
Осенью 2019 года Check Point прекратил поддержку версий R77.XX, и нужно было обновляться. О разнице между версиями, плюсах и минусах перехода на R80 сказано уже немало. Давайте лучше поговорим о том, как, собственно, обновить виртуальные appliance Check Point (CloudGuard for VMware ESXi, Hyper-V, KVM Gateway NGTP) и что может пойти не так.
Итак, у нас было 2 инженера CCSE, более десятка виртуальных кластеров Check Point R77.30, несколько облаков, немножечко хотфиксов и целое море разнообразных багов, глюков и всего такого, всех цветов и размеров, а еще очень сжатые сроки. Погнали!
Содержание:
Подготовка
Обновляем сервер управления
Обновляем кластер
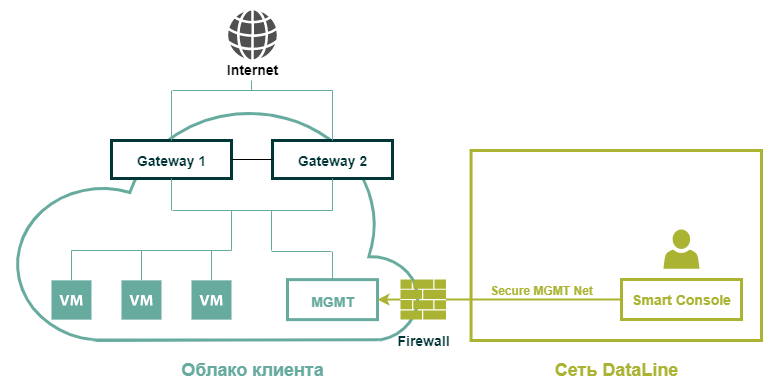
Так выглядит типичная облачная инфраструктура клиента с виртуальным Check Point
Подготовка
Первым делом нужно проверить достаточность ресурсов для обновления. Рекомендованные минимальные требования для R80.20 сейчас выглядят так:
| Device |
CPU |
RAM |
HDD |
| Security Gateway |
2 core |
4 Gb |
От 15 GB |
| SMS |
2 core |
6 Gb |
— |
Рекомендации описаны в документе CP_R80.20_GA_Release_Notes.
Но мы будем реалистами. Если в самой минимальной конфигурации этого достаточно, то, как показывает практика, обычно у нас включена https-инспекция, на SMS работает SmartEvent и т.д., что, разумеется, требует совершенно других мощностей. Но в целом не больших, чем для R77.30.
Но есть нюансы. И касаются они, в первую очередь, размеров физической памяти. Многие операции непосредственно в процессе обновления потребуют места на жестком диске.
Для сервера управления размер свободного пространства на диске будет очень сильно зависеть от объема текущих логов (если мы желаем их сохранить) и от количества сохраненных Database Revisions, хотя они-то нам в большом количестве уже не понадобятся. Разумеется, для нод кластера (если только вы не храните логи еще и локально) это все не имеет значения. Вот как можно проверить наличие необходимого места:
- Подключаемся к Smart Management Server по ssh, заходим в expert mode и вводим команду:
[Expert@cp-sms:0]# df -h - На выходе мы увидим примерно такую конфигурацию:
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_splat-lv_current 30G 7.4G 21G 27% /
/dev/sda1 289M 24M 251M 9% /boot
tmpfs 2.0G 0 2.0G 0% /dev/shm
/dev/mapper/vg_splat-lv_log 243G 177G 53G 78% /var/log - Нас в данный момент интересует раздел /var/log
Учитывайте, что в зависимости от политики хранения и удаления старых лог-файлов, а также размера экспортируемой базы может понадобиться больше места. Если при создании архива свободного места станет меньше, чем указано в политике хранения лог-файлов, система начнет стирать старые логи и НЕ включит их в архив.
Также для самого процесса обновления системе понадобится минимум 13 GB нераспределенного места на жестком диске. Проверить его наличие можно командой:
[Expert@cp-sms:0]# pvs
Увидим приблизительно вот такой вывод:
PV VG Fmt Attr PSize PFree
/dev/sda3 vg_splat lvm2 a- 141.69G 43.69G
В данном случае у нас есть 43 GB. Ресурсов хватает. Можно приступать к обновлению.
Обновляем сервер управления Check Point SMS
Перед началом работ нужно сделать следующее:
- Устанавливаем пакет Migration Tools на сервер управления. Для этого необходимо выгрузить образ с портала Check Point.
- Загружаем архив на сервер управления через WinSCP в папку /var/log/UpgradeR77.30_R80.20 (если нужно, то предварительно создать папку).
- Подключаемся к серверу управления через SSH и пройти в папку с архивом:cd /var/log/UpgradeR77.30_R80.20/
- Разархивируем файл:tar -zxvf ./<название файла>.tgz
- Запускаем утилиту pre_upgrade_verifier командой: ./pre_upgrade_verifier -p $FWDIR -c R77 -t R80.20
- По выполнению команды будет сформирован отчет о несовместимых настройках. Он доступен по адресу: /opt/CPsuite-R77/fw1/log/pre_upgrade_verification_report.(xls, html, txt). Удобнее выгрузить его через SCP и смотреть через браузер.
Для устранения всех несовместимых настроек используйте SK117237. - После повторно запустить утилиту pre_upgrade_verifier, чтобы убедиться, что все причины несовместимости устранены.
- Далее собираем информацию о сетевых интерфейсах, таблице маршрутизации и выгружаем конфигурацию GAIA:
ip a > /var/log/UpgradeR77.30_R80.20/cp-sms-config.txt
ip r > /var/log/UpgradeR77.30_R80.20/cp-sms-config.txt
clish -c "show configuration" > /var/log/UpgradeR77.30_R80.20/cp-sms-config.txt - Выгружаем полученный файл через SCP.
- Делаем snapshot на уровне виртуализации.
- Увеличиваем timeout SSH сессии до 8 часов. Тут как повезет: в зависимости от размеров экспортируемой базы может продолжаться от нескольких минут до нескольких часов. Для этого:
[Expert@HostName]# clish -c "show inactivity-timeout" смотрим текущий timeout clish,
[Expert@HostName]# clish -c "set inactivity-timeout 720" указываем новый timeout clish (в минутах),
[Expert@HostName]# echo $TMOUT смотрим текущий timeout expert mode,
[Expert@HostName]# export TMOUT=3600 указываем новый timeout expert mode (в секундах), если поставить значение 0, то timeout будет выключен. - Подгружаем и монтируем установочный образ SMS.iso к виртуальной машине.
Перед следующим шагом ОБЯЗАТЕЛЬНО еще раз проверьте, что у вас достаточно нераспределенного места на жестком диске (напоминаю, нужно 13 GB).
- Перед началом экспорта конфигурации меняем лог файл командой: fw logswitch
Экспорт конфигурации и логов
- Запускаем утилиту migrate_export для выгрузки конфигурации. Для этого проходим в ранее созданную папку: cd /var/log/UpgradeR77.30_R80.20/ и используем команду: ./migrate export -l /var/log/UpgradeR77.30_R80.20/SMS_w_logs_export_r77_r80.tgz
либо
проходим в папку: cd $FWDIR/bin/upgrade_tools/ и
запускаем оттуда команду: ./migrate export -l /var/log/UpgradeR77.30_R80.20/SMS_w_logs_export_r77_r80.tgz
Если экспортируемая база большая, то процедура может занять несколько часов.
НЕ ОТКЛЮЧАЙТЕ SSH-СЕССИЮ во время процедуры.
В процессе выполнения GAIA покажет вот такое сообщение:
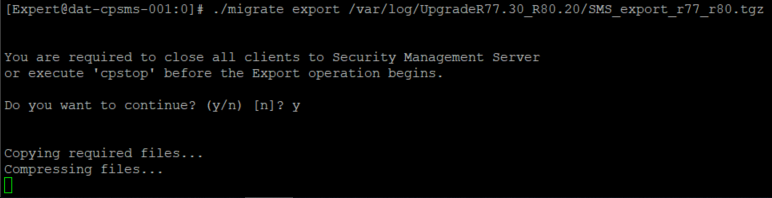
Можно смело сходить за кофе и обедом.
После мы либо увидим сообщение об ошибке вот такого вида:

Либо сообщение об успешном завершении операции:

Если процесс продолжается уже пару часов, то можно его проверить. НЕ ОТКЛЮЧАЯ текущую сессию, установите параллельную сессию по ssh и введите команду top. Среди процессов должен отображаться процесс migrate.
Если без отключения SSH-сессии никак, то используйте: yes | nohup ./migrate export -l /var/log/UpgradeR77.30_R80.20/SMS_w_logs_export_r77_r80.tgz
В этом случае сессию отключать можно, но будет неудобно отслеживать прогресс: проверять завершение процесса придется по команде top, да и в случае проблемы сообщения об ошибке не будет. Поэтому данный вариант мы крайне не рекомендуем. - Снимаем checksum с архива: md5sum /var/log/UpgradeR77.30_R80.20/SMS_w_logs_export_r77_r80.tgz
- Сохраняем в блокнот полученное значение.
- Подключаемся к SMS через SCP и выгружаем архив с конфигурацией на рабочую станцию. Обязательно использовать передачу файлов в формате Binary.



Экспорт базы SmartEvent
Здесь нам понадобится заранее установленный SMS версии R80. Любой тестовый подойдет.
- От SMS нам нужен скрипт, расположенный здесь:$RTDIR/bin/eva_db_backup.csh
- Через SCP загружаем скрипт eva_db_backup.csh в папку: /var/log/UpgradeR77.30_R80.20/
- Подключаемся по SSH к SMS. Скопировать файл в папку: cp /var/log/UpgradeR77.30_R80.20/eva_db_backup.csh
$RTDIR/bin/eva_db_backup.csh
- Изменяем кодировку: dos2unix $RTDIR/bin/eva_db_backup.csh
- Добавляем владельца: chown -v admin:root $RTDIR/bin/eva_db_backup.csh
- Добавляем права: chmod -v 0755 $RTDIR/bin/eva_db_backup.csh
- Запускаем экcпорт базы SmartEvent: $RTDIR/bin/eva_db_backup.csh
- Выгружаем полученные файлы через SCP: $RTDIR/bin/<дата>-db-backup.backup и $RTDIR/bin/eventiaUpgrade.tar на рабочую станцию.
Обновление
- Переходим в WebUI GAIA SMS → CPUSE → Show all packages.
- В случае, когда CPUSE выдает ошибку подключения к облаку Check Point, проверяем DGW, DNS и настройки Proxy.
- Если все верно, а ошибка не исчезает, то нужно обновить CPUSE вручную, руководствуясь sk92449.
- Скачиваем образ и проходим Verifier. В случае необходимости устраняем несоответствия.
В результате должны увидеть вот такое сообщение:
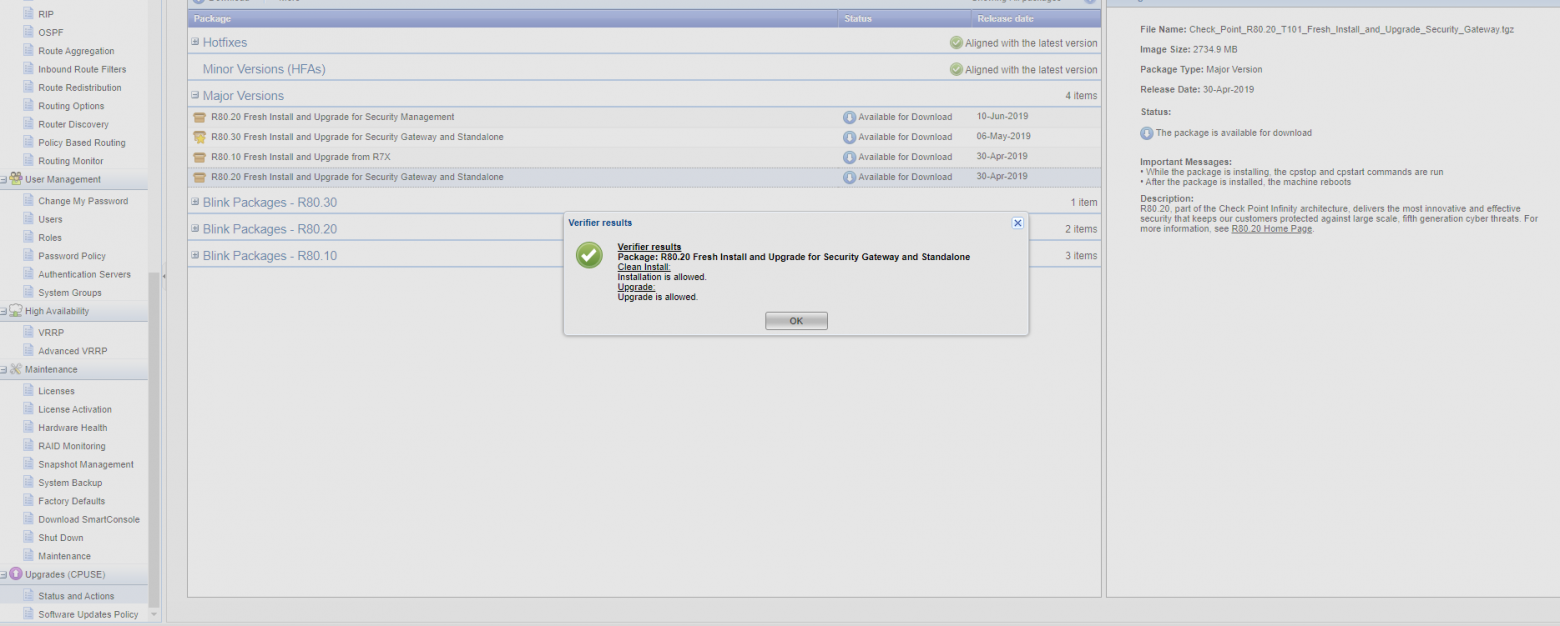
- Выбираем R80.20 Fresh Install and Upgrade for Security Management.
- При установке обновления выбираем Clean Install. После инсталляции система перезагрузится.
- Проходим First Time Wizard.
- После получения доступа проверяем учетные записи.
- Подключаемся к SMS по SSH и меняем shell нашего пользователя на /bin/bash/:
set user <имя пользователя> shell /bin/bash/
save config (в случае, если мы хотим оставить bin/bash/ как shell по умолчанию и после перезагрузки). - Далее подключаемся к SMS через SCP и в режиме Binary передаем архив с конфигурацией SMS_w_logs_export_r77_r80.tgz в папку /var/log/UpgradeR77.30_R80.20/
- Снимаем checksum с архива: md5sum /var/log/UpgradeR77.30_R80.20/SMS_w_logs_export_r77_r80.tgz и сравниваем с предыдущим значением. Checksum должны совпадать.
- Увеличиваем timeout SSH сессии до 8 часов. Для этого:
[Expert@HostName]# clish -c "show inactivity-timeout" смотрим текущий timeout clish,
[Expert@HostName]# clish -c "set inactivity-timeout 720" указываем новый timeout clish (в минутах),
[Expert@HostName]# echo $TMOUT смотрим текущий timeout expert mode,
[Expert@HostName]# export TMOUT=3600 указываем новый timeout expert mode (в секундах). Если поставить значение 0, то timeout будет выключен. - Для импорта настроек запускаем утилиту migrate import. Для этого переходим в папку: cd $FWDIR/bin/upgrade_tools/и запускаем импорт: ./migrate imp
ort -l /var/log/UpgradeR77.30_R80.20/SMS_w_logs_export_r77_r80.tgz

Наслаждаемся жизнью ближайшие пару часов. НЕ ОТКЛЮЧАЙТЕ SSH-СЕССИЮ во время процедуры. В конце процесс migrate выдаст либо сообщение об успешном завершении операции, либо ошибку.
Чек-лист проверок после обновления
- Доступность ресурсов.
- SIC с GW.
- Лицензии. Если лицензии отображаются неверно либо не отображаются на SMS, запускаем команду vsec_central_licence для распределения лицензий.
- Установка политики.
Импорт базы SmartEvent
- Активируйте блейд SmartEvent.
- Подключаемся через WinSCP к SMS и в режиме binary передаем выгруженные ранее файлы <дата>-db-backup.backup и eventiaUpgrade.tar в папку /var/log/UpgradeR77.30_R80.20/
- Запускаем скрипт командой: $RTDIR/bin/eventiaUpgrade.sh -upgrade /var/log/UpgradeR77.30_R80.20/eventiaUpgrade.tar
- Проверяем статус: watch -n 10 eventiaUpgrade.sh
- Проверяем логи в SmartEvent. СОН!
Обновляем кластер Check Point GW (Active/Backup)
Перед началом работ
- Сохраняем конфигурацию GAIA с каждой ноды кластера в файл, для этого воспользоваться командой: clish -c "show configuration" > ./<Название файла>.txt
- Выгружаем файлы при помощи WinSCP.
- Подключаемся к WebUI обеих нод и переходим на вкладку CPUSE → Show all packages.
- Находим пакет обновлений для версии R80.20 Fresh Install, нажимаем Download.
- Проверяем, что CCP-протокол работает в режиме Вroadcast, для этого вводим команду: cphaprob -a if
Если выбран режим Multicast, смените его командой: cphaconf set_ccp broadcast (команда выполняется на каждой ноде). - Устанавливаем Downtime для задействованных нод в вашей системе мониторинга.
- Проверяем, что на уровне виртуализации включены параметры MAC Address Change и Forged Transmits для sync-сети.
Обновление
- Подключаемся по ssh к Active-ноде и запускаем команду для мониторинга состояния кластера: watch -n 2 cphaprob stat
- Возвращаемся в WebUI Stanby ноды на вкладку CPUSE и для выбранного пакета R80.20 Fresh Install запускаем Verifier.
- Анализируем отчет Verifier. Если установка разрешена, идем дальше.
- Выбираем пакет R80.20 Fresh Install и запускаем Upgrade. В процессе Upgrade система будет перезагружена. Настройки GAIA сохраняются. В момент перезагрузки отслеживаем состояние кластера. После загрузки статус обновленной ноды должен смениться на READY. В ряде случаев у нас возникал момент, когда еще не обновленная нода переходила в статус Active Attention и переставала отображать статус обновленной ноды. Не пугайтесь – такой вариант также допустим.
- По завершению обновления открываем SmartDashboard.
- Открываем кластерный объект и меняем версию кластера с R77.30 на R80.20. Жмем Ок. Если при сохранении изменений появляется ошибка:
An internal error has occurred. (Code: 0x8003001D, Could not access file for write operation),
следуйте SK119973. После этого сохраняем изменения и жмем Install Policy. - В настройках убираем галочку с параметра For gateway clusters, if installation on a cluster member fails, do not install on that cluster.
- Устанавливаем политику. Система выдаст ошибку для Active-ноды, которая еще не обновлена.
- Подключаемся к обновленной ноде по ssh и запускаем команду для мониторинга состояния кластера: watch -n 2 cphaprob stat
- Подключаемся к WebUI Active-ноды и переходим во вкладку CPUSE → Show all packages.Находим пакет обновлений для версии R80.20 Fresh Install, жмем Download.
- Устанавливаем Downtime для задействованных нод в вашей системе мониторинга.
- Возвращаемся в WebUI Active-ноды на вкладку CPUSE и для выбранного пакета R80.20 Fresh Install запускаем Verifier.
- Анализируем отчет Verifier. Если установка разрешена, идем дальше.
- Выбираем пакет R80.20 Fresh Install и запускаем Upgrade. В процессе Upgrade система будет перезагружена. Настройки GAIA сохраняются. В момент перезагрузки отслеживаем состояние кластера на уже обновленной ноде. После перезагрузки состояние кластера на обновленной ноде изменится с READY на ACTIVE.
- Когда завершится процесс Upgrade, запускаем SmartDashboard и устанавливаем политику.
Чек-лист проверок после обновления
- Журналы событий в SmartLog, состояние VPN-туннелей.
- Настройки GAIA.
- Восстановление кластера после тестового Failover.
- Лицензии и контракты. В случае если лицензии отображаются неверно либо не отображаются на SMS, запускаем команду. vsec_central_licence для распределения лицензий.
- CoreXL.
- SecureXL.
- Hotfix и CPinfo на двух нодах.
Заключение
В общем-то на этом моменте все – вы обновились.
У нас весь процесс занимал в среднем от 6 до 12 часов, в зависимости от размеров экспортируемых баз. Работы проводили две ночи: одна – для обновления SMS, вторая – для кластера.
Простоя трафика не было, несмотря на то, что все вышеупомянутые ошибки мы проверяли на себе.
Конечно, иногда могут возникнуть и совершенно новые трудности в процессе обновления, но это Check Point, и, как мы все знаем, всегда есть hotfix!
Удачных вам черно-розовых ночей и обновлений!
