
Приходит как-то на завод специалист по цифровизации. Здесь походил, там походил, лоб наморщил и говорит: «Я знаю, как у вас тут можно кое-что оптимизировать. Экономить конкретно будете! Дайте только мне доступ во-о-от к этим данным по производству». В ответ на заводе разводят руки. «Вот у нас по продажам аналитика. Вот по турбинам что-то есть — шибко умные турбины у Siemens. А по остальному оборудованию отродясь ничего не было».
Вы прочитали миниатюру о конфликте двух миров — промышленности и аналитики. Мы как раз из последнего, и вот как все выглядит для нас: с одной стороны — созданные для управления оборудованием и недоступные для простых смертных протоколы обмена данными с большим количеством цифр в названии. С другой — аналитические системы, красивая отчетность, удобные дэшборды и прочие приятности.

Не каждое производство дошло до высокого технологического уровня. Но помогать нужно всем. На фото кадр из х/ф «Завод».
В этом посте мы расскажем, как стараемся вылепить производству человеческое (по меркам простого дата-сайентиста) лицо — дать возможность бизнес-аналитикам обрабатывать промышленные данные и пользоваться красивой BI-отчетностью.
Недавно мы были в гостях у одной газоперерабатывающей компании. Компания большая, несколько заводов объединяет. Зашли в диспетчерскую. Оборудовано там все очень здорово: у каждого диспетчера по 6-8 мониторов, а на стенах огромные плазмы. Вот только содержимое этих плазм… оставляет желать лучшего. Странного вида карта, дурацкие стрелочки, поверх этого окошки из Windows, которые пережили страшные пытки и показывают какие-то цифры.
«Почему так вырвиглазно?» — спрашиваем мы. «Это лучшее, что можно выжать из наших промышленных систем» — слышим в ответ. Время реакции диспетчера на инцидент обычно не должно превышать 30 секунд, но с таким интерфейсом уложиться непросто. Никаким BI здесь и не пахнет.
Еще одна неинтерфейсная история. Приходят на завод дата-сайентисты и говорят: «Дайте вот эти данные по вашей установке, и мы с 95%-ной точностью сможем прогнозировать проблемы в ней». Ну, по крайней мере, они так обещают. На заводе кивают, и для дата-сайентистов начинается сценарий в лучших традициях Кафки. Точечный сбор данных. По сотне систем. Для каждой нужно написать пять заявлений. Приложить личную биографию и родословную до пятого колена. Сдать все анализы, приложить их к эссе на свободную тему и подловить хорошее настроение начальника. И только тогда можно рассчитывать на успех. Точнее, надеяться.
Чтобы решить проблемы, подобные тем, что описаны выше, нужно подружить промышленность с аналитикой. Для этого мы строим единую систему с комплексной архитектурой. Такая система умеет работать с совершенно разными типами данных и на их основе решать аналитические задачи. Строим именно систему с комплексной архитектурой, а не что-то универсальное, потому что универсальные системы решают любые задачи одинаково плохо. В комплексной архитектуре мы объединяем инструменты аналитики разных типов данных. Вот как это может выглядеть:
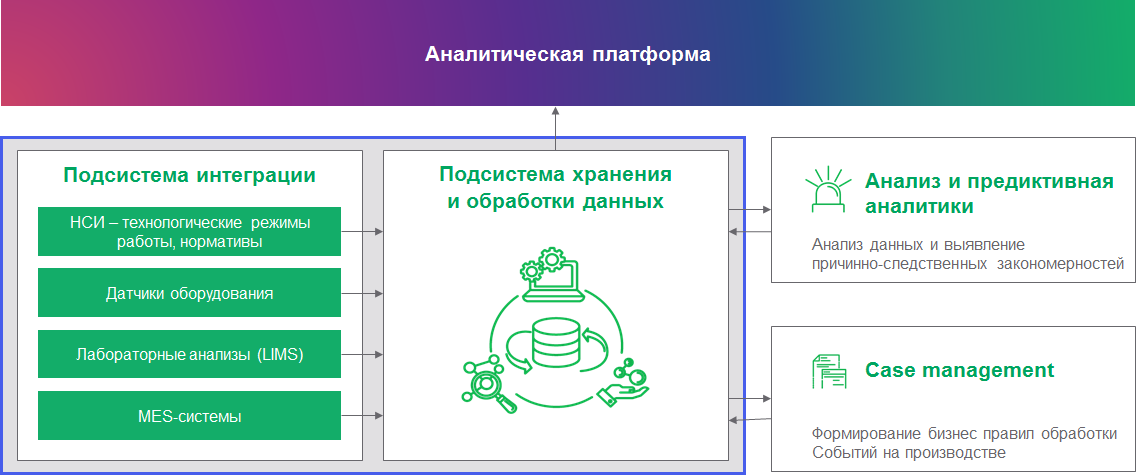
Типов данных на производстве немало. Есть классические реляционные данные из бизнес-систем и учетных систем. Есть данные с датчиков оборудования — временные ряды. Есть события из видеоаналитики — их складывают в даталэйк и делают по ним комплексный мониторинг (сейчас это популярная тема). Есть логи из бизнес-систем, которые нужно индексировать для последующей обработки (мы используем Apache Solr), чтобы получить реальную картину происходящего на производстве с учетом камер наблюдения и оценить, как операторы реагируют на те или иные события. И это еще не все, у каждого производства свое сочетание требований. А в итоге всю работу с данными стоит связать в рамках единой экосистемы, которая позволит собирать данные в централизованное хранилище с гибкой настройкой доступа и едиными инструментами анализа.
Недавно был у нас проект: организовать мониторинг технологического режима работы завода, а также качества сырья. Система мониторинга должна отслеживать в реальном времени все важные показатели и сверять их с нормативами по весьма оригинальным формулам. Из одной базы данных мы берем лабораторные анализы сырья, из другой — показатели работы оборудования.
В итоге оператор получает комплексную картину происходящего в его установке: на что нужно обратить внимание, стоит ли остановить работу и насколько все серьезно. По каждому отклонению от нормативной работы оператор должен зафиксировать причину сбоя. Таким образом, растет база знаний по случившимся инцидентам.
При этом вся аналитика отображается через красивую и удобную BI-систему. Она позволяет не только строить простую отчетность, но и создавать понятные и интуитивные информационные панели (дашборды). И это еще один аргумент, почему так важно подружить промышленные данные с аналитическими системами. По соображениям NDA мы не можем показать дашборды с этого проекта, но приведем для контраста публичные примеры подходов к визуализации BI систем и промышленных систем.
Вот как могут выглядеть отчеты BI:

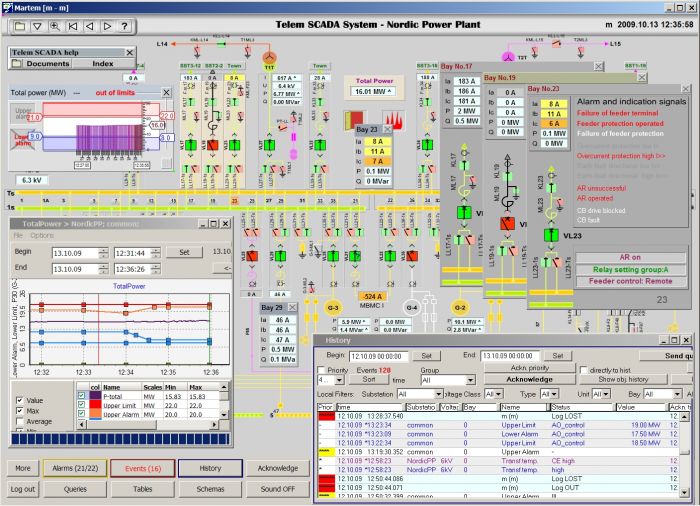
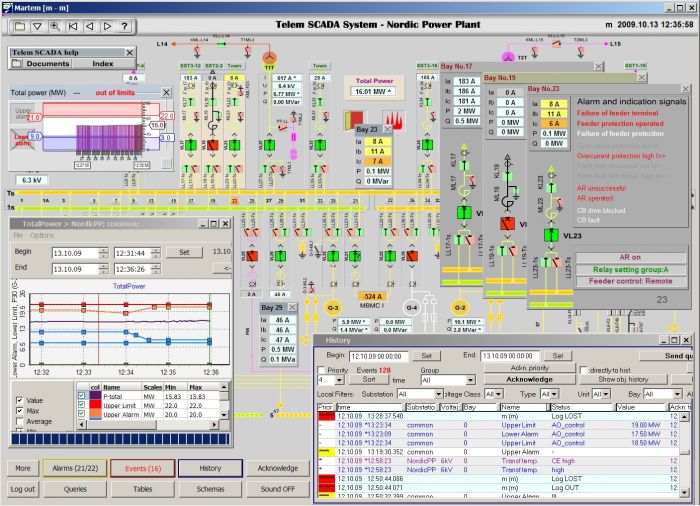
А вот интерфейс SCADA:
В рамках развития нашей платформы мы рассматриваем подключение средств предиктивной аналитики, которая выявляет причинно-следственные закономерности. Разные причины приводят к разным вариантам развития событий. Например, плохое качество сырья или неверная настройка оборудования после планового техобслуживания могут повлечь за собой снижение качества конечной продукции или выход оборудования из строя.
Одним из ключевых требований к системе аналитики является скорость получения информации. Это сбор телеметрии с датчиков и расчет показателей (план/факт агрегационнных показателей по цеху) в режиме near real-time. Это позволяет корректировать оперативное управление производством.
Примерно так все работает в дивном новом мире. Но в реальности есть нюансы.
Как свести данные промышленных систем (которые толком никто не собирает) в удобном для дата-аналитики виде? Один из стандартных протоколов для промышленных данных — OPC DA/HDA. Он вроде как является открытым, но доступ к его спецификации имеют только участники консорциума. Членство в консорциуме стоит дорого, а стабильных открытых реализаций этого протокола не существует.
Для того, чтобы связать этот и другие промышленные протоколы с современными системами аналитики, мы создаем для каждого протокола шлюзы. Этим занимается отдельная команда промышленных решений. Большое количество цифр в названиях протоколов их только вдохновляет. Команда имеет опыт написания промышленных коннекторов (например, по протоколу OPC DA/HDA, с использованием PI SDK и пр.).
А вот для связи промышленных протоколов с миром big data мы используем Apache NiFi — инструмент из экосистемы Hadoop, который позволяет реализовать интеграцию в потоковом режиме обработки.
Проложив этот самый важный мост между промышленностью и аналитическими системами, мы смогли решить задачу на привычном нам стеке Hadoop. В промышленных проектах мы чаще всего используем дистрибутивы нашего отечественного партнера Arenadata. С помощью Apache Phoenix мы выбираем данные по JDBC при помощи SQL. В последних версиях Phoenix был хорошо оптимизирован для работы с временными рядами, которые всегда появляются в промышленных проектах.
Мы смогли закрыть комплексную аналитическую систему продуктами одного вендора, что важно, когда речь заходит об enterprise-решениях. Для расчета уставок (отклонений в режимах работы оборудования), расчетных показателей и других KPI используется Apache Spark — компонент для выполнения распределенных вычислений в режиме near real-time в рамках экосистемы Hadoop.
Увы, с промышленными протоколами все сложно. В первый раз, когда мы планировали делать интеграцию с PI, то рассчитывали, что возьмем его стандартный JDBC-интерфейс и будет нам простое и быстрое счастье. А когда начали с интерфейсом работать, оказалось, что его пропускной способности недостаточно даже для того, чтобы грузить текущие данные. Не говоря уже о загрузке истории. Но у коннектора есть свой внутренний API SDK, который умеет быстро работать с данными. Так что мы написали на этом API специальный шлюз и решили проблему.
Мы подошли к решению этой задачи таким образом, чтобы в итоге получилось представление периодов отклонений в виде витрины. Для этого нужно было посчитать, сколько раз и когда показатели выходили за пределы нормы. Если анализировать всю историю в поисках отклонений, это потребует много ресурсов. Так что мы просто проходили по ряду значений, сравнивая каждое последующее и предыдущее. Если оба в норме/не в норме — отклонения нет/оно продолжается. Если одно из двух не в норме — засчитываем, соответственно, начало или конец отклонения. Так мы смогли сэкономить вычислительные мощности при создании витрины со статистикой для аналитиков и технологов.
Цель этих проектов в промышленности — не только сделать все красиво и понятно, но и подготовить аналитическую платформу для производства, перейти к цифровому предприятию, где есть возможность собирать и анализировать все события в одном месте.
Что касается описанной платформы, то она полезна сразу нескольким подразделениям. Мы решили задачу людей, которые управляют производством. Если раньше операторы могли не реагировать на незначительные отклонения в работе оборудования, то сейчас им приходится отчитываться перед руководством за каждое несоответствие норме. Это обеспечивает value в данный момент. Цифровизаторам и R&D-службам мы дали удобный источник информации о производстве, который позволяет анализировать любые события за любой промежуток времени — это обеспечит value в будущем.
Сейчас мы активно занимаемся развитием таких технологичных платформ, экспериментируем с реализацией. В общем, стремимся отодвинуть промышленность подальше от ручного управления к автоматизации контроля производства, как на заводах у Илона Маска.
Мы будем рады пообщаться со всеми — как с разработчиками и архитекторами big data (которых можем пригласить в нашу команду), так и с цифровизаторами, руководителями производства, рассказать им о нашем опыте и предложить варианты совместной работы. Для всех желающих мы проводим big data-митапы, на которых с радостью готовы обсудить все вопросы и предложения.
Моя почта — EOsipov@croc.ru
Вы прочитали миниатюру о конфликте двух миров — промышленности и аналитики. Мы как раз из последнего, и вот как все выглядит для нас: с одной стороны — созданные для управления оборудованием и недоступные для простых смертных протоколы обмена данными с большим количеством цифр в названии. С другой — аналитические системы, красивая отчетность, удобные дэшборды и прочие приятности.

Не каждое производство дошло до высокого технологического уровня. Но помогать нужно всем. На фото кадр из х/ф «Завод».
В этом посте мы расскажем, как стараемся вылепить производству человеческое (по меркам простого дата-сайентиста) лицо — дать возможность бизнес-аналитикам обрабатывать промышленные данные и пользоваться красивой BI-отчетностью.
Что мы имеем сейчас
Недавно мы были в гостях у одной газоперерабатывающей компании. Компания большая, несколько заводов объединяет. Зашли в диспетчерскую. Оборудовано там все очень здорово: у каждого диспетчера по 6-8 мониторов, а на стенах огромные плазмы. Вот только содержимое этих плазм… оставляет желать лучшего. Странного вида карта, дурацкие стрелочки, поверх этого окошки из Windows, которые пережили страшные пытки и показывают какие-то цифры.
«Почему так вырвиглазно?» — спрашиваем мы. «Это лучшее, что можно выжать из наших промышленных систем» — слышим в ответ. Время реакции диспетчера на инцидент обычно не должно превышать 30 секунд, но с таким интерфейсом уложиться непросто. Никаким BI здесь и не пахнет.
Еще одна неинтерфейсная история. Приходят на завод дата-сайентисты и говорят: «Дайте вот эти данные по вашей установке, и мы с 95%-ной точностью сможем прогнозировать проблемы в ней». Ну, по крайней мере, они так обещают. На заводе кивают, и для дата-сайентистов начинается сценарий в лучших традициях Кафки. Точечный сбор данных. По сотне систем. Для каждой нужно написать пять заявлений. Приложить личную биографию и родословную до пятого колена. Сдать все анализы, приложить их к эссе на свободную тему и подловить хорошее настроение начальника. И только тогда можно рассчитывать на успех. Точнее, надеяться.
Заводская аналитика
Чтобы решить проблемы, подобные тем, что описаны выше, нужно подружить промышленность с аналитикой. Для этого мы строим единую систему с комплексной архитектурой. Такая система умеет работать с совершенно разными типами данных и на их основе решать аналитические задачи. Строим именно систему с комплексной архитектурой, а не что-то универсальное, потому что универсальные системы решают любые задачи одинаково плохо. В комплексной архитектуре мы объединяем инструменты аналитики разных типов данных. Вот как это может выглядеть:
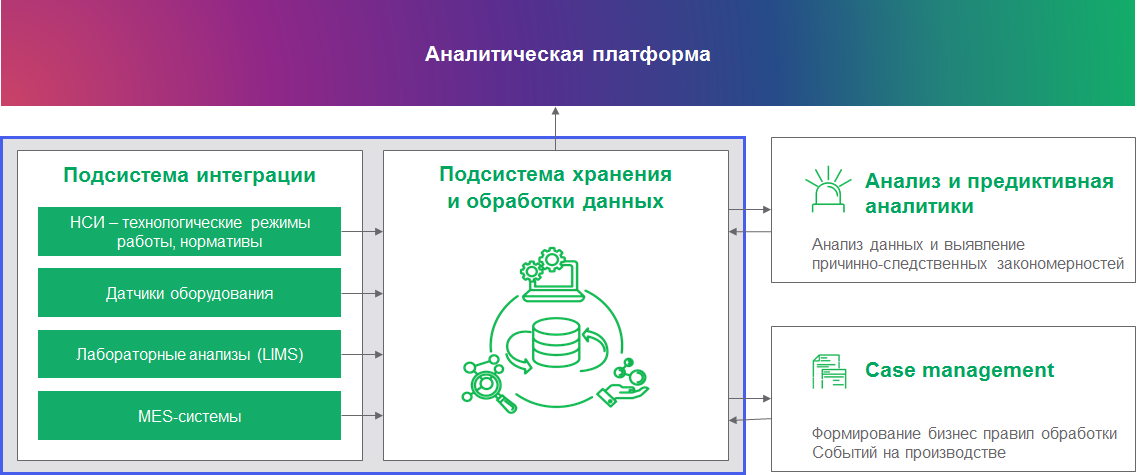
Типов данных на производстве немало. Есть классические реляционные данные из бизнес-систем и учетных систем. Есть данные с датчиков оборудования — временные ряды. Есть события из видеоаналитики — их складывают в даталэйк и делают по ним комплексный мониторинг (сейчас это популярная тема). Есть логи из бизнес-систем, которые нужно индексировать для последующей обработки (мы используем Apache Solr), чтобы получить реальную картину происходящего на производстве с учетом камер наблюдения и оценить, как операторы реагируют на те или иные события. И это еще не все, у каждого производства свое сочетание требований. А в итоге всю работу с данными стоит связать в рамках единой экосистемы, которая позволит собирать данные в централизованное хранилище с гибкой настройкой доступа и едиными инструментами анализа.
Недавно был у нас проект: организовать мониторинг технологического режима работы завода, а также качества сырья. Система мониторинга должна отслеживать в реальном времени все важные показатели и сверять их с нормативами по весьма оригинальным формулам. Из одной базы данных мы берем лабораторные анализы сырья, из другой — показатели работы оборудования.
В итоге оператор получает комплексную картину происходящего в его установке: на что нужно обратить внимание, стоит ли остановить работу и насколько все серьезно. По каждому отклонению от нормативной работы оператор должен зафиксировать причину сбоя. Таким образом, растет база знаний по случившимся инцидентам.
При этом вся аналитика отображается через красивую и удобную BI-систему. Она позволяет не только строить простую отчетность, но и создавать понятные и интуитивные информационные панели (дашборды). И это еще один аргумент, почему так важно подружить промышленные данные с аналитическими системами. По соображениям NDA мы не можем показать дашборды с этого проекта, но приведем для контраста публичные примеры подходов к визуализации BI систем и промышленных систем.
Вот как могут выглядеть отчеты BI:
А вот интерфейс SCADA:
В рамках развития нашей платформы мы рассматриваем подключение средств предиктивной аналитики, которая выявляет причинно-следственные закономерности. Разные причины приводят к разным вариантам развития событий. Например, плохое качество сырья или неверная настройка оборудования после планового техобслуживания могут повлечь за собой снижение качества конечной продукции или выход оборудования из строя.
Одним из ключевых требований к системе аналитики является скорость получения информации. Это сбор телеметрии с датчиков и расчет показателей (план/факт агрегационнных показателей по цеху) в режиме near real-time. Это позволяет корректировать оперативное управление производством.
Примерно так все работает в дивном новом мире. Но в реальности есть нюансы.
Анализ промышленных данных, или головная боль бизнес-аналитика на производстве
Как свести данные промышленных систем (которые толком никто не собирает) в удобном для дата-аналитики виде? Один из стандартных протоколов для промышленных данных — OPC DA/HDA. Он вроде как является открытым, но доступ к его спецификации имеют только участники консорциума. Членство в консорциуме стоит дорого, а стабильных открытых реализаций этого протокола не существует.
Для того, чтобы связать этот и другие промышленные протоколы с современными системами аналитики, мы создаем для каждого протокола шлюзы. Этим занимается отдельная команда промышленных решений. Большое количество цифр в названиях протоколов их только вдохновляет. Команда имеет опыт написания промышленных коннекторов (например, по протоколу OPC DA/HDA, с использованием PI SDK и пр.).
А вот для связи промышленных протоколов с миром big data мы используем Apache NiFi — инструмент из экосистемы Hadoop, который позволяет реализовать интеграцию в потоковом режиме обработки.
Проложив этот самый важный мост между промышленностью и аналитическими системами, мы смогли решить задачу на привычном нам стеке Hadoop. В промышленных проектах мы чаще всего используем дистрибутивы нашего отечественного партнера Arenadata. С помощью Apache Phoenix мы выбираем данные по JDBC при помощи SQL. В последних версиях Phoenix был хорошо оптимизирован для работы с временными рядами, которые всегда появляются в промышленных проектах.
Мы смогли закрыть комплексную аналитическую систему продуктами одного вендора, что важно, когда речь заходит об enterprise-решениях. Для расчета уставок (отклонений в режимах работы оборудования), расчетных показателей и других KPI используется Apache Spark — компонент для выполнения распределенных вычислений в режиме near real-time в рамках экосистемы Hadoop.
Нюансы
Увы, с промышленными протоколами все сложно. В первый раз, когда мы планировали делать интеграцию с PI, то рассчитывали, что возьмем его стандартный JDBC-интерфейс и будет нам простое и быстрое счастье. А когда начали с интерфейсом работать, оказалось, что его пропускной способности недостаточно даже для того, чтобы грузить текущие данные. Не говоря уже о загрузке истории. Но у коннектора есть свой внутренний API SDK, который умеет быстро работать с данными. Так что мы написали на этом API специальный шлюз и решили проблему.
Мы подошли к решению этой задачи таким образом, чтобы в итоге получилось представление периодов отклонений в виде витрины. Для этого нужно было посчитать, сколько раз и когда показатели выходили за пределы нормы. Если анализировать всю историю в поисках отклонений, это потребует много ресурсов. Так что мы просто проходили по ряду значений, сравнивая каждое последующее и предыдущее. Если оба в норме/не в норме — отклонения нет/оно продолжается. Если одно из двух не в норме — засчитываем, соответственно, начало или конец отклонения. Так мы смогли сэкономить вычислительные мощности при создании витрины со статистикой для аналитиков и технологов.
Перспективы
Цель этих проектов в промышленности — не только сделать все красиво и понятно, но и подготовить аналитическую платформу для производства, перейти к цифровому предприятию, где есть возможность собирать и анализировать все события в одном месте.
Что касается описанной платформы, то она полезна сразу нескольким подразделениям. Мы решили задачу людей, которые управляют производством. Если раньше операторы могли не реагировать на незначительные отклонения в работе оборудования, то сейчас им приходится отчитываться перед руководством за каждое несоответствие норме. Это обеспечивает value в данный момент. Цифровизаторам и R&D-службам мы дали удобный источник информации о производстве, который позволяет анализировать любые события за любой промежуток времени — это обеспечит value в будущем.
Сейчас мы активно занимаемся развитием таких технологичных платформ, экспериментируем с реализацией. В общем, стремимся отодвинуть промышленность подальше от ручного управления к автоматизации контроля производства, как на заводах у Илона Маска.
Мы будем рады пообщаться со всеми — как с разработчиками и архитекторами big data (которых можем пригласить в нашу команду), так и с цифровизаторами, руководителями производства, рассказать им о нашем опыте и предложить варианты совместной работы. Для всех желающих мы проводим big data-митапы, на которых с радостью готовы обсудить все вопросы и предложения.
Моя почта — EOsipov@croc.ru
