
Примерно так выглядит первая инсталляция CEPH на реальном железе.
Вы установили цеф, но он тормозит и падает непонятно почему? Тогда вы пришли по адресу! Я прокачаю ваш CEPH.
Вы послушали своих друзей и поставили первые попавшиеся диски на свою колымагу, а потом удивляетесь, что она не делает рекорд круга на местном картадроме, а вы мечтали о Нюрбургринге? Правильно! Так не бывает, от физики никуда не уйдешь, поэтому перед построением кластера вы должны посчитать IOPS-ы (хотя бы примерно), требуемый объем и под это подбирать диски. Если вы думаете забить кластер 8ТБ дисками, то не стоит ожидать от него сотен тысяч IOPS. Что такое IOPS-ы и их примерное значение для разных типов дисков приведено здесь.
Еще одна вещь, на которую стоит обратить внимание — это журналы.
Для тех, кто не в курсе: ceph сначала пишет данные на журнал, а через какое-то время переносит их на медленный OSD. Сразу же появляются любители сэкономить, взять одну или две SSD побыстрее и сделать их журналом для 20-25 OSD. Во-первых, IOPS-ы у вас несколько просядут. Во-вторых, это работает до первой смерти SSD. Тогда у вас падают все OSD, что были на этом SSD. К настройке журналов надо подходить очень внимательно. В рекомендациях на сайте ceph.com указано, что необходимо не больше 5-6 OSD на один SSD, но при этом не указано, какой размер журнала указать и какой параметр filestore max sync interval выбрать. К сожалению, данные параметры индивидуальны для каждого кластера, поэтому подбирать их вам нужно будет самостоятельно путём многочисленных тестов.
Второе, что бросается в глаза, в нашей колымаге, это два больших дивана вместо сидений. Вы же не будете в 2017 году ставить в свою машину два дивана вместо сидений?

Применительно к CEPH мы сейчас говорим о пулах.
Обычно делают один большой пул и на этом останавливаются, но это неправильно. Один большой пул ведет к проблемам с удобством управления и апгрейдом. Как апгрейд связан с размером пула? А вот так: апгрейдить живой кластер на лету очень опасно, поэтому есть смысл развернуть новый небольшой рядом, отреплецировать данные в новый пул и переключить. Из этого выходит рекомендация: поделить данные на логические сущности. Если у вас openstack, то есть смысл отталкиваться от зон openstack. При большом количестве серверов размазывайте их по стойкам и рулите правилами crushmap.
Теперь залезем под капот.

Если мы проектируем систему не под десятки тысяч IOPS, то процессор можно поставить начального уровня. Однако учтите: чем больше дисков на один сервер и чем больше они могут отдать IOPS, тем сильнее нагрузка. Поэтому, если у вас сверхбюджетная конфигурация из 2-3х JBOD-ов на один сервер (что само по себе плохая идея), то процессор у вас будет грузиться сильно. Мы же с одним JBOD и 30-ю дисками процессор в полку еще не загоняли. А вот «проводку» меняем. Нет, конечно и на 1гбит\сек оно заведется, но при падении OSD начинается ребаланс и тут уже канал загружается по полной. Поэтому interconnect между нодами CEPH 10гбит/сек обязательно. Правило хорошего тона делать LACP.
«Подвеску» лучше усилить. Ставим памяти, исходя из рекомендованных 1 гигабайт RAM на 1тб данных. Можно и больше. По оперативной памяти CEPH достаточно прожорлив.

Теперь о быстрой езде на том, что построили.
В CEPH имеется проверка целостности данных — так называемые scrub и deep scrub. Их запуск сильно влияет на IOPS, поэтому запускать их лучше скриптом ночью, ограничив количество проверяемых PG.
Ограничьте скорость ребаланса параметрами osd_recovery_op_priority и osd_client_op_priority. Вполне можно пережить днём медленный ребаланс, а ночью, в моменты минимальной нагрузки, запустить его на полную.
Не заполняйте кластер под завязку: ограничение 85% не просто так создано. Если нет возможности увеличения места в кластере новыми серверами, то используйте reweight-by-utilization. Учтите, что у этой утилиты есть параметр по умолчанию 120%, а также что при её запуске начинается ребаланс.
Параметр weight тоже влияет на заполнение, но косвенно. Да, в CEPH есть weight и reweight. Обычно weight делают равным объему диска.

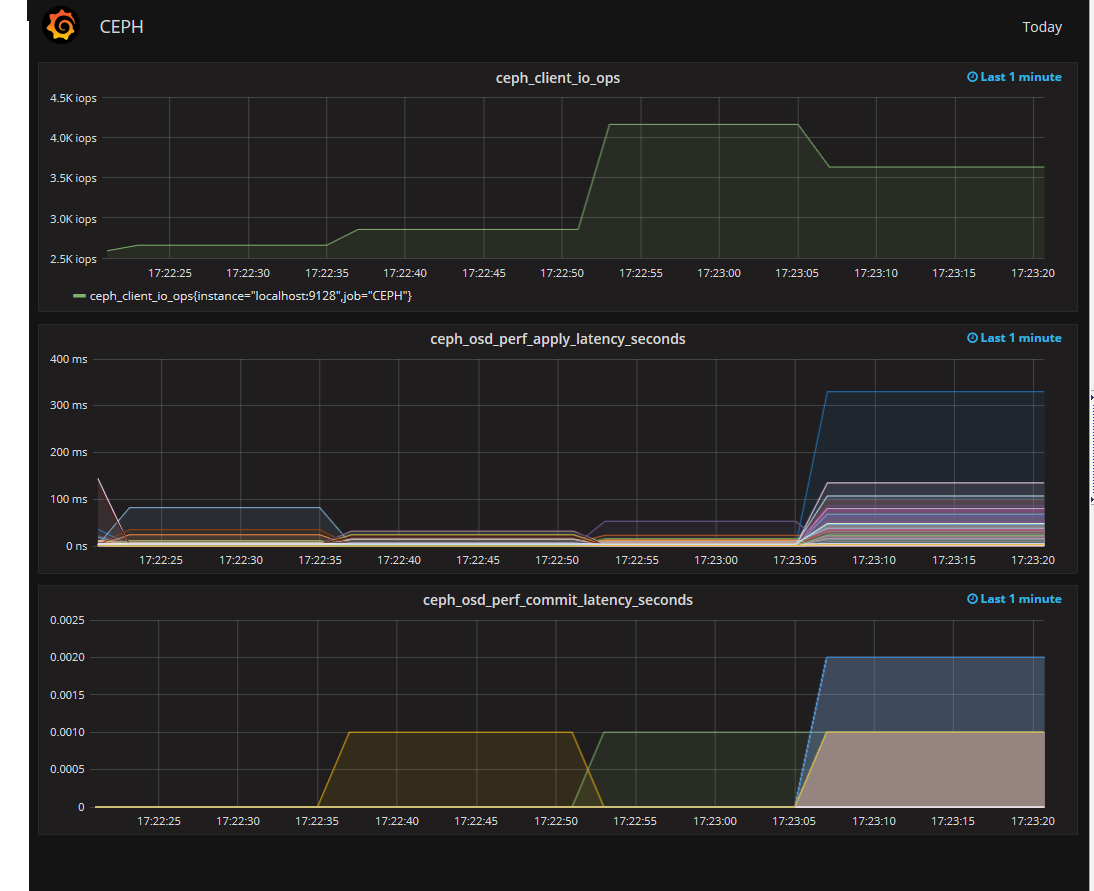
Итак, наш CEPH почти прокачан, осталось только приделать монитор. Мониторить можно чем угодно, но особо интересен мониторинг вывода ceph osd perf. Более всего интересен fs_apply_latency. Именно он показывает нам, какая из OSD долго отвечает и снижает производительность кластера. Притом, что SMART на этих OSD может быть вполне себе хорошим.
Выглядит это примерно так.

Итак, съемки превращения старой колымаги закончены. Пора показать backstage и опровергнуть о мифы, которые я слышал:
- Нормально делай — нормально будет. При грамотном проектировании CEPH не нужна большая команда админов на его поддержку.
- Баги есть. Видели ООМ на ОСД. Просто пришёл ООМ, убил ОСД, потом еще одну. На этом остановилось. Обновили CEPH, пару раз еще приходил ООМ, но потом так же внезапно прекратился. Отдебажить не удалось.
- Местами CEPH очень прожорлив по swap. Возможно надо править настройки swappiness.
- Переход с двойной на тройную репликацию это печально и долго, так что всё же хорошо подумайте.
- Используйте однотипные сервера, одну ОС в кластере и одну версию CEPH, вплоть до минорной. Теоретически, CEPH заведется на всём, но зачем потом индивидуально дебажить каждую железку?
- В CEPH меньше багов, чем кажется. Если вы думаете, что нашли баг, то для начала внимательнее почитайте документацию.
- Заведите один тестовый стенд на физическом железе. Не всё можно проверить в виртуальных машинах.
Отдельно хочу сказать о том, что не надо делать:
- Не вынимайте диски из разных нод плоского кластера со словами «это же цеф, чего ему будет?». Health error будет. В зависимости от количества данных в кластере и уровня репликации.
- Двойная репликация — путь экстремалов. Во-первых, больше шансов потерять данные, во-вторых, медленнее ребаланс.
- Dev релизы пусть тестируют разработчики, особенно всякие новые с bluestore. Оно, конечно, может работать, но когда грохнется, то как вы будете доставать данные из непонятной файловой системы?
- FIO с параметром engine=rbd может врать. Не стоит на неё полагаться при тестах.
- Не тащите сразу в прод всё то новое, что вы нашли в документации. Сначала проверьте на физическом стенде.
Спасибо за внимание.
