
Часто бывает, что после разбиения проекта на модули скорость его сборки сильно ниже ожидаемой. Причины могут быть разные, от кривых настроек Gradle до неподходящего железа. Сегодня я хочу разобрать одну из причин — бутылочные горлышки среди модулей, и как с ними бороться.
По всем правилам приличия представлюсь — меня зовут Перевалов Данил, а теперь давайте перейдём к теме.
А что за горлышки такие?
Простыми русскими народными словами бутылочное горлышко это узкое место. Но я как представитель высокоинтеллектуального и высоковыпендрежного класса программистов привык использовать английский аналог — bottleneck. Буквальный перевод которого и значит — бутылочное горлышко. На самом деле у меня просто вызывает улыбку слово «горлышко». Как-то непосредственно и по-детски оно звучит.
Ладно. А как вообще модуль может стать узким местом, а-ля «бутылочным горлышком»?
Всё просто. Допустим, у нас есть модуль, который… Просто долго собирается. Ну вот в нём просто много кода. И всё.
Проблема в том, что другие модули могут зависеть от него. А значит, не начнут собираться, пока он не закончит.
Что это значит для нас? Что если мы попробуем запустить параллельную сборку нашего проекта, допустим, на трёх Gradle Worker, то увидим простои.
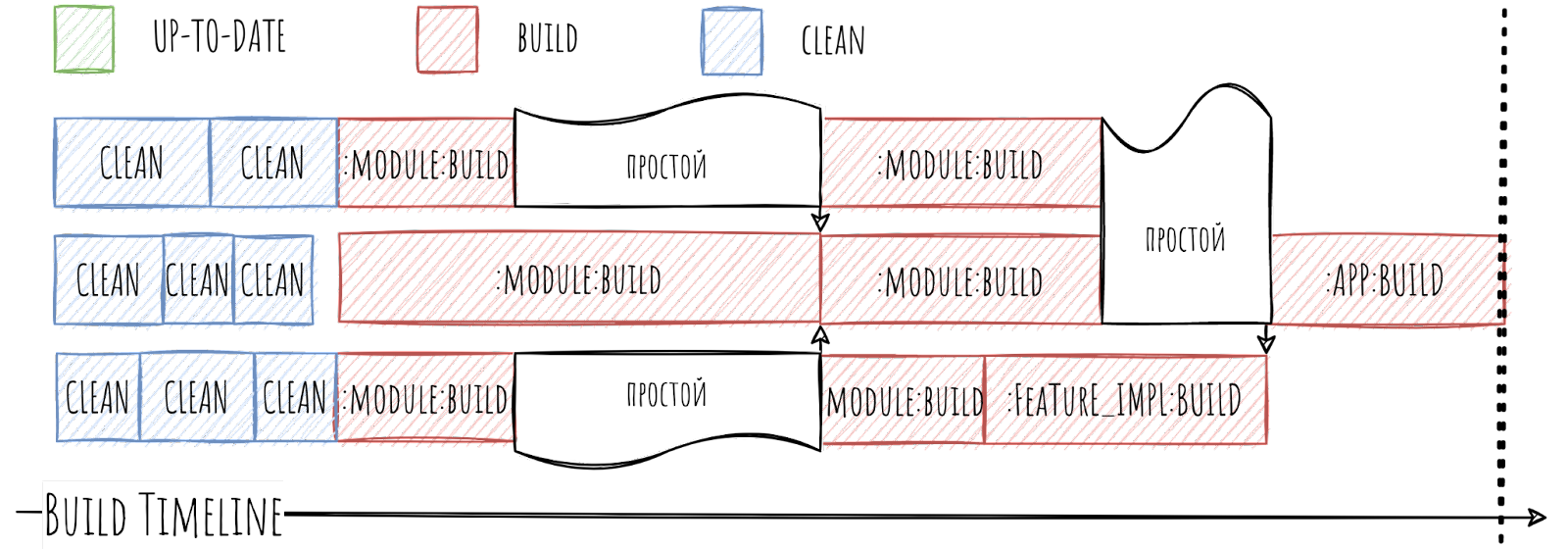
В момент простоя Gradle Worker’у нечем заняться, так как он ожидает сборки нашего бутылочного горлышка. Как следствие, мы не используем 100% потенциальных ресурсов, и сборка собирается дольше, чем могла бы.
Многие внедряют многомодульность ради скорости сборки, а тут такая подстава.
С другой стороны, ну были какие-то простои, но вроде немного… Так-то оно так, но когда мы захотим добиться ещё большего уменьшения времени сборки и попробуем использовать 6 Gradle Worker, то увидим более печальную картину.
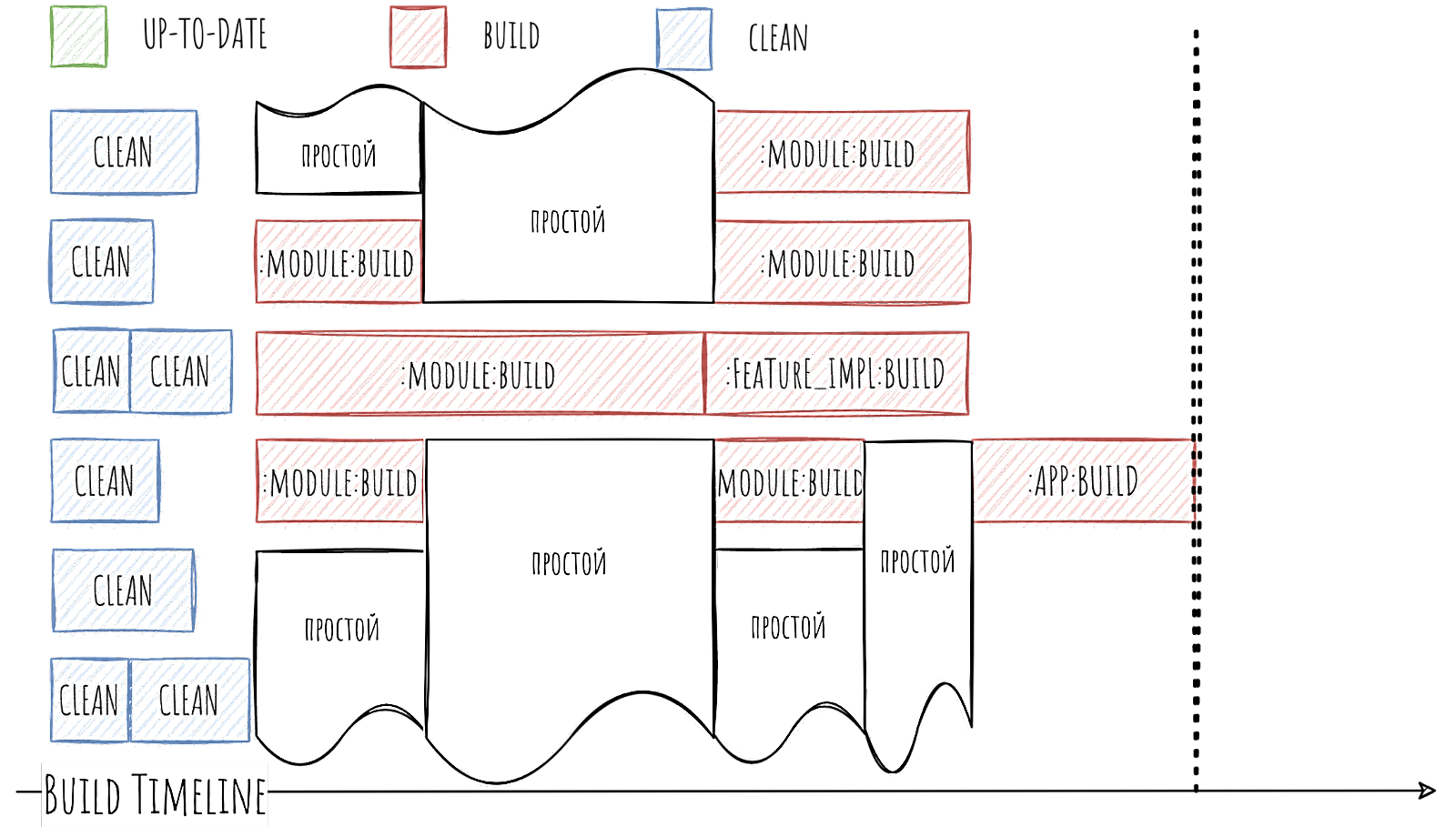
Чуть ли не половину времени Gradle Worker’ы будут простаивать. И вот это уже не шутки. Ведь мы использовали всего-то 6 Gradle Worker. В наше время 12 или 16 поточные процессоры в локальных машинах не редкость и хотелось бы утилизировать всю их мощь. 6 Gradle Worker забьют их максимум на 70%. А что уж говорить про CI, где 64 или 128 потоков это норма.
Как итог написанного выше: из-за бутылочных горлышек время сборки больше, чем могло бы быть, что, по сути, равноценно увеличению времени сборки. Значит, разработчики дольше разрабатывают, а значит, теряются деньги. Никто не любит терять деньги.
Логично, что надо как-то бороться с этими паразитами, но для начала их надо как-то найти.
Поиск бутылочных горлышек
Итак, какие варианты: Google, частный сыщик или может объявление на столбе?
Если без глупых шуток, то варианта у нас всего два:
Ручной, точнее, глазной, ну то есть визуальный. Из минусов — низкая точность, я бы сказал «на глаз», и не очень быстро. Из плюсов — не требует никакой подготовки.
Автоматизированный. По сути, антипод ручного. Из плюсов — более высокая точность и высокая скорость. Из минусов — надо кодить, но точно ли это минус?
Ручной способ
Весь способ основывается на Gradle Scan. Это встроенная возможность Gradle генерировать очень и очень подробный отчёт о сборке. Для того чтобы он сгенерировался нужно просто добавить параметр --scan. Например:
./gradlew assembleDebug --scanВ итоге вам придёт ссылка на отчёт, который необходимо будет активировать.
Из этого отчёта нас интересует только один раздел — Timeline. В котором, как ни странно, нам нужен будет сам timeline. Выглядит он примерно так:

Мы видим каждого из Gradle Worker’ов в качестве горизонтальной линии. В данном случае их 8. А также можно увидеть, чем занимался каждый из Gradle Worker в любой момент времени. Серым цветом обозначены какие-либо Tasks, а когда ничего нет, то это простой.
С такого отдаления мало что можно разглядеть, поэтому приблизим первый блок с простоями, благо Gradle Scan позволяет это сделать.

Тут уже можно подробно разглядеть и сами простои и их причины.
Далее, видим, что в определённый момент времени какой-либо модуль собирался в одиночестве. Смело обвиняем его в том, что он блокировал сборку, а значит, является бутылочным горлышком. Проводим экзекуцию (об этом далее) и заново начинаем поиск.
Сразу оговорю важный момент, полностью от простоев вы не избавитесь. Всегда будут микромоменты, когда кто-то кого-то блокирует, или кто-то кого-то ждёт. Поэтому не стоит сильно упарываться, и как только достигните показателя в 5—10% простоев, то можно остановиться.
Также нужно понимать, что если вы достигли идеального результата и все четыре ваших Gradle Worker’а всё время чем-то заняты…

То просто запустите проект на 16-ти Gradle Worker’ах и разрушьте иллюзию.

В итоге опять чуть ли не половину времени занимают простои. Можно очень долго повышать количество Gradle Worker и долго пытаться бороться с горлышками. Но лучше просто в количестве Gradle Worker отталкивайтесь от количества ваших модулей и вашего железа. Большинству компаний вряд ли понадобится больше 16 штук.
Такой способ хорошо подходит, если у вас меньше 100 модулей или 5—7 разработчиков. Просто раз в квартал находите самые злостные бутылочные горлышки и исправляете.
А что, если модулей сильно больше? Или разработчиков 25? Как следствие проблемы с бутылочными горлышками будут возникать чаще и бить больнее. Ведь простои на 60 секунд за год накапают на приличное количество впустую потраченного времени. Значит, это дело надо как-то автоматизировать.
Автоматический способ
По сути, нам просто надо автоматизировать те действия, что мы совершали в ручном способе. А как вообще автоматизировать то, что мы наблюдаем? Начнём с того, как не надо это делать.
Как не стоит мерить
Во-первых, не стоит строить автоматизацию вокруг длительности сборки модуля. Ведь тот факт, что модуль собирается долго, ещё не означает, что он является бутылочным горлышком. Он может ни от кого не зависеть, да и от него будет зависеть только, например, app. В итоге блокировать он никого не будет и спокойно себе соберётся параллельно с другими модулями.
Во-вторых, не стоит строить автоматизацию вокруг количества связей модулей. Может показаться, что если от нашего модуля зависит, допустим, 20 других модулей, то он плохой и выступает бутылочным горлышком. Это может быть какой-нибудь core-network, который просто выступает фасадом для всех библиотек связанных с сетью, и собирается от силы 2 секунды. Да и не факт, что он прям заблокирует Gradle Worker’ы, ведь параллельно с ним могут в спокойном режиме собираться какие-нибудь core-database или core-location.
Сами по себе это действительно рабочие показатели, которые могут многое рассказать о проблемах с вашими модулями. Но в нашем «уголовном деле» о бутылочных горлышках это лишь косвенные улики.
Поэтому сначала посмотрим, что интересного нам может предоставить Gradle, и что мы можем с этим сделать. Начнём с визуализации данного действа, а потом закрепим это кодом.
Визуализация
Вспомним, что нам показывает Timeline в Gradle Scan: несколько Gradle Worker, которые в определённый момент времени занимаются какой-то задачей, связанной с отдельными модулями. На глаз легко увидеть простои.
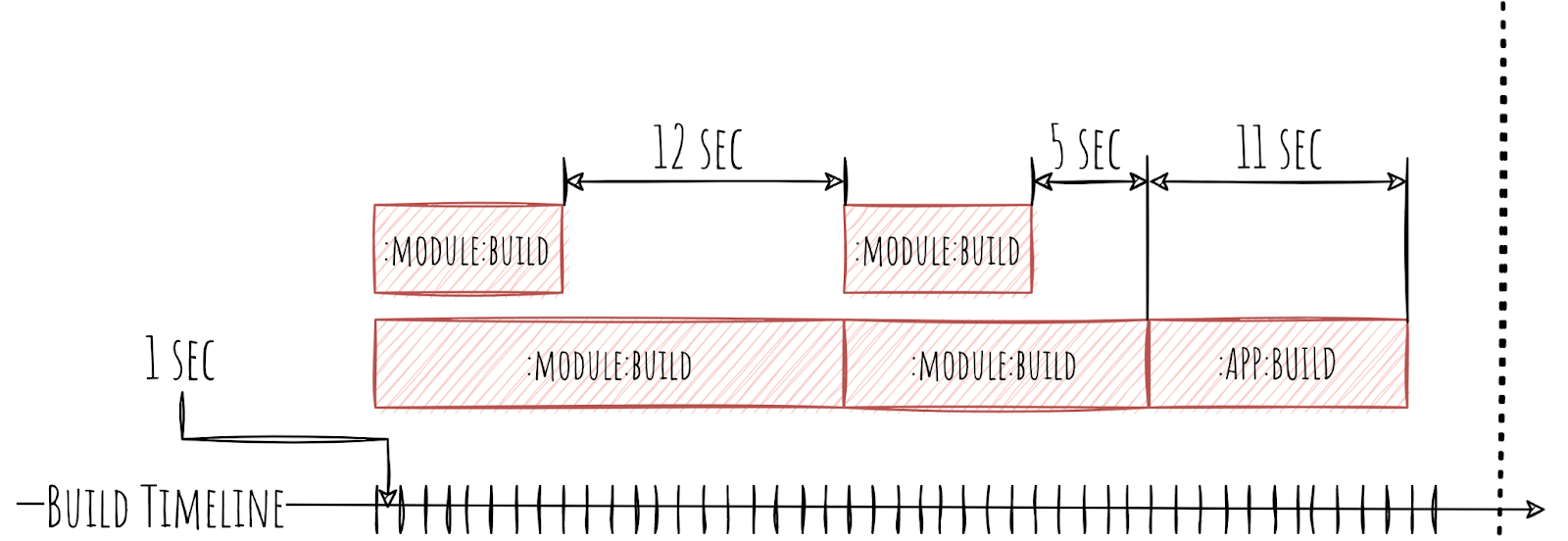
Более того, мы можем не только их увидеть, но и померить сколько времени Gradle Worker простаивал. И из этого мы уже видим виновника простоев. Что из информации, которую нам предоставляет Gradle, может помочь нам сделать это автоматически?
Что нам даёт Gradle
Конечно же, Gradle предоставляет нам время начала работы над каждой из Task.
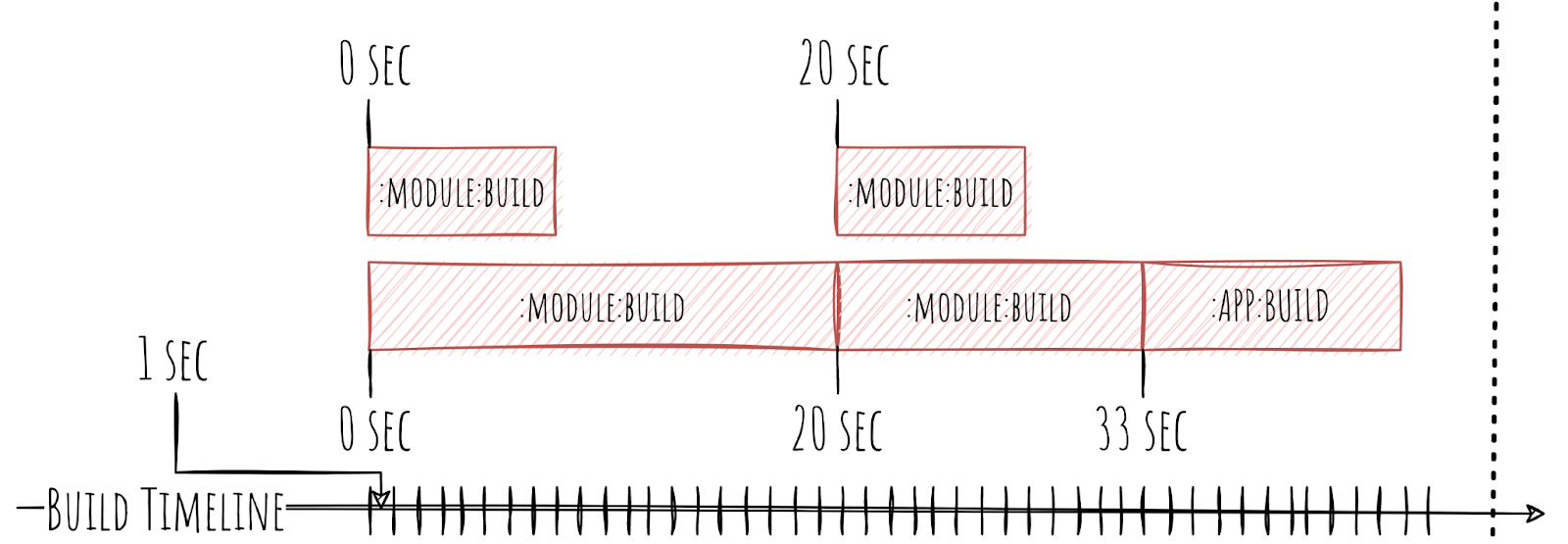
Также он предоставляет нам время конца этой Task. Благодаря этому, мы можем вычислить и продолжительность каждой из Task.
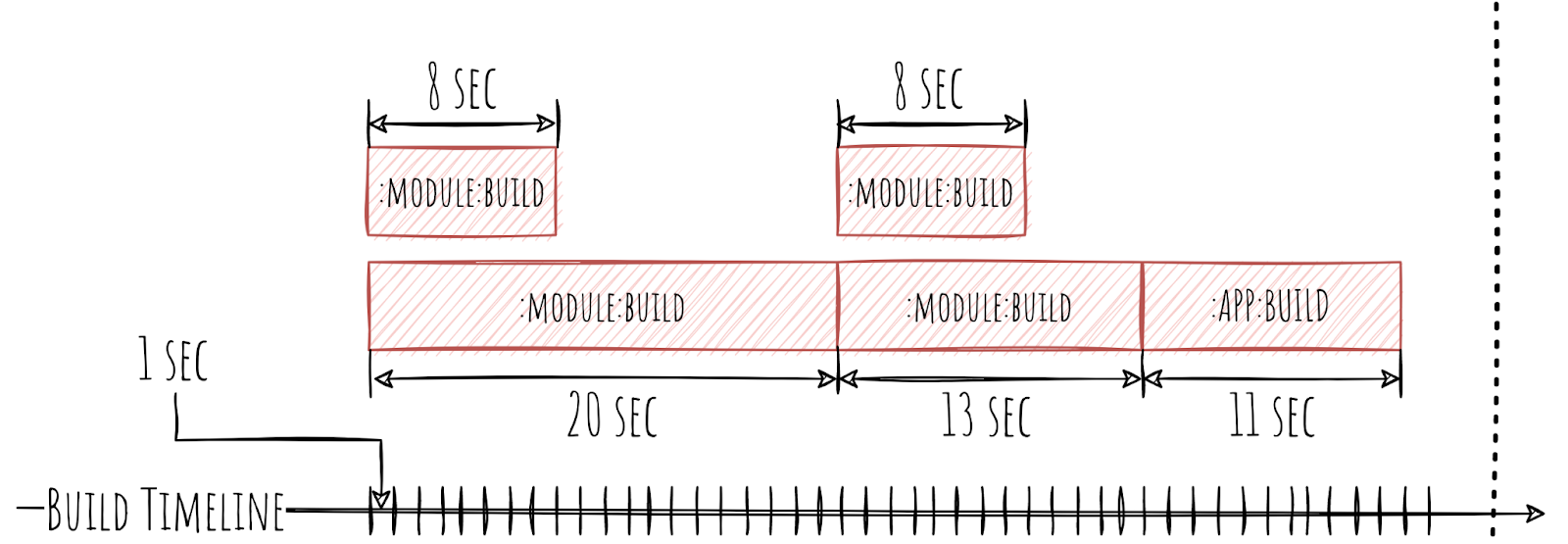
По сути, это вся информация, которая нам может понадобиться. Немного. Может возникнуть вопрос — «И ради этого ты рисовал диаграммы? Серьёзно?». И мой ответ: «Да, так понятнее».
Данные у нас есть, но что с ними теперь делать?
Что нам с этим делать?
Конечно же, двумерный массив. Скорее, конечно, список списков, ведь так чуть удобнее.
Главный список у нас будет размером равным количеству секунд времени сборки. Длится сборка 87 секунд, значит и список будет из 87 элементов. Во вложенном списке будут модули, которые собирались в данную секунду. Если попытаться это визуализировать, например, для двух Gradle Worker, то это будет выглядеть как-то так.

Весьма похоже на обычный timeline, только разбитый на сегменты.
Теперь надо с помощью этих данных научится вычислять бутылочные горлышки. Пробежимся по главному списку и если в данную секунду количество собираемых модулей меньше чем 2 (количество Gradle Worker), то начисляем единственному модулю 1 балл.
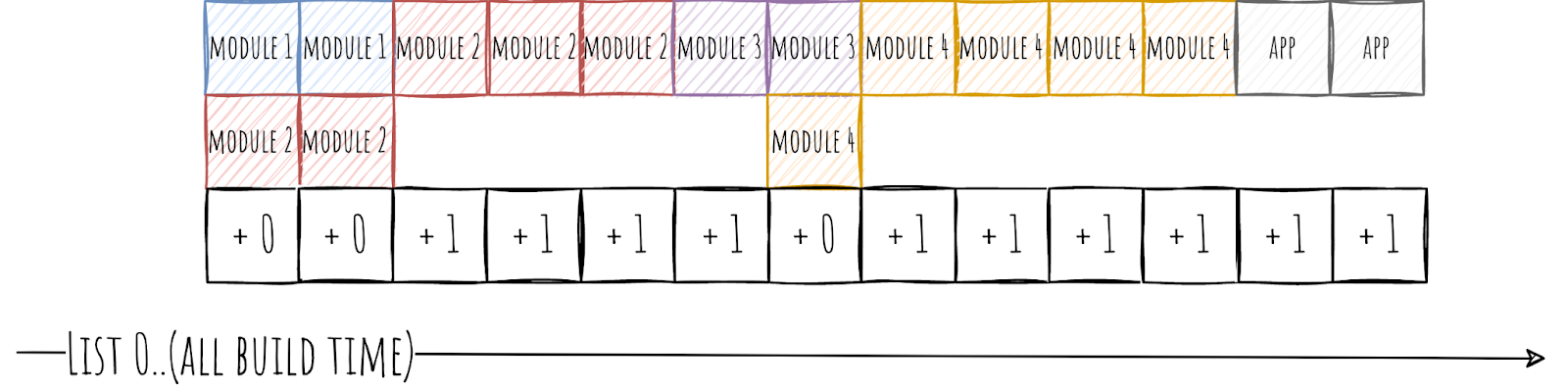
По сути, 1 балл у модуля означает, что в данный момент собирался только он, а все остальные его ждут, а значит, был простой ресурсов на 1 секунду.
Так как вряд ли вы используете всего два Gradle Worker, то надо как-то усложнить алгоритм. Поэтому рассмотрим на примере аж трёх Gradle Worker.
Основная логика остаётся прежней, но чуть обрастает жирком. Всё так же бежим по главному списку и выставляем каждому модулю в списке количество баллов равное общему количеству Gradle Worker минус количество занятых Gradle Worker и в конце поделим результат на количество занятых Gradle Worker. Для понимания я даже сделал сверхсложную формулу: (wA - wU) / wU, где wA это общее количество Gradle Worker, а wU количество занятых Gradle Worker.
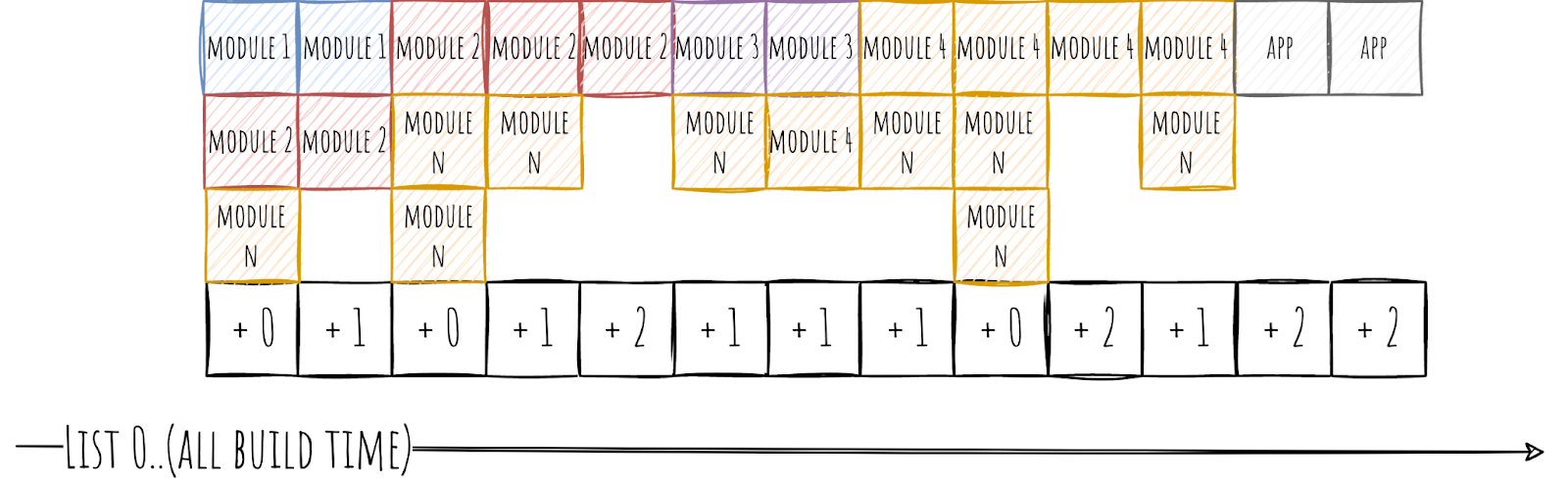
В итоге мы видим, насколько каждый из модулей внёс свой вклад в простои в секундах. Например, если у нас работали два Gradle Worker из трёх, то каждому из модулей зачисляем по 0.5 секунды. А если работал только один, то модуль получит аж 2 секунды.
Алгоритм может показаться не очень точным. Так оно и есть, но тут высокая точность не важна, так как итоговая цель — не отсортировать все модули по вредности, а выявить только самые вредные модули. Ведь если модуль приводит к простоям на полсекунды, то на исправление этой ситуации вы потратите больше времени, чем сможете выиграть.
А как это выглядит с точки зрения кода?
Код
Для начала нам надо как-то достать необходимые данные из Gradle. Это можно сделать внутри кастомного Gradle Plugin.
Достаём данные
Для этого Gradle нам предоставляет такую штуку как BuildService, в который мы можем имплементировать OperationCompletionListener.
public interface OperationCompletionListener {
void onFinish(FinishEvent event);
}В его метод onFinish приходит нужная нам информация о каждой из завершённых Task.
Из этого мы уже можем слепить собственный data класс с нужными нам полями.
data class TaskExecutionData(
val projectName: String,
val taskName: String,
val startTime: Long,
val endTime: Long
)Здесь projectName — имя модуля, taskName — имя Task, startTime и endTime — время начала Task в миллисекундах и окончания Task в миллисекундах.
Данные мы получили, теперь их надо как-то обработать.
Обрабатываем данные
У нас есть куча данных по каждому из Task. Для начала соберём из них Set которому дадим лаконичное название taskDataSet.
Настало время сделать наш список списков, то есть Timeline.
private fun createTimeline(
taskDataSet: Set<TaskExecutionData>
): List<Set<TaskExecutionData>> {
...
}Сначала вычисляем общее время сборки — buildTime. Для этого находим время начала самой первой Task — startTime и время окончания самой последней Task — endTime. Дальше buildTime вычислить несложно, просто вычитаем startTime из endTime.
val startTime = taskDataSet.minOf { it.startTime }
val endTime = taskDataSet.maxOf { it.endTime }
val buildTime = endTime — startTimeВ итоге создаётся список размером c buildTime. То есть количество миллисекунд, которое заняла сборка. Да-да, именно миллисекунд. В отличии от визуализации, где всё считалась в секундах, в реальном коде лучше использовать миллисекунды. Дело в том, что многие Task по длительности сильно меньше, чем одна секунда, и может сложиться ситуация, когда мы не учли какую-то Task или случайно посчитали её дважды.
val timeline = 0..buildTimeОсталось превратить наш timeline в список списков. Для этого бежим по списку timeline через map и в каждой из миллисекунд формируем абсолютное время — calcTime. Далее находим в списке Task которые выполнялись в данную calcTime миллисекунду с помощью оператора filter.
timeline.map { currentBuildTime ->
val calcTime = startTime + currentBuildTime
taskDataSet
.filter { calcTime >= it.startTime }
.filter { calcTime < it.endTime }
.toSet()
}Сшив все куски вместе, получаем полноценный метод, который строит необходимый нам timeline.
private fun createTimeline(
taskDataSet: Set<TaskExecutionData>
): List<Set<TaskExecutionData>> {
val startTime = taskDataSet.minOf { it.startTime }
val endTime = taskDataSet.maxOf { it.endTime }
val buildTime = (endTime — startTime)
val timeline = 0..buildTime
return timeline.map { currentBuildTime ->
val calcTime = startTime + currentBuildTime
taskDataSet
.filter { calcTime >= it.startTime }
.filter { calcTime < it.endTime }
.toSet()
}
}Теперь надо из этого timeline сделать список модулей с заблокированным ими временем.
Для этого сначала определяем количество Gradle Worker, задействованных при сборке.
val maxWorkerCount = timeline.maxOf { it.size }Затем бежим по timeline и для каждой миллисекунды определяем время простоя — blockedTime, по знакомой нам формуле.
timeline.forEach { set ->
val blockedTime = (maxWorkerCount — set.size).toDouble() / set.size
...
}Ну и осталось подсчитать время простоя вызванное каждым из модулей. Для этого просто прибавляем blockedTime к значению из Map, в которой ключом является имя модуля, а значением — общее время простоя, вызванное модулем.
set.forEach { taskData ->
val moduleName = taskData.projectName
val previous = blockedTimeMap.getOrDefault(moduleName, 0)
blockedTimeMap[moduleName] = previous + blockedTime
}Всё вместе это выглядит так.
private fun createBlockedTimeList(
timeline: List<Set<TaskExecutionData>>
): List<Pair<String, Double>> {
val maxWorkerCount = timeline.maxOf { it.size }
val blockedTimeMap = mutableMapOf<String, Double>()
timeline.forEach { set ->
val blockedTime = (maxWorkerCount — set.size).toDouble() / set.size
set.forEach { taskData ->
val moduleName = taskData.projectName
val previous = blockedTimeMap.getOrDefault(moduleName, 0)
blockedTimeMap[moduleName] = previous + blockedTime
}
}
return blockedTimeMap.toList()
}Сделаю небольшое отступление и скажу, что данное решение скорее для примера. В реальности лучше в качестве ключа использовать имя Task, а не модуля. За счёт этого можно будет применить фильтр к имени Task и найти не только слишком долго собирающиеся модули, но и, например, модули со слишком долгой кодогенерацией или слишком долгим прохождением Unit-тестов.
Но вернёмся к нашему коду. Мы составили список, теперь надо сформировать из него итоговый результат и вывести его.
Выводим результат
Всё просто: фильтруем, да сортируем.
val bottlenecks = blockTimeList
.filter { it.second > 5000.0 }
.sortedBy { it.second }
.takeLast(5)
.reversed()
println("Bottlenecks:\n${bottlenecks.joinToString("\n")}")Бежим по нашему списку и для начала отсеиваем некритичные для нас простои. Пусть это будет 5 секунд, то есть 5000 миллисекунд. Далее сортируем по времени простоя, забираем 5 самых злостных нарушителей и разворачиваем список, чтобы проще было читать.
В итоге мы увидим что-то вроде такого:
Bottlenecks:
(feature_1_impl, 100000)
(base_module_1, 90000)
(feature_2_impl, 50000)
(base_module_3, 40000)
(app, 30000)Мы нашли самые вредные из горлышек. Основная задача выполнена. Можно вместо вывода в лог сделать проверку на CI на то, что не появилось модулей, которые создают простоев более чем на, допустим, 10 секунд, и запускать перед залитием кода в develop. Так можно отсечь большую часть проблем.
В целом, можно применить более сложный и точный алгоритм с учётом большего количества различных показателей, вроде тех же длительности и количества связей. Но, честно говоря, я не вижу в этом сакрального смысла. Пока, по крайней мере. Ведь самых злостных нарушителей такой алгоритм найдёт, а с мелкими бороться невыгодно.
Так что, теперь давайте разберём, какие виды горлышек бывают, и как с ними бороться.
Виды горлышек, и как с ними бороться
Я попытался как-то систематизировать виды горлышек, которые наблюдал лично. Поэтому я не могу ручаться, что это прям все-все виды. Вероятно, в вашем проекте может возникнуть что-то иное. Я выделил для себя следующие виды в порядке их вредности для времени сборки:
Разросшийся базовый модуль.
Главный модуль.
Модуль с плохой иерархией.
Продуктовый монолит.
Теперь подробнее про каждый из них. Начнём с базового модуля.
Разросшийся базовый модуль
Как и говорит нам название — это просто базовый модуль, который, по какой-то причине, стал слишком большим. Причины могут быть разные, от изначально неудачной структуры базовых модулей, до неожиданного усложнения на каком-то из слоёв приложения.
Рассмотрим на примере. Допустим, у нас есть модуль base-data, в котором хранятся все базовые классы для работы с данными. Походы в сеть, работа с базой данных и т.п.

Это может вылиться в то, что если в вашем приложении произойдёт усложнение в работе с данными, то модуль станет собираться сильно дольше. При этом он будет блокировать сборку других модулей, которым нужна работа с данными.
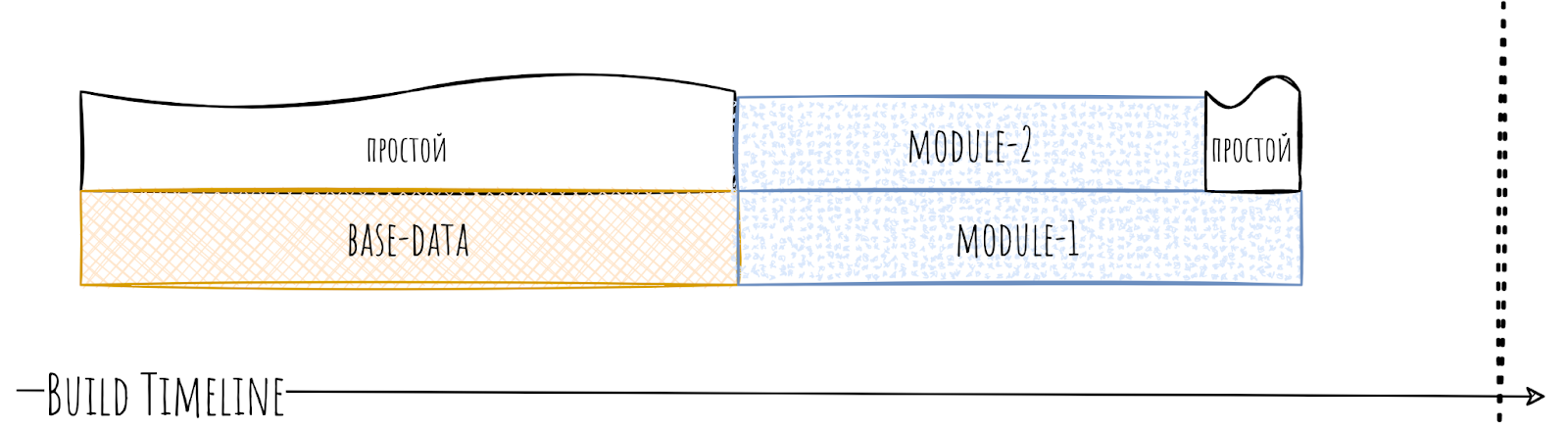
В итоге у нас появляется простой.
Как побороть это? Распил. Надо залезть внутрь модуля и понять — нет ли в нём составных частей, которые можно было бы вынести отдельно.
В 90% случаев в базовых модулях такие части можно найти без особых усилий. Скорее всего, они даже будут слабо связаны между собой. Наш модуль base-data без зазрения совести разделяем на два модуля: base-network и base-database.
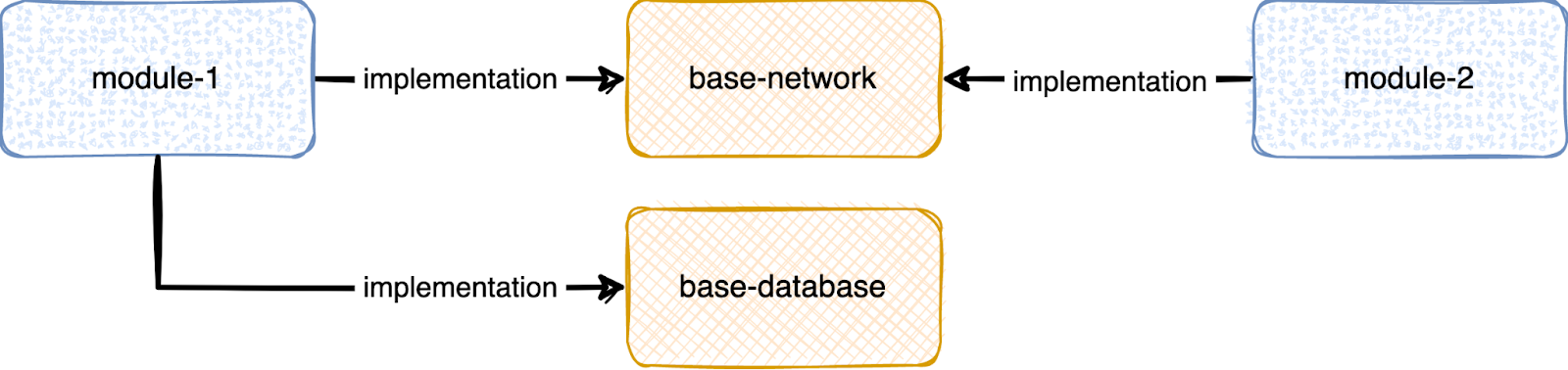
Каждый из этих «дочерних» базовых модулей будет собираться быстрее, чем base-data, а самое главное — они могут собираться параллельно друг другу. В итоге на timeline мы увидим сильные изменения.
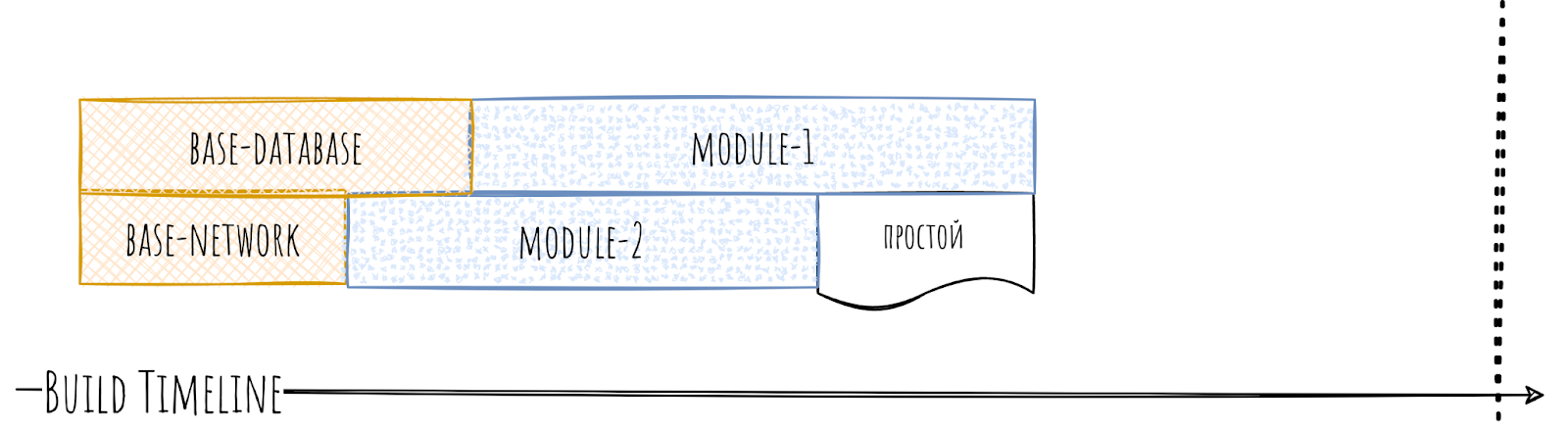
Помимо того, что базовые модули теперь собираются быстрее за счёт параллельности, так теперь и части модулей не нужна связь на base-database, и они смогут начать собираться сразу после сборки base-network, не дожидаясь base-database.
Как результат, простоев стало сильно меньше. Мы победили!
Но… Модуль то базовый и, как следствие, сильно популярный. Если распил его на составляющие вряд ли займёт у вас много времени, то вот разбираться в связях, кого и куда теперь надо подключать, ведь не всем нужна работа с сетью, и не всем нужна работа с базой данных, может занять очень и очень много времени. Даже на сотне модулей это неприятная задача, что уж говорить о 400 модулях и больше. Пока разберёшься с частью связей в develop, кто-то накинет ещё парочку.
Тут можно воспользоваться «лайфхаком». Можно превратить base-data в прокси модуль, к которому мы как api подключим новые модули base-network и base-database. Как следствие, все, кто подключает к себе base-data, транзитивно получат и его «дочерние» модули. При этом сам base-data может не содержать кода вообще.
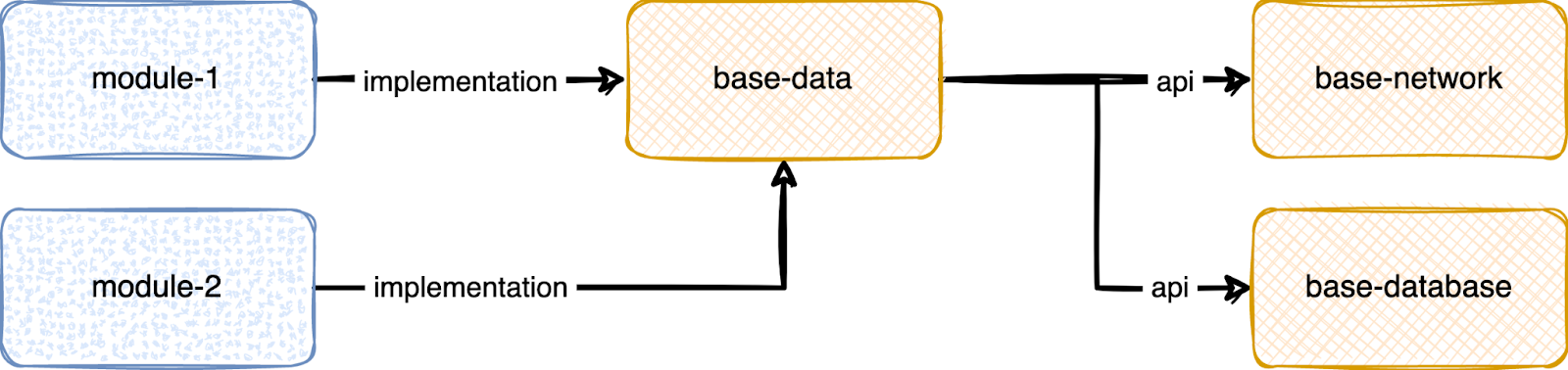
С точки зрения timeline у нас не всё так прекрасно: base-network и base-database собираются параллельно, но вот другие модули вынуждены ждать завершения base-data.
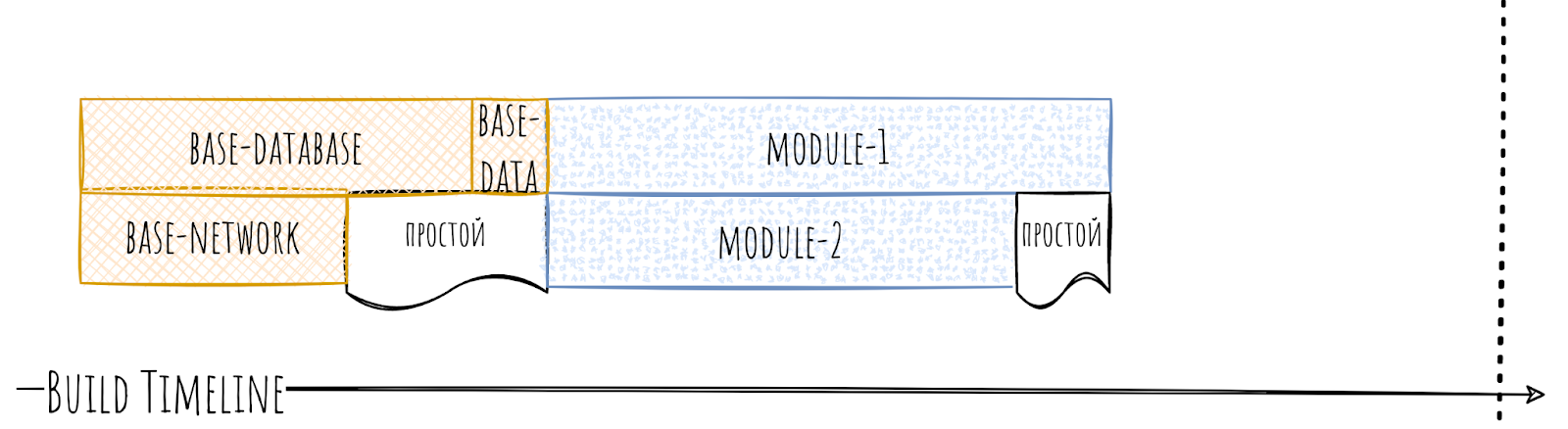
Зато мы получили возможность в момент распила сразу не разбираться со всеми зависимостями. Можно сначала выкатить распил. Затем запретить использовать base-data в новых модулях и в самом конце, потихоньку, без спешки разбираться с зависимостями по одному модулю. За счёт этого «лайфхака» и низкой связности распил базовых модулей вряд ли будет для вас слишком сложным. Поэтому повышаем сложность и посмотрим на app.
Главный модуль
Обычно он у всех называется app, но может называться и по-другому или их может быть несколько. В него в итоге приходят все ветви дерева модулей. Он ствол этого могучего дерева, и из-за этого с ним есть проблемы.
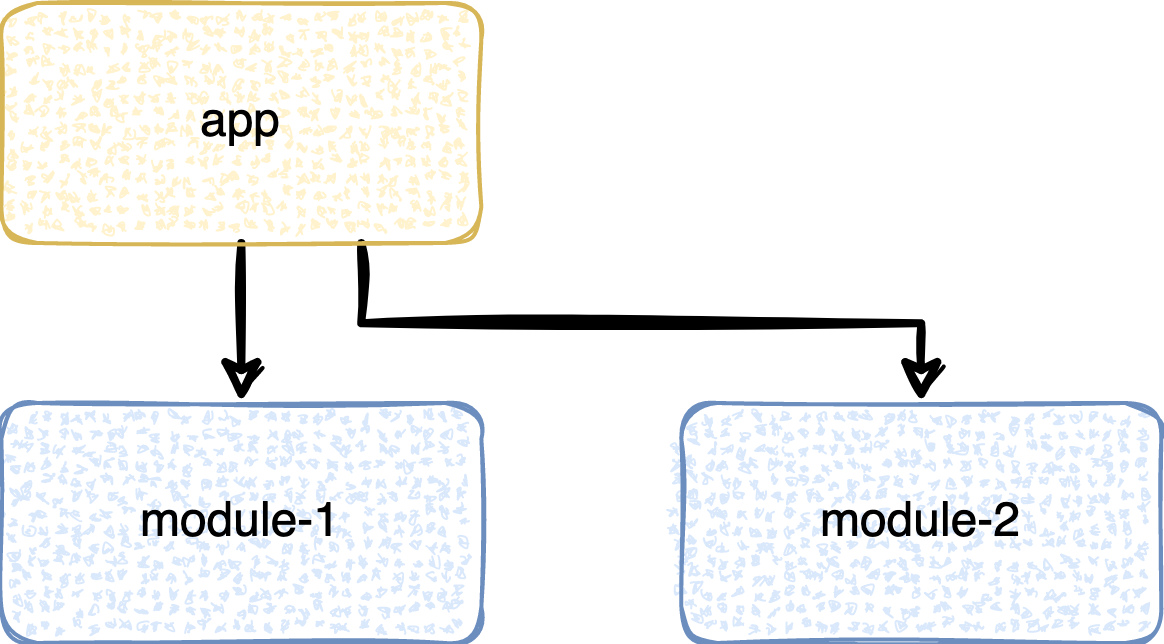
Он собирается последним, и стандартные модули не могут собираться параллельно с ним. И он становится бутылочным горлышком, не по своей воле, конечно, но всё таки.
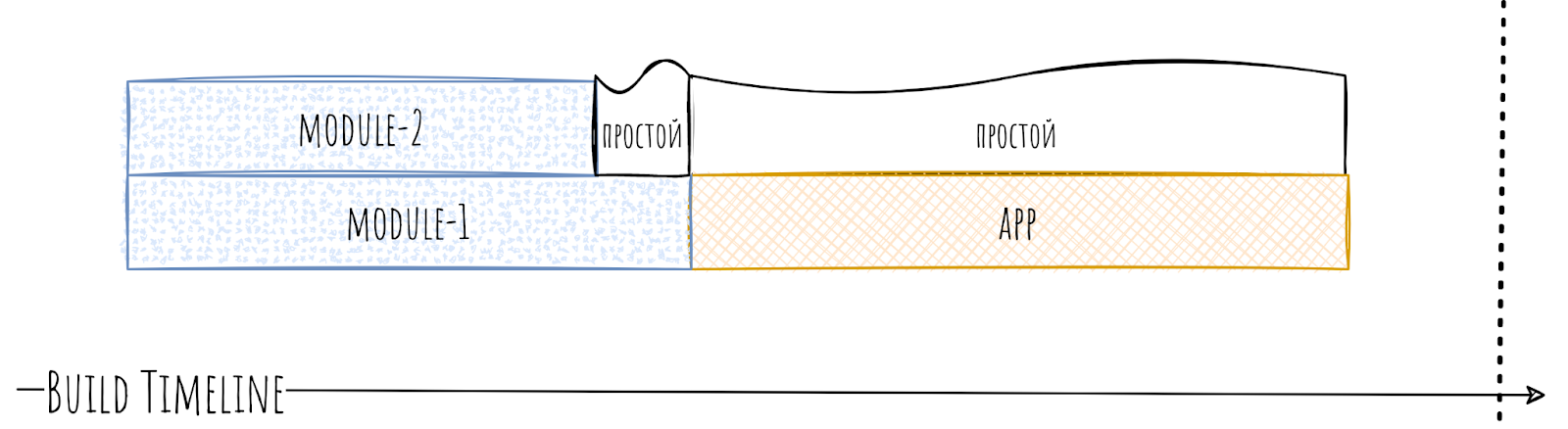
Получается, что пока собирается app, у нас генерируется простой. Ведь ему просто не с кем сбориться параллельно.
Что тут можно сделать? Распил. Опять.
Раз мы не можем побороть тот факт, что app является бутылочным горлышком, то надо хотя бы уменьшить время его сборки.
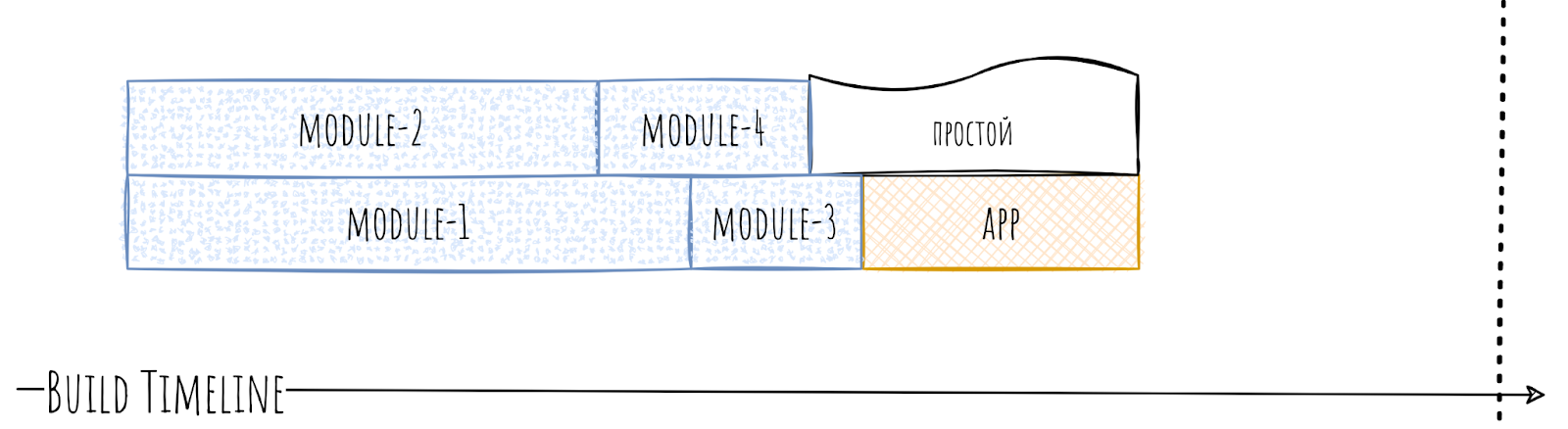
Поэтому выносим из app всё, что можно вынести, оставляя только то, что вынести нельзя или не имеет смысла. Желательно при этом распиливать в несколько модулей.
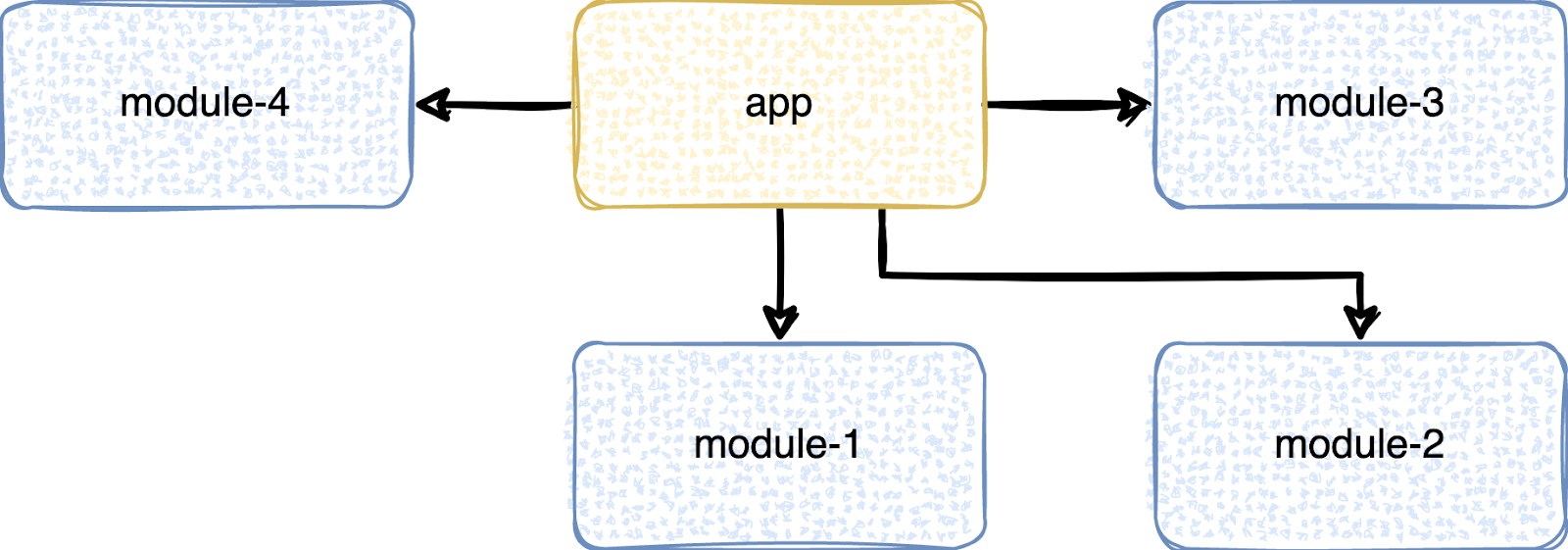
За счёт этого время сборки существенно улучшится, а время простоев уменьшится.
Но неужели никак нельзя избавиться от app как бутылочного горлышка насовсем? Вообще, способ есть. Но он крайне не универсален. Имя этого способа dynamic-feature. Магия тут в том, что app не подключает к себе dynamic-feature как обычный модуль. Наоборот, это dynamic-feature подключает к себе app и другие модули.

Польза тут именно в модулях, которые нужны только dynamic-feature. Они-то не обязаны зависеть от app и, как следствие, могут собираться с ним параллельно.
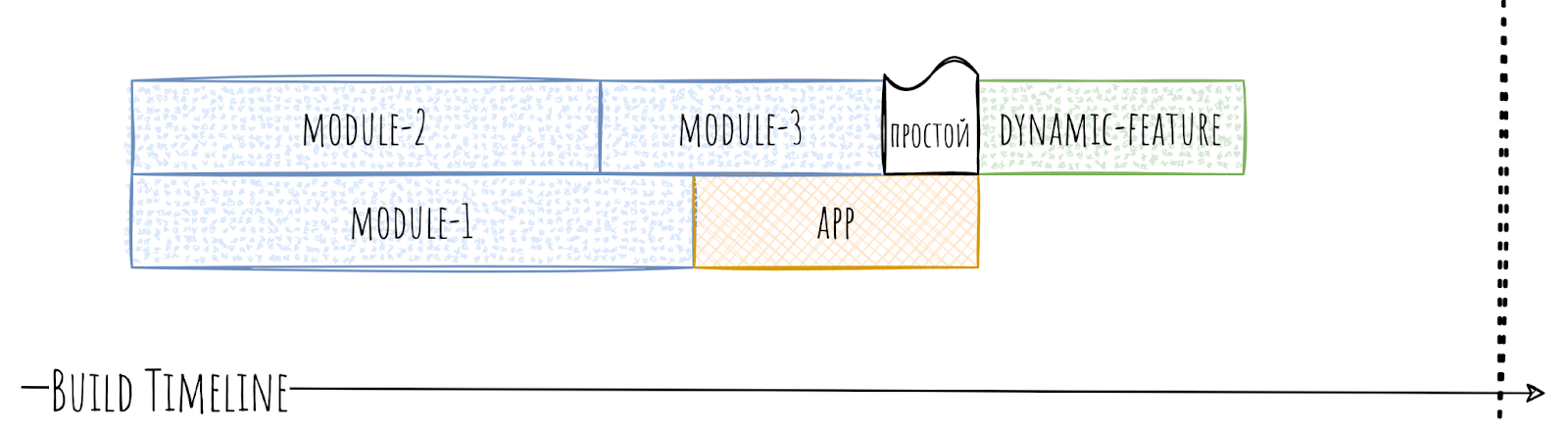
За счёт этого наше дерево модулей можно превратить в лес, и для скорости сборки это хорошо. Естественно, если у вас больше одной dynamic-feature. Если одна, то ситуация с app повторяется.
Способ, откровенно говоря, не для всех, даже если создавать install-time dynamic-feature. Как минимум придётся сменить или переработать связывание модулей. Да и публикация становится чуть сложнее.
Поэтому посмотрим на что-то более однозначное и доставляющее больше проблем.
Модуль с плохой иерархией
Как понятно из названия это какой-то модуль, у которого нечаянно или специально накосячили с иерархией.
Рассмотрим на таком примере:
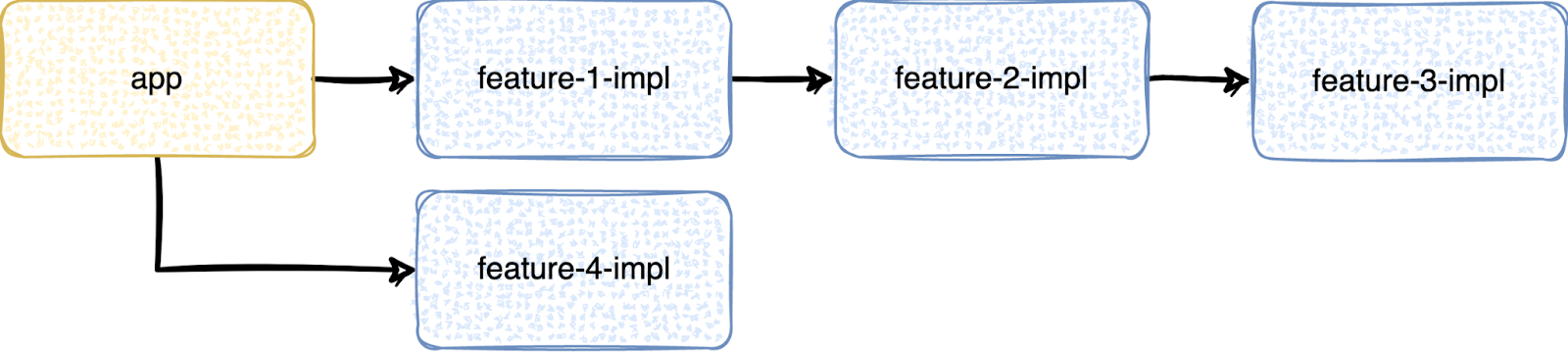
Фичёвый модуль feature-1-impl подключает к себе feature-2-impl, а тот в свою очередь подключает к себе feature-3-impl. Но ведь фичёвые модули не должны подключать друг друга напрямую? Да, не должны. Потому иерархия и плохая. Причин для её возникновения может быть множество — плохо распилили, недопоняли иерархию, торопились, банально опечатались, неудачно скопипастили build файл и т.п. Причин может быть множество, и они в текущем контексте не важны.
Важно то, что такая иерархия очень плохо влияет на скорость сборки.
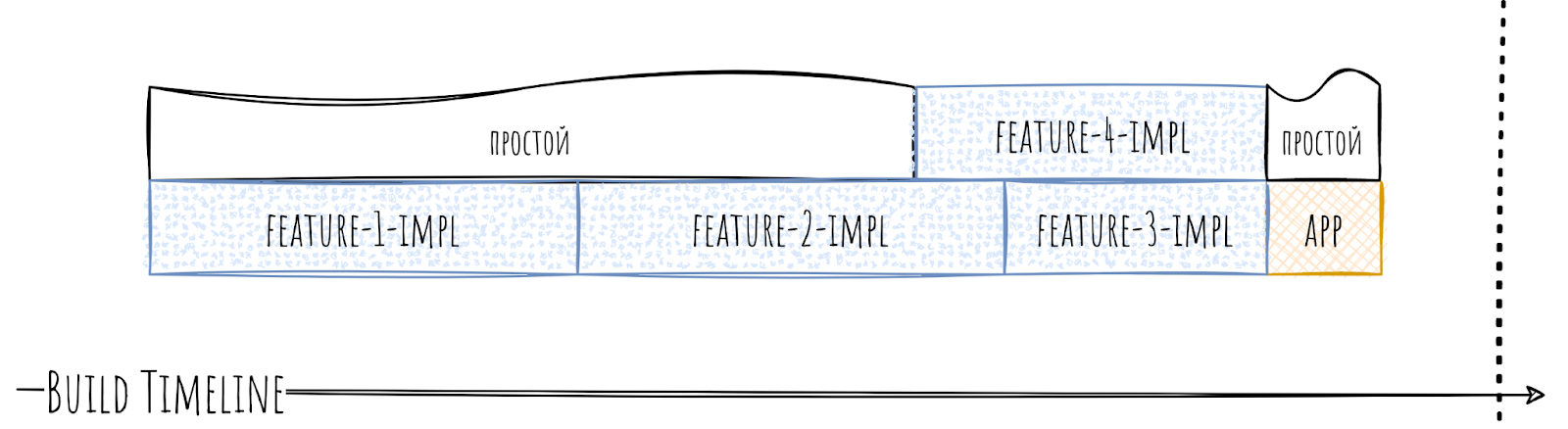
Могут генерироваться простои очень больших размеров. Так как, по сути, часть модулей стала собираться последовательно.
Что тут делать? Распил? На удивление, не распил. Нужно восстановить правильную иерархию. Для начала надо найти причину, почему такая иерархия вообще установилась. На удивление всё просто: отключаем неверную зависимость в build-файле и пытаемся собрать. Скорее всего, что-то отвалится и сборка не пройдёт. По сути, это и будет причина. В зависимости от ситуации общий для двух модулей компонент надо будет либо вынести в отдельное место, либо разделить на составные части, либо банально копировать. В итоге иерархия станет правильной.
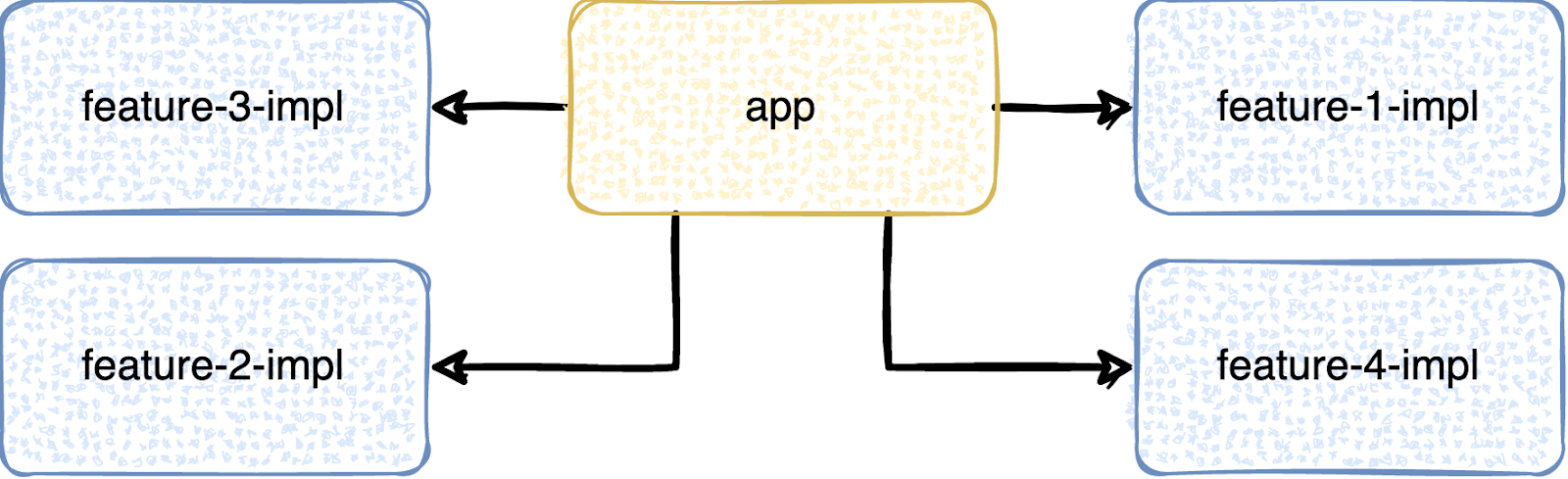
На время сборки это подействует крайне приятным образом, уменьшив количество простоев очень серьёзно.
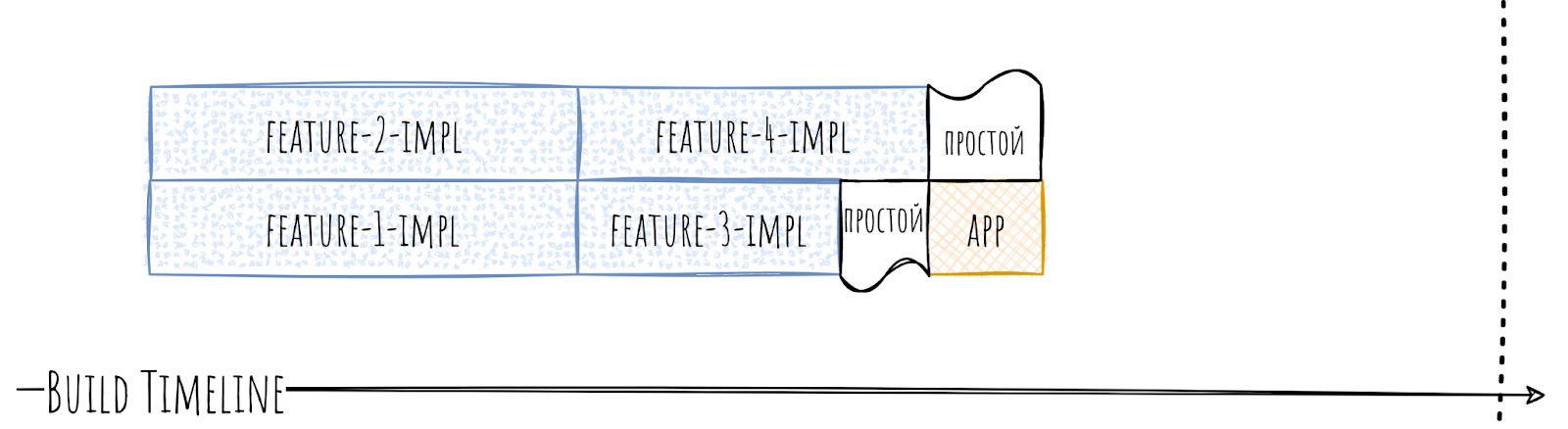
Несмотря на большой вред для времени сборки, такой тип горлышек довольно легко чинится. Что для нас определённо плюс.
Ну и давайте, наконец, взглянем на последний тип — продуктовые монолиты.
Продуктовые монолиты
А что за название такое — «продуктовый монолит»? А это просто я его сам придумал :)
Продуктовый монолит — это либо наследие из одномодульных времён, либо ошибка коллективного бессознательного группы разработчиков, когда они ради возможности что-то переиспользовать начинают всё складывать в какой-то один модуль. Каждый выносит только что-то своё, что не может навредить, но разработчиков-то 20, и в итоге получается гигантский монолитный модуль. Часто такими модулями являются модули со слишком общим названием — вроде utils или shared-list-ui, user-api/user-feature.
При этом такой модуль с точки зрения иерархии может прикидываться невинной овечкой.
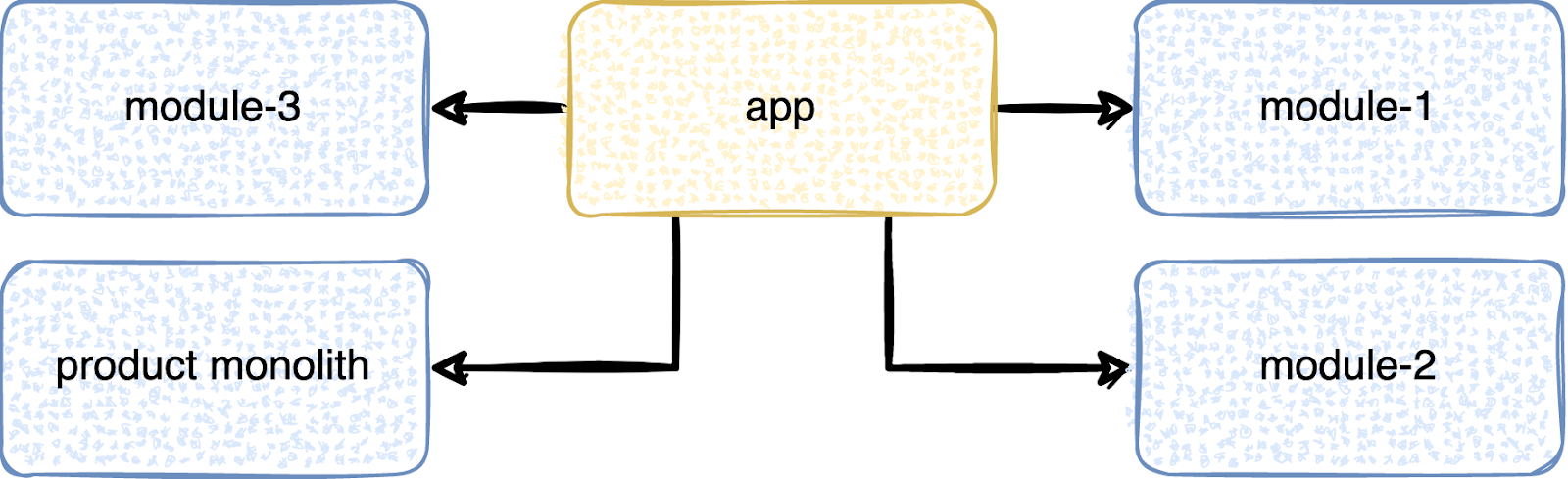
Но в timeline раскрывается его истинная суть. За счёт своего объема он может собираться в 5 и более раз дольше, чем обычный модуль, чем и вызывает простои.
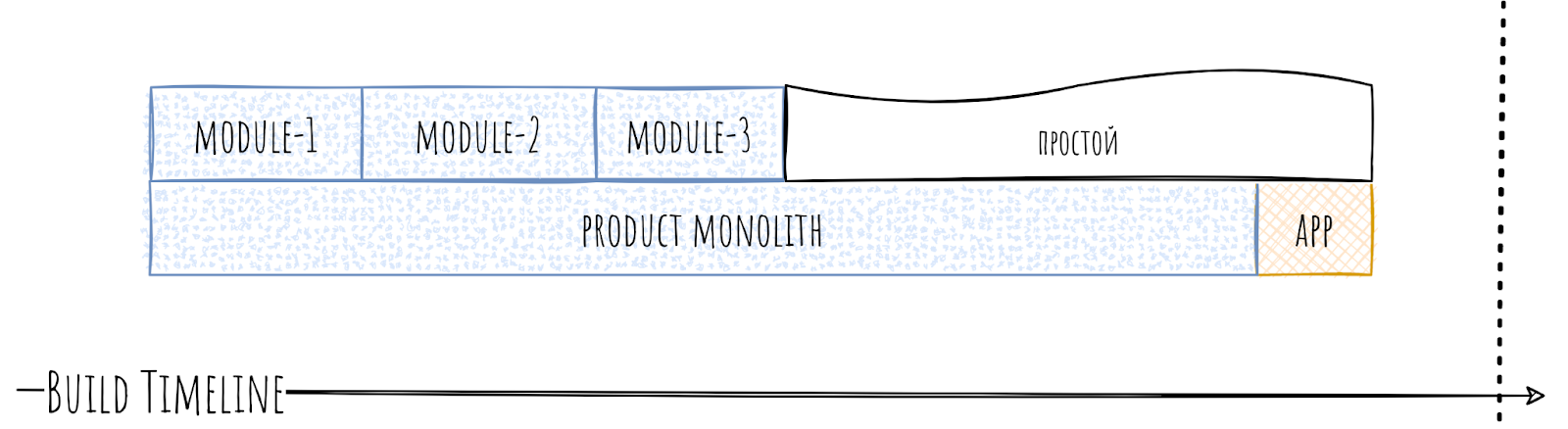
И как бы уже всё не радужно, но в реальности всё ещё хуже, потому что часто продуктовые монолиты содержат в себе и плохую иерархию. А так как модуль огромный, то и неправильных связей может быть много.
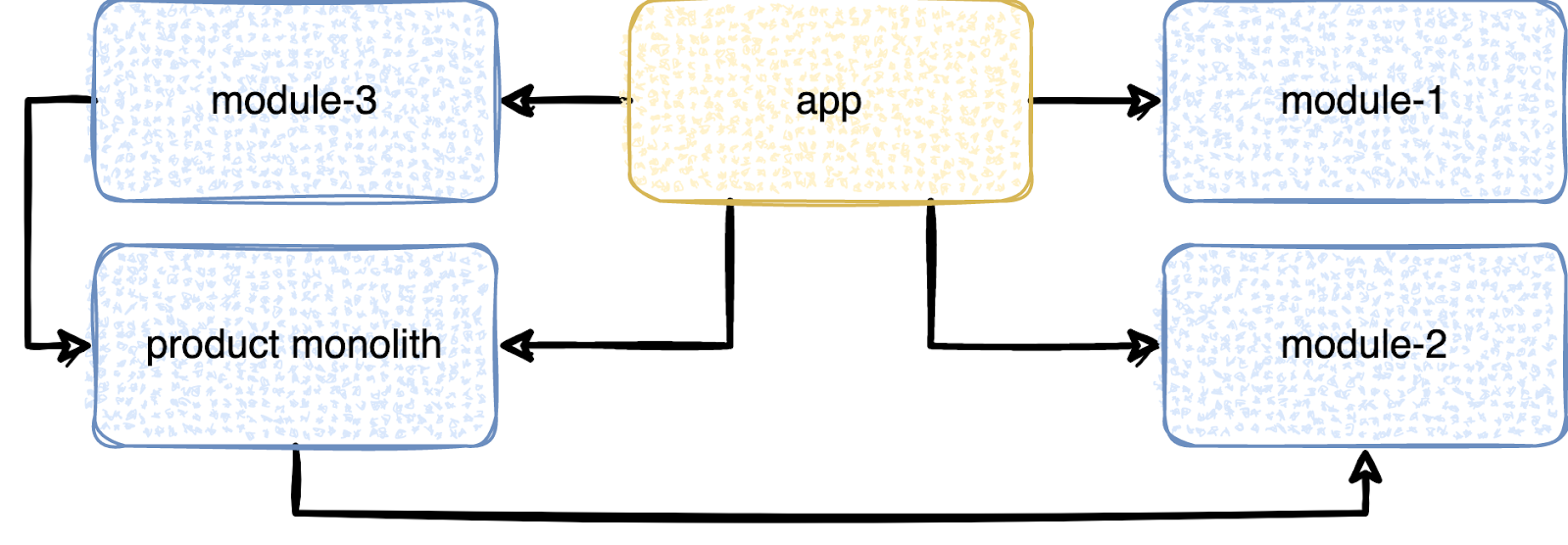
В итоге на timeline мы видим форменный ужас.
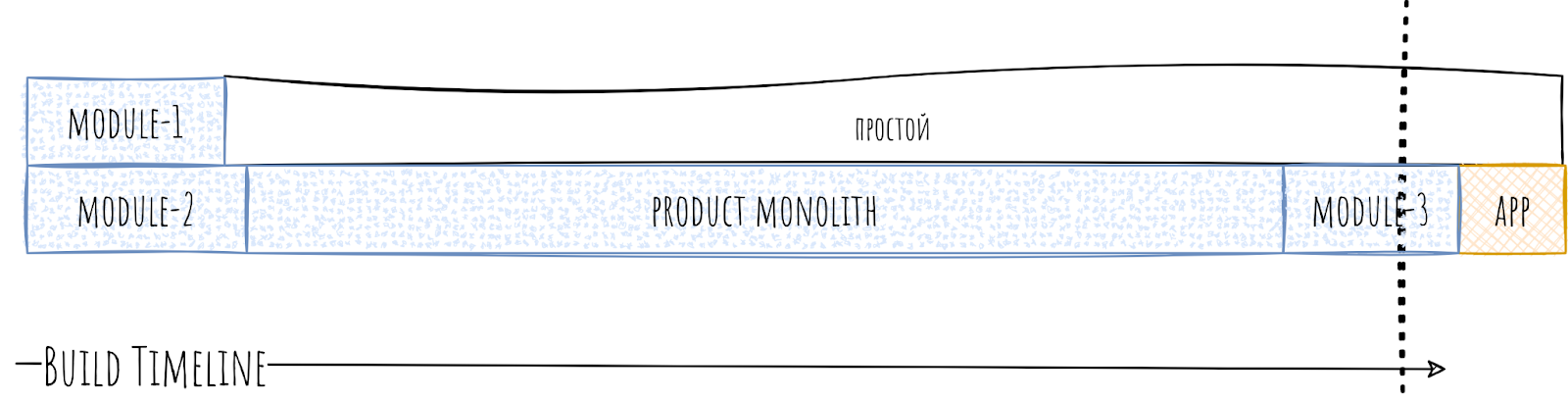
В итоге вместо параллельной сборки мы наблюдаем последовательную.
А что с этим делать? А то же самое, что мы делали с предыдущими типами горлышек. Восстанавливаем иерархию и распиливаем. Порядок этих действий может варьироваться, в зависимости от ситуации.
Для начала, допустим, восстановим иерархию с помощью каких-то общих модулей.
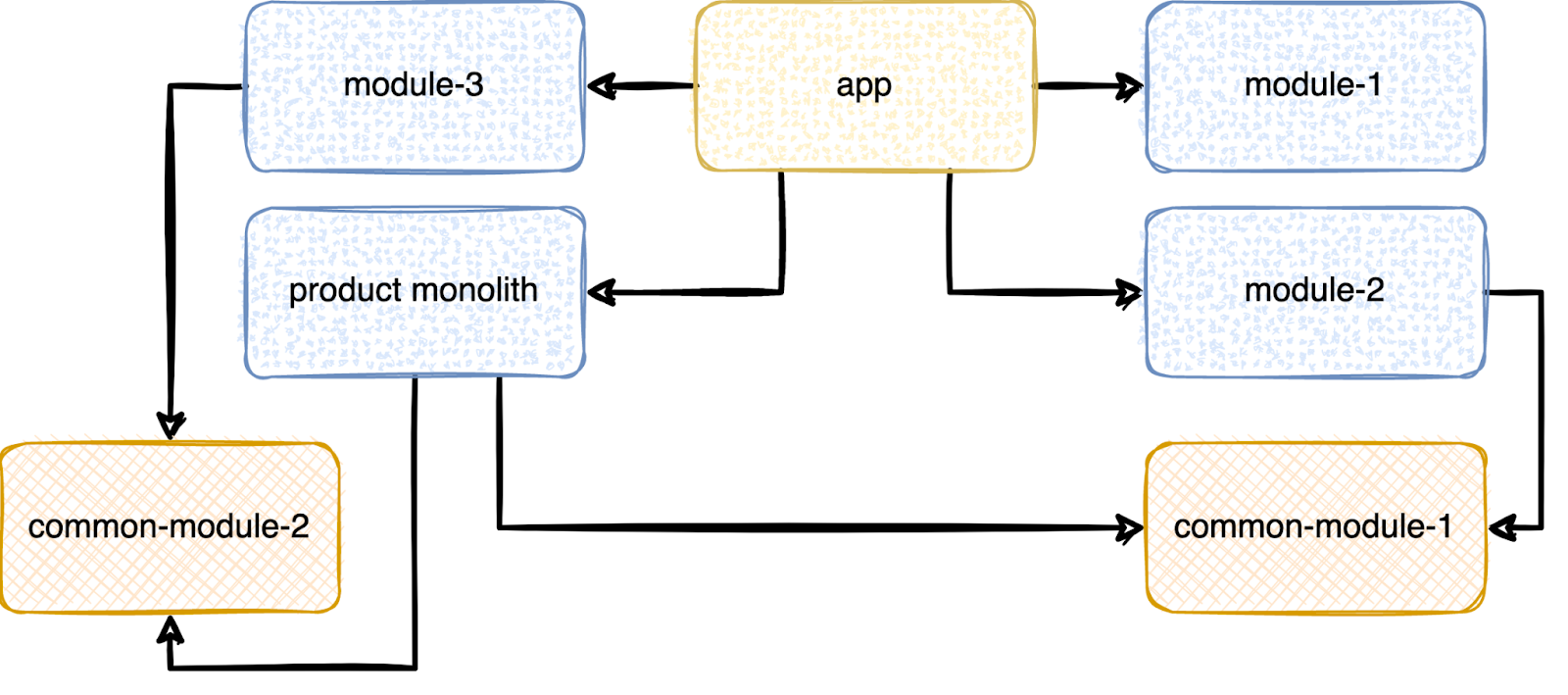
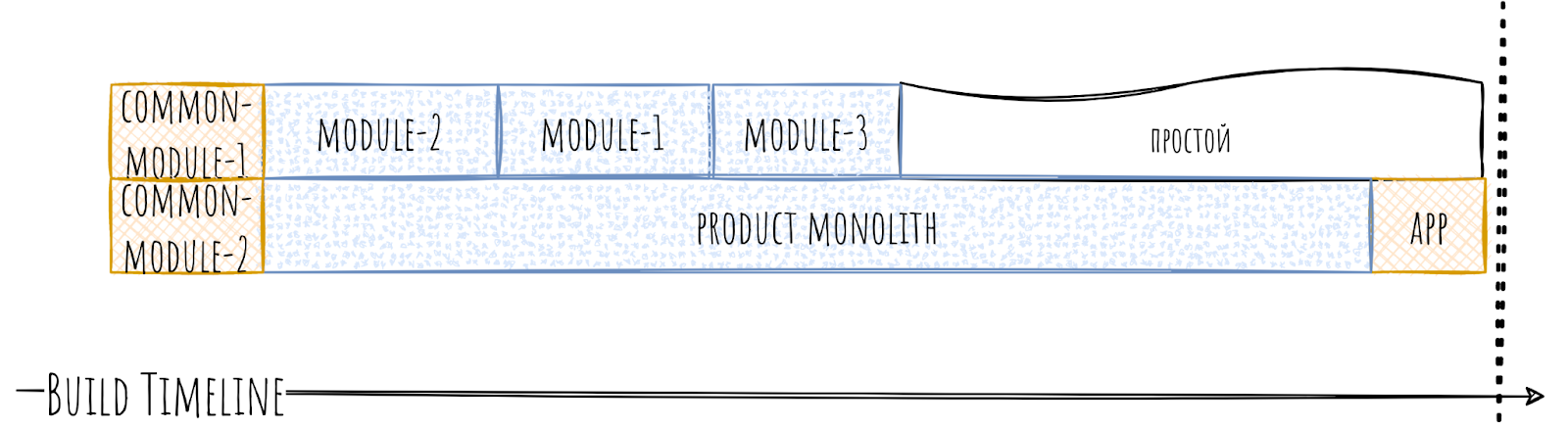
Timeline уже станет сильно лучше. В случае с продуктовым монолитом восстановить иерархию может быть сложнее, так как модуль в целом больше, то и причин иметь неправильную зависимость у него может быть больше.
Ну и теперь распил, тут опять же всё непросто и для начала разделим наш монолит на три части.
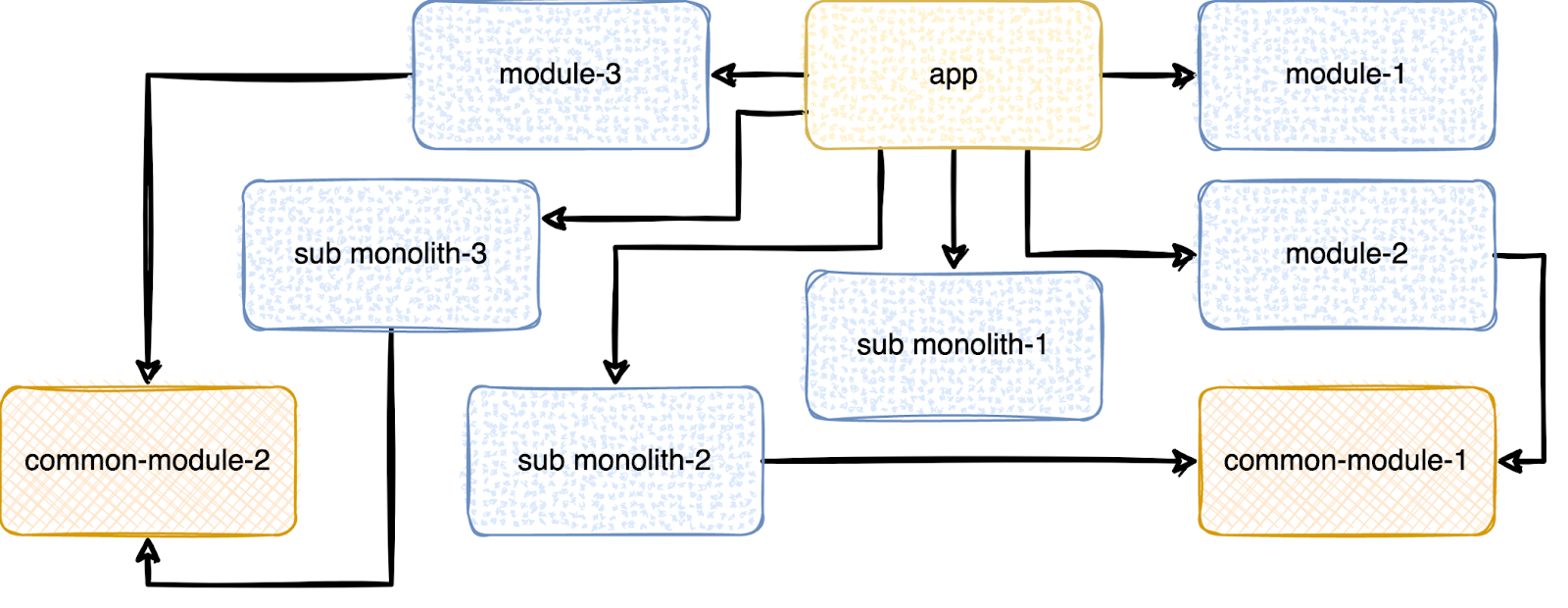
Попутно может выясниться, что не всем его частям нужны дополнительные зависимости к общим модулям, что ещё более положительно скажется на скорости сборки.
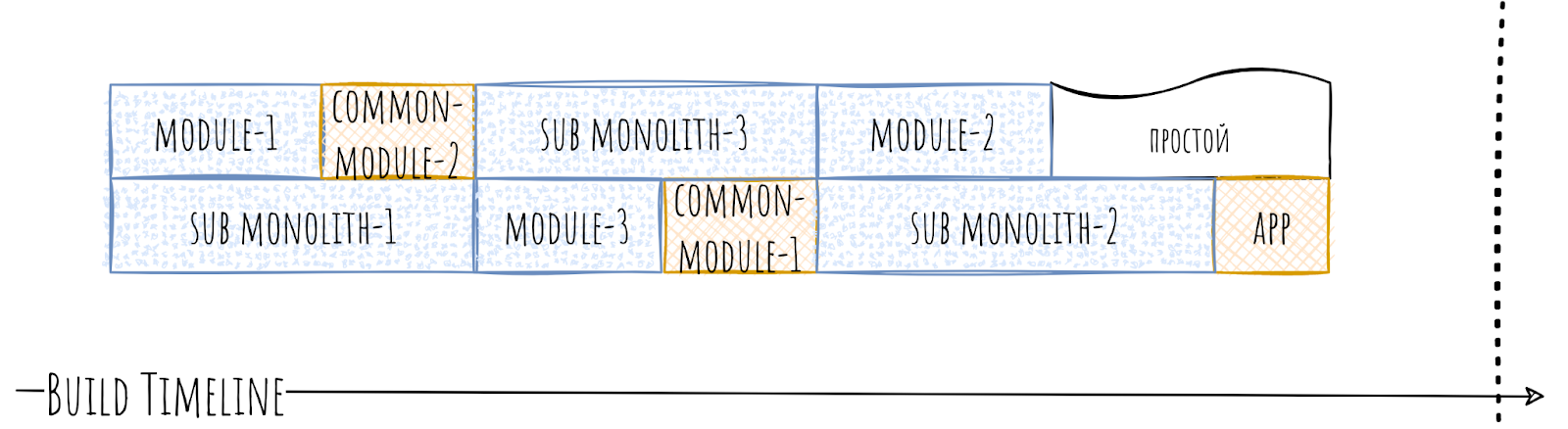
Разбираться с монолитами — это всегда тот ещё геморрой. Это долго и неприятно, но и результат обычно внушающий.
Итог
В случае с бутылочными горлышками, как и с сердечно-сосудистыми заболеваниями, — лучше заниматься профилактикой, а если уж подхватили, то лечить, пока проблема не разрослась, и дальше держать руку на пульсе.
Ну и самое главное, бутылочные горлышки — это дорого. Как с точки зрения времени разработчика, так и с точки зрения времени железа. Бороться с ними точно нужно. К сожалению, это не тот случай, где можно победить проблему в зародыше, так как сходу сложно определить, станет ли конкретный модуль проблемой. Но когда проблемный модуль уже проявил себя, то стоит избавиться от него как можно раньше. Так как потом исправлять его будет сильно дороже.
Другие статьи цикла:
Многомодульный BDSM: стоит ли внедрять Gradle модули и какие типы модулей бывают?
Многомодульный BDSM: как связать Gradle модули и как с ними общаться после этого?
