
Мы довольно часто помогаем бизнесу заказчика переехать в «облако». Это совершенно нормальный запрос, и большая часть крупных компаний так или иначе переносит свои мощности. Около 80% случаев приходится на перенос уже виртуализированной инфраструктуры из «домашней» серверной в дата-центр, остальные 20% — это перенос прямо с железа (включая рабочие станции пользователей) в виртуальную среду плюс вынос самого вычислительного узла в «облако».
Давайте расскажу по шагам, как это происходит у нас. Начну с того, что редко кто переезжает сразу всеми сервисами. Обычно сначала уводят некритичные, смотрят пару месяцев, а потом уже переводят всё остальное.
Подготовка
Итак, первое, что делается, — это оценка мощностей и инфраструктуры. Про выбор гипервизора и технические детали можно прочитать вот тут.
По сути, нужно иметь список сервисов и знать, какие мощности под них нужны и какие понадобятся. Задача хорошего админа со стороны заказчика — составить точный список того, что переезжает. То есть «разлепить» сервисы до уровня, когда становится понятно, какой процесс для чего нужен и сколько ресурсов кушает.
Мы выделяем мощности с небольшим запасом.
Затем начинается оценка средств переезда — как правило, встают вопросы переноса данных и конвертации виртуальных машин в формат нужного гипервизора.
Затем, собственно, переезд части сервисов: сначала, как я говорил, уводятся некритичные. Чаще всего начинают с виртуалок пользователей либо, если речь о разработке, с тестовых сред. После пары месяцев прогона тестовых сред в новом «облаке» наступает очередь продакшна. Хотя были и обратные примеры — например, у нас один банк почти с нуля перенёс в наше «облако» тяжёлую базу данных (мы дали IaaS и помогли адаптироваться к нашему «облаку»). Им было очень нужно быстро переехать — не хватало их вычислительных ресурсов, и, взвесив все риски, они решили, что лучше так.
Но обычно всё проще. В зависимости от средств миграции планируем время, когда будет перемещение сервисов. Проще всего и дешевле всего делать это с даунтаймом хотя бы в 4–6 часов, сложнее — если нужна полная доступность сервиса во время переезда. Ещё бывают случаи, когда одновременно нужна и полная доступность сервиса, и каналы у заказчика медленные, не позволяют быстро перенести данные.
Переезд
Для офлайн-переездов чаще всего забирается информация с помощью продукта Clonezilla. Ещё более простой метод — выключение продуктива, загрузка в файловое хранилище всего образом (подробнее об этом тут), затем конвертация. Мы поддерживаем все типы виртуализации.
При необходимости переезда в онлайне чаще всего работаем так: ставим агенты Double-Take на обе стороны (откуда едем и куда едем, то есть на сервер заказчика и на виртуалку в «облаке»), плюс на управляющую машину. Дешевле всего переключиться с простоем в несколько минут, но у Вижна есть лицензия и на мгновенное переключение (она дороже на порядок). Был у нас случай с оракловой базой, там простой составил 2 секунды.
Можно переезжать средствами приложений — это когда мы делаем не образ операционки в целом, а непосредственно нужной части. Чаще всего речь про MS SQL, у него отличная «родная» репликация.
Дальше образ тащится через выделенный канал или VPN. Некоторые заказчики пробрасывают просто через большой Интернет. Как правило, если речь о переносе серверного узла в «облако», у заказчика есть свой канал прямо до провайдера. Если переносится «зоопарк» без виртуализации, дело иногда сложнее: приходится строить VPN-туннель или же выгружать образы на отчуждаемые носители. Вообще, часто обычный VPN у провайдеров ограничивается где-то до 20 Мбит чисто по особенностям технологии. Поэтому обязательно нужен провайдерский L2VPN, либо придётся таскать через Интернет на свой страх и риск. Или же нужен патчкорд до провайдера, чтобы делать обмен напрямую, но с шифрованием. Выделенные каналы — не проблема, связь «“облако” — физика» получают многие: мы спокойно соединяем железные сервера во Владивостоке с виртуальными у нас. VPN посредством «облака»: ничего специально не надо, есть как базовый сервис.
Есть случаи, когда данных реально много, и даже гигабитный канал на стороне заказчика не устраивает. Тогда можно выгрузить всё на жёсткий диск с продуктива, привезти к нам, загрузить в «облако». Один раз даже таскали ноутбук с огромным жёстким диском. Кстати, заехать ко всем провайдерам просто, главный вопрос заказчиков — как потом выехать, если понадобится. У нас точно так же без проблем: например, однажды от нас переезжал заказчик со своим S3-подобным хранилищем (точнее, с нашего S3-совместимого они тащили всё на свой узел из-за особенностей по тому, как оформили обработку персональных данных). Просто попросили выгрузить в S3 все виртуалки в VMDK. Прибыли с 2 жёсткими дисками по 2 Тб, подключились к серверу, скопировали образы. Мы можем в VMDK или другом формате спокойно отдать.
Ещё один метод естественного переезда — через бэкап и восстановление на новой площадке, если у заказчика хорошо поставлено резервное копирование или схемы аварийного восстановления.
Заказчик часто удивляется, что есть важность порядка миграции. Бывает так: когда начинается переезд, выясняется, что один из сервисов был нужен для работы другой службы. Поэтому всегда составляются схемы зависимостей, прорабатывается план миграции, что за чем.
Часто при переносе с железных платформ нужно делать ещё и апгрейд ОС исходных серверов — это тоже без проблем, но надо запланировать.
Особенности платформ
Довольно часто случается, что у заказчика в серверном узле одна платформа виртуализации, а переезд делается на другую по разным причинам. Особенно часто идёт миграция с VMware на KVM. Ключевой момент здесь в том, что для KVM есть два типа виртуализации. Первый и более производительный — virtio, для его работы требуются предустановленные драйвера. Во втором случае — legacy — менее производительный, когда используются IDE-диск и сетевой адаптер Intel E1000. Однако иногда этот тип виртуализации позволяет решить проблемы совместимости.
Дальше начинается квест с разным спектром гостевых операционок — 2003 и даже 2008 (она тоже была). Сложнее всего было с 2003, потому что не всё гладко вставало. В частности, обычно установка драйверов происходит на устройство, которое должно быть в операционной системе, но в случае миграции дрова ставятся ещё на машине, с которой идёт переезд на устройства, которых по факту нет. Чтобы при развёртывании всё сразу встало как надо. Это важно, потому что до запуска в облаке у такой машины нет сетевого адаптера, у виртуалки свой HDD и Ethernet. У машины в «облаке» свой драйвер HDD и своя сеть. В итоге в легаси-режиме ей прокидывается старый IDE-диск и адаптер. Но не во всех случаях это работало. В итоге пришли к тому, что с доставшими нас 2003-ми виндами решили выгружать снепшоты в промежуточное окружение (Proxmoxy), а там можно запустить виртуальную машину так, что у неё первый диск будет её «старый» IDE, а второй будет виртуальный, который винда увидит как существующее устройство. Вначале производилась в среде виртуализации Proxmox установка драйверов на ВМ для работы в KVM-плече, а уже затем ВМ выгружалась к нам в «облако». Потом виртуалка загружалась назад в «облако» и взлетала. Ещё была Убунта-8 лохматая, но даже она новее 2003-й винды. Самое весёлое — обновить эти ОС на стороне заказчика нельзя, например, на некоторых старых системах крутится «Консультант-Плюс» с купленной лицензией — это легаси, которое они вообще боятся трогать.
Следующая особенность — кластер. Если заказчик на своей площадке использовал, то при миграции в «облако» такая архитектура обычно требует переделки. Точнее, затащить классический кластер в «облако» — не самый рациональный подход. С этим всегда есть сложности: как перетащить? Само по себе кластерное ПО будет лишней прослойкой. Но из продуктива его часто нельзя выдернуть. Тут привлекаем экспертов по кластерам и думаем — чаще всего кластер убирается заранее на стороне заказчика, потому что тащить его за собой нет смысла.
Встают вопросы совместимости, часто — при переезде Cisco в KVM либо при переносе MikroTik. В целом оно заводится: Микротик не поддерживается напрямую в KVM, но у нас есть опыт его настройки. От нашего «облака» шли связки в Рязань, Казань и Подольск, где, собственно, стоял Микротик, который строил все туннели между производствами.
Часто у заказчиков есть ожидание, что «облако» само по себе заранее предполагает DR (потому что оно расположено в двух дата-центрах). Этого из коробки нет, и надо сразу проектировать инфраструктуру так, чтобы она могла переезжать. Мы стараемся помогать: оцениваем возможность переезда, даём советы. Зрелые заказчики к этому готовы, и они сразу таким возможностям радуются (благо их сервисы к этому готовы). И вовсе не обязательно это делать средствами гипервизора — можно настроить репликацию изнутри виртуальной машины.
Фактически мы поставляем заказчику ресурсы одного большого «облака», где он может выбрать три разные платформы: KVM-плечо для размещения одного куска инфраструктуры, «облачное» плечо на VMware (платформа Cisco Powered) для другого и MS-плечо на базе Hyper-V для третьего соответственно. Например, одному крупному банку очень хотелось завести у нас тестовую среду и скрестить её со своим железом, где крутился докер. Докеру на фиг не упала наша вебочка, но разработчикам очень понравилось API облака — у них своя самописная web-среда для всех тестовых площадок в разных дата-центрах. Подцепили наше API, дальше слияние докеров прошло отлично (спасибо возможностям и гибкости KVM, который позволяет очень многое докручивать). Ещё одна особенность: облачное плечо на Hyper-V мы специально проектировали для защиты ПДн. Такой подход накладывает ряд ограничений, и не любого заказчика с произвольными требованиями можно «приземлить» в облачное плечо Hyper-V.
Рабочие станции не тащатся как отдельные машины — часто переносится либо один образ и файлшара, либо заказчик ставит Цитрикс-ферму. В теории можно в «облако» принести свой сервак с такой фермой и поставить, но эта фича нужна редко. Две кнопочки — и вот уже можно копировать настройки для вашей железки. Плюс у нас хорошо можно совместить «облака», в том числе внутри дата-центра плечи на разных гипервизорах.
Часто бывают промахи по перформансу. Канал, диски — могли недооценить требования к машине. Например, часто на «железных» переездах те, кто привык работать без виртуализации, забывают, что нужно отдавать несколько процентов производительности на работу гипервизора. Если у кого-то на серваках были графические карты — у нас графических карт в «облаке» нет. Был конфуз: заказчик не прочитал спеку, и сделали виртуализацию для видеомонтажа, 32 ядра, 200 гигов оперативы. Но у нас эта машина шла как сервер «облака», и предполагалось, что она отдаёт рабочий стол только ради консолей (стояло ограничение на 1,5 FPS для такого обмена). Зато СХД с диким перформансом: можно выбирать количество операций на те или иные нужды, оплата по факту.
Ещё некоторые заказчики не знают об ограничениях в лицензировании продуктов, размещённых в «облаке». Например, виртуальные машины с ОС Windows лицензирует исключительно поставщик сервиса IaaS (как владелец физических серверов).
Часто при миграции всплывают сетевые ошибки, которым много лет. Например, при одном сложном переезде выяснилось, что MSS был неверно сконфигурирован — остался костыль с 2007 года, и его так в результате никто не трогал. Результат был в том, что RDP-сессии рвались.
Ещё есть особенность внешней адресации. Получается, что в Интернет машинки могут входить через NAT, есть статическая трансляция.
Один из заказчиков хотел иметь в «облаке» подсеть «белых» IP-адресов от определённого провайдера. Дабы сэкономить средства и время, мы придумали следующую схему:
- Строился VPN-туннель от маршрутизатора заказчика до «облака», но без указания AS КРОК.
- Так как заказчик является провайдером, он выделил необходимую себе подсеть «белых» IP-адресов.
- Трафик через VPN приходил на оборудование провайдера и через его собственную AS транслировался по BGP в Интернет.
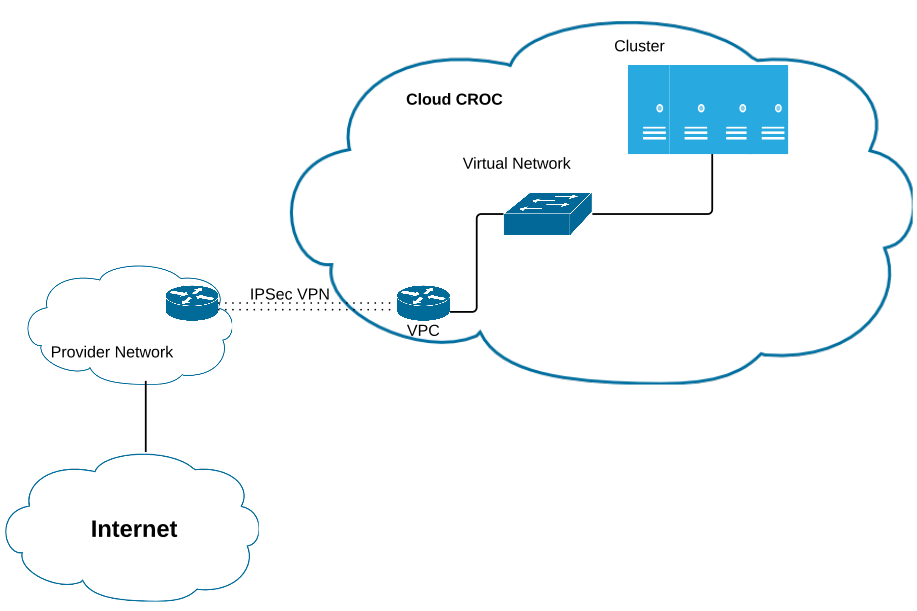
То есть просто через внешний свой сервак они транслировали адрес в Интернет, то есть ходили не через выход «облака», а через роутер на заводе. Их не напрягало, потому что канал позволял.
Вот примерно так. Почитать ещё про «облака» можно здесь:
