Всем привет!
Сегодня хотим познакомить вас с нашим новым сервисом CloudLITE, который мы официально запускаем сегодня. CloudLITE – это интернет-магазин для облачных ресурсов по модели IaaS на базе VMware.
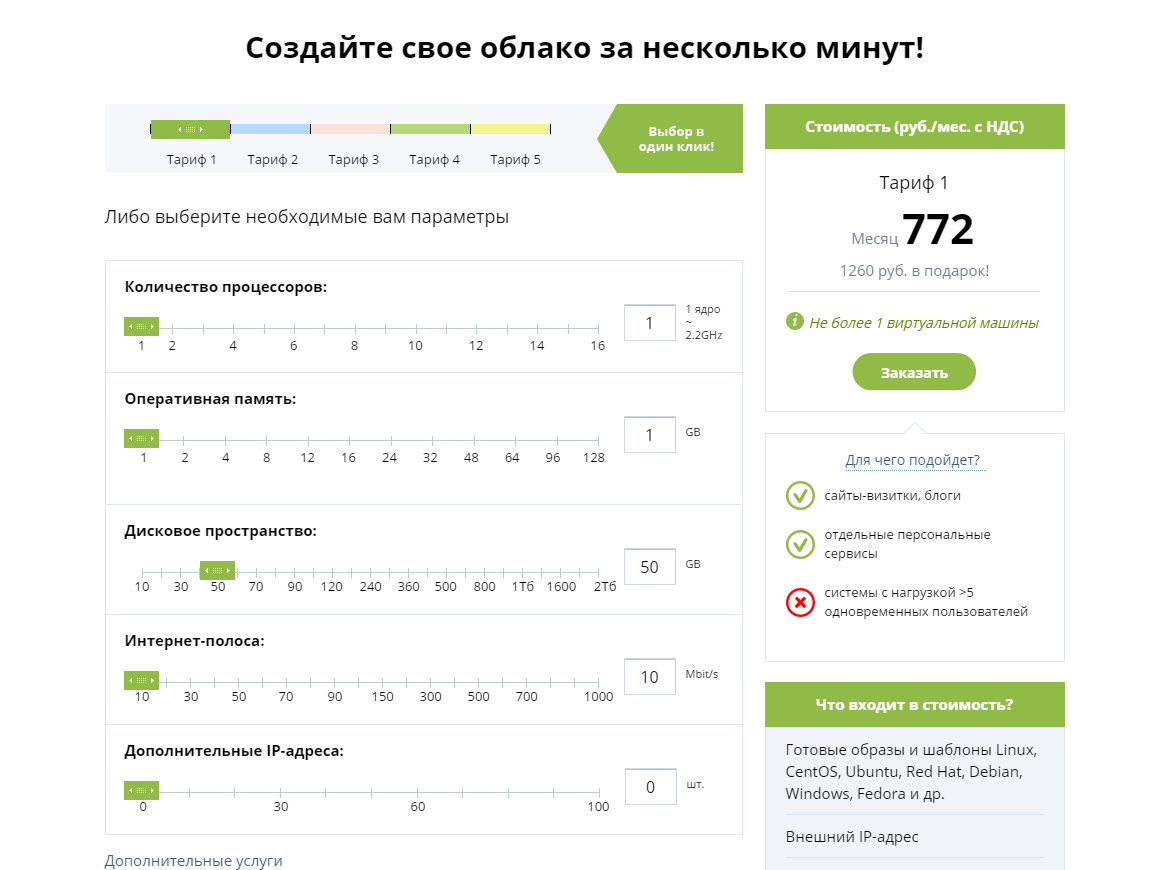
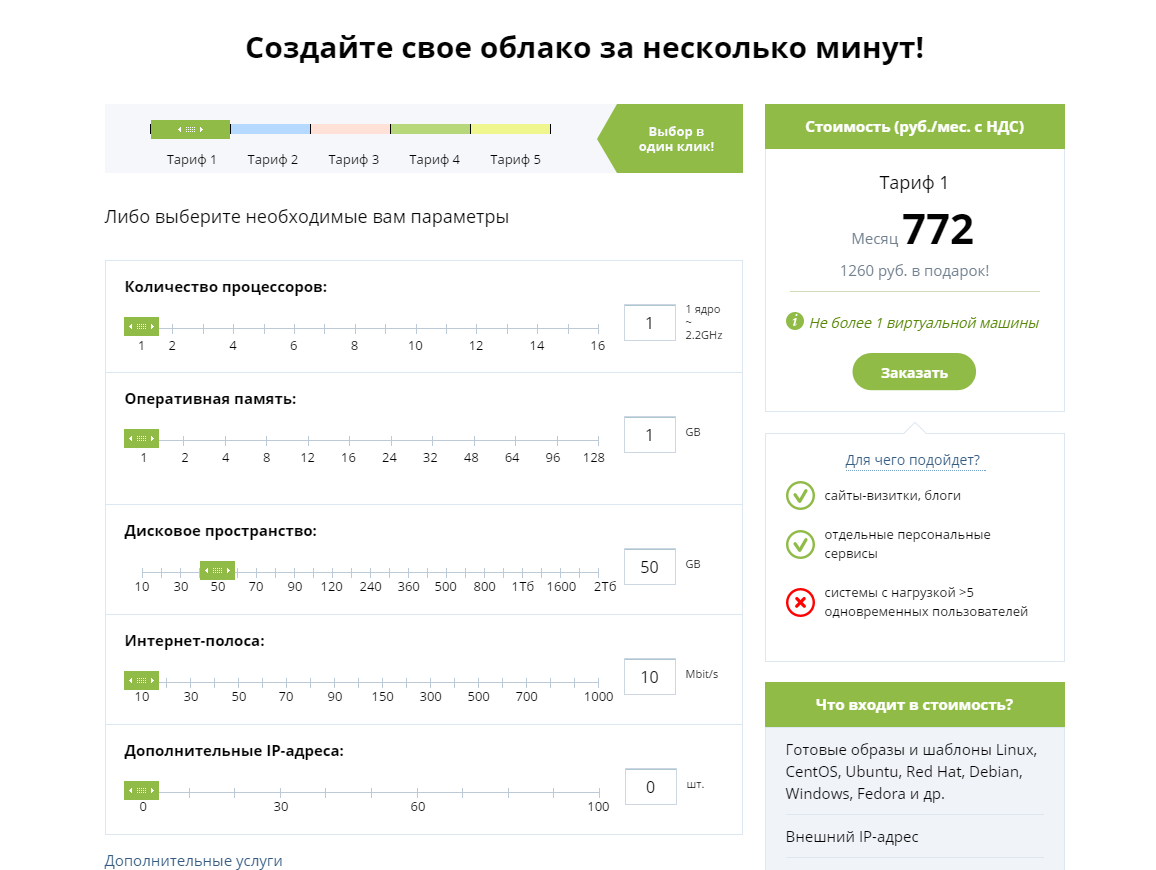
Новый сервис позволяет купить ресурсы через сайт и развернуть полноценную виртуальную инфраструктуру за считанные минуты. В магазине можно выбрать 5 готовых конфигураций или создать свое облако с помощью онлайн-калькулятора.
В стоимость каждой конфигурации входит интернет-полоса до 10 мбит/сек с безлимитным трафиком, 1 IP-адрес, техподдержка, детальный SLA с показателем доступности 99,95% и, конечно же, тест-драйв, аж целый месяц. Подробности в конце статьи. Для самых стойких.
UPD: Всем спасибо большое за интерес к CloudLITE. За первую неделю у нас уже более 150 регистраций. Отдельная благодарность всем тем, кто не держал в себе и активно высказывался по поводу нового сервиса. Вы нам очень помогаете!
Аттракцион щедрости продолжается, и мы по-прежнему ждем всех желающих на 1 месяц тест-драйва, а наш ящик feedback@cloudlite.ru — новых предложений и замечаний ;)

Для кого и чего?
Изначально CloudLITE задумывался как решение для крупных компаний, которым необходимы ресурсы под тестовые среды и разработку. В таких случаях представители бизнеса готовы отказаться от «лишних» девяток в аптайме, но получить возможность сэкономить, сохранив при этом прежний функционал. Мы пошли именно по этому пути, предложив более низкую стоимость и более «мягкий» SLA (99,95 %). И решили на этом не останавливаться…
В результате мы создали отдельный, полностью автоматизированный сервис CloudLITE, в котором покупка ресурсов и развертывания виртуальной инфраструктуры происходит в формате самообслуживания. Это позволило опустить ценовую планку еще ниже и сделать сервис, как мы надеемся, интересным для представителей СМБ, микро-бизнеса, а также индивидуальных пользователей.
Помимо оперативной организации «песочниц», возможности CloudLITE можно использовать для «продвинутого» хостинга интернет-магазинов, медиа-проектов, блогов и пр., если вы исчерпали возможности виртуального хостинга и VDS/VPS, а вариант с выделенным сервером вам не подходит.
СМБ могут разместить в облачной инфраструктуре CloudLITE корпоративную почту и сайт, офисные приложения и многое другое.
Можно сказать, что в итоге у нас получилась своего рода light-версия облака CloudLine по части обслуживания, SLA и стоимости, но с неизменно широким функционалом IaaS и надежными программно-аппаратными решениями enterprise-уровня. Ну, и, конечно же, наш опыт Premier-partner VMware, никуда не делся :).
Панель управления vCloud Director
Управление облачными ресурсами осуществляется с помощью панели управления vCloud Director. С ней вы сможете:
• создавать виртуальные машины нужной конфигурации;
• управлять ВМ (включать, выключать, клонировать, создавать шаблоны и пр.);
• устанавливать любое системное и прикладное ПО;
• экспортировать и импортировать образы и шаблоны ВМ;
• создавать внутренние и маршрутизируемые сети (с выходом в интернет или к внешнему физическому оборудованию);
• гибко управлять правами доступа пользователей к пулу виртуальных ресурсов;
• мощный API (ему стоит посвятить отдельный пост)
и многое другое.
Для удобства в общем каталоге уже размещены шаблоны ВМ с предустановленными ОС (Centos, Ubuntu, Linux, Windows и пр.)
У панели очень богатый функционал. Чтобы упростить процесс знакомства мы подготовили для вас подробные инструкции со скриншотами.
Как устроено облако CloudLITE?
CloudLITE, как и существующие облачные сервисы DataLine, работает под управлением гипервизора VMware vSphere 5.5.
Благодаря встроенному балансировщику (Distributed Resource Scheduler, DRS) нагрузка на кластер распределяется оптимальным образом. DRS непрерывно отслеживает состояние кластера, и, если на одном из серверов не хватает какого-то ресурса (процессора, памяти), то балансировщик с помощью механизма «живой» миграции vMotion переносит часть ВМ с этого сервера на менее занятые. Это позволяет избежать борьбы за ресурсы между виртуальными машинами и гарантировать одинаково высокую мощность для всех клиентов CloudLITE.
Отказоустойчивость кластера обеспечивает технология VMware HA (high availability). Она позволяет оперативно отслеживать сбои в работе оборудования кластера виртуализации и, в случае выхода из строя одного из серверов, осуществлять миграцию ВМ на резервные серверы кластера и перезапускать их там.
Отличительной особенностью CloudLITE от других облачных сервисов DataLine стало использование СХД класса software defined storage — VMware VSAN. Это решение объединяет диски промышленного уровня с интерфейсом NL SAS и кэширующие PCIe флеш-карты в единое распределенное хранилище.
Облако развернуто на 4-сокетных серверах Huawei FusionServer RH5885 V3 на базе процессоров Intel Xeon. Каждый сервер имеет на борту 4 высокопроизводительных интерфейса 10G Ethernet. В качестве сетевого оборудования используются высокопроизводительные коммутаторы 10G Cisco Nexus.
Все оборудование располагается в дата-центре NORD 3 уровня Tier 3 на севере Москвы (видеотур для желающих), а это значит, что все элементы инженерной инфраструктуры зарезервированы (как минимум по схеме N+1), помещения и прилегающая территория тщательно охраняется.
SLA
Несмотря на свою «мягкость» (99,95 % вместо традиционного для облачных сервисов DataLine 99,982%), SLA CloudLITE не менее детальный и охватывает все аспекты предоставления сервиса. Показатель доступности 99,95% означает, что простой облачного сервиса не может превышать 4,38 часов в год или 21.56 минут в месяц. Еще одним важным показателем является производительность: для процессора она составляет до 1200 MIPS/ядро, для дисковой подсистемы — до 100 IOPS/320GB.
В SLA регламентируются наши обязательства по скорости реакции на инцидент, его разрешение в соответствие с присвоенным приоритетом, а также штрафные санкции к нам, если мы их не соблюдаем.
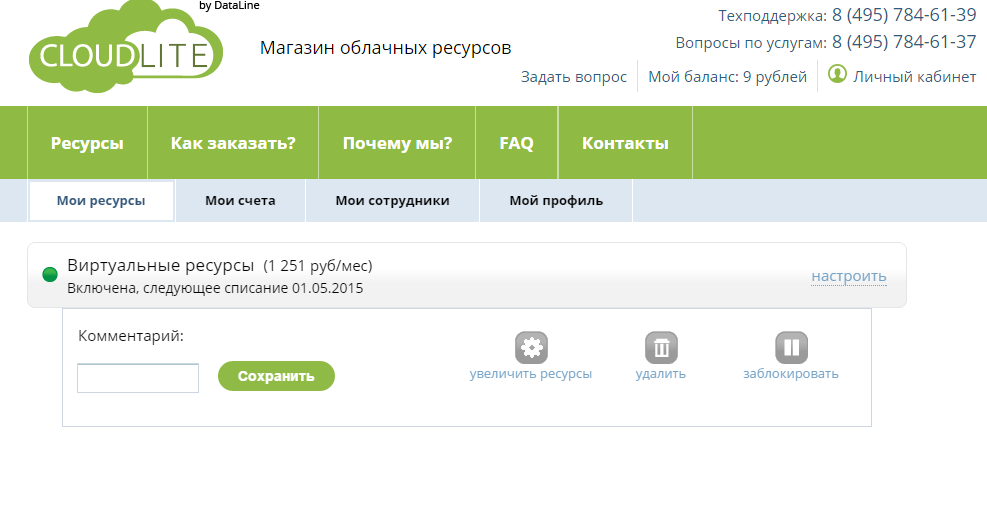
Личный кабинет (биллинг)
В качестве биллинг-платформы и Личного кабинета мы использовали решение Velvica, позволяющее полностью автоматизировать продажу \ покупку облачных ресурсов.
Благодаря Velvica пользователи CloudLITE могут самостоятельно создавать свои виртуальные дата-центры в нашем облаке, оплачивать ресурсы через сайт, пополняя счет в личном кабинете, и отслеживать всю историю списаний. Доступ к панели управления облачным ЦОД осуществляется из личного кабинета напрямую, без дополнительной авторизации (single sign-on). Платформа также дает возможность оформлять подписку на облачные ресурсы для юрлиц с выставлением счетов и прочей необходимой документацией.
Продолжение следует…
В этой версии мы успели реализовать не все, что хотелось, поэтому мы все еще продолжаем совершенствовать имеющийся функционал, убирать баги :) и добавлять новые возможности.
В честь открытия мы дарим целый месяц бесплатного тестирования для конфигурации 2 vCPU, 2 GB RAM и 50 GB HDD со всем фаршем (безлимитный трафик, IP и прочие ништячки).
Призываем принять самое активное участие в тестировании нового сервиса. Мы будем очень-очень признательны за ваши замечания и предложения, присланные на feedback@cloudlite.ru.
Поехали!
UPD: Всем спасибо большое за интерес к CloudLITE. У нас уже более 150 регистраций. Отдельная благодарность всем тем, кто не держал в себе и активно высказывался по поводу нового сервиса. Вы нам очень помогаете!
Аттракцион щедрости продолжается, и мы по-прежнему ждем всех желающих на 1 месяц тест-драйва, а наш ящик feedback@cloudlite.ru — новых предложений и замечаний ;)
Сегодня хотим познакомить вас с нашим новым сервисом CloudLITE, который мы официально запускаем сегодня. CloudLITE – это интернет-магазин для облачных ресурсов по модели IaaS на базе VMware.
Новый сервис позволяет купить ресурсы через сайт и развернуть полноценную виртуальную инфраструктуру за считанные минуты. В магазине можно выбрать 5 готовых конфигураций или создать свое облако с помощью онлайн-калькулятора.
В стоимость каждой конфигурации входит интернет-полоса до 10 мбит/сек с безлимитным трафиком, 1 IP-адрес, техподдержка, детальный SLA с показателем доступности 99,95% и, конечно же, тест-драйв, аж целый месяц. Подробности в конце статьи. Для самых стойких.
UPD: Всем спасибо большое за интерес к CloudLITE. За первую неделю у нас уже более 150 регистраций. Отдельная благодарность всем тем, кто не держал в себе и активно высказывался по поводу нового сервиса. Вы нам очень помогаете!
Аттракцион щедрости продолжается, и мы по-прежнему ждем всех желающих на 1 месяц тест-драйва, а наш ящик feedback@cloudlite.ru — новых предложений и замечаний ;)

Для кого и чего?
Изначально CloudLITE задумывался как решение для крупных компаний, которым необходимы ресурсы под тестовые среды и разработку. В таких случаях представители бизнеса готовы отказаться от «лишних» девяток в аптайме, но получить возможность сэкономить, сохранив при этом прежний функционал. Мы пошли именно по этому пути, предложив более низкую стоимость и более «мягкий» SLA (99,95 %). И решили на этом не останавливаться…
В результате мы создали отдельный, полностью автоматизированный сервис CloudLITE, в котором покупка ресурсов и развертывания виртуальной инфраструктуры происходит в формате самообслуживания. Это позволило опустить ценовую планку еще ниже и сделать сервис, как мы надеемся, интересным для представителей СМБ, микро-бизнеса, а также индивидуальных пользователей.
Помимо оперативной организации «песочниц», возможности CloudLITE можно использовать для «продвинутого» хостинга интернет-магазинов, медиа-проектов, блогов и пр., если вы исчерпали возможности виртуального хостинга и VDS/VPS, а вариант с выделенным сервером вам не подходит.
СМБ могут разместить в облачной инфраструктуре CloudLITE корпоративную почту и сайт, офисные приложения и многое другое.
Можно сказать, что в итоге у нас получилась своего рода light-версия облака CloudLine по части обслуживания, SLA и стоимости, но с неизменно широким функционалом IaaS и надежными программно-аппаратными решениями enterprise-уровня. Ну, и, конечно же, наш опыт Premier-partner VMware, никуда не делся :).
Панель управления vCloud Director
Управление облачными ресурсами осуществляется с помощью панели управления vCloud Director. С ней вы сможете:
• создавать виртуальные машины нужной конфигурации;
• управлять ВМ (включать, выключать, клонировать, создавать шаблоны и пр.);
• устанавливать любое системное и прикладное ПО;
• экспортировать и импортировать образы и шаблоны ВМ;
• создавать внутренние и маршрутизируемые сети (с выходом в интернет или к внешнему физическому оборудованию);
• гибко управлять правами доступа пользователей к пулу виртуальных ресурсов;
• мощный API (ему стоит посвятить отдельный пост)
и многое другое.
Для удобства в общем каталоге уже размещены шаблоны ВМ с предустановленными ОС (Centos, Ubuntu, Linux, Windows и пр.)
У панели очень богатый функционал. Чтобы упростить процесс знакомства мы подготовили для вас подробные инструкции со скриншотами.
Как устроено облако CloudLITE?
CloudLITE, как и существующие облачные сервисы DataLine, работает под управлением гипервизора VMware vSphere 5.5.
Благодаря встроенному балансировщику (Distributed Resource Scheduler, DRS) нагрузка на кластер распределяется оптимальным образом. DRS непрерывно отслеживает состояние кластера, и, если на одном из серверов не хватает какого-то ресурса (процессора, памяти), то балансировщик с помощью механизма «живой» миграции vMotion переносит часть ВМ с этого сервера на менее занятые. Это позволяет избежать борьбы за ресурсы между виртуальными машинами и гарантировать одинаково высокую мощность для всех клиентов CloudLITE.
Отказоустойчивость кластера обеспечивает технология VMware HA (high availability). Она позволяет оперативно отслеживать сбои в работе оборудования кластера виртуализации и, в случае выхода из строя одного из серверов, осуществлять миграцию ВМ на резервные серверы кластера и перезапускать их там.
Отличительной особенностью CloudLITE от других облачных сервисов DataLine стало использование СХД класса software defined storage — VMware VSAN. Это решение объединяет диски промышленного уровня с интерфейсом NL SAS и кэширующие PCIe флеш-карты в единое распределенное хранилище.
Облако развернуто на 4-сокетных серверах Huawei FusionServer RH5885 V3 на базе процессоров Intel Xeon. Каждый сервер имеет на борту 4 высокопроизводительных интерфейса 10G Ethernet. В качестве сетевого оборудования используются высокопроизводительные коммутаторы 10G Cisco Nexus.
Все оборудование располагается в дата-центре NORD 3 уровня Tier 3 на севере Москвы (видеотур для желающих), а это значит, что все элементы инженерной инфраструктуры зарезервированы (как минимум по схеме N+1), помещения и прилегающая территория тщательно охраняется.
SLA
Несмотря на свою «мягкость» (99,95 % вместо традиционного для облачных сервисов DataLine 99,982%), SLA CloudLITE не менее детальный и охватывает все аспекты предоставления сервиса. Показатель доступности 99,95% означает, что простой облачного сервиса не может превышать 4,38 часов в год или 21.56 минут в месяц. Еще одним важным показателем является производительность: для процессора она составляет до 1200 MIPS/ядро, для дисковой подсистемы — до 100 IOPS/320GB.
В SLA регламентируются наши обязательства по скорости реакции на инцидент, его разрешение в соответствие с присвоенным приоритетом, а также штрафные санкции к нам, если мы их не соблюдаем.
Личный кабинет (биллинг)
В качестве биллинг-платформы и Личного кабинета мы использовали решение Velvica, позволяющее полностью автоматизировать продажу \ покупку облачных ресурсов.
Благодаря Velvica пользователи CloudLITE могут самостоятельно создавать свои виртуальные дата-центры в нашем облаке, оплачивать ресурсы через сайт, пополняя счет в личном кабинете, и отслеживать всю историю списаний. Доступ к панели управления облачным ЦОД осуществляется из личного кабинета напрямую, без дополнительной авторизации (single sign-on). Платформа также дает возможность оформлять подписку на облачные ресурсы для юрлиц с выставлением счетов и прочей необходимой документацией.
Продолжение следует…
В этой версии мы успели реализовать не все, что хотелось, поэтому мы все еще продолжаем совершенствовать имеющийся функционал, убирать баги :) и добавлять новые возможности.
В честь открытия мы дарим целый месяц бесплатного тестирования для конфигурации 2 vCPU, 2 GB RAM и 50 GB HDD со всем фаршем (безлимитный трафик, IP и прочие ништячки).
Призываем принять самое активное участие в тестировании нового сервиса. Мы будем очень-очень признательны за ваши замечания и предложения, присланные на feedback@cloudlite.ru.
Поехали!
UPD: Всем спасибо большое за интерес к CloudLITE. У нас уже более 150 регистраций. Отдельная благодарность всем тем, кто не держал в себе и активно высказывался по поводу нового сервиса. Вы нам очень помогаете!
Аттракцион щедрости продолжается, и мы по-прежнему ждем всех желающих на 1 месяц тест-драйва, а наш ящик feedback@cloudlite.ru — новых предложений и замечаний ;)

