Всем привет, меня зовут Александр, я работаю в ЦИАН инженером и занимаюсь системным администрированием и автоматизацией инфраструктурных процессов. В комментариях к одной из прошлых статей нас попросили рассказать, откуда мы берем 4 ТБ логов в день и что с ними делаем. Да, логов у нас много, и для их обработки создан отдельный инфраструктурный кластер, который позволяет нам оперативно решать проблемы. В этой статье я расскажу о том, как мы за год адаптировали его под работу с постоянно растущим потоком данных.
С чего мы начинали
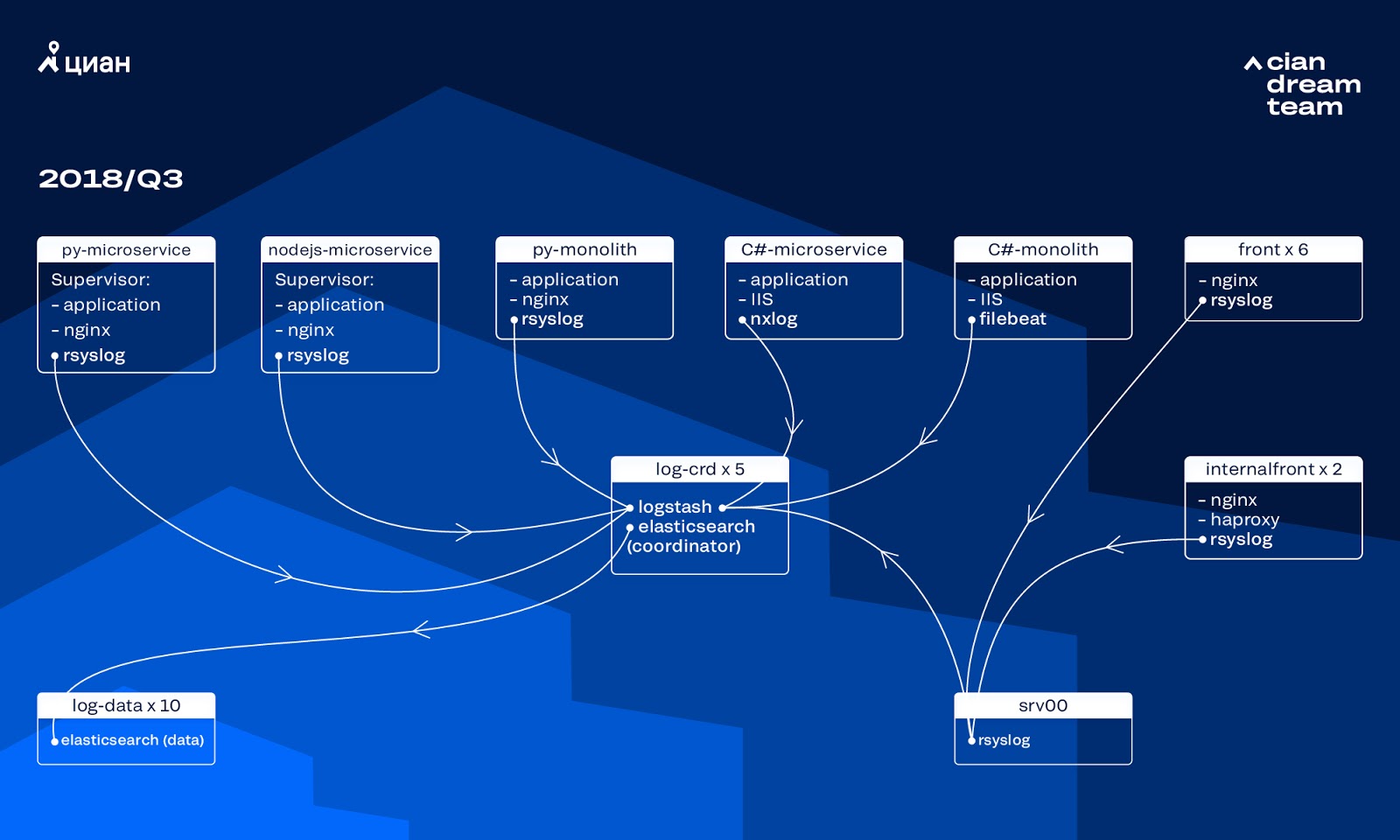
Последние несколько лет нагрузка на cian.ru росла очень быстро, и к третьему кварталу 2018 года посещаемость ресурса достигла 11.2 млн уникальных пользователей в месяц. В то время в критические моменты мы теряли до 40% логов, из-за чего не могли оперативно разбираться с инцидентами и тратили очень много времени и сил на их решение. Еще мы часто не могли найти причину проблемы, и она повторялась спустя какое-то время. Это был ад, с которым надо было что-то делать.
На тот момент для хранения логов мы использовали кластер из 10 дата-нод с ElasticSearch версии 5.5.2 с типовыми настройками индексов. Его внедрили больше года назад как популярное и доступное решение: тогда поток логов был не такой большой, смысла придумывать нестандартные конфигурации не было.
Обработку входящих логов обеспечивал Logstash на разных портах на пяти координаторах ElasticSearch. Один индекс, независимо от размера, состоял из пяти шардов. Была организована почасовая и дневная ротация, в результате каждый час в кластере появлялось порядка 100 новых шардов. Пока логов было не очень много, кластер справлялся и на его настройках никто не заострял внимания.
Проблемы быстрого роста
Объем сгенерированных логов рос очень быстро, так как друг на друга наложились два процесса. С одной стороны, пользователей у сервиса становилось все больше. А с другой, мы начали активно переходить на микросервисную архитектуру, распиливая наши старые монолиты на C# и Python. Несколько десятков новых микросервисов, заменявших части монолита, генерировали заметно больше логов для инфраструктурного кластера.
Именно масштабирование и привело нас к тому, что кластер стал практически неуправляем. Когда логи начали поступать со скоростью 20 тыс. сообщений в секунду, частая бесполезная ротация увеличила количество шардов до 6 тысяч, а на одну ноду приходилось более 600 шардов.
Это приводило к проблемам с выделением оперативной памяти, а при падении ноды начинался одновременный переезд всех шардов, умножающий трафик и нагружающий остальные ноды, что делало практически невозможной запись данных в кластер. И в этот период мы оставались без логов. А при проблеме с сервером мы теряли 1/10 кластера в принципе. Добавляло сложностей большое количество индексов маленького размера.
Без логов мы не понимали причин инцидента и могли рано или поздно наступить на те же грабли снова, а в идеологии нашей команды это было недопустимо, так как все механизмы работы у нас заточены как раз на обратное — никогда не повторять одни и те же проблемы. Для этого нам был нужен полный объем логов и доставка их практически в режиме реального времени, так как команда дежурных инженеров мониторила алерты не только от метрик, но и от логов. Для понимания масштабов проблемы — на тот момент общий объем логов составлял порядка 2 Тб в сутки.
Мы поставили задачу — полностью исключить потерю логов и сократить время их доставки в кластер ELK максимум до 15 минут во время форс-мажоров (на эту цифру в дальнейшем мы опирались, как на внутренний KPI).
Новый механизм ротации и hot-warm ноды
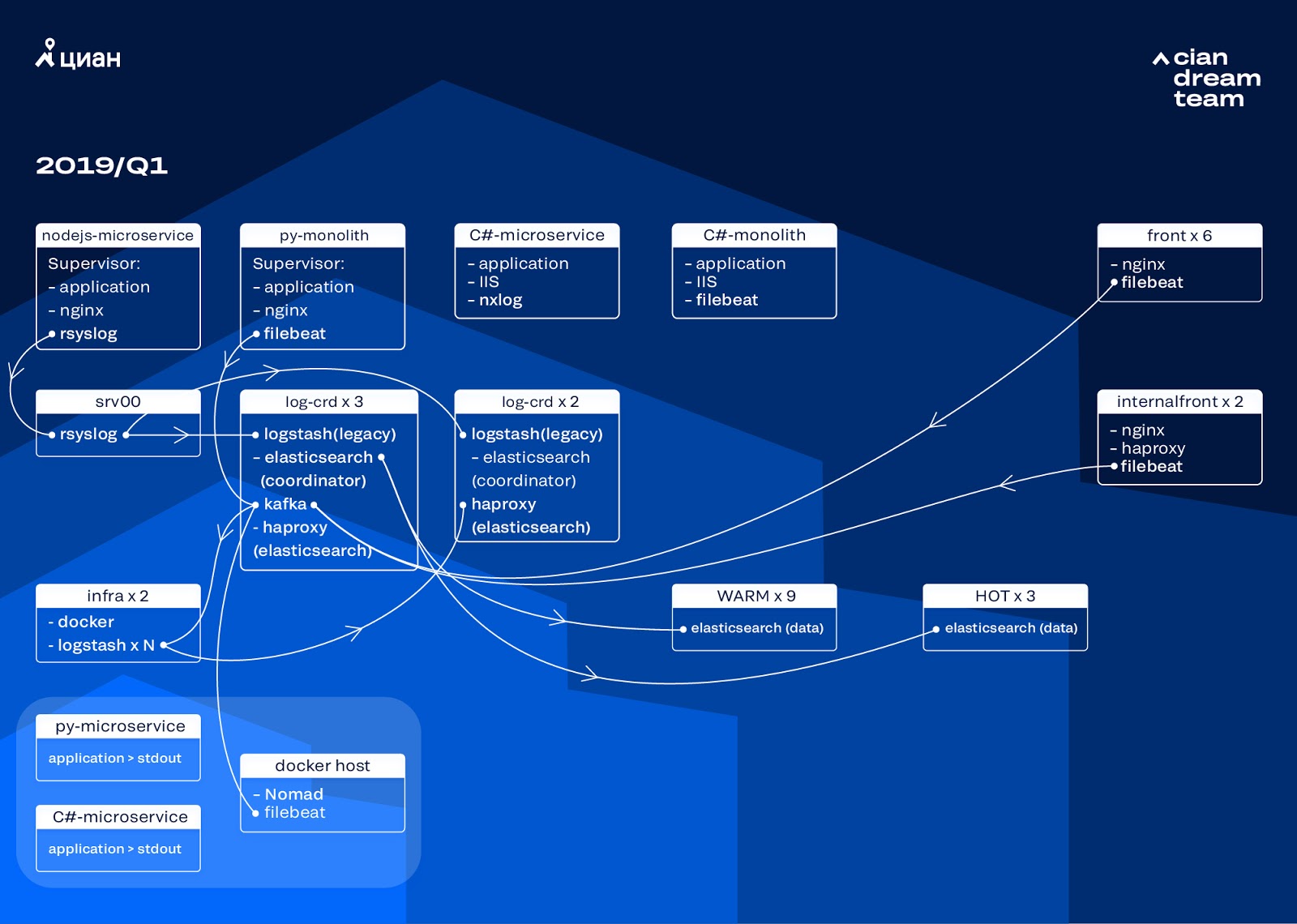
Преобразование кластера мы начали с обновления версии ElasticSearch с 5.5.2 на 6.4.3. У нас в очередной раз лег кластер 5 версии, и мы решили его погасить и полностью обновить — логов-то все равно нет. Так что этот переход мы совершили всего за пару часов.
Самым масштабным преобразованием на этом этапе стало внедрение на трех нодах с координатором в качестве промежуточного буфера Apache Kafka. Брокер сообщений избавил нас от потери логов во время проблем с ElasticSearch. Одновременно мы добавили в кластер 2 ноды и перешли на hot-warm архитектуру с тремя «горячими» нодами, расставленными в разных стойках в дата-центре. На них мы по маске перенаправили логи, которые нельзя терять ни в коем случае — nginx, а также логи ошибок приложений. На остальные ноды уходили минорные логи — debug, warning и т. п., а также через 24 часа переезжали «важные» логи с «горячих» нод.
Чтобы не увеличивать количество индексов малого размера, мы перешли с ротации по времени на механизм rollover. На форумах было много информации о том, что ротация по размеру индекса очень ненадежна, поэтому мы решили использовать ротацию по количеству документов в индексе. Мы проанализировали каждый индекс и зафиксировали количество документов, после которого должна срабатывать ротация. Таким образом мы достигли оптимального размера шарда — не более 50 Гб.
Оптимизация кластера
Однако полностью от проблем мы не избавились. К сожалению, все равно появлялись маленькие индексы: они не достигали заданного объема, не ротировались и удалялись глобальной очисткой индексов старше трех дней, так как мы убрали ротацию по дате. Это приводило к потере данных из-за того, что индекс из кластера исчезал полностью, а попытка записи в несуществующий индекс ломала логику curator’а, который мы использовали для управления. Alias для записи преобразовывался в индекс и ломал логику rollover’а, вызывая бесконтрольный рост некоторых индексов до 600 Гб.
Например, для конфига ротации:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
При отсутствии rollover alias возникала ошибка:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Решение этой проблемы мы оставили на следующую итерацию и занялись другим вопросом: перешли на pull логику работы Logstash, занимающегося обработкой входящих логов (удалением лишней информации и обогащением). Мы поместили его в docker, который запускаем через docker-compose, там же разместили logstash-exporter, который отдает метрики в Prometheus для оперативного мониторинга потока логов. Так мы дали себе возможность плавно менять количество инстансов logstash, отвечающих за обработку каждого вида логов.
Пока мы совершенствовали кластер, посещаемость cian.ru выросла до 12,8 млн уникальных пользователей в месяц. В результате получилось, что наши преобразования немного не успевали за изменениями на продакшене, и мы столкнулись с тем, что «теплые» ноды не справлялись с нагрузкой и тормозили всю доставку логов. «Горячие» данные мы получали без сбоев, но в доставку остальных приходилось вмешиваться и делать ручной rollover, чтобы равномерно распределять индексы.
При этом масштабирование и изменение настроек инстансов logstash в кластере осложнялось тем, что это был локальный docker-compose, и все действия выполнялись руками (для добавления новых концов необходимо было руками пройти по всем серверам и везде сделать docker-compose up -d).
Перераспределение логов
В сентябре этого года мы все еще продолжали распиливать монолит, нагрузка на кластер возрастала, а поток логов приближался к 30 тысячам сообщений в секунду.
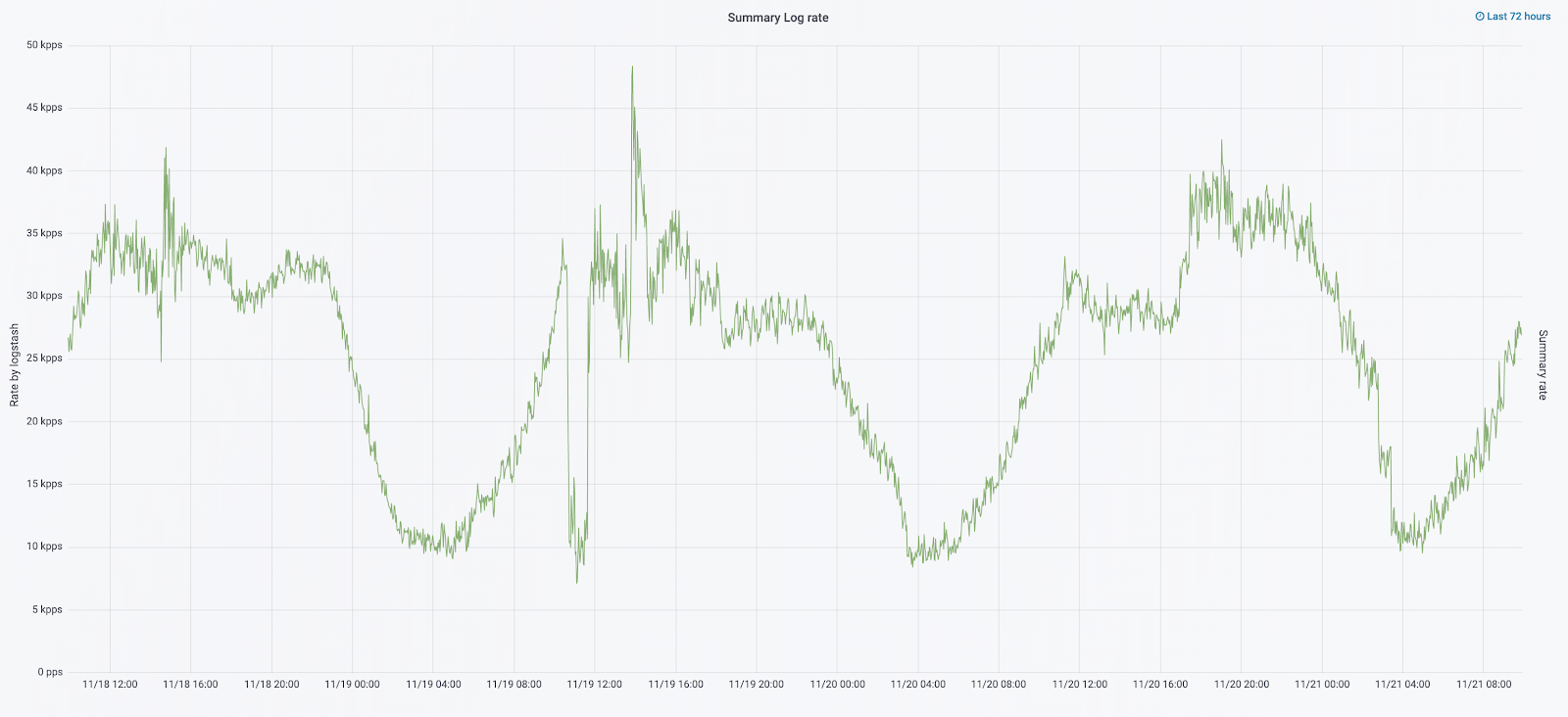
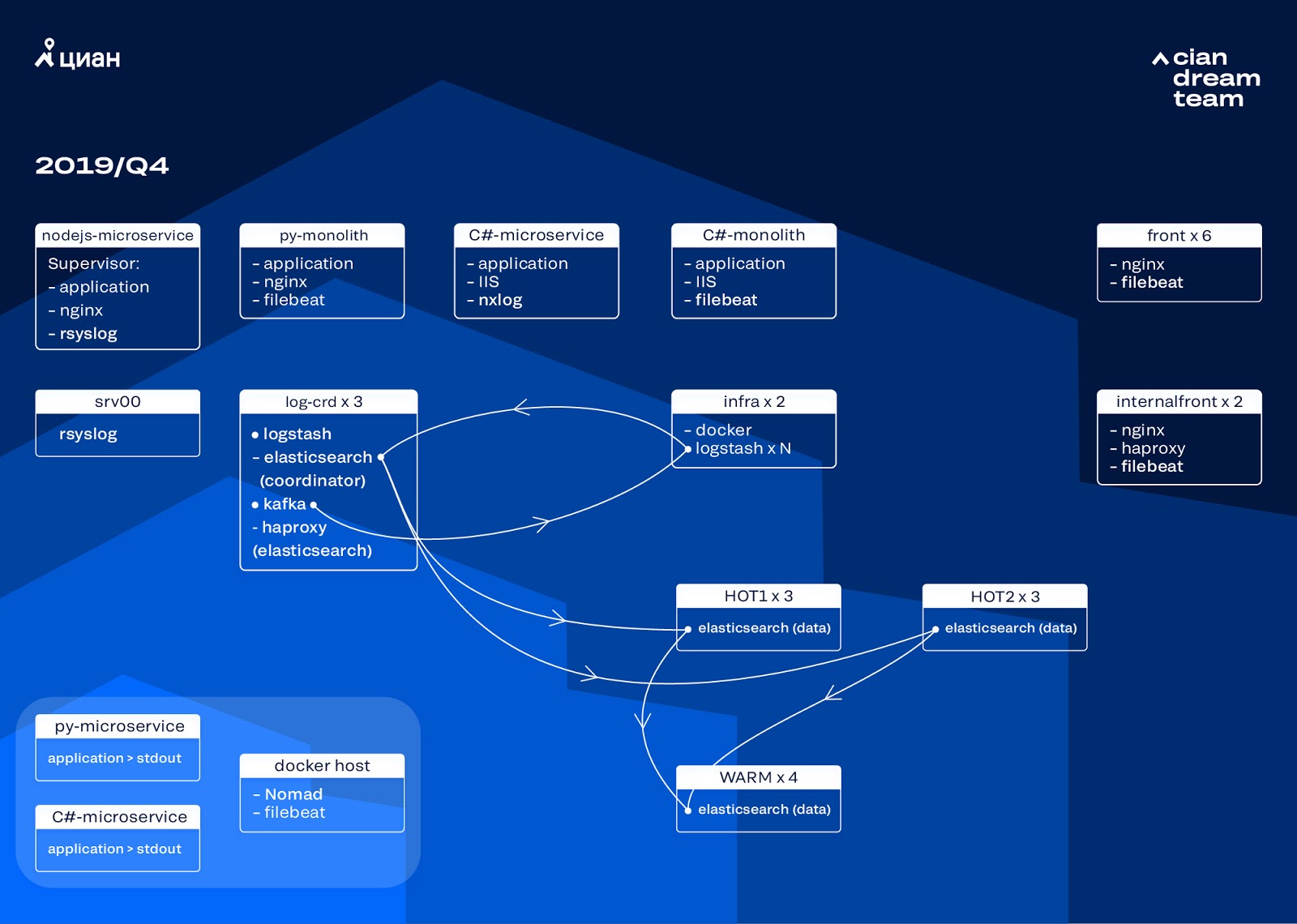
Следующую итерацию мы начали с обновления железа. С пяти координаторов мы перешли на три, заменили дата-ноды и выиграли по деньгам и по объему хранилища. Для нод мы используем две конфигурации:
- Для «горячих» нод: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 для Hot1 и 3 для Hot2).
- Для «теплых» нод: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
На этой итерации мы вынесли индекс с access-логами микросервисов, который занимает столько же места, сколько логи фронтовых nginx, во вторую группу из трех «горячих» нод. Данные на «горячих» нодах мы теперь храним 20 часов, а затем переносим на «теплые» к остальным логам.
Проблему исчезновения маленьких индексов мы решили перенастройкой их ротации. Теперь индексы ротируются в любом случае каждые 23 часа, даже если там мало данных. Это немного увеличило количество шардов (их стало порядка 800), но с точки зрения производительности кластера это терпимо.
В результате в кластере получилось шесть «горячих» и всего четыре «теплых» ноды. Это вызывает небольшую задержку на запросах по большим интервалам времени, но увеличение числа нод в будущем решит эту проблему.
В этой итерации исправили и проблему отсутствия полуавтоматического масштабирования. Для этого мы развернули инфраструктурный Nomad кластер — аналогичный тому, что уже развернут у нас на продакшен. Пока количество Logstash автоматически не изменяется в зависимости от нагрузки, но мы придем и к этому.
Планы на будущее
Реализованная конфигурация отлично масштабируется, и сейчас мы храним 13,3 Тб данных — все логи за 4 суток, что необходимо для экстренного разбора алертов. Часть логов мы преобразуем в метрики, которые складываем в Graphite. Чтобы облегчить работу инженеров, у нас есть метрики для инфраструктурного кластера и скрипты для полуавтоматической починки типичных проблем. После увеличения количества дата-нод, которое запланировано на следующий год, мы перейдем на хранение данных с 4 до 7 дней. Этого будет достаточно для оперативной работы, так как мы всегда стараемся расследовать инциденты как можно скорее, а для долгосрочных расследований есть данные телеметрии.
В октябре 2019 года посещаемость cian.ru выросла уже до 15,3 млн уникальных пользователей в месяц. Это стало серьезной проверкой архитектурного решения по доставке логов.
Сейчас мы готовимся обновить ElasticSearch до версии 7. Правда, для этого придется обновлять mapping многих индексов в ElasticSearch, т. к. они переехали с версии 5.5 и были объявлены как deprecated в 6 версии (в 7 версии их просто нет). А это значит, что в процессе обновления обязательно будет какой-нибудь форс-мажор, который на время решения вопроса оставит нас без логов. Из 7 версии больше всего ждем Kibana с улучшенным интерфейсом и новыми фильтрами.
Основной цели мы достигли: перестали терять логи и сократили время простоя инфраструктурного кластера с 2-3 падений в неделю до пары часов сервисных работ в месяц. Вся эта работа на продакшене почти незаметна. Однако теперь мы можем точно определить, что происходит с нашим сервисом, можем быстро делать это в спокойном режиме и не переживать, что логи потеряются. В общем, мы довольны, счастливы и готовимся к новым подвигам, о которых расскажем позже.
