Мы продолжаем цикл статей про Cisco Hyperflex. В этот раз мы познакомим вас с работой Cisco Hyperflex в условиях высоконагруженных СУБД Oracle и Microsoft SQL, а также сравним полученные показатели с конкурентными решениями.
Кроме того, мы продолжаем показывать возможности Hyperflex в регионах нашей страны и с радостью приглашаем вас посетить очередные демонстрации решения, которые на этот раз пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
Гиперконвергентные решения до недавнего времени являлись не очень подходящим решением для СУБД, тем более с высокой нагрузкой. Однако, благодаря использованию в качестве аппаратной платформы для Cisco Hyperflex фабрики UCS, за 10 лет доказавшей свою надежность и производительность, уже сегодня эта ситуация изменилась.
Хотите узнать больше? Тогда добро пожаловать под кат.
На текущий момент есть два подхода к организации гиперконвергентных решений. Первый подход основан на Software-defined решениях, которые поставляются как программное обеспечение, а оборудование заказчики подбирают самостоятельно. Второй подход основан на решениях «под ключ», то есть содержащих и ПО, и оборудование, и техническую поддержку. Мы в компании Cisco придерживаемся второго подхода и поставляем уже готовые решения нашим заказчикам, поскольку только таким образом можно гарантировать стабильное поведение системы, качественную техническую поддержку от одного производителя и высокую производительность.
Именно высокая производительность системы является одним ключевых факторов при принятии решения об использовании того или иного продукта в mission-critical задачах.
Сегодня организации, как правило, размещают критически важные задачи на классических решениях трехуровневой архитектуры (СХД > сеть хранения > серверы). При этом большинство организаций стремиться упростить и удешевить ИТ-инфраструктуру, не снизив при этом её стабильность и производительность. По этой причине, все чаще и чаще заказчики обращают внимание на гиперконвергентные решения.
В рамках этой статьи мы расскажем о последних тестах (февраль 2019 года), которые выполняла независимая лаборатория ESG (Enterprise Strategy Group). При тестировании эмулировалась работа высоконагруженных СУБД Oracle и MS SQL (OLTP тесты), что является одним из самых критичных компонентов ИТ-инфраструктуры в реальном продуктивном окружении.
Данная нагрузка выполнялась на трёх решениях: Cisco Hyperflex, а также двух software-defined решениях, которые устанавливались на те же серверы, что используются в Hyperflex, то есть на серверы Cisco UCS.
В системе вендора А не используется кэш, поскольку конфигурация с кэшем не поддерживается разработчиком решения. По этой причине были использованы диски для хранения большего объема.
OLTP тесты выполнялись с четырьмя виртуальными машинами и рабочим набором данных в 3,2 ТБ. Перед выполнением каждого теста каждая ВМ заполнялась записанными данными с помощью инструмента тестирования. Это гарантирует, что тест считывает «реальные» данные и записывает их в существующие блоки, а не просто возвращает нулевые блоки или нулевые значения непосредственно из памяти. Это происходит, когда данные не заполнены, поэтому было важно убедиться, что тест точно отражает, как данные считываются и записываются в среде приложения. Заполнение этого большого рабочего комплекта заняло продолжительное время, но на наш взгляд — это продуктивное вложение времени, поскольку позволяет получить более точные данные о производительности.
Тестирование проводилось с использованием инструмента HCI Bench (на основе Oracle Vdbench) и профилей ввода-вывода, предназначенных для эмуляции сложных критически важных рабочих нагрузок OLTP с использованием бэкэндов Oracle и SQL Server. Размеры блоков были назначены в соответствии с эмулируемыми приложениями со 100% случайным доступом к данным (full random).
Первым был выполнен OLTP тест, разработанный для эмуляции среды Oracle. Vdbench использовался для создания рабочей нагрузки с различными соотношениями чтения и записи. Тест проводился на четырех виртуальных машинах. В течение четырехчасового теста HyperFlex удалось показать более 420 000 IOPS с задержкой всего 4.4 милисекунды. Программные решения A и B смогли показать только 238 000 и 251 000 IOPS соответственно.


Уровень задержек в разных системах был примерно одинаков, за исключением задержки записи для вендора B, которое в среднем составляло 26,49 мс, при очень хороших показателях задержек на чтение в 2,9 мс. Сжатие и дедупликация были активны во всех системах.
Затем была рассмотрена рабочая нагрузка OLTP, предназначенная для эмуляции СУБД Microsoft SQL Server.
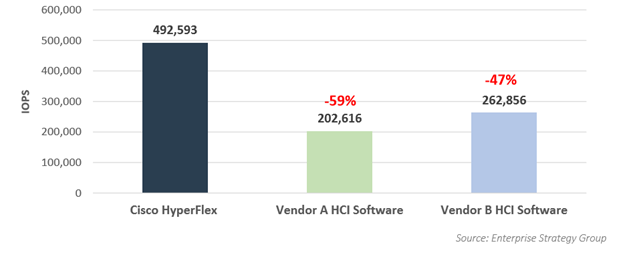
В результате данного теста кластер Cisco HyperFlex примерно в два раза превзошёл обоих конкурентов А и B. 490 000 IOPS у Cisco против 200 000 и 260 000 у производителей A и B.
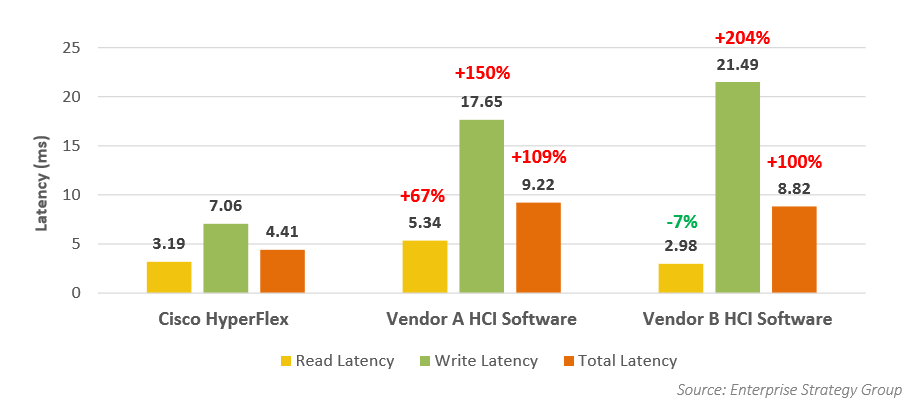
Результат по задержкам в Cisco HyperFlex не сильно отличался от теста Oracle, то есть он был на хорошем уровне 4,4 мс. При этом производители A и B показали результаты значительно хуже, чем в тесте для Oracle. Единственный положительный момент для конкурентного решения B – это стабильно низкий уровень задержек при чтении на уровне 2,9 мс, по всем остальным показателям Hyperflex опередил конкурентные решения в два раза и более.
Тестирование, проведенное независимой лабораторией ESG не только в очередной раз подтвердило достойный уровень производительности решения Cisco Hyperflex, но и доказало, что гиперконвергентные системы уже готовы для повсеместного использования в задачах уровня mission-critical.
Гиперконвергентные системы долгое время считались более подходящими для некритичных нагрузок. В 2016 году ESG провело опрос среди крупных компаний. Их спросили, почему они предпочли традиционную инфраструктуру, а не гиперконвергентную. 54% опрошенных ответили, что причина в производительности.
Перенесемся в 2018 год. Картина изменилась: повторный опрос ESG выявил уже только 24% опрошенных, которые до сих пор считают, что традиционные подходы все ещё лучше с точки зрения производительности.
Когда эволюция технологий меняет критерии выборы решения в отрасли, часто возникает несоответствие между тем, что хотят заказчики, и тем, что они могут получить. Производители, которые могут увидеть, чего не хватает и заполнить эту пустоту – получают преимущество. Cisco предлагает гиперконвергентное решение, которое обеспечивает простоту и экономичность, а также стабильно высокую производительность, которой не хватает и которая необходима заказчикам для критически важных рабочих нагрузок.
Компания Cisco поступательно двигается вперед в области гиперконвергентных систем, что подтверждается не только отличными характеристиками решения Cisco Hyperflex, но и присутствием на рынке. Поэтому осенью 2018 года компания Cisco заслуженно вошла в группу лидеров рынка HCI по версии Gartner.

Уже сейчас вы можете убедиться в том, что Hyperflex является превосходным решением для самых сложных и требовательных задач бизнеса, посетив наши демонстрации, которые пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
Кроме того, мы продолжаем показывать возможности Hyperflex в регионах нашей страны и с радостью приглашаем вас посетить очередные демонстрации решения, которые на этот раз пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
Гиперконвергентные решения до недавнего времени являлись не очень подходящим решением для СУБД, тем более с высокой нагрузкой. Однако, благодаря использованию в качестве аппаратной платформы для Cisco Hyperflex фабрики UCS, за 10 лет доказавшей свою надежность и производительность, уже сегодня эта ситуация изменилась.
Хотите узнать больше? Тогда добро пожаловать под кат.
Введение
На текущий момент есть два подхода к организации гиперконвергентных решений. Первый подход основан на Software-defined решениях, которые поставляются как программное обеспечение, а оборудование заказчики подбирают самостоятельно. Второй подход основан на решениях «под ключ», то есть содержащих и ПО, и оборудование, и техническую поддержку. Мы в компании Cisco придерживаемся второго подхода и поставляем уже готовые решения нашим заказчикам, поскольку только таким образом можно гарантировать стабильное поведение системы, качественную техническую поддержку от одного производителя и высокую производительность.
Именно высокая производительность системы является одним ключевых факторов при принятии решения об использовании того или иного продукта в mission-critical задачах.
Сегодня организации, как правило, размещают критически важные задачи на классических решениях трехуровневой архитектуры (СХД > сеть хранения > серверы). При этом большинство организаций стремиться упростить и удешевить ИТ-инфраструктуру, не снизив при этом её стабильность и производительность. По этой причине, все чаще и чаще заказчики обращают внимание на гиперконвергентные решения.
В рамках этой статьи мы расскажем о последних тестах (февраль 2019 года), которые выполняла независимая лаборатория ESG (Enterprise Strategy Group). При тестировании эмулировалась работа высоконагруженных СУБД Oracle и MS SQL (OLTP тесты), что является одним из самых критичных компонентов ИТ-инфраструктуры в реальном продуктивном окружении.
Данная нагрузка выполнялась на трёх решениях: Cisco Hyperflex, а также двух software-defined решениях, которые устанавливались на те же серверы, что используются в Hyperflex, то есть на серверы Cisco UCS.
Тестовые конфигурации

В системе вендора А не используется кэш, поскольку конфигурация с кэшем не поддерживается разработчиком решения. По этой причине были использованы диски для хранения большего объема.
Методология тестирования
OLTP тесты выполнялись с четырьмя виртуальными машинами и рабочим набором данных в 3,2 ТБ. Перед выполнением каждого теста каждая ВМ заполнялась записанными данными с помощью инструмента тестирования. Это гарантирует, что тест считывает «реальные» данные и записывает их в существующие блоки, а не просто возвращает нулевые блоки или нулевые значения непосредственно из памяти. Это происходит, когда данные не заполнены, поэтому было важно убедиться, что тест точно отражает, как данные считываются и записываются в среде приложения. Заполнение этого большого рабочего комплекта заняло продолжительное время, но на наш взгляд — это продуктивное вложение времени, поскольку позволяет получить более точные данные о производительности.
Тестирование проводилось с использованием инструмента HCI Bench (на основе Oracle Vdbench) и профилей ввода-вывода, предназначенных для эмуляции сложных критически важных рабочих нагрузок OLTP с использованием бэкэндов Oracle и SQL Server. Размеры блоков были назначены в соответствии с эмулируемыми приложениями со 100% случайным доступом к данным (full random).
Рабочая нагрузка Oracle Database
Первым был выполнен OLTP тест, разработанный для эмуляции среды Oracle. Vdbench использовался для создания рабочей нагрузки с различными соотношениями чтения и записи. Тест проводился на четырех виртуальных машинах. В течение четырехчасового теста HyperFlex удалось показать более 420 000 IOPS с задержкой всего 4.4 милисекунды. Программные решения A и B смогли показать только 238 000 и 251 000 IOPS соответственно.

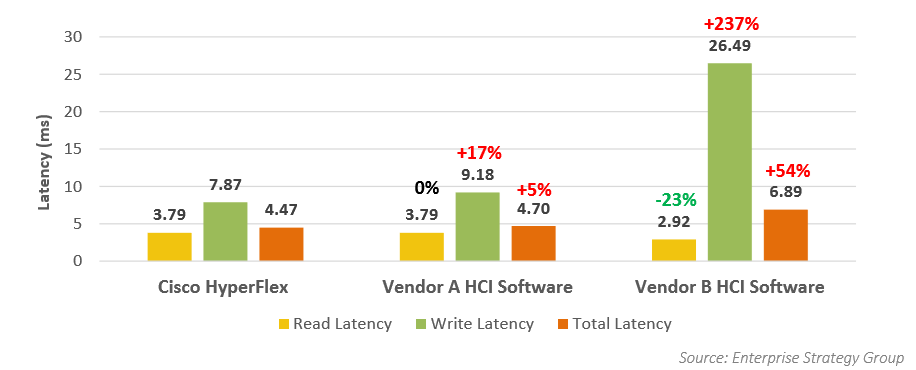
Уровень задержек в разных системах был примерно одинаков, за исключением задержки записи для вендора B, которое в среднем составляло 26,49 мс, при очень хороших показателях задержек на чтение в 2,9 мс. Сжатие и дедупликация были активны во всех системах.
Рабочая нагрузка Microsoft SQL Server
Затем была рассмотрена рабочая нагрузка OLTP, предназначенная для эмуляции СУБД Microsoft SQL Server.

В результате данного теста кластер Cisco HyperFlex примерно в два раза превзошёл обоих конкурентов А и B. 490 000 IOPS у Cisco против 200 000 и 260 000 у производителей A и B.

Результат по задержкам в Cisco HyperFlex не сильно отличался от теста Oracle, то есть он был на хорошем уровне 4,4 мс. При этом производители A и B показали результаты значительно хуже, чем в тесте для Oracle. Единственный положительный момент для конкурентного решения B – это стабильно низкий уровень задержек при чтении на уровне 2,9 мс, по всем остальным показателям Hyperflex опередил конкурентные решения в два раза и более.
Выводы
Тестирование, проведенное независимой лабораторией ESG не только в очередной раз подтвердило достойный уровень производительности решения Cisco Hyperflex, но и доказало, что гиперконвергентные системы уже готовы для повсеместного использования в задачах уровня mission-critical.
Гиперконвергентные системы долгое время считались более подходящими для некритичных нагрузок. В 2016 году ESG провело опрос среди крупных компаний. Их спросили, почему они предпочли традиционную инфраструктуру, а не гиперконвергентную. 54% опрошенных ответили, что причина в производительности.
Перенесемся в 2018 год. Картина изменилась: повторный опрос ESG выявил уже только 24% опрошенных, которые до сих пор считают, что традиционные подходы все ещё лучше с точки зрения производительности.
Когда эволюция технологий меняет критерии выборы решения в отрасли, часто возникает несоответствие между тем, что хотят заказчики, и тем, что они могут получить. Производители, которые могут увидеть, чего не хватает и заполнить эту пустоту – получают преимущество. Cisco предлагает гиперконвергентное решение, которое обеспечивает простоту и экономичность, а также стабильно высокую производительность, которой не хватает и которая необходима заказчикам для критически важных рабочих нагрузок.
Компания Cisco поступательно двигается вперед в области гиперконвергентных систем, что подтверждается не только отличными характеристиками решения Cisco Hyperflex, но и присутствием на рынке. Поэтому осенью 2018 года компания Cisco заслуженно вошла в группу лидеров рынка HCI по версии Gartner.

Уже сейчас вы можете убедиться в том, что Hyperflex является превосходным решением для самых сложных и требовательных задач бизнеса, посетив наши демонстрации, которые пройдут в городах Москва и Краснодар.
Москва – 28 мая. Запись по ссылке.
Краснодар – 5 июня. Запись по ссылке.
