
Контент-планы для блогов [часто] делают как попало. То авторы заносят темы и правят бал вместо редакторов, то редактора что-то ситуативно выискивают и «латают дыры». Да, еще есть блоги имени себя любимых — с новостями и пресс-релизами...
В результате блог просто висит на сайте — он как бы есть, но толку от него ноль (верней даже минус, потому что за все это дело все-таки нужно платить).
Если вы не хотите, чтобы блог стал чемоданом без ручки, подойдите к планированию контента системно. Разберем подход, основанный на подборе популярной семантики в нише. На примере блога сервиса для управления задачами покажем, как составить контент-план от А до Я.
План действий
Собираем информационную семантику
Составляем базовый список запросов
Генерируем запросы при помощи комбинатора
Углубляем семантику средне- и низкочастотниками
Расширяем семантику словами из правой колонки Вордстат
Расширяем фразами-ассоциациями
Расширяем семантику поисковыми подсказками
Исследуем площадки вопросов и ответов
Чистим, снимаем частотность и кластеризуем
Пример контент-плана для сервиса планирования задач
Что делать дальше
Обозначим проблемы
Программы и сервисы, которые помогают организовать время, спланировать рабочие задачи, распределить домашние дела, сейчас в тренде. В связи с подъемом интереса у пользователей владельцам бизнеса и маркетологам в этой нише хочется отстроиться от конкурентов, рассказать о своих выгодах, убедить в экспертности, вызвать доверие. В этом как раз и поможет блог.
В результате аудита выявили ряд проблем, которые предстояло решить:
- Блог существует давно, написан приличный объем статей, но ведется «для галочки». Контент-плана и расписания публикаций нет и никогда не было.
- Долгое время информационный раздел на сайте был отдан на откуп подрядчикам по SEO, которые часто менялись. В результате каждый собирал ключевые фразы по собственному разумению и заказывал под них на бирже невнятные «SEO-тексты».
- Сейчас блог поручен штатному сотруднику, но понимания, как и зачем его вести, нет, поэтому темы каждый раз приходится мучительно формулировать.
- Поведенческие показатели статей неутешительные: высокий процент отказов (у некоторых статей – до 80%), небольшое время просмотра.
- В Яндекс.Метрике не подключена контентная аналитика, поэтому детально проанализировать показатели по каждой статье проблематично.
- Низкая посещаемость блога по сравнению с другими разделами.
- По ссылкам на скачивание демо-версии программы, размещенным в конце статей, критически мало кликов.
План действий
Есть разные источники тем для публикаций в корпоративном блоге:
- Информация из отдела продаж.
- Частые вопросы в онлайн-консультанте.
- Обсуждения и комментарии в корпоративных соцсетях.
- Сайты и соцсети конкурентов, особенно разделы FAQ и блог.
- Публикации конкурентов на внешних площадках.
Эти источники вполне можно использовать для формирования контент-плана. Но наша задача – не просто писать статьи на интересные целевой аудитории темы, но и привлечь в блог условно бесплатный трафик из поисковых систем, а затем сконвертировать его в загрузки программы.
В этом случае нужно собрать семантику, сгруппировать ключевые слова и оптимизировать каждую статью под группу информационных запросов. В то же время чисто «сеошные» статьи ни о чем, написанные ради употребления ключей, не сработают. Низкокачественные материалы не способны формировать доверие к бренду и наращивать лояльную аудиторию.
На основе поставленных задач разработан такой план действий:
- Собрать список базовых ключевых слов, которые описывают инструмент.
- Распарсить базовый список на средне- и низкочастотные запросы.
- Выявить пул информационных запросов и/или запросов с неясным интентом.
- Расширить семантику словами из правой колонки Вордстат.
- Расширить список запросов фразами-ассоциациями и поисковыми подсказками.
- Собрать вопросы по тематике сайта на Q&A ресурсах.
- Сгруппировать запросы в тематические кластеры.
- Составить контент-план на основе собранной семантики.
- Составить план публикаций в месяц и придерживаться его.
Широкий пул информационных запросов станет основой контент-плана и надолго обеспечит нас актуальными для целевой аудитории темами.
Собираем информационную семантику
Пройдемся по этапам сбора семантики для составления контент-плана блога и расскажем об инструментах автоматизации, которые облегчили процесс.
Составляем базовый список запросов
На первом этапе составили базовый список из 39 ключевых фраз, описывающих функционал программы, также включили в него общие тематические ключи – «список дел», «организация удаленной работы», «планирование рабочего дня», «планирование рабочего времени», «постановка задач удаленным сотрудникам», «расписание дел».
Первоначальный список фраз для небольшого сайта лучше собирать вручную с помощью Яндекс.Вордстата. Так больше шансов уже на первом этапе отсеять мусорные запросы, которые приведут нецелевой трафик. В нашем случае таким оказался, например, запрос «планировщик проектов» – видим, что вложенные запросы касаются в основном дизайн-проектов и проектов домов:
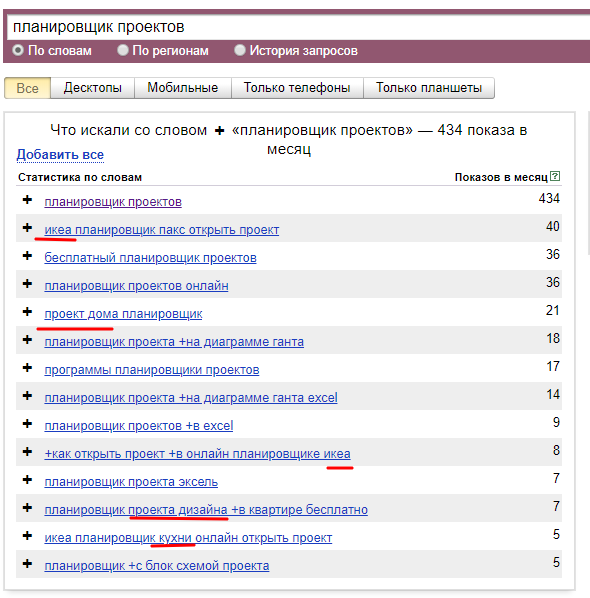
Вот такой список базовых фраз получился у нас (с разбавленной частотностью по региону «Россия»):
| бизнес планировщик | 143 |
| календарь задач | 3240 |
| контроль сотрудников программа | 633 |
| органайзер задач | 159 |
| организация удаленной работы | 6255 |
| планирование рабочего времени | 3210 |
| планирование рабочего дня | 1816 |
| планировщик времени | 580 |
| планировщик дел | 1681 |
| планировщик дня | 614 |
| планировщик задач | 9300 |
| постановка задач удаленным сотрудникам | 28 |
| почасовое расписание +на неделю | 15 |
| приложение постановка задач | 241 |
| приложения +для организации работы | 646 |
| приложения +для планирования | 3649 |
| программа +для планирования времени | 203 |
| программа +для планирования дел | 320 |
| программа +для планирования задач | 353 |
| программа +для планирования целей | 280 |
| программа +для постановки задач | 389 |
| программа контроля задач | 982 |
| программа органайзер | 1477 |
| программа распределения задач | 237 |
| программа управления задачами | 2183 |
| программы +для бизнес планирования | 125 |
| программы +для планирования +на компьютер | 104 |
| программы +для удаленной работы | 4539 |
| программы +для управления проектами | 781 |
| программы +для фриланса | 69 |
| программы +по планированию времени | 128 |
| программы управления делами | 378 |
| расписание дел | 4468 |
| сервис +для постановки задач | 87 |
| сервис контроля задач | 93 |
| сервис планирования времени | 22 |
| сервисы +для командной работы | 49 |
| список дел | 70844 |
| список задач +на день | 408 |
Генерируем запросы при помощи комбинатора
Нас не устраивает небольшое количество фраз с информационным потенциалом, которое удалось найти при первоначальном сборе семантики. Попробуем сгенерировать запросы путем перемножения в бесплатном комбинаторе слов от Click.ru. Загружаем списки слов в колонки и запускаем процесс перемножения. Выбираем очевидные сочетания с высокочастотными целевыми запросами:
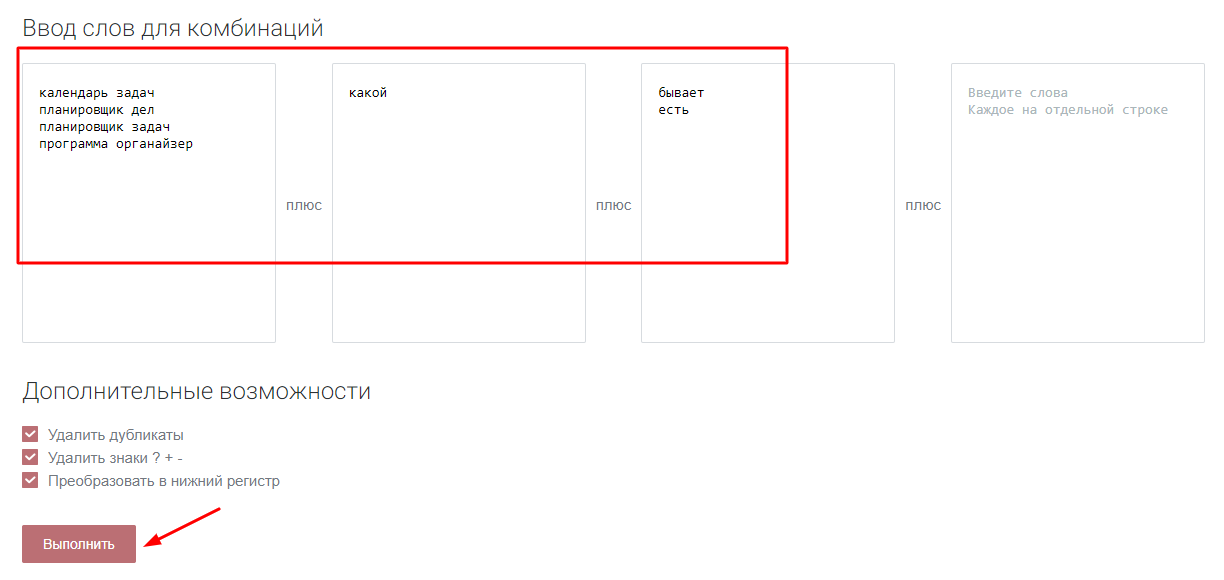
В инструменте есть возможность сразу же проверить частотность, чтобы не добавлять не актуальные фразы:

Запросы с ненулевой частотностью добавляем в базовый список, их оказалось немного:
| планировщик дел какой есть |
| программа органайзер что это |
| календарь задач как сделать |
| планировщик задач как создать |
| планировщик задач как настроить |
Углубляем семантику средне- и низкочастотниками
Дальше нужно собрать средне- и низкочастотные хвосты у этих опорных фраз. В них надеемся найти в том числе информационные запросы.
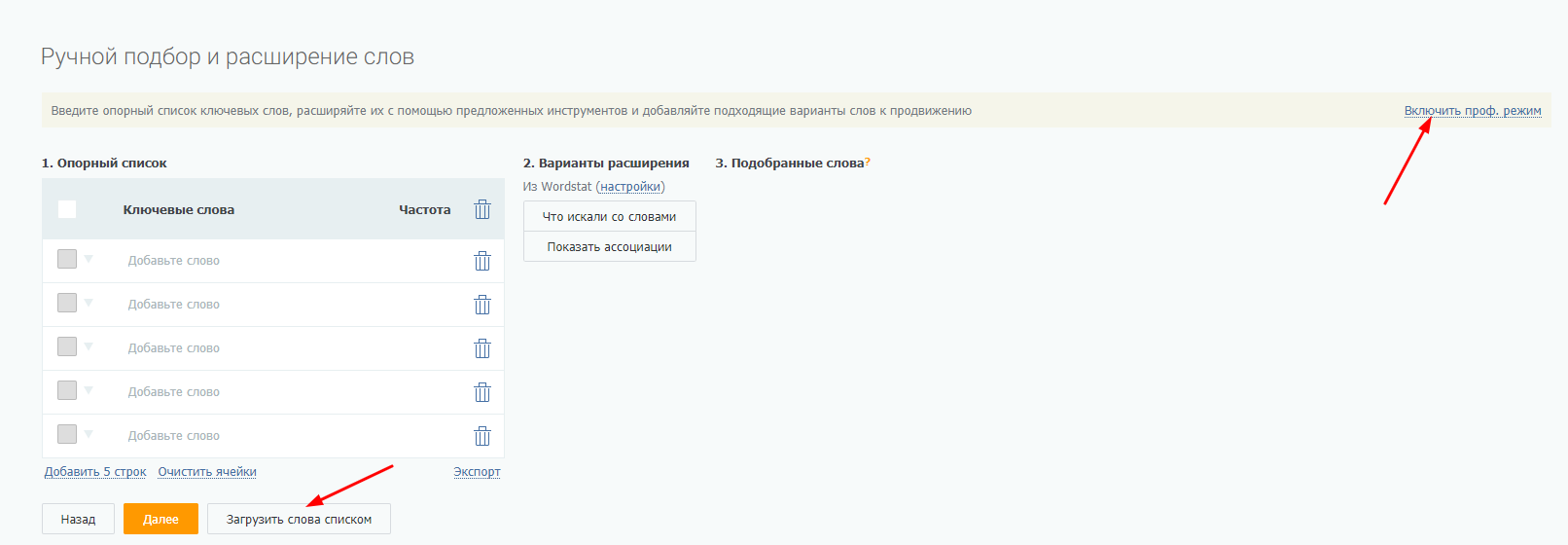
Распарсить базовые фразы можно при помощи бесплатного инструмента от PromoPult. Зарегистрируйтесь, добавьте проект и выберите «Поисковое продвижение SEO». Дальше система начнет автоматический подбор слов. Но у нас опорный список уже есть. Поэтому сразу листаем ниже и видим раздел «Ручной подбор и расширение слов». Включаем профессиональный режим и добавляем список базисов:
Далее углубляем семантику при помощи левой колонки Вордстат (функция «Что искали со словом»):
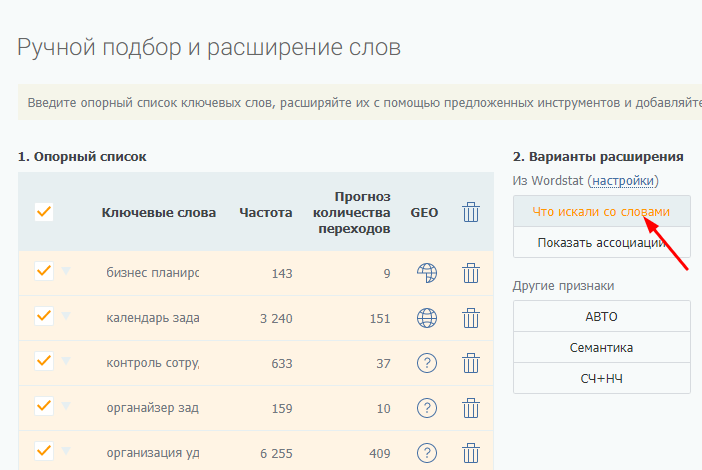
Настройки парсинга можно менять – уменьшать или увеличивать количество страниц левой и правой колонок, добавлять минус-слова:
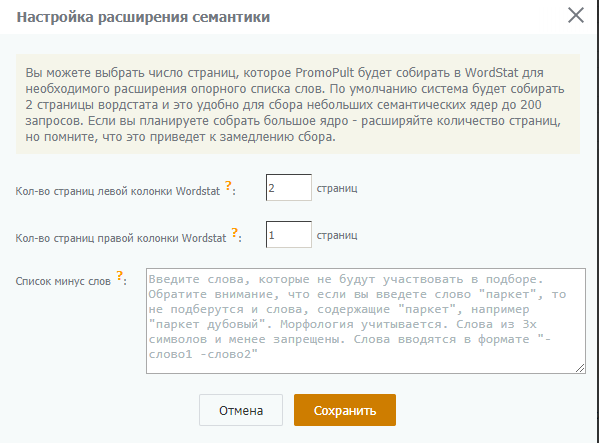
На первом этапе из базовых 44-х мы получили чуть больше 400 слов, прямо в интерфейсе удалили нецелевые (они автоматически добавляются в список минус-фраз для последующего парсинга) и провели углубление еще раз.
Из расширенного списка фраз убираем коммерческие («скачать», «бесплатно» и т.д.) и оставляем запросы, имеющие информационный потенциал или неясный интент.
Расширяем семантику словами из правой колонки Вордстат
Следующий этап – расширение списка словами из правой колонки Вордстат. Выполняем его при помощи опции «показать ассоциации» все того же ручного подборщика PromoPult:
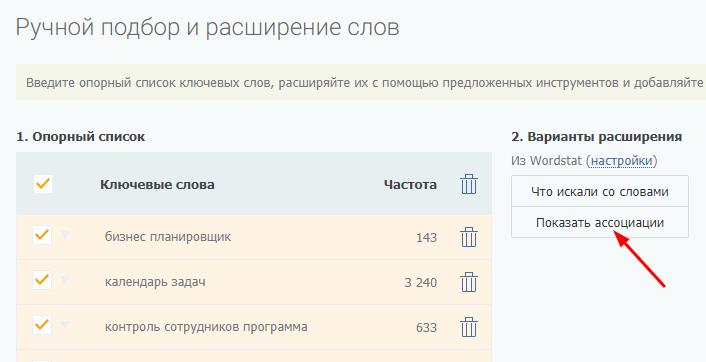
Чистим список. Подходящие по тематике фразы добавляем в опорный список слов:
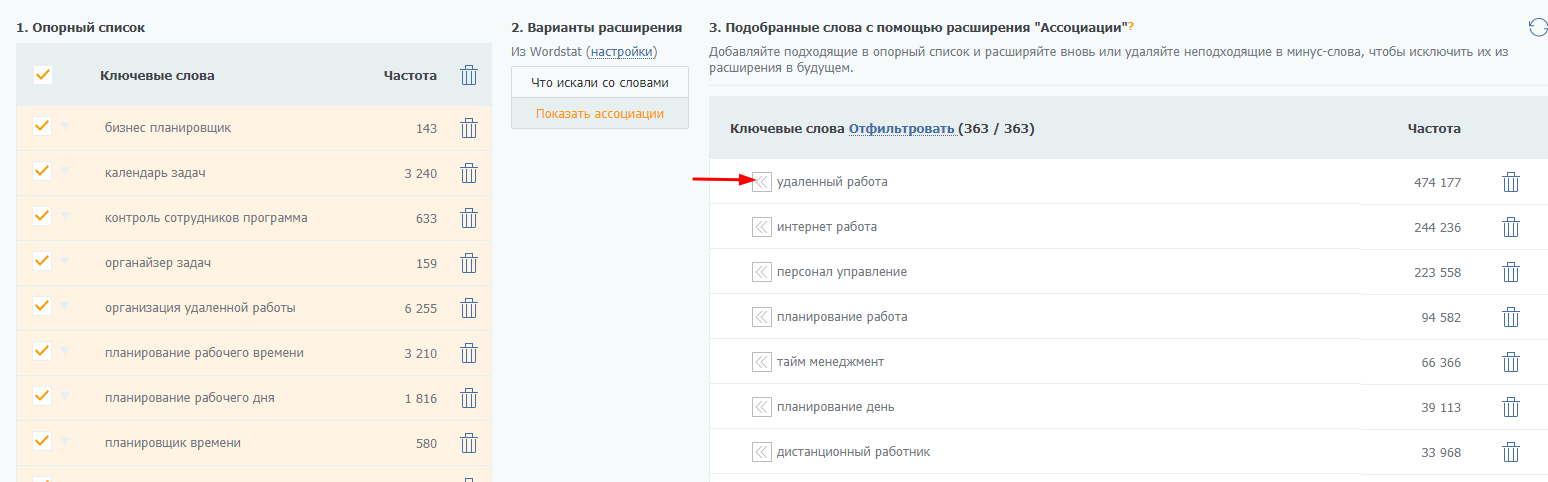
Нам удалось расширить семантику чуть более чем на 50 целевых запросов.
Расширяем фразами-ассоциациями
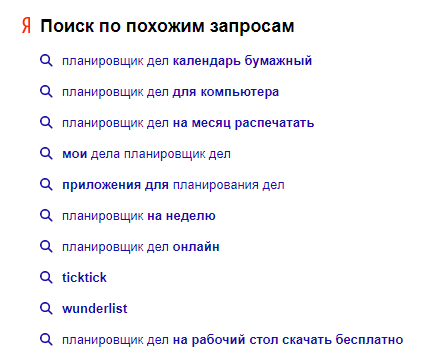
Дополнительный источник информационной семантики – блоки «Вместе с запросом ищут» в Яндексе и Google. Вот пример такого списка запросов в Яндексе:
Собирать руками релевантные фразы-ассоциации из двух поисковых систем по всему опорному списку ключей очень долго. Воспользуемся автоматизированным инструментом от Click.ru. Загружаем список опорных фраз, которые собрали на первом этапе:
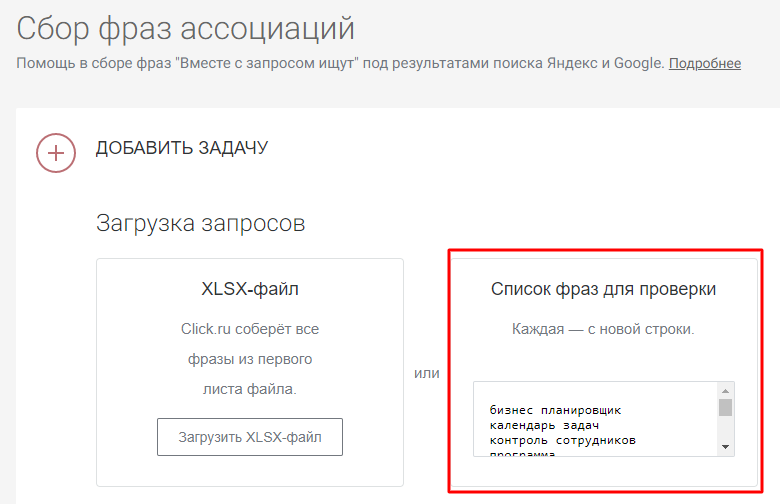
Выставляем нужный регион и запускаем парсинг. При желании можно добавить список минус-слов:
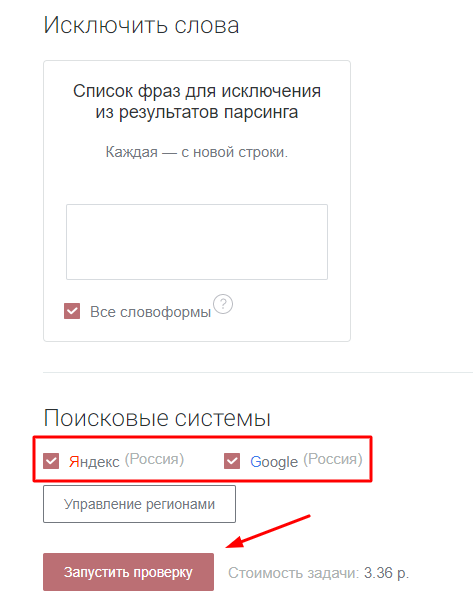
Через несколько минут получаем результат и выгружаем его в формате XLSX.
Сразу удаляем нерелевантные слова, например, «бизнес планировщик тетрадь». Чистку можно провести и на последнем этапе, но у нас небольшой список, который можно быстро обработать вручную.
Подходящие фразы добавляем в файл с семантикой. Некоторые из них могут дублировать ключи, собранные на предыдущих этапах. Этого не стоит бояться, мы избавимся от дублей позже. С помощью парсера фраз-ассоциаций мы пополнили список информационных запросов на 105 ключей.
Расширяем семантику поисковыми подсказками
Расширить список можно при помощи поисковых подсказок. Вот пример подсказки в Google по одному из высокочастотных ключей:
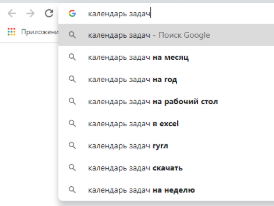
Опять же, не будем тратить время и собирать руками все релевантные подсказки по базовым ключам в двух поисковых системах. Воспользуемся парсером поисковых подсказок в Click.ru. Чтобы не парсить микронизкочастотную семантику, в качестве опорных фраз добавляем двух-трехсловные ключи:
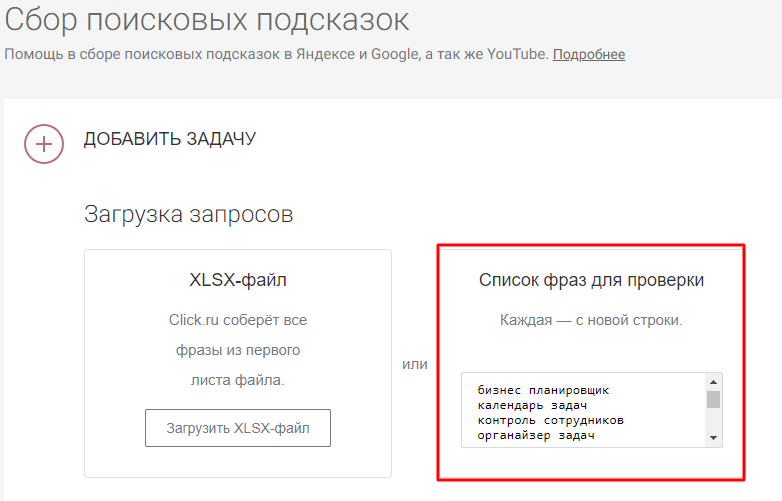
Указываем нужные регионы, метод сбора (в нашем случае собираем подсказки к исходным фразам) и запускаем проверку:
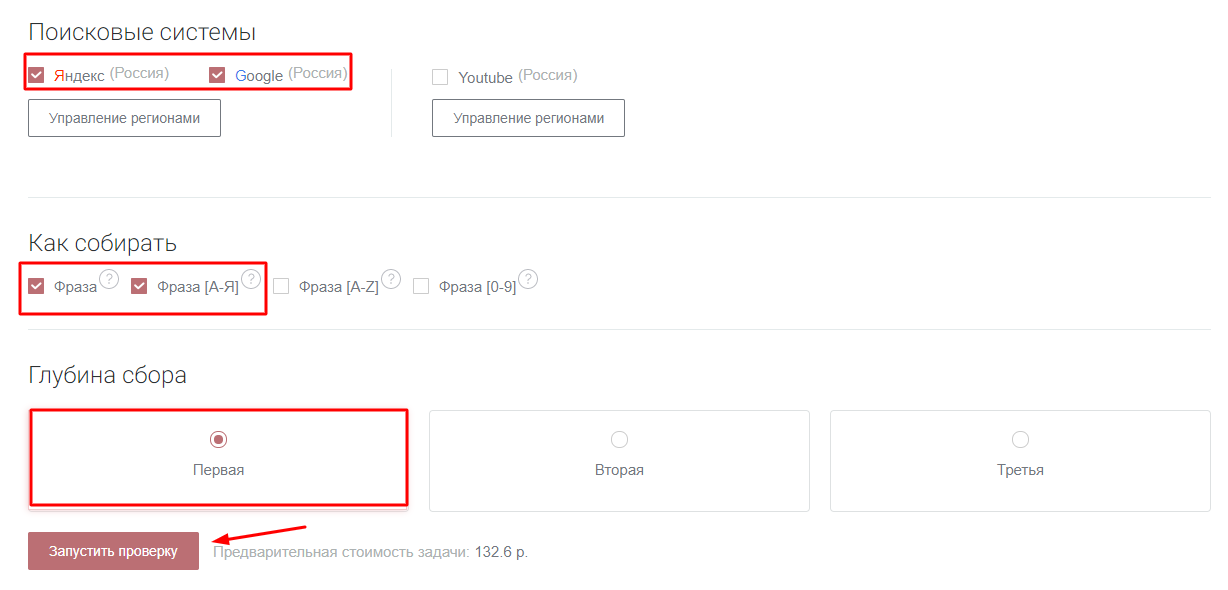
Глубину сбора оставили первую, чтобы не собирать слишком низкочастотные «хвосты». Как и в инструменте парсинга фраз-ассоциаций, здесь можно добавить минус-слова.
Вот подробный гайд по сбору поисковых подсказок
Если хотите облегчить процесс чистки полученных из подсказок запросов, запустите парсинг по методу «Фраза» для небольшой группы ключей. Затем выберите нерелевантные слова и добавьте их в список фраз для исключения на этапе сбора подсказок по всем базовым ключевикам.
Результат выгружаем в XLSX-файл и видим, что по 21 опорной фразе инструмент собрал 163 подсказки из Яндекса и 125 из Google. Сразу отказываемся от ручной чистки нерелевантных фраз — просто добавляем их в общий список.
Исследуем площадки вопросов и ответов
Кладезь информационной семантики – Q&A сайты (сайты вопросов и ответов). В России это Ответы Mail.ru и Яндекс.Кью. Вводим в строку поиска высокочастотные запросы и смотрим, что спрашивали люди:
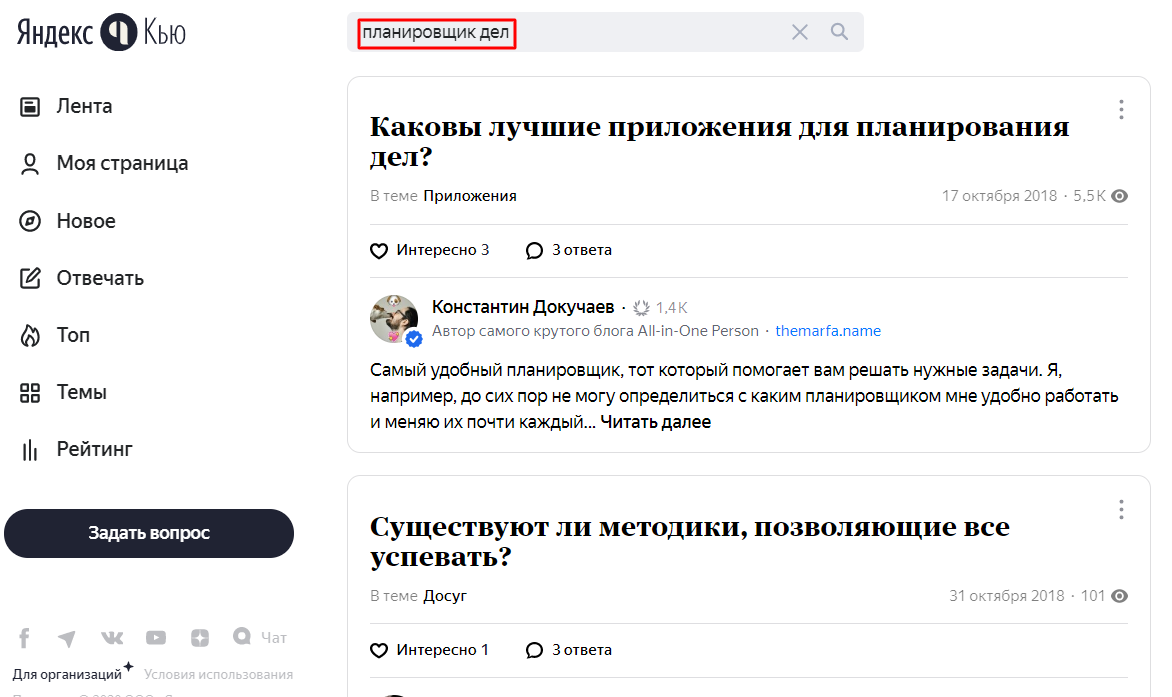
Вопросы можно переформулировать в темы статей (например, «Как работать организованно»), а можно вычленить из них информационные ключи.
Чтобы не копировать каждый вопрос вручную, используйте браузерное расширение для парсинга (например, Scraper). К сожалению, такие парсеры работают только на Ответах Mail.ru – на Кью вопросы невозможно выделить. Утешает только, что Яндекс.Кью – более молодой сервис, вопросов там еще не так много, как на сайте Mail.ru. В нашей тематике реально просмотреть все вопросы по высокочастотникам вручную.
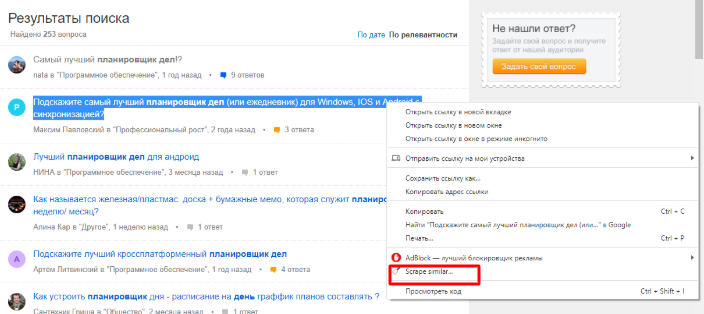
Итак, парсим формулировки вопросов с Ответов Mail.ru при помощи расширения Scraper. На странице с результатами поиска по релевантному запросу выделяем любой вопрос, кликаем правой кнопкой и в контекстном меню выбираем «Scrape similar...»:
Собранные вопросы копируем и вставляем в Excel-файл или Google Таблицу:
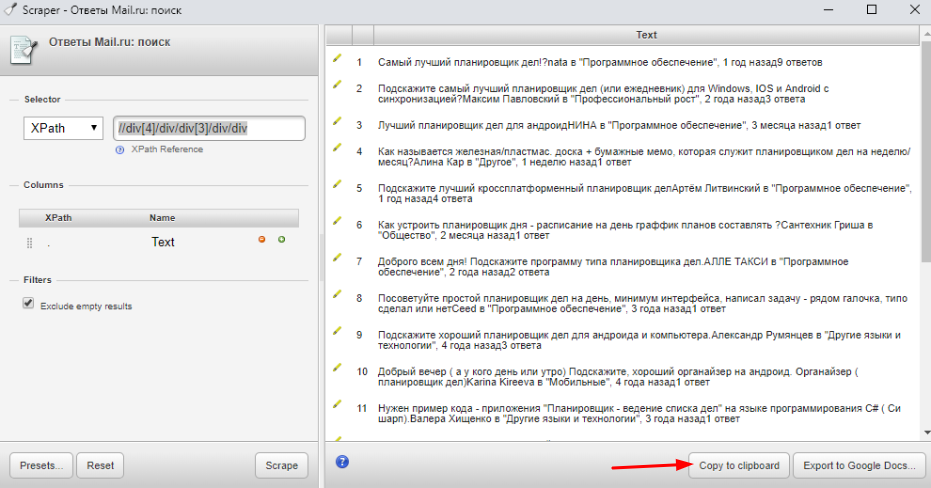
После изучения Q&A сайтов наш файл с семантикой пополнился еще несколькими ключевыми фразами:
| лучший кроссплатформенный планировщик дел |
| планировщик дня |
| где вести дела |
| простой планировщик задач |
| электронный планировщик дел |
| планировщик дел на несколько человек |
Для сбора низкочастотной семантики есть еще один интересный онлайн-сервис – AnswerThePublic. Он подбирает к заданной фразе вопросы, сравнения, предлоги и визуализирует низкочастотный «хвост»:
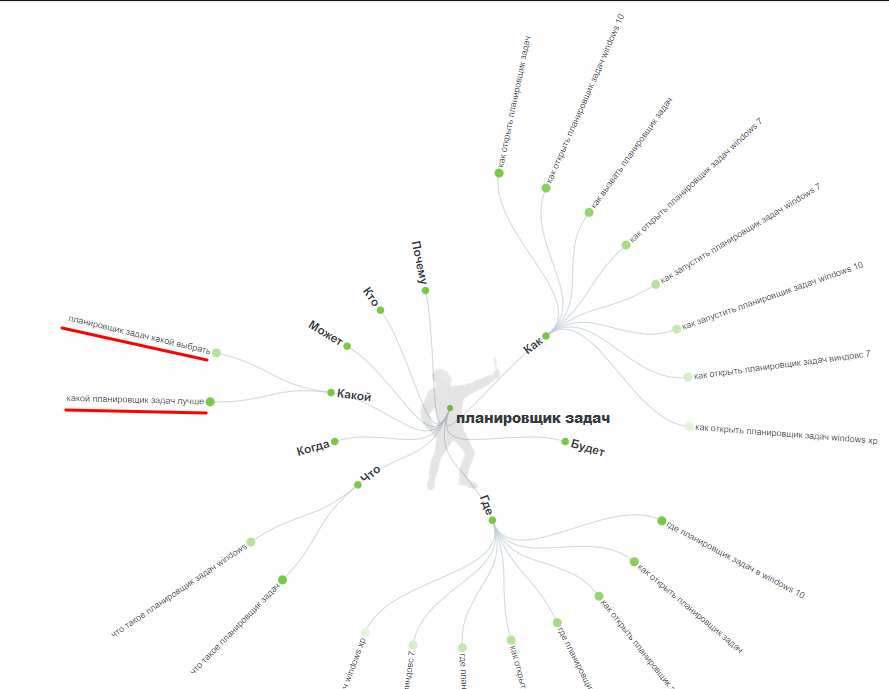
Все подобранные фразы можно скачать в CSV. Единственный минус сервиса – лимит на бесплатные запросы в день.
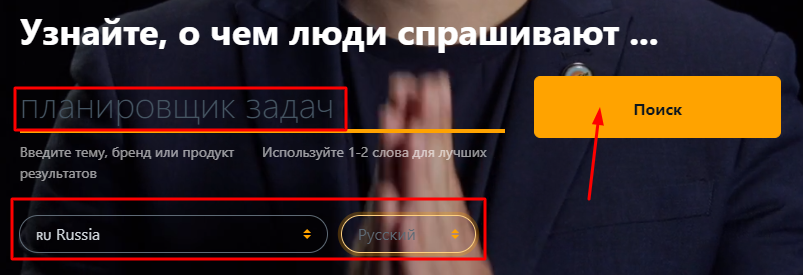
Мы провели операцию с высокочастотными запросами «планировщик задач», «планировщик дел» и «программа органайзер». Вводим фразу, выбираем страну и язык:
Выгружаем результат в CSV:
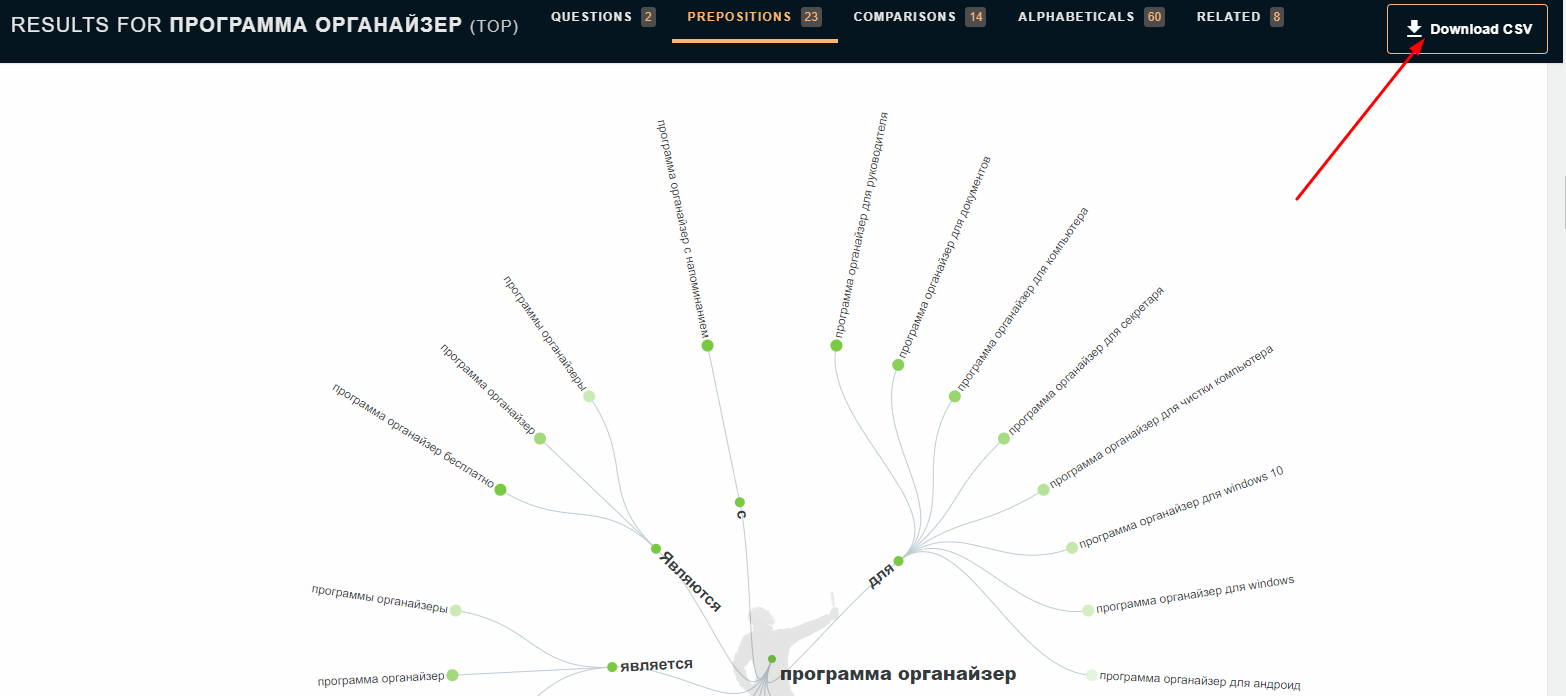
Наш список запросов пополнился еще десятком релевантных низкочастотных ключей.
Чистим, снимаем частотность и кластеризуем
В результате всех манипуляций у нас получился обширный список из 654 ключей. Но, как мы уже упоминали, в нем могут быть дубли. Почистить собранные фразы поможет бесплатный инструмент – нормализатор слов. Загружаем XLSX-файл с собранным ядром, отмечаем необходимые действия с запросами и запускаем выполнение задачи:
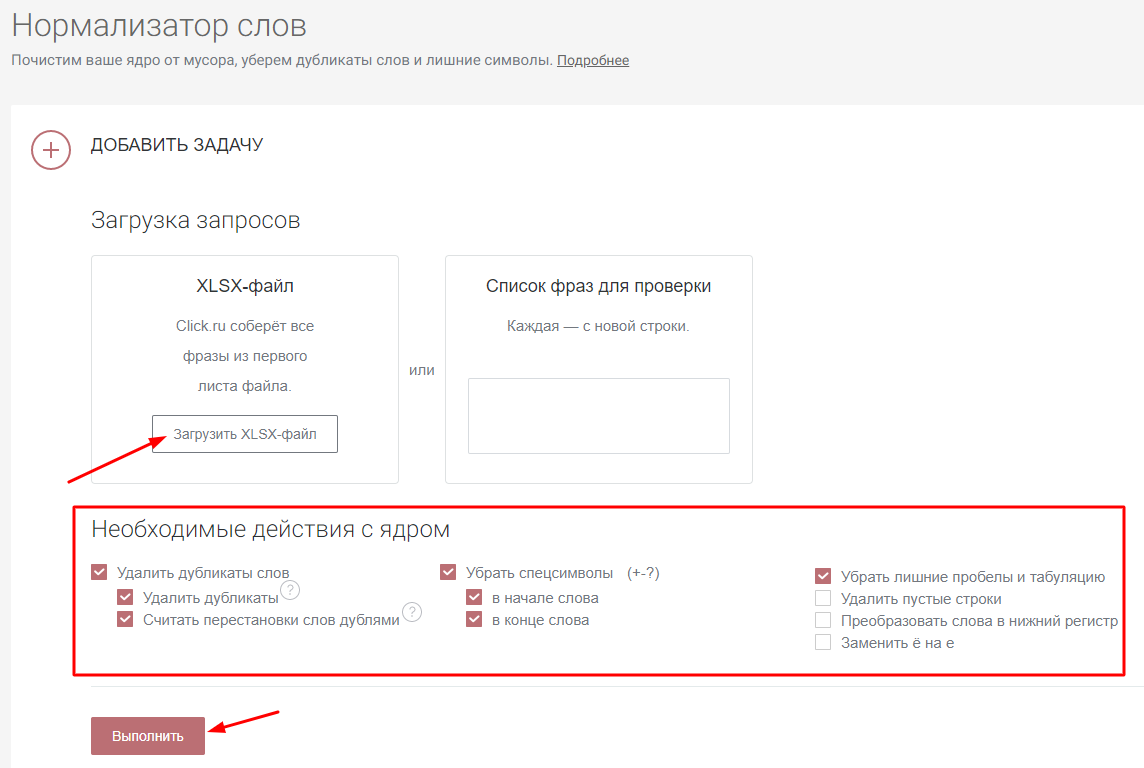
На выходе получаем очищенный список из 453 фраз. Уже лучше!
Теперь выявим фразы с нулевой частотностью с использованием оператора "". Такие запросы не принесут трафика на статью, поэтому их можно безболезненно удалить. Для сбора частотности используем парсер Wordstat. Загружаем XLSX-файл с очищенной семантикой, выбираем регион и типы частотностей и запускаем парсинг:
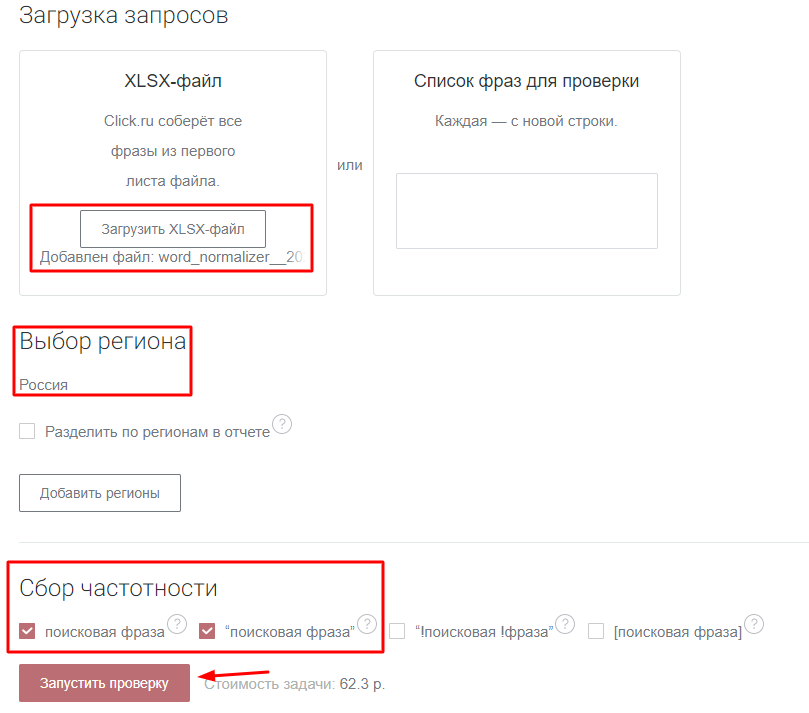
Результат выгружаем в XLSX-файл и удаляем запросы с точной частотностью 0. Список запросов сократился до 361.
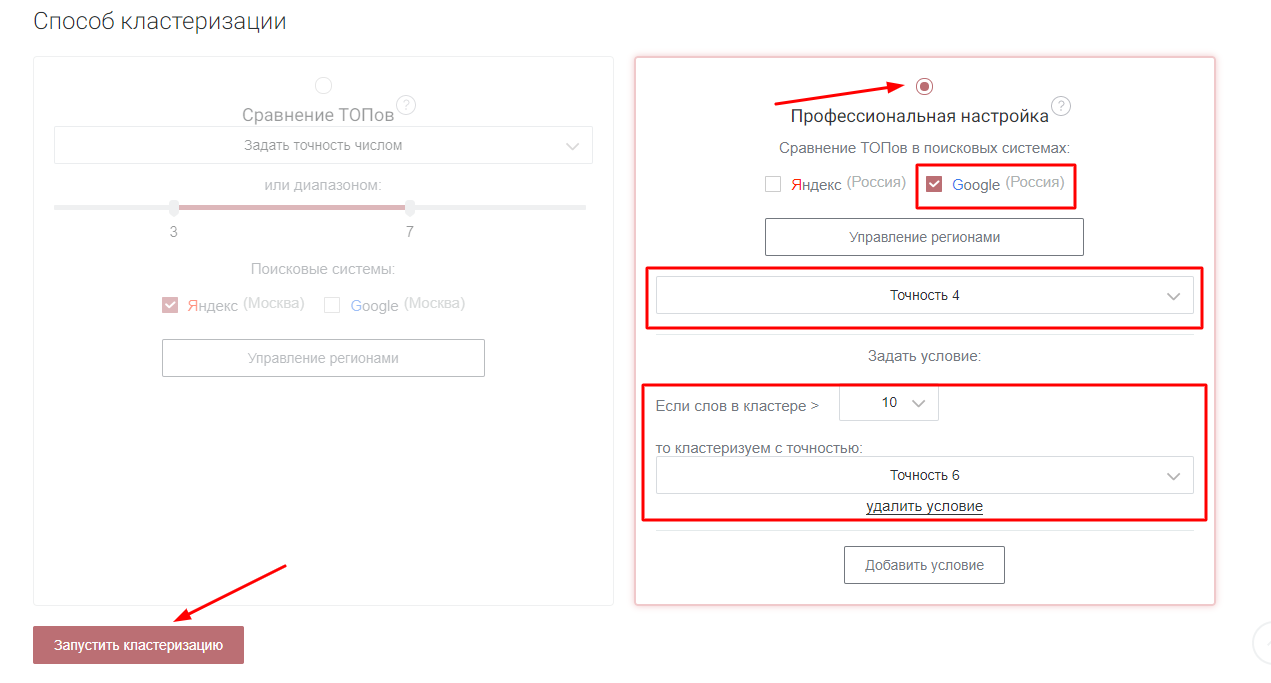
Теперь нужно распределить ключевые слова по группам. Это можно сделать двумя способами. Первый – ручная группировка на основе здравого смысла – довольно трудозатратно для такого количества фраз. К тому же важно учесть, какие ключевики поисковые системы определяют как принадлежащие к одной группе, ведь мы собираемся вести каждый кластер запросов на отдельную статью блога. Применяем автоматизированный инструмент кластеризации. Он группирует фразы по методу сравнения ТОПов (HARD):
- Загружаем XLSX-файл со списком фраз. В файле – только запросы, без частотностей, заголовков столбцов и другой служебной информации.
- Выбираем профессиональную настройку – она позволяет точнее распределить фразы по кластерам.
- Сравнивать ТОПы будем по Google, т.к. из этой поисковой системы идет большая доля трафика на сайт.
- Выбираем точность кластеризации 4 (от четырех одинаковых результатов в ТОПе).
- Выставляем условие: если слов в кластере больше 10, то увеличиваем точность кластеризации до 6.
- Запускаем процесс.
Подробный гайд по кластеризации вы найдете по ссылке.
Выгружаем результат в формате XLSX. На первом листе файла содержатся такие данные:
- название кластера;
- ключевые слова, которые относятся к кластеру;
- частотность ключевого слова и суммарная частотность кластера;
- число совпадений ТОПа;
- подсветки для ключевых слов и кластеров – слова и фразы, которые поисковик выделяет жирным в выдаче;
- количество главных страниц в ТОП10;
- URL, который находится в ТОПе по запросу.
Мы кластеризовали ядро по одному региону и поисковой ситеме. Кроме распределенных по кластерам запросов в файле есть отдельный лист с адресами сайтов, которые находятся в ТОПе по семантическому ядру – система уже выбрала конкурентов из выдачи.
Теперь мы можем удалить нерелевантные кластеры – это намного удобнее, чем удалять не подходящие под тематику проекта запросы по одному. Например, удаляем кластер, связанный с планировщиком задач для Windows. Нашу программу можно устанавливать на Windows, Android и iOS, но запросы «планировщик задач windows» связаны с штатным функционалом операционной системы, который так и называется – «Планировщик заданий».
На основе кластеров запросов составляем контент-план.
Пример контент-плана для сервиса планирования задач
Мы составили контент-план на основе информационной семантики на период с мая по октябрь из расчета по три статьи в месяц – итого 18 тем:
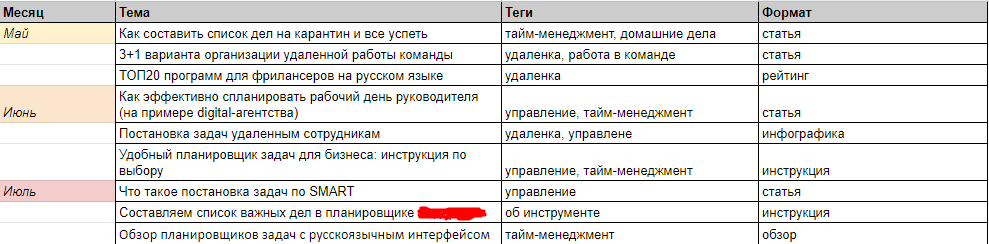
Напротив каждой темы есть пометка о предполагаемом формате контента и теги, к которым она относится.
Не все кластеры оказались охваченными, запас тем при таком плане публикаций остается еще как минимум на полгода. Если потребуется быстрее охватить весь пул информационной семантики, используем собранные запросы как основу для публикаций на внешних площадках, email-рассылки, постов в соцсетях.
Что делать дальше
Наладили производство и публикацию контента по составленному плану? Не стоит сидеть сложа руки и ждать, когда на сайт польется трафик из поисковиков. Вот перечень шагов, которые нужно предпринять, чтобы ускорить продвижение корпоративного блога:
- Подключить контентную аналитику в Яндекс.Метрике, добавить на сайт микроразметку Schema.org и Open Graph.
- Каждую статью оптимизировать под соответствующий кластер ключевых запросов.
- Провести аудит ранее размещенных статей: удалить безнадежные, переработать и оптимизировать те, которые имеет смысл. При этом опираться на поведенческие показатели статей и актуальность с точки зрения семантики (вот кейс по актуализации статей).
- Анонсировать выход каждого нового материала в корпоративных соцсетях и покупать размещения в тематических сообществах.
- Подключить платные способы продвижения – запустить для статей таргетированную рекламу.
Сделаете все правильно — и все будет гуд.
Что еще почитать по теме:
Нишевый контент: как 10% статей дают 61% конверсий из блога
