
Как уже известно, около 70 % отказов в приложениях происходят из-за изменений: развёртывания нового кода, применённых миграции в базе данных, изменения конфигурационных файлов и т.д. Остальные 30 % сбоев происходят в ходе работы приложения без прямого вмешательства разработчиков и системных администраторов: из-за проблем с сетью или дисками, возросшей нагрузки от пользователей, аварии в дата-центре. На первую группу мы можем повлиять с помощью управления изменениями и стратегии проведения этих изменений, а как повысить устойчивость к проблемам из второй группы, мы поговорим в этой статье.
Healthchecks
Экземпляры сервисов непрерывно запускаются, перезапускаются и останавливаются из-за отказов, развёртывания или автомасштабирования, что приводит к временной или постоянной недоступности экземпляров. Чтобы избежать проблем с обработкой запросов, балансировщик нагрузки должен исключать из маршрутизации нерабочие экземпляры сервисов.
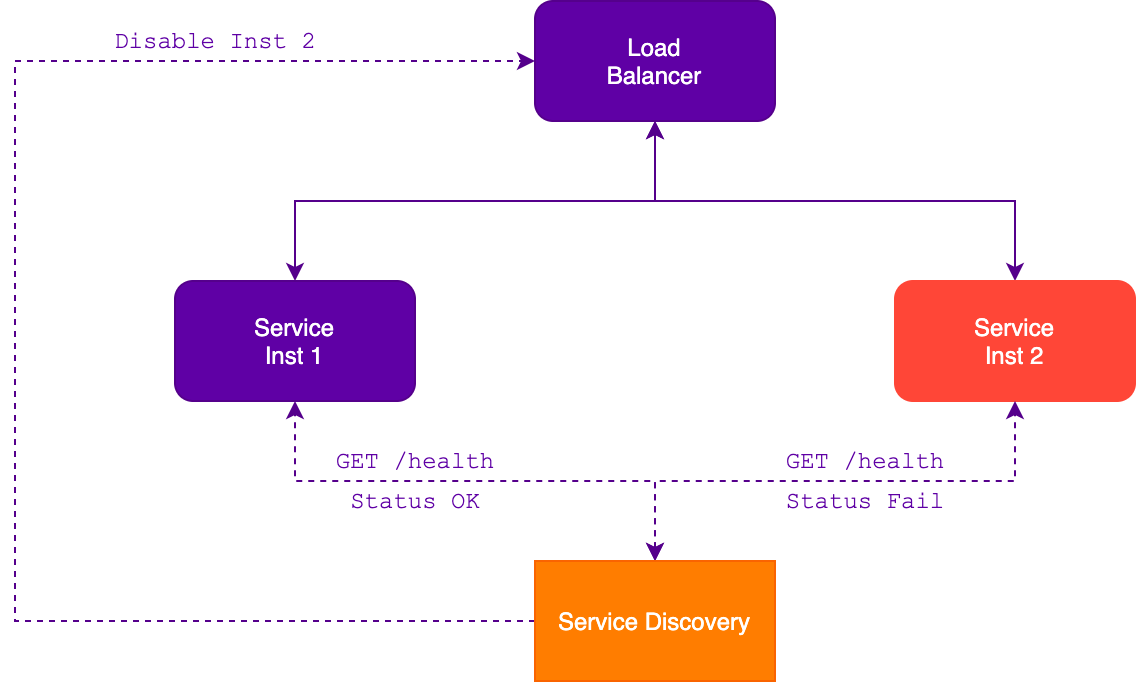
Экземпляр сервиса может сам отправлять информацию о своём состоянии с определённой периодичностью, либо предоставлять API для проверки внешним сервисом. Современные средства обнаружения непрерывно собирают данные о состоянии экземпляров и динамически перенастраивают балансировщики для направления трафика на здоровые сервисы.
Self-healing
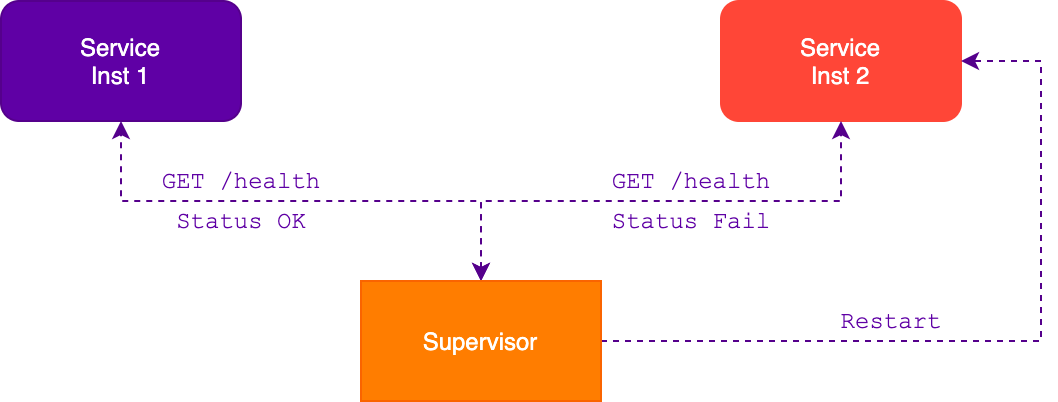
Механизм самовосстановления может восстановить работу приложения без сторонней помощи. В большинстве случаев это реализуют с помощью сторонней службы, которая наблюдает за экземплярами, собирает данные о состоянии и перезапускает в случае, если какой-то экземпляр слишком долго находится в сломанном состоянии. Например, supervisord или systemd.
В большинстве случаев такая реализация будет очень полезной, но может привести к непрерывному перезапуску приложения, когда из-за перегрузки или таймаута базы данных приложение не может ответить наблюдающей службе, что оно работает. В таком случае потребуется реализовать дополнительную логику обработки подобных пограничных ситуаций, чтобы служба наблюдения узнавала о состоянии приложения и не перезапускала его.
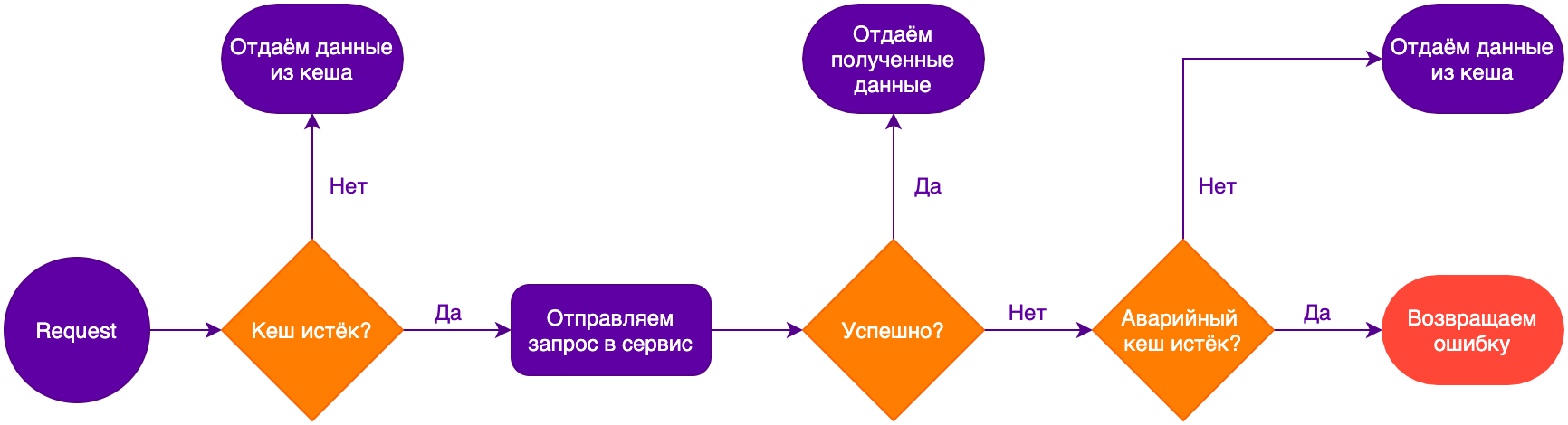
Failover caching
Аварийное кеширование позволит сервисам продолжать работу в случае временной недоступности. Такой кеш имеет два времени жизни: более короткое для обычного кеширования и более долгое — для аварийного. В нормальном режиме работы, когда основной кеш истёк, запрос будет обработан сервисом. В случае недоступности сервиса данные берутся из аварийного кеша. А если аварийный кеш истёк, то фиксируется отказ.
Однако этот механизм можно использовать только в том случае, когда возвращать устаревшие данные лучше, чем не возвращать ничего.
Retry
В тех случаях, когда невозможно использовать кеширование, либо когда данные необходимо изменить, подходящим вариантом может быть повтор запроса. За время ожидания перед повторным запросом сервис может перезапуститься, или балансировщик может переключить маршруты на работающие экземпляры. При реализации логики повторного запроса следует учесть некоторые моменты:
Большое количество повторных вызовов может усугубить аварийную ситуацию или блокировать восстановление работы сервиса.
В системах микросервисов повторные вызовы могут каскадом порождать новые запросы.
Если вызывающая сторона не знает, была ли выполнена операция прежде, чем запрос завершился с ошибкой, то повторный запрос может привести к множественному выполнению операции.
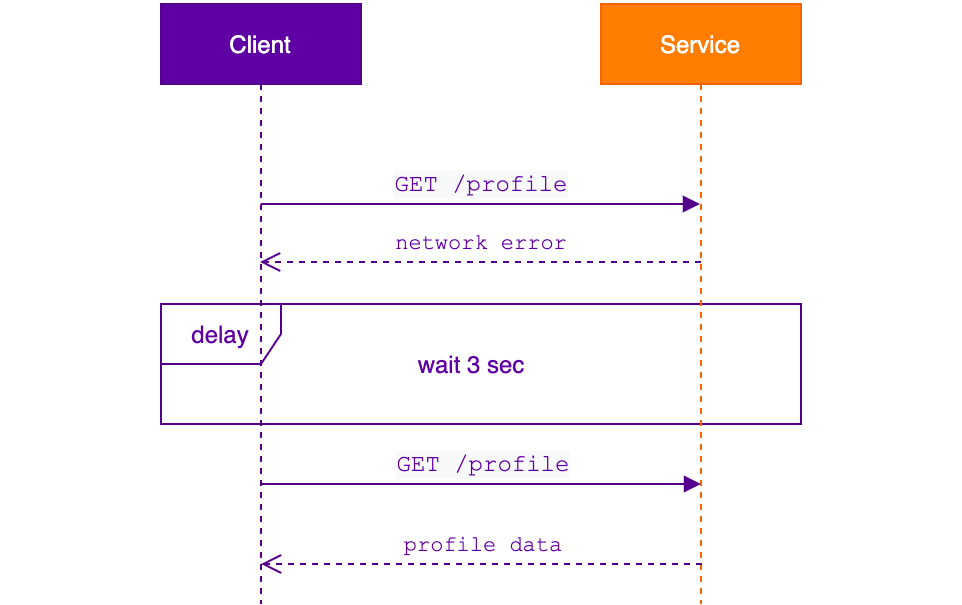
Чтобы минимизировать или избежать негативных последствий повторного вызова, следует жёстко ограничить количество попыток повтора и увеличивать время ожидания перед следующей попыткой, например, по алгоритму экспоненциальной выдержки. Также вызываемый сервис должен уметь обрабатывать запросы идемпотентно.
Мы используем повторные вызовы в случае сетевых ошибок: таймаут TCP-соединения и разрешения имени в DNS. При этом используем не только для HTTP-запросов, но и для критичных запросов к базе данных.
Rate limiting
Ограничение частоты запросов помогает предотвратить перегрузки сервиса и его отказ, пока сервис не будет масштабирован под нагрузку. Если клиенты сервиса могут без проблем для себя уменьшить частоту запросов, то можно использовать этот приём. Если же это невозможно, например, в случае событий реального времени, то придётся искать другой способ.
Есть две стратегии реализации ограничения:
по количеству запросов в минуту;
по количеству одновременно выполняющихся запросов.

Ограничение по числу запросов в единицу времени.
Первый вариант защищает сервис от флуда, вызванного ошибкой в скрипте, внешними ботами или настойчивыми пользователями. Второй вариант позволяет держать под контролем нагрузку на ресурсоёмкие методы API и не позволять потреблять все ресурсы сервиса одним пользователем.
Ограничение можно настроить не только по IP-адресу. У себя мы используем лимитер с настраиваемым ключом для защиты от дублирования заявок с сайтов. Он проверяет не только адрес, но и значения некоторых полей форм, а также имеет гибкую настройку количества запросов по минутам, часам и дням.
Load shedding
Лимитеры частоты запросов принимают решение в зависимости от того, какой конкретно клиент выполняет запрос. Это хорошо подходит для обычного режима работы, но в случае инцидента может быть необходимо сбросить часть неприоритетных запросов, чтобы критически важные продолжили выполняться. Такой механизм должен работать на основе информации о состоянии всей системы, а не участия отдельных клиентов. Возможны два варианта:
выделенный запас мощности;
анализ потребления.
В первом варианте мы выделяем долю общей пропускной способности сервиса под критический трафик. Например, сервис способен обрабатывать 50 тысяч запросов в секунду, устанавливаем резерв в 20 % (10 тыс.). В таком случае остальной трафик не должен превышать 80 % (40 тыс.). Шеддер отклонит все некритичные запросы сверх этого потока. Жёсткий лимит позволит гарантировать, что весь критический трафик всегда будет обработан.
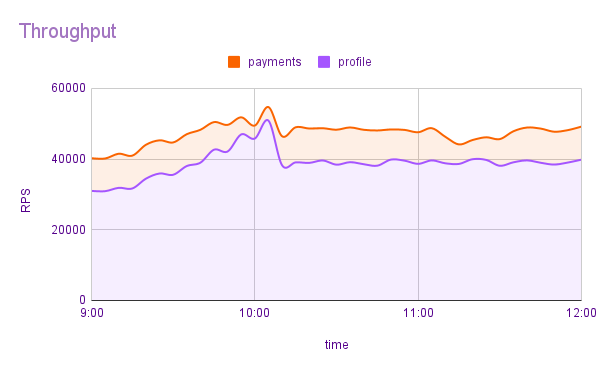
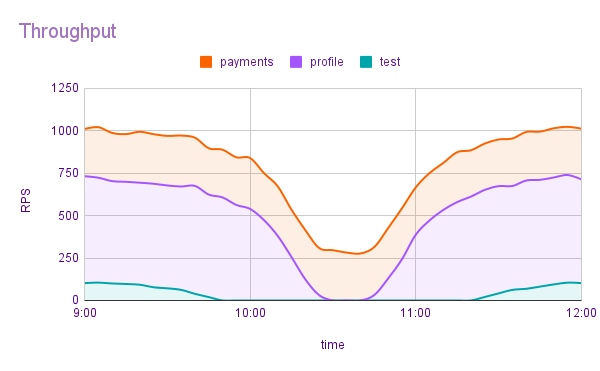
Во втором варианте мы анализируем загруженность сервиса, и в случае замедления его работы начинаем плавно подрезать наименее критичные запросы. Если ситуация пришла в норму, то начинаем плавно возвращать трафик. Если не помогло, то продолжаем урезать трафик с приоритетом выше, вплоть до того, что остаются только критически важные запросы. Такой подход позволяет ограничить влияние уже происходящего инцидента и контролировать ущерб.
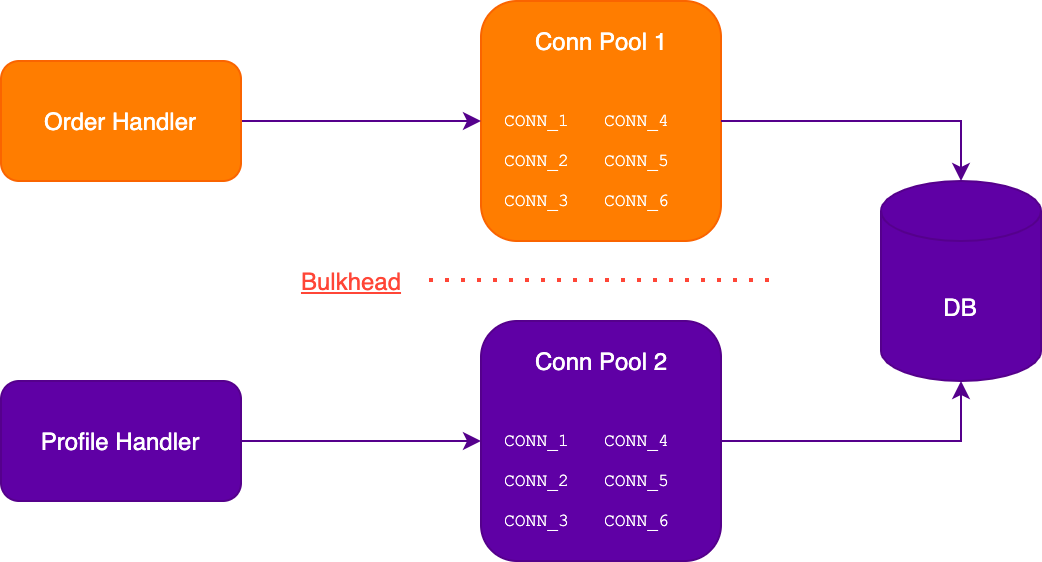
Bulkheads
Этот паттерн получил название от корабельных переборок. Они делят внутреннее пространство корабля на отсеки, позволяя изолировать пробоину в корпусе. При этом затапливается только один или несколько отсеков, остальные остаются сухими и поддерживают корабль на плаву. В контексте программного обеспечения паттерн предполагает разделение ресурсов сервиса на несколько независимых блоков, например, создание двух пулов подключений к базе данных: один для критических задач, второй для остальных. Таким образом один полностью занятый пул не приведёт к полному отказу в обслуживании клиентов и сервис сохранит ограниченную работоспособность.
Circuit breaker
Чтобы ограничить время выполнения операции или запроса, мы можем использовать таймауты. Они позволяют предотвратить зависание операций, однако подобрать подходящие значения времени в сложных, динамических, распределенных системах почти невозможно. Поэтому вместо того, чтобы полагаться на таймауты, следует использовать паттерн предохранитель.
Предохранитель защищает ресурсы сервиса (соединения, дескрипторы), не позволяя их использовать в случае отказа вызываемого сервиса. Вместе с тем, вызываемый сервис быстрее восстановится после отказа, так как на него не поступают запросы от других сервисов.
Предохранитель открывается, когда зафиксирует некоторое количество ошибок за короткий промежуток времени. Все последующие запросы через него будут возвращать ошибку сразу, без отправки во внешний сервис. Предохранитель сохраняет такое состояние в течение заданного промежутка времени, после чего закрывается и снова пропускает все запросы во внешний сервис.
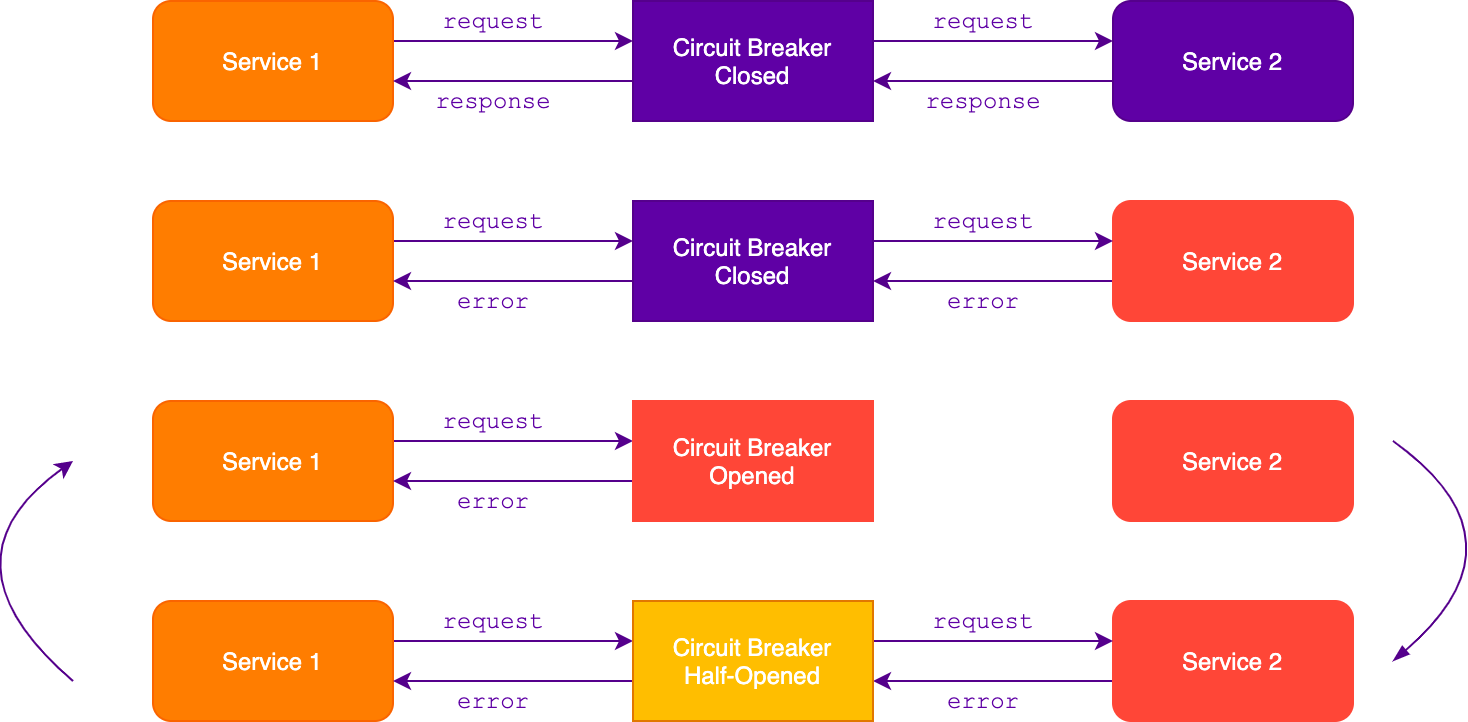
Возможен вариант с полуоткрытым режимом. В этом случае спустя некоторое время после открытия предохранитель пропустит один запрос для проверки сервиса. Если запрос отработал, то предохранитель закрывается, если же завершился с ошибкой — возвращается в открытое состояние.
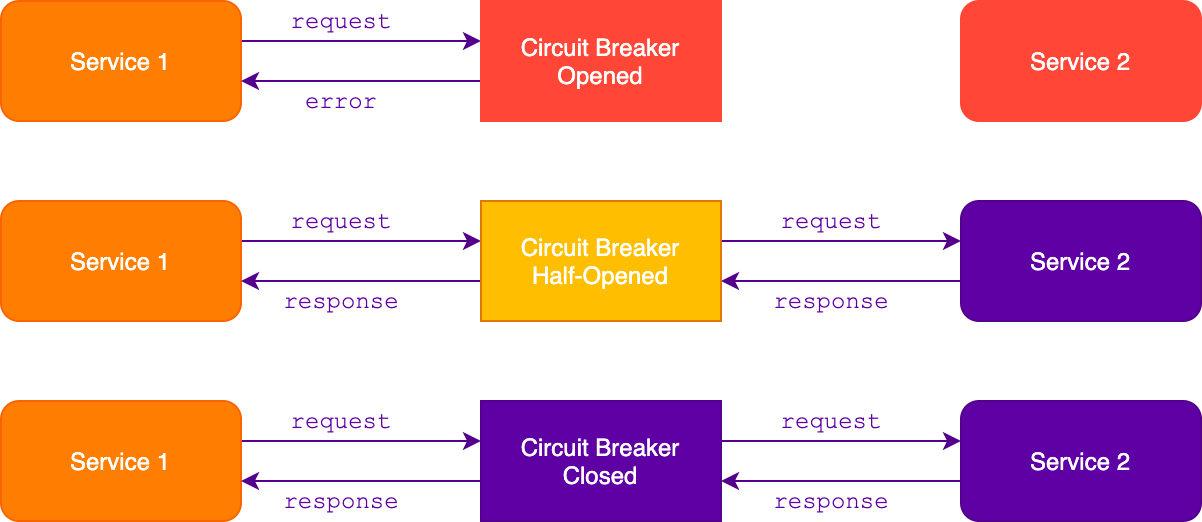
С настройкой параметров предохранителя следует быть аккуратным, иначе он может оказаться слишком чувствительным и будет срабатывать даже при кратковременных проблемах с сетью. В итоге открытый предохранитель может отклонить с ошибкой больше запросов, чем было бы без него.
