
Привет, меня зовут Иван, и я делаю Авито Доставку. Когда пользователь покупает товар с доставкой, мы показываем ему список отделений служб доставки с ценами. Цена доставки может меняться от отделения к отделению. Мы смотрим на область карты, где покупатель ищет товар и информацию по объявлению, например, координаты продавца, вес и размеры товара. И на выходе показываем человеку список отделений с адресами и ценой доставки в каждое из них.
В ходе разработки калькулятора цены доставки возникла такая задача: есть структура базы данных PostgreSQL и запрос к ней от сервиса на Go. Нужно заставить всё это работать достаточно быстро. В итоге нам удалось поднять пропускную способность сервиса с 50 до 5000 RPS и выявить пару нюансов при общении сервиса с базой. Об этом и пойдёт рассказ.

В статье мы не будем разбирать нефункциональные требования к сервису, построение структуры базы или оптимизацию SQL-запроса. Будем считать, что база и запрос свалились на нас в виде входных данных, а требования выставлять не станем — вместо этого будем мониторить пропускную способность и время отклика сервиса.
Структура базы данных

Не нужно искать физический смысл в этих отношениях — это просто две денормализованные сущности, которые нужны для поиска. Строятся они на основе обычной БД в третьей нормальной форме.
Объём данных такой:
- send: ~400 тысяч записей;
- receive: ~160 миллионов записей.
SQL-запрос
SELECT r.terminal_id,
r.lat, r.lon,
r.tariff_zone_id,
r.min_term, r.max_term
FROM receive r
INNER JOIN (
SELECT DISTINCT ON (s.provider) provider, tariff_id, s.tag_from_id, Point(s.lat, s.lon) <-> Point (:seller_lat, :seller_lon) AS dist
FROM send s
WHERE
s.lat BETWEEN :seller_leftbot_lat AND :seller_righttop_lat
AND s.lon BETWEEN :seller_leftbot_lon AND :seller_righttop_lon
AND :now BETWEEN s.active_from AND s.active_until
AND s.max_weight > :weight AND s.max_height > :height AND s.max_length > :length AND s.max_width > :width AND s.max_declared_cost > :declared_cost
ORDER BY provider, dist
) AS s USING (tag_from_id)
WHERE
r.lat BETWEEN :buyer_leftbot_lat AND :buyer_righttop_lat
AND r.lon BETWEEN :buyer_leftbot_lon AND :buyer_righttop_lon
AND r.max_weight > :weight AND r.max_height > :height AND r.max_length > :length AND r.max_width > :width AND r.max_declared_cost > :declared_cost
LIMIT :limit;Чтобы запрос работал быстро, нужно создать пару индексов:
CREATE INDEX send_idx
ON send(lon, lat, active_from, active_until);
CREATE INDEX receive_idx
ON receive(tag_from_id, lon, lat);Можно спорить, какие поля нужно включать в индексы, а какие — нет. Эту комбинацию мы подобрали через нагрузочные тесты: это некий sweet spot, когда индекс получается относительно лёгким и одновременно даёт нужную производительность.
Порядок полей в индексах тоже важен. Например, долготу (lon) есть смысл ставить в индексе впереди широты (lat): Россия вытянута в широтном направлении, и долгота оказывается более селективна.
Сервис на Go
В интересах статьи сервис будет максимально упрощён. Он всего лишь:
- разбирает входные данные;
- формирует запрос и шлёт его в БД;
- сериализует ответ базы в JSON и отдаёт его.
В реальности он ещё считает цену на основе tariff_zone_id, но суть та же: основная нагрузка ложится на базу данных, в Go происходит минимум действий. Построен сервис на обычном Server из net/http и использует одну горутину на запрос.
Архитектура решения
Искать подходящие отделения и считать цены доставки будем на бэкенде. Для повышения надёжности и по юридическим причинам тарифы и методику расчёта цены доставки мы хотим хранить у себя, а не ходить за ценой к подрядчикам. Тарифы будем хранить в унифицированном виде для всех служб доставки.
Для расчёта цены используем отдельный микросервис со своим хранилищем.
В качестве хранилища мы рассматривали Elasticsearch, MongoDB, Sphinx и PostgreSQL. По результатам исследования выбрали PostgreSQL: он закрывает наши потребности и при этом существенно проще в поддержке для нашей компании, your mileage may vary.
Налоги и комиссии в статье рассматривать не будем. Нас интересует только базовая цена доставки от подрядчика.
Тестовый стенд

Сервис развёрнут в Kubernetes на трёх подах по 500 Мб. База развёрнута в LXC-контейнере с 4 ядрами и 16 Гб памяти. В качестве connection pooler используется pgbouncer, развёрнутый в контейнере с базой.
Это достаточно стандартный для Авито сетап. В реальном сервисе был бы ещё один pgbouncer, развёрнутый внутри каждого пода с сервисом.
План запроса
Посмотрим, как исполняется запрос к базе данных:

В запросе осталась сортировка — оптимизировать её в поиск минимума Постгрес не стал. Это не очень хорошо, но на наших данных максимум может сортироваться около ста записей, обычно — от 20 до 50. Кажется, с этим можно жить.
Основные же затраты идут на поиск по btree-индексу по большой таблице.
Результаты «в лоб»
Пора уже запустить тест.
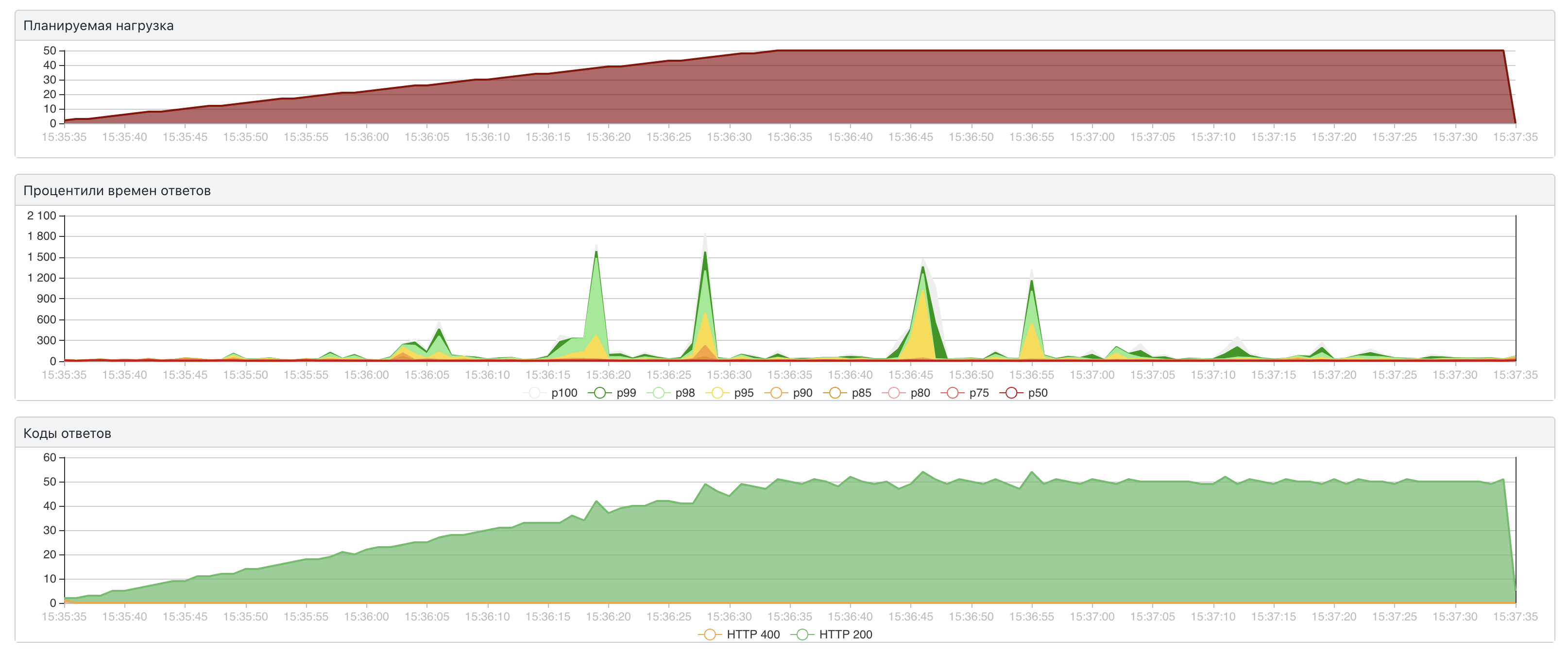
50 RPS / 314 мс для 99-го перцентиля
Уже на низких RPS появляются подозрительные пики в графике времени отклика. Это видно на среднем графике, по вертикальной шкале время в миллисекундах. 70 RPS сервис не держит совсем. Надо это оптимизировать.
Подход к оптимизации
Оптимизация — это цикл из нескольких шагов:
- Определить цели и индикаторы. Чего хотим и как будем измерять успех.
- Создать тестовые данные. В нашем случае — заполнить базу и сгенерировать ленту запросов к сервису.
- Добиться полной нагрузки одного из ресурсов, увидеть узкое место.
- Расширить узкое место.
- Повторять до достижения целей.
Наши цели — 200 RPS минимум, лучше 500 RPS. Индикаторы — пропускная способность сервиса и время отклика.
Тестовые данные — это важно
Мы старались по максимуму использовать реальные данные. Использовали их, где получалось, для наполнения базы, добавив шум. Для создания ленты запросов собрали реальные запросы с прода. Где это было невозможно, использовали генератор. Было ясно, что любые предположения, не основанные на реальных данных, будут снижать надёжность результатов тестов.
Изначально мы использовали ленту в 20 тысяч запросов. И довольно быстро удалось добиться такого результата:

Тут сервис держит 1000 RPS при 52.5 мс. Всё красиво, кроме скачков времени отклика, но давайте попробуем потестировать ту же конфигурацию на ленте в 150 тысяч запросов:

Уже на 200 RPS сервис заваливается. Запросы отваливаются по таймауту, появляются 500-ки. Оказывается, предыдущий тест врёт примерно в 10 раз по пропускной способности.
Похоже, для ленты в 20 тысяч запросов использовалась лишь часть данных в таблицах. PostgreSQL смог всё закэшировать и работал быстро. Для ленты в 150 тысяч требовалось больше данных из таблиц, в кэш они не поместились, и быстродействие упало.
Получается, не уделив достаточно внимания входным данным, легко испортить всё нагрузочное тестирование.
Переезд на pgx/v4
Скачки времени отклика на графиках выше намекают на наличие проблем в подключении сервиса к базе.
До сих пор мы использовали библиотеку pgx третьей версии и не ограничивали размер пула соединений. Если уж оптимизировать эту часть, то давайте переедем на четвёртую версию и уже на ней будем всё настраивать. Тем более, про неё есть много хороших отзывов.
Переехали, ограничили пул до 10 соединений. Пробуем:

Стало лучше, но принципиально ничего не изменилось. В чём дело? Смотрим метрики pgbouncer’а:

Синий — число активных клиентских соединений (cl_active), красные точки — число клиентских соединений, которым не досталось серверного соединения (cl_waiting, правая шкала, снимается раз в 30 секунд).
Видно, что число активных соединений под нагрузкой катастрофически падает. Как выяснилось, так проявлялся один из багов в pgx/v4. Как мы искали для него решение, я уже рассказывал в статье про починку pgx.
Откат на pgx/v3
На тот момент баг в pgx/v4 еще не был исправлен, и мы воспользовались воркэраундом: откатились на третью версию и отключили отмены запросов.

Сильно лучше не стало, но самые хорошие новости ждали нас в метриках pgbouncer:
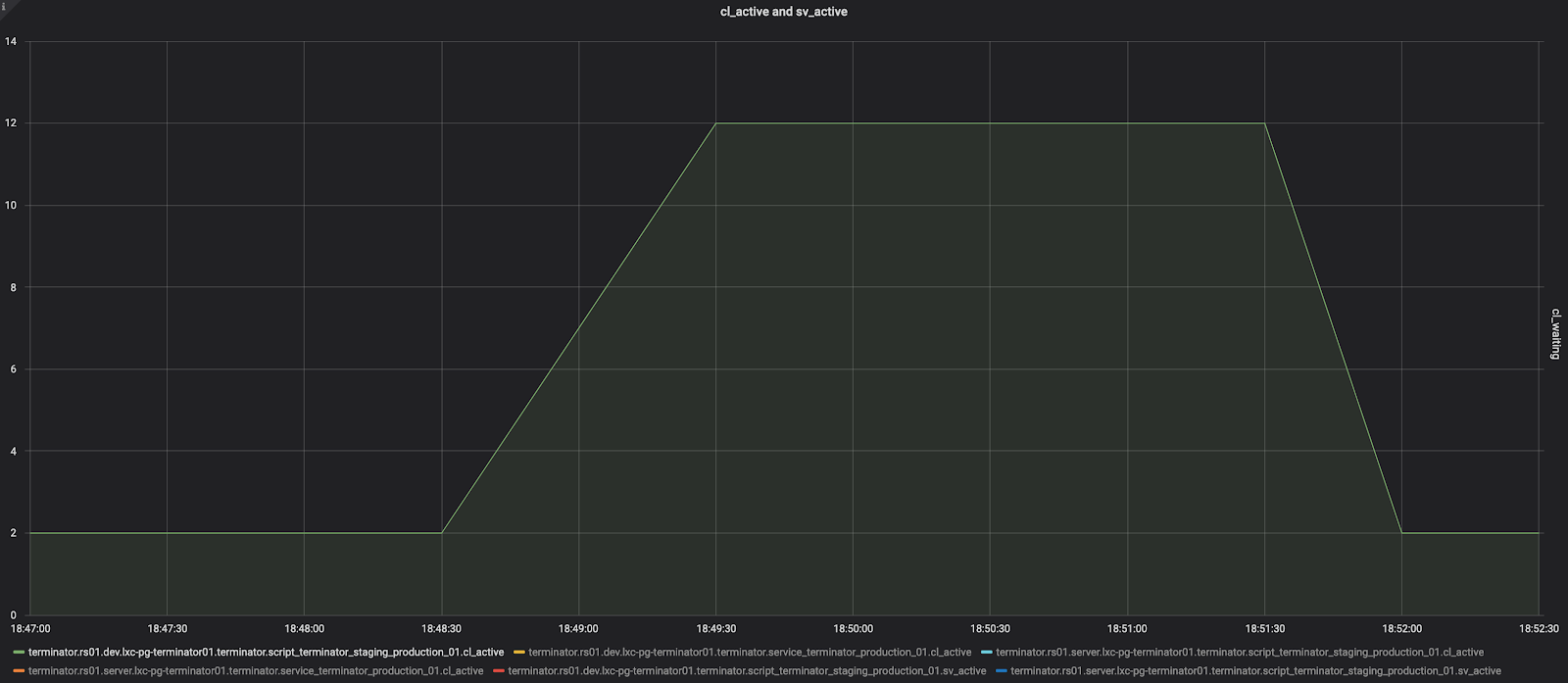
Число активных соединений растёт до максимума под нагрузкой — здесь пул ограничен до 12 — и не падает до конца теста.
С этого момента мы стали собирать ещё и результаты закрытых тестов. Закрытый тест — это когда задаётся не скорость подачи запросов, а общее число запросов в системе. Это более щадящий режим, но он удобнее для отладки производительности, т.к. даёт меньше шума.

130 RPS при 20 параллельных запросах
В метриках контейнера с базой мы увидели полку в операциях ввода-вывода:
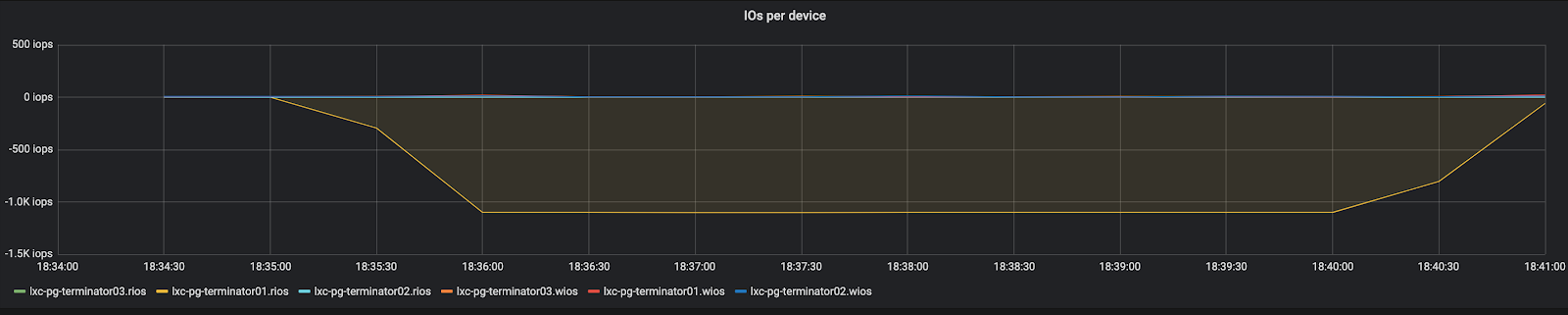
Жёлтое — это число операций чтения (растёт вниз). Мы выбрали всю квоту контейнера на операции чтения, то есть нам удалось, наконец-то нормально нагрузить базу.
Масштабируем базу по диску
Проверим, является ли узким местом диск. Увеличиваем квоту контейнера в 8 раз, смотрим:
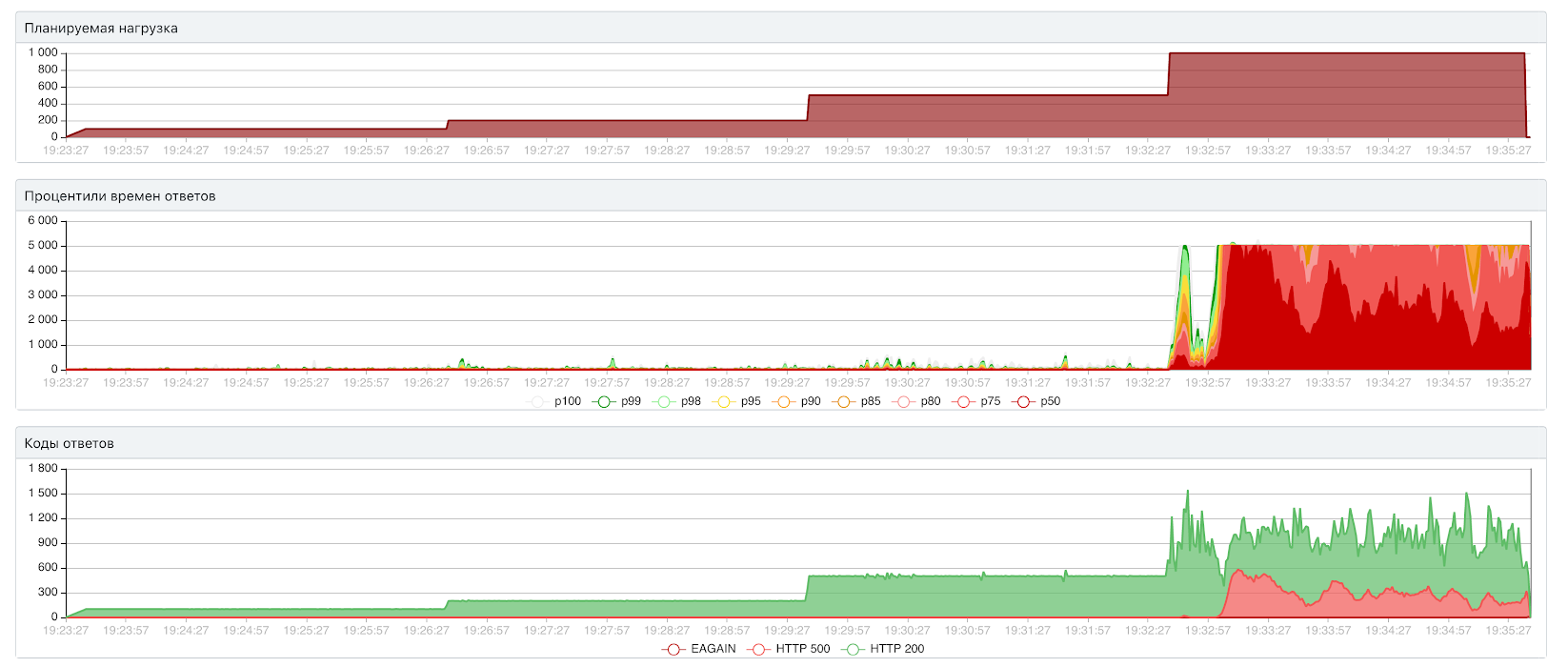
Открытый тест: 500 RPS / 109 мс
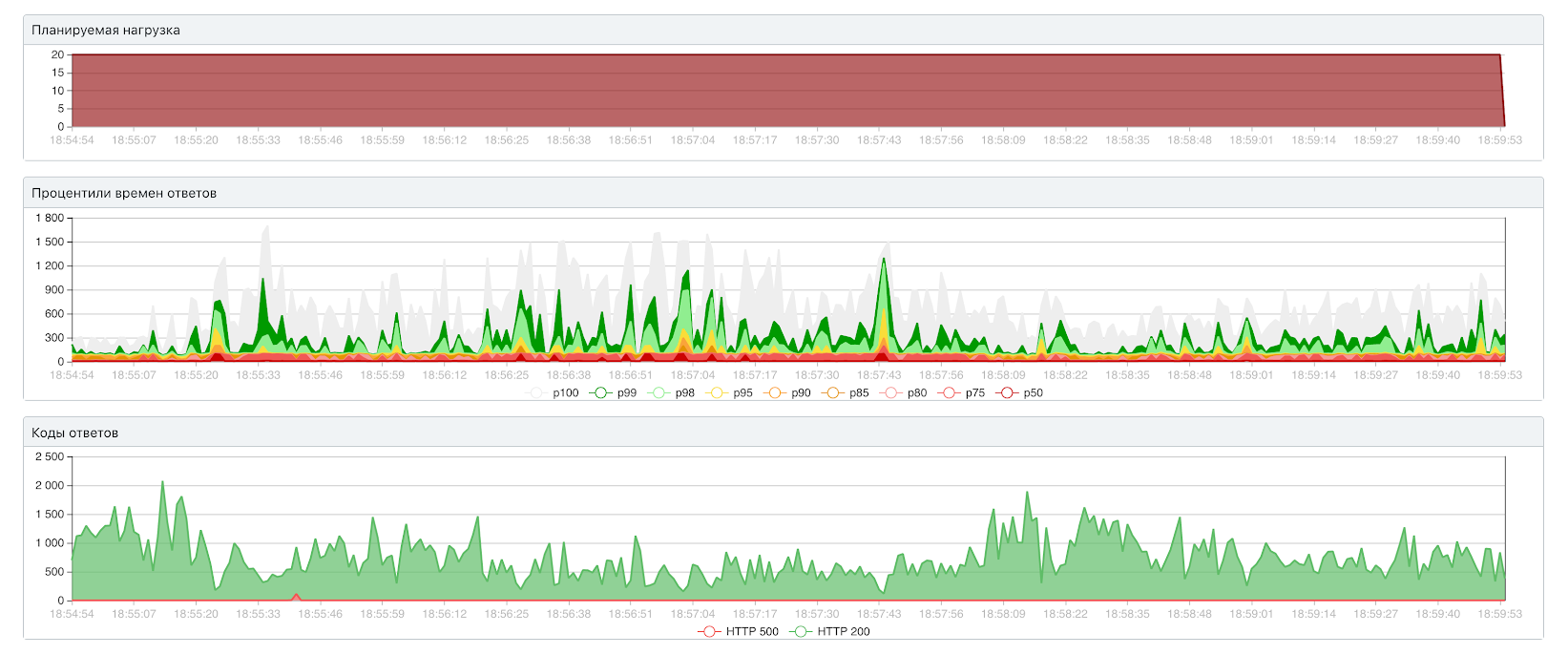
Закрытый тест: 745 RPS
В закрытом тесте пропускная способность выросла со 130 RPS до 745 — почти линейный рост. Значит, мы действительно упираемся в диск.
Оценим предел вертикального масштабирования. Снимаем с контейнера ограничение на операции ввода-вывода вообще:
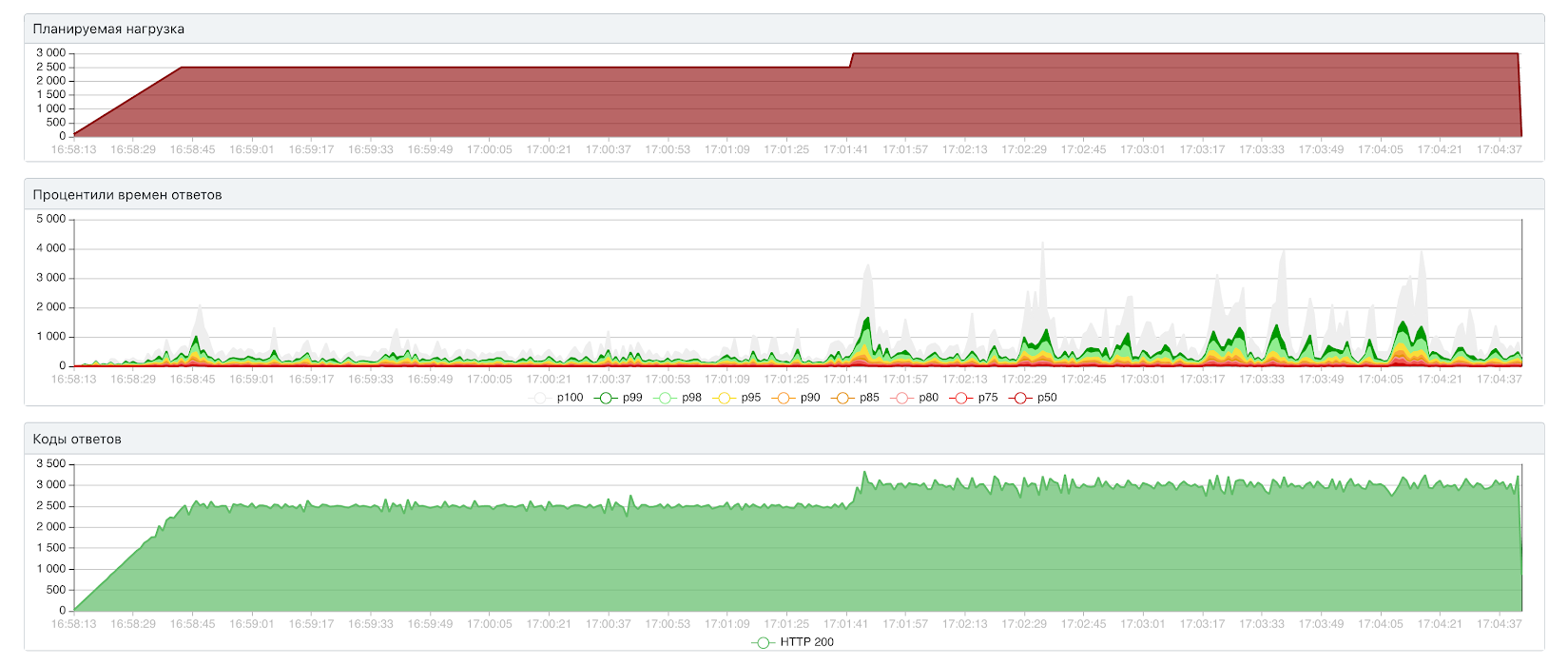
Открытый тест: 3000 RPS / 602 мс

Закрытый тест (20 инстансов): 2980 RPS / 62 мс
Заметим, что закрытому тесту явно не хватает 20 параллельных запросов, чтобы нагрузить сервис. Мы съели вообще весь диск на всём сервере с базой:

Зелёное — число операций чтения (растёт вниз)
Конечно, в продакшене так себя вести нельзя: придут злые девопсы и будут нас ругать. Вообще, упираться в диск очень не хочется: его сложно масштабировать, мы будем мешать соседям по серверу, а они будут мешать нам.
Попытаемся уместить данные в память, чтобы диск перестал быть узким местом.
Масштабируем базу по памяти
Смотрим размеры наших таблиц и индексов:
SELECT
pg_size_pretty( pg_total_relation_size('send')) send,
pg_size_pretty(pg_indexes_size('send')) send_indexes,
pg_size_pretty( pg_total_relation_size('receive')) receive,
pg_size_pretty(pg_indexes_size('receive')) receive_indexes;Видим 21 Гб данных и 6 Гб индексов. Это существенно больше полезного объёма данных, но тут Постгресу виднее.
Нужно подобрать конфигурацию базы, которая могла бы вместить 27 Гб в памяти. В Авито используются несколько типовых конфигураций PostgreSQL: они хорошо изучены, а параметры в них согласуются друг с другом. Никто не запрещает кастомизировать конфигурацию под потребности конкретного сервиса, но начинать лучше с одной из готовых конфигураций.
Смотрим список конфигураций и находим вот такую:

8 ядер, 64 Гб памяти, effective_cache_size 48 Гб
effective_cache_size — это не настоящий размер кэша, это просто параметр планировщика, чтобы тот представлял, на сколько памяти ему рассчитывать. Можно здесь хоть петабайт поставить — размер кэша не увеличится. Просто планировщик будет предпочитать алгоритмы, которые хорошо работают с данными в памяти. Но всё же этот параметр в типовой конфигурации наши DBA выбрали не случайно: он учитывает разные кэши, доступные базе, в том числе кэш операционной системы. В общем, надо пробовать:

Открытый тест: 4000 RPS / 165 мс

Закрытый тест (100 инстансов): 5440 RPS / 106 мс

Операции чтения (зелёное) — на нуле, операции записи (жёлтое) — в незначительных количествах
Диск больше не является узким местом и, прямо скажем, бездельничает.

Утилизация CPU — полностью загружены все 8 ядер
Теперь мы упираемся в процессор. Это хорошо: масштабировать его относительно просто, а мешать мы никому не будем.
Единственное, что смущает, — большая разница в результатах открытого и закрытого тестов. Это может свидетельствовать о проблемах с соединениями. Смотрим метрики pgbouncer, и точно:

Опять cl_waiting подскочил. В этот раз, правда, cl_acitve (жёлтое) не падает, а cl_waiting (красные точки, правая шкала) не поднимается выше 12.
Ну, это просто ошибка в конфигурации базы. Размер пула должен быть 24, именно такой пул выставлен в сервисе. А на стороне базы он остался равным 12. Исправляем, смотрим:

Открытый тест: 5000 RPS / 140 мс
Закрытый тест (100 инстансов): 5440 RPS / 94 мс
Вот теперь хорошо. В закрытом тесте результаты те же, а вот в открытом пропускная способность выросла с 4000 до 5000 RPS. Стоит отметить, что нет никакого смысла использовать больше соединений, чем размер пула БД: это лишь портит производительность. Впрочем, это наблюдение заслуживает более пристального изучения.
Куда делась 1000 RPS
Итак, превышение размера пула сервиса над размером пула БД в два раза ведёт к потере 20% пропускной способности (с 5000 RPS до 4000 RPS). Почему? И почему в закрытом тесте разница не видна?
Давайте разберём, что вообще происходит, когда сервис выполняет запрос через pgx. Вот мы посылаем некий запрос:
rows, err := h.db.QueryContext(ctx, `SELECT 1`)h.db — это пул соединений. Внутри QueryContext происходит Pool.Acquire(), который захватывает конкретное соединение для выполнения нашего запроса. Соединений на всех не хватает, требуется синхронизация, для чего используется sync.Cond:
func (p *Pool) Acquire(ctx context.Context) (*Resource, error) {
//...
p.cond.Wait()
//...sync.Cond внутри — это пара атомиков, мьютекс и очередь на связном списке (см. notifyList, который используется под капотом у sync.Cond), то есть издержки на синхронизацию здесь минимальны. Горутина просто записывает себя в конец очереди и паркуется, ожидая, пока рантайм её разбудит. К тому же всё это происходит на стороне сервиса, который не является узким местом в нашем случае.
type notifyList struct {
wait uint32
notify uint32
lock mutex
head *sudog
tail *sudog
}type Cond struct {
//...
notify notifyList
//...
}sync.Cond внутри сделан как очередь
Теперь представим, что пул сервиса больше, чем пул базы данных. У pgbouncer’а появляются 24 клиентских соединения, но только 12 серверных. Он вынужден жонглировать клиентскими соединениями, подключая их к серверным поочередно. Это дорогая операция, т.к. нужно менять состояние серверного соединения. В частности, установить новые переменные, что требует общения с базой через сокет по протоколу. И всё это происходит, в нашем случае, в контейнере с базой, то есть мультиплексирование отъедает ресурсы у базы, которая и так является узким местом.
/* link if found, otherwise put into wait queue */
bool find_server(PgSocket *client)
{
//...
/* send var changes */
if (server) {
res = varcache_apply(server, client, &varchange);
//...
}
//...
if (server) {
if (varchange) {
server->setting_vars = 1;
server->ready = 0;
res = false; /* don't process client data yet */
if (!sbuf_pause(&client->sbuf))
disconnect_client(client, true, "pause failed");
//...Переключение соединений может потребовать общения с сервером по сети
Видимо, в этом и кроется причина потери производительности: мультиплексирование соединений на pgbouncer’е под нагрузкой — зло.
Разница результатов открытого и закрытого тестов
Почему разница не заметна в закрытом тесте, у меня точного ответа нет, но есть рабочая гипотеза.
Судя по коду find_server(), pgbouncer не стремится любой ценой подключить соединение к серверному. Нашлось свободное серверное соединение — хорошо, подключим. Нет — придётся подождать. Этакая кооперативная многозадачность, в которой соединения не очень хотят кооперироваться.
Получается, активное клиентское соединение, в котором без остановки выполняются запросы, может довольно долго не освобождать серверное соединение. А запрос, попавший на неактивное соединение, будет долго ждать своей очереди.
Пока запросов в системе мало, как в закрытом тесте, это роли не играет: запросам хватает таймаута, чтобы дождаться своей очереди. В открытом тесте запросов в системе в разы больше, они выстраиваются в очередь на захват соединения в pgx и тратят там большую часть таймаута. На захват серверного соединения в pgbouncer времени не остается. Происходит таймаут и 500-я ошибка.
Но это лишь правдоподобные рассуждения, хорошо бы их проверить. Когда-нибудь потом.
Запуск на холодную
Мы добились хорошей производительности в стационарном режиме за счёт размещения данных в памяти. Но как поведёт себя сервис в ситуации, когда данных в памяти нет, например, после аварии?
Перезагружаем сервис и сервер с базой, смотрим:

Разогнались до 5000 RPS за 10 секунд, примерно за минуту — до максимума. Значит, никакие механизмы прогрева кэша нам не нужны, можно сразу подавать боевой трафик.
Переезд pgx/v4, попытка номер два
Раз уж появился фикс для четвёртой версии, надо его попробовать в деле. Обновляем библиотеку:
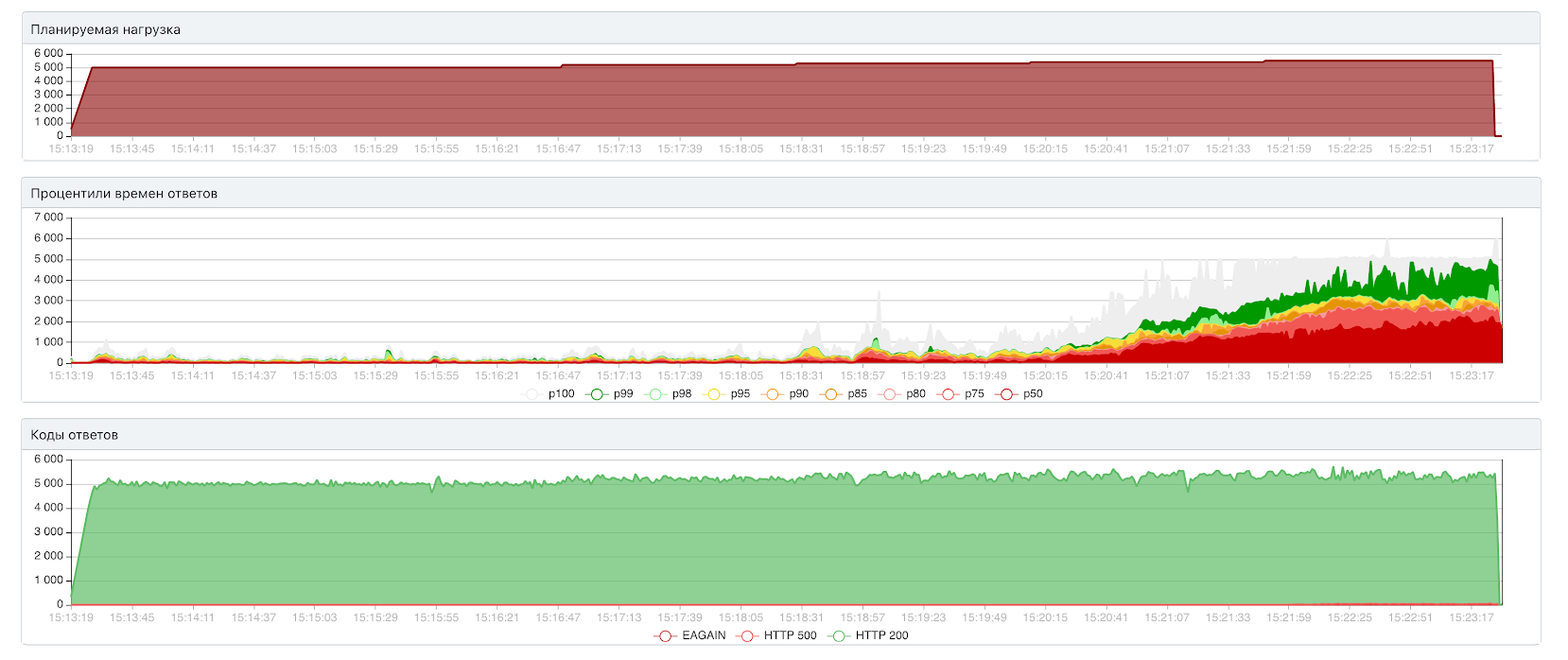
Открытый тест: 5000 RPS / 217 мс, 5300 RPS / 645 мс
Закрытый тест: 5370 RPS / 43 мс
По производительности примерно то же самое, что и в третьей версии. Разница в том, как сервис деградирует при заведомо запредельной нагрузке. С четвёртой версией это происходит медленнее.
Подбор размера пула в сервисе
Как мы увидели, ограничение размера пула сервиса оказывает весьма существенное влияние на производительность. К сожалению, часто пул не ограничивают вообще. Из-за этого сервис держит меньшую нагрузку, чем мог бы, возникают мистические таймауты под штатной нагрузкой, а в некоторых случаях может серьёзно деградировать производительность базы данных.
Общее число соединений есть смысл выбирать в интервале от числа ядер, доступных базе, до ограничения на число серверных соединений у pgbouncer (каким его выбрать — вопрос для DBA).
При числе соединений меньше числа ядер база остаётся незагруженной, т.к. в Постгресе каждое соединение обслуживается отдельным процессом, который максимум может нагрузить одно ядро. Если соединений больше, чем максимальное число серверных соединений, начнётся мультиплексирование.
Конечно, эти соображения пригодны, когда нет долгих транзакций и медленных выборок из базы, которые надолго занимают соединение. Если они у вас есть, стоит подумать, как от них избавиться. Кроме того, опасно именно переключение соединений под нагрузкой. Задачи, работающие в разное время, например, сервис с пиковым трафиком днем и ночной крон, могут использовать полный пул каждая: мультиплексирования будет немного.
Не забываем
Закрывать результат
Это обсуждали множество раз, но тем не менее. Даже если в документации к библиотеке написано, что закрывать Rows необязательно, лучше всё же закрыть самому через defer.
rows, err := conn.Query(...)
if err != nil {
return err
}
defer rows.Close() // лучше закрыть принудительно
for rows.Next() {
// ...
}
if rows.Err() != nil {
return err
}Как только внутри цикла по rows.Next() случится паника или мы сами добавим туда выход из цикла — rows останется незакрытым. Незакрытый результат — это соединение, которое не может быть использовано другими запросами, но занимает место в пуле. Его придется убивать по таймауту и заменять на новое, а это долго.
Быстрые транзакции
Применительно к pgbouncer: медленные транзакции забивают серверный пул.
Долгая транзакция вызывает те же проблемы, что и незакрытый результат: соединение невозможно использовать ни для чего другого.
Особенно опасны незакрытые транзакции, а это ошибка, которую в Go сделать довольно легко. Если pool_mode установлен в transaction, как это сделано у нас, то незакрытая транзакция надолго занимает собой соединение, в нашем случае на два часа.
Медленные же транзакции часто можно без больших затрат разделить на несколько быстрых. Если же это невозможно, то стоит подумать об отдельной реплике базы для них.
Keepalive
Keepalive — это фича, которую не стоит включать бездумно. Она полезна, когда входящих соединений мало, например, если к вам ходят другие ваши сервисы и вы можете контролировать, сколько соединений они создают. При бесконтрольном создании соединений под высокой нагрузкой у сервиса окажется множество незакрытых соединений. Каждое из них отъест свои 2-4 Кб, и будет плохо.
Проверять гипотезы практикой
В вопросах производительности запросто можно получить противоположный ожидаемому результат. Слишком много факторов вмешиваются в процесс. Любое своё предположение желательно проверять на железе и с цифрами.
TL;DR, или выводы
- Прокачали сервис от 50 до 5000 RPS, не применяя никакой особой магии.
- Мультиплексирование соединений в pgbouncer’е под нагрузкой — зло.
- Использовать в сервисе пул большего размера, чем в базе данных — вредно.
- Выработать привычку делать транзакции быстрыми и закрывать результаты БД.
Благодарности
Кроме меня над задачей работали коллеги из Доставки: Кирилл Любаев, Александр Кузнецов, Алексей Власов.
И огромное спасибо всем, кто помогал:
- Андрею Аксёнову — за идеи, что гео-индексы здесь не нужны, что инты рулят и вообще, проще — лучше.
- Павлу Андрееву, нашему DBA-инженеру, — за терпение и оптимизацию на стороне PostgreSQL.
