Иногда нам необходимо импортировать очень большие данные в базу, которые порой достигают нескольких десятков гигабайтов. Мы проводим регулярные бэкапы, горячие бэкапы, в важных сервисах используем репликацию и Высокую Доступность. Чаще всего пользователи полагаются на встроенную функцию СУБД, используют ее без каких-либо изменений, ждут пока процесс импортирования закончится, а иногда и вовсе не дожидаются.
В этом блоге я хочу рассказать о разных способах импортирования данных в СУБД CUBRID, уточнив, какой из них более эффективен, и почему. Часть этих рекомендаций можно применить также и в других системах управления базами данных.
Итак, в CUBRID импортирование данных можно произвести, используя следующие инструменты.
Сначала я приведу результаты небольшого теста, чтобы Вы смогли увидеть общую картину и понять, почему определенные из вышеприведенных решений работают быстрее, чем другие. Затем я расскажу о рекомендациях, которые помогут Вам значительно ускорить процесс импортирования данных.
Для каждого из способов мы проведем тест на небольшом количестве данных (100,000 записей), чтобы понять, в каком направлении движется каждый из них. Тест будет проводиться на Windows 7 x86 с установленным CUBRID 8.4.0. Таким образом, мы будем использовать:
Также будут присутствовать следующие конфигурации.
CSQL — это инструмент для интерпретации и запуска SQL запросов в командной строке. По сравнению с CUBRID Manager CSQL намного легче и быстрее. Он может работать в двух режимах. Первый — это автономный режим, а второй — режим Клиент-сервер.
Более подробно об этих режимах можете узнать в мануале.
Пришло время создать базу для нашего теста. Мы можем сделать это в командной строке, запустив команду
Затем нам необходимо подключиться к этой базе, использую CSQL, и создать необходимые таблицы.
Так как мы всё приготовили, остается импортировать все данные, которые находятся в файле dbtest.sql.
Чтобы запустить CSQL в автономном режиме и считать все данные с файла, вводим следующую команду.
Чтобы запустить CSQL в режиме Клиент-сервер и считать все данные с файла, вводим следующую команду.
Для этого мы будем использовать ту же информацию о базе данных и ее схеме. Затем запустим следующий скрипт, чтобы ввести 100,000 записей.
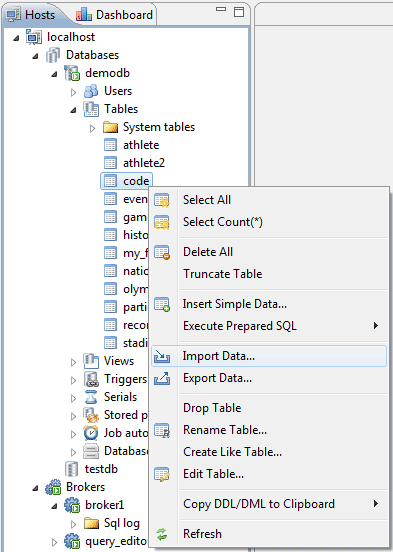
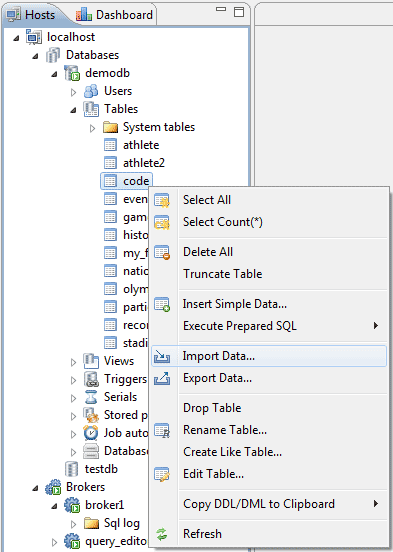
Здесь мы будем импортировать данные с того же файла, который мы создали в CSQL тесте. Используя функцию Import Data (см. скриншот ниже), мы импортируем все данные.
Следующие результаты теста показаны в секундах.

Как видно в вышеприведенном графике, CSQL в автономном режиме является самым быстрым способом импортирования данных в CUBRID. Причина этому является то, что он напрямую работает с файлами базы данных, минуя серверные процессы. В этом режиме CSQL ведет себя как сервер, а не как клиент подключенный к серверу. Поэтому этот инструмент импортирует данные быстрее всего.
Однако есть моменты, когда мы не можем использовать CSQL в автономном режиме, так как в этом режиме не допускается подключение более одного пользователя. Это означает, что CSQL должен быть единственным приложением, который работает с базой данных на тот момент. А это в свою очередь означает, что база данных должна быть отключена. Если база данных работает, это означает, что другой пользователь (хост) использует его. В таком случае попытка подключиться к базе с помощью CSQL в автономном режиме выдаст следующую ошибку.
В таких случаях Вам необходимо либо убедиться, что никто больше не подключен к базе данных, полностью отключив ее, либо использовать другие способы импортирования данных. Чтобы отключить базу в командной строке, введите команду
Это является одним из самых главных рекоммендаций разработчикам, которые планируют импортировать большие объемы данных.
Не создавайте никакие индексы до того, как Вы завершите импортирование всех данных. Это касается таких индексов, как:
Иначе каждый ввод данных (
В CUBRID есть два вида журналирования:
Журналирование на стороне клиента относится к параметру
Когда журналирование включено на стороне клиента, каждый SQL оператор, обработанный CAS (CUBRID Application Server), будет сохранен в логах СУБД. Соответственно, это увеличит общее время импортирования. Поэтому если Вам не нужны логи всего процесса импортирования (как, например, в режиме Высокой Доступности), то отключите его на время, пока импортирование не завершится.
Есть несколько способов отключения журналирования. Ниже покажу как это сделать в CUBRID Manager и в коммандной строке.
Пример в CM
Чтобы отключить журналирование (

В модальном окне укажите значение параметра

Чтобы окончательно применить изменения, необходимо перезапустить Брокер. Также нажимаем правой кнопкой мыши на Брокер и выбираем Broker Off для отключения, а затем Broker On, чтобы обратно запустить Брокер. Теперь можете запускать импортирование.
Пример в командной строке
В текстовом редакторе откройте cubrid_broker.conf, конфигурационный файл брокера, который находится в директории conf там, где Вы установили CUBRID. В этом файле Вы можете изменять значения всех параметров Брокера, влючая
Затем перезапустите Брокер в командной строке с помощью команды
Журналирование на стороне сервера относится параметру media_failure_support самого CUBRID Server, который определяет необходимость сохранять архивные логи в случае отказа в работе устройств хранения данных. Если значение данного параметра является yes, что и является значением по умолчанию, то все активные логи будут скопированы в архивные логи, когда активные логи заполнятся, и транзакция еще активна. Если же значение media_failure_support = no, то все архивные журналы, созданные после того, как активные журналы заполнились, будут автоматически удалены. Нужно заменить, что любые архивные логи будут сразу же удалены, если значение этого параметра измениться на no.
Таким образом, установив значение media_failure_support = no, можно сократить общее время импортирования данных. Чтобы изменить этот параметр, нажмите правой кнопкой на хост и выберите его свойства (Properties).

В модальном окне укажите значение параметра

Чтобы применить все изменения, перезапустите сервер.
Если Вы решили работать с CUBRID Manager для импортирования данных, обязательно укажите количество потоков, а также количество транзакций в одном коммите.
Потоки позволят CM использовать несколько параллельных соединений для осуществления INSERT запросов. Чтобы определить количество потоков, укажите их число в Thread count. Однако вы также должны помнить, что слишком большое количество ни к чему хорошему не приведет. Все зависит от возможности Вашего железа. Обычно мы рекомендуем от 5 до 10 потоков.

Также время импортирования зависит от количества транзакций в одном коммите (commit cycle). Это значение определяет, как часто должны введенные данные фиксироваться. Частая фиксация транзакций приведет к ухудшению производительности. Но с другой стороны редкая фиксация может потребовать много оперативной памяти. Поэтому опять же это зависит от конфигураций железа.
data_buffer_size является одним из важных параметров в оптимизации работы всего CUBRID сервера. Он определяет объем страниц данных, которые необходимо сохранить в кэш CUBRID сервера. Чем больше значение data_buffer_size, тем больше страниц данных можно хранить в буфере сервера, что позволяет значительно уменьшить количество I/O операций, значит и производительность в целом.
Но если значение этого параметра слишком велико, может быть осуществлен свопинг пула буфера между операционной системой и сервером в связи с отсутствием достаточного количества памяти, а если своп-диск не создан, то база данных (заметьте, не сервер, а сама база данных) вообще не запустится, так как просто напросто не хватит памяти. Поэтому, исходя из физического потенциала железа, рекомендуется настраивать значение параметра data_buffer_size равное примерно две трети размера системной памяти. По умолчанию data_buffer_size = 512M (мегабайт).
insert_execution_mode является очень полезным параметром, который позволяет запускать INSERT запросы на стороне сервера нежели на стороне клиента. Это полезно, когда на стороне клиента очень мало доступной памяти, или необходимо грязное чтение до ввода данные для периодического резервного копирования.
Параметр может принимать 7 значений (подробности смотрите в Database Server Parameters). По умолчанию значение insert_execution_mode = 1, что означает, что все запросы INSERT INTO… SELECT ... вида будут запускаться на стороне сервера. Так как при импортировании данных мы не используем данное строение запроса, нам необходимо изменить значение на 2, что позволит нам запускать все запросы в виде INSERT INTO… VALUES ... на стороне сервера (см. рисунок ниже).

Итак, чтобы уменьшить общее время импортирования и увеличить производительность CUBRID сервера, следуйте этим советам:
Что-то я пропустил? Напишите в комментариях о своем опыте и о том, как часто Вы импортируете данные.
В этом блоге я хочу рассказать о разных способах импортирования данных в СУБД CUBRID, уточнив, какой из них более эффективен, и почему. Часть этих рекомендаций можно применить также и в других системах управления базами данных.
Итак, в CUBRID импортирование данных можно произвести, используя следующие инструменты.
- Самый легкий способ — это использовать CUBRID Manager
- Также Вы можете использовать PHP, Java и другие драйвера
- Иначе можно использовать CSQL, CUBRID SQL интерпретатор в командной строке.
- Можно также настроить репликацию или Высокую Доступность, но это за рамками этой статьи.
Сначала я приведу результаты небольшого теста, чтобы Вы смогли увидеть общую картину и понять, почему определенные из вышеприведенных решений работают быстрее, чем другие. Затем я расскажу о рекомендациях, которые помогут Вам значительно ускорить процесс импортирования данных.
О тесте
Для каждого из способов мы проведем тест на небольшом количестве данных (100,000 записей), чтобы понять, в каком направлении движется каждый из них. Тест будет проводиться на Windows 7 x86 с установленным CUBRID 8.4.0. Таким образом, мы будем использовать:
- CSQL
-S автономный режим (Stand-alone mode)
-C режим клиент-сервер (Client-server mode)
- CUBRID Manager
- PHP API
Также будут присутствовать следующие конфигурации.
- Фиксация транзакций будет каждые 5000 раз (Commit cycle)
- Мы будем измерять только время запуска INSERT запросов, поэтому база и необходимые таблицы будут созданы заранее.
Сценарий теста
Запуск CSQL в командной строке (режимы -S и -C)
CSQL — это инструмент для интерпретации и запуска SQL запросов в командной строке. По сравнению с CUBRID Manager CSQL намного легче и быстрее. Он может работать в двух режимах. Первый — это автономный режим, а второй — режим Клиент-сервер.
- В автономном режиме CSQL напрямую работает с файлами базы данных и обрабатывает все запросы и серверные комманды. Иначе говоря, запросы могут быть обработаны, минуя сервер. Однако, в связи с тем, что в автономном режиме допускается только один активный пользователь, в нем можно работать только для выполнения административных задач.
- В режиме Клиент сервер CSQL работает, как клиент, и как обычный клиент, он посылает все запросы для обработки серверу.
Более подробно об этих режимах можете узнать в мануале.
Пришло время создать базу для нашего теста. Мы можем сделать это в командной строке, запустив команду
cubrid createdb dbtest.Затем нам необходимо подключиться к этой базе, использую CSQL, и создать необходимые таблицы.
$> csql demodb
CUBRID SQL Interpreter
Type `;help' for help messages.
csql> CREATE TABLE test1(a int, b TIMESTAMP, c int AUTO_INCREMENT)
csql> ;ru
Current transaction has been committed.
1 command(s) successfully processed.
csql> ;ex- В CSQL команда ;ru означает «запустить введенные запросы» (run).
- Команда ;ex — выход (exit). О всех возможных командах можете узнать здесь.
Так как мы всё приготовили, остается импортировать все данные, которые находятся в файле dbtest.sql.
INSERT INTO test1 VALUES (0 , SYS_TIMESTAMP, NULL);
INSERT INTO test2 VALUES (1 , SYS_TIMESTAMP, NULL);
……………………
INSERT INTO test1 VALUES (99998 , SYS_TIMESTAMP, NULL);
INSERT INTO test1 VALUES (99999 , SYS_TIMESTAMP, NULL);
Чтобы запустить CSQL в автономном режиме и считать все данные с файла, вводим следующую команду.
$> csql -u dba -p 1111 –S -i dbtest1.sql dbtestЧтобы запустить CSQL в режиме Клиент-сервер и считать все данные с файла, вводим следующую команду.
$> csql -u dba -p 1111 –C -i dbtest1.sql dbtestИмпорт в PHP
Для этого мы будем использовать ту же информацию о базе данных и ее схеме. Затем запустим следующий скрипт, чтобы ввести 100,000 записей.
$host_ip = "localhost";
$host_port = 33000;
$db_name = "dbtest";
$userId = "dba";
$password = "1111";
$cubrid_con = @cubrid_connect($host_ip, $host_port, $db_name, $userId, $password);
if($cubrid_con)
{
$sql = "insert into " . $db_name . " (a, b) values (?, SYS_TIMESTAMP)";
$reg = cubrid_prepare($cubrid_con, $sql, CUBRID_INCLUDE_OID);
// Insert 100,000 records in the loop.
for($i = 0; $i < 100000; ++$i)
{
$res = cubrid_bind($reg, 1, $i);
$res = cubrid_execute($reg);
// Commit once in 5,000 times (commit cycle).
if (($i+1) % 5000 == 0)
{
cubrid_commit($cubrid_con);
echo $i, "
";
}
}
}Импорт данных в CUBRID Manager
Здесь мы будем импортировать данные с того же файла, который мы создали в CSQL тесте. Используя функцию Import Data (см. скриншот ниже), мы импортируем все данные.
Результаты тестов
Следующие результаты теста показаны в секундах.
| 50,000 записей | 100,000 записей | 300,000 записей | |
|---|---|---|---|
| csql-S | 5 | 10 | 29 |
| csql-C | 111 | 224 | 599 |
| PHP | 68 | 136 | 413 |
| CM | 17 | 33 | 96 |

Заключение и рекомендации
Используйте CSQL в автономном режиме
Как видно в вышеприведенном графике, CSQL в автономном режиме является самым быстрым способом импортирования данных в CUBRID. Причина этому является то, что он напрямую работает с файлами базы данных, минуя серверные процессы. В этом режиме CSQL ведет себя как сервер, а не как клиент подключенный к серверу. Поэтому этот инструмент импортирует данные быстрее всего.
Однако есть моменты, когда мы не можем использовать CSQL в автономном режиме, так как в этом режиме не допускается подключение более одного пользователя. Это означает, что CSQL должен быть единственным приложением, который работает с базой данных на тот момент. А это в свою очередь означает, что база данных должна быть отключена. Если база данных работает, это означает, что другой пользователь (хост) использует его. В таком случае попытка подключиться к базе с помощью CSQL в автономном режиме выдаст следующую ошибку.
$> csql -S demodb
ERROR: Unable to mount disk volume "C:CUBRIDdatabasesdemodbdemodb_lgat".
The database "C:CUBRIDDATABA~1demodbdemodb", to which the disk volume belongs,
is in use by user USER-PC$ on process 3096 of host user-PC since Thu Sep 22 11:04:01 2011.В таких случаях Вам необходимо либо убедиться, что никто больше не подключен к базе данных, полностью отключив ее, либо использовать другие способы импортирования данных. Чтобы отключить базу в командной строке, введите команду
cubrid server stop dbtest1.Создавайте любые CONSTRAINT после импортирования данных
Это является одним из самых главных рекоммендаций разработчикам, которые планируют импортировать большие объемы данных.
Не создавайте никакие индексы до того, как Вы завершите импортирование всех данных. Это касается таких индексов, как:
INDEX (обычный индекс), UNIQUE (уникальный индекс), REVERSE INDEX (обратный индекс), REVERSE UNIQUE (обратный уникальный индекс) и даже PRIMARY KEY (первичный ключ автоматически создаст обычный индекс).Иначе каждый ввод данных (
INSERT) во время процесса импортирования будет влечь за собой обязательную индексацию, что увелит общее время импортирования. Поэтому следуйте этим инструкциям:- Создайте таблицу.
- Добавьте все необходимые колонки и укажите их типы данных, но не указывайте никакие ограничения, даже первичный ключ.
- Импортируйте все данные.
- И только тогда создайте все необходимые индексы и первычные ключи.
Отключайте журналирование во время импортирования
В CUBRID есть два вида журналирования:
- Журналирование на стороне клиента
- Журналирование на стороне сервера
Журналирование на стороне клиента
Журналирование на стороне клиента относится к параметру
SQL_LOG в Брокере CUBRID. По умолчанию значение SQL_LOG = ON.Когда журналирование включено на стороне клиента, каждый SQL оператор, обработанный CAS (CUBRID Application Server), будет сохранен в логах СУБД. Соответственно, это увеличит общее время импортирования. Поэтому если Вам не нужны логи всего процесса импортирования (как, например, в режиме Высокой Доступности), то отключите его на время, пока импортирование не завершится.
Есть несколько способов отключения журналирования. Ниже покажу как это сделать в CUBRID Manager и в коммандной строке.
Пример в CM
Чтобы отключить журналирование (
SQL_LOG = OFF), нажмите правой кнопкой мыши на Брокер и выберите Properties (Свойства).
В модальном окне укажите значение параметра
SQL_LOG как OFF. Затем сохраните изменения, нажав на ОК.
Чтобы окончательно применить изменения, необходимо перезапустить Брокер. Также нажимаем правой кнопкой мыши на Брокер и выбираем Broker Off для отключения, а затем Broker On, чтобы обратно запустить Брокер. Теперь можете запускать импортирование.
Пример в командной строке
В текстовом редакторе откройте cubrid_broker.conf, конфигурационный файл брокера, который находится в директории conf там, где Вы установили CUBRID. В этом файле Вы можете изменять значения всех параметров Брокера, влючая
SQL_LOG. См. вырезку кода ниже.[broker]
...
SQL_LOG =OFF
...Затем перезапустите Брокер в командной строке с помощью команды
cubrid broker restart.Журналирование на стороне сервера
Журналирование на стороне сервера относится параметру media_failure_support самого CUBRID Server, который определяет необходимость сохранять архивные логи в случае отказа в работе устройств хранения данных. Если значение данного параметра является yes, что и является значением по умолчанию, то все активные логи будут скопированы в архивные логи, когда активные логи заполнятся, и транзакция еще активна. Если же значение media_failure_support = no, то все архивные журналы, созданные после того, как активные журналы заполнились, будут автоматически удалены. Нужно заменить, что любые архивные логи будут сразу же удалены, если значение этого параметра измениться на no.
Таким образом, установив значение media_failure_support = no, можно сократить общее время импортирования данных. Чтобы изменить этот параметр, нажмите правой кнопкой на хост и выберите его свойства (Properties).

В модальном окне укажите значение параметра
media_failure_support как no. Затем сохраните изменения, нажав на ОК.
Чтобы применить все изменения, перезапустите сервер.
Указывайте количество потоков и фиксаций транзакций
Если Вы решили работать с CUBRID Manager для импортирования данных, обязательно укажите количество потоков, а также количество транзакций в одном коммите.
Потоки позволят CM использовать несколько параллельных соединений для осуществления INSERT запросов. Чтобы определить количество потоков, укажите их число в Thread count. Однако вы также должны помнить, что слишком большое количество ни к чему хорошему не приведет. Все зависит от возможности Вашего железа. Обычно мы рекомендуем от 5 до 10 потоков.

Также время импортирования зависит от количества транзакций в одном коммите (commit cycle). Это значение определяет, как часто должны введенные данные фиксироваться. Частая фиксация транзакций приведет к ухудшению производительности. Но с другой стороны редкая фиксация может потребовать много оперативной памяти. Поэтому опять же это зависит от конфигураций железа.
Используйте data_buffer_size
data_buffer_size является одним из важных параметров в оптимизации работы всего CUBRID сервера. Он определяет объем страниц данных, которые необходимо сохранить в кэш CUBRID сервера. Чем больше значение data_buffer_size, тем больше страниц данных можно хранить в буфере сервера, что позволяет значительно уменьшить количество I/O операций, значит и производительность в целом.
Но если значение этого параметра слишком велико, может быть осуществлен свопинг пула буфера между операционной системой и сервером в связи с отсутствием достаточного количества памяти, а если своп-диск не создан, то база данных (заметьте, не сервер, а сама база данных) вообще не запустится, так как просто напросто не хватит памяти. Поэтому, исходя из физического потенциала железа, рекомендуется настраивать значение параметра data_buffer_size равное примерно две трети размера системной памяти. По умолчанию data_buffer_size = 512M (мегабайт).
Используйте insert_execution_mode
insert_execution_mode является очень полезным параметром, который позволяет запускать INSERT запросы на стороне сервера нежели на стороне клиента. Это полезно, когда на стороне клиента очень мало доступной памяти, или необходимо грязное чтение до ввода данные для периодического резервного копирования.
Параметр может принимать 7 значений (подробности смотрите в Database Server Parameters). По умолчанию значение insert_execution_mode = 1, что означает, что все запросы INSERT INTO… SELECT ... вида будут запускаться на стороне сервера. Так как при импортировании данных мы не используем данное строение запроса, нам необходимо изменить значение на 2, что позволит нам запускать все запросы в виде INSERT INTO… VALUES ... на стороне сервера (см. рисунок ниже).

Итак, чтобы уменьшить общее время импортирования и увеличить производительность CUBRID сервера, следуйте этим советам:
- Используйте CSQL в автономном режиме
- Создавайте любые CONSTRAINT после импортирования данных
- Отключайте журналирование во время импортирования
- Указывайте количество потоков и фиксаций транзакций
- Используйте data_buffer_size
- Используйте insert_execution_mode
Что-то я пропустил? Напишите в комментариях о своем опыте и о том, как часто Вы импортируете данные.
