
Инфомодель — это система управления метаданными в Авито. Она управляет категоризацией объявлений, их таксономией и каталогами. В недавней статье на Медиуме мы рассказали, как с ней работаем: зачем Инфомодель нужна и как она взаимодействует с остальными системами Авито.
Сегодня же я затрону такую немаловажную тему при работе с данными, как подготовка новых изменений и их деплой в prod.

Как мы жили раньше
Когда в 2017 году мы только начали работу над проектом Инфомодели, Авито работал по сути с двумя окружениями: prod и dev. Все данные Инфомодели лежали в базе, никаких интерфейсов или процессов для их изменения не было, все правки вносились через код миграциями. Люди писали SQL-миграции в основном репозитории нашего монолита, добавляя нужные новые записи в таблицах или изменяя их. При деплое миграции раскатывались командой DBA в prod, или накатывались автоматом на dev.
Но здесь скрывалась проблема: что делать, если твоя фича ещё не готова? Что если тебе надо добавить изменения, которые точно затронут окружающих? Чтобы изменения никого не поломали, у нас была колонка is_active (bool), которая использовалась при получении данных из базы. Например, вот таблица категорий:
|category_id|parent_id|name |sorting|icon |is_active|slug |
|-----------|---------|----------|-------|------|---------|----------|
|1 | |Транспорт |10 |01.gif|true |transport |
|9 |1 |Автомобили|1100 | |true |avtomobili|Чтобы получить из неё данные для отрисовки, скажем, дерева категорий, мы делали обычный SELECT вида:
SELECT * FROM categories WHERE is_active = true;Если же надо было добавить новую категорию так, чтобы её пока никто не видел, мы создавали миграцию, в которой делали INSERT новой строки, а её is_active делали false. После деплоя кода в dev-среду, миграция прогонялась автоматически и добавляла новую строку:
|category_id|parent_id|name |sorting|icon |is_active|slug |
|-----------|---------|----------|-------|------|---------|----------|
|1 | |Транспорт |10 |01.gif|true |transport |
|2 |1 |Автомобили|1100 | |true |avtomobili|
|3 |1 |Грузовики |1200 | |false |gruzoviki |На бэке же приходилось обновлять запрос на получение данных, добавляя в него следующее:
SELECT * FROM categories WHERE is_active = true OR category_id = 3;Таким образом мы получали новую категорию на нашей локальной сборке, но окружающие изменения не видели. Дальше мы доделывали задачу и убирали этот OR. А команда DBA заменяла is_active на true при последующей выкатке в prod.
Проблематика
Часто вносить изменения, не подключая разработчиков на каждый чих, с подобным подходом невозможно. Особенно если речь идёт о каких-то параллельных или совместных изменениях.
Но компания растёт, бизнес требует вносить изменения всё чаще, как быть?
Решение
Когда мы продумывали архитектуру первой версии Инфомодели, то поставили перед собой требование дать бизнесу возможность быстро вносить изменения в Инфомодель. И, главное, вносить их так, чтобы команды Авито не блокировались друг другом.
В итоге мы придумали довольно элегантное и эффективное решение, которое позволяет командам:
работать с данными параллельно;
релизить свои изменения тогда, когда они к этому готовы;
тестировать изменения на лету;
знать, кто и когда вносил любые изменения;
видеть diff между своими изменениями и тем, что сейчас в prod.
Решение мы назвали «Версионирование Инфомодели». Что оно из себя представляет?
По сути мы разработали Git поверх Postgres. Каждый человек, работая с Инфомоделью, выполняет свои задачи в своей изолированной ветке. В ней он может менять всё, что угодно: хоть удалить категорию, хоть создать сто новых.
Всё ветвление делается из одной общей production-ветки под названием master, в которую нельзя вносить изменения напрямую. С точки зрения интерфейса, заведение новых веток выглядит так:
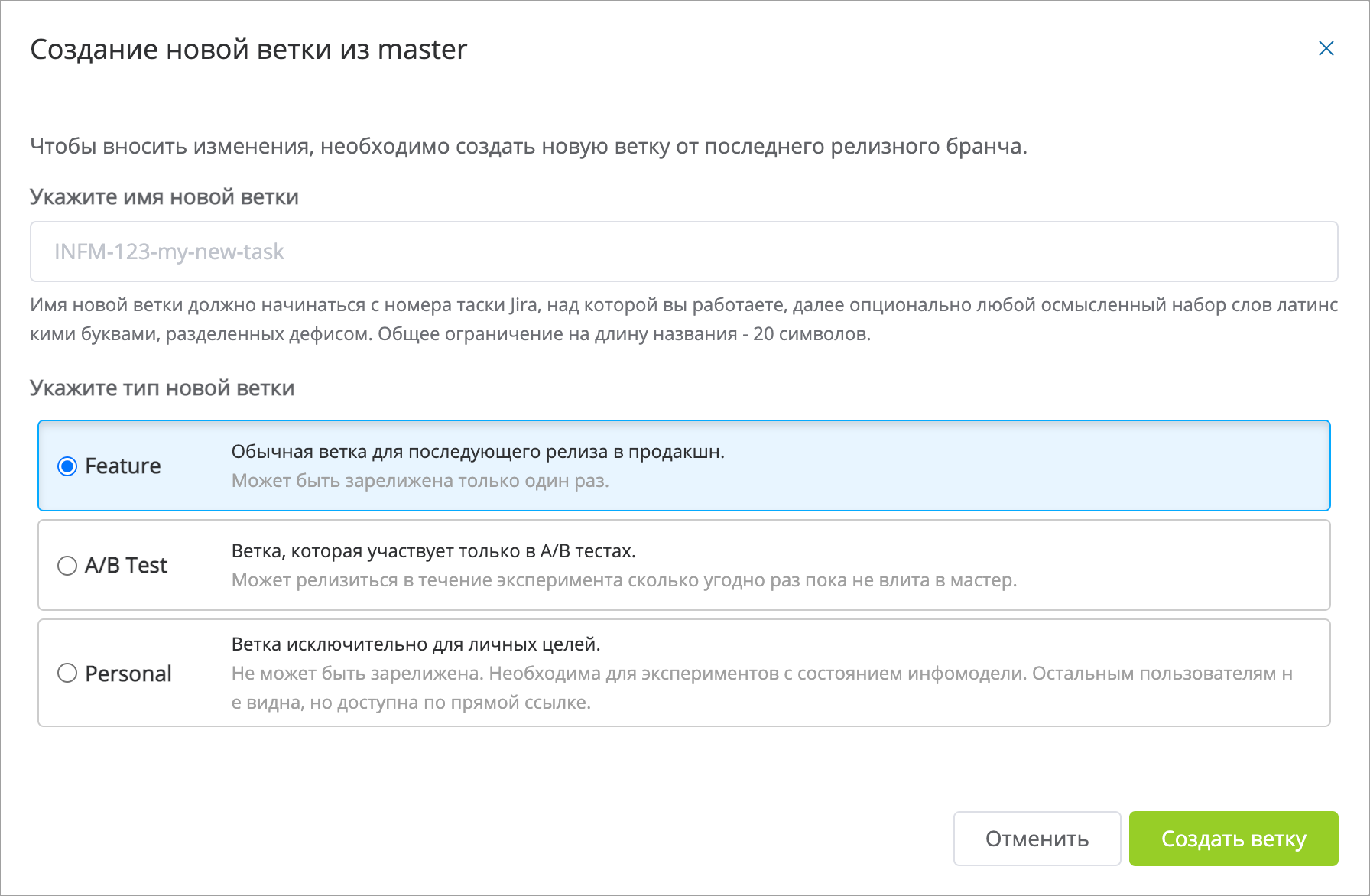
У нас есть три разных типа веток. Их отличия связаны с процессом релиза, который стоит раскрыть с учётом того, как работают ветвление под капотом.
Техническая сторона
Одной из задач, которые мы поставили перед собой при разработке технической составляющей версионирования, была простота в понимании и лёгкий дебаг того, что происходит с ветками.
Схема данных
Чтобы обеспечить изоляцию веток друг от друга, мы реализовали ветвление на уровне схем Postgres. Каждая ветка — это отдельная схема, которая обладает тем же набором необходимых таблиц и записей, что и master. При создании новой ветки мы специальной хранимкой дублируем всю схему master целиком. Пользователи работают только со своим слепком данных, не трогая окружающих.
Конечно, нам пришлось завести отдельную схему для хранения служебной информации: списка веток и их схем, списка юзеров и так далее. Для этого существует отдельная схема metadata, содержащая необходимый набор таблиц, чтобы работала машинерия Инфомодели.
Первая задача выполнена: наши юзеры могут вносить изменения в данные параллельно и не пересекаясь.
Но здесь крылась первая проблема, с которой мы столкнулись: primary keys. Создавая новые записи, люди создавали и новые строки в таблицах с autoincrement PK. Добавив две разные записи в две разные схемы, они получали одни и те же ключи, что сводило на нет всю схему. Мы вынесли все последовательности в схему metadata и пошарили их между схемами веток. Это решило проблему, и больше id не пересекались.
Работа с изменениями
Как и в Git, мы храним у себя все изменения, которые внес пользователь. Для этого в каждой схеме (и в master тоже) существует служебная таблица changelog. Эта таблица хранит записи по каждому изменению в текущей ветке:
> SELECT * FROM mslanin.changelog;
|changelog_id|user_id|branch_id|action_type|target_id|target_type |old_state |new_state |created_at |batch_hash |is_auto|
|------------|-------|---------|-----------|---------|------------|-------------------------------------------|-------------------------------------------|-------------------|--------------------------------|-------|
|12071608 |13 |8514 |updated |9 |сategory |{"name": "Автомобили"} |{"name": "Аааавтомобили!"} |2021-06-16 06:18:20|dxjpoccqdjcr0trw8zqrfrwpmyoeip3m|false |
|12071609 |13 |8514 |created |100085 |сategory |{} |{"name": "Самолеты", "category_id": 100085}|2021-06-16 06:18:32|iai7urvs3n3to0mslirpp5vlejaouqit|false |
|12071610 |13 |8514 |deleted |100085 |сategory |{"name": "Самолеты", "category_id": 100085}|{} |2021-06-16 06:18:41|vyww9u4xsnjvi9pkpdurcreeuigyunha|false |Как видно из таблицы, мы знаем, кто, когда, и что сделал с какой сущностью. В итоге юзер в интерфейсе всегда может посмотреть список своих изменений или найти и отдебажить чужие:
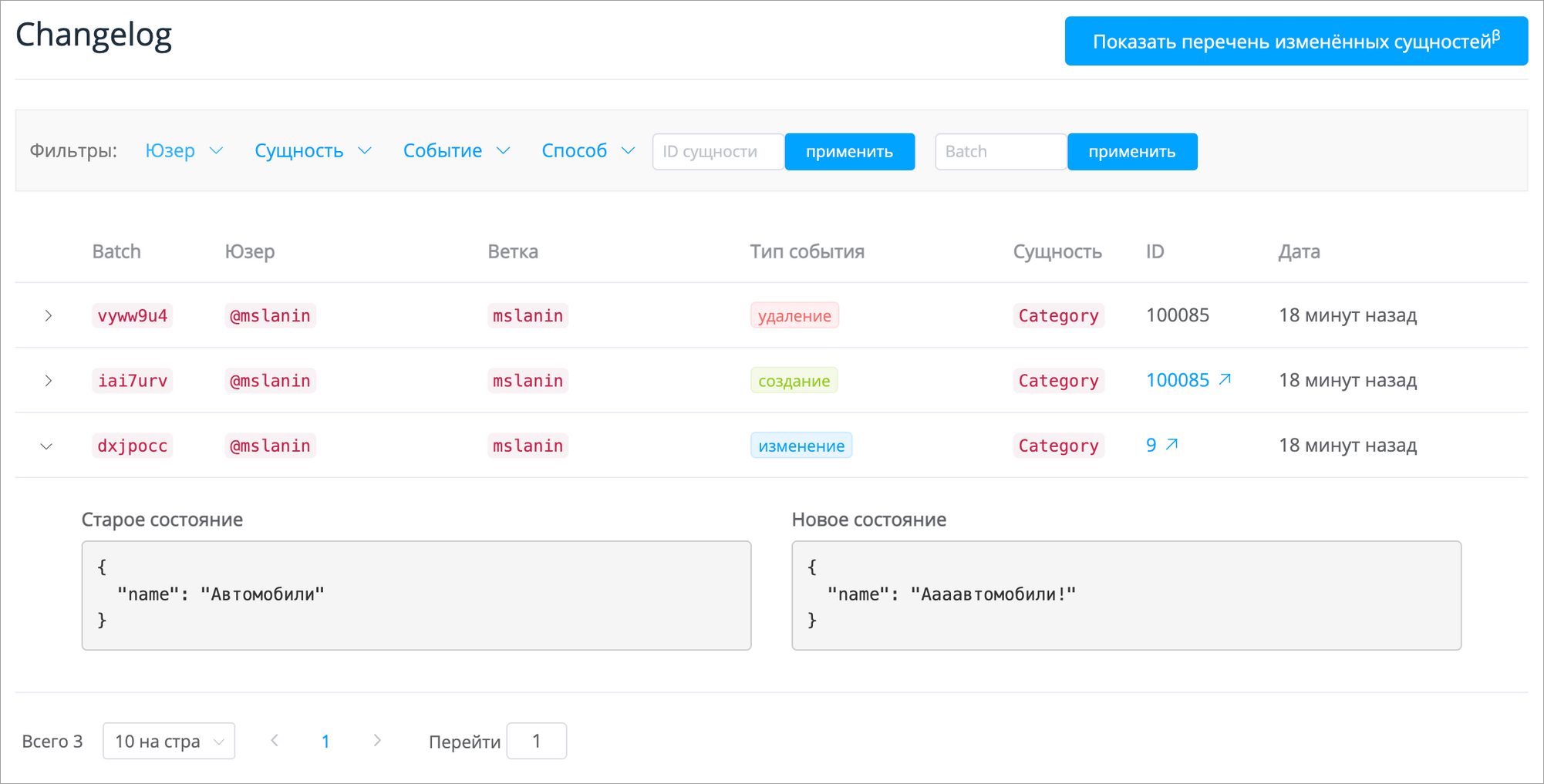
Представим, что пользователь решил удалить категорию. Одним действием будут удалены и сама категория и все связанные с ней атрибуты. А на одно действие пользователя будет создано несколько записей в чейнджлоге. Чтобы объединить эти записи, мы ввели свойство batch_hash (string). По нему мы можем определить изменения, произведённые с базой в пределах одного действия пользователя. Также по нему мы можем откатывать изменения одно за другим.
Таким образом мы добились ещё двух пунктов: видим все изменения и можем посмотреть diff.
Выкатка изменений в prod
Тот факт, что мы храним все изменения, позволяет нам сливать ветки между собой. Тот самый процесс релиза изменений в prod, который был упомянут выше, — не что иное, как блокировка ветки для изменений и наложение записей из чейнджлога одной за другой на сущности в ветке master, откуда они попадают в prod.
Мы даём людям самим решать, когда они готовы отправить свои изменения в prod.
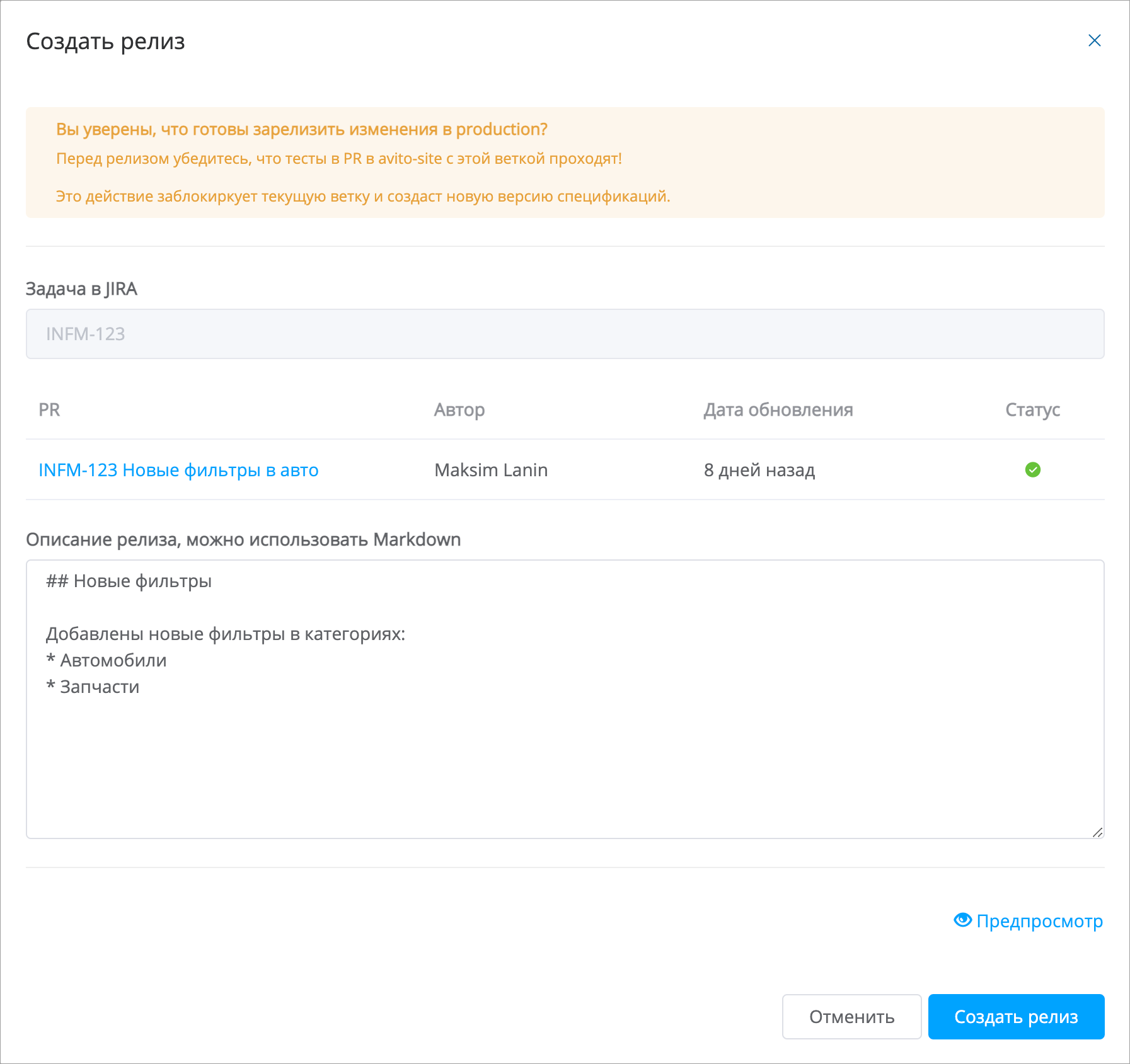
Создание веток с именем, начинающимся с номера Jira-таски, позволяет не только отличать ветки друг от друга, но и провязывать изменения в Инфомодели и изменения снаружи. Мы знаем, какие PR были в сделаны в пределах таски и прошли ли там тесты. Если нет, то не даём релизить изменения.
После старта релиза мы прогоняем ещё несколько билдов с тестами прежде чем запускаем мердж изменений. Это нужно, чтобы продуктовые команды были уверены, что изменение им ничего не сломает.
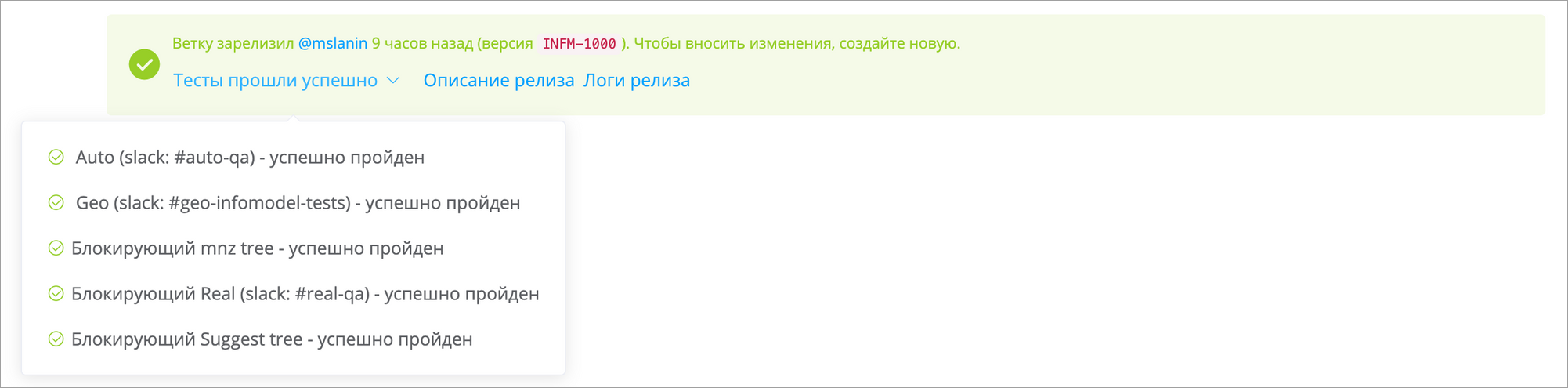
Отставание ветки
После вливания изменений одной ветки в prod, остальные активные ветки автоматически блокируются для релиза. В них можно вносить изменения, но релизить их нельзя, ведь владелец ветки не видит всей текущей картины.
Чтобы исправить это, пользователь может подлить мастер в свою ветку одним кликом. Под капотом мы создадим ещё одну чистую схему из мастера и вольем в неё все изменения из предыдущей ветки, которые юзер успел сделать. Механизм сродни git rebase.
Но и тут есть подводные камни. Что если в мастер попали изменения, которые удаляют какие-то сущности, с которыми работал пользователь в своей ветке? Получится ситуация, что в его схеме будут строки, которые через foreign key ссылаются на несуществующие записи.
Для решения подобных проблем у нас есть механизм, ласково названный Garbage Collector. Он запускается после каждого подливания мастера. Задача Garbage Collector — следить за тем, чтобы в ветке пользователя всё было консистентно и удалять записи, которые ссылаются в никуда. По окончанию работы он присылает юзеру нотификацию в Слак об успешном завершении операции. Изменения, которые внёс Garbage Collector, в чейнджлоге помечаются свойством is_auto (bool). В UI их можно найти по специальному фильтру.
Тестирование изменений
Перед тем как зарелизить изменения, пользователь может захотеть посмотреть, как они выглядят на самом Авито. Для этого он может создать тестовый стенд нашего монолита или своего конкретного сервиса и «натравить» его на свою ветку напрямую. Это позволит бэкенду переключиться с мастера на его ветку и показать юзеру результат работы.
Таким образом мы закрыли последний пункт из требований к системе, связанный с тестирование собственных изменений на лету.
Минусы подхода
К минусам можно отнести отсутствие dev-среды как таковой. Один инстанс Инфомодели раздаёт данные как для продакшн окружения, так и для всех дев-сред, которые ссылаются на еще незарелиженные ветки.
Также очевидный минус — при изменении схемы данных необходимо отмигрировать все существующие схемы веток. Порой это вызывает серьёзные проблемы с учётом их количества.
Итоги
За время существования системы было создано 2226 веток. Из них до релиза дошло 2073. В среднем выкатка одного изменения занимает 2 дня.
