Хотим в общих чертах рассказать про первые достижения с deep learning в анимации персонажей для нашей программы Cascadeur.
Во время работы над Shadow Fight 3 у нас накопилось много боевой анимации — около 1100 движений средней длительностью около 4 секунд. Нам давно казалось, что это может быть хорошим датасетом для обучения какой-нибудь нейронной сети.
Однажды мы заметили, что когда аниматоры делают первые наброски идей на бумаге, то им достаточно нарисовать буквально палочного человечка, чтобы представить себе позу персонажа. Мы подумали, что раз опытный аниматор может хорошо выставить позу по простому рисунку, то вполне возможно, что и нейронная сеть справится. Из этого наблюдения родилась простая идея: давайте из каждой позы мы возьмем только 6 ключевых точек — запястья, щиколотки, таз и основание шеи. Если нейронная сеть знает только позиции этих точек, то сможет ли она предсказать остальную позу — позиции 37 остальных точек персонажа?
Как устроить процесс обучения, было понятно с самого начала: на вход сеть получает позиции 6 точек из конкретной позы, на выходе дает позиции остальных 37 точек, а мы сравниваем их с позициями, которые были в исходной позе. В оценочной функции можно использовать метод наименьших квадратов для расстояний между предсказанными позициями точек и исходными.
Для обучающего датасета у нас были все движения персонажей из Shadow Fight 3. Мы взяли позы из каждого кадра, и получилось около 115 000 поз. Но этот набор имел специфику — персонаж почти всегда смотрел вдоль оси X, а левая нога всегда была впереди в начале движения. Чтобы решить эту проблему, мы искусственно расширили датасет, сгенерировав зеркальные позы, а также случайно вращая каждую позу в пространстве. Это также позволило нам увеличить датасет до двух миллионов поз. Мы использовали 95% нашего датасета для обучения сети и 5% для настройки параметров и тестирования.

Мы взяли достаточно простую архитектуру нейронной сети — полносвязную пятислойную сеть с функцией активации и методом инициализации из Self-Normalizing Neural Networks. На последнем слое активация не используется. Имея по 3 координаты для каждого узла, мы получаем входной слой размером 6*3 элементов и выходной слой размером 37*3 элементов. Мы искали оптимальную архитектуру для скрытых слоев и остановились на пятислойной архитектуре с количеством нейронов в 300, 400, 300, 200 на каждом скрытом слое, однако сети с меньшим количеством скрытых слоев также выдавали неплохой результат. Также весьма полезной оказалась L2 регуляризация параметров сети, она сделала предсказания более плавными и непрерывными.
Нейросеть с такими параметрами предсказывает положение точек со средней ошибкой в 3.5 см. Это весьма высокая ошибка, но надо учесть специфику задачи. Для одного набора входных значений может существовать множество возможных выходных значений. Поэтому нейросеть в итоге научилась выдавать наиболее вероятные, усредненные предсказания. Однако при увеличении числа входных точек до 16 ошибка уменьшалась в два раза, что на практике давало очень точное предсказание позы.
Но при этом нейронная сеть не смогла выдавать полностью корректную позу, сохраняющую длины всех костей и правильное соединение суставов. Поэтому мы дополнительно запускаем процесс оптимизации, выравнивающий все твердые тела и суставы нашей физической модели.
На практике результаты оказались вполне убедительными — вы можете увидеть их в нашем ролике. Но также есть и специфика из-за того, что обучающий датасет — боевые анимации из файтинга с оружием. Например, персонаж как будто предполагает, что он повернут одним плечом к противнику, как в боевой стойке, и соответствующим образом поворачивает стопы и голову. А когда вытягиваешь ему руку, то кисть поворачивается не как при ударе кулаком, а как при ударе мечом.
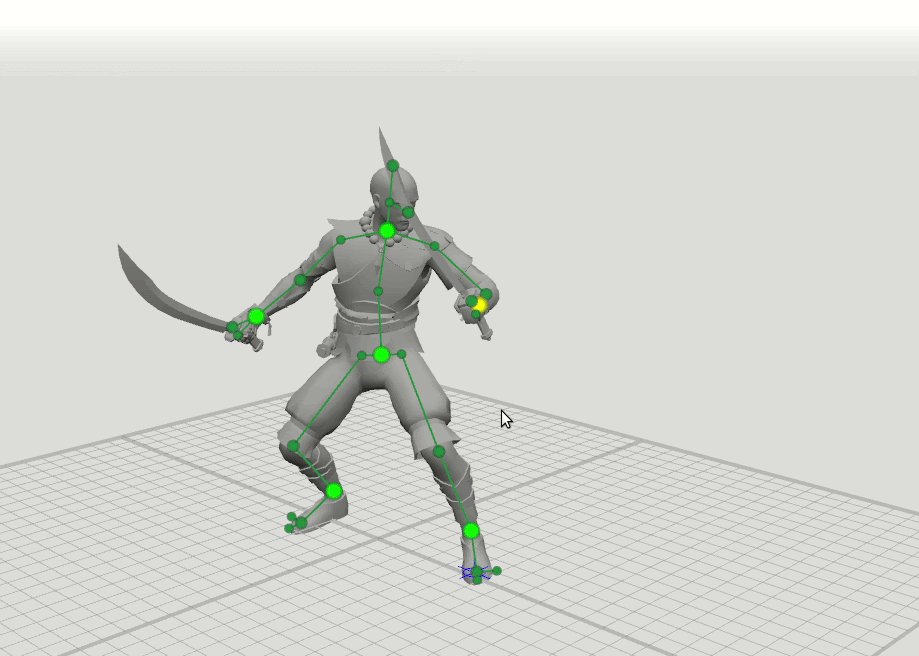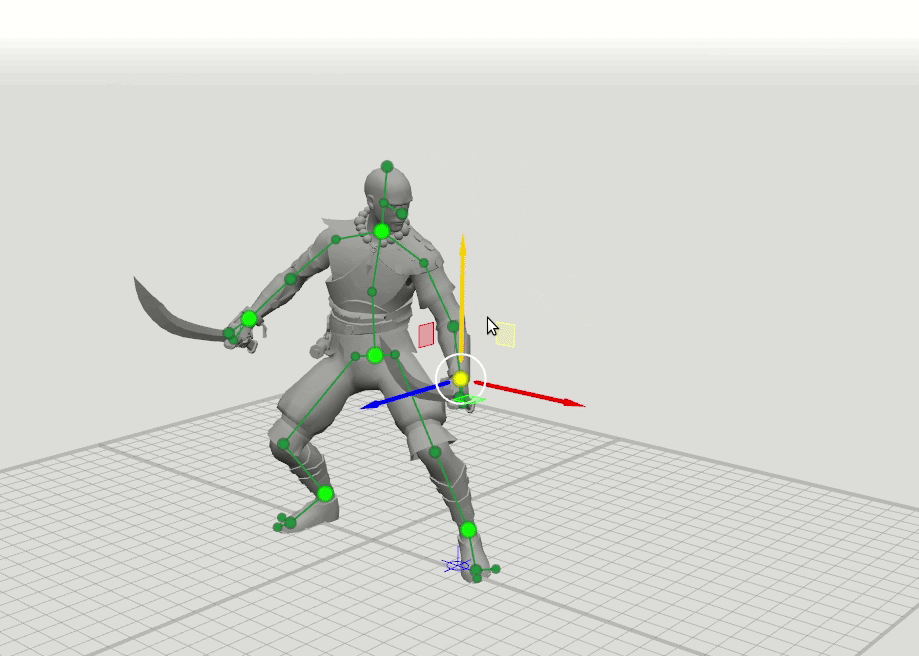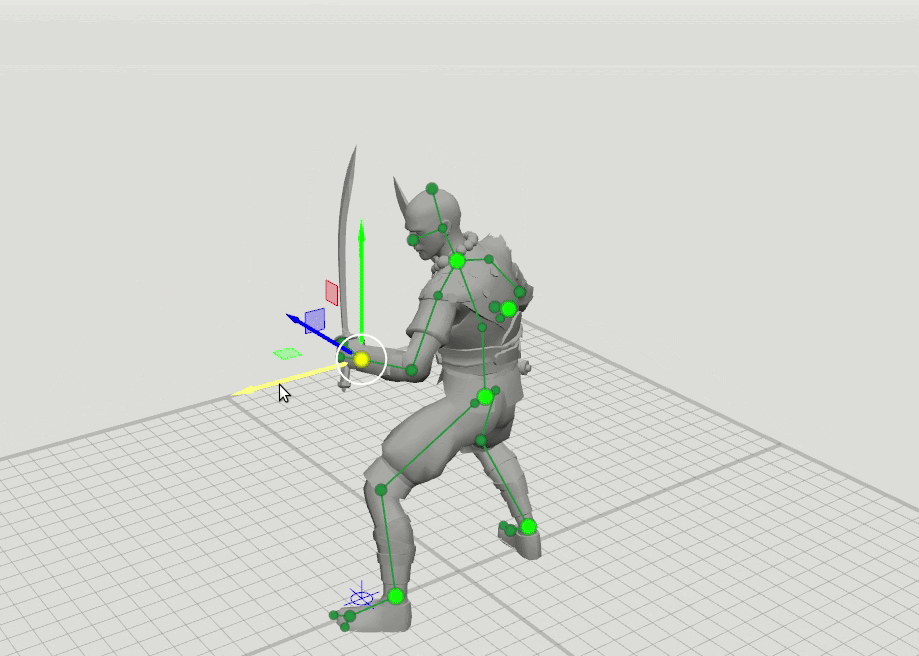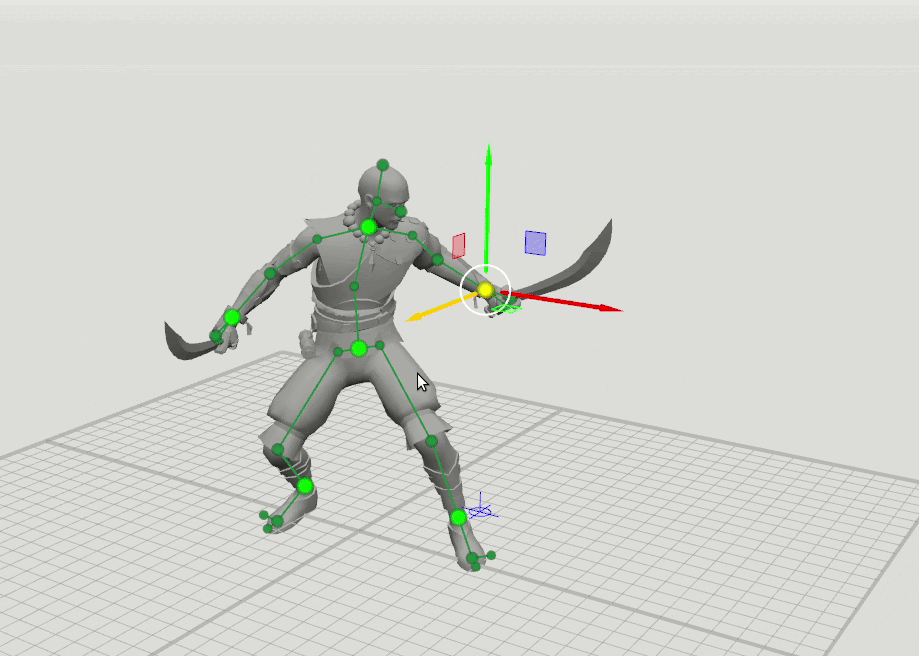
Из этого появилась логичная идея следующего шага — обучить еще несколько сетей с расширенным набором точек, задающих ориентацию кистей, стоп и головы, а также положение коленей и локтей. Мы добавили 16-точечную и 28-точечную схемы. Оказалось, что результаты работы этих сетей можно комбинировать так, что пользователь может задавать позиции произвольному набору точек. Например, пользователь решил подвинуть левый локоть, а правый не трогал. Тогда положение правого локтя и правого плеча предсказываются по 6-точечной схеме, а положение левого плеча предсказывается по 16-точечной схеме.

Похоже, из этого получается действительно интересный инструмент для работы с позой персонажа. Его потенциал еще не раскрыт до конца, и у нас есть идеи, как его улучшать и применять не только для работы с позой. Первая версия этого инструмента уже доступна в текущей версии Cascadeur. Попробовать ее вы сможете, если запишетесь на закрытый бета тест на нашем сайте cascadeur.com
Будем рады узнать ваше мнение и ответить на вопросы.
В команду Banzai Games требуется Deep learning researcher. Подробнее о вакансии можно прочитать здесь.
