C ноября 2018 года компания Cisco начинает серию демонстраций нового гиперконвергентного решения Cisco HyperFlex в регионах России. Записаться на демонстрацию можно через форму обратной связи, перейдя по ссылке. Присоединяйтесь!
• Екатеринбург – до конца ноября 2018 года
• Томск, Новосибирск, Красноярск, Омск – 20 ноября 2018 года – 30 декабря 2018 года
• Владивосток, Южно-Сахалинск: 21 января 2019 года – февраль 2019 года.
Cisco HyperFlex – это новейшая гипергонвергентная система, которая решает проблему высокой сложности отказоустойчивых систем ЦОД-ов и корпоративных инфраструктур.

Традиционный подход к построению ЦОД основывается на разделении серверов, сети хранения данных и систем хранения данных. Такой подход делает инфраструктуру крайне сложной и дорогой.
Cisco HyperFlex по сути является «ЦОД-ом в коробке», которая объединяет вычислительную инфраструктуру, виртуальные машины и систему хранения данных в единую отказоустойчивую и высокопроизводительную инфраструктуру.

Также HyperFlex является крайне простым решением для внедрения и позволяет организовать высокодоступную ИТ-инфраструктуру с нуля в максимально сжатые сроки всего из 3-х серверов.
Еще в 2017-ом году независимая лаборатория Enterprise Strategy Group (ESG Lab) провела сравнительные тесты производительности Cisco HyperFlex и конкурентных решений.
Тесты проводились с помощью HCIBench, который является стандартным отраслевым инструментом для тестирования гиперконвергентных решений. В основе HCIBench лежит Oracle Vdbench, который эмулирует рабочую нагрузку на виртуальных машинах.
Тесты проводились для двух сценариев: гибридный и all-flash.
Для гибридного сценария использовался четырехузловой кластер HyperFlex HX220c с одним SSD-диском 480 Гб для кэша и шестью SAS дисками по 1,2 Тб на каждом узле кластера (итого 4xSSD+24xSAS HDD). Нагрузка генерировалась с 140 виртуальных машин (по 35 на ноду кластера), с 4-мя vCPU, 4 GB RAM и виртуальных HDD 20 GB (суммарно на кластер 560 vCPU, 560 GB RAM, 2800 GB HDD).
В ходе тестирования использовались различные профили нагрузки, но при этом всегда со 100% случайными данными, что наиболее характерно для сред с большим количеством виртуальных машин.
Наиболее интересным тестом было измерение задержек относительно значений IOPS при соотношении чтения и записи 70%/30% и блоке 4k, full random.
Результаты приведены на рисунке ниже:
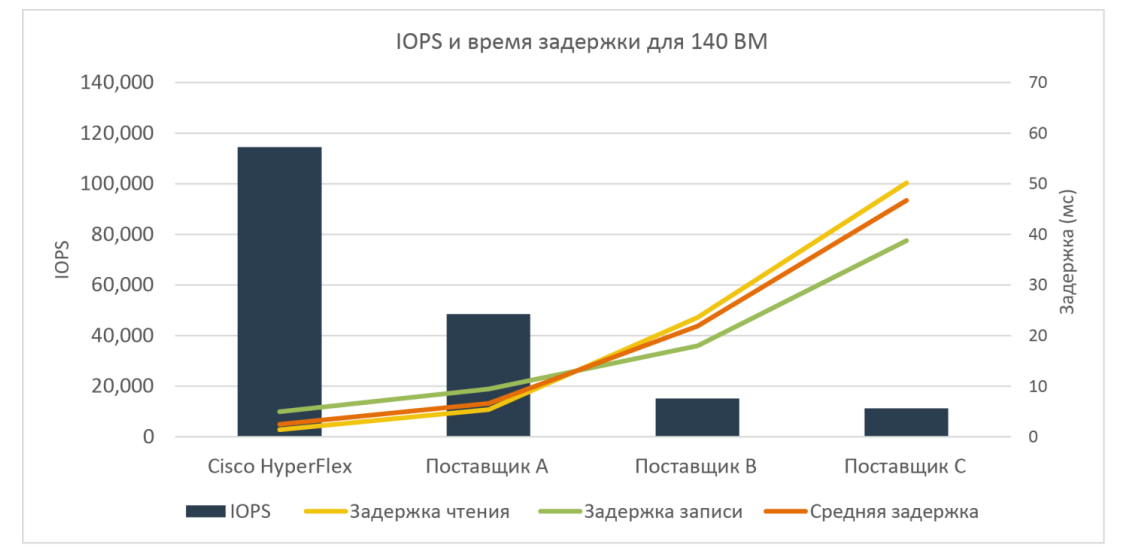
Как видно из результатов, гибридный вариант HyperFlex более чем в два раза превосходит ближайшего конкурента (~120 000 IOPS против ~60 000 IOPS).
Если обраться к тесту All-flash сценария, то в этом случае тестировалась та же нагрузка, но использовался четырехузловой кластер HyperFlex HX220c только из SSD-дисков (один SSD 400 GB для кэша и шесть SSD 960 GB для данных, суммарно 4xSSD 400GB+24xSSD 960 GB на весь кластер). У альтернативного поставщика использовалась аналогичная конфигурация.
При тех же профилях нагрузки (соотношение чтения и записи 70%/30% и блоке 4k, full random) результаты были следующие:
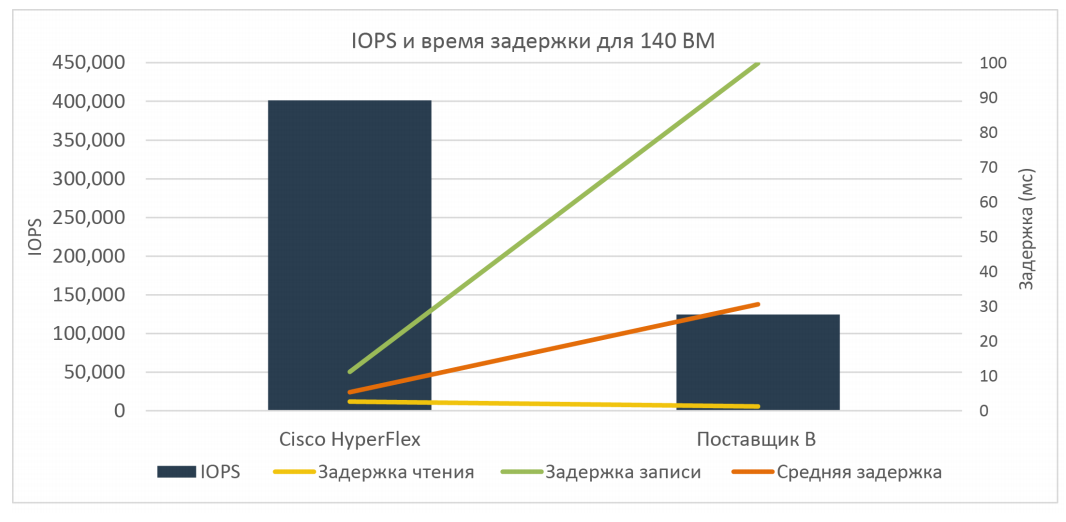
В итоге при All-flash сценарии решение HyperFlex уже в три раза превзошло ближайшего конкурента (400 000 IOPS против 150 000 IOPS).
Полная версия отчета о тестировании HyperFlex от ESG Lab приведена по ссылке ниже:
www.cisco.com/c/dam/global/ru_ru/products/hyperflex/pdf/esg_lab_validation_cisco_hyperflex.pdf
С момента независимого тестирования от ESG lab уже прошел год, и с тех пор в HyperFlex появились новые возможности – растянутый кластер, поддержка платформы разработки с Kubernetes, а недавно SAP сертифицировал HyperFlex для SAP HANA.
Таким образом, Cisco HyperFlex стал первым гиперконвергентным решением, сертифицированным по всем трем классам вычислительной нагрузки SAP: SAP Applications, SAP Data HUB и HANA.
Это еще раз подтверждает, что HyperFlex соединяет в себе высокую надежность, производительность и беспрецедентную простоту использования.
• Екатеринбург – до конца ноября 2018 года
• Томск, Новосибирск, Красноярск, Омск – 20 ноября 2018 года – 30 декабря 2018 года
• Владивосток, Южно-Сахалинск: 21 января 2019 года – февраль 2019 года.
Cisco HyperFlex – это новейшая гипергонвергентная система, которая решает проблему высокой сложности отказоустойчивых систем ЦОД-ов и корпоративных инфраструктур.

Традиционный подход к построению ЦОД основывается на разделении серверов, сети хранения данных и систем хранения данных. Такой подход делает инфраструктуру крайне сложной и дорогой.
Cisco HyperFlex по сути является «ЦОД-ом в коробке», которая объединяет вычислительную инфраструктуру, виртуальные машины и систему хранения данных в единую отказоустойчивую и высокопроизводительную инфраструктуру.
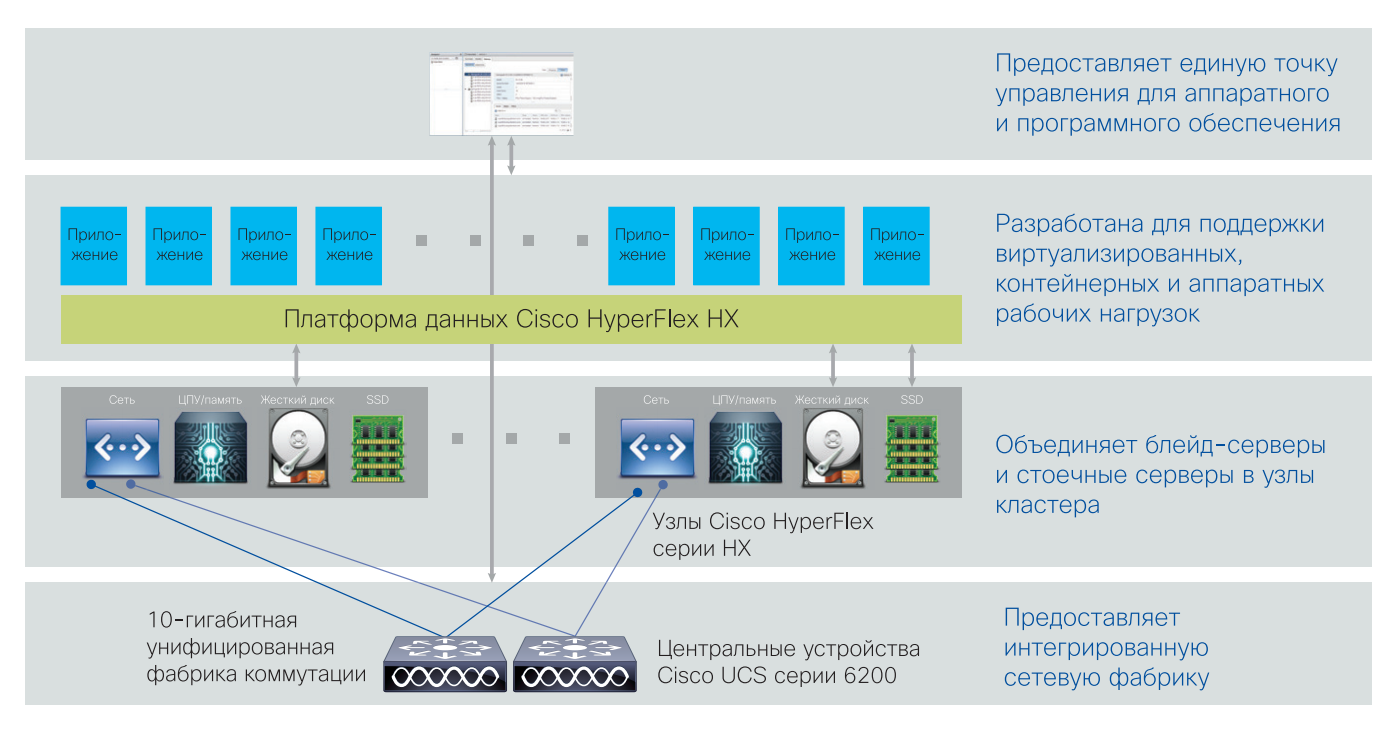
Также HyperFlex является крайне простым решением для внедрения и позволяет организовать высокодоступную ИТ-инфраструктуру с нуля в максимально сжатые сроки всего из 3-х серверов.
Еще в 2017-ом году независимая лаборатория Enterprise Strategy Group (ESG Lab) провела сравнительные тесты производительности Cisco HyperFlex и конкурентных решений.
Тесты проводились с помощью HCIBench, который является стандартным отраслевым инструментом для тестирования гиперконвергентных решений. В основе HCIBench лежит Oracle Vdbench, который эмулирует рабочую нагрузку на виртуальных машинах.
Тесты проводились для двух сценариев: гибридный и all-flash.
Для гибридного сценария использовался четырехузловой кластер HyperFlex HX220c с одним SSD-диском 480 Гб для кэша и шестью SAS дисками по 1,2 Тб на каждом узле кластера (итого 4xSSD+24xSAS HDD). Нагрузка генерировалась с 140 виртуальных машин (по 35 на ноду кластера), с 4-мя vCPU, 4 GB RAM и виртуальных HDD 20 GB (суммарно на кластер 560 vCPU, 560 GB RAM, 2800 GB HDD).
В ходе тестирования использовались различные профили нагрузки, но при этом всегда со 100% случайными данными, что наиболее характерно для сред с большим количеством виртуальных машин.
Наиболее интересным тестом было измерение задержек относительно значений IOPS при соотношении чтения и записи 70%/30% и блоке 4k, full random.
Результаты приведены на рисунке ниже:
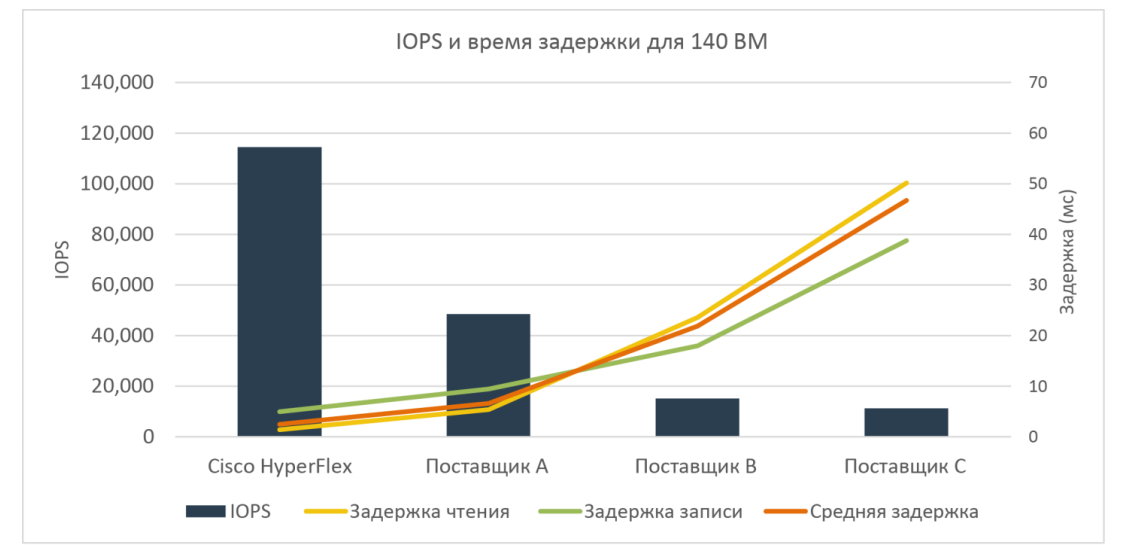
Как видно из результатов, гибридный вариант HyperFlex более чем в два раза превосходит ближайшего конкурента (~120 000 IOPS против ~60 000 IOPS).
Если обраться к тесту All-flash сценария, то в этом случае тестировалась та же нагрузка, но использовался четырехузловой кластер HyperFlex HX220c только из SSD-дисков (один SSD 400 GB для кэша и шесть SSD 960 GB для данных, суммарно 4xSSD 400GB+24xSSD 960 GB на весь кластер). У альтернативного поставщика использовалась аналогичная конфигурация.
При тех же профилях нагрузки (соотношение чтения и записи 70%/30% и блоке 4k, full random) результаты были следующие:
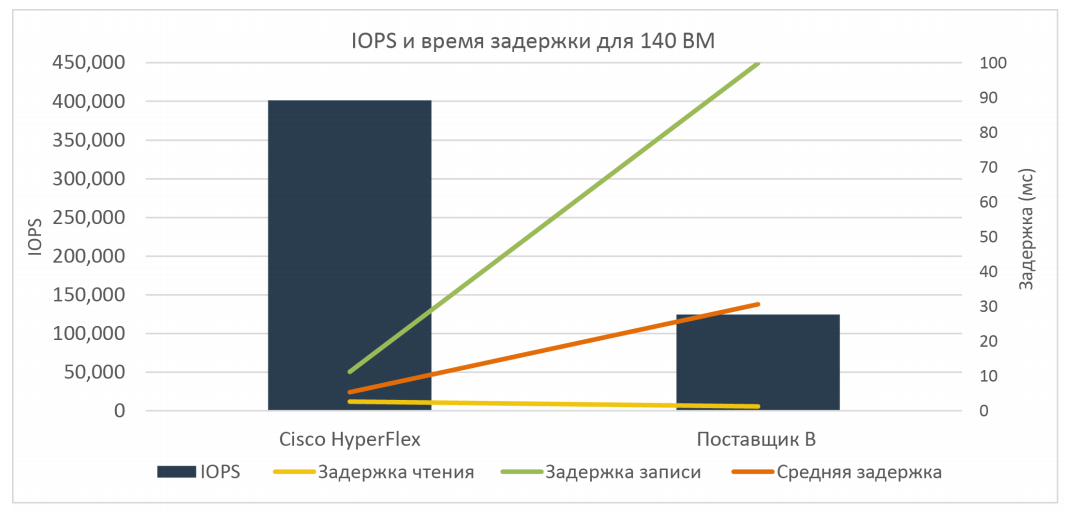
В итоге при All-flash сценарии решение HyperFlex уже в три раза превзошло ближайшего конкурента (400 000 IOPS против 150 000 IOPS).
Полная версия отчета о тестировании HyperFlex от ESG Lab приведена по ссылке ниже:
www.cisco.com/c/dam/global/ru_ru/products/hyperflex/pdf/esg_lab_validation_cisco_hyperflex.pdf
С момента независимого тестирования от ESG lab уже прошел год, и с тех пор в HyperFlex появились новые возможности – растянутый кластер, поддержка платформы разработки с Kubernetes, а недавно SAP сертифицировал HyperFlex для SAP HANA.
Таким образом, Cisco HyperFlex стал первым гиперконвергентным решением, сертифицированным по всем трем классам вычислительной нагрузки SAP: SAP Applications, SAP Data HUB и HANA.
Это еще раз подтверждает, что HyperFlex соединяет в себе высокую надежность, производительность и беспрецедентную простоту использования.
