
Многие клиенты, арендующие у нас облачные ресурсы, используют виртуальные Check Point’ы. С их помощью клиенты решают различные задачи: кто-то контролирует выход серверного сегмента в Интернет или же публикует свои сервисы за нашим оборудованием. Кому-то необходимо прогонять весь трафик через IPS blade, а кому-то хватает Check Point в роли VPN-шлюза для доступа к внутренним ресурсам в ЦОДе из филиалов. Есть и те, кому нужно защитить свою инфраструктуру в облаке для прохождения аттестации по ФЗ-152, но об этом я расскажу как-нибудь отдельно.
По долгу службы я занимаюсь поддержкой и администрированием Check Point'ов. Сегодня расскажу, что нужно учесть при разворачивании кластера из Check Point'ов в виртуальной среде. Затрону моменты уровня виртуализации, сети, настроек самого Check Point'а и мониторинга.
Не обещаю открыть Америку – многое есть в рекомендациях и best practices вендора. Но их же никто не читает), поэтому погнали.
Режим работы кластера
У нас Check Point'ы живут в кластерах. Самая частая инсталляция – кластер из двух нод в режиме active-standby. Если с active-нодой что-то случается, она становится неактивной, и в работу включается standby-нода. Переключение на «запасную» ноду обычно происходит из-за проблем в синхронизации между участниками кластера, состоянии интерфейсов, установленной политики безопасности, просто из-за сильной нагрузки на оборудование.
В кластере из двух нод мы не используем режим active-active.
При падении одной из нод выжившая нода может просто не выдержать двойной нагрузки, и тогда мы потеряем все. Если очень хочется active-active, то в кластере должно быть минимум 3 ноды.
Настройки сети и виртуализации
На сетевом оборудовании разрешено прохождение multicast-трафика между SYNC-интерфейсами членов кластера. В случае если прохождение multicast-трафика невозможно, то протокол синхронизации (CCP) используется broadcast. Ноды в кластере Check Point'а синрохнизируются между собой. Сообщения об изменениях передаются от ноды к ноде через multicast. У Check Point'а используется нестандартная реализация мультикаста (используется не multicast IP-адрес). Из-за этого некоторое оборудование, например, коммутатор Cisco Nexus, эти сообщения не понимает и поэтому блокирует их. В этом случае переключаемся на broadcast.
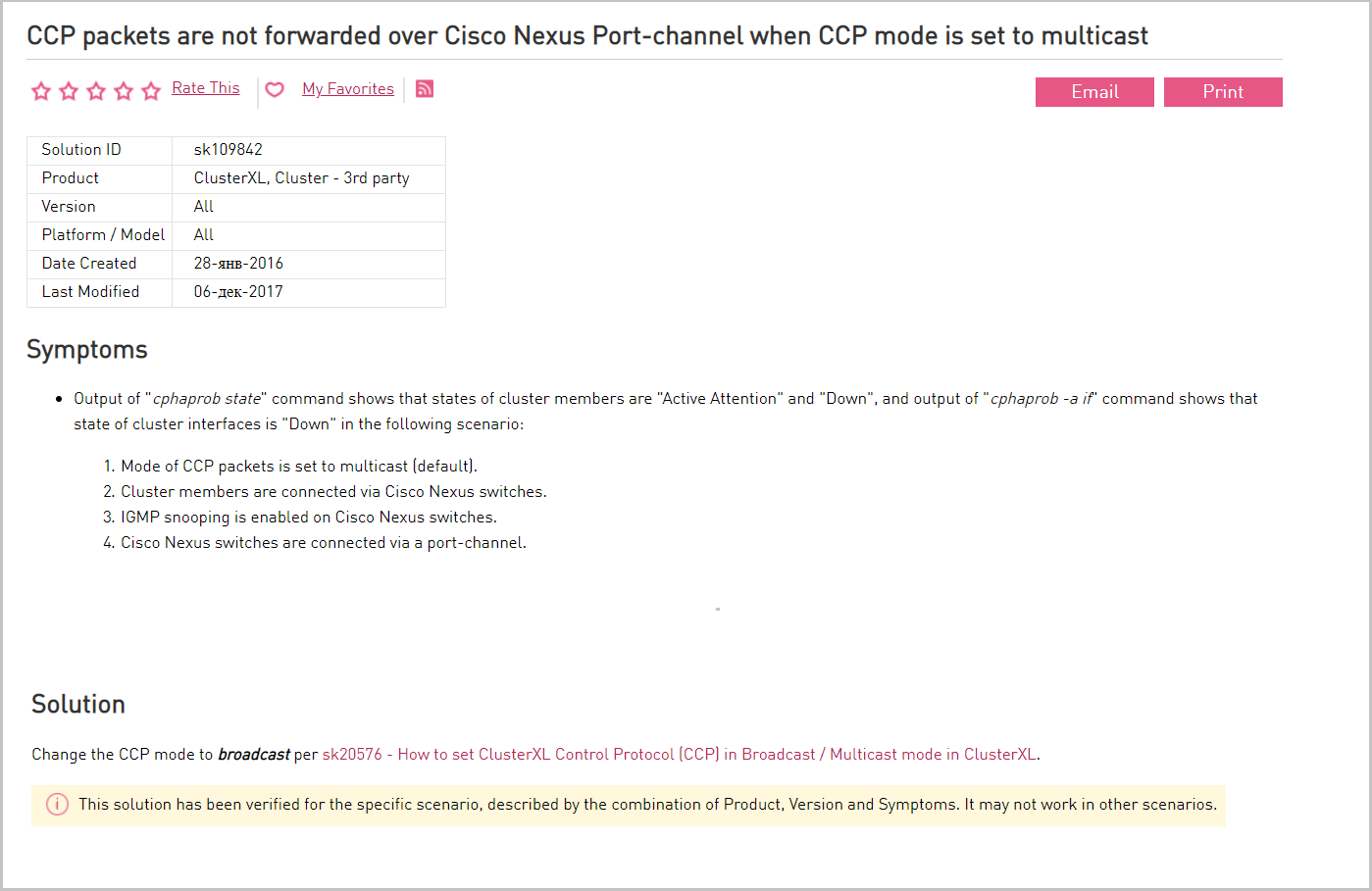
Описание проблемы с Cisco Nexus и ее решения на портале вендора.
На уровне виртуализации также разрешаем прохождение multicast-трафика. Если multicast запрещен для синхронизации кластера (CCP), то используем broadcast.
В консоли Check Point'а c помощью команды cphaprob -a if можно посмотреть настройки CPP и его режим работы (multicast или broadcast). Чтобы изменить режим работы, используем команду cphaconf set_ccp broadcast.

Ноды кластера должны находиться на разных ESXi-хостах. Тут все понятно: при падении физического хоста вторая нода продолжает работать. Этого можно достичь с помощью DRS anti-affinity rules.
Размеры виртуальной машины, на которой будет работать Check Point. Рекомендации вендора – 2 vCPU и 6 ГБ, но это для минимальной конфигурации, например, если у вас работает firewall с минимальной пропускной способностью. По нашему опыту внедрений, при использовании нескольких программных блейдов желательно использовать как минимум 4 vCPU, 8 GB RAM.
На ноду мы выделяем в среднем 150 ГБ диска. При развертывании виртуального Check Point диск разбивается на партиции, и мы можем регулировать, какое пространство выделить под System Swap, System Root, Logs, Backup and Upgrade.
При увеличении System Root партицию Backup and Upgrade также нужно увеличить, чтобы соблюсти пропорцию между ними. Если пропорция не соблюдается, то очередной бэкап может не уместиться диске.
Disk Provisioning – Thick Provision Lazy Zeroed.Check Point генерирует много событий и логов, каждую секунду появляется 1000 записей. Под них лучше сразу зарезервировать место. Для этого при создании виртуальной машины выделяем ей диск по технологии Thick Provisioning, т.е. есть резервируем место на физическом хранилище в момент создания диска.
Настроено 100% резервирование ресурсов для Check Point при миграции между ESXi-хостами. Рекомендуем зарезервировать 100 % ресурсов, чтобы виртуальная машина, на который развернут Check Point, не конкурировала за ресурсы с другими ВМ на хосте.
Прочее. У нас используется версия Check Point'а R77.30. Для нее рекомендуется использовать RedHat Enterprise Linux version 5 (64-bit) в качестве гостевой ОС на виртуальной машине. Из сетевых драйверов – VMXNET3 или Intel E1000.
Настройки Check Point’a
На шлюзах и сервере управления установлены последние обновления Check Point. Проверяем наличие обновлений через CPUSE.
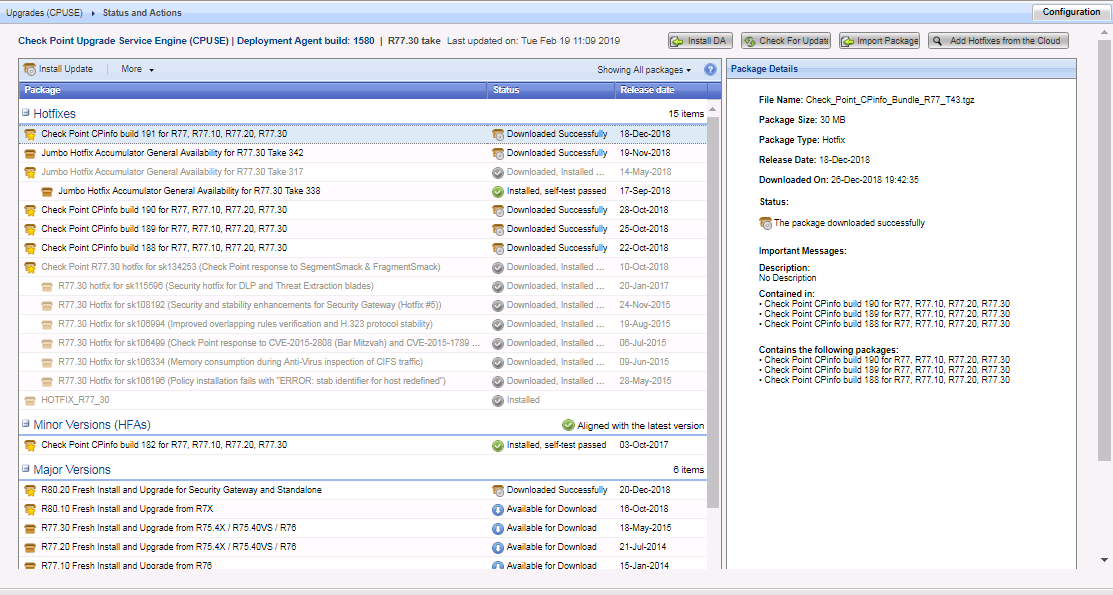
С помощью Verifier проверяем, что пакет обновлений, который мы собираемся установить, не конфликтует с системой.

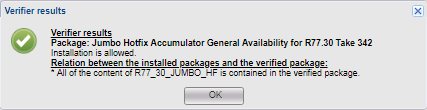
Verifier, конечно, штука хорошая, но есть нюансы. Некоторые обновления несовместимы с add-on, но этих конфликтов Verifier не покажет и позволит обновиться. В конце обновления у вас появится ошибка, и только из нее вы узнаете, что мешает обновлению. Например, такая ситуация возникла с пакетом обновлений MABDA_001 (Mobile Access Blade Deployment Agent), которая решает проблему с запуском Java Plugin в браузерах отличных от IE.
Настроено ежедневное автоматическое обновление сигнатур для IPS и других программных блейдов. Check Point выпускает сигнатуры, с помощью которых можно детектировать или блокировать новые уязвимости. Уязвимости автоматически присваивается уровень критичности. В соответствии с этим уровнем и выставленным фильтром система принимает решение о том, детектировать или блокировать сигнатуру. Тут важно не переусердствовать с фильтрами, периодически проверять и вносить корректировки, чтобы не блокировался легитимный трафик.
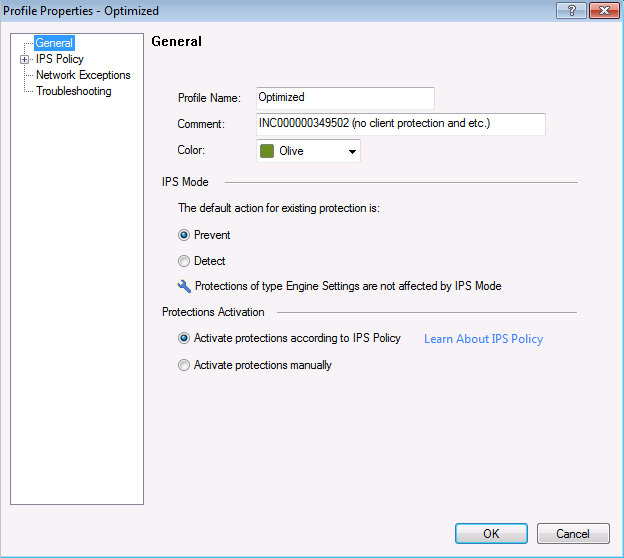
Профиль IPS, где выбираем действие по отношению к сигнатуре в соответствии с ее параметрами.
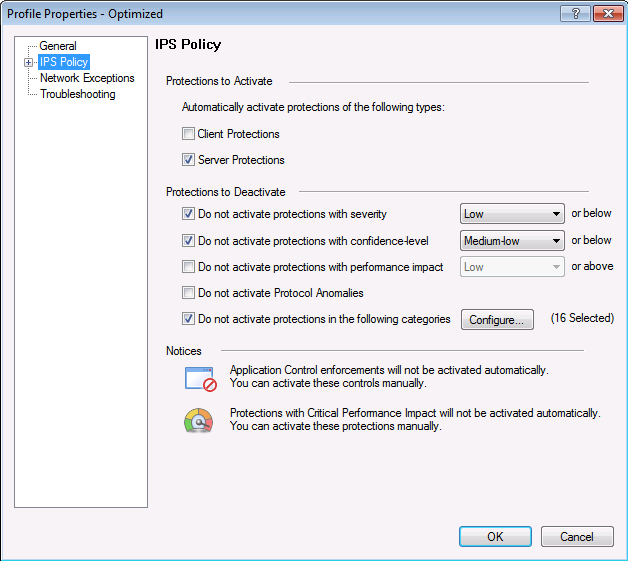
Настройки политики для данного профиля IPS в соответствии с параметрами сигнатур: уровень критичности, влияние на производительность и пр.
На оборудовании Check Point настроен протокол синхронизации времени NTP. По рекомендациям, Check Point следует использовать внешний NTP-сервер для синхронизации времени на оборудовании. Сделать это можно через веб-портал gaia.
Неточно выставленное время может привести к рассинхронизации кластера. Если время будет неправильным, то крайне неудобно искать интересующую нас запись в логах. Каждая запись в журналах событий маркируется так называемым timestamp.
Настроен Smart Event для оповещения о срабатываниях IPS, App Control, Anti-Bot и т. д. Это отдельный модуль со своей лицензией. Если он у вас есть, то с его помощью удобно визуализировать информацию о работе всех программных блейдов и устройств. Например, атаки, количество срабатываний IPS, уровень критичности угроз, какие запрещенные приложения используют пользователи и пр.
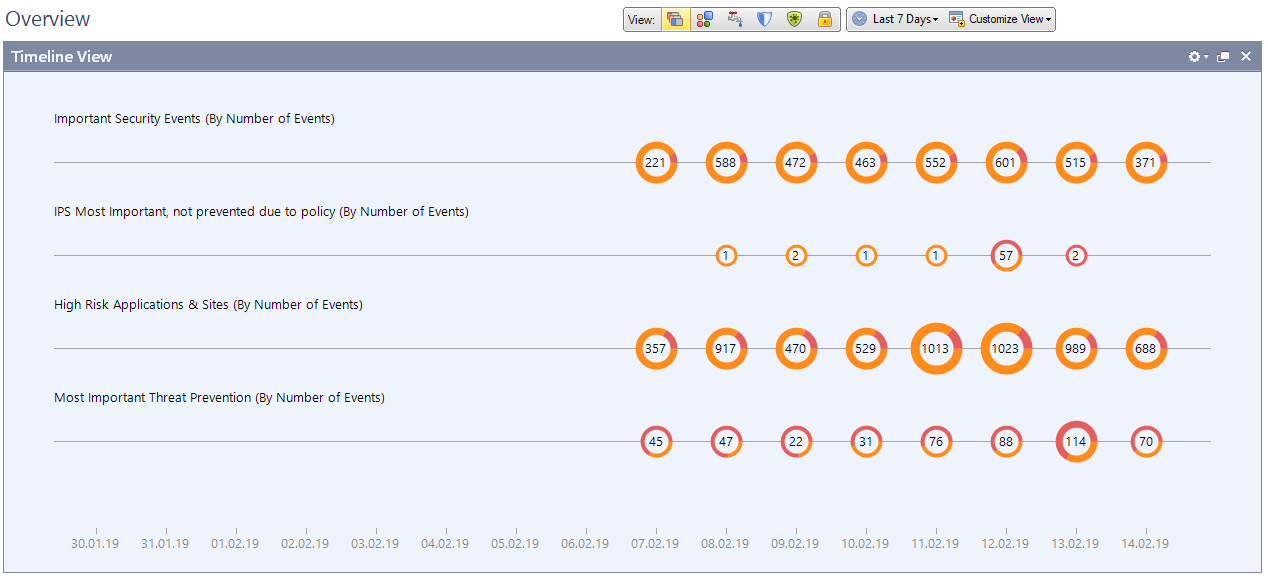
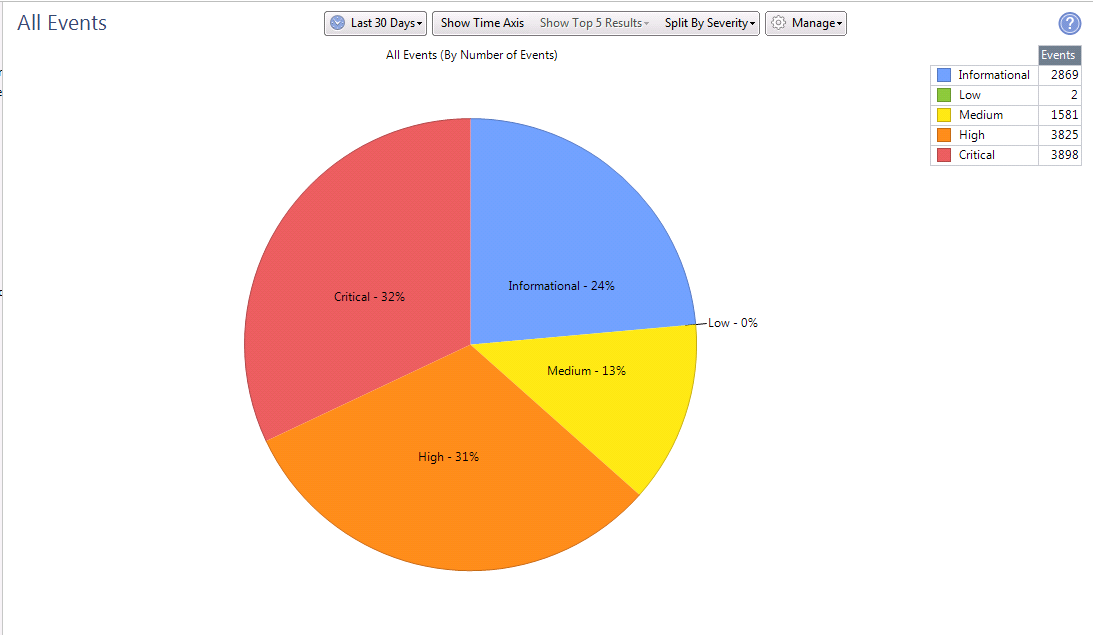
Это статистика за 30 дней по количеству сигнатур и степени их критичности.
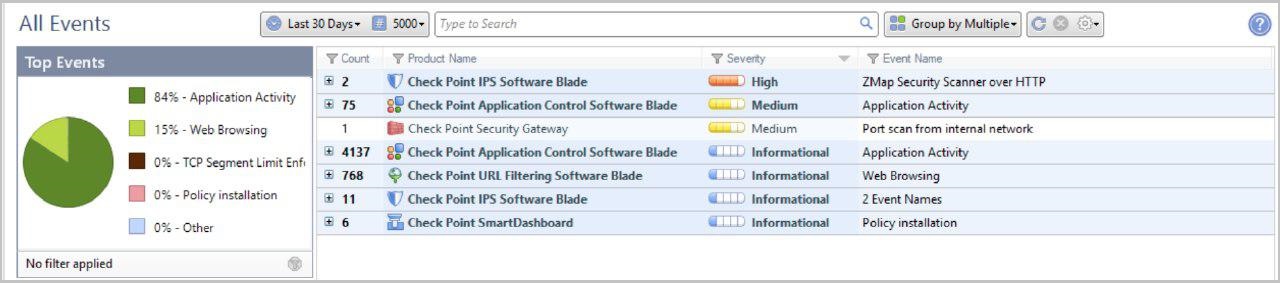
Более подробная информация по детектированным сигнатурам на каждом программном блейде.
Мониторинг
Важно отслеживать как минимум следующие параметры:
- состояние кластера;
- доступность компонент Check Point'а;
- загрузку процессора;
- оставшееся место на диске;
- свободную память.
У Check Point'а есть отдельный программный блейд – Smart Monitoring (отдельная лицензия). В нем можно дополнительно следить за доступностью компонент Check Point'а, нагрузками на отдельные блейды, статусами лицензий.
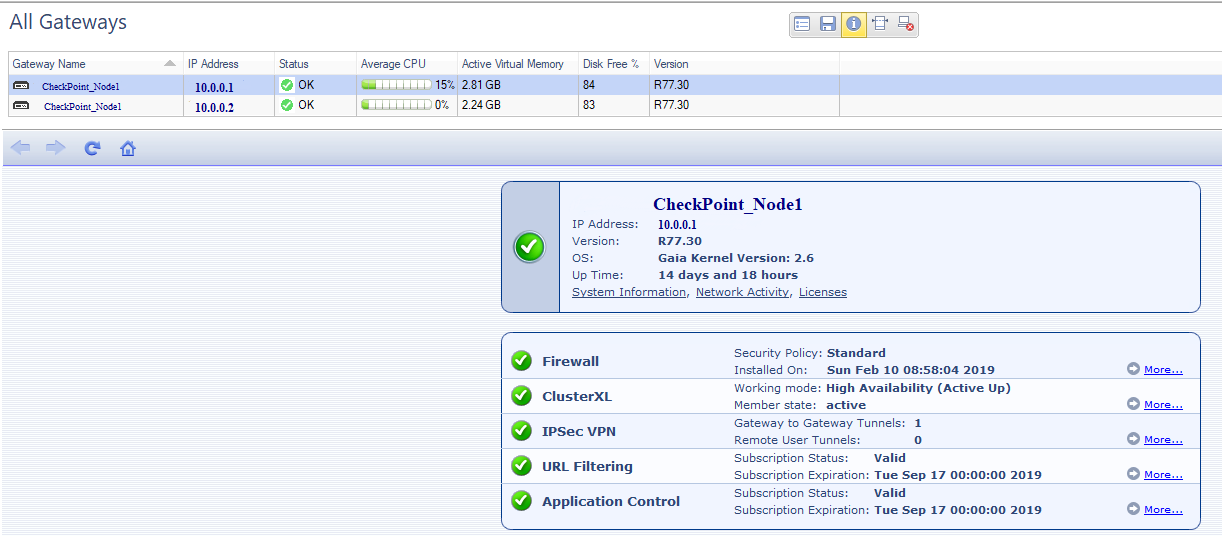
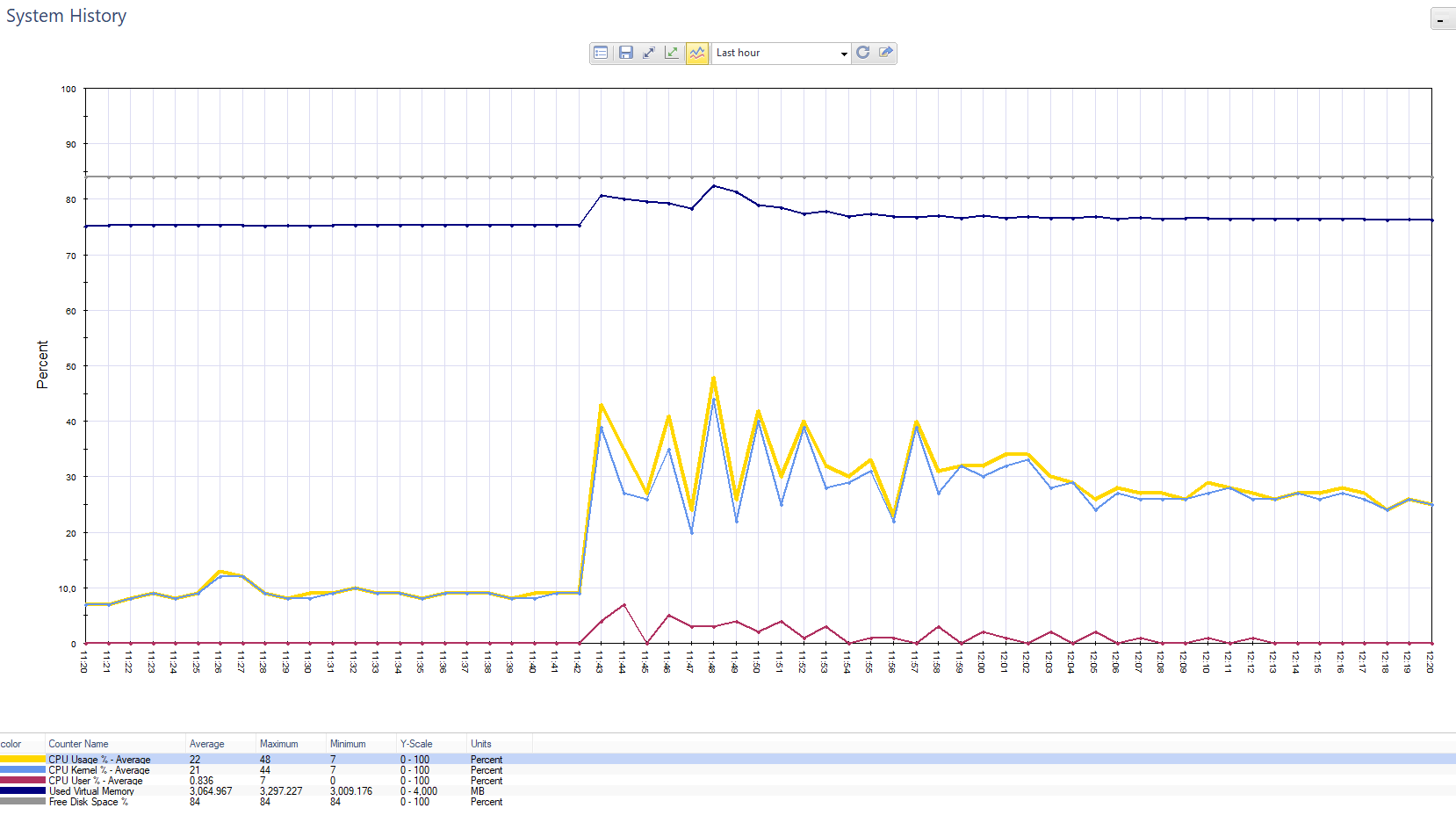
График по нагрузке на Chek Point. Всплеск – это заказчик отправлял push-уведомления 800 тыс. клиентам.

График по нагрузке на блейд Firewall в той же ситуации.
Мониторинг можно настроить и через сторонние сервисы. У нас, например, также используется Nagios, где мы мониторим:
- сетевую доступность оборудования;
- доступность кластерного адреса;
- загрузку CPU по ядрам. При загрузке более 70% приходит оповещение на почту. Такая высокая загрузка может говорить о специфическом трафике (vpn, например). Если это часто повторяется, то, возможно, не хватает ресурсов и стоит расширить пул.
- свободную оперативную память. Если остается меньше 80%, то мы об этом узнаем.
- загрузка диска по определенным партициям, например var/log. Если она скоро забьется, то надо расширять.
- Split Brain (на уровне кластера). Отслеживаем состояние, когда обе ноды становятся активными и между ними пропадает синхронизация.
- High availability mode – отслеживаем, что кластер работает в режиме active-standby. Смотрим на состояния нод – active, standby, down.
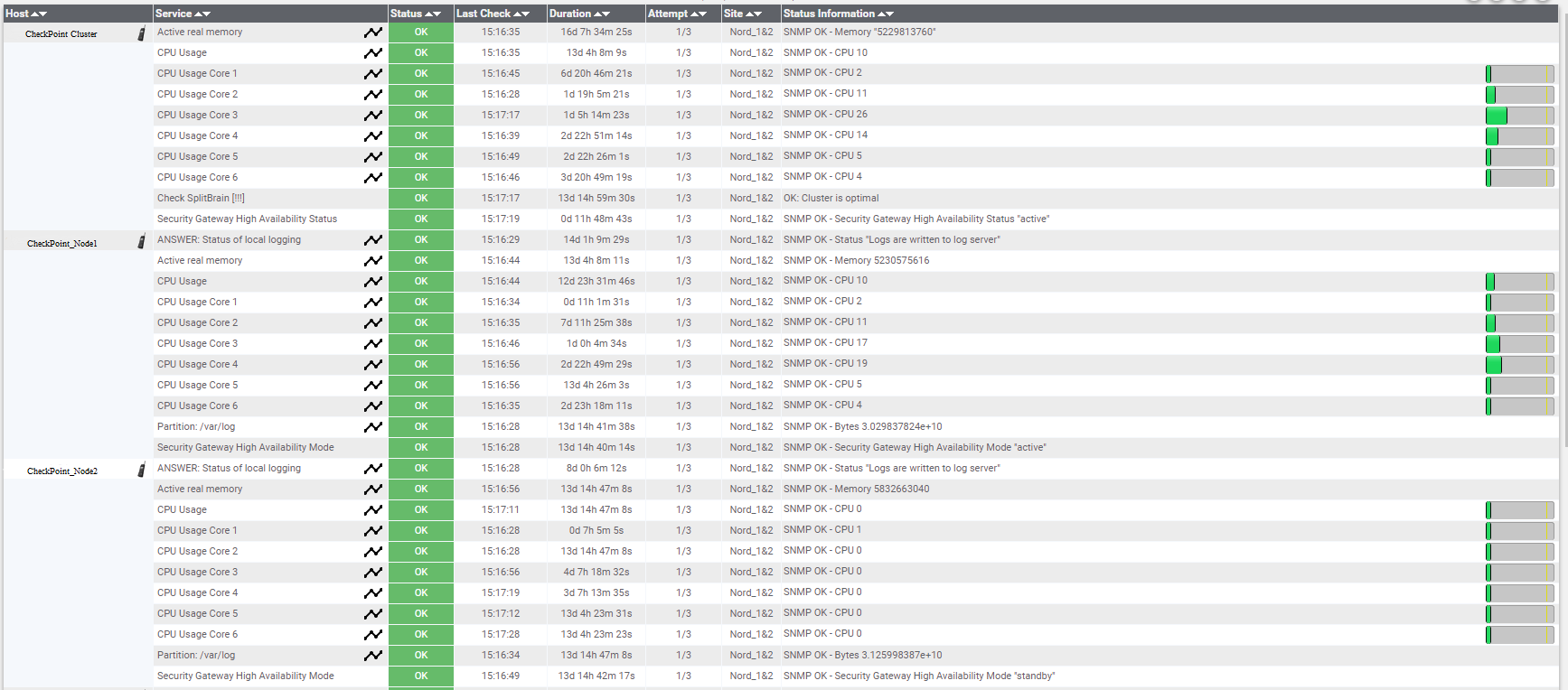
Параметры мониторинга в Nagios.
Также стоит мониторить состояние физических серверов, на которых развернуты ESXi-хосты.
Резервное копирование
Сам вендор рекомендует делать снепшот сразу после инсталляции обновления (Hotfixies).
В зависимости от частоты изменений настраивается полный бэкап раз в неделю или месяц. В нашей практике мы делаем ежедневное инкрементное копирование файлов Check Point и полный бэкап раз в неделю.
На этом все. Это были самые базовые моменты, которые нужно учесть при развертывании виртуальных Check Point’ов. Но даже выполнение этого минимума поможет избежать проблем с их работой.
