
Привет, Хабр! Меня зовут Александр Крашенинников, я руковожу DataTeam в Badoo. Сегодня я поделюсь с вами простой и элегантной утилитой для распределённого выполнения команд в стиле xargs, а заодно расскажу историю её возникновения.
Наш отдел BI работает с объёмами данных, для обработки которых требуются ресурсы более чем одной машины. В наших процессах ETL (Extract Transform Load) в ход идут привычные миру Big Data распределённые системы Hadoop и Spark в связке с OLAP-базой Exasol. Использование этих инструментов позволяет нам горизонтально масштабироваться как по дисковому пространству, так и по CPU/ RAM.
Безусловно, в наших процессах ETL существуют не только тяжеловесные задачи на кластере, но и машинерия попроще. Широкий пласт задач решается одиночными PHP/ Python-скриптами без привлечения гигабайтов оперативной памяти и дюжины жёстких дисков. Но в один прекрасный день нам потребовалось адаптировать одну CPU-bound задачу для выполнения в 250 параллельных инстансов. Настала пора маленькому Python-скрипту покинуть пределы родного хоста и устремиться в большой кластер!
Варианты манёвра
Итак, мы имеем следующие входные условия задачи:
- Долгоиграющая (около одного часа) CPU-bound задача на языке Python.
- Требуется выполнить задачу 250 раз с различными входными параметрами.
- Результат выполнения получить синхронно, то есть запустить что-то, подождать, выйти с exit code согласно результатам.
- Минимальное время исполнения – считаем, что у нас имеется достаточное количество вычислительных ресурсов для параллелизации.
Варианты реализации
Один физический хост
Тот факт, что запускаемые приложения являются однопоточными и не используют более 100% одного ядра CPU, даёт нам возможность бесхитростно осуществлять последовательность fork-/ exec-действий при реализации каждой задачи.
C использованием xargs:
commands.list:
/usr/bin/uptime
/bin/pwd
krash@krash:~$ cat commands.list | xargs -n 1 -P `nproc` bash -c
/home/krash
18:40:10 up 14 days, 9:20, 7 users, load average: 0,45, 0,53, 0,59Подход прост как валенок и хорошо себя зарекомендовал. Но в нашем случае мы его отметаем, поскольку при исполнении нашей задачи на машине с 32 ядрами результат мы получим через ~восемь часов, а это не соответствует формулировке «минимальное время исполнения».
Несколько физических хостов
Следующий инструмент, который можно применить для такого решения, – GNU Parallel. Помимо локального режима, схожего по функционалу с xargs, он имеет возможность выполнения программ через SSH на нескольких серверах. Выбираем несколько хостов, на которых будем исполнять задачи («облако»), делим список команд между ними и посредством parallel исполняем задачи.
Создаём файл nodelist со списком машин и числом ядер, которые мы там можем утилизировать:
1/ cloudhost1.domain
1/ cloudhost2.domainЗапускаем:
commands.list:
/usr/bin/uptime
/usr/bin/uptime
krash@krash:~$ parallel --sshloginfile nodelist echo "Run on host \`hostname\`: "\; {} ::: `cat commands.list`
Run on host cloudhost1.domain:
15:54 up 358 days 19:50, 3 users, load average: 25,18, 21,35, 20,48
Run on host cloudhost2.domain:
15:54 up 358 days 15:37, 2 users, load average: 24,11, 21,35, 21,46Однако этот вариант мы тоже отметаем в силу эксплуатационных особенностей: у нас нет сведений о текущей загрузке и доступности хостов кластера, и возможно попадание в ситуацию, когда параллелизация принесёт только вред, так как один из целевых хостов будет перегружен.
Hadoop-based решения
У нас есть проверенный инструмент BI, который мы знаем и умеем использовать, связка Hadoop+Spark. Чтобы втиснуть наш код в рамки кластера, есть два решения:
Spark Python API (PySpark)
Поскольку исходная задача написана на Python, а у Spark есть соответствующий API для этого языка, можно попробовать портировать код на парадигму map/reduce. Но и этот вариант нам пришлось отвергнуть, так как стоимость адаптации была неприемлемой в рамках этой задачи.
Hadoop Streaming
Map/reduce-фреймворк Hadoop позволяет выполнять задания, написанные не только на JVM-совместимых языках программирования. В нашем конкретном случае задача называется map-only – нет reduce-стадии, так как результаты выполнения не подвергаются какой-либо последующей агрегации. Запуск задачи выглядит так:
hadoop jar $path_to_hadoop_install_dir/lib/hadoop-streaming-2.7.1.jar \
-D mapreduce.job.reduces=0 \
-D mapred.map.tasks=$number_of_jobs_to_run \
-input hdfs:///path_for_list_of_jobs/ \
-output hdfs:///path_for_saving_results \
-mapper "my_python_job.py" \
-file "my_python_job.py"Этот механизм работает следующим образом:
- Мы запрашиваем у Hadoop-кластера (YARN) ресурсы на выполнение задачи.
- YARN выделяет какое-то количество физических JVM (YARN containers) на разных хостах кластера.
- Между контейнерами делится содержимое файлов(а), лежащих в папке hdfs://path_for_list_of_jobs.
- Каждый из контейнеров, получив свой список строк из файла, запускает скрипт my_python_job.py и передаёт ему последовательно в STDIN эти строки, интерпретируя содержимое STDOUT как возвратное значение.
Пример с запуском дочернего процесса:
#!/usr/bin/python
import sys
import subprocess
def main(argv):
command = sys.stdin.readline()
subprocess.call(command.split())
if __name__ == "__main__":
main(sys.argv)И вариант с «контроллером», запускающим бизнес-логику:
#!/usr/bin/python
import sys
def main(argv):
line = sys.stdin.readline()
args = line.split()
MyJob(args).run()
if __name__ == "__main__":
main(sys.argv)Этот подход наиболее полно соответствует нашей задаче, но имеет ряд недостатков:
- Мы лишаемся потока STDOUT выполняемой задачи (он используется в качестве канала коммуникации), а хотелось бы после завершения задачи иметь возможность посмотреть логи.
- Если в будущем мы захотим запускать ещё какие-то задачи на кластере, нам придётся делать для них wrapper.
В результате анализа вышеописанных вариантов реализации мы приняли решение создать свой велосипед продукт.
Hadoop xargs
Требования, предъявляемые к разрабатываемой системе:
- Выполнение списка задач с оптимальным использованием ресурсов Hadoop-кластера.
- Условие успешного завершения – «все подзадачи отработали успешно, иначе – fail».
- Возможность сохранения подзадач для дальнейшего анализа.
- Опциональный перезапуск задачи при коде выхода, отличном от нуля.
В качестве платформы для реализации мы выбрали Apache Spark – мы с ней хорошо знакомы и умеем её «готовить».
Алгоритм работы:
- Получить из STDIN список задач.
- Сделать из него Spark RDD (распределённый массив).
- Запросить у кластера контейнеры для выполнения.
- Распределить массив задач по контейнерам.
- Для каждого контейнера запустить map-функцию, принимающую на вход текст внешней программы и производящую fork-exec.
Код всего приложения до неприличия простой, и непосредственно интерес представляет, собственно, код функции:
package com.badoo.bi.hadoop.xargs;
import lombok.extern.log4j.Log4j;
import org.apache.commons.exec.CommandLine;
import org.apache.commons.lang.NullArgumentException;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.function.VoidFunction;
import java.io.IOException;
import java.util.Arrays;
/**
* Executor of one command
* Created by krash on 01.02.17.
*/
@Log4j
public class JobExecutor implements VoidFunction<String> {
@Override
public void call(String command) throws Exception {
if (null == command || command.isEmpty()) {
throw new NullArgumentException("Command can not be empty");
}
log.info("Going to launch '" + command + "'");
Process process = null;
try {
CommandLine line = CommandLine.parse(command);
ProcessBuilder builder = getProcessBuilder();
// quotes removal in bash-style in order to pass correctly to execve()
String[] mapped = Arrays.stream(line.toStrings()).map(s -> s.replace("\'", "")).toArray(String[]::new);
builder.command(mapped);
process = builder.start();
int exitCode = process.waitFor();
log.info("Process " + command + " finished with code " + exitCode);
if (0 != exitCode) {
throw new InstantiationException("Process " + command + " exited with non-zero exit code (" + exitCode + ")");
}
} catch (InterruptedException err) {
if (process.isAlive()) {
process.destroyForcibly();
}
} catch (IOException err) {
throw new InstantiationException(err.getMessage());
}
}
ProcessBuilder getProcessBuilder() {
return new ProcessBuilder().inheritIO();
}
}Сборка
Сборка приложения производится стандартным для Java-мира инструментом – Maven. Единственное различие – в среде, в которой будет запускаться приложение. Если вы не используете Spark для вашего кластера, то сборка выглядит так:
mvn clean installВ этом случае получившийся JAR-файл будет содержать в себе исходный код Spark’а. В случае, если на машине, с которой производится запуск приложения, установлен клиентский код Spark, он должен быть исключён из сборки:
mvn clean install -Dwork.scope=providedВ результате такой сборки файл приложения будет существенно меньше (15 Кб против 80 Мб).
Запуск
Пусть у нас есть файл commands.list со списком заданий следующего вида:
/bin/sleep 10
/bin/sleep 20
/bin/sleep 30Запускаем приложение:
akrasheninnikov@cloududs1.mlan:~> cat log.log | /local/spark/bin/spark-submit --conf "spark.master=yarn-client" hadoop-xargs-1.0.jar
17/02/10 15:04:26 INFO Application: Starting application
17/02/10 15:04:26 INFO Application: Got 3 jobs:
17/02/10 15:04:26 INFO Application: /bin/sleep 10
17/02/10 15:04:26 INFO Application: /bin/sleep 20
17/02/10 15:04:26 INFO Application: /bin/sleep 30
17/02/10 15:04:26 INFO Application: Application name: com.badoo.bi.hadoop.xargs.Main
17/02/10 15:04:26 INFO Application: Execution environment: yarn-client
17/02/10 15:04:26 INFO Application: Explicit executor count was not specified, making same as job count
17/02/10 15:04:26 INFO Application: Initializing Spark
17/02/10 15:04:40 INFO Application: Initialization completed, starting jobs
17/02/10 15:04:52 INFO Application: Command '/bin/sleep 10' finished on host bihadoop40.mlan
17/02/10 15:05:02 INFO Application: Command '/bin/sleep 20' finished on host bihadoop31.mlan
17/02/10 15:05:12 INFO Application: Command '/bin/sleep 30' finished on host bihadoop18.mlan
17/02/10 15:05:13 INFO Application: All the jobs completed in 0:00:32.258После завершения работы через GUI YARN мы можем получить логи приложений, которые запускали (пример для команды uptime):
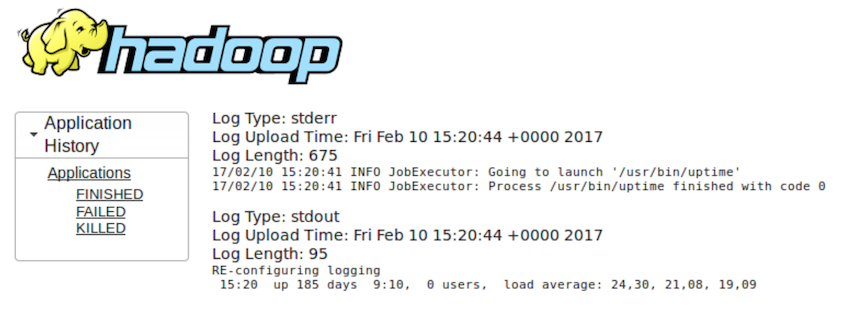
В случае невозможности выполнения команды весь процесс выглядит следующим образом:
akrasheninnikov@cloududs1.mlan:~> echo "/bin/unexistent_command" | /local/spark/bin/spark-submit --conf "spark.master=yarn-client" --conf "spark.yarn.queue=uds.misc" --conf "spark.driver.host=10.10.224.14" hadoop-xargs-1.0.jar
17/02/10 15:12:14 INFO Application: Starting application
17/02/10 15:12:14 INFO Main: Expect commands to be passed to STDIN, one per line
17/02/10 15:12:14 INFO Application: Got 1 jobs:
17/02/10 15:12:14 INFO Application: /bin/unexistent_command
17/02/10 15:12:14 INFO Application: Application name: com.badoo.bi.hadoop.xargs.Main
17/02/10 15:12:14 INFO Application: Execution environment: yarn-client
17/02/10 15:12:14 INFO Application: Explicit executor count was not specified, making same as job count
17/02/10 15:12:14 INFO Application: Initializing Spark
17/02/10 15:12:27 INFO Application: Initialization completed, starting jobs
17/02/10 15:12:29 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 1 times
17/02/10 15:12:29 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 2 times
17/02/10 15:12:30 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 3 times
17/02/10 15:12:30 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 4 times
17/02/10 15:12:30 ERROR Main: FATAL ERROR: Failed to execute all the jobs
java.lang.InstantiationException: Cannot run program "/bin/unexistent_command": error=2, No such file or directory
at com.badoo.bi.hadoop.xargs.JobExecutor.call(JobExecutor.java:56)
at com.badoo.bi.hadoop.xargs.JobExecutor.call(JobExecutor.java:16)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachAsync$1.apply(JavaRDDLike.scala:690)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachAsync$1.apply(JavaRDDLike.scala:690)
at scala.collection.Iterator$class.foreach(Iterator.scala:727)
at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28)
at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$15.apply(AsyncRDDActions.scala:118)
at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$15.apply(AsyncRDDActions.scala:118)
at org.apache.spark.SparkContext$$anonfun$37.apply(SparkContext.scala:1984)
at org.apache.spark.SparkContext$$anonfun$37.apply(SparkContext.scala:1984)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:88)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)Заключение
Разработанное решение позволило нам соблюсти все условия исходной задачи:
- Мы получаем у Hadoop ядра для запуска нашего приложения, согласно требованиям (числу ядер) – максимальный уровень параллелизации.
- При выдаче ресурсов учитываются загрузка и доступность хостов (за счёт API YARN).
- Мы сохраняем содержимое STDOUT/ STDERR всех задач, которые запускаем.
- Не пришлось переписывать исходное приложение.
- "Write once, run anywhere" © Sun Microsystems – разработанное решение теперь можно использовать для запуска любых других задач.
Радость от полученного результата была столь велика, что мы не могли не поделиться ею с вами. Исходные коды Hadoop xargs мы опубликовали на GitHub.
