Сбор, хранение, преобразование и презентация данных — основные задачи, стоящие перед инженерами данных (англ. data engineer). Отдел Business Intelligence Badoo в сутки принимает и обрабатывает больше 20 млрд событий, отправляемых с пользовательских устройств, или 2 Тб входящих данных.
Исследование и интерпретация всех этих данных — не всегда тривиальные задачи, иногда возникает необходимость выйти за рамки возможностей готовых баз данных. И если вы набрались смелости и решили делать что-то новое, то следует сначала ознакомиться с принципами работы существующих решений.
Словом, любопытствующим и сильным духом разработчикам и адресована эта статья. В ней вы найдёте описание традиционной модели исполнения запросов в реляционных базах данных на примере демонстрационного языка PigletQL.
Содержание
- Предыстория
- Структура интерпретатора SQL
- Модель Volcano и исполнение запросов
- PigletQL
- Выводы
- Литература
Предыстория
Наша группа инженеров занимается бэкендами и интерфейсами, предоставляющими возможности для анализа и исследования данных внутри компании (к слову, мы расширяемся). Наши стандартные инструменты — распределённая база данных на десятки серверов (Exasol) и кластер Hadoop на сотню машин (Hive и Presto).
Большая часть запросов к этим базам данных — аналитические, то есть затрагивающие от сотен тысяч до миллиардов записей. Их выполнение занимает минуты, десятки минут или даже часы в зависимости от используемого решения и сложности запроса. При ручной работе пользователя-аналитика такое время считается приемлемым, но для интерактивного исследования через пользовательский интерфейс не подходит.
Со временем мы выделили популярные аналитические запросы и запросы, с трудом излагаемые в терминах SQL, и разработали под них небольшие специализированные базы данных. Они хранят подмножество данных в подходящем для легковесных алгоритмов сжатия формате (например, streamvbyte), что позволяет хранить в памяти одной машины данные за несколько дней и выполнять запросы за секунды.
Первые языки запросов к этим данным и их интерпретаторы были реализованы по наитию, нам приходилось постоянно их дорабатывать, и каждый раз это занимало непозволительно много времени.
Языки запросов получались недостаточно гибкими, хотя очевидных причин для ограничения их возможностей не было. В итоге мы обратились к опыту разработчиков интерпретаторов SQL, благодаря чему смогли частично решить возникшие проблемы.
Ниже я расскажу про самую распространённую модель выполнения запросов в реляционных базах данных — Volcano. К статье прилагается исходный код интерпретатора примитивного диалекта SQL — PigletQL, поэтому все интересующиеся легко смогут ознакомиться с деталями в репозитории.
Структура интерпретатора SQL
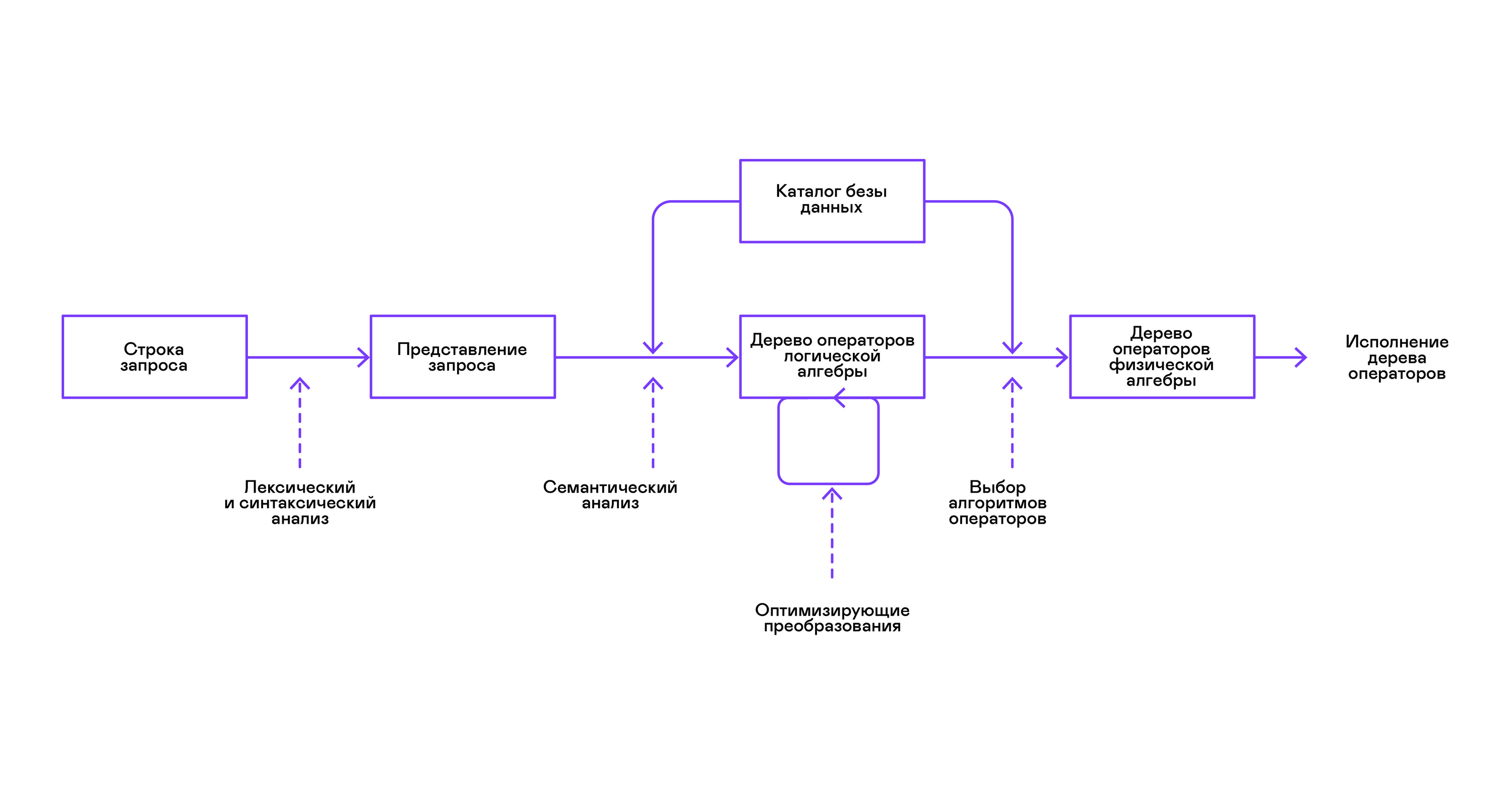
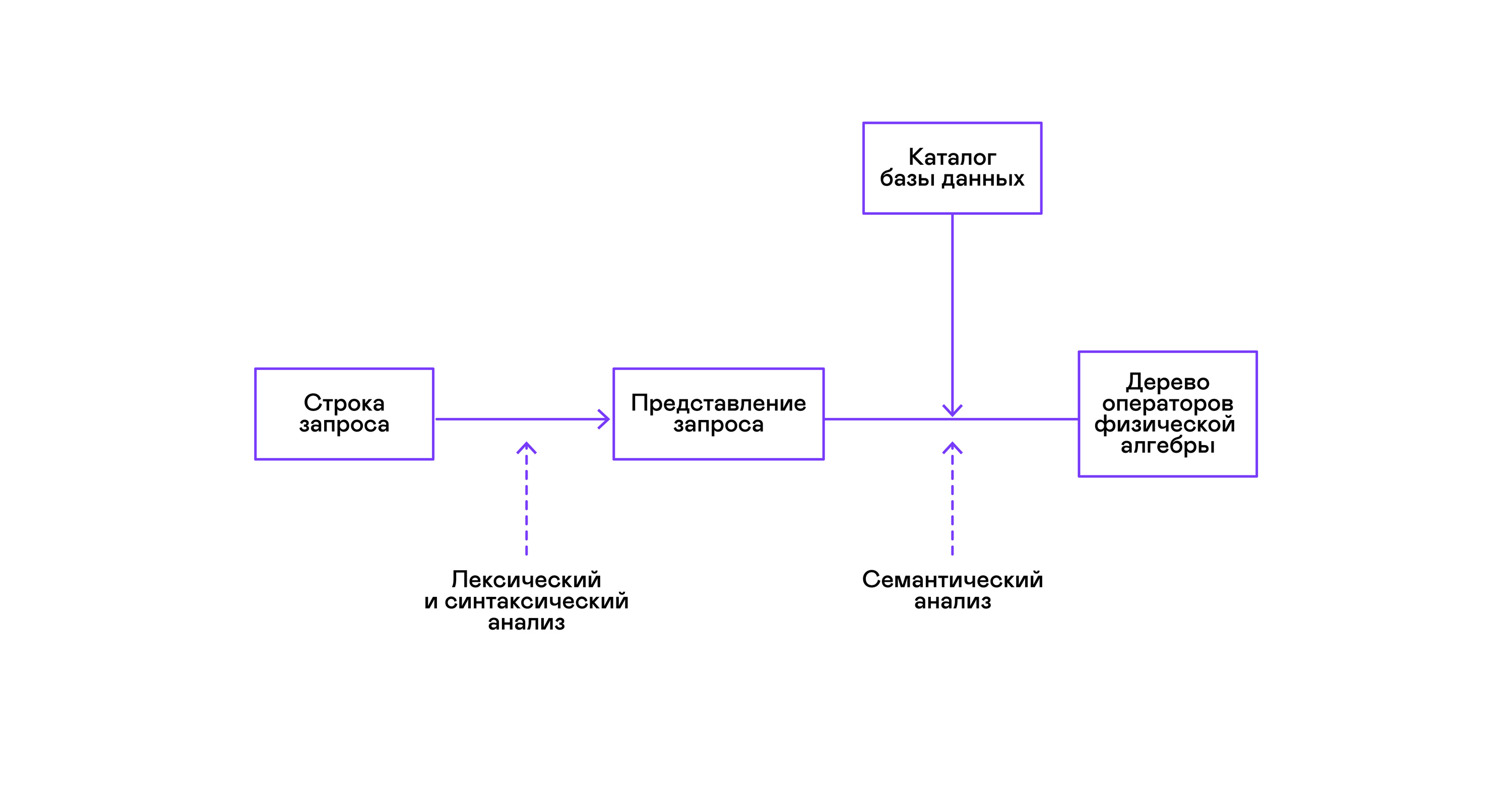
Большая часть популярных баз данных предоставляет интерфейс к данным в виде декларативного языка запросов SQL. Запрос в виде строки преобразуется синтаксическим анализатором в описание запроса, похожее на дерево абстрактного синтаксиса. Несложные запросы возможно выполнять уже на этом этапе, однако для оптимизирующих преобразований и последующего исполнения это представление неудобно. В известных мне базах данных для этих целей вводятся промежуточные представления.
Образцом для промежуточных представлений стала реляционная алгебра. Это язык, где явно описываются преобразования (операторы), проводимые над данными: выбор подмножества данных по предикату, соединение данных из разных источников и т. д. Кроме того, реляционная алгебра — алгебра в математическом смысле, то есть для неё формализовано большое количество эквивалентных преобразований. Поэтому над запросом в форме дерева операторов реляционной алгебры удобно проводить оптимизирующие преобразования.
Существуют важные отличия между внутренними представлениями в базах данных и оригинальной реляционной алгеброй, поэтому правильнее называть её логической алгеброй.
Проверка валидности запроса обычно проводится при компиляции первоначального представления запроса в операторы логической алгебры и соответствует стадии семантического анализа в обычных компиляторах. Роль таблицы символов в базах данных играет каталог базы данных, в котором хранится информация о схеме и метаданных базы данных: таблицах, колонках таблиц, индексах, правах пользователей и т. д.
По сравнению с интерпретаторами языков общего назначения у интерпретаторов баз данных есть ещё одна особенность: различия в объёме данных и метаинформации о данных, к которым предполагается делать запросы. В таблицах, или отношениях в терминах реляционной алгебры, может быть разное количество данных, на некоторых колонках (атрибутах отношений) могут быть построены индексы и т. д. То есть в зависимости от схемы базы данных и объёма данных в таблицах запрос надо выполнять разными алгоритмами, и использовать их в разном порядке.
Для решения этой задачи вводится ещё одно промежуточное представление — физическая алгебра. В зависимости от наличия индексов на колонках, объёма данных в таблицах и структуры дерева логической алгебры предлагаются разные формы дерева физической алгебры, из которых выбирается оптимальный вариант. Именно это дерево показывают базе данных в качестве плана запроса. В обычных компиляторах этому этапу условно соответствуют этапы распределения регистров, планирования и выбора инструкций.
Последним этапом работы интерпретатора является непосредственно исполнение дерева операторов физической алгебры.
Модель Volcano и исполнение запросов
Интерпретаторы дерева физической алгебры в закрытых коммерческих базах данных использовались практически всегда, но академическая литература обычно ссылается на экспериментальный оптимизатор Volcano, разрабатывавшийся в начале 90-х.
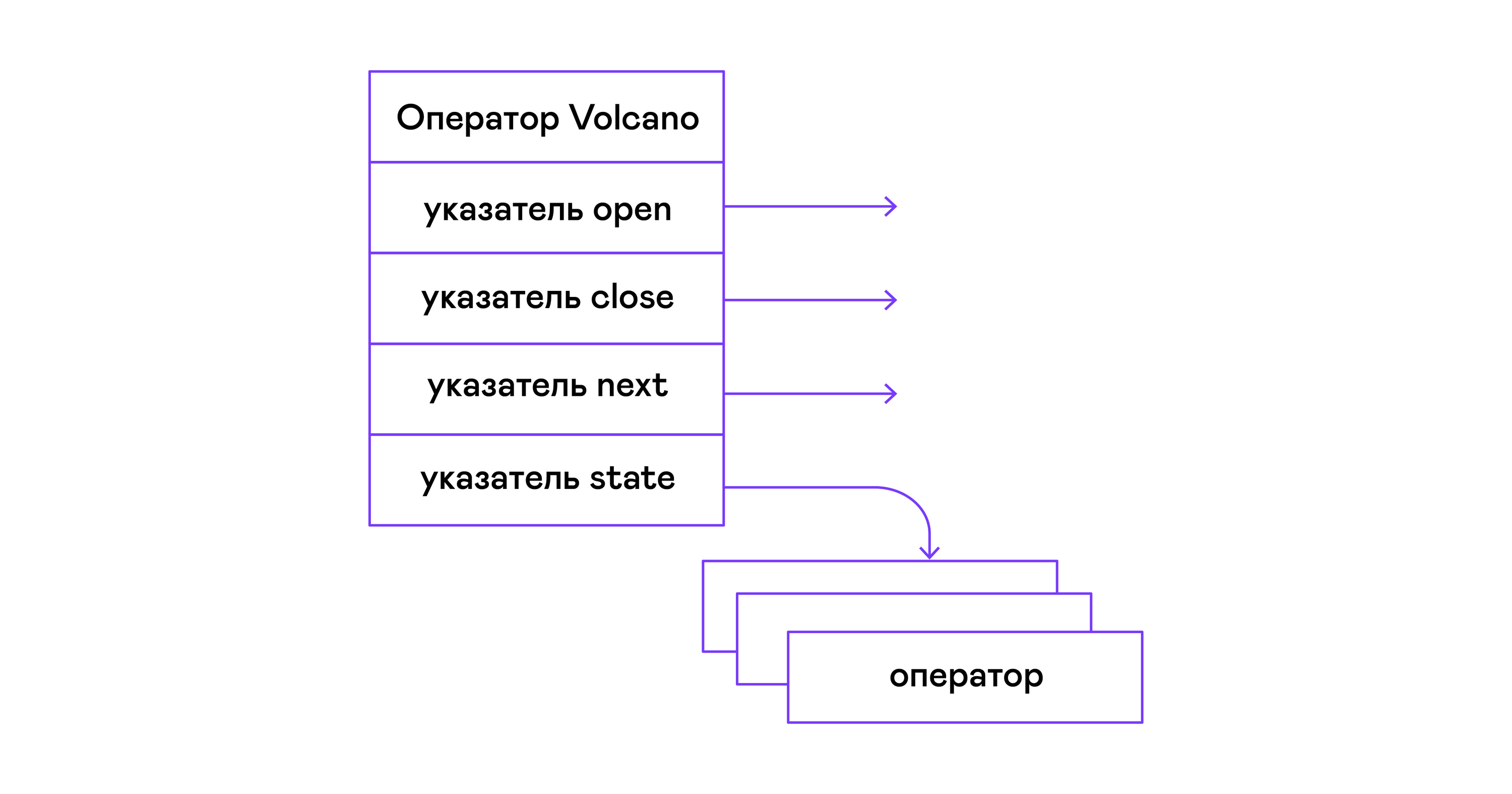
В модели Volcano каждый оператор дерева физической алгебры превращается в структуру с тремя функциями: open, next, close. Помимо функций, оператор содержит рабочее состояние — state. Функция open инициирует состояние оператора, функция next возвращает либо следующий кортеж (англ. tuple), либо NULL, если кортежей не осталось, функция close завершает работу оператора:
Операторы могут быть вложены друг в друга, чтобы сформировать дерево операторов физической алгебры. Каждый оператор, таким образом, перебирает кортежи либо существующего на реальном носителе отношения, либо виртуального отношения, формируемого перебором кортежей вложенных операторов:
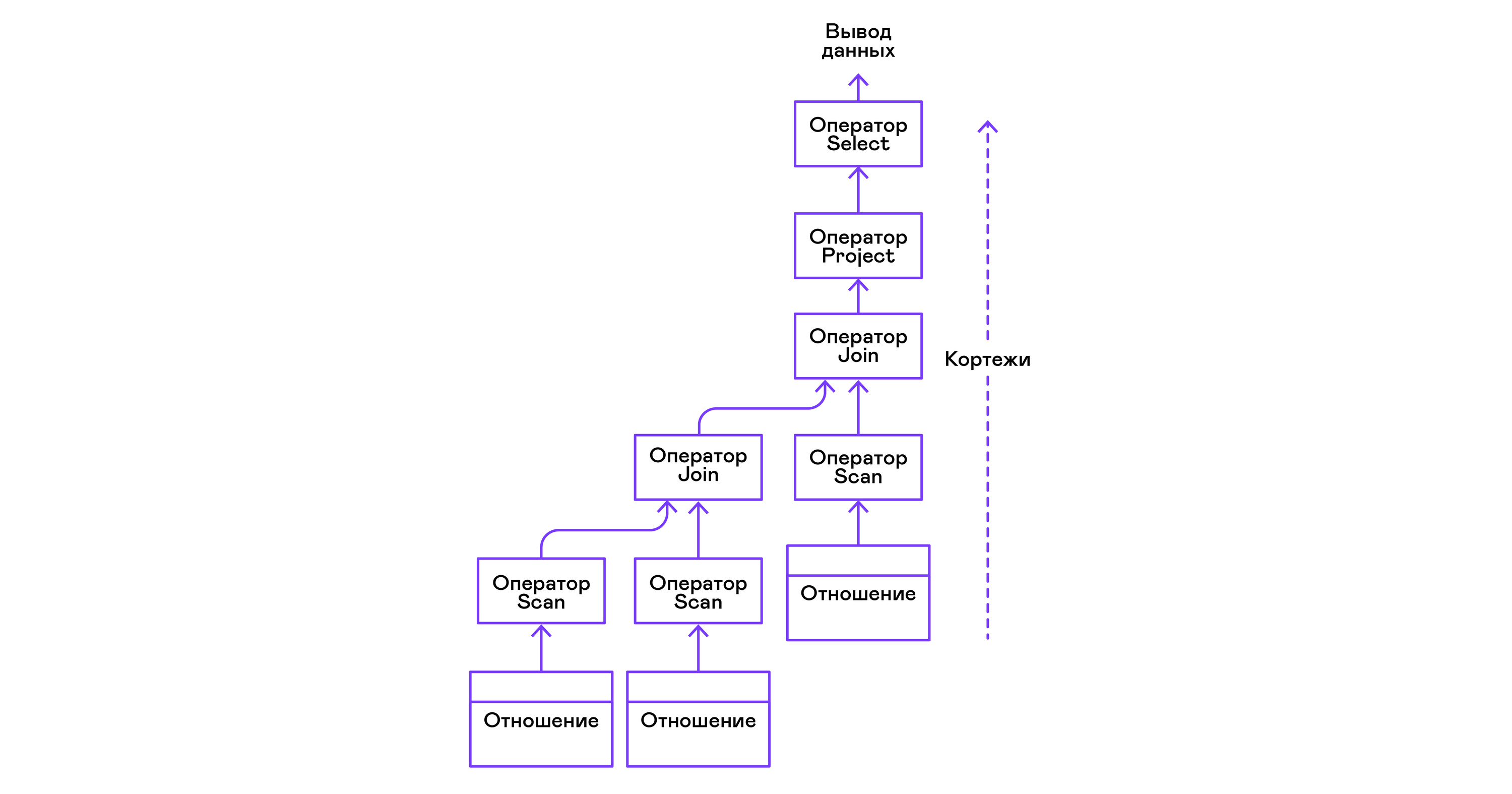
В терминах современных языков высокого уровня дерево таких операторов представляет собой каскад итераторов.
От модели Volcano отталкиваются даже промышленные интерпретаторы запросов в реляционных СУБД, поэтому именно её я взял в качестве основы интерпретатора PigletQL.
PigletQL
Для демонстрации модели я разработал интерпретатор ограниченного языка запросов PigletQL. Он написан на C, поддерживает создание таблиц в стиле SQL, но ограничивается единственным типом — 32-битными положительными целыми числами. Все таблицы располагаются в памяти. Система работает в один поток и не имеет механизма транзакций.
В PigletQL нет оптимизатора и запросы SELECT компилируются прямо в дерево операторов физической алгебры. Остальные запросы (CREATE TABLE и INSERT) работают непосредственно из первичных внутренних представлений.
Пример сессии пользователя в PigletQL:
> ./pigletql
> CREATE TABLE tab1 (col1,col2,col3);
> INSERT INTO tab1 VALUES (1,2,3);
> INSERT INTO tab1 VALUES (4,5,6);
> SELECT col1,col2,col3 FROM tab1;
col1 col2 col3
1 2 3
4 5 6
rows: 2
> SELECT col1 FROM tab1 ORDER BY col1 DESC;
col1
4
1
rows: 2Лексический и синтаксический анализаторы
PigletQL — очень простой язык, и использования сторонних инструментов на этапах лексического и синтаксического анализа его реализация не потребовала.
Лексический анализатор написан вручную. Из строки запроса создаётся объект анализатора (scanner_t), который и отдаёт токены один за другим:
scanner_t *scanner_create(const char *string);
void scanner_destroy(scanner_t *scanner);
token_t scanner_next(scanner_t *scanner);Синтаксический анализ проводится методом рекурсивного спуска. Сначала создаётся объект parser_t, который, получив лексический анализатор (scanner_t), заполняет объект query_t информацией о запросе:
query_t *query_create(void);
void query_destroy(query_t *query);
parser_t *parser_create(void);
void parser_destroy(parser_t *parser);
bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);Результат разбора в query_t — один из трёх поддерживаемых PigletQL видов запроса:
typedef enum query_tag {
QUERY_SELECT,
QUERY_CREATE_TABLE,
QUERY_INSERT,
} query_tag;
/*
* ... query_select_t, query_create_table_t, query_insert_t definitions ...
**/
typedef struct query_t {
query_tag tag;
union {
query_select_t select;
query_create_table_t create_table;
query_insert_t insert;
} as;
} query_t;Самый сложный вид запросов в PigletQL — SELECT. Ему соответствует структура данных query_select_t:
typedef struct query_select_t {
/* Attributes to output */
attr_name_t attr_names[MAX_ATTR_NUM];
uint16_t attr_num;
/* Relations to get tuples from */
rel_name_t rel_names[MAX_REL_NUM];
uint16_t rel_num;
/* Predicates to apply to tuples */
query_predicate_t predicates[MAX_PRED_NUM];
uint16_t pred_num;
/* Pick an attribute to sort by */
bool has_order;
attr_name_t order_by_attr;
sort_order_t order_type;
} query_select_t;Структура содержит описание запроса (массив запрошенных пользователем атрибутов), список источников данных — отношений, массив предикатов, фильтрующих кортежи, и информацию об атрибуте, используемом для сортировки результатов.
Семантический анализатор
Фаза семантического анализа в обычном SQL включает проверку существования перечисленных таблиц, колонок в таблицах и проверку типов в выражениях запроса. Для проверок, связанных с таблицами и колонками, используется каталог базы данных, где хранится вся информация о структуре данных.
В PigletQL сложных выражений не бывает, поэтому проверка запроса сводится к проверке метаданных таблиц и колонок по каталогу. Запросы SELECT, например, проверяются функцией validate_select. Приведу её в сокращённом виде:
static bool validate_select(catalogue_t *cat, const query_select_t *query)
{
/* All the relations should exist */
for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) {
if (catalogue_get_relation(cat, query->rel_names[rel_i]))
continue;
fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]);
return false;
}
/* Relation names should be unique */
if (!rel_names_unique(query->rel_names, query->rel_num))
return false;
/* Attribute names should be unique */
if (!attr_names_unique(query->attr_names, query->attr_num))
return false;
/* Attributes should be present in relations listed */
/* ... */
/* ORDER BY attribute should be available in the list of attributes chosen */
/* ... */
/* Predicate attributes should be available in the list of attributes projected */
/* ... */
return true;
}
Если запрос валиден, то следующим этапом становится компиляция дерева разбора в дерево операторов.
Компиляция запросов в промежуточное представление
В полноценных интерпретаторах SQL промежуточных представлений, как правило, два: логическая и физическая алгебра.
Простой интерпретатор PigletQL запросы CREATE TABLE и INSERT выполняет непосредственно из своих деревьев разбора, то есть структур query_create_table_t и query_insert_t. Более сложные запросы SELECT компилируются в единственное промежуточное представление, которое и будет исполняться интерпретатором.
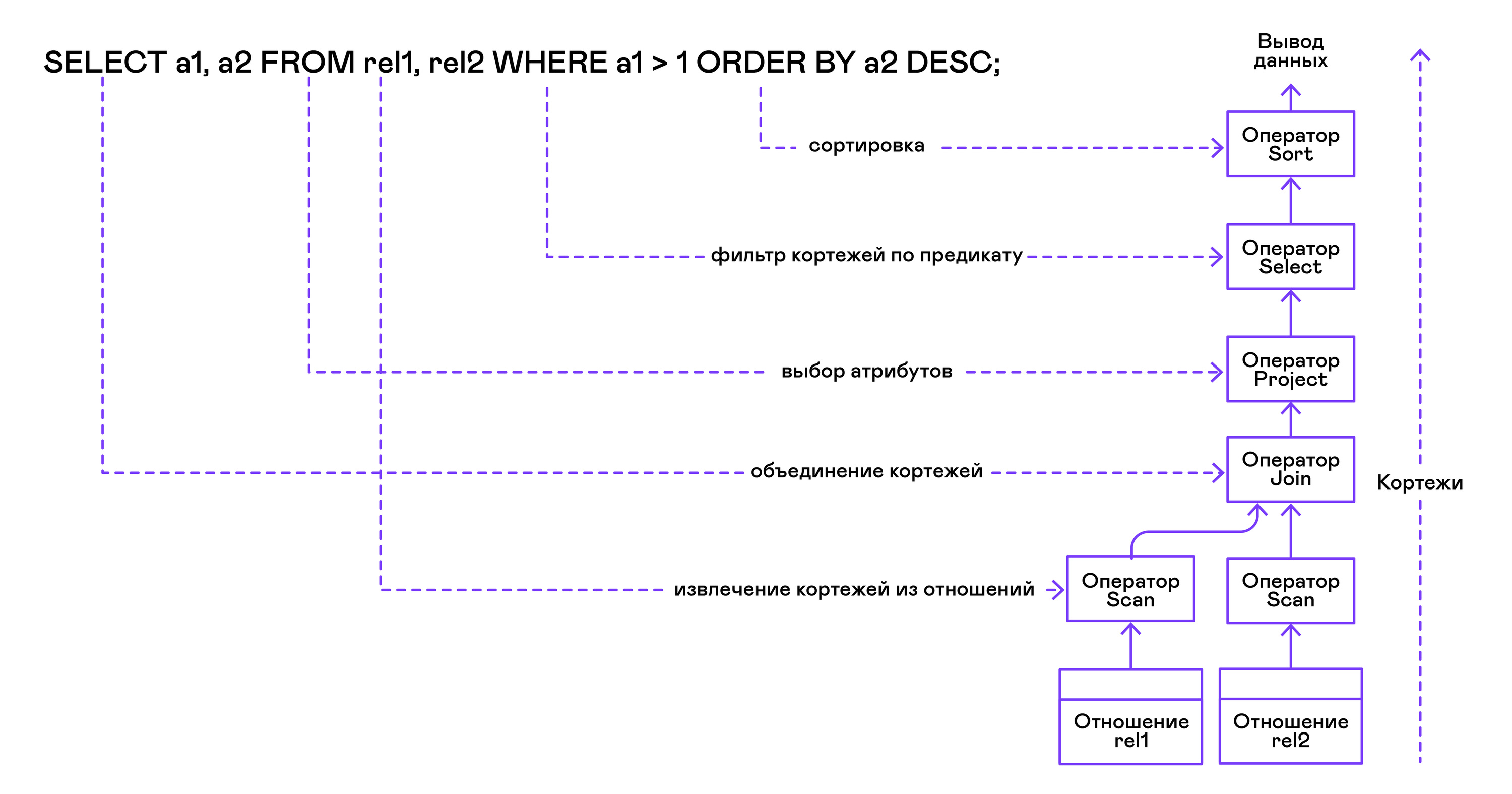
Дерево операторов строится от листьев к корню в следующей последовательности:
Из правой части запроса ("… FROM relation1, relation2, …") получаются имена искомых отношений, для каждого из которых создаётся оператор scan.
Извлекающие кортежи из отношений операторы scan объединяются в левостороннее двоичное дерево через оператор join.
Атрибуты, запрошенные пользователем ("SELECT attr1, attr2, …"), выбираются оператором project.
Если указаны какие-либо предикаты ("… WHERE a=1 AND b>10 …"), то к дереву сверху добавляется оператор select.
Если указан способ сортировки результата ("… ORDER BY attr1 DESC"), то к вершине дерева добавляется оператор sort.
Компиляция в коде PigletQL:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query)
{
/* Current root operator */
operator_t *root_op = NULL;
/* 1. Scan ops */
/* 2. Join ops*/
{
size_t rel_i = 0;
relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]);
root_op = scan_op_create(rel);
rel_i += 1;
for (; rel_i < query->rel_num; rel_i++) {
rel = catalogue_get_relation(cat, query->rel_names[rel_i]);
operator_t *scan_op = scan_op_create(rel);
root_op = join_op_create(root_op, scan_op);
}
}
/* 3. Project */
root_op = proj_op_create(root_op, query->attr_names, query->attr_num);
/* 4. Select */
if (query->pred_num > 0) {
operator_t *select_op = select_op_create(root_op);
for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) {
query_predicate_t predicate = query->predicates[pred_i];
/* Add a predicate to the select operator */
/* ... */
}
root_op = select_op;
}
/* 5. Sort */
if (query->has_order)
root_op = sort_op_create(root_op, query->order_by_attr, query->order_type);
return root_op;
}После формирования дерева обычно проводятся оптимизирующие преобразования, но PigletQL сразу переходит к этапу исполнения промежуточного представления.
Исполнение промежуточного представления
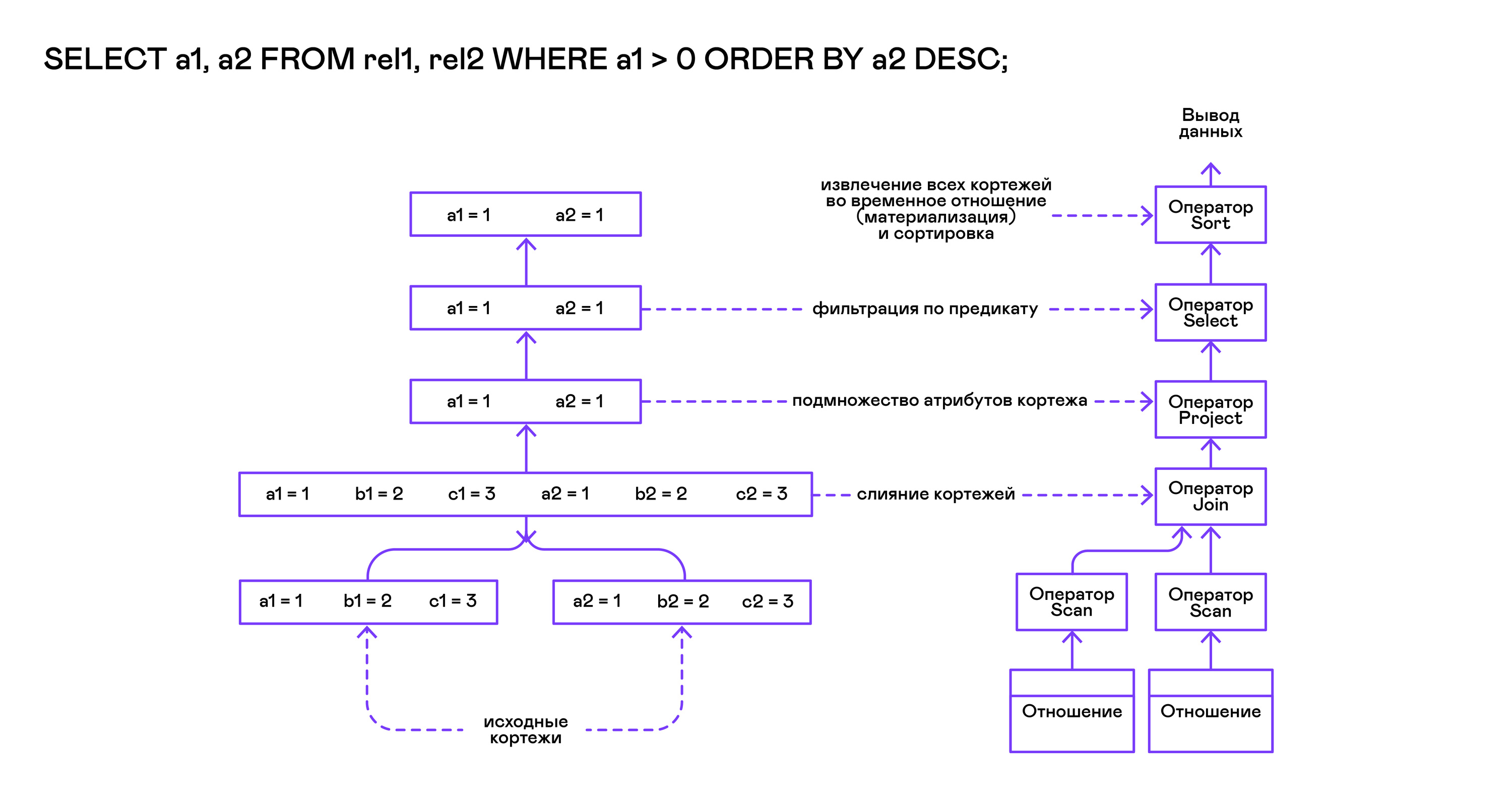
Модель Volcano подразумевает интерфейс работы с операторами через три общие для них операции open/next/close. В сущности, каждый оператор Volcano — итератор, из которого кортежи «вытягиваются» один за другим, поэтому такой подход к исполнению ещё называется pull-моделью.
Каждый из этих итераторов может сам вызывать те же функции вложенных итераторов, формировать временные таблицы с промежуточными результатами и преобразовывать входящие кортежи.
Выполнение запросов SELECT в PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query)
{
/* Compile the operator tree: */
operator_t *root_op = compile_select(cat, query);
/* Eval the tree: */
{
root_op->open(root_op->state);
size_t tuples_received = 0;
tuple_t *tuple = NULL;
while((tuple = root_op->next(root_op->state))) {
/* attribute list for the first row only */
if (tuples_received == 0)
dump_tuple_header(tuple);
/* A table of tuples */
dump_tuple(tuple);
tuples_received++;
}
printf("rows: %zu\n", tuples_received);
root_op->close(root_op->state);
}
root_op->destroy(root_op);
return true;
}Запрос сначала компилируется функцией compile_select, возвращающей корень дерева операторов, после чего у корневого оператора вызываются те самые функции open/next/close. Каждый вызов next возвращает либо следующий кортеж, либо NULL. В последнем случае это означает, что все кортежи были извлечены, и следует вызвать закрывающую итератор функцию close.
Полученные кортежи пересчитываются и выводятся таблицей в стандартный поток вывода.
Операторы
Самое интересное в PigletQL — дерево операторов. Я покажу устройство некоторых из них.
Интерфейс у операторов общий и состоит из указателей на функции open/next/close и дополнительной служебной функции destroy, высвобождающей ресурсы всего дерева операторов разом:
typedef void (*op_open)(void *state);
typedef tuple_t *(*op_next)(void *state);
typedef void (*op_close)(void *state);
typedef void (*op_destroy)(operator_t *op);
/* The operator itself is just 4 pointers to related ops and operator state */
struct operator_t {
op_open open;
op_next next;
op_close close;
op_destroy destroy;
void *state;
} ;Помимо функций, в операторе может содержаться произвольное внутреннее состояние (указатель state).
Ниже я разберу устройство двух интересных операторов: простейшего scan и создающего промежуточное отношение sort.
Оператор scan
Оператор, с которого начинается выполнение любого запроса, — scan. Он просто перебирает все кортежи отношения. Внутреннее состояние scan — это указатель на отношение, откуда будут извлекаться кортежи, индекс следующего кортежа в отношении и структура-ссылка на текущий кортеж, переданный пользователю:
typedef struct scan_op_state_t {
/* A reference to the relation being scanned */
const relation_t *relation;
/* Next tuple index to retrieve from the relation */
uint32_t next_tuple_i;
/* A structure to be filled with references to tuple data */
tuple_t current_tuple;
} scan_op_state_t;Для создания состояния оператора scan необходимо отношение-источник; всё остальное (указатели на соответствующие функции) уже известно:
operator_t *scan_op_create(const relation_t *relation)
{
operator_t *op = calloc(1, sizeof(*op));
assert(op);
*op = (operator_t) {
.open = scan_op_open,
.next = scan_op_next,
.close = scan_op_close,
.destroy = scan_op_destroy,
};
scan_op_state_t *state = calloc(1, sizeof(*state));
assert(state);
*state = (scan_op_state_t) {
.relation = relation,
.next_tuple_i = 0,
.current_tuple.tag = TUPLE_SOURCE,
.current_tuple.as.source.tuple_i = 0,
.current_tuple.as.source.relation = relation,
};
op->state = state;
return op;
}Операции open/close в случае scan сбрасывают ссылки обратно на первый элемент отношения:
void scan_op_open(void *state)
{
scan_op_state_t *op_state = (typeof(op_state)) state;
op_state->next_tuple_i = 0;
tuple_t *current_tuple = &op_state->current_tuple;
current_tuple->as.source.tuple_i = 0;
}
void scan_op_close(void *state)
{
scan_op_state_t *op_state = (typeof(op_state)) state;
op_state->next_tuple_i = 0;
tuple_t *current_tuple = &op_state->current_tuple;
current_tuple->as.source.tuple_i = 0;
}
Вызов next либо возвращает следующий кортеж, либо NULL, если кортежей в отношении больше нет:
tuple_t *scan_op_next(void *state)
{
scan_op_state_t *op_state = (typeof(op_state)) state;
if (op_state->next_tuple_i >= op_state->relation->tuple_num)
return NULL;
tuple_source_t *source_tuple = &op_state->current_tuple.as.source;
source_tuple->tuple_i = op_state->next_tuple_i;
op_state->next_tuple_i++;
return &op_state->current_tuple;
}
Оператор sort
Оператор sort выдаёт кортежи в заданном пользователем порядке. Для этого надо создать временное отношение с кортежами, полученными из вложенных операторов, и отсортировать его.
Внутреннее состояние оператора:
typedef struct sort_op_state_t {
operator_t *source;
/* Attribute to sort tuples by */
attr_name_t sort_attr_name;
/* Sort order, descending or ascending */
sort_order_t sort_order;
/* Temporary relation to be used for sorting*/
relation_t *tmp_relation;
/* Relation scan op */
operator_t *tmp_relation_scan_op;
} sort_op_state_t;Сортировка проводится по указанным в запросе атрибутам (sort_attr_name и sort_order) над временным отношением (tmp_relation). Всё это происходит во время вызова функции open:
void sort_op_open(void *state)
{
sort_op_state_t *op_state = (typeof(op_state)) state;
operator_t *source = op_state->source;
/* Materialize a table to be sorted */
source->open(source->state);
tuple_t *tuple = NULL;
while((tuple = source->next(source->state))) {
if (!op_state->tmp_relation) {
op_state->tmp_relation = relation_create_for_tuple(tuple);
assert(op_state->tmp_relation);
op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation);
}
relation_append_tuple(op_state->tmp_relation, tuple);
}
source->close(source->state);
/* Sort it */
relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order);
/* Open a scan op on it */
op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state);
}Перебор элементов временного отношения проводится временным оператором tmp_relation_scan_op:
tuple_t *sort_op_next(void *state)
{
sort_op_state_t *op_state = (typeof(op_state)) state;
return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);;
}
Временное отношение деаллоцируется в функции close:
void sort_op_close(void *state)
{
sort_op_state_t *op_state = (typeof(op_state)) state;
/* If there was a tmp relation - destroy it */
if (op_state->tmp_relation) {
op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state);
scan_op_destroy(op_state->tmp_relation_scan_op);
relation_destroy(op_state->tmp_relation);
op_state->tmp_relation = NULL;
}
}
Здесь хорошо видно, почему операции сортировки на колонках без индексов могут занимать довольно много времени.
Примеры работы
Приведу несколько примеров запросов PigletQL и соответствующие им деревья физической алгебры.
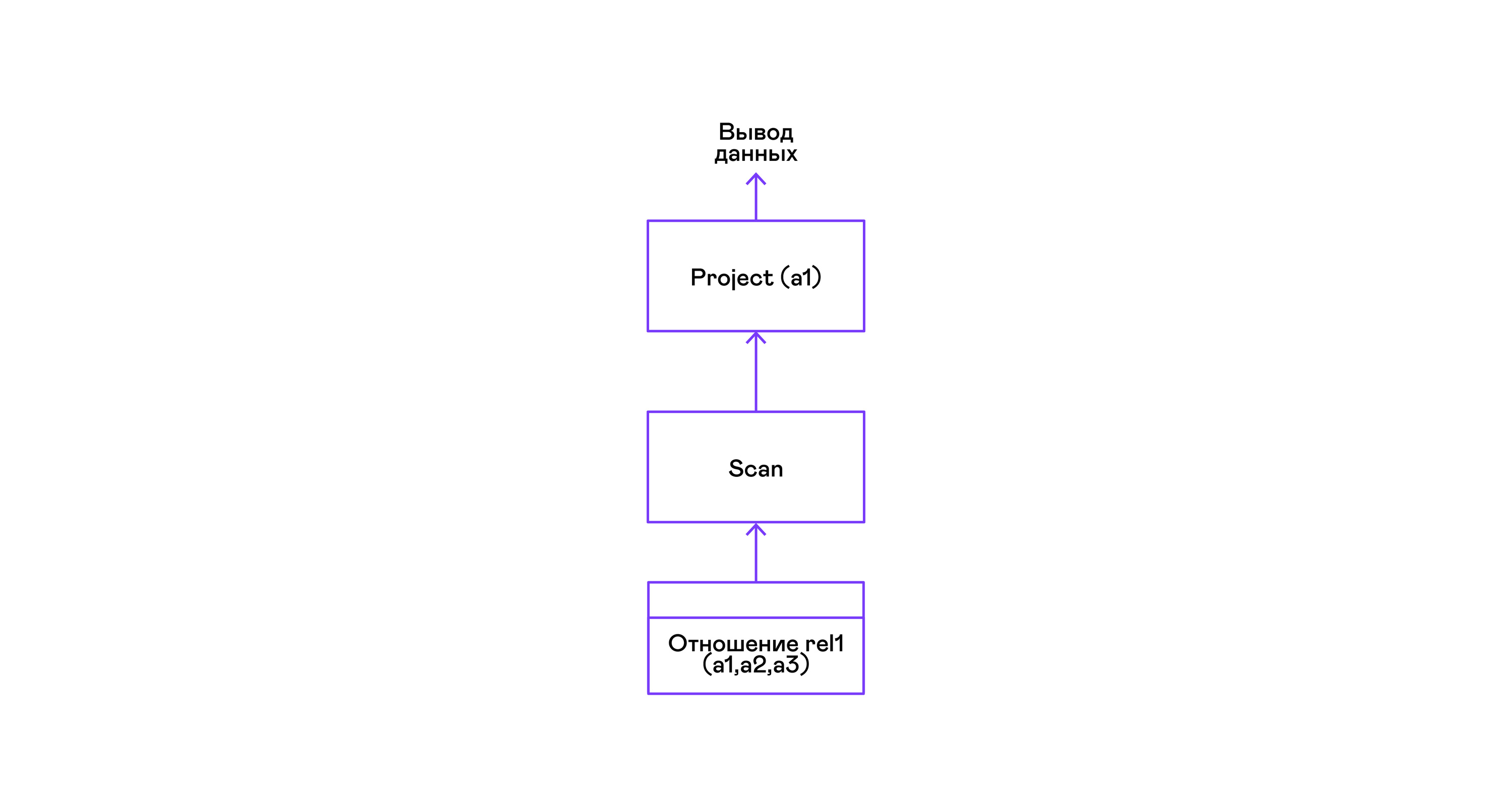
Самый простой пример, где выбираются все кортежи из отношения:
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> select a1 from rel1;
a1
1
4
rows: 2
>Для простейшего из запросов используются только извлекающий кортежи из отношения scan и выделяющий у кортежей единственный атрибут project:
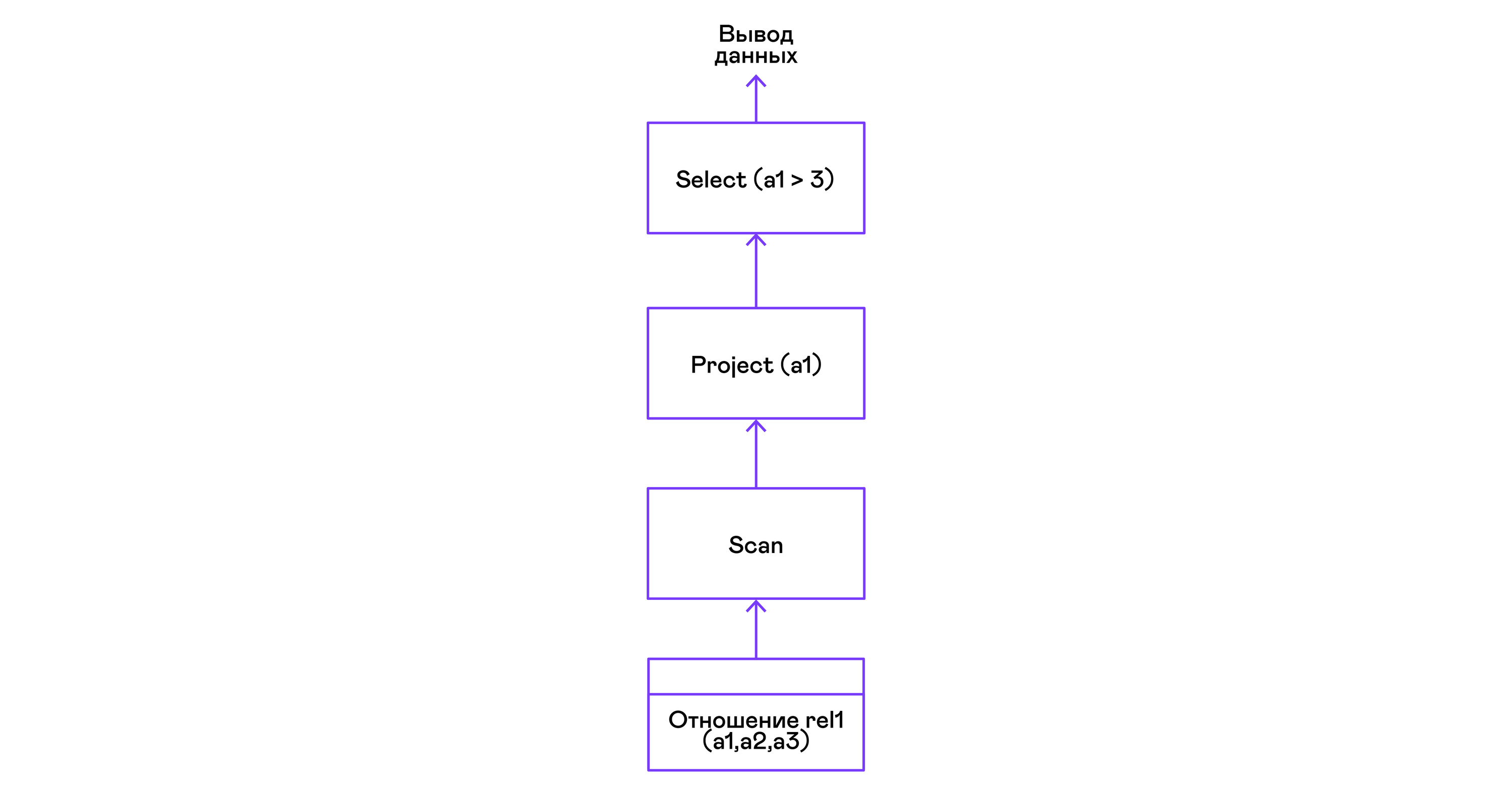
Выбор кортежей с предикатом:
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> select a1 from rel1 where a1 > 3;
a1
4
rows: 1
>Предикаты выражаются оператором select:
Выбор кортежей с сортировкой:
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> select a1 from rel1 order by a1 desc;
a1
4
1
rows: 2Оператор сортировки scan в вызове open создает (материализует) временное отношение, помещает туда все входящие кортежи и сортирует целиком. После этого в вызовах next он выводит кортежи из временного отношения в указанном пользователем порядке:

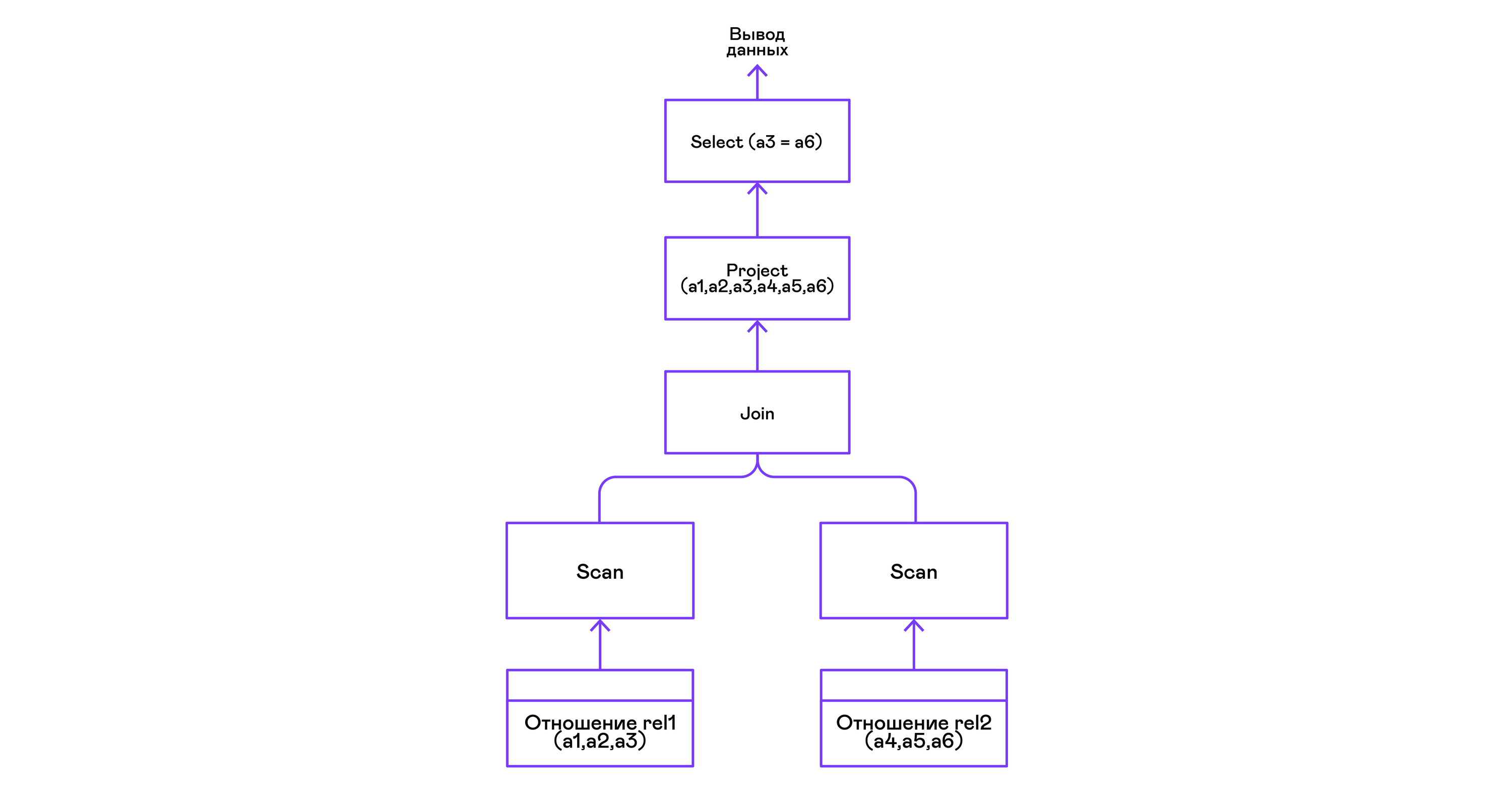
Соединение кортежей двух отношений с предикатом:
> ./pigletql
> create table rel1 (a1,a2,a3);
> insert into rel1 values (1,2,3);
> insert into rel1 values (4,5,6);
> create table rel2 (a4,a5,a6);
> insert into rel2 values (7,8,6);
> insert into rel2 values (9,10,6);
> select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6;
a1 a2 a3 a4 a5 a6
4 5 6 7 8 6
4 5 6 9 10 6
rows: 2Оператор join в PigletQL не использует никаких сложных алгоритмов, а просто формирует декартово произведение из множеств кортежей левого и правого поддеревьев. Это очень неэффективно, но для демонстрационного интерпретатора сойдет:
Выводы
Напоследок замечу, что если вы делаете интерпретатор языка, похожего на SQL, то вам, вероятно, стоит просто взять любую из многочисленных доступных реляционных баз данных. В современные оптимизаторы и интерпретаторы запросов популярных баз данных вложены тысячи человеко-лет, и разработка даже простейших баз данных общего назначения занимает в лучшем случае годы.
Демонстрационный язык PigletQL имитирует работу интерпретатора SQL, но реально в работе мы используем только отдельные элементы архитектуры Volcano и только для тех (редких!) видов запросов, которые трудно выразить в рамках реляционной модели.
Тем не менее повторюсь: даже поверхностное знакомство с архитектурой такого рода интерпретаторов пригодится в тех случаях, где требуется гибко работать с потоками данных.
Литература
Если вам интересны основные вопросы разработки баз данных, то книги лучше, чем “Database system implementation” (Garcia-Molina H., Ullman J. D., Widom J., 2000), вы не найдёте.
Единственный её недостаток — теоретическая направленность. Лично мне нравится, когда к материалу прилагаются конкретные примеры кода или даже демонстрационный проект. За этим можно обратиться к книге “Database design and implementation” (Sciore E., 2008), где приводится полный код реляционной базы данных на языке Java.
Популярнейшие реляционные базы данных по-прежнему используют вариации на тему Volcano. Оригинальная публикация написана вполне доступным языком, и её легко найти в Google Scholar: “Volcano — an extensible and parallel query evaluation system” (Graefe G., 1994).
И хотя в деталях интерпретаторы SQL довольно сильно изменились за последние десятилетия, но самая общая структура этих систем не менялась уже очень давно. Получить представление о ней можно из обзорной работы того же автора “Query evaluation techniques for large databases” (Graefe G. 1993).
