
Сегодня мы расскажем о том, как в Badoo изменился подход к проектированию нагруженных “key-value” сервисов. Вы узнаете, по какой схеме такие сервисы создавались нами несколько лет назад (использование БД в качестве репозиториев и специализированного демона как интерфейса к данным), с какими трудностями мы при этом столкнулись и к какой архитектуре в результате пришли, разрешив появившиеся проблемы.
Современные интернет-проекты активно используют внутренние сервисы, позволяющие обращаться к значениям по ключу. Это могут быть как готовые решения, так и собственные разработки. Начиная с 2006 года, специалистами компании Badoo был создан ряд таких сервисов, в числе которых:
- сервис, сообщающий о месторасположении данных пользователя по его идентификатору;
- сервис, хранящий информацию о количестве обращений к профайлу пользователя;
- список интересов пользователей;
- несколько “геосервисов”, позволяющих определить местонахождение пользователя.
Несмотря на их разнообразие, применялся единый подход к проектированию, согласно которому сервис должен был состоять из следующих компонент:
- Базы-репозитория, которая хранит эталонную версию данных.
- Быстрого демона на C или C++, который обрабатывает запросы на получение данных и обновляется вместе с базой-репозиторием.
- PHP-классов, обеспечивающих работу с демоном и базой-репозиторием.
Нам было важно, чтобы любой из сервисов мог обрабатывать большое количество одновременных запросов, поэтому решение на базе только одного MySQL не подходило. Отсюда и появилась дополнительная компонента в виде быстрого демона, которую не получилось заменить системой memcached, т.к. нам нужно было использовать специфические индексы данных.
В конце 2010 года все большую популярность стал набирать HandlerSocket MySQL plug-in, написанный японским умельцем, предоставляющий NoSQL интерфейс к данным, хранимым в MySQL. Уже весной 2011 года специалисты Badoo обратили своё внимание на новую технологию, надеясь с её помощью упростить разработку и поддержку “key-value” сервисов компании.
“Первая жертва”
В сети для поиска новых друзей Badoo зарегистрировано огромное количество пользователей, которые получают различные уведомления по электронной почте. И у каждого из этих пользователей есть возможность выбрать тип уведомлений, которые он хотел бы получать. Соответственно, нужно где-то хранить почтовые настройки и предоставлять к этим данным доступ. Более 99% запросов к ним – запросы на чтение. Основными «читателями» являются скрипты-генераторы и отправители электронной почты, которые на основании этих данных принимают решение о возможности или невозможности отправлять корреспонденцию определенного типа конкретному пользователю. Сначала для хранения данных использовалась только БД, однако она перестала справляться с постоянно растущим числом запросов на чтение. Для снятия этой нагрузки был создан специальный демон — EmailNotification.
“Old school” реализация сервиса
Ключевой составляющей сервиса был С-демон, хранящий в памяти все настройки и предоставляющий к ним доступ на чтение и запись по простейшему протоколу поверх TCP. К тому же данный демон собирал статистику обращений, по которой мы строили графики.
Вначале архитектура сервиса была достаточно простой и выглядела так:
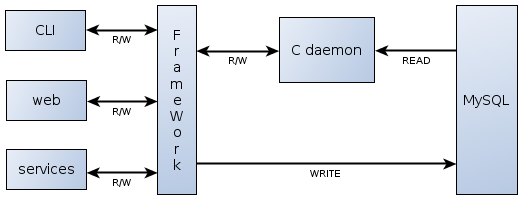
Настройки постоянно хранились в базе на одном DB-сервере, а С-демон работал на другом. При старте демон выбирал из базы все данные и строил по ним индекс (judy arrays). Процесс инициализации занимал около 15 минут, но так как данная операция потребовалась всего лишь несколько раз за все время существования сервиса, то это не являлось существенным недостатком. В процессе работы клиенты (CLI-скрипты, веб и другие сервисы) через специальный API обращались к демону, например, с вопросом, можно ли этому пользователю отправить это письмо или нет, и демон по встроенной логике искал у себя в памяти настройку и выдавал ответ. «Клиенты-писатели» отдавали демону команду поменять определенные настройки для определенного пользователя.
Задача записи данных в MySQL была целиком возложена на EmailNotification API. При этом потенциально могла возникнуть рассинхронизация данных, например, когда запись успешно прошла в базу, но не прошла в демон, или наоборот. Тем не менее сервис прекрасно работал. До тех пор, пока в 2007 году в Badoo не произошла «маленькая неприятность», а именно — появился второй дата-центр, географически удаленный от первого и предназначенный для обслуживания пользователей Нового Света. Сразу стало понятно, что обычным дублированием архитектурного решения на новой площадке обойтись не удастся. Так как письма одному и тому же пользователю могут отправляться с обоих площадок, требуется, чтобы оба сервиса оперировали одинаковыми данными.
К счастью, специально для таких случаев внутри компании имеется система CPQ-событий (CPQ — Cross Platform Queue, кроссплатформенные очереди. — Прим. автора), которая позволяет оперативно, а главное — гарантированно и в заданной последовательности передавать информацию о произошедших событиях между площадками. В результате на двух площадках архитектура сервиса приняла следующий вид:
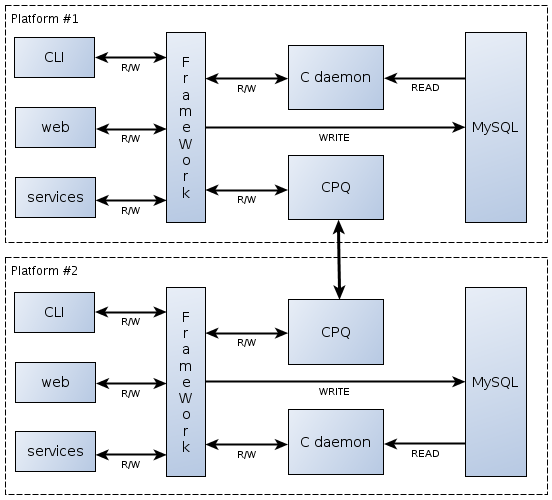
Теперь любые запросы на запись шли не только в базу и С-демон локальной площадки, но и в CPQ. CPQ передавала запрос в смежную очередь другой площадки, а та уже воспроизводила запрос на запись через EmailNotification API на этой же площадке.
Система усложнилась, но тем не менее продолжала стабильно работать на протяжении нескольких лет. И все было бы хорошо, если бы не появилось расхождение данных на площадках. В двух базах имеющихся площадок было разное количество настроек. И хотя разница была менее 0.1%, ощущения «чистоты и защищенности» как не бывало. Более того, мы обнаружили, что разница появилась не только между базами площадок, но она присутствовала между базой и С-демоном в рамках одной площадки. Пришлось задуматься над тем, как сделать сервис более надёжным.
Новый подход
Изначально основных требований к сервису EmailNotification было два: первое — высокая скорость обработки запросов на чтение, с чем прекрасно справлялся С-демон; второе — идентичность данных на обоих площадках, с которой были проблемы. Вместо того, чтобы биться над синхронизацией, мы решили полностью переделать архитектуру сервиса, пойдя по пути ее упрощения:
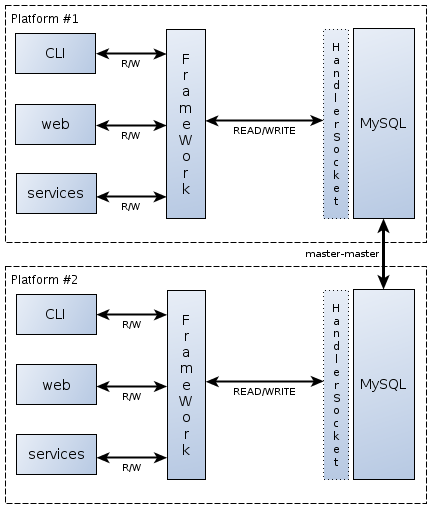
Прежде всего, мы подключили плагин HandlerSocket к MySQL и научили наш API работать через него с базой. Благодаря этому мы смогли отказаться от использования С-демона. Затем, упростив API, мы убрали из схемы CPQ-сервис, заменив его хорошо зарекомендовавшей себя “master-master” репликацией между площадками. В результате мы получили очень простую и надежную схему, которая обладает следующими преимуществами:
- Репликация осуществляется прозрачно, не требуется написание кода, работающего с внутренним CPQ-сервисом. При этом задержка при переносе обновлений между площадками сократилась от нескольких секунд до долей секунды.
- Атомарность записи данных (наконец-то!). Если запрос EmailNotification API на запись в HandlerSocket завершился успешно, значит, задача выполнена, запись точно продублируется на другой площадке, и нам не нужно информировать об этом никакие другие компоненты.
Были ли у нас проблемы при переходе на новую схему? Серьезных — нет. AUTO_INCREMENT уже поддерживается плагином HandlerSocket, составные индексы работают, ENUM-ы тоже, пришлось только отказаться от CURRENT_TIMESTAMP-значения по умолчанию для одного из timestamp полей.
Как известно, преимущество HandlerSocket не в скорости его работы — она скорее приемлемая, нежели впечатляющая, а в его возможности стабильно работать под большим количеством запросов в единицу времени. Учитывая, что сейчас сервис обслуживает всего 2 — 2.5 тысячи запросов в секунду на одной площадке, то у нас есть большой запас прочности.
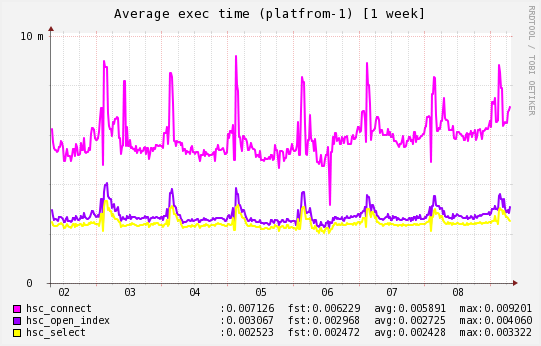
Но для особо интересующихся скоростью работы плагина HandlerSocket приведем график со средним временем выполнения трех команд: подключению к HandlerSocket, открытию индекса и выборке по нему данных (значения по оси Y в миллисекундах):
Заключительное слово
За последний год в Badoo наметилась тенденция использовать HandlerSocket в качестве “key-value” репозитория с постоянным хранением данных. Это позволяет нам писать более простой и понятный код, избавляет С-программистов от работы над тривиальными задачами и заметно упрощает поддержку. И пока все говорит о том, что движение в данном направлении продолжится.
Но не стоит думать, что использование HandlerSocket внутри Badoo ограничивается простейшими задачами. К примеру, у нас имеется большой опыт его использования для решения задач с преобладанием функции записи, где под действительно большой нагрузкой проявляется ряд нюансов. Если вам интересны детали — комментируйте, спрашивайте, и мы обязательно продолжим эту тему новыми статьями.
Спасибо!
