
Автор: Денис Цыплаков, Solution Architect, DataArt
Постановка задачи
Одной из проблем при построении микросервисных архитектур и особенно при миграции монолитной архитектуры на микросервисы часто становятся транзакции. Каждый микросервис отвечает за собственную группу функций, возможно, управляет данным, ассоциированными с этой группой, и может обслуживать запросы пользователя либо автономно, либо посылая запросы другим микросервисам. Все это прекрасно работает, пока нам не требуется обеспечить консистентность данных, которыми управляют разные микросервисы.
Например, наше приложение работает в каком-то большом интернет-магазине. Кроме всего прочего, у нас есть три отдельных, слабо связанных между собой бизнес-области:
- Склад — что, где, как и как давно хранится, сколько товара определенного типа сейчас есть на складах и т. п.
- Отправка товара — упаковка, отгрузка, трекинг доставки, разбор жалоб на ее задержку и т. п.
- Ведение таможенной отчетности по движению товаров, если товар отправляется за границу (на самом деле, я не знаю, надо ли в таком случае что-то специально оформлять, но все-таки подключу к процессу государственные службы, чтобы добавить драматизма).
Каждая из этих трех областей включают множество непересекающихся функций и может быть представлена в виде нескольких микросервисов.
Есть одна проблема. Предположим, человек купил товар, товар упаковали и отправили курьером. Кроме прочего, нам надо указать, что на складе стало на одну единицу товара меньше, отметить, что процесс доставки товара начался, и если товар отправляется, скажем, в Китай, позаботиться о бумагах для таможни. Если в приложении происходит сбой (например, крэшится нода) на второй или третьей стадии процесса, наши данные приходят в неконсистентное состояние, и всего несколько таких сбоев могут привести к достаточно неприятным проблемам для бизнеса (например, визиту таможенников).
В классической монолитной архитектуре такого рода проблема просто и элегантно решается транзакциями в базе данных. Но как быть, если мы используем микросервисы? Даже если мы из всех сервисов используем одну БД (что не очень изящно, но в нашем случае возможно), работа с этой БД идет из разных процессов, и растянуть транзакцию между процессами у нас не получится.
Решения
У проблемы есть несколько решений:
- Как ни странно, иногда проблему можно игнорировать. Если мы знаем, что сбой происходит не чаще чем раз в месяц, и ручная ликвидация последствий стоит приемлемых для бизнеса денег, на проблему можно не обращать внимания, как бы некрасиво это ни выглядело. Не знаю, можно ли игнорировать претензии таможенной службы, но можно предположить, что при определенных обстоятельствах возможно даже это.
- Компенсация (речь идет не о денежной компенсации таможне, допустим, вы заплатили штраф) — группа разного рода шагов, усложняющих последовательность обработки, но позволяющих обнаружить и обработать сбившийся процесс. Например, перед началом операции мы пишем в специальный сервис, что начинаем операцию отгрузки, а в конце помечаем, что все закончилось хорошо. Затем периодически проверяем, нет ли незаконченных операций, и если они есть, глядя во все три базы данных, пытаемся привести данные в консистентное состояние. Это вполне рабочий способ, но он существенно усложняет логику обработки, и делать так для каждой операции — довольно мучительно.
- Двухфазные транзакции, если говорить строго, спецификация XA+, позволяющая создавать транзакции, распределенные относительно приложений — весьма тяжеловесный механизм, который мало кто любит и, что более важно, мало кто умеет настраивать. К тому же, с легковесными микросервисами он слабо совместим идеологически.
- В принципе транзакция — частный случай consensus problem, и для решения задачи можно использовать многочисленные системы распределенного консенсуса (грубо говоря, все, что гуглится по ключевым словам paxos, raft, zookeeper, etcd, consul). Но в практическом применении для обширных и разветвленных данных складской деятельности все это выглядит еще сложнее двухфазных транзакций.
- Очереди и eventual consistency (согласованность в конечном счете) — мы разбиваем задание на три асинхронных задачи, последовательно обрабатываем данные, передавая их между сервисами из очереди в очередь, и используем механизм подтверждения доставки. В таком случае код не сильно усложняется, но есть несколько моментов, о которых надо помнить:
- Очередь гарантирует доставку «один или более раз», т. е. при повторной доставке одного и того же сообщения сервис должен корректно эту ситуацию обрабатывать, а не отгружать товар два раза. Это можно делать, например, через уникальный UUID заказа.
- Данные в каждый момент времени будут немного неконсистентны. Т. е. товар будет сначала пропадать со склада и только потом с небольшой задержкой будет создаваться ордер на его отправку. Еще позже будут оформляться данные для таможни. В нашем примере это совершенно нормально и не влечет проблем для бизнеса, но есть случаи, когда такое поведение данных может быть весьма неприятным.
- Если в результате самый первый сервис должен вернуть какие-то данные пользователю, последовательность вызовов, которая в конце концов доставляет данные в браузер пользователя, может быть весьма нетривиальной. Основная проблема — браузер посылает запросы синхронно и обычно ожидает синхронного же ответа. Если вы делаете асинхронную обработку запросов, то вам надо строить асинхронную доставку ответа в браузер. Классически делается это либо через веб-сокеты, либо через периодические запросы на наличие новых событий из браузера к серверу. Есть механизмы, например такие, как SocksJS, которые упрощают некоторые аспекты построения этого звена, но дополнительная сложность все равно будет.
В большинстве случаев последний вариант оказывается наиболее приемлемым. Он не сильно усложняет обрабатывающий запрос, правда, работает в несколько раз дольше, но, как правило, это приемлемо для такого рода операцией. Он также требует чуть более сложной организации данных для отсечения повторных запросов, но в этом тоже ничего суперсложного нет.
Схематически один из вариантов обработки транзакций с использованием очередей и Eventual consistency может выглядеть так:
- Пользователь совершил покупку, сообщение об этом посылается в очередь (Например, кластер RabbitMQ или, если мы работаем в Google Cloud Platform — Pub/Sub). Очередь персистентна, гарантирует доставку один или более раз, и транзакционна, т. е. если сервис, обрабатывающий сообщение внезапно упадет, сообщение не потеряется, а будет доставлено новому экземпляру сервиса еще раз.
- Сообщение поступает сервису, который помечает товар на складе как готовящийся к отправке и в свою очередь посылает в очередь сообщение «Товар готов к отправке».
- На следующем шаге сервис, отвечающий за отправку, получает сообщение о готовности к отправке, создает задание на отправку и далее посылает сообщение «отправка товара запланирована».
- Следующий сервис, получив сообщение, что отправка запланирована, запускает процесс оформления бумаг для таможни.
При этом каждое сообщение, получаемое сервисом, проверяется на уникальность, и если сообщение с таким UUID уже было обработано, игнорируется.
Здесь база (базы) данных в каждый момент времени находится в немного неконсистентном состоянии, т. е. товар на складе уже отмечен как находящийся в процессе доставки, но собственно задания на доставку еще нет, оно появится через секунду-другую. Но при этом у нас есть 99.999 % (по сути, это число равняется уровню надежности сервиса очередей) гарантии, что задание на отправку появится. Для большинства бизнесов это приемлемо.
О чем тогда статья?
В статье я хочу рассказать об еще одном способе решения проблемы транзакционности в микросервисных приложениях. Несмотря на то, что микросервисы лучше всего работают, когда у каждого сервиса своя база данных, для небольших и среднего размера систем все данные, как правило, легко умещаются в современную реляционную базу данных. Это справедливо практически для любой внутренней системы предприятия. Т. е. часто жесткой необходимости разделять данные между разными физическими машинами у нас нет. Мы можем хранить данные разных микросервисов в несвязанных между собой группах таблиц одной базы. Это особенно удобно, если вы разделяете на сервисы старое, монолитное приложение и уже разделили код, но данные все еще живут в одной базе. Однако проблема разделения транзакций все еще остается — транзакция жестко привязана к сетевому соединению и, соответственно, процессу, который открыл это соединение, а процессы у нас разделены. Как быть?
Выше я описал несколько распространенных способов решения проблемы, но далее хочу предложить еще один способ для частного случая, когда все данные лежат в одной базе. Этот способ я не рекомендую пытаться реализовать в настоящем проекте, но он достаточно любопытен, чтобы я его изложил в статье. Ну и вдруг он все же пригодится в каком-то частном случае.
Суть его очень проста. Транзакция ассоциирована с сетевым соединением, при этом база данных на самом деле не знает, кто сидит на том конце открытого сетевого соединения. Ей все равно, главное, чтобы в сокет поступали корректные команды. Понятно, что обычно сокет принадлежит эксклюзивно одному процессу на стороне клиента, но я вижу как минимум три способа это обойти.
1. Изменение кода БД
На уровне кода базы данных для баз данных, код которых мы можем менять, делая свою сборку БД, реализуем механизм передачи транзакции между соединениями. Как это может работать с точки зрения клиента:
- Начинаем транзакцию, делаем какие-то изменения, наступает время передать транзакцию следующему сервису.
- Мы говорим БД дать нам UUID транзакции и ждать N секунд. Если за это время не придет другое соединение с этим UUID, откатывать транзакцию, если придет — передать все структуры данных, ассоциированные с транзакцией, новому соединению и продолжать работу уже с ним.
- Передаем UUID следующему сервису (т. е. другому процессу, возможно, на другой VM).
- В нем открываем соединение и даем команду БД — продолжить транзакцию с заданным UUID.
- Продолжаем работать с БД в рамках транзакции начатой другим процессом.
Этот способ самый легковесный в использовании, но требует модификации кода БД, прикладные программисты этим обычно не занимаются, для этого требуется много специальных навыков. Передавать данные, скорее всего, придется между процессами БД, да и баз данных, код которых мы можем спокойно поменять по большому счету одна — PostgreSQL. Вдобавок, работать это будет только для unmanaged-серверов, в RDS или Cloud SQL с этим не пойдешь.
Схематично это выглядит так:

2. Манипуляция сокетами
Второе, что приходит в голову, — тонкая манипуляция сокетами соединений с базой данных. Мы можем сделать некий “Reverse socket proxy”, который направляет команды, поступающие от нескольких клиентов, на определенный порт в один поток команд к БД.
По сути это приложение, очень похожее на pgBouncer, только, вдобавок к его стандартному функционалу, делающее некоторые манипуляции с потоком байтов от клиентов и умеющее по команде подставлять один клиент вместо другого.
Этот способ мне категорически не нравится, для его реализации необходимо подчищать бинарные пакеты, циркулирующие между сервером и клиентами. И он все еще требует много системного программирования. Привел я его исключительно для полноты списка.
3. Gateway JDBC
Мы можем сделать gateway JDBC-драйвер — берем стандартный JDBC-драйвер для конкретной БД, пусть это будет PostgreSQL. Оборачиваем класс и ко всем его внешним методам делаем HTTP-интерфейсы (можно и не HTTP, но разница небольшая). Далее мы делаем еще один JDBC-драйвер — фасад, который все вызовы методов перенаправляет в gateway JDBС. Т. е. по сути мы распиливаем существующий драйвер на две половинки и связываем эти половинки по сети. Получаем вот такую схему компонент:
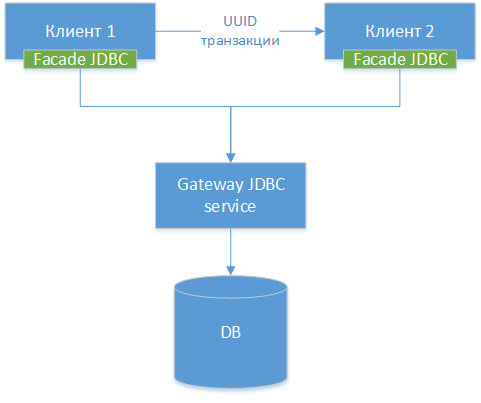
NB!: Как мы видим, все три варианта похожи, разница заключается только в том, на каком уровне мы осуществляем передачу соединения и каким инструментарием для этого пользуемся.
После этого мы учим наш драйвер делать по сути тот же трюк с UUID-транзакцией, который описан в способе 1.
В коде Java-приложения использование этого способа может выглядеть следующим образом.
Сервис А — начало транзакции
Ниже приведен код некоторого сервиса, который начинает транзакцию, делает изменения в БД и передает ее дальше другому сервису для завершения. В коде мы используем прямую работы с JDBC-классами. В 2019 году так, конечно, никто не делает, но для простоты примера код упрощен.
// В реальном приложении мы, конечно, соединение “руками”
// не открываем
Class.forName("org.postgresql.FacadeDriver");
var connection = DriverManager.getConnection(
"jdbc:postgresqlfacade://hostname:port/dbname","username", "password");
// Делаем какие-то изменения в БД
statement = dbConnection.createStatement();
var statement.executeUpdate(“insert ...”);
/* Все, мы сделали изменения и готовы передать транзакцию дальше.
transactionUUID(int) Это псевдо-функция, до БД она не доходит, а
обрабатывается JDBC gateway-сервисом. В ResultSet возвращается
единственная строка с одним полем типа Varchar, содержащим UUID.
После выполнения этого запроса соединение блокируется и на
все запросы возвращает ошибку. Чтобы его разблокировать, надо
дать команду на возобновления транзакции с данным UUID.
Число 60 — это таймаут, после которого транзакция откатывается.
В реальных приложениях такие запросы делаются с помощью, например,
JDBCTemplate. Здесь для иллюстративности у меня ResultSet
*/
var rs = statement.executeQuery(“select transactionUUID(60)”);
String uuid = extractUUIDFromResultSet(rs);
// передаем дальнейшую обработку удаленному сервису
remoteServiceProxy.continueProcessing(uuid, otherParams);
// Больше в рамках этого соединения никаких операций совершать нельзя
// освобождаем все ресурсы и выходим.
closeEverything();
return;
Сервис В — завершение транзакции
// Здесь мы продолжаем с места, где был вызван метод
// remoteServiceProxy.continueProcessing(...)
// Точно так же открываем соединение.
Class.forName("org.postgresql.FacadeDriver");
var connection = DriverManager.getConnection(
"jdbc:postgresqlfacade://hostname:port/dbname","username", "password");
// Теперь нам надо сказать Gateway JDBC, что мы продолжаем
// транзакцию. Команда continue transaction не идет в БД, а обрабатывается
// gateway JDBC
statement = dbConnection.createStatement();
statement.executeUpdate(“continue transaction ”+uuid);
// Все, мы подсоединились к транзакции, стартовавшей в другом сервисе и
// можем продолжать наполнять базу данными
statement.executeUpdate(“update ...");
// Завершаем транзакцию
connection.commit();
return;Взаимодействие с другими компонентами и фреймворками
Рассмотрим возможные побочные эффекты такого архитектурного решения.
Пул конектов
Поскольку на самом деле настоящий пул коннектов у нас будет находится внутри JDBC gateway — пулы конектов в сервисах лучше вообще выключить, т. к. они будут захватывать и держать внутри сервиса коннект, который мог бы быть использован другим сервисом.
Плюс к этому, после получения UUID и ожидания передачи в другой процесс соединение по сути становится нерабочим, и с точки зрения frontend JDBC, оно авто-закрывается, а с точки зрения gateway JDBC, его надо удерживать, не отдавая никому, кроме того, кто придет с нужным UUID.
Другими словами, двойной менеджмент пула коннектов в Gateway JDBC и внутри каждого из сервисов может давать сложно уловимые, неприятные ошибки.
JPA
С JPA я вижу две возможные проблемы:
- Менеджмент транзакций. При комите JPA движок может думать, что он сохранил все данные, тогда как они не сохранились. Скорее всего, ручное управление транзакциями и flush() перед передачей транзакции должны решить проблему.
- Кэш второго уровня, скорее всего, будет работать некорректно, но в распределенных системах его использование в любом случае ограничено.
Spring transactions
Механизм управления транзакциями фреймворка Spring, пожалуй, задействовать не получится, и управлять ими вам придется вручную. Почти уверен, что его можно расширить — например, написать custom scope — но чтобы сказать наверняка, надо изучить, как там устроено расширение Spring Transactions, а я туда пока не смотрел.
Плюсы и минусы
Плюсы
- Практически не требует модификации существующего монолитного кода при распиливании.
- Можно писать сложные кросс-серверные транзакции практически без усложнения кода.
- Позволяет делать кросс-сервисную трассировку исполнения транзакций.
- Решение достаточно гибкое, можно использовать классические транзакции, там где не требуется распределенности и делиться транзакцией только для тех операций, где требуется кросс-сервисное взаимодействие.
- Команде проекта не требуется в принудительном порядке осваивать новые технологии. Новые технологии это, конечно, хорошо, но задача — обязательно и срочно (до вчерашнего числа!) научить 20 разработчиков концепции построения реактивных систем — может быть весьма нетривиальной. При этом нет гарантии, что все 20 человек с обучением справятся в срок.
Минусы
- Немасштабируемое и, по сути, немодульное на уровне БД, в отличие от решения с очередями. У вас все еще одна база данных, в которую сходятся все запросы и вся нагрузка. В этом смысле решение тупиковое: если вы потом захотите нарастить нагрузку или сделать решение модульным по данным, вам придется все переделывать.
- Надо очень осторожно передавать транзакцию между процессами, особенно процессами написанными на фреймворках. У сессий есть свои настройки, и для различных фреймворков внезапная смена соединения с базой может привести в неправильной работе. См., например, настройки сессии и транзакции для PostgreSQL.
- Когда я рассказал идею в нашем локальном архитекторском чате в DataArt, первое, о чем спросили меня коллеги, — пил ли я (нет, не пил!). Но я признаю, что идея, скажем так, не самая распространенная, и если вы ее реализуете у себя в проекте, она будет выглядеть очень необычно для других его участников.
- Требует кастомного JDBC-драйвера. Его написание требует времени, вам придется его отлаживать, искать в нем ошибки, в том числе, вызванные ошибками обмена по сети, и т. д.
Предупреждение
Еще раз предупреждаю: не пытайтесь повторить этот трюк
Всех с первым апреля!
