Oracle кластер умер, да здравствует кластеризация!
Здесь и далее имеется в виду cluster хранения данных, а не Oracle Real Application Custer
Проблематика
Большим информационным системам свойственно постоянное поступление различной информации, которая накапливается, обсчитывается и архивируется. Мы рассмотрим вариант структурированных данных, хранящихся на сервере RDBMS Oracle и в качестве примера возьмём таблицу, содержащую CDR записи (т.е. записи о вызовах) для абонентов оператора связи.
Данные о звонках поступают хаотично, т.е. не упорядоченно, как вы понимаете, по атрибутам абонентов. Все данные имеют свой жизненный цикл — оперативные, актуальные и архивные. Со временем частота обращений и требования по скорости доступа к данным меняются (т.е. падают). Т.о. записи годичной давности вполне можно хранить на медленных дисках, активные — на дисках с высокой скоростью доступа и без претензий на производительность операций записи, а вот вновь поступающим данным свойственно требование к максимально высокой скорости записи и чтения.
Рассмотрим вариант хранения данных в кластерной таблице
Данные консолидируются по общему признаку. Можно разместить одну или несколько таблиц в кластере, построенном на базе идентификатора абонента, и при обращении к данным по одному идентификатору все данные по этому абоненту будут храниться в одном и том же месте с точностью до размера чанка кластера. Т.е. если все данные влазят в 2 чанка, которые размещены в 2-х блоках базы данных, то для получения 100 строк данных по указанному пользователю достаточно будет вычитать всего 2 блока базы данных. Если бы данные были размазаны по таблице, то мы могли бы для получения тех же 100 строк произвести чтение 100 блоков базы данных. Выигрыш на уровне доступа к данным очевиден.
Кластерному хранению можно приписать следующие характеристики:
- Данные консолидируются по общему признаку.
- Минимизируется Disk IO при доступе по кластерному ключу.
- Минимизируется Disk IO при join по кластерному ключу при совместном хранении таблиц.
- Характеризуется высоким Disk IO при наполнении.
- Не очень дружен с Parallel DML — высокий уровень сериализации.
Рассмотрим вариант хранения данных в обычной таблице
- Данные, как правило, хранятся в порядке поступления.
- Характерна высокая скорость наполнения.
- Дружественно к Parallel DML.
- С ростом объема данных может начаться деградация скорости вставки из-за индексов.
- При высокоселективной выборке (по индексу) наблюдается высокий DiskIO.
Требования к организации данных
В общем случае заказчик ожидает от правильной организации данных следующих характеристик:
- Высокая скорость DML и вставки в частности.
- Высокая скорость выборки.
- Хорошая масштабируемость.
- Лёгкость в администрировании.
Секционирование данных
Один из способов повышения эффективности хранения данных это использование секционирования (Oracle Partitioning Option).
- Разбивка в длину (сокращение времени деградации производительности вставки).
- Разбивка в ширину (повышение масштабируемости).
- Возможность управлять каждым сегментом в отдельности.
- Высокая эффективность Parallel операций над сегментированными объектами.
Например, при разбивке на сегменты в ширину достигается снижение ожиданий на индексных сегментах по сравнению с обычной таблицей с ростом количества конкурентных DML операций над данным объектом.
Предположим, что две таблицы EQ сегментированы по некоторому идентификатору по hash(N). При EQ Partition Join операциях по этому идентификатору будет произведена операция HASH JOIN не на уровне таблиц, а на уровне секций с одинаковым значением hash. Это в разы сократит время, необходимое для проведения указанной операции на заданном объёме данных.
Хотелось бы ещё наделить секционированные таблицы эффективностью кластера по доступу к данным…
Кластеризация данных
Лучший способ заставить таблицу отдавать данные с эффективностью кластера это организовать их так же, как в кластере.
Представьте, что данные у вас разбиты в длину по дате поступления (одна секция за период) и hash секционированы в ширину по идентификатору абонента. Все индексы — локальные. Данные поступают последовательно (по дате) и случайным образом по идентификатору абонента.
Основная секция позволяет использовать Partition Pruning для запросов за период и включает в выборку только те секции, которые содержат данные за указанный период, а дополнительное сегментирование по hash от идентификатора абонента позволяет выбрать только те секции, которые содержат данные по указанному абоненту. Но далее данные размазаны по секции и на получение, например, 100 записей по абоненту за день мы произведём 100 операций дискового чтения.
Однако есть одно «НО»: день прошел и данные за вчера ещё могут поступить, но вот за позавчера уже маловероятно. Таким образом, можно поступить так:
- Создать таблицу с таким же набором полей, что и наша сегментированная таблица с тем же принципом hash-сегментирования, что и на нашей таблице, как:
, где P1 — секция за «позавчера».create table TBL1 as select * from table %TBL% partition(P1) order by subscriber_id, record_date... - Создать такие же индексы, как и на секции таблицы.
- Выполнить операцию
и заменить секцию на таблицу, содержащую те же данные, но в упорядоченном (ака: кластеризованном по subscriber_id) виде.alter table %TBL% exchange partition P1 with table TBL1
P.S.> Можно автоматизировать данный процесс, используя пакет dbms_redefinition.
Вроде, всё выглядит просто, но каков, спросите вы, эффект?..
Далее рассмотрим четыре случая:
- Данные не реорганизованы.
- Произведен rebuild индексов.
- Произведена реорганизация.
- Произведена реорганизация с компрессией данных.
Кластеризация при высоком Phisical IO
Так, если запустить одновременно около сотни процессов, осуществляющих доступ к данным по случайным идентификаторам абонента за указанный период, то средняя производительность одного процесса — в зависимости от организации данных — будет варьироваться следующим образом:
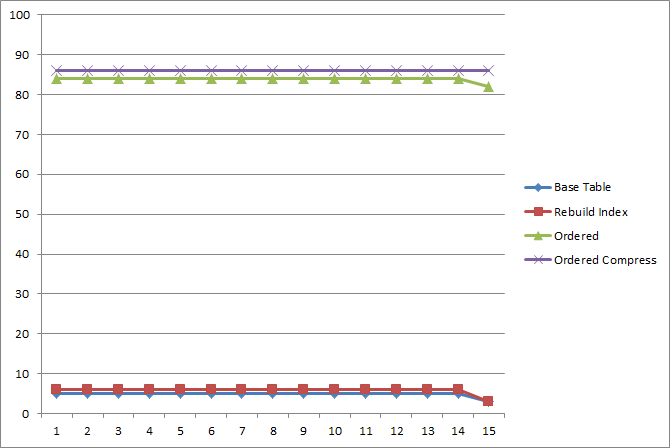
Т.е. мы добились прироста производительности на Disk IO на порядок для данных с характеристиками около 13-19 записей на клиента за период одной секции.
Ниже привожу данные по ожиданиям ввода/вывода и времени отклика:
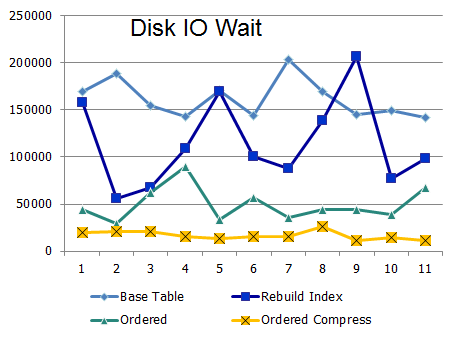

Кластеризация при высоком Logical IO
Представим теперь, что у нас производится доступ к данным, которые размещены в памяти сервера Oracle, а не читаются с диска. Каков будет (и будет ли) выигрыш при такой организации, когда используется только Logical IO.
Производительность процессов (req/sec):
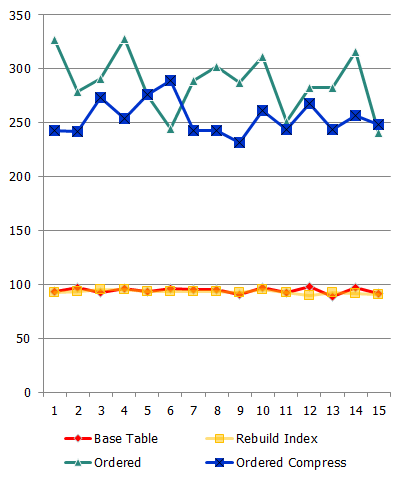
время ожидания:
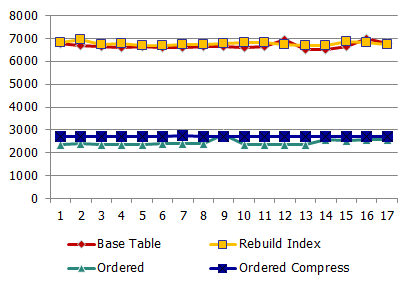
и время отклика:
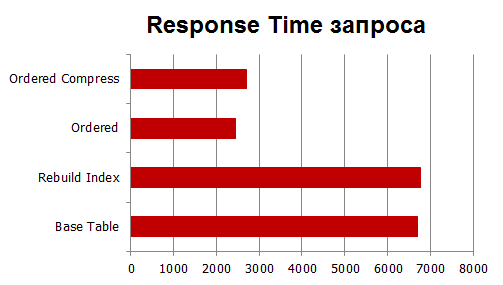
Как мы видим, прирост меньше, чем при Phisical IO, но всё-равно увеличение происходит в разы.
Управление объёмом данных
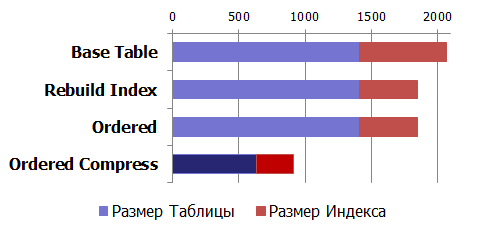
Даже операция обычного rebuild индекса даёт сокращение его объема. Что же произойдёт с объемом дискового пространства при реорганизации данных, а также использования компрессии?
Эффект сжатия (компрессии):

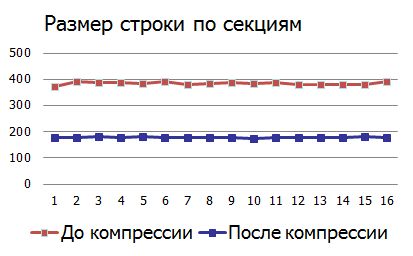
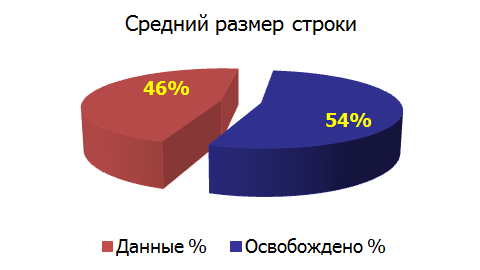
Заключение
Учитывая специфику структуры данных конкретной информационной системы посредством реорганизации данных, можно достичь:
- Повышения производительности отдельных операций.
- Повышения производительности всей системы за счёт освободившегося ресурса.
- Снижения объёма потребляемых ресурсов, т.е. экономии средств на стоимости решения.
- ...
P.S.> Может показаться, что реорганизация большого объема данных сильно затратная операция. Это, конечно, да, но в итоге объем операций ввода/вывода можно сократить. На примере данных заказчика могу сказать, что обращение к реорганизуемой таким образом таблице только системой самообслуживания (а это менее половины нагрузки на таблицу) менее чем за час создавало объём ввода/вывода к данной таблице больше, чем размер всех её секций за сутки. Так что игра может стоить свеч, хоть и создаёт для ДБА дополнительную работу.
