Привет, Хабр)
Этой статьей мы начинаем серию публикаций о технологиях оптического распознавания (OCR, ICR) и понимания документов, разработанных специалистами компании Cognitive Technologies. Многие из этих решений более 10 лет успешно функционируют в разных организациях и помогают оптимизировать процессы обработки бланков Пенсионного фонда, анкет на получение загранпаспорта, платежных поручений Сбербанка РФ, результатов голосования акционеров Газпрома и десятки других документов.
Сегодня наш рассказ об одной из наиболее сложных и интересных с научной точки зрения проблем, которую приходится решать при распознавании деловых документов, это снятие помех или отделение полезной информации от «мусора».
Вначале необходимо определить, что речь идет о документах с рукопечатным заполнением, построенных по заранее известной форме.

Сетка ячеек

Отдельные клетки

Строка с засечками
Рисунок 1. Виды решеток знакомест
а)

б)

Рисунок 2.Пример заполненного поля в присутствии засечек (а) и после снятия регулярных помех (б)
В таких случаях расположение полей ввода данных в документе известно заранее и описано в
модели документа, которая включает описание статических элементов (линий разграфки, заголовки полей), состав элементов, их взаимное расположение, размеры и другие характеристики. Для бланков документов, подразумевающих заполнение от руки, поля ввода оформляются как специального вида решетка, в которой для каждой буквы отведена отдельная клетка (знакоместо).
Решетки знакомест бывают различного типа. На практике наиболее часто используются три основных типа решеток: в виде сетки ячеек, отдельных клеток и в виде строки с засечками (Рисунок 1). Все они имеют характерную прямоугольную структуру (состоят из горизонтальных и вертикальных линий).
На рисунке 2а приведен пример заполненного рукопечатного поля с решеткой типа «строка с засечками». С точки зрения распознающей системы, решетка знакомест по сути является структурированным шумом, наложенным на текстовые данные, порождающим большое количество ошибок распознавания. В частности, в отличие от некоррелированного шума типа «соль/перец», наложенные решетки делают полностью непригодными топологические методы распознавания символов. Таким образом, попытка удаления этих «искусственных» помех может привести к существенному росту качества распознавания.
Знания о точном расположении опорных элементов позволяют подавить их, почти не искажая при этом текста. Несмотря на то, что теоретически эта информация известна (заложена в модель документа), на практике она часто бывает неполной или неверной. В процессе печати, заполнения и последующей оцифровки бланков привносятся различного рода деформации (сдвиг, наклон, незначительные растяжения, связанные с протяжкой в принтере и/или сканере) и шумовые сигналы (пятна, тени от сгиба бумаги и другие). Поэтому эталонное описание решеток часто не соответствует их реализации: теряется свойство прямоугольной формы, нарушается периодичность между засечками и прочее (Рисунок 3).


Нарушение периодичности

Искажение прямолинейности
Рисунок 3. Примеры деформаций решеток знакомест
Из вышесказанного вытекают следующие проблемы, связанные с точной локализацией опорных элементов:
- • Искажение прямолинейности линий.
- • Нарушение периодичности в решетках знакомест.
- • Наличие посторонних статических элементов в непосредственной близости к полям ввода (Рис. 4).
- • Наличие элементов заполнения, морфологически похожих на отрезки прямых.
Первые две проблемы могут быть устранены путем применения алгоритма динамической трансформации временной оси (DTW, Dynamic time warping), который является классическим примером использования метода динамического программирования. Исключить из внимания линии разграфки можно с помощью дополнительных знаний о структуре решеток знакомест: наличии стыков горизонтальных и вертикальных соединительных линий. Такие структурные особенности легко детектируются с помощью морфологических фильтров типа «hit-or-miss».
Остановимся немного подробнее на алгоритме локализации опорных решеток, построенном на применении этих двух инструментов.
Методы предварительной идентификации документов позволяют определить приблизительные области полей заполнения, а также угол наклона документа в целом. К сожалению, из-за деформаций изображения это не гарантирует точной ориентации отдельных полей. Кроме того, на анкетах встречаются так называемые «надпечатки» – наносимые с помощью принтера вариативные части анкеты. По понятным причинам поля надпечатки могут иметь наклон, отличный от глобального наклона документа. Предлагаемый алгоритм локализации ожидает «на входе» прямо ориентированное изображение, поэтому первым шагом следует довернуть изображение поля, определив его угол наклона. Для этого используется алгоритм, опирающийся на быстрое преобразование Хафа. Далее, на основании знаний о числе и типе стыков с вертикальными составляющими решетки, определяется положение горизонтальных опорных линий. Следующим этапом находится расположение вертикальных опорных элементов. В заключение, с помощью метода динамического программирования корректируются расположение горизонтальных линий для каждой ячейки.
Отметим, что задачи определения ориентации изображения и снятия точно найденной решетки являются отдельными задачами и в этой статье не рассматриваются.
Теперь рассмотрим более подробно алгоритмы поиска и корректировки линий и стыков.
Поиск горизонтальных линий с известным шаблоном стыков
Итак, для того, чтобы выделять опорные горизонтальные линии решеток на фоне посторонних контрастных линий, предлагается опереться на информацию о сопряжении опорной линии с вертикальными элементами решетки. Будем описывать искомый объект простейшим регулярным выражением – строкой, содержащей смысловые символы и символ возможного повтора (‘*’). Назовем это описание шаблоном линии.
В качестве смысловых символов будем использовать символы типа стыка (например, ‘└’, ‘┴’, ‘┘’), а также символы наличия линии без стыков (‘─’) и отсутствия линии (‘○’). Например, нижние опорные линии всех полей, изображенных на Рис. 4, описываются паттерном «└ ─* ┴ ─* ┘», а полей с решеткой типа «отдельные клетки» – «└ ─* ┘ ○ * └ ─* ┘ ○ * └ ─* ┘ …».
Рассмотрим теперь метод оценивания пикселя изображения как центрального пикселя стыка линий. Фактически, нам необходимо оценить, насколько темным является центральный пиксель, а также пиксели, располагающиеся в тех направлениях, в которых мы ожидаем наличия линий. Кроме того, мы должны проверить, что в остальных направлениях пиксели достаточно светлые (иначе на крестообразный стык будут реагировать все детекторы), а, кроме того, светлыми должны быть диагонали (иначе детектор будет реагировать на углы черных прямоугольников). Будем рассматривать паттерн из 9 пикселей в узлах регулярной решетки с шагом L, соразмерным ожидаемой толщине линии. На рис. 5 изображена ожидаемая конфигурация для стыка «┴». Пиксель, для которого производятся вычисления, соответствует центру приведенной схемы.
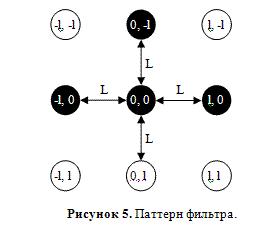
Построим теперь морфологический фильтр, соответствующий рассматриваемой конфигурации. По пикселям, помеченным на схеме белым, будем искать минимум, а по черным – максимум. Затем найдем разность полученных значений, и обнулим, если она меньше 0. Полученное значение W будем считать оценкой качества искомого стыка в данном пикселе:
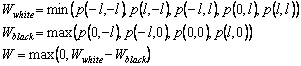
Аналогичным образом строятся детекторы всех остальных типов стыков, а также детектор прямой без стыков. Для детектора отсутствия линии способ построения немного отличается:
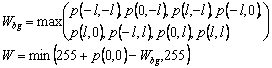
где Wbg несет смысл оценки яркости фона в присутствии возможных загрязнений в любом из пикселей паттерна.
Итак, применяя соответствующие морфологические фильтры к изображению поля, мы получаем в каждом пикселе набор оценок, говорящих, насколько данный пиксель похож на центральный пиксель стыка, линии или пробела (Рис. 5).
Теперь для каждой строки изображения поля определим, насколько она соответствует искомому паттерну, и среди всех строк выберем наилучшую. Вполне очевидно, что задача оценки одной строки – это задача динамического программирования. Действительно, создадим таблицу, каждый столбец которого соответствует смысловому символу шаблона либо символу, сопровождаемому звездочкой, а каждая строка – пикселю строки изображения. Каждый элемент таблицы заполним оценкой пикселя, задаваемого строкой, на соответствие стыку, задаваемому столбцом (Табл. 1). Нашей задачей будет найти путь с наибольшим весом в таблице от левого до правого края, при условии, что в столбцах без звездочки мы можем двигаться только на одну ячейку вправо вниз по диагонали, а в столбцах со звездочкой – так же или на одну ячейку вниз. При этом весом пути будет считаться сумма значений ячеек, по которым проходит путь. (В Табл. 1 оптимальный путь выделен голубым цветом.)
Решив эту задачу последовательно для каждой строки изображения, найдем координаты нижней и (если есть у данного вида решетки) верхней опорной линии решетки.
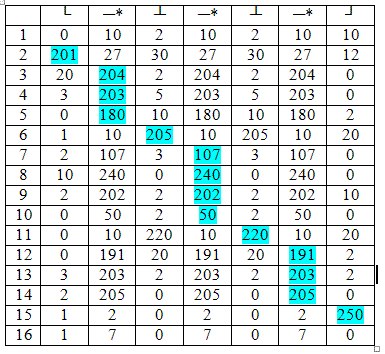
Таблица 1. Пример поиска оценивания соответствия шаблону методом динамического программирования.
Поиск вертикальных линий
Вертикальные линии решетки можно было бы искать с помощью частотного анализа горизонтальной проекции. Но из-за неидеальной системы подачи бумаги принтеров и протяжных сканеров в решетках знакомест часто нарушается периодичность между засечками (Рис. 6).
a)
 б)
б)
в)
 г)
г)
Рисунок 6. Результат детекции стыков ‘└’, ‘┴’ и ‘─’ (б, в, г) на изображении поля (а).
Кроме того, при экстренном увеличении числа ячеек поля на этапе разработки бланка (при внезапном знакомстве с фамилией «Гедиминайте-Бержанскайте-Клаусутайте») случается, что добавленные ячейки имеют нестандартный размер. Проблема усугубляется тем, что даже в случае идеальной геометрии решетки из-за символов, имеющих выраженные вертикальные штрихи, на проекции отображается много ложных пиков.
Последнюю проблему, впрочем, можно частично ослабить: так как на данном этапе детектирования решетки нам уже известно расположение горизонтальных линий, можно рассматривать не проекцию всего изображения на горизонтальную ось, а проекцию лишь части, которая находится выше нижней линии решетки, но ниже верхней линии или высоты засечек в случае решеток соответствующего типа. Тем самым обеспечивается, что пики, образованные высокими буквами, не будут превышать пики, образованные элементами решетки. Кроме того, разумно добавить в гистограмму вес «┴» и «┬» стыков, чтобы усилить истинные пики.
Зная предположительный период и возможную погрешность в расстоянии между вертикальными опорными элементами, можно быстро посчитать всевозможные варианты расположения таких элементов на заданном нам участке, и выбрать наилучший вариант. Эта задача хорошо решается методом динамического программирования, причем в данном случае для решения не потребуется таблица.
Будем двигаться вдоль гистограммы слева направо. На каждом шагу рассмотрим отрезок гистограммы, где x – наше текущее положение, p – ожидаемый период, а ∆ – максимальное отклонение. Найдём максимум среди значений гистограммы по указанному отрезку и прибавим к текущей ячейке, а в параллельном массиве сохраним индекс максимума. Тогда глобальный максимум полученной гистограммы будет соответствовать положению последней вертикальной линии, а соответствующий индекс будет указывать на предыдущий элемент списка найденных линий. Пройдя по списку, восстановим положения всех вертикальных опорных элементов.
Корректировка расположения горизонтальных линий
После нахождения вертикальных и горизонтальных линий решетка знакомест считается сформированной. Однако, для алгоритма снятия решётки требуется пиксельная точность, а при протягивании бумаги на этапе печати и сканирования изображение может подвергнуться веерной дисторсии (если лист будет поворачиваться по мере прохождения по тракту). Кроме того, алгоритм определения угла наклона изображения поля также может внести небольшие ошибки. Поставим задачу следующим образом: требуется найти последовательность смещений по вертикали элементов горизонтальной линии от ячейки к ячейке (Рис. 3), при условии, что каждое отдельное смещение не может быть больше, чем k пикселей (как правило, k=1).
Эта задача также решается методом динамического программирования.
Соберем вертикальную гистограмму размера, равного высоте поля (что превышает размер решетки), для каждой ячейки решетки и заполним этими гистограммами таблицу шириной, равной числу ячеек. Будем максимизировать путь от левой до правой границы таблицы, разрешая при смещении вправо сдвигаться вверх или вниз не более чем на k элементов. Найденный максимальный путь будет проходить по положениям элементов опорной горизонтальной линии.
С помощью этих двух инструментов и решалась задача точной локализации решеток знакомест. Разработанный подход к решению задачи сопоставления был программно реализован и в настоящий момент промышленно используется для потокового ввода анкет ОСАГО, заявлений на выдачу кредитов, а также анкет сетевого маркетинга.
Качество работы алгоритма оценивалось на наборе из 395 полисов ОСАГО, содержащих 12245 полей (Табл. 2). Для этого набора вручную были введены правильные значения всех полей, затем система распознавания была запущена в трех режимах: с выключенной подсистемой снятия решеток, с включенным «наивным» алгоритмом (опирающимся исключительно на анализ гистограмм) и с предложенным алгоритмом. Качество распознавания замерялось как процент правильно (без единой ошибки) распознанных полей. Ценой двухкратного замедления работы системы удалось поднять качество распознавания с 30% до 80%. Следует отметить, что системы распознавания документов с качеством распознавания ниже 70% как правило нерентабельны – заполнение оператором всех полей оказывается быстрее, чем исправление ошибок.
Как показал детальный просмотр обработанных изображений, предложенный алгоритм обеспечивает:
- Корректную работу с полями, захватывающими посторонние контрастные линии разграфки.
- Корректную обработку полей с переменной шириной ячеек.
- Корректную обработку решеток знакомест с нарушенной геометрией (включая веерные искажения).
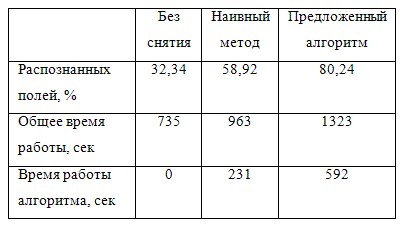
Таблица 2
Подробнее информацию по этой теме можно прочитать в статье А.В. Куроптев, Д.П. Николаев, В.В. Постников. «Точная локализация опорных решеток полей заполнения в анкетах методами динамического программирования и морфологической фильтрации», опубликованной в Трудах института системного анализа Российской академии наук (ИСА РАН), 2013, Т. 63, №3, стр.
