
Наши турецкие клиенты попросили нас правильно настроить бэкап для дата-центра. Мы делаем подобные проекты в России, но именно здесь история была больше про исследование того, как лучше сделать.
Дано: есть локальное S3-хранилище, есть Veritas NetBackup, который обзавёлся новым расширенным функционалом по перемещению данных в объектные хранилища теперь уже с поддержкой дедупликации, и есть проблема со свободным местом в этом локальном хранилище.
Задача: сделать всё так, чтобы процесс хранения резервных копий был быстр и дешев.
Собственно, до этого в S3 всё складывалось просто файлами, причём это были полные слепки критичных машин дата-центра. То есть не так, чтобы очень оптимизированно, но зато всё работало на старте. Сейчас же пришло время разобраться и сделать правильно.
На картинке то, к чему мы пришли:

Как видно, первый бэкап делался медленно (70 Мб/с), а последующие бэкапы тех же систем — значительно быстрее.
Собственно, дальше чуть больше деталей про то, какие там особенности.
Заказчики хотят делать бекапы как можно чаще и хранить как можно дешевле. Дёшево хранить их лучше всего в объектных хранилищах типа S3, потому что они обходятся дешевле всего по цене обслуживания на Мегабайт из того, откуда можно накатить бэкап обратно в разумные сроки. Когда бэкапа много, это становится не очень дёшево, потому что большую часть хранилища занимают копии одних и тех же данных. В случае HaaS турецких коллег можно уплотнить хранение примерно на 80-90%. Понятное дело, что это относится именно к их специфике, но минимум на 50% дедупа я бы точно рассчитывал.
Для решения проблемы основные вендоры уже давно сделали гейтвеи на S3 Амазона. Все их методы совместимы с локальными S3, если они поддерживают API Амазона. В турецком ЦОДе бэкап делается в нашу S3, как и в T-III «Компрессоре» в России, поскольку такая схема работы хорошо себя показала у нас.
А наша S3 полностью совместима с методами бэкапа в Амазон S3. То есть все средства для бэкапа, которые поддерживают эти методы, позволяют копировать всё в подобное хранилище «из коробки».
В Veritas NetBackup сделали фичу CloudCatalyst:

То есть между машинами, которые надо бэкапить, и гейтвеем встал промежуточный Linux-сервер, через который проходит бэкапный трафик с агентов СРК и делается их дедупликация «налету» перед передачей их в S3. Если раньше там было 30 бэкапов по 20 Гб с компрессией, то теперь (из-за похожести машин) их стало по объёму на 90% меньше. Движок дедупликации используется тот же, что и при хранении на обычных дисках средствами Netbackup.
Вот что происходит до промежуточного сервера:
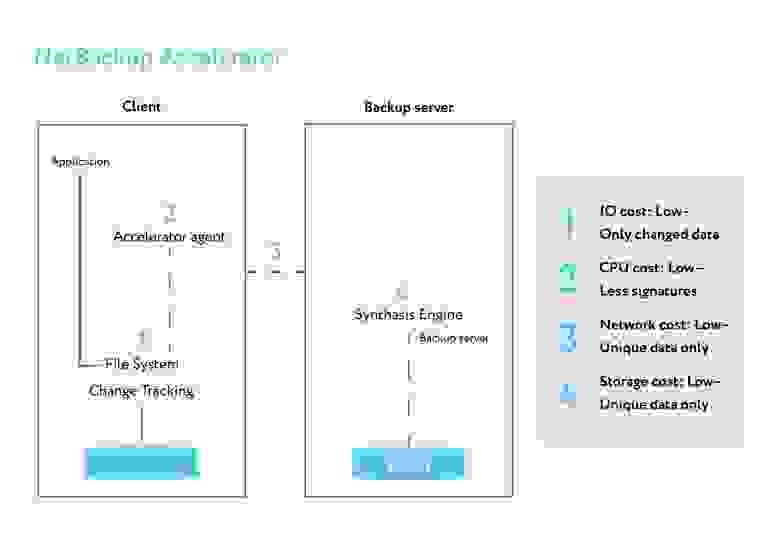
Мы протестировали и пришли к выводу, что при внедрении в наших ЦОДах это даёт экономию места в хранилищах S3 для нас и для заказчиков. Как владелец коммерческих ЦОДов, конечно, тарифицируем по занимаемому объёму, но всё равно это очень выгодно для нас тоже — потому что зарабатывать мы начинаем на более масштабируемых местах в софте, а не на аренде железа. Ну, и это сокращение внутренних издержек.
Акселератор позволяет уменьшить трафик с агентов, т.к. передаются только изменения данных, то есть даже полные бэкапы не льются целиком, поскольку медиа-сервер собирает последующие полные резервные копии из инкрементальных бэкапов.
Промежуточный сервер имеет своё хранилище, куда он пишет «кэш» данных и держит базу для дедупликации.
В полной архитектуре выглядит так:
Начинается всё с полного сканирования — это полноценный полный бекап. В этот момент медиа-сервер забирает всё, делает дедупликацию и передает в S3. Скорость до медиа-сервера низкая, от него — повыше. Главное ограничение — вычислительная мощность сервера.
Следующие бэкапы делаются с точки зрения всех систем полными, но на деле это что-то вроде синтетических полных бэкапов. То есть фактическая передача и запись на медиа-сервер идёт только тех блоков данных, которые ещё не встречались в резервных копиях ВМ раньше. А передача и запись в S3 идёт только тех блоков данных, хэша которых нет в базе дедупликации медиа-сервера. Если более простыми словами — что не встречалось ни в одном бэкапе ни одной ВМ раньше.
При ресторе медиа-сервер запрашивает нужные дедуплицированные объекты с S3, регидрирует их и передает агентам СРК, т.е. надо учитывать объем траффика при ресторе, который будет равен реальному объему восстанавливаемых данных.
Вот как это выглядит:

Целостность данных обеспечивается защитой самого S3 — там есть хорошая избыточность для защиты от аппаратных сбоев типа погибшего шпинделя жёсткого диска.
Медиа-серверу нужно 4 Тб кэша — это рекомендация Веритаса по минимальному объёму. Лучше больше, но мы делали именно так.
Когда партнёр кидал в наше S3 20 Гб, мы хранили 60 Гб, потому что обеспечиваем трёхкратное георезервирование данных. Сейчас трафика куда меньше, что хорошо и для канала, и для тарификации по хранению.
В данном случае маршруты закрыты мимо «большого Интернета», но можно гонять трафик и через VPN L2 через Интернет, но только медиа-сервер лучше ставить до провайдерского входа.
Если интересно узнать про эти фичи в наших российских ЦОДах или есть вопросы по реализации у себя — спрашивайте в комментариях или в почте ekorotkikh@croc.ru.
Дано: есть локальное S3-хранилище, есть Veritas NetBackup, который обзавёлся новым расширенным функционалом по перемещению данных в объектные хранилища теперь уже с поддержкой дедупликации, и есть проблема со свободным местом в этом локальном хранилище.
Задача: сделать всё так, чтобы процесс хранения резервных копий был быстр и дешев.
Собственно, до этого в S3 всё складывалось просто файлами, причём это были полные слепки критичных машин дата-центра. То есть не так, чтобы очень оптимизированно, но зато всё работало на старте. Сейчас же пришло время разобраться и сделать правильно.
На картинке то, к чему мы пришли:

Как видно, первый бэкап делался медленно (70 Мб/с), а последующие бэкапы тех же систем — значительно быстрее.
Собственно, дальше чуть больше деталей про то, какие там особенности.
Логи бэкапов для тех, кто готов читать полстраницы дампа
Full with rescan
Dec 18, 2018 12:09:43 PM — Info bpbkar (pid=4452) accelerator sent 14883996160 bytes out of 14883994624 bytes to server, optimization 0.0%
Dec 18, 2018 12:10:07 PM — Info NBCC (pid=23002) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats (multi-threaded stream used) for (NBCC): scanned: 14570817 KB, CR sent: 1760761 KB, CR sent over FC: 0 KB, dedup: 87.9%, cache disabled
Full
Dec 18, 2018 12:13:18 PM — Info bpbkar (pid=2864) accelerator sent 181675008 bytes out of 14884060160 bytes to server, optimization 98.8%
Dec 18, 2018 12:13:40 PM — Info NBCC (pid=23527) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats for (NBCC): scanned: 14569706 KB, CR sent: 45145 KB, CR sent over FC: 0 KB, dedup: 99.7%, cache disabled
Incremental
Dec 18, 2018 12:15:32 PM — Info bpbkar (pid=792) accelerator sent 9970688 bytes out of 14726108160 bytes to server, optimization 99.9%
Dec 18, 2018 12:15:53 PM — Info NBCC (pid=23656) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats for (NBCC): scanned: 14383788 KB, CR sent: 15700 KB, CR sent over FC: 0 KB, dedup: 99.9%, cache disabled
Full
Dec 18, 2018 12:18:02 PM — Info bpbkar (pid=3496) accelerator sent 171746816 bytes out of 14884093952 bytes to server, optimization 98.8%
Dec 18, 2018 12:18:24 PM — Info NBCC (pid=23878) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats for (NBCC): scanned: 14569739 KB, CR sent: 34120 KB, CR sent over FC: 0 KB, dedup: 99.8%, cache disabled
Dec 18, 2018 12:09:43 PM — Info bpbkar (pid=4452) accelerator sent 14883996160 bytes out of 14883994624 bytes to server, optimization 0.0%
Dec 18, 2018 12:10:07 PM — Info NBCC (pid=23002) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats (multi-threaded stream used) for (NBCC): scanned: 14570817 KB, CR sent: 1760761 KB, CR sent over FC: 0 KB, dedup: 87.9%, cache disabled
Full
Dec 18, 2018 12:13:18 PM — Info bpbkar (pid=2864) accelerator sent 181675008 bytes out of 14884060160 bytes to server, optimization 98.8%
Dec 18, 2018 12:13:40 PM — Info NBCC (pid=23527) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats for (NBCC): scanned: 14569706 KB, CR sent: 45145 KB, CR sent over FC: 0 KB, dedup: 99.7%, cache disabled
Incremental
Dec 18, 2018 12:15:32 PM — Info bpbkar (pid=792) accelerator sent 9970688 bytes out of 14726108160 bytes to server, optimization 99.9%
Dec 18, 2018 12:15:53 PM — Info NBCC (pid=23656) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats for (NBCC): scanned: 14383788 KB, CR sent: 15700 KB, CR sent over FC: 0 KB, dedup: 99.9%, cache disabled
Full
Dec 18, 2018 12:18:02 PM — Info bpbkar (pid=3496) accelerator sent 171746816 bytes out of 14884093952 bytes to server, optimization 98.8%
Dec 18, 2018 12:18:24 PM — Info NBCC (pid=23878) StorageServer=PureDisk_rhceph_rawd:s3.cloud.ngn.com.tr; Report=PDDO Stats for (NBCC): scanned: 14569739 KB, CR sent: 34120 KB, CR sent over FC: 0 KB, dedup: 99.8%, cache disabled
В чём проблема
Заказчики хотят делать бекапы как можно чаще и хранить как можно дешевле. Дёшево хранить их лучше всего в объектных хранилищах типа S3, потому что они обходятся дешевле всего по цене обслуживания на Мегабайт из того, откуда можно накатить бэкап обратно в разумные сроки. Когда бэкапа много, это становится не очень дёшево, потому что большую часть хранилища занимают копии одних и тех же данных. В случае HaaS турецких коллег можно уплотнить хранение примерно на 80-90%. Понятное дело, что это относится именно к их специфике, но минимум на 50% дедупа я бы точно рассчитывал.
Для решения проблемы основные вендоры уже давно сделали гейтвеи на S3 Амазона. Все их методы совместимы с локальными S3, если они поддерживают API Амазона. В турецком ЦОДе бэкап делается в нашу S3, как и в T-III «Компрессоре» в России, поскольку такая схема работы хорошо себя показала у нас.
А наша S3 полностью совместима с методами бэкапа в Амазон S3. То есть все средства для бэкапа, которые поддерживают эти методы, позволяют копировать всё в подобное хранилище «из коробки».
В Veritas NetBackup сделали фичу CloudCatalyst:

То есть между машинами, которые надо бэкапить, и гейтвеем встал промежуточный Linux-сервер, через который проходит бэкапный трафик с агентов СРК и делается их дедупликация «налету» перед передачей их в S3. Если раньше там было 30 бэкапов по 20 Гб с компрессией, то теперь (из-за похожести машин) их стало по объёму на 90% меньше. Движок дедупликации используется тот же, что и при хранении на обычных дисках средствами Netbackup.
Вот что происходит до промежуточного сервера:

Мы протестировали и пришли к выводу, что при внедрении в наших ЦОДах это даёт экономию места в хранилищах S3 для нас и для заказчиков. Как владелец коммерческих ЦОДов, конечно, тарифицируем по занимаемому объёму, но всё равно это очень выгодно для нас тоже — потому что зарабатывать мы начинаем на более масштабируемых местах в софте, а не на аренде железа. Ну, и это сокращение внутренних издержек.
Логи
228 Jobs (0 Queued 0 Active 0 Waiting for Retry 0 Suspended 0 Incomplete 228 Done — 13 selected)
(Filter Applied [13])
Job Id Type State State Details Status Job Policy Job Schedule Client Media Server Start Time Elapsed Time End Time Storage Unit Attempt Operation Kilobytes Files Pathname % Complete (Estimated) Job PID Owner Copy Parent Job ID KB/Sec Active Start Active Elapsed Robot Vault Profile Session ID Media to Eject Data Movement Off-Host Type Master Priority Deduplication Rate Transport Accelerator Optimization Instance or Database Share Host
— 1358 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:16:19 PM 00:02:18 Dec 18, 2018 12:18:37 PM STU_DP_S3_****backup 1 100% root 1358 Dec 18, 2018 12:16:27 PM 00:02:10 Instant Recovery Disk Standard WIN-*********** 0
1360 Backup Done 0 VMware Full NGNCloudADC NBCC Dec 18, 2018 12:16:48 PM 00:01:39 Dec 18, 2018 12:18:27 PM STU_DP_S3_****backup 1 14,535,248 149654 100% 23858 root 1358 335,098 Dec 18, 2018 12:16:48 PM 00:01:39 Instant Recovery Disk Standard WIN-*********** 0 99.8% 99%
1352 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:14:04 PM 00:02:01 Dec 18, 2018 12:16:05 PM STU_DP_S3_****backup 1 100% root 1352 Dec 18, 2018 12:14:14 PM 00:01:51 Instant Recovery Disk Standard WIN-*********** 0
1354 Backup Done 0 VMware Incremental NGNCloudADC NBCC Dec 18, 2018 12:14:34 PM 00:01:21 Dec 18, 2018 12:15:55 PM STU_DP_S3_****backup 1 14,380,965 147 100% 23617 root 1352 500,817 Dec 18, 2018 12:14:34 PM 00:01:21 Instant Recovery Disk Standard WIN-*********** 0 99.9% 100%
1347 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:11:45 PM 00:02:08 Dec 18, 2018 12:13:53 PM STU_DP_S3_****backup 1 100% root 1347 Dec 18, 2018 12:11:45 PM 00:02:08 Instant Recovery Disk Standard WIN-*********** 0
1349 Backup Done 0 VMware Full NGNCloudADC NBCC Dec 18, 2018 12:12:02 PM 00:01:41 Dec 18, 2018 12:13:43 PM STU_DP_S3_****backup 1 14,535,215 149653 100% 23508 root 1347 316,319 Dec 18, 2018 12:12:02 PM 00:01:41 Instant Recovery Disk Standard WIN-*********** 0 99.7% 99%
1341 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:05:28 PM 00:04:53 Dec 18, 2018 12:10:21 PM STU_DP_S3_****backup 1 100% root 1341 Dec 18, 2018 12:05:28 PM 00:04:53 Instant Recovery Disk Standard WIN-*********** 0
1342 Backup Done 0 VMware Full_Rescan NGNCloudADC NBCC Dec 18, 2018 12:05:47 PM 00:04:24 Dec 18, 2018 12:10:11 PM STU_DP_S3_****backup 1 14,535,151 149653 100% 22999 root 1341 70,380 Dec 18, 2018 12:05:47 PM 00:04:24 Instant Recovery Disk Standard WIN-*********** 0 87.9% 0%
1339 Snapshot Done 150 VMware — NGNCloudADC NBCC Dec 18, 2018 11:05:46 AM 00:00:53 Dec 18, 2018 11:06:39 AM STU_DP_S3_****backup 1 100% root 1339 Dec 18, 2018 11:05:46 AM 00:00:53 Instant Recovery Disk Standard WIN-*********** 0
1327 Snapshot Done 0 VMware — *******.********.cloud NBCC Dec 17, 2018 12:54:42 PM 05:51:38 Dec 17, 2018 6:46:20 PM STU_DP_S3_****backup 1 100% root 1327 Dec 17, 2018 12:54:42 PM 05:51:38 Instant Recovery Disk Standard WIN-*********** 0
1328 Backup Done 0 VMware Full *******.********.cloud NBCC Dec 17, 2018 12:55:10 PM 05:29:21 Dec 17, 2018 6:24:31 PM STU_DP_S3_****backup 1 222,602,719 258932 100% 12856 root 1327 11,326 Dec 17, 2018 12:55:10 PM 05:29:21 Instant Recovery Disk Standard WIN-*********** 0 87.9% 0%
1136 Snapshot Done 0 VMware — *******.********.cloud NBCC Dec 14, 2018 4:48:22 PM 04:05:16 Dec 14, 2018 8:53:38 PM STU_DP_S3_****backup 1 100% root 1136 Dec 14, 2018 4:48:22 PM 04:05:16 Instant Recovery Disk Standard WIN-*********** 0
1140 Backup Done 0 VMware Full_Scan *******.********.cloud NBCC Dec 14, 2018 4:49:14 PM 03:49:58 Dec 14, 2018 8:39:12 PM STU_DP_S3_****backup 1 217,631,332 255465 100% 26438 root 1136 15,963 Dec 14, 2018 4:49:14 PM 03:49:58 Instant Recovery Disk Standard WIN-*********** 0 45.2% 0%
(Filter Applied [13])
Job Id Type State State Details Status Job Policy Job Schedule Client Media Server Start Time Elapsed Time End Time Storage Unit Attempt Operation Kilobytes Files Pathname % Complete (Estimated) Job PID Owner Copy Parent Job ID KB/Sec Active Start Active Elapsed Robot Vault Profile Session ID Media to Eject Data Movement Off-Host Type Master Priority Deduplication Rate Transport Accelerator Optimization Instance or Database Share Host
— 1358 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:16:19 PM 00:02:18 Dec 18, 2018 12:18:37 PM STU_DP_S3_****backup 1 100% root 1358 Dec 18, 2018 12:16:27 PM 00:02:10 Instant Recovery Disk Standard WIN-*********** 0
1360 Backup Done 0 VMware Full NGNCloudADC NBCC Dec 18, 2018 12:16:48 PM 00:01:39 Dec 18, 2018 12:18:27 PM STU_DP_S3_****backup 1 14,535,248 149654 100% 23858 root 1358 335,098 Dec 18, 2018 12:16:48 PM 00:01:39 Instant Recovery Disk Standard WIN-*********** 0 99.8% 99%
1352 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:14:04 PM 00:02:01 Dec 18, 2018 12:16:05 PM STU_DP_S3_****backup 1 100% root 1352 Dec 18, 2018 12:14:14 PM 00:01:51 Instant Recovery Disk Standard WIN-*********** 0
1354 Backup Done 0 VMware Incremental NGNCloudADC NBCC Dec 18, 2018 12:14:34 PM 00:01:21 Dec 18, 2018 12:15:55 PM STU_DP_S3_****backup 1 14,380,965 147 100% 23617 root 1352 500,817 Dec 18, 2018 12:14:34 PM 00:01:21 Instant Recovery Disk Standard WIN-*********** 0 99.9% 100%
1347 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:11:45 PM 00:02:08 Dec 18, 2018 12:13:53 PM STU_DP_S3_****backup 1 100% root 1347 Dec 18, 2018 12:11:45 PM 00:02:08 Instant Recovery Disk Standard WIN-*********** 0
1349 Backup Done 0 VMware Full NGNCloudADC NBCC Dec 18, 2018 12:12:02 PM 00:01:41 Dec 18, 2018 12:13:43 PM STU_DP_S3_****backup 1 14,535,215 149653 100% 23508 root 1347 316,319 Dec 18, 2018 12:12:02 PM 00:01:41 Instant Recovery Disk Standard WIN-*********** 0 99.7% 99%
1341 Snapshot Done 0 VMware — NGNCloudADC NBCC Dec 18, 2018 12:05:28 PM 00:04:53 Dec 18, 2018 12:10:21 PM STU_DP_S3_****backup 1 100% root 1341 Dec 18, 2018 12:05:28 PM 00:04:53 Instant Recovery Disk Standard WIN-*********** 0
1342 Backup Done 0 VMware Full_Rescan NGNCloudADC NBCC Dec 18, 2018 12:05:47 PM 00:04:24 Dec 18, 2018 12:10:11 PM STU_DP_S3_****backup 1 14,535,151 149653 100% 22999 root 1341 70,380 Dec 18, 2018 12:05:47 PM 00:04:24 Instant Recovery Disk Standard WIN-*********** 0 87.9% 0%
1339 Snapshot Done 150 VMware — NGNCloudADC NBCC Dec 18, 2018 11:05:46 AM 00:00:53 Dec 18, 2018 11:06:39 AM STU_DP_S3_****backup 1 100% root 1339 Dec 18, 2018 11:05:46 AM 00:00:53 Instant Recovery Disk Standard WIN-*********** 0
1327 Snapshot Done 0 VMware — *******.********.cloud NBCC Dec 17, 2018 12:54:42 PM 05:51:38 Dec 17, 2018 6:46:20 PM STU_DP_S3_****backup 1 100% root 1327 Dec 17, 2018 12:54:42 PM 05:51:38 Instant Recovery Disk Standard WIN-*********** 0
1328 Backup Done 0 VMware Full *******.********.cloud NBCC Dec 17, 2018 12:55:10 PM 05:29:21 Dec 17, 2018 6:24:31 PM STU_DP_S3_****backup 1 222,602,719 258932 100% 12856 root 1327 11,326 Dec 17, 2018 12:55:10 PM 05:29:21 Instant Recovery Disk Standard WIN-*********** 0 87.9% 0%
1136 Snapshot Done 0 VMware — *******.********.cloud NBCC Dec 14, 2018 4:48:22 PM 04:05:16 Dec 14, 2018 8:53:38 PM STU_DP_S3_****backup 1 100% root 1136 Dec 14, 2018 4:48:22 PM 04:05:16 Instant Recovery Disk Standard WIN-*********** 0
1140 Backup Done 0 VMware Full_Scan *******.********.cloud NBCC Dec 14, 2018 4:49:14 PM 03:49:58 Dec 14, 2018 8:39:12 PM STU_DP_S3_****backup 1 217,631,332 255465 100% 26438 root 1136 15,963 Dec 14, 2018 4:49:14 PM 03:49:58 Instant Recovery Disk Standard WIN-*********** 0 45.2% 0%
Акселератор позволяет уменьшить трафик с агентов, т.к. передаются только изменения данных, то есть даже полные бэкапы не льются целиком, поскольку медиа-сервер собирает последующие полные резервные копии из инкрементальных бэкапов.
Промежуточный сервер имеет своё хранилище, куда он пишет «кэш» данных и держит базу для дедупликации.
В полной архитектуре выглядит так:
- Мастер-сервер управляет конфигурацией, обновлениями и прочим и находится в облаке.
- Медиа-сервер (промежуточная *nix-машина) должен находиться наиболее близко к резервируемым системам в плане сетевой доступности. Здесь делается дедупликация бекапов со всех резервируемых машин.
- На резервируемых машинах есть агенты, которые в общем случае отправляют на медиа-сервер только то, чего нет в его хранилище.
Начинается всё с полного сканирования — это полноценный полный бекап. В этот момент медиа-сервер забирает всё, делает дедупликацию и передает в S3. Скорость до медиа-сервера низкая, от него — повыше. Главное ограничение — вычислительная мощность сервера.
Следующие бэкапы делаются с точки зрения всех систем полными, но на деле это что-то вроде синтетических полных бэкапов. То есть фактическая передача и запись на медиа-сервер идёт только тех блоков данных, которые ещё не встречались в резервных копиях ВМ раньше. А передача и запись в S3 идёт только тех блоков данных, хэша которых нет в базе дедупликации медиа-сервера. Если более простыми словами — что не встречалось ни в одном бэкапе ни одной ВМ раньше.
При ресторе медиа-сервер запрашивает нужные дедуплицированные объекты с S3, регидрирует их и передает агентам СРК, т.е. надо учитывать объем траффика при ресторе, который будет равен реальному объему восстанавливаемых данных.
Вот как это выглядит:

И вот ещё кусок логов
169 Jobs (0 Queued 0 Active 0 Waiting for Retry 0 Suspended 0 Incomplete 169 Done — 1 selected)
Job Id Type State State Details Status Job Policy Job Schedule Client Media Server Start Time Elapsed Time End Time Storage Unit Attempt Operation Kilobytes Files Pathname % Complete (Estimated) Job PID Owner Copy Parent Job ID KB/Sec Active Start Active Elapsed Robot Vault Profile Session ID Media to Eject Data Movement Off-Host Type Master Priority Deduplication Rate Transport Accelerator Optimization Instance or Database Share Host
— 1372 Restore Done 0 nbpr01 NBCC Dec 19, 2018 1:05:58 PM 00:04:32 Dec 19, 2018 1:10:30 PM 1 14,380,577 1 100% 8548 root 1372 70,567 Dec 19, 2018 1:06:00 PM 00:04:30 WIN-*********** 90000
Job Id Type State State Details Status Job Policy Job Schedule Client Media Server Start Time Elapsed Time End Time Storage Unit Attempt Operation Kilobytes Files Pathname % Complete (Estimated) Job PID Owner Copy Parent Job ID KB/Sec Active Start Active Elapsed Robot Vault Profile Session ID Media to Eject Data Movement Off-Host Type Master Priority Deduplication Rate Transport Accelerator Optimization Instance or Database Share Host
— 1372 Restore Done 0 nbpr01 NBCC Dec 19, 2018 1:05:58 PM 00:04:32 Dec 19, 2018 1:10:30 PM 1 14,380,577 1 100% 8548 root 1372 70,567 Dec 19, 2018 1:06:00 PM 00:04:30 WIN-*********** 90000
Целостность данных обеспечивается защитой самого S3 — там есть хорошая избыточность для защиты от аппаратных сбоев типа погибшего шпинделя жёсткого диска.
Медиа-серверу нужно 4 Тб кэша — это рекомендация Веритаса по минимальному объёму. Лучше больше, но мы делали именно так.
Итог
Когда партнёр кидал в наше S3 20 Гб, мы хранили 60 Гб, потому что обеспечиваем трёхкратное георезервирование данных. Сейчас трафика куда меньше, что хорошо и для канала, и для тарификации по хранению.
В данном случае маршруты закрыты мимо «большого Интернета», но можно гонять трафик и через VPN L2 через Интернет, но только медиа-сервер лучше ставить до провайдерского входа.
Если интересно узнать про эти фичи в наших российских ЦОДах или есть вопросы по реализации у себя — спрашивайте в комментариях или в почте ekorotkikh@croc.ru.
