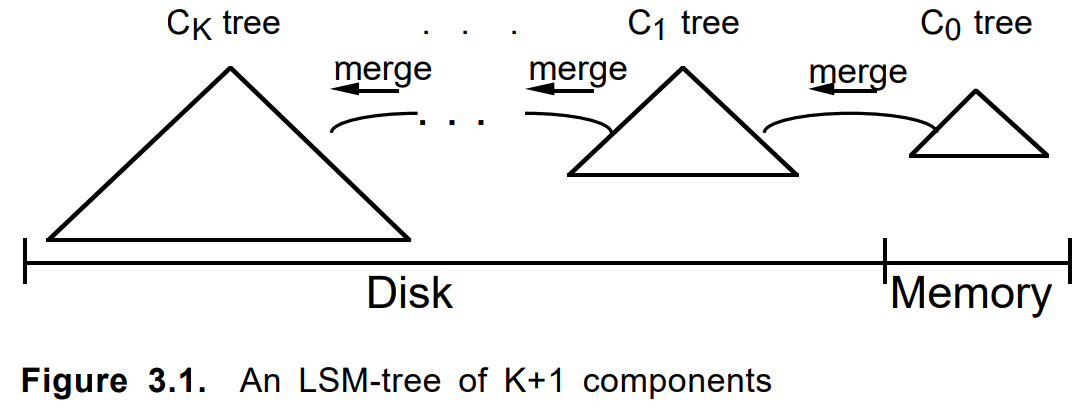
При добавлении документ сначала складывался в аддон. При его переполнении либо по иным критериям по нему строился постоянный чанк. Соседние несколько чанков при необходимости сливались в новый, а исходные удалялись. Обновление документа или его удаление отрабатывались аналогично.
Критерии слияния, длина цепочки, алгоритм обхода, учёт удаленных элементов и обновлений, прочие параметры тюнились. Сам подход был задействован ещё в нескольких схожих задачах и оформился в виде отдельного внутреннего LSM-фреймворка на чистом .net'е. Примерно в то же время вышел в свет и стал популярным LevelDB.
У алгоритма LSM в нашем случае есть очень подходящие черты:
- мгновенная вставка/удаление/обновление,
- сниженная нагрузка на SSD при актуализации,
- упрощенный формат чанков,
- выборочный поиск только по старым/новым чанкам,
- тривиальный бэкап,
- чего еще душе угодно.
- ...
Вообще, велосипеды иногда и для саморазвития изобретать полезно.
Макро-, микро-, нано-оптимизации
Ну и напоследок поделимся техническими советами, как мы в Антиплагиате делаем такие штуки на .Net'е (и не только на нём).
Заметим заранее, что часто всё очень сильно зависит от вашего конкретного железа, данных или режима использования. Подкрутив в одном месте, мы вылетаем из кэша CPU, в другом — упрёмся в пропускную способность SATA-интерфейса, в третьем — начнём зависать в GC. А где-то и вовсе в неэффективность реализации конкретного системного вызова.

Источник изображения:Википедия
Работа с файлом
Проблема с доступом к файлу у нас не уникальна. Есть терабайтный экзабайтный большой файл, объём которого во много раз превышает объём оперативной памяти. Задача — прочесть разбросанный по нему миллион каких-то небольших случайных значений. Причём делать это быстро, качественно и недорого. Приходится ужиматься, бенчмаркать и много думать.
Начнём с простого. Чтобы прочитать заветный, байт нужно:
- Открыть файл (new FileStream);
- Переместиться на нужную позицию (Position или Seek, без разницы);
- Прочитать нужный массив байт (Read);
- Закрыть файл (Dispose).
И это плохо, потому что долго и муторно. Путем проб, ошибок и многократного наступания на грабли мы выявили следующий алгоритм действий:
Single open, multiple read
Если эту последовательность делать в лоб, на каждый запрос к диску, то мы очень быстро загнемся. Каждый из этих пунктов уходит в запрос к ядру OS, что накладно.
Очевидно, следует один раз открыть файл и последовательно вычитывать с него все миллионы наших значений, что мы и делаем
Nothing Extra
Получение размера файла, текущей позиции в нём — также достаточно тяжёлые операции. Даже если файл не менялся.
Следует избегать любых запросов типа получения размера файла или текущей позиции в нём.
FileStreamPool
Далее. Увы, FileStream по сути однопоточен. Если вы хотите читать файл параллельно, придётся создавать/закрывать новые файловые потоки.
Пока не создадут что-то типа aiosync, придётся изобретать собственные велосипеды.
Мой совет – создайте пул файловых потоков на файл. Это позволит избежать траты времени на открытие/закрытие файла. А если его объединить с ThreadPool и учесть, что SSD выдаёт свои мегаIOPS'ы при сильной многопоточности… Ну вы меня поняли.
Allocation unit
Далее. Устройства хранения данных (HDD, SSD, Optane) и файловая система оперируют файлами на уровне блоков (cluster, sector, allocation unit). Они могут не совпадать, но сейчас это почти всегда 4096 байт. Чтение одного-двух байтов на границе двух таких блоков в SSD происходит примерно в полтора раза медленнее, чем внутри самого блока.
Следует организовывать свои данные так, чтобы вычитываемые элементы были в рамках границ
кластера сектораблока.No buffer.
Далее. FileStream по умолчанию использует буфер размером в 4096 байт. И есть плохая новость — его нельзя выключить. Тем не менее, если вы читаете данных больше, чем размер буфера, то последний будет в игноре.
При случайном чтении следует выставить буфер в 1 байт (меньше не получится) и далее считать, что тот не используется.
Use buffer.
Кроме случайных чтений, есть ещё и последовательные. Здесь буфер уже может стать полезным, если вы не хотите вычитывать всё разом. Советую для начала обратиться к этой статье. Какой размер буфера выставить, зависит от того, находится ли файл на HDD или на SSD. В первом случае оптимальным будет 1MB, во втором будет достаточно стандартных 4kB. Если размер вычитываемой области данных сравним с этими значениями, то лучше её вычитать разом, пропустив буфер, как и в случае случайного чтения. Буферы больших размеров не будут приносить профита по скорости, но начнут бить по GC.
При последовательном чтении больших кусков файла следует выставить буфер в 1MB для HDD и 4kB для SSD. Well, it depends.
MMF vs FileStream
В 2011 году пришла наводка на MemoryMappedFile, благо этот механизм был реализован начиная с .Net Framework v4.0. Сначала задействовали его при кэшировании фильтра Блума, что уже доставляло неудобств в 32-битном режиме из-за ограничения в 4ГБ. Но при переходе в мир 64-х бит захотелось ещё. Первые тесты впечатляли. Бесплатное кэширование, чумовая скорость, удобный интерфейс чтения структур. Но были и проблемы:
- Во-первых, как ни странно, скорость. Если данные уже прокэшированы, то всё ок. Но если нет — чтение одного байта из файла сопровождалось «поднятием наверх» намного большего количества данных, чем это было бы при обычном чтении.
- Во-вторых, как ни странно, память. При разогреве shared-память растёт, workingset — нет, что логично. Но далее соседние процессы начинают вести себя не очень хорошо. Могут уйти в своп, либо непроизвольно упасть от OoM. Объём, занимаемый MMF в оперативной памяти, увы, контролировать невозможно. А профит от кэша в случае, когда сам читаемый файл на пару порядков больше памяти, становится бессмысленным.
Со второй проблемой ещё можно было бы бороться. Она исчезает, если индекс работает в докере либо на выделенной виртуалке. Но вот проблема скорости была фатальной.
В итоге от MMF отказались чуть более, чем полностью. Кэширование в Антиплагиате стали делать в явном виде, по возможности удерживая в памяти наиболее часто используемые слои при заданных приоритетах и лимитах.

Источник изображения:Википедия
Bits/Bytes
Не байтами мир един. Иногда нужно снизойти до уровня бита.
Для примера: представим, что у вас триллион частично упорядоченных чисел, жаждущих сохранения и частого чтения. Как со всем этим работать?
- Простой BinaryWriter.Write? — быстро, но медленно. Размер все-таки имеет значение. Холодное чтение в первую очередь зависит от размера файла.
- Очередная вариация VarInt? — быстро, но медленно. Постоянство имеет значение. Объём начинает зависеть от данных, что требует дополнительной памяти для позиционирования.
- Побитовая упаковка? — быстро, но медленно. Приходится ещё тщательнее контролировать свои руки.
Идеального решения нет, но в конкретном случае простое сжатие диапазона с 32-х бит до необходимого хранить хвосты сэкономило на 12% больше (десятки ГБ!), чем VarInt (с сохранением только разницы соседних, само собой), а тот — в разы от базового варианта.
Другой пример. У вас в файле есть ссылка на некоторый массив чисел. Ссылка 64-битная, файл на терабайт. Всё вроде ок. Иногда чисел в массиве много, иногда мало. Часто мало. Очень часто. Тогда просто берём и храним весь массив в самой ссылке. Profit. Упаковать аккуратно только не забудьте.
Struct, unsafe, batching, micro-opts
Ну и прочие микрооптимизации. Я здесь не буду писать про банальные «стоит ли сохранять Length массива в цикле» или «что быстрее, for или foreach».
Есть два простых правила, и мы им будем придерживаться: 1. «бенчмаркай всё», 2. «больше бенчмаркай».
Struct. Используются повсеместно. Не грузят GC. И, как это модно нынче бывает, у нас тоже есть свой мегабыстрый ValueList.
Unsafe. Позволяет мапить (и размапить) структуры в массив байт при использовании. Тем самым нам не нужны отдельные средства сериализации. Есть, правда, вопросы к пинингу и дефрагментации кучи, но пока не проявлялось. Well, it depends.
Batching. Работать с множеством элементов следует через пачки/группы/блоки. Читать/писать файл, передавать между функциями. Отдельный вопрос — размер этих пачек. Обычно есть оптимум, и его размер часто находится в диапазоне от 1kB до 8MB (размер кэша CPU, размер кластера, размер страницы, размер чего-то ещё). Попробуйте прокачать через функцию IEnumerable<byte> или IEnumerable<byte[1024]> и прочувствуйте разницу.
Pooling. Каждый раз, когда вы пишите «new», где-то умирает котёнок. Разок new byte[85000] — и трактор проехался по тонне гусей. Если нет возможности задействовать stackalloc, то создайте пул каких-либо объектов и переиспользуйте его заново.
Inlining. Как созданием двух функций вместо одной можно ускорить всё в десять раз? Просто. Чем меньше размер тела функции (метода), тем больше шансов, что он будет заинлайнен. К сожалению, в мире dotnet пока нет возможности делать частичный инлайнинг, так что если у вас есть горячая функция, которая в 99% случаях выходит после обработки первых нескольких строк, а остальная сотня строк идёт на обработку оставшегося 1%, то смело разбивайте её на две (или три), вынося тяжёлый хвост в отдельную функцию.
What else?
Span<T>, Memory<T> — многообещающе. Код будет проще и, может быть, чуть быстрее. Ждём релиза .Net Core v3.0 и Std v2.1, чтобы на них перейти, т.к. наше ядро на .Net Std v2.0, которое спаны нормально не поддерживает.
Async/await — пока неоднозначно. Простейшие бенчмарки случайного чтения показали, что действительно потребление CPU падает, но вот скорость чтения также снижается. Надо смотреть. Внутри индекса пока не используем.
Заключение
Надеюсь, мне удалость доставить вам удовольствие от понимания красоты некоторых решений. Нам действительно очень нравится наш индекс. Он эффективен, красив кодом, отлично работает. Узкоспециализированное решение в ядре системы, критическом месте ее работы лучше, чем общее. Наша система контроля версий помнит ассемблерные вставки в С++ код. Теперь плюсов четыре — только чистый C#, только .Net. На нем мы пишем даже самые сложные алгоритмы поиска и ничуть не жалеем об этом. С появлением .Net Core, переход на Docker путь к светлому DevOps-будущему стал проще и яснее. Впереди — решение задачи динамической шардизации и репликации без снижения эффективности и красоты решения.
Спасибо всем, кто дочитал до конца. Обо всех очепятках и прочих нестыковках просьба писать комментарии. Буду рад любым обоснованным советам и опровержениям в комментариях.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}