
Эта статья – большущий гайд по технологиям, которые мы в СДЭК используем для проверки наших внутренних приложений, написанных на React Native. Часть из этих подходов вполне можно применить не только в мобильной разработке, но и за её пределами. Дальше буду описывать все в контексте веб-разработки. Если вас это еще не испугало – приглашаю окунуться в головокружительный мир автотестирования мобильных приложений.
Еще делая первые шаги в разработке, я всегда искал пути, как максимально быстро проверить то, что написал. 5 лет назад, чтобы собрать Hello World для андроида, требовалось несколько минут, которые в течение дня могли складываться в час. Это меня абсолютно не устраивало. В тот момент я открыл для себя тесты и понял, что для тестирования бизнес-логики собирать реальное приложение совсем не обязательно. А после втянулся в интеграционное и e2e тестирование, где удалось перепробовать множество разных техник, о которых я вам и расскажу.
В этой статье вы узнаете:
какие существуют подходы при проектировании приложений, чтобы тестировать их было легко,
какие инструменты используем мы,
а главное – как мы пишем и проектируем тесты.
Но для начала немного теории.
Терминология
Существует распространенное заблуждение, что тесты – это лишняя трата времени, проще протыкать руками. Но написав тест единожды, вы получите:
Сценарий, по которому необходимо работать с вашей логикой.
Документацию, которая всегда актуальна в отличие от Confluence.
Уверенность в завтрашнем дне, ведь сломанный тест не позволит вашему CI задеплоить что-то на прод.
В интернете ходит красивая теоретическая картинка, показывающая, к какому относительному количеству тестов на проекте стоит стремиться. Она сама достойна отдельного обсуждения, но здесь мы ее рассмотрим просто, чтобы зафиксировать терминологию в рамках этой статьи и разбить тесты на определенные группы:
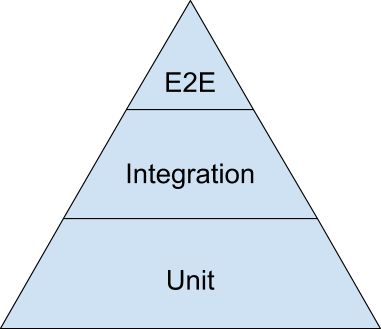
Вверху пирамиды end-to-end тесты, проходящие через всё приложение, как будто это делает реальный пользователь на реальном окружении. Например, весь процесс авторизации с реальным бэкендом.
В середине – интеграционные тесты, проверяющие работу нескольких частей приложения в связке. Например, весь процесс авторизации, но с мокнутым бэкендом.
В основании пирамиды – хорошо знакомые всем unit-тесты, тестирующие атомарные части приложения. Например, отдельные функции бизнес-логики.
Считается, что unit-тестов должно быть больше всего – их легче всего запускать и они работают быстро. Для них не нужно поднимать реальное окружение как для e2e, не нужно связывать компоненты как для интеграционных. Мы просто проверили, что при входе А получаем выход Б.
На первый взгляд, звучит разумно: чем тесты быстрее, тем чаще они будут запускаться. А чем чаще тесты запускаются, тем выше шанс, что они найдут нам проблему. К тому же быстрые тесты можно запускать и без CI. Звучит красиво и утопично, особенно в случаях, когда тестируемая система – сплошной пласт бизнес-логики. Например, бэкенд.
В случае мобильных приложений, чаще всего мы говорим про слой отображения - View. Даже в приложениях, где логики чуть больше чем 0, именно верстки и взаимодействия между компонентами все равно будет сильно больше. Нам важно знать, как ведут себя нативные библиотеки от разных разработчиков в связке друг с другом, как это все выглядит на UI и работает ли даже на слабых телефонах. Обязательно со скриншотами, видео и замерами перфоманса.
Unit-тесты здесь не помогут, поэтому в нашем случае именно интеграционные тесты стоят в основании пирамиды, а Unit-ами мы проверяем «математику», которой не так много. Но все же начать я предлагаю с unit-тестов, поскольку остальное базируются именно на их концепции.
Что вообще тестировать?
Ответ очевиден и приходит на ум сразу, когда вы пытаетесь вкатиться в тесты чуть серьезнее: бизнес-логику, которую пишите.
Предположим, у нас есть сетевой запрос, который должен повторяться до победного, но максимум 3 раза. Напишем реализацию в лоб:
async function fetchUsers() {
for (let retryCount = 0; retryCount < 3; retryCount++) {
console.log('try request =', retryCount)
try {
const result = await fetch('https://github.com/users')
return result
} catch (e) {
console.warn('error')
}
}
}Что в данной функции является бизнес логикой? Сетевой запрос? Количество повторов? Объективно говоря – всё. Нам нужно проверить как то, что функция действительно вернет результат, если запрос завершится успешно, так и то, что в случае ошибки запрос будет повторен максимум 3 раза.
Такой код тестировать сложно, потому что он полон сайд эффектов и является решением "сделай все и сразу". С точки зрения разработчика, очень удобно вызвать всего одну функцию и решить проблему, но с точки зрения тестирования – все совсем наоборот.
Давайте также в лоб напишем тест, который просто делает запрос и проверяет, что он завершился успешно:
test(`should be success`, async () => {
const resultPromise = fetchUsers()
expect(resultPromise).resolves.toBeCalled()
})Если такой тест запустить несколько раз, результат его выполнения будет меняться с success на fail без видимых причин. Например, когда нет интернета. Такие тесты называют flaky, потому что его результат нестабилен.
Предположим, что мы хотим сделать тест стабильнее, но не хотим ничего переписывать. Здесь на помощь нам приходят "моки".
Моки
Под моком обычно понимают нечто, что нарушая все законы, лезет внутрь кода и меняет реализации внутри системы, которые вызываются неявно.
В нашем случае, мы неявно обращаемся к функции fetch, определенной где-то в глобальном скоупе. Для того, чтобы ее замокать, существует множество разных библиотек, но мы обратимся к дефолтному jest.
test(`should be success`, async () => {
global.fetch = jest.fn().mockImplementation(() => Promise.resolve())
const resultPromise = fetchUsers()
expect(resultPromise).resolves.toBeCalled()
})Теперь результат выполнения fetchUsers всегда один и тот же. Поздравляю, вы только что сделали свой первый шаг к тестированию, пусть и пошли по кривой дорожке работы с моками.
Почему кривой? Разве моки – это плохо?
Когда вы вводите в тестирование моки, это означает, что вы начинаете знать о внутреннем устройстве функции и методах, которые оно вызывает внутри. Это плохо, потому что протекает абстракция и тесты становятся хрупкими.
Вместо того, чтобы тестировать функцию как черный ящик, вы начинаете знать о внутренностях ее реализации, что делает тест хрупким
Если однажды вместо fetch внутри нашей функции кто-то начнет использовать XMLHttpRequest, то тест упадет, хотя по факту, функция продолжит работать корректно. Это ведет к тому, что после каждого изменения функции нужно будет менять еще и тест. Есть ощущение, что проще сразу написать так, чтобы не пришлось переписывать.
В этом нам помогут фейки. В простом понимании, это те же моки, но прокинутые явно. В этой статье я намеренно разделил эти два понятия, чтобы показать принцип. В разработке под одним могут подразумевать другое и наоборот.
Единственное жизнеспособное применение моков – подмена реализаций, которые вы не способны контролировать. Например, текущее время и дату на устройстве, какую-то библиотеку для работы с пушами и т.д. (здесь стоит отметить, что даже с такими вещами можно обойтись без моков – достаточно закрыть чужие реализации интерфейсом).
Как мы можем избавиться от моков?
Устраняя неявные зависимости.
В нашем случае, мы можем передать неявную зависимость на fetch в аргументы функции. Давайте сделаем это:
async function fetchWithRetry<T>(request: () => Promise<T>): Promise<T> {
for (let retryCount = 0; retryCount < 3; retryCount++) {
console.log('try request =', retryCount)
try {
const result = await request()
return result
} catch (e) {
console.warn('error')
}
}
}Теперь наша функция может работать не только с юзерами, но и с любым другим запросом. Тестировать эту функцию стало проще:
test(`should return value when success`, async () => {
const result = await fetchWithRetry(() => Promise.resolve([]))
expect(result).toBe([])
})Мы избавились от моков и просто прокидываем нужную реализацию через аргументы функции, подменяя её, когда это необходимо.
А что дальше?
Мы проверили кейс, при котором функция возвращает результат при успешном запросе. Теперь давайте убедимся, что функция действительно выполнится максимум 3 раза, а не 100:
test('should retry 3 times if failed', async () => {
const alwaysReject = jest.fn(() => Promise.reject())
const resultPromise = await fetchWithRetry(alwaysReject)
expect(alwaysReject).toBeCalledTimes(3)
})На этом моменте большая часть разработчиков успокоится и посчитает, что функция успешно проверена. На самом деле, все тесты, которые мы написали – прошли, а чаще всего это означает, что мы что-то упустили.
До тех пор, пока написанный вами тест не упадёт – считайте, что вы ничего не протестировали, так как все потенциальные баги от вас ускользнули
Цель тестирования – найти ошибки в вашем функционале. Если ошибки вы не нашли, то польза от такой работы эфемерна.

Чтобы протестировать все кейсы, нужно найти все возможные выходы функции при всех возможных входах. Можно пользоваться простым правилом: ищем пограничные случаи; все, что внутри этих случаев и все, что снаружи. Делать это достаточно утомительно, не говоря о том, что велик шанс упустить один из сценариев. Благо весь наш мир состоит из примитивов, вложенных друг в друга, а значит – все это дело можно успешно генерировать. С этим нам поможет…
Property based testing
Задача такого тестирования: обеспечить полноту всех возможных сценариев.
Давайте слегка изменим нашу функцию, избавив её от ещё одной неявной зависимости в виде количества повторений:
async function fetchWithRetry<T>(request: () => Promise<T>, maxRetries = 3): Promise<T> {
for (let retryCount = 0; retryCount < maxRetries; retryCount++) {
console.log('try request =', retryCount)
try {
const result = await request()
return result
} catch (e) {
console.warn('error')
}
}
}Теперь мы можем контролировать: сколько раз наша функция должна пытаться повторить вызов. Давайте напишем такой тест, который сам будет генерировать нам числа и на основе них строить тест. В этом нам поможет fast-check:
import * as fc from 'fast-check'
test(`should retry any integer values passed to it`, async () => {
fc.assert( // убедимся что
fc.asyncProperty(
fc.integer(), // для любого целого числа
async (number) => {
const alwaysReject = jest.fn(() => Promise.reject()) // когда запрос с ошибкой
const resultPromise = await fetchWithRetry(alwaysReject, number)
expect(alwaysReject).toBeCalledTimes(number) // функция будет вызвана такое же количество раз, какое было передано в параметре
}
),
)
})После запуска можем увидеть следующий лог:
UnhandledPromiseRejectionWarning: Error: Property failed after 2 tests
{ seed: -1329951604, path: "1:1:0:0:0", endOnFailure: true }
Counterexample: [-1]
Shrunk 4 time(s)
Got error: Error: expect(jest.fn()).toBeCalledTimes(expected)
Expected number of calls: -1
Received number of calls: 0Видим, что тест упал, когда в него передали отрицательное число. То есть функция не то чтобы не сделала ретрай – она даже не попыталась сделать запрос, когда в нее передали аргументы, которые не ожидал разработчик. Баг это или фича – решать, конечно же, вам, но этот тест показал, что такая ситуация возможна.
Окей, мы написали юнит-тест руками, сгенерировали тестовые данные и даже кое-что нашли! Наш тест и сама функция стали чуть больше и сложнее как для восприятия, так и для проверки.
Сложные тесты = большие проблемы
Генерировать тестовые данные это, конечно, хорошо, особенно для простых случаев типа нашего. Но в более сложных системах генерация данных может сыграть злую шутку, когда вам придется реализовывать алгоритмы для их проверки.
Чем меньше в тесте непроверенных алгоритмов, тем лучше. Чем он тупее и прямее, тем проще его воспринимать и меньше шанс ошибиться при написании. Если возникла ситуация, в которой наш тест становится сложным и вы подозреваете, что он может работать неверно, то для этого есть решение…
ПИСАТЬ ТЕСТЫ НА ТЕСТЫ

Шучу, конечно. По крайней мере, не руками. Для проверки тестов на целостность придумали…
Мутационное тестирование
Оно заходит в код вашего приложения, мутирует его (меняя, например, плюсы на минусы) и запускает ваш тест еще раз. Если с искаженной логикой программы ваш тест прошел, значит, что тест написан неверно. То есть по сути, мы все-таки пишем тесты на тесты, но не руками, а автоматически их генерируем.
К примеру, у этого проекта много тестов и 100% покрытие кода:

однако запустив мутантов в наш код, обнаружим, что половина тестов false-positive и продолжают работать даже тогда, когда код поломан:

Проверяя тесты мутационным тестированием, вы можете легко убедиться, что у 100% покрытия кода тестами с качеством общего не больше, чем у луна-парка с луной.
Следует понимать, что все это не бесплатно и внедряя мутационное тестирование, вы платите скоростью запуска тестов и последующим анализом репортов. Но как говорится, всё есть яд и всё есть лекарство, важна лишь дозировка. Так что мутационное тестирование, действительно, может вам помочь в проверке целостности тестов.
Интеграционные тесты c Detox

Detox – это святой Грааль всех автоматизаторов, связанных с react-native, поскольку он берет на себя всю работу по взаимодействию с девайсами.
В целом, некорректно предъявлять претензии к инструменту, позиционирующему себя как gray-box для e2e тестов. Он отлично работает в сценариях, когда необходимо сделать что-то, что теоретически может сделать пользователь:
нажать кнопку;
ввести текст;
открыть пуш;
cделать другие взаимодействия с экраном.
Но например, когда вы пытаетесь просто подменить данные, как мы ранее это делали в jest, начинаются приседания невиданных масштабов.
Мы в СДЭК используем Detox в повседневной разработке, и я даже рассказывал об этом на CodeFest, наверное, поэтому я так его люблю и ненавижу.
Detox предлагает вам систему моков, основанную на патчинге файлов через Metro:

Мягко говоря, rich developer experience вы здесь не получите. Вдобавок выше мы обсудили, чем плохи моки и почему их следует заменять фейками.
Detox предлагает вам полностью заменять один файл другим в процессе сборки. Этот подход абсолютно не масштабируем, а также хрупок, поскольку оригинальный файл попросту будет игнорироваться. Малейшие изменения могут поломать как тесты, так и само приложение при неправильных импортах.
Фактически, процесс разработки/ тестирования с помощью Detox выглядит так:
1. Вы мокаете файл, где лежит ваш endpoint.url на localhost:1234
2. Поднимаете локальный сервер на этом порте
3. Описываете в тесте, на какие вызовы эндпоинтов что должно возвращаться
4. Проверяете, что ожидаемый результат = фактическому

Я поднимал вопрос к авторам, предлагая им API, который доступен в Android с Espresso, но пока у разработчиков нет представления, как этого достичь. Если оно есть у вас – не стесняйтесь оставлять комментарии под этим Issue или открыть новое. Возможно, именно ваше решение в итоге упростит жизнь сотням других разработчиков. Но вернемся к нашему тесту.
Тест получается громоздкий, его достаточно просто писать, но сложно читать и поддерживать. К сожалению, это понимание приходит спустя 50 написанных тестов, когда старые начали падать, так как изменились требования и поменялась логика. Становится очевидно, что надо смотреть в сторону упрощения, а достичь этого можно придерживаясь более декларативного описания.
BDD
Первым в голову, конечно же, приходит cucumber. Этот фреймворк предлагает описывать сценарии на языке Gherkin
Feature: Оцените статью
Scenario: Пользователю понравилась статья
When пользователь поставил лайк
Then автор понял, что не зря старается
Scenario: Пользователю не понравилась статья
When пользователь оставил комментарий, как дополнить статью
Then автор стал лучше и больше не допустит подобных ошибокМало того, что это еще один новый синтаксис, работа с cucumber практически не отличается, а порой сложнее, чем написать тест в лоб.
Единственный плюс: написание сценариев можно передать настоящим профессионалам QA, а разработчикам – лишь реализовать их. Если вы используете в своей компании cucumber, напишите в комментариях, как он помогает вам, какие проблемы решает, а какие привносит. В нашем случае он не подошел и мы начали искать дальше.
Design review
Хотя мы и говорим о фронтенде, в design review речь не о Figma и макетах, а о проектировании решения, его оценке и уже после – реализации в коде. Такой подход позволяет:
посмотреть на проблему со всех углов и уловить непонятные моменты в ТЗ еще на самом раннем этапе. Нахождение ошибок в ТЗ перед реализацией существенно сокращает количество необходимого времени на выпуск фичи;
не забивать себе голову кодом и тонкостями реализации, что позволяет учесть не только пограничные случаи, но и все остальные;
создавать документацию, к которой может обратиться и проверить любой человек.
Вопрос – как описать документ так, чтобы он:
был оцифрован – так вы сможете поделиться им с кем угодно и получить дополнительный фидбэк;
легко читался – чтобы быстро понять, что происходит в логике даже спустя несколько лет;
легко изменялся – чтобы проектирование не было обременением, а наоборот, инструментом, который хочется использовать ежедневно;
при изменении не требовал делать лишних изменений в коде (для оптимизации труда разработчика).
Посмотрев по сторонам, можно заметить xstate – одну из реализаций стейт-машин. Для неё существует интерфейс в виде stately.ai, позволяющий визуализировать весь процесс в виде наглядной диаграммы:

Проектирование решения в таком варианте позволяет вам достичь всех целей, о которых мы говорили ранее. К тому же такую диаграмму можно дать QA и, в отличие от cucumber, им не придется учить специфичный синтаксис – все делается максимально интуитивно.
После проектирования вы можете экспортировать вашу стейт-машину в виде json-файла и сгенерировать тесты, обеспечив постоянную актуальность такой документации. Если хотите подробностей, то от авторов на YouTube есть ролик, раскрывающий основные моменты.
Вернемся в серую реальность, где все не так радужно, как на картинке.
XState не любит TypeScript
XState хоть и написан на TypeScript, но от типизации в привычном понимании там почти ничего нет. У вас будет доступ к названиям функций из библиотеки, возможно, какой-то примитивный автокомплит дефолтных пропсов, но не больше. К примеру, автокомплита у названий ваших состояний и экшенов не будет.
В том варианте, в котором она поставляется из коробки – решение точно не для ежедневной разработки. Но если его немного допилить, можно получить вполне рабочее решение с автокомплитом и полноценной поддержкой TypeScript:

Основная сложность состоит в том, чтобы типизировать json, который отдает stately.ai в вид, который будет понятен TypeScript-у. Мы это сделали и делимся с вами ссылкой на github.
Теперь для описания тестовых сценариев вам нужно следующее:
Реализовать сценарий на stately.ai и экспортировать в виде
.json:

Создать какой-нибудь
auth.machine.tsи вставить туда полученный json. Обязательно пометить его как const, чтобы строки считались строковыми литераламиexport default { … } as constПередать в функцию
declareTestModel, где вы тут же получите типизацию вашихeventsиexpectations. Все, что вам останется – это просто заполнить их данными и запустить тест:
")
Такой подход в виде описания сценариев сильно облегчает поддержку и читаемость тестов. Вместо огромного количества вложенных друг в друга последовательных цепочек действий вы получаете условную "карту", в которой необходимо разметить состояния вашего приложения в виде экспектов и действий, которые приводят к изменению этого состояния.

Поддержка таких тестов облегчается тем, что у вас есть наглядная диаграмма и при необходимости изменить связи между действиями и состояниями вам не придется что-то менять в реализации, поскольку все шаги вы уже описали.
К сожалению, stately.ai заточен в первую очередь под реализацию стейт-машин именно для бизнес-логики, а не тестов. Из-за чего приходится бороться с некоторыми трудностями:
неконсистентной выдачей json файла, где структура файла хоть и незначительно, но порой меняется;
отсутствием нормальной типизации, из-за чего приходится писать свои обертки;
отсутствием поддержки property based testing.
Несмотря на все минусы – это отличный помощник, который помогает нашему отделу внутренних приложений на React Native в СДЭК проектировать и поставлять более качественные приложения.
Заключение
Надеюсь, тот опыт, которым я поделился, будет полезен. С полученными знаниями у вас не должно возникнуть трудностей при самостоятельном более подробном раскрытии каждой из заинтересовавших тем. В следующей статье планирую раскрыть тему "Тестирование через Detox" более подробно, с реальными примерами и способами оптимизации.
Тестируйте с удовольствием, а главное задавайте себе вопрос: для чего тесты нужны именно вам.
