
Пока маркетологи обмазываются BigData и бегают в таком виде на пресс-конференциях, я предлагаю просто скачать бесплатный инструмент с тестовыми наборами данных, шаблонами процессов и начать работать.
Закачка, установка и получение первых результатов — минут 20 максимум.
Я говорю про RapidMiner — опенсорсную среду, которая при всей своей бесплатности некисло «уделывает» коммерческих конкурентов. Правда, сразу скажу, что разработчики всё равно её продают, а в опенсорс отдают только предпоследние версии. Дома можно попробовать потому, что есть вообще бесплатные сборки со всей-всей логикой с всего лишь двумя ограничениями — максимальный объем используемой памяти 1 Гб и работа только с обычными файлами (csv, xls и т.п.) в качестве источника данных. Естественно, в малом бизнесе это тоже не проблема.
Что надо знать про RapidMiner
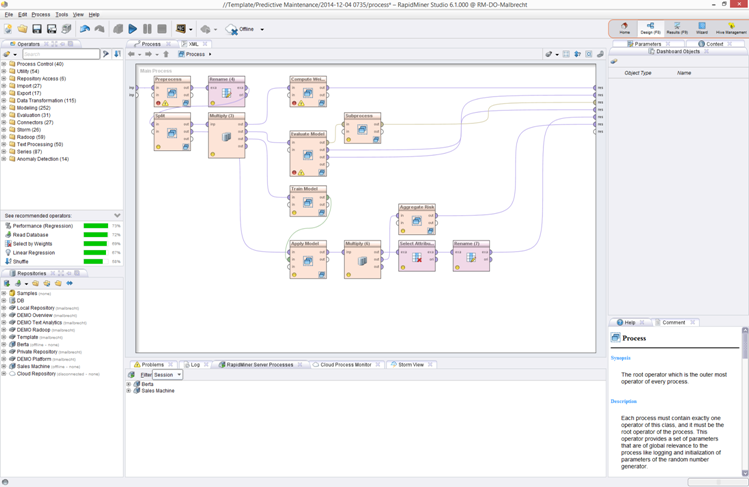
Вот интерфейс. Вы закидываете данные, а потом просто перетаскиваете операторы в GUI, формируя процесс обработки данных. От вас — только понимание того, что вы делаете. Весь код берёт на себя среда. «Под капот» можно, конечно, залезть, но в большинстве случаев это просто не надо.
Важные фичи
- Хороший GUI. По сути, каждый функциональный блок собран в кубик. Ничего нового в подходе, но очень крутое исполнение. Обычно разница между классическим программированием и визуальным сильно бьёт по функциональности. Например, в SPSS Modeler всего 50 узлов, а тут целых 250 в базовой загрузке.
- Есть хорошие инструменты подготовки данных. Обычно предполагается, что данные готовятся где-то ещё, но тут уже есть готовый ETL. В том же коммерческом SPSS возможностей для подготовки куда меньше.
- Расширяемость. Есть старый добрый язык R. Полностью интегрированы операторы система WEKA. В общем, это не «детский сад» и не закрытый фреймворк. Надо будет спуститься на низкий уровень — без проблем.
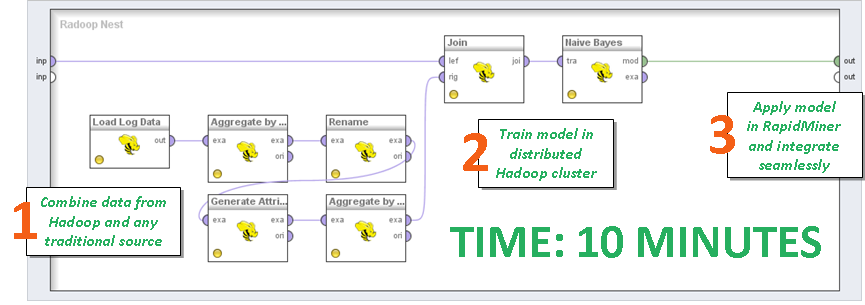
- Дружит с Hadoop (отдельное платное расширение с незамысловатым названием Radoop), причём как с чистым, так и с коммерческими реализациями. То есть когда вы решите молотить не табличку XLS с демо-набором данных, а боевую БД, да еще и при помощи модного ныне Apache Spark — всё сразу встанет как надо. Самое приятное — писать код не надо. Можно в майнере аналитиком написать скрипт через всё тот же GUI и отдать в обработку.
- Архитектурно данные снаружи. Ставим платформу, грузим данные и начинаем смотреть, где какие кореляции, что можем спрогнозировать. Это и плюс, и минус, почему — ниже.
- Кроме IDE есть ещё сервер. Rapid Miner Studio создаёт процессы, а на сервере их можно публиковать. Что-то типа планировщика — сервер знает, какой процесс когда запускать, с какой частой, что делать, если где-то что-то отвалилось, кто отвечает за каждый из процессов, кому как отдавать ресурсы, куда выгружать результаты. В общем, все-все-все современные плюшки.
- А ещё сервер же умеет сразу строить минимальные отчёты. Можно выгружать не в XLS, а рисовать графику прямо там. Это нравится маркетингу маленьких компаний и удобно для небольших проектов. И, естественно, это очень недорого (даже в коммерческой версии) в сравнении с Моделлером и SAS. Но — сразу говорю — области применения у них разные.
- Быстрое развитие. Только поднялся серьезный шум вокруг Apache Spark — через пару месяцев вышел релиз о поддержке базового функционала.
Минусы
- Деньги. С 2011 года в опенсорс уходит предпоследняя версия продукта. С выходом новой предыдущая становится опенсорсной. Cтартер не позволяет строить процессы, обработка которых съест больше гигибайта оперативной памяти. Триал две недели.
- Компания по Гартнеру не самая большая. Это плохо для внедрения и поддержки, потому что своими силами они это делать не могут. С другой стороны, всё это для больших бизнесов по политике компании отдаётся на интеграторов (то есть, как раз нам).
- Авторитет компании пока не накоплен — внедрений не так много, молодая. За SAS ещё никого не увольняли, даже если бюджет в три раза выше, а здесь имя не на слуху.
- Плохо с консалтингом, нет формализованных процессов техподдержки. Предполагается, что это всё делают, опять же, интеграторы. Мы и делаем, но с точки зрения большого бизнеса нельзя не упомянуть про эту особенность.
- Не все вещи анализируются на сервере, в некоторых случаях платформа пробует агрегировать данные на локальной машине. Это плохо, когда модель требует всей базы, то есть когда нельзя взять и прогнать алгоритм на небольшом куске данных. Предполагается, что вы используете Hadoop или аналог для решения этой проблемы. Там всё есть.
- Аналитика классических баз данных (то, что не Big Data по критерию многообразия) на шаг позади классических решений. То есть если вы захотите сделать предагрегацию перед выгрузкой in-database, то это нужно задать ручками явно, сам RapidMiner до этого не догадается.

RapidMiner vs IBM SPSS Modeler
У RM гораздо шире функциональные возможности по обработке, банально больше узлов. С другой стороны, в SPSS есть режимы «автопилота». Авто-модели (Auto Numeric, Auto Classifier) — перебирают несколько возможных моделей с разными параметрами, выбирают несколько лучших. Не сильно опытный аналитик может построить на таком адекватную модель. Она почти наверняка будет уступать в точности построенным опытным специалистом, но есть сам факт — можно построить модель ничего не понимая в этом. В RM есть аналог (Loop and Deliver Best), но он все же требует хотя бы выбрать модели и критерии выбора лучшего. Автоматическая предобработка данных (Auto Data Prep) — другая известная фишка SPSS — иначе и чуть более муторно реализована в RapidMiner.

В SPSS сборка данных выполняется одним узлом Automated Data Preparation, галочками проставляется, что нужно сделать с данными. В RapidMiner — собирается из атомарных узлов в произвольной последовательности.
RapidMiner vs SAS
По возможностям «сделать что угодно» RM выше, но, в конечном итоге, с помощью какой-то матери и некоторых усложнений можно получить тот же результат и в SAS. Но здесь совершенно другой подход — придётся переучиваться, если вы привыкли к SAS. Ещё SAS предоставляет множество вертикальных решений — банки, ритейл. Платформа разговаривает с пользователем на его бизнес-языке. RM более абстрактен, в нём придётся самому формулировать, что есть что.
RapidMiner vs Demantra
Не совсем правильно сравнивать эти два пакета, но важно для иллюстрации того, как работает RM. Oracle Demantra (и, очень грубо, все схожие продукты под конкретную индустрию или задачу)- это готовый пакет, заточенный под конкретные задачи закупок и поставок. Там есть конкретные операции — загрузили данные о продажах, получили прогноз по закупкам товара. Одна модель, очень много готовых шаблонов. Дорого, круто и под большой бизнес.
С другой стороны, в RM можно повторить всё то же самое, но половину логики придётся изобретать заново. Это очень удобно для data scientist’ов в плане кастомизации и гибкости конечного решения, но крайне сложно для бизнес-пользователей — они просто не увидят знакомых слов и инструментов
Архитектура

Задачи
Итак, перед нами чистое поле для решения любых задач. Наиболее частые в России, решающиеся такими инструментами — это:
- Анализ транзакций (например, банковских) для противодействия мошенничеству.
- Клиентская аналитика. Это самая горячая тема. Проще всего и выгоднее всего бывает выстроить модель оттока клиентов и отмечать флагом тех, кто к этому готов. Для рынка телекомов, например, переход абонента куда-то ещё — это трагедия, потому что людей больше не становится. Поэтому за флажок «клиент может убежать» они готовы платить реальные деньги.
- Персональные рекомендации. Это любит розница — что кому предложить. Как раз тот случай, когда вы только-только не купили презервативы, а про вас уже запомнили, что через несколько месяцев нужно давать скидки на детское питание.
- Прогнозирование поставок и продаж. При том, что есть готовые пакеты для этого, RapidMiner тупо дешевле. Не надо покупать Боинг, если у вас средний бизнес. И не надо покупать тот же JDA (он стоит как два Боинга). Нет, там всё очень круто и по возможностям, и по интеграции — но банально мало кто может позволить себе это купить.
- Текстовая аналитика — о чём люди пишут. Например, анализ эмоционального оттенка отзывов или комментариев в автоматическом режиме. Это «50 жаловались на связь в Волгограде по улице Победы», «20 похвалили сервис», «Основная причина недовольства абонентов — частые разрывы соединения» и так далее.
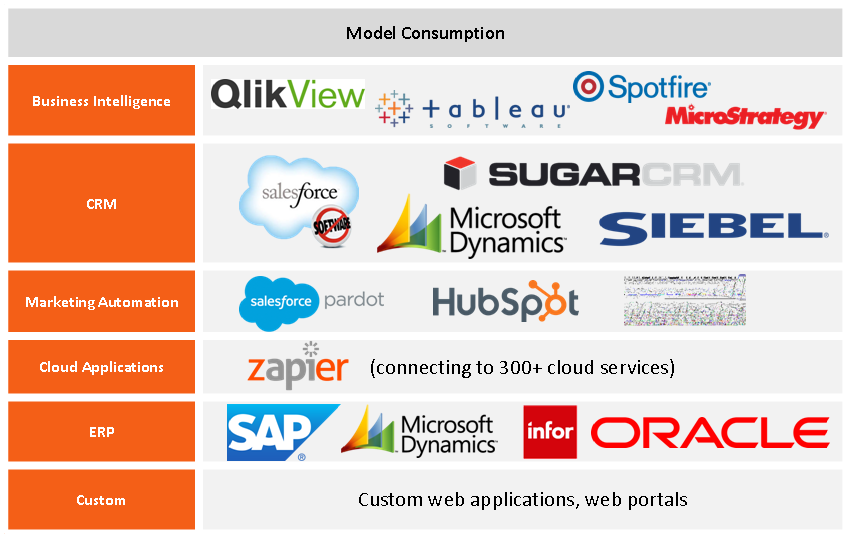
- Часто бывает нужна готовая интеграция на уровне базы и веб-сервисов. По сути, тут ничего не надо писать, задаётся только частота опроса, какие модель и процесс использовать, и кто потребитель. Для асинхронных или месячных отчётов ещё проще, есть даже подтягивания данных из Дропбокса для совсем малого бизнеса и готовая интеграция с Амазоновскими сервисами.
- Коммерческий RapidMiner очень хорошо работает с большими данными. Exadata и Vertica — классические базы данных 2.0 или массивно-параллельные СУБД — поддерживаются «во все тяжкие».

А это моя (и не только моя) любимая тема — метамоделирование. Для тех, кто немного в стороне от этого — разные модели часто находят разные взаимосвязи, формируя на одной и той же выборке разные результаты. И ошибаются часто тоже в разных местах. И это нужно использовать — составить ансамбль моделей (Model Ensemble) Например, оператор Vote (голосование) — учитываются «мнения» всех моделей, входящих в ансамбль и на выход выдается результат, набравший наибольшее количество «голосов». Или один из наиболее популярных среди «продвинутых» data scientist’ов метод Bagging (Bootstrap Aggregation) — обучение нескольких моделей на разных подвыборках исходных данных с последующим усреднением их результатов.
Миграция
Что могу сказать по опыту нескольких переходов на RapidMiner: тут важно отметить, что с точки зрения Data Science впечатления положительны. Технологически немного хуже — очистка данных пошла труднее, мы уже привыкли к парадигме и простоте SPSS и SAS. Здесь нужно было больше перестраивать мозг — всё делается совсем по-другому. Очень разные архитектурные реализации, поэтому сразу говорю — мигрировать самостоятельно будет достаточно сложно в плане компетенций специалистов. Учиться надо заново. Но для нас и заказчиков результат того стоил.
Очень много приятых мелких фишек. Например, имеет смысл сказать про «макросы» — это параметры работы процесса, которые можно использовать в любой его точке. Например, в качестве макроса можно использовать имя файла, дату его создания, среднее значение какого-либо атрибута данных, наилучшую достигнутую точность, номер итерации, последнее время запуска процесса. Часто выручает при создании нетривиальных операций обработки. К примеру, с помощью макроса может быть ограничено время выполнения операции, при этом порог времени не фиксируется, а является расчетным параметром — зависит от размера данных, времени суток (ночные оптимизации могут выполняться дольше).
Из недавнего — строили модель для прогнозирования пассажиропотока. Вот тут уже мы использовали RM на 100%, т.к. строили все «с нуля» и некуда было оглядываться, не нужно было переносить существующие процессы и пытаться их повторить на другом инструменте.
Что делать, чтобы начать
Вот ссылка на закачку собранного релиза с официального сайта.
Если у вас данных мало — просто пользуйтесь, пока не надоест, компания прекрасно понимает, что их полную версию покупает только средний и большой бизнес. Если данных мало — вам будет важно знать, что цены фиксированные, не зависят от заказчика.
Если чувствуете, что штука крутая, но хочется освоить быстро — приходите к нам в учебный центр. Мы — официальный партнёр RapidMiner, и по итогам курсов выдаются сертификаты.От вас — базовые знания матстатистики (хотя бы представлять, что такое выбросы, среднее значение, нормальное распределение и дисперсия) и базовые знания компьютера. Мы дадим свои наборы данных от одного немецкого телекома, если у вас нет своего (или приносите в обезличенном виде его тоже) и вместе соберём кейс по прогнозированию оттока клиентов. А потом смоделируем модель исходя из того, сколько денег есть на их удержание. Например, есть 10 тысяч рублей и 100 000 клиентов — нужно выбрать из них тех, кого дешевле удержать, и кто больше принесет компании денег в перспективе. Попасть в наиболее вероятного клиента и максимизировать конечную выгоду (это, кстати, называется Uplift Modeling или, если вы больше привыкли к терминологии SAS — Incremental Response Modeling).
И ещё раз: версия Starter полноценная с точки зрения аналитического функционала, а, значит, proof-of-concept вашей идеи для вашей компании можно сделать абсолютно бесплатно.
