Всем привет! Я руковожу «Наносемантикой», сегодня хотел бы поделиться с вами результатами нашего сравнения сервисов ASR на русском языке. Мы подготовили датасет, проанализировали результаты работы систем распознавания речи разных вендоров, собрали в одной статье основные выводы.
Почему мы решили сделать сравнение?
Как для разработчиков, так и для конечных пользователей важно, насколько качественной будет система распознавания речи, и насколько эффективно она будет реализована в том или ином устройстве или приложении. Голосовой канал вносит шумы распознавания, а это влияет на работу систем классификации и анализа текстов (например, классификаторы интентов, NER, системы коррекции орфографии и пунктуации). Исследование помогает как нам самим, так и другим компаниям понять, какие есть уязвимые места в системе, что стоит подтянуть и доработать.
В этой статье мы расскажем, как по метрикам CER и WER мы оценивали качество распознавания речи различных вендоров.
Про CER и WER, если вдруг кто-то забыл или не знал
Для начала рассмотрим расчёт каждой из метрик для одного распознавания:
CER — частота ошибок в символах
WER — частота ошибок в словах
Оба метода используют расстояние Левенштейна — это метод оценки разницы между двумя строками, который учитывает количество вставок, удалений и замен в одной из строк относительно другой. WER использует его на уровне слов, CER — на уровне символов. То есть на вход оба метода получают по две строки: распознавание вендора и исходная строка, она же референс.
Формула расчёта:
WER = (S+D+I)/N = (S+D+I)/(S+D+C), где:
S — количество замен
D — количество удалений
I — количество вставок
C — количество корректных слов
N — количество слов в исходной строке
Формула для CER точно такая же, но вместо слов используются символы. При этом, при подсчёте CER мы НЕ считаем пробелы.
Для каждого тестового датасета в итоге принято считать 4 величины:
Average CER, sum of relationships — средняя частота ошибок в символах, сумма отношений
Average WER, sum of relationships — средняя частота ошибок в словах, сумма отношений
Average CER, relationship of sums — средняя частота ошибок в символах, отношение сумм
Average WER, relationship of sums — средняя частота ошибок в словах, отношение сумм (сортировка и присвоение мест вендоров в табличках ниже в статье производилась именно по этому параметру)
Рассмотрим на примере формулы для WER, потому как для CER они будут точно такие же, но на символьном уровне.
Если m — количество элементов (аудиозаписей) в датасете, то:
Average WER, sum of relationships = ((S1 + D1 + I1)/N1 + … + (Sm + Dm + Im)/Nm)/m
Average WER, relationship of sums = (S1+… + Sm + D1+… + Dm + I1 + … Im)/(N1 + … Nm)
Как мы собирали тестовый датасет
В тестовом датасете есть две категории данных:
Телефония
Микрофоны пользовательских устройств
Данные телефонных звонков мы брали у колл-центров, а живую речь собирали с помощью бота VoicyBot, который предоставляет пользователям мессенджера «Телеграм» возможность распознавания голосовых сообщений в текст с помощью бота. Мы договорились с VoicyBot, и они согласились включить наш сервис по распознаванию речи в список тех, кого можно выбрать при установке бота. В итоге мы начали получать поток живой речи.
Разумеется, в указанных случаях пользователей предупреждают, что их данные могут быть использованы поставщиком сервиса.
В данных телефонии и микрофонов пользовательских устройств есть подкатегории мужских и женских голосов, каждая из которых, в свою очередь, делится на короткие (менее 5 слов), средние (от 5 до 10 слов) и длинные записи (более 10 слов). В общей сложности мы собрали примерно по 180-200 образцов записей на каждую категорию.
Мы старались сделать каждую категорию максимально «сбалансированной»: вручную отобрали множество записей, чтобы в датасет в итоге вошли наиболее нейтральные — не затрагивающие профессиональные и специфические темы и не содержащие несловарные слова.
Датасет размечен вручную с перепроверкой несколькими разметчиками.
Язык датасета – русский.
Ни одна запись из тестового датасета не использовалась для обучения наших нейросетей и не публиковалась в опенсорс: хотелось сделать аккуратный замер качества ASR.
С кем мы сравнивали наши 4 модели
В рамках бенчмарка мы рассмотрели 17 систем у 14 разных вендоров и сравнили их с четырьмя моделями «Наносемантики» — две из них обучены на данных телефонии (одна из них имеет обновлённую языковую модель – ashmanov_8_2), а две другие – на живой речи с девайсов (аналогично, одна из них имеет обновлённую LM – ashmanov_16_2).
Кто попал в наше сравнение:
ЦРТ (Центр речевых технологий) - crt (в табличках)
Азур (Microsoft) - azure
Яндекс - yandex
Google - google
Тинькофф - tinkoff
3iTech (3i VOX) - vox_telephony
Wit.ai - wit
Amazon - amazon
Alpha Cephei - alpha_cephei
Silero (в бенчмарках модель https://www.silero.ai/silero-ee-v012-release/) - silero
Сбер - sber_media, sber_general и sber_cc_and_ivr
VOSK - vosk
Как сравнивали?
После того, как мы собрали образцы записей для каждой категории, мы разметили их с помощью нашей платформы для сбора и разметки датасетов NLab Marker и прогнали аудио через все указанные сервисы.
В процессе тестирования бенчмарков оказалось, что некоторые вендоры не могут корректно обработать всю нашу выборку (стабильно возвращались пустые ответы, либо ответы, содержащие латинские символы). Поэтому мы сделали 2 исследования. Первое – на тех данных, которые смогли корректно обработать все вендоры. Во втором исследовании статистика каждого вендора считалась на тех данных, которые именно он смог корректно обработать.
После мы составили бенчмарки — таблички со сравнением WER и CER. Также мы решили считать погрешностью отрыв не более чем в 1% Average WER (relationship of sums) – этим можно пренебречь. Поэтому получилось, что одно и то же место делят сразу несколько вендоров. При этом, места раздавались только лучшим моделям от вендоров (чтобы выявить именно лучших вендоров).
Приводим часть таблиц, чтобы не перегружать статью.
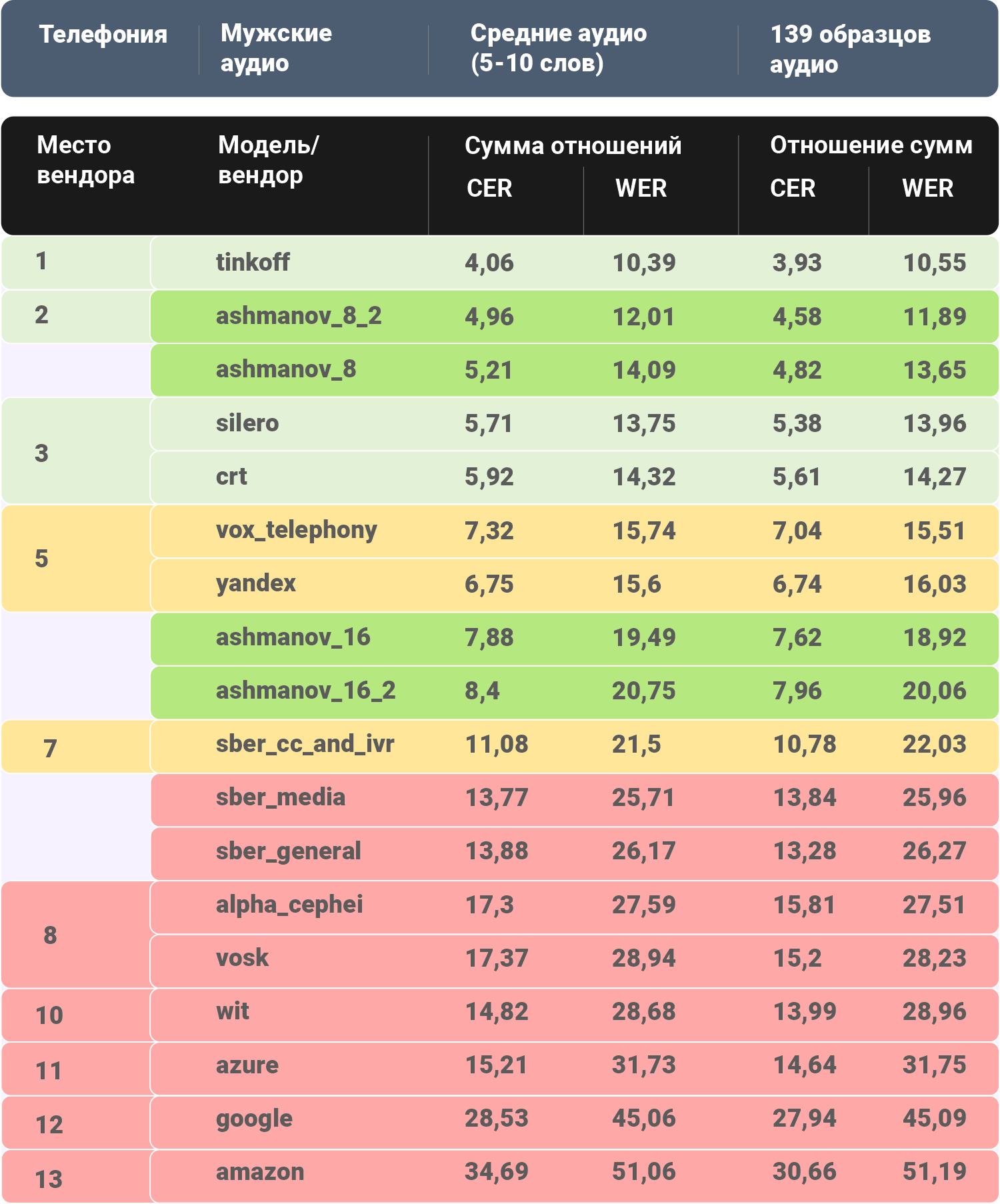
Какие получились результаты (сортировка по крайнему правому столбцу)
Исследование №1 (статистика вендоров только на тех данных, которые смогли корректно обработать все вендоры без исключения)




Медальный зачёт:

Исследование №2 (статистика каждого вендора только на тех данных, которые смог корректно обработать именно рассматриваемый вендор)





Медальный зачёт:

Выводы
Итого:

Как видно из результатов, наша система распознавания речи получила уверенное первое и второе место по всем параметрам:) Разберём чуть подробнее.
Исследование №1 (статистика вендоров только на тех данных, которые смогли корректно обработать все вендоры без исключения)
Телефония
В 5 из 6 категорий первое место занимает/делит система Тинькофф. На средних по длине женских аудио она заняла второе место (после нашего решения). Наши модели в 3 категориях делят первое место с Тинькофф, в мужских средних занимают второе место (отставание от лидера 1.34%), а в женских коротких аудио делят второе место с Яндексом (отставание от лидера 1.79%). Наш отрыв от 2-3 мест составляет в среднем 2.3%. При этом Average CER у нас стабильно на первых местах (периодически делим его с тем же Тинькофф). Это, кстати, означает, что нам нужно улучшить нашу языковую модель. Четыре третьих места по WER у Silero, по два у ЦРТ и 3iTech, одно третье место у Яндекса. Мужские длинные аудио стали самыми сложными для всех вендоров – лучший результат по Average WER выше 11.3%.
Микрофоны
Все первые места у наших моделей. Наш отрыв от конкурентов по Average WER в среднем более чем 2.48%. Average CER у наших моделей стабильно на первых местах. Шесть вторых мест у Сбера и ЦРТ, три у Silero и одно у Яндекса. Женские короткие аудио стали самыми сложными для всех вендоров – лучший результат по Average WER выше 13.5%.
Исследование №2 (статистика каждого вендора только на тех данных, которые смог корректно обработать именно рассматриваемый вендор)
Телефония
И снова в 5 из 6 категорий первое место занимает/делит система Тинькофф. На средних женских аудио они заняли второе место. Наши модели также взяли первые места в 5 из 6 категорий. В женских коротких аудио наша модель делит второе место с Яндексом (отставание от лидера 1.83%). Наш отрыв от 2-3 мест составляет в среднем 2,86%. При этом Average CER у нас стабильно на первых местах (периодически делим его с тем же Тинькофф), кроме второго места в коротких женских аудио. Четыре третьих места у Silero, три у ЦРТ, два у 3iTech и одно третье место у Яндекса. Мужские короткие аудио стали самыми сложными для всех вендоров – лучший результат по Average WER выше 14.6%.
Микрофоны
Наши модели заняли шесть первых мест. Отрыв от конкурентов по Average WER в среднем более чем 2.2%. Average CER у наших моделей тоже стабильно на первых местах. В коротких мужских аудио на первое место попали также ЦРТ и Сбер. Пять вторых мест у ЦРТ и Сбера, одно второе место у Silero. Мужские короткие аудио стали самыми сложными для всех вендоров – лучший результат по Average WER выше 15.8%.
Вот таким достаточно простым способом можно проверить качество системы распознавания речи и как результат — увидеть точки роста, где стоит усилиться и сделать доработки (дособрать речевые датасеты конкретного вида, собрать дополнительные корпуса и т. д.).
Ответ на статью Silero
В конце мая на Хабре вышла статья со сравнением ASR от Silero. Мы бы хотели её покритиковать, затем, если аудитории интересно, обсудить это в комментариях:
В рассмотренных сравнениях нет группировки по категориям телефон/микрофон, пол, длина аудио. Получается, что тестовая выборка может быть не сбалансирована по этим характеристикам. Хотя, вообще говоря, модель может лучше справляться с короткими аудио, и хуже – с длинными (мы это наблюдаем для всех вендоров, и тут хорошо видна важность качественной языковой модели). Т.е. разные модели могут справляться с одними реальными кейсами лучше других.
Не рассмотрены вариации WER и CER (хотя бы как в нашей статье). Да, результаты похожи, но не одинаковы. На наш взгляд, Average WER, relationship of sums является более точной метрикой, нежели Average WER, sum of relationships. Формулу WER не указали, но, скорее всего, подразумевается Average WER, sum of relationships.
Интерпретация результатов в формате «лучший-худший» не является полной. Например, модель может быть везде на 2-м месте. Вряд ли такой результат можно признать плохим. Однако, в подобной трактовке она получит свой «0». Отдельно хорошо бы смотреть на само значение WER, чтобы понять, где модели справились лучше, а где хуже. Ну и уж тем более не понятно желание найти «худшего» (NB: по той статье "Ашманов" – худший). Всё же потенциальных клиентов интересуют именно лидеры технологии. Поэтому логично делать акцент на топ-3/5 решений.
Мелочь: итоговая табличка с WER не очень удобная – нет никакой сортировки результатов вендоров по категориям и т.д.
Отдельно остановлюсь на тестах нашей ASR коллегами из Silero (кратко – сделано всё было максимально криво и некрасиво):
Мы не предоставляли коллегам доступа для тестирования. Сайт был скрыт под http-аутентификацией, доступы мы даём всем желающим, но от коллег не было запроса. Вероятно, они притворились потенциальным клиентом и получили доступ. Зачем? Сказали бы честно, что хотят протестировать – нам вообще не жалко, дали бы и доступ, и документацию. Помогли бы не ошибиться с API.
Было замечание, что на стенде не было документации. Да, потому что это непубличный сайт, документацию мы направляем клиентам и интеграторам по почте. Если бы они сделали запрос – мы бы скинули документацию, и им бы не пришлось догадываться (не особо успешно), как сервис работает.
Наш сервер, на котором Silero решили провести нагрузочное тестирование, не предназначался для больших нагрузок. Для демо нам не нужны большие пропускные способности, т.к. туда просто по паролю выдаются доступы заказчикам для ознакомления с ASR через браузер. В момент теста от Silero на нашем демо-стенде не было даже GPU – все бодро считалось и на CPU.
Самое важное: неизвестно, зачем прогонять свои данные телефонии только через модель для 16 kHz. Всё же звонки нужно прогонять через модели, приспособленные именно для телефонии – у нас (и у других вендоров) есть отдельная модель для этого, которая училась на соответствующих данных с частотой 8 kHz. Опять же, можно было бы запросить у нас документацию, либо попробовать разобраться в вопросе самостоятельно. Качество распознавания телефонных данных моделью для девайсов – ожидаемо очень плохое.
В итоге результаты сравнения (по крайней мере, для нашей ASR) получились некорректными. Это портит результаты всего сравнения. Повторюсь, всё это на пустом месте – нам самим интересно, чтобы нас тестировали, так как мы таким образом можем находить наши слабые места. Но тестирование Silero для нас оказалось бесполезным – так как аудио гонялись не через ту модель. После публикации своего сравнения на Хабре и наших комментариев о некорректности сравнения коллеги за доступами и документацией не пришли, видимо, исправлять некорректные данные им не хочется.
В своём сравнении, представленном в своих этой и прошлой статьях, мы старались сделать всё максимально аккуратно, так как нам самим интересно, какой сейчас расклад сил в нашей сфере.
Наши планы – расширить датасет записями:
В автомобиле
С различными говорами
В офисах и кафе
С фоновой музыкой/ТВ
Будет рады любой обратной связи и предложениям, всем спасибо за внимание и до новых встреч!
P. S. Наши open source наработки доступны тут: наш GitHub
Распознавание речи: SOVA ASR
Датасет для распознавания речи: SOVA Dataset
Синтез речи: SOVA TTS
