Если вы занимаетесь выращиванием больших баз данных и вдруг упираетесь в потолок производительности — пришло время расширяться. Со scale-out расширением понятно: серверы добавляете и горя не знаете. Со scale-up все не так весело. Согласно стандартной glueless-архитектуре, мы берем два процессора, потом добавляем к ним еще два… так доходим до восьми и все. Больше Intel не предусмотрел, копите на новый сервер.
Но есть и альтернатива — glued-архитектура. В ней двухпроцессорные вычислительные блоки соединяются между собой через нод-контроллеры. С их помощью верхний порог на один сервер поднимается до 16 и более процессоров. В этом посте подробней расскажем о glued-архитектуре вообще и о том, как она реализована в наших серверах.
Рынок распределенных вычислений и больших данных, если верить статистике, растет на 18-19% в год. Значит, вопрос выбора софта для этих целей остается актуальным. В этом посте мы начнем с того, зачем нужны распределенные вычисления, подробней остановимся на выборе ПО, расскажем о применении Hadoop с помощью Cloudera, а напоследок поговорим о выборе железа и о том, как оно разными способами влияет на производительность.
Крупные производители популярного софта заботятся о своих заказчиках по-разному. Один из способов — создать программу сертификации. Чтобы, когда заказчики в раздумьях блуждают между аппаратными конфигами для конкретного софта, производитель этого софта мог подойти и с уверенностью показать пальцем: «Бери вот это и все будет хорошо».
Такую программу для своего SQL Server разработал Microsoft — SQL Server Fast Track (DWFT). По ней сертифицируются конфигурации хранилищ данных — те, которые соответствуют требованиям рабочей нагрузки и могут быть внедрены с меньшим риском, стоимостью и сложностью. Звучит прекрасно, но интересно все-таки оценить эти критерии на практике. Для этого мы подробно разберем одну из конфигураций, имеющих сертификацию SQL Server Data Warehouse Fast Track.
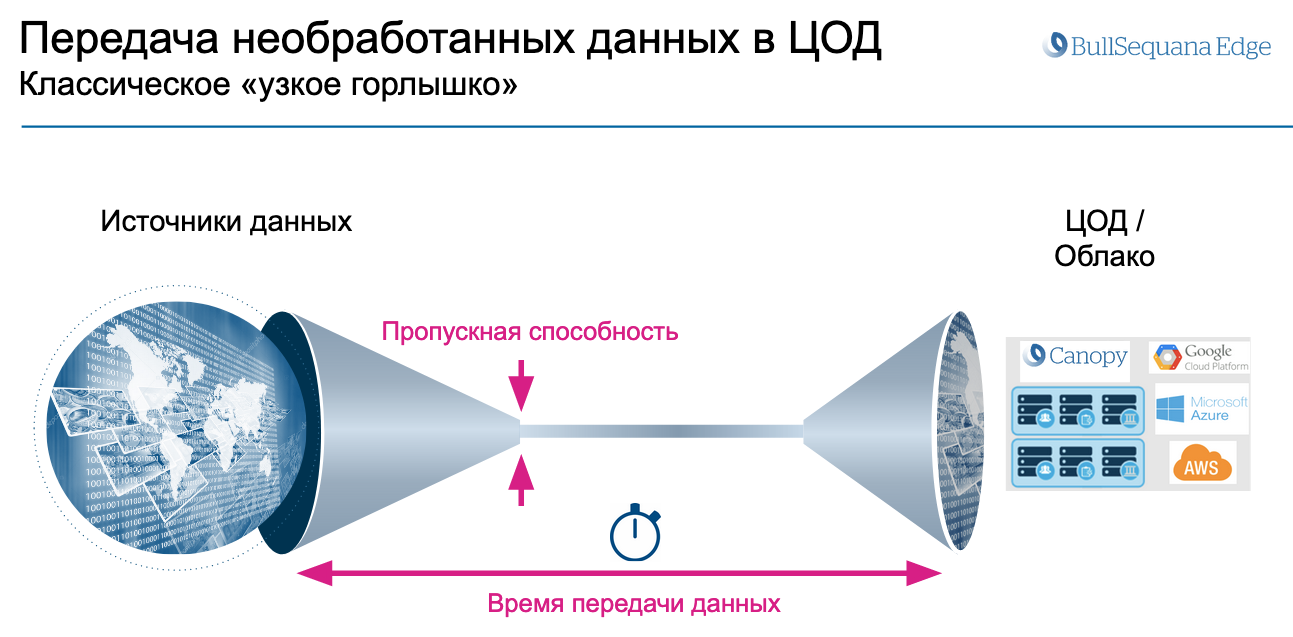
При разработке сетевой инфраструктуры обычно рассматривают либо локальные вычисления, либо облачные. Но этих двух вариантов и их комбинаций мало. Например, что делать, если от облачных вычислений отказаться нельзя, а пропускной способности не хватает или трафик стоит слишком дорого?
Добавить промежуточное звено, которое выполнит часть вычислений на границе локальной сети или производственного процесса. Эта периферийная концепция называется Edge Computing — «граничные вычисления». Концепция дополняет текущую облачную модель использования данных, и в этой статье мы рассмотрим необходимое оборудование и примеры задач для него.
SAP HANA — популярная in-memory СУБД, включающая сервисы хранилищ (Data Warehouse) и аналитики, встроенное промежуточное ПО, сервер приложений, платформу для настройки или разработки новых утилит. За счет устранения задержек традиционных СУБД с SAP HANA можно сильно увеличить производительность систем, обработку транзакции (OLTP) и бизнес-аналитику (OLAP).
Развернуть SAP HANA можно в режимах Appliance и TDI (если говорить о продуктивных средах). Для каждого варианта у производителя есть свои требования. В этом посте мы расскажем о преимуществах и недостатках разных вариантов, а также для наглядности — о наших реальных проектах с SAP HANA.
Привет, Хабр! Все мы, живя в эпоху высоких технологий, с привычкой относимся к огромному количеству окружающих нас умных девайсов, заметно облегчающих жизнь человека. Речь сегодня пойдет о видеокамерах и данных, получаемых в процессе видеонаблюдения. Этой статьей мы открываем серию публикаций про наш комплекс видеоаналитики и рассмотрим мы его на примере финансового сектора.
Привет, Хабр! Мы постоянно проводим тесты различных софтверных решений на нашем оборудовании, и иногда простая, казалось бы, задача разворачивается на недели решения. Как раз о таком случае сегодня и пойдет речь. Главный герой нашего рассказа - Павел, технический специалист компании Atos в России.