
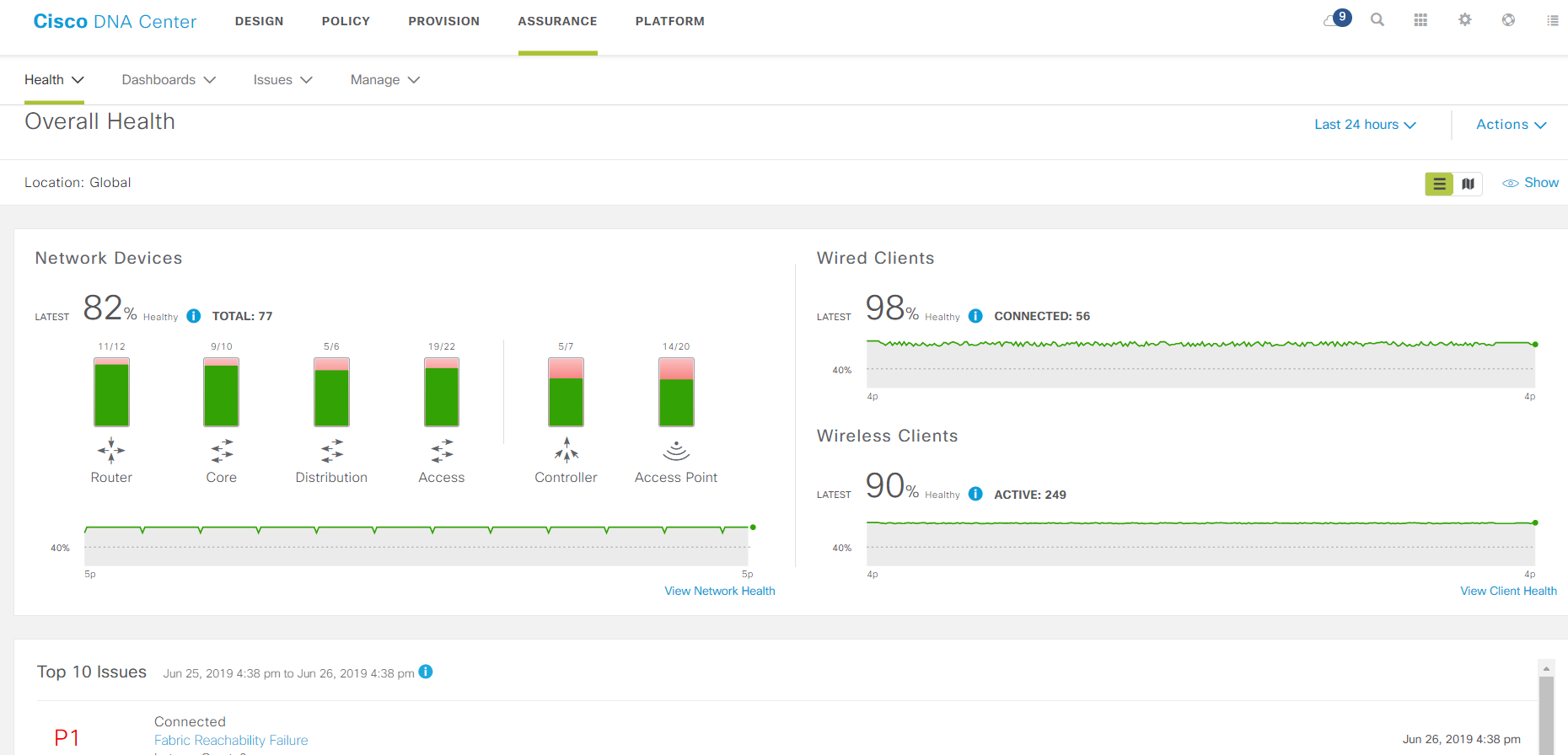
Основная страница мониторинга.
SD-Access — это реализация нового подхода к строительству локальных сетей от Cisco. Сетевые устройства объединяются в фабрику, поверх неё строится оверлей, и всем этим управляет центральный компонент — DNA Center. Выросло всё это из систем мониторинга сети, только теперь мутировавшая система мониторинга не просто мониторит, но собирает подробную телеметрию, конфигурирует всю сеть как единое устройство, находит в ней проблемы, предлагает их решения и вдобавок энфорсит политики безопасности.
Забегая вперёд, скажу, что решение довольно громоздкое и на данный момент нетривиальное в плане освоения, но чем больше сеть и чем важнее безопасность, тем выгоднее на него переходить: серьёзно упрощает управление и траблшутинг.
Предыстория – как мы на это решились?
Заказчик переезжал в новый свежекупленный офис из арендуемого. Локальную сеть планировали сделать по традиционной схеме: коммутаторы ядра, коммутаторы доступа плюс какой-нибудь привычный мониторинг. В это время мы как раз развернули стенд с SD-Access в нашей лаборатории и успели немного пощупать решение и пройти обучение с очень кстати посетившим Москву экспертом из французского офиса Cisco.
Пообщавшись с вендором, и мы, и заказчик решились-таки строить сеть по-новому. Увидели вот такие преимущества:
- SD-Access должен упростить операционную рутину — настройку портов и прав доступа для подключения пользователей. В новом решении эти настройки делаются с помощью визардов, а параметры портов задаются в очевидном виде в привязке к группам «Администраторы», «Бухгалтерия», «Принтеры», а не к VLAN и IP-подсетям. Понять проще, ошибиться сложнее. Для заказчика такое упрощение важно, потому что его центр ИТ-компетенции расположен в Сибири, а офис, который мы поднимали, — в Москве. Центр перегружен сложными задачами и работает по своему часовому поясу, поэтому, чем больше задач по обслуживанию сети смогут решать спецы на месте, тем больше времени у Центра для экспертной работы.
- Часть задач по траблшутингу сети, которыми раньше занимался Центр, благодаря новой архитектуре тоже смогут выполнить специалисты на месте. Для этого предусмотрены свои визарды и данные телеметрии и путей прохождения трафика в сети в понятном виде. При возникновении сложных проблем всё равно придётся покопаться в дебагах, но проблемы мелкие гораздо чаще решаются «на месте» с привлечением меньшего количества знаний.
- Заказчику важно обеспечить безопасность: идеология SD-Access предполагает чёткое разделение пользователей и устройств на группы и определение политик взаимодействия между ними, авторизацию при любом клиентском подключении к сети и обеспечение «прав доступа» по всей сети. IT-подразделение привыкает планировать и обслуживать сеть в духе этой идеологии. По-другому систему администрировать будет неудобно, если же следовать правильным подходам, то администрирование становится проще. В традиционной сети от такого подхода, наоборот, росли и усложнялись конфиги, а поддерживать их становилось труднее.
- Заказчику предстоит обновлять и другие офисы, разбросанные по стране. Если внедрять SD-Access и там, то сила предыдущих двух пунктов будет только повышаться.
- Процесс запуска для новых офисов тоже упрощён благодаря Plug-and-Play-агентам в коммутаторах. Бегать по кроссовым с консолью, а то и вообще выезжать на объект не нужно.
Недостатки мы увидели уже потом.
Планирование
Прикинули верхнеуровневый дизайн. Планируемая архитектура стала выглядеть так:
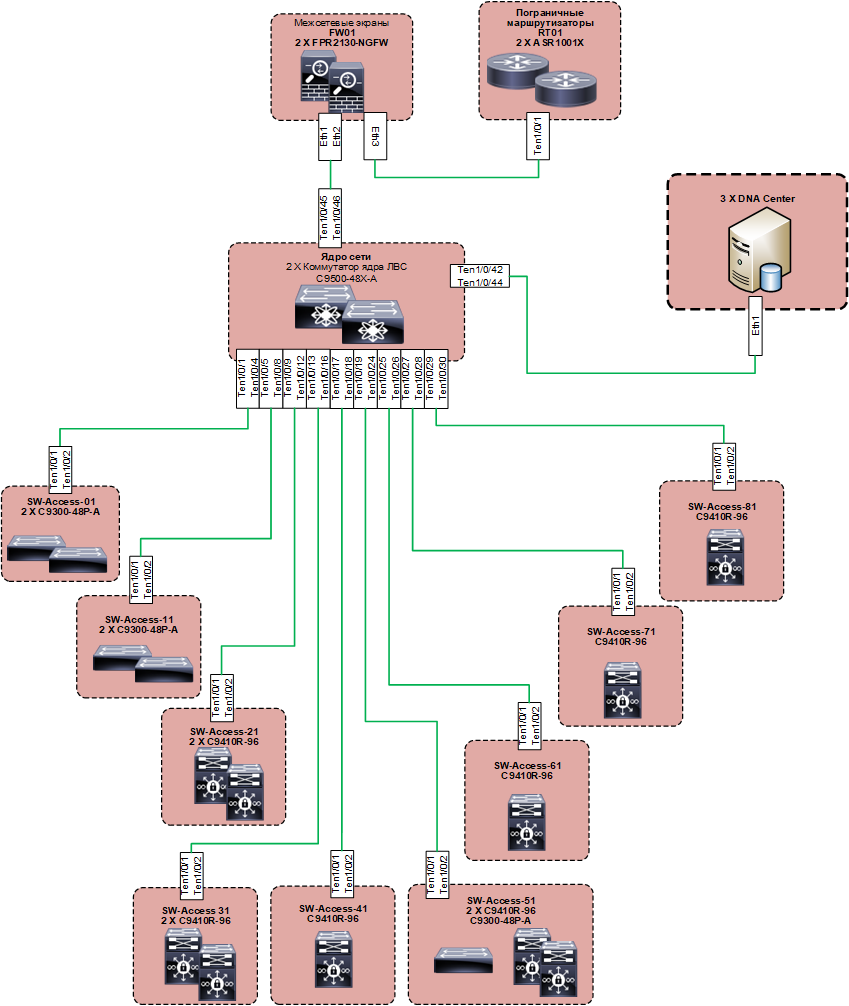
Внизу под этим — underlay, построенный на привычных протоколах (основа — IS-IS), но идея решения такова, что тонкости его работы нас интересовать не должны. Overlay выполнен на LISP и VXLAN. Логикой решения предполагается предпочтительное использование 802.1x-авторизации на портах доступа. Впрочем, заказчик предполагал использовать её в обязательном порядке для всех изначально. Можно обойтись и без 802.1x и настраивать сеть почти «по старинке», тогда нужно настраивать пулы IP-адресов вручную, а потом опять же руками на каждом порту прописывать, к какому IP-пулу он принадлежит, причём сделать Copy-Paste, как раньше в командной строке, не получится, всё только через веб. При таком подходе плюсы решения превращаются в жирный минус. Такую схему можно применять только там, где это неизбежно, но не на всей сети. Применение прав доступа обеспечивается за счёт SGT-меток.
Заказали оборудование и софт, а пока всё ехало, стали «приземлять» дизайн, чтобы понять, что будем настраивать. Тут и столкнулись с первой сложностью: если раньше с заказчиком нужно было согласовать IP-подсети и набор номеров VLAN так, чтобы это встраивалось в принятые у него схемы, то теперь всё это нас не интересовало: нужно было понять, какие группы пользователей и устройств пользуются сетью, как взаимодействуют между собой и какими сетевыми сервисами пользуются. Непривычно и для нас, и для заказчика. Получить подобную информацию оказалось сложнее. На первый взгляд, именно от таких данных нужно было отталкиваться при проектировании сетей всегда, но на практике почти всегда закладывался стандартный набор VLAN, а потом реальность впихивалась в него в ходе эксплуатации мозолистыми руками админов. В парадигме SD-Access выбора нет: сеть строится «под бизнес».
Сроки сжимались, подъехало оборудование. Нужно было настраивать.
Как мы это внедряли
Процесс внедрения сети отличается от старых схем ещё больше, чем процесс планирования. Раньше инженер соединял устройства между собой, настраивал их одно за другим и получал один за другим работающие сегменты сети. С SD-Access процесс внедрения выглядит следующим образом:
- Соединить между собой все сетевые коммутаторы.
- Поднять все контроллеры DNA Center.
- Интегрировать их с ISE (через него происходит вся авторизация).
- С помощью DNA Center превратить сетевые коммутаторы в фабрику.
- Расписать роли коммутаторов в фабрике (Edge Node, Control Node, Border Node).
- Настроить на DNA Center группы оконечных устройств и пользователей сети и виртуальные сети.
- Настроить правила взаимодействия между ними.
- Задеплоить группы устройств и правила на фабрику.
Это в первый раз. Причём DNA Center для первичного развёртывания требует DNS, NTP и доступ в облако Cisco для скачивания обновлений (со Smart Account). На нашем внедрении выяснилось, что обновляться при первичной установке DNA Center очень любит: доведение всех его компонентов до актуальных версий заняло около двух дней, хоть и происходило в основном без нашего участия.
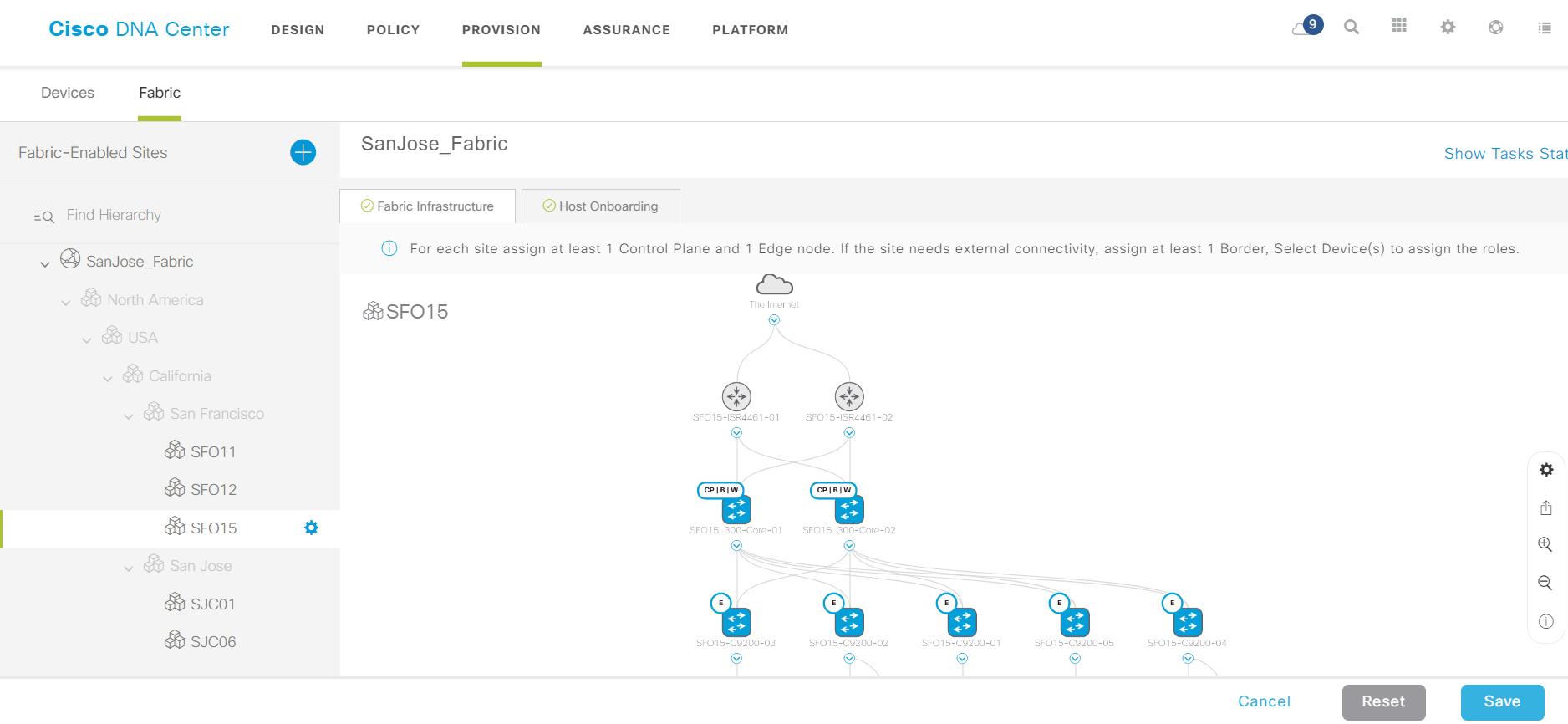
Пример собранной фабрики.
Когда же DNA Center уже работает, чтобы поднять новый офис, достаточно повторить пункты 1, 4, 5 и 8. Новые коммутаторы благодаря Plug-and-Play Agent получают адреса DNA Center по DHCP (опцией), берут оттуда предварительные конфиги и становятся видны в интерфейсе управления DNA Center. Остаётся расписать их роли (Egde/Control/Border), и новая фабрика готова. Группы устройств и политики на ней можно использовать старые.
Конечно, когда сталкиваешься с таким процессом впервые, сложно понять, с какой стороны к нему подойти. Вдобавок вместе с парадигмой SD-Access и соответствующими продуктами Cisco породила такое количество новых терминов и определений, что даст возможность даже бывалому CCIE снова почувствовать себя юным. Вот основные:
- Scalable Group — группы устройств со схожими правами доступа к сетевым ресурсам: те самые «Администраторы», «Бухгалтерия», «Принтеры» и т. д.
- Virtual Network — изолированный L2-L3-сегмент, в который входят группы устройств. По сути, VRF. Предполагается, что связь между такими сегментами будет происходить через межсетевой экран. Имеет смысл разбивать группы по таким виртуальным сетям в тех случаях, когда необходимо максимальное разграничение доступа, например, можно выделить три разных Virtual Network для системы видеонаблюдения, сотрудников офиса и его гостей.
- Access Control Contract — правила сетевого взаимодействия между группами.
- Control Plane/Edge/Border/Intermediate Node — разные типы коммутаторов в фабрике DNA Center в зависимости от их функций: Edge Node — подключение пользователей; Control Plane Node — обеспечение отслеживания клиентских подключений, работы LISP Map-Server и Map-Resolve; Border Node — обеспечение связи с внешними сетями; Intermediate Node — промежуточные коммутаторы, аналог Distribution-уровня в традиционных сетях.
- Роль устройства в сети (Device Role) — то, как DNA Center представляет себе роль устройства в зависимости от того, какие подключения к нему видит: Access, Distribution, Core, Border Router или Unknown. Этот атрибут может пригодиться, например, при определении рекомендуемой версии IOS: можно назначить разные рекомендуемые версии для коммутаторов доступа и коммутаторов ядра, если серия коммутаторов одна и та же.
Вообще как следует обучиться концептам стоит и тем, кто внедряет, и тем, кто будет это эксплуатировать. От незнания внедренцы затянут сроки, а у админов потом упадут KPI. Так можно и без премий остаться. Ну а недоверие руководства заказчика к выбранному решению — проблемы вообще для всех.
С внедрением из-за того, что заказчику нужно было уже заезжать в новый офис, мы пошли по следующей схеме:
- Создали одну группу и одну виртуальную сеть на всех в режиме OpenAuth без принудительной авторизации, только логи подключений.
- Админы скоммутировали в сеть рабочие станции, принтеры и т. п., пользователи переехали в новый офис и начали работать.
- Далее выделялся один пользователь, который по логике должен принадлежать другой группе.
- Мы настраивали в DNA Center саму эту группу и политики её взаимодействия с другими группами.
- Перемещали пользователя в эту новую группу и включали для него режим ClosedAuth с авторизацией.
- Вместе со специалистами заказчика выявляли проблемы с доступом, возникавшие у пользователя, и корректировали настройки контрактов (политик взаимодействия его группы с остальными).
- Когда были уверены, что пользователь работает без проблем, перемещали в его группу остальных пользователей, которые должны были к ней принадлежать, и наблюдали за происходившим.
Далее пункты с 3-го по 7-й необходимо было повторять для новых групп до тех пор, пока все пользователи и устройства, подключаемые к сети, не окажутся в своих группах. При работе в режиме OpenAuth клиентское устройство делает попытку авторизации. При удачном исходе на порт, к которому оно подключено, применяются настройки, соответствующие группе, к которой это устройство принадлежит, а при неудачном оно попадает в IP Pool, заранее настроенный на порту коммутатора, — своего рода откат к традиционному режиму работы локальной сети.
Конечно, как и на любом новом продукте, немало часов мы провели, обновляя софты и выявляя баги. К счастью, Cisco TAC помогал в этом оперативно. Однажды с утра, зайдя в веб-интерфейс DNA Center, обнаружили, что вся сеть лежит. При этом ни одной жалобы от пользователей: офис работает, попивая утренний кофе. Покопались в логах, и выяснилось, что возникла проблема с SNMP, по которому DNA Center получает информацию о состоянии фабрики. Сети не видно, а она есть. Помогло исключение части OID из поллинга.
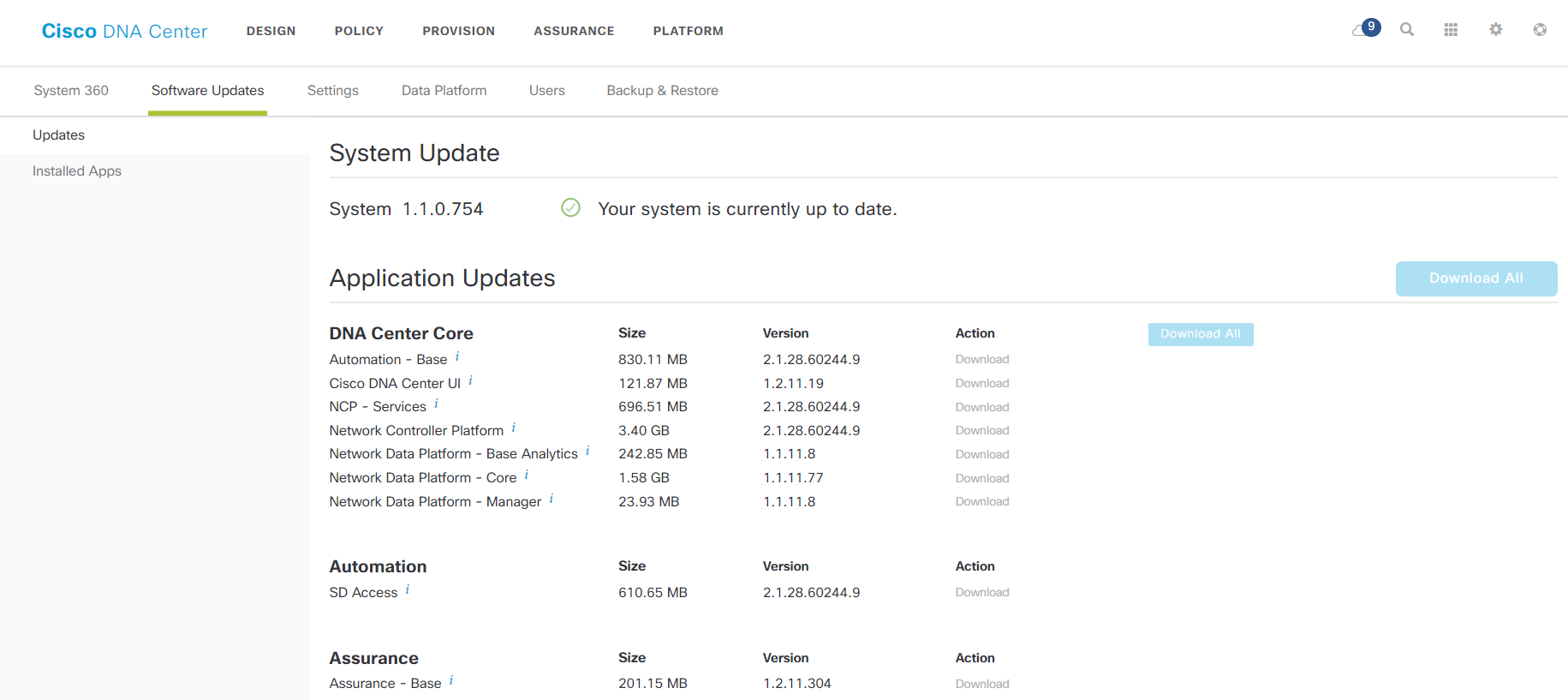
Страничка с версиями компонентов.
Как это эксплуатировать?
DNA Center собирает с фабрики кучу полезных данных по SNMP, Netflow и Syslog и умеет их представлять в понятном виде. Это особенно полезно при решении плавающих проблем вроде «что-то вчера у многих телефония отваливалась, хотя сейчас вроде нормально». Можно полазать в данных Application Experience и попытаться понять, что происходило. Так есть шанс устранить проблему до того, как «прилетит» в следующий раз. Или доказать, что сеть была ни при чём.
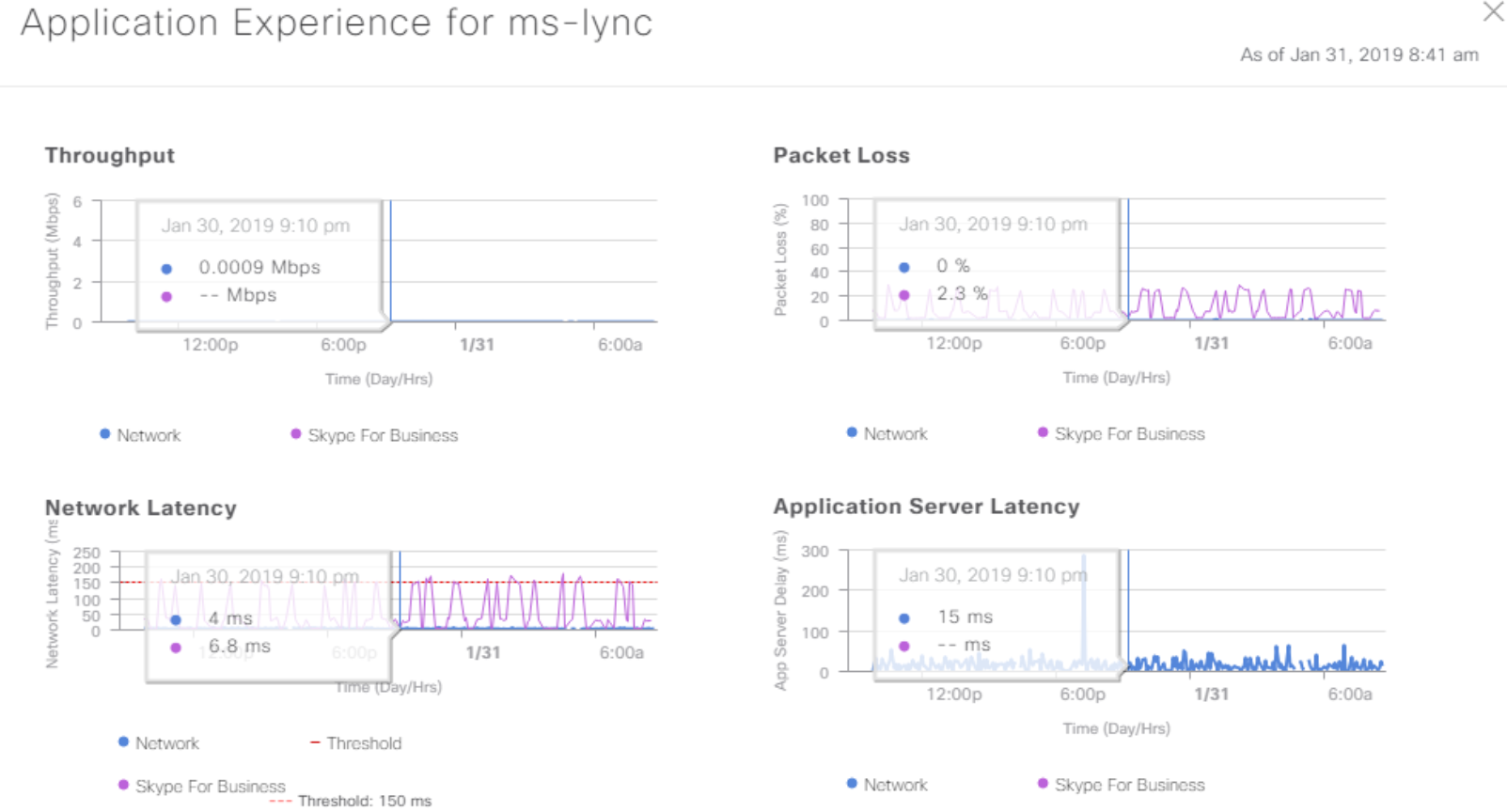
Данные о качестве работы приложения.
Для многих проблем, которые DNA Center показывает как Alarm, он подсказывает, «куда копать».
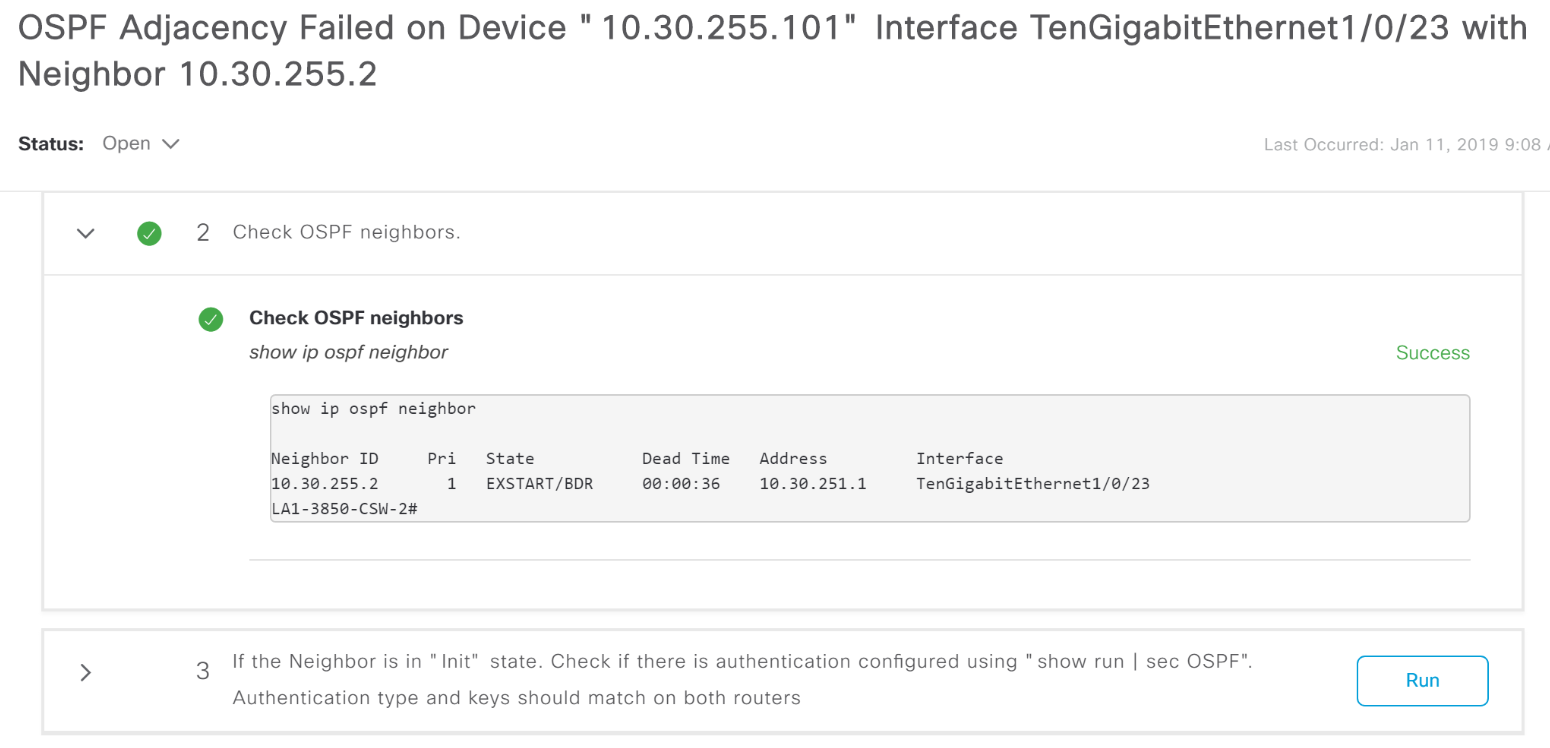
Пример сообщения о падении OSFP Adjacency с подсказкой, что делать.
Легче стало проводить рутинный анализ. Например, при необходимости можно быстро отследить путь трафика по сети, не лазая на устройства одно за одним. С авторизацией через ISE DNA Center подхватывает и показывает имена клиентов, в том числе и на проводной сети: не нужно лазать в поисках IP-адреса.

Пример отслеживания пути трафика через сеть. Красная метка на одном из устройств говорит, что трафик заблокирован на нём списком контроля доступа.
Можно быстро увидеть, какой сегмент сети охвачен проблемой (коммутаторы в DNA Center разбиваются по локациям, площадкам и этажам).
«Геймифицированный» показатель качества жизни приложений в сети в процентах позволяет поверхностно оценить состояние сети и видеть, не становится ли ей хуже со временем.
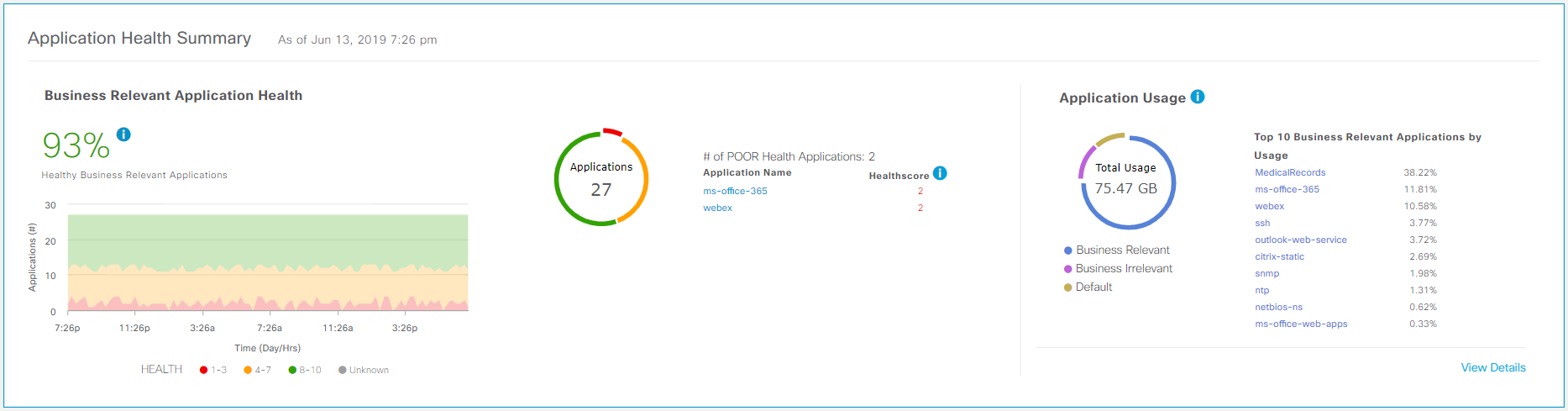
Показатель качества жизни приложений.
Как и раньше в Prime Infrastructure, предусмотрено также управление версиями ПО на сетевых устройствах. DNA Center держит свой репозиторий, куда образы можно заливать как вручную, так и автоматически подкачивать с Cisco.com, а потом деплоить на устройства. При этом можно программировать и запускать скрипты для проверки корректности работы сети до и после обновления. Стандартный пречек-скрипт, к примеру, включает в себя проверку доступности свободного места на флеше, состояние confi-register, сохранён ли конфиг. Поддерживается и патчинг ПО для тех устройств, которые это умеют.

Репозиторий ПО на DNA Center.
Ну и, конечно, доступ к командной строке сетевых железок по-прежнему есть.
Итог
Продукт новый, подходы новые внедрять можно, правда, осторожно. Из-за новизны кода встречаются баги в работе, но техподдержка Cisco реагирует оперативно, а девелоперы выпускают обновления регулярно. Из-за новизны подхода к управлению сетью вероятность ошибок на ранних этапах эксплуатации довольно высока, но постепенно админы привыкают, и ошибок становится меньше, чем при поддержке традиционной ЛВС. Стоит заранее подумать о том, как оттестировать и обкатать всё на части пользователей, а потом распространить на всех (хотя с опытом понимаешь, что это полезно при внедрении любых ИТ-решений, даже самых понятных и проверенных).
В чем польза? Автоматизация, ускорение типовых операций, снижение простоев из-за ошибок конфигурации, повышение надежности работы сети благодаря тому, что причины неисправности в сети известны мгновенно. По оценке Cisco, ИТ администратор сэкономит 90 дней в году. Отдельно безопасность: при Zero Trust-подходе эпической проблемы с последующим попаданием в прессу можно избежать, но это, по понятным причинам, мало кто оценивает.
