Привет, Хабр! В предыдущей статье мы рассмотрели парадигму параллельных вычислений MapReduce. В этой статье мы перейдём от теории к практике и рассмотрим Hadoop – мощный инструментарий для работы с большими данными от Apache foundation.
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.

Как известно парадигму MapReduce предложила компания Google в 2004 году в своей статье MapReduce: Simplified Data Processing on Large Clusters. Поскольку предложенная статья содержала описание парадигмы, но реализация отсутствовала – несколько программистов из Yahoo предложили свою реализацию в рамках работ над web-краулером nutch. Более подробно историю Hadoop можно почитать в статье The history of Hadoop: From 4 nodes to the future of data
Изначально Hadoop был, в первую очередь, инструментом для хранения данных и запуска MapReduce-задач, сейчас же Hadoop представляет собой большой стек технологий, так или иначе связанных с обработкой больших данных (не только при помощи MapReduce).
Основными (core) компонентами Hadoop являются:
Также существует большое количество проектов непосредственно связанных с Hadoop, но не входящих в Hadoop core:
Отдельно хотелось бы отметить проект Apache Spark, который представляет собой движок для распределённой обработки данных. Apache Spark обычно использует компоненты Hadoop, такие как HDFS и YARN для своей работы, при этом сам в последнее время стал популярнее, чем Hadoop:
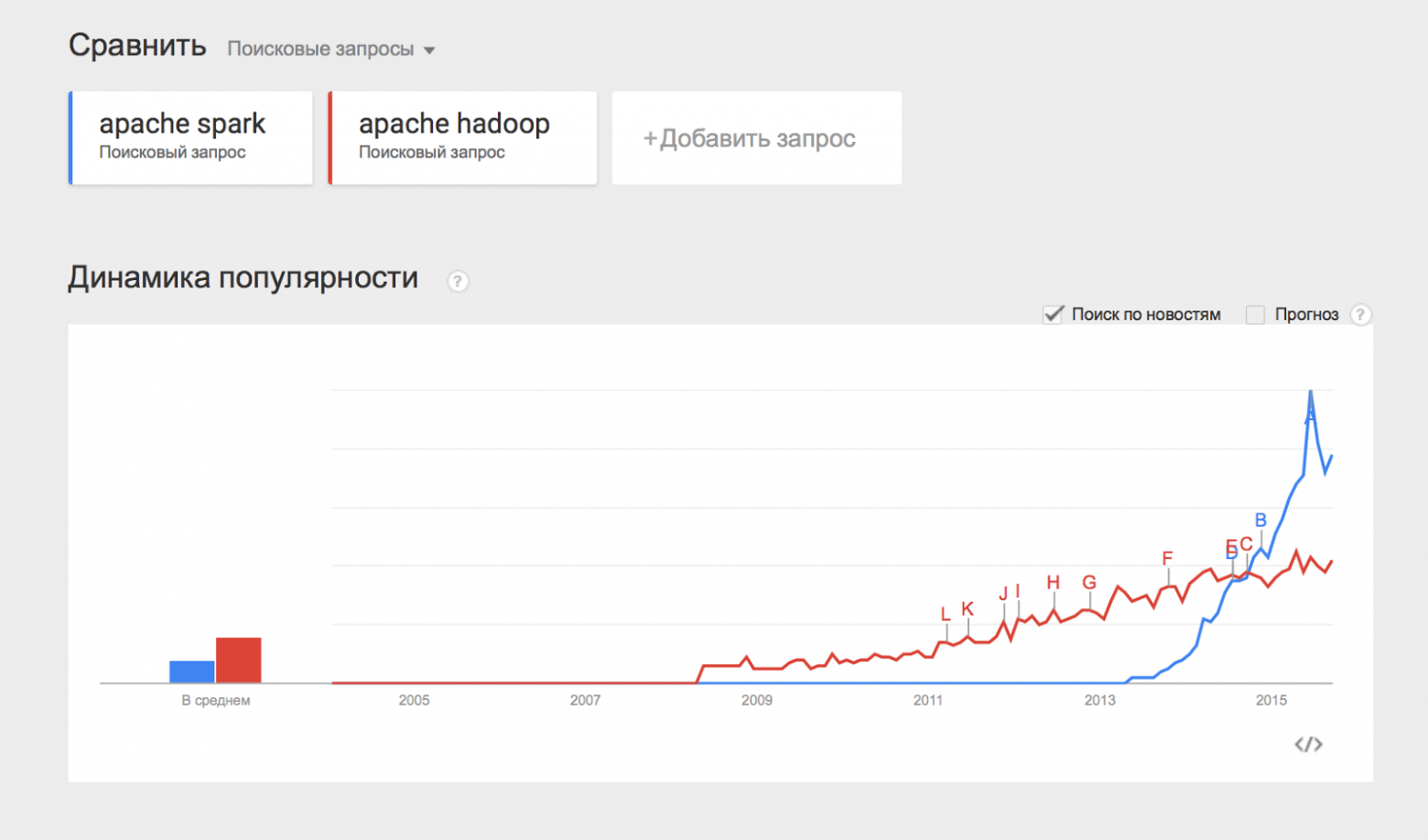
Некоторым из перечисленных компонент будут посвящены отдельные статьи этого цикла материалов, а пока разберём, каким образом можно начать работать с Hadoop и применять его на практике.
Раньше установка Hadoop представляла собой достаточно тяжёлое занятие – нужно было по отдельности конфигурировать каждую машину в кластере, следить за тем, что ничего не забыто, аккуратно настраивать мониторинги. С ростом популярности Hadoop появились компании (такие как Cloudera, Hortonworks, MapR), которые предоставляют собственные сборки Hadoop и мощные средства для управления Hadoop-кластером. В нашем цикле материалов мы будем пользоваться сборкой Hadoop от компании Cloudera.
Для того чтобы установить Hadoop на свой кластер, нужно проделать несколько простых шагов:
Кластер должен работать на одной из поддерживаемых операционных систем семейства linux: RHEL, Oracle Enterprise linux, SLES, Debian, Ubuntu.
После установки вы получите консоль управления кластером, где можно смотреть установленные сервисы, добавлять/удалять сервисы, следить за состоянием кластера, редактировать конфигурацию кластера:
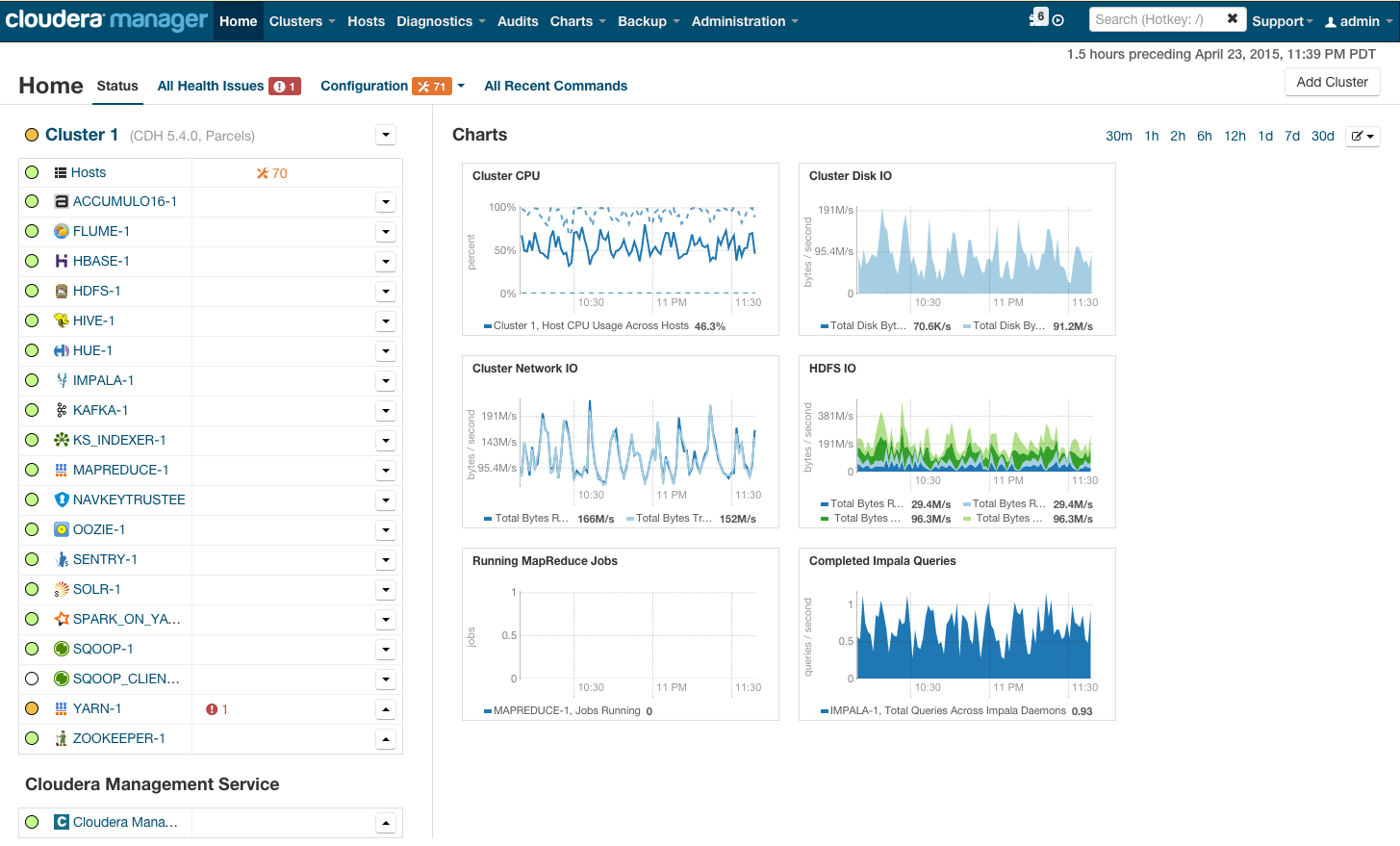
Более подробно с процессом установки Hadoop на кластер при помощи cloudera manager можно ознакомиться по ссылке в разделе Quick Start.
Если же Hadoop планируется использовать для «попробовать» – можно не заморачиваться с приобретением дорогого железа и настройкой Hadoop на нём, а просто скачать преднастроенную виртуальную машину по ссылке и пользоваться настроенным hadoop’ом.
Теперь покажем как запустить MapReduce-задачу на Hadoop. В качестве задачи воспользуемся классическим примером WordCount, который был разобран в предыдущей статье цикла. Для того, чтобы экспериментировать на реальных данных, я подготовил архив из случайных новостей с сайта lenta.ru. Скачать архив можно по ссылке.
Напомню формулировку задачи: имеется набор документов. Необходимо для каждого слова, встречающегося в наборе документов, посчитать, сколько раз встречается слово в наборе.
Решение:
Map разбивает документ на слова и возвращает множество пар (word, 1).
Reduce суммирует вхождения каждого слова:
Теперь задача запрограммировать это решение в виде кода, который можно будет исполнить на Hadoop и запустить.
Самый простой способ запустить MapReduce-программу на Hadoop – воспользоваться streaming-интерфейсом Hadoop. Streaming-интерфейс предполагает, что map и reduce реализованы в виде программ, которые принимают данные с stdin и выдают результат на stdout.
Программа, которая исполняет функцию map называется mapper. Программа, которая выполняет reduce, называется, соответственно, reducer.
Streaming интерфейс предполагает по умолчанию, что одна входящая строка в mapper или reducer соответствует одной входящей записи для map.
Вывод mapper’a попадает на вход reducer’у в виде пар (ключ, значение), при этом все пары соответствующие одному ключу:
Итак, реализуем mapper и reducer на python:
Данные, которые будет обрабатывать Hadoop должны храниться на HDFS. Загрузим наши статьи и положим на HDFS. Для этого нужно воспользоваться командой hadoop fs:
Утилита hadoop fs поддерживает большое количество методов для манипуляций с файловой системой, многие из которых один в один повторяют стандартные утилиты linux. Подробнее с её возможностями можно ознакомиться по ссылке.
Теперь запустим streaming-задачу:
Утилита yarn служит для запуска и управления различными приложениями (в том числе map-reduce based) на кластере. Hadoop-streaming.jar – это как раз один из примеров такого yarn-приложения.
Дальше идут параметры запуска:
После запуска в консоли можно будет увидеть прогресс выполнения задачи и URL для просмотра более детальной информации о задаче.
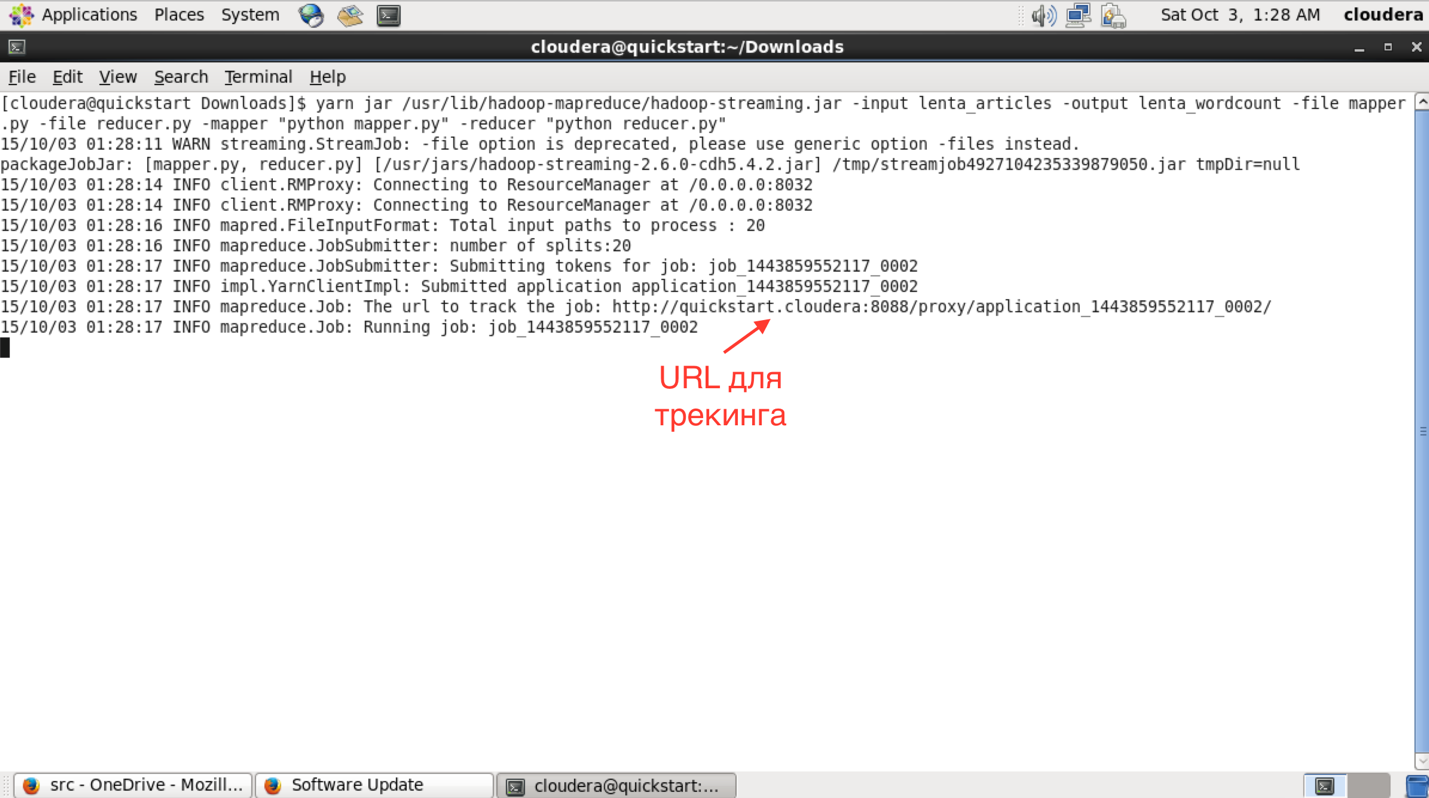
В интерфейсе доступном по этому URL можно узнать более детальный статус выполнения задачи, посмотреть логи каждого маппера и редьюсера (что очень полезно в случае упавших задач).

Результат работы после успешного выполнения складывается на HDFS в папку, которую мы указали в поле output. Просмотреть её содержание можно при помощи команды «hadoop fs -ls lenta_wordcount».
Сам результат можно получить следующим образом:
Команда «hadoop fs -text» выдаёт содержимое папки в текстовом виде. Я отсортировал результат по количеству вхождений слов. Как и ожидалось, самые частые слова в языке – предлоги.
Сам по себе hadoop написан на java, и нативный интерфейс у hadoop-a тоже java-based. Покажем, как выглядит нативное java-приложение для wordcount:
Этот класс делает абсолютно то же самое, что наш пример на Python. Мы создаём классы TokenizerMapper и IntSumReducer, наследуя их от классов Mapper и Reducer соответсвенно. Классы, передаваемые в качестве параметров шаблона, указывают типы входных и выходных значений. Нативный API подразумевает, что функции map на вход подаётся пара ключ-значение. Поскольку в нашем случае ключ пустой – в качестве типа ключа мы определяем просто Object.
В методе Main мы заводим mapreduce-задачу и определяем её параметры – имя, mapper и reducer, путь в HDFS, где находятся входные данные и куда положить результат.
Для компиляции нам потребуются hadoop-овские библиотеки. Я использую для сборки Maven, для которого у cloudera есть репозиторий. Инструкции по его настройке можно найти по ссылке. В итоге файл pom.xmp (который используется maven’ом для описания сборки проекта) у меня получился следующий):
Соберём проект в jar-пакет:
После сборки проекта в jar-файл запуск происходит похожим образом, как и в случае streaming-интерфейса:
Дожидаемся выполнения и проверяем результат:
Как нетрудно догадаться, результат выполнения нашего нативного приложения совпадает с результатом streaming-приложения, которое мы запустили предыдущим способом.
В статье мы рассмотрели Hadoop – программный стек для работы с большими данными, описали процесс установки Hadoop на примере дистрибутива cloudera, показали, как писать mapreduce-программы, используя streaming-интерфейс и нативный API Hadoop’a.
В следующих статьях цикла мы рассмотрим более детально архитектуру отдельных компонент Hadoop и Hadoop-related ПО, покажем более сложные варианты MapReduce-программ, разберём способы упрощения работы с MapReduce, а также ограничения MapReduce и как эти ограничения обходить.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Часть 1: Принципы работы с большими данными, парадигма MapReduce
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.

Общая информация о Hadoop
Как известно парадигму MapReduce предложила компания Google в 2004 году в своей статье MapReduce: Simplified Data Processing on Large Clusters. Поскольку предложенная статья содержала описание парадигмы, но реализация отсутствовала – несколько программистов из Yahoo предложили свою реализацию в рамках работ над web-краулером nutch. Более подробно историю Hadoop можно почитать в статье The history of Hadoop: From 4 nodes to the future of data
Изначально Hadoop был, в первую очередь, инструментом для хранения данных и запуска MapReduce-задач, сейчас же Hadoop представляет собой большой стек технологий, так или иначе связанных с обработкой больших данных (не только при помощи MapReduce).
Основными (core) компонентами Hadoop являются:
- Hadoop Distributed File System (HDFS) – распределённая файловая система, позволяющая хранить информацию практически неограниченного объёма.
- Hadoop YARN – фреймворк для управления ресурсами кластера и менеджмента задач, в том числе включает фреймворк MapReduce.
- Hadoop common
Также существует большое количество проектов непосредственно связанных с Hadoop, но не входящих в Hadoop core:
- Hive – инструмент для SQL-like запросов над большими данными (превращает SQL-запросы в серию MapReduce–задач);
- Pig – язык программирования для анализа данных на высоком уровне. Одна строчка кода на этом языке может превратиться в последовательность MapReduce-задач;
- Hbase – колоночная база данных, реализующая парадигму BigTable;
- Cassandra – высокопроизводительная распределенная key-value база данных;
- ZooKeeper – сервис для распределённого хранения конфигурации и синхронизации изменений этой конфигурации;
- Mahout – библиотека и движок машинного обучения на больших данных.
Отдельно хотелось бы отметить проект Apache Spark, который представляет собой движок для распределённой обработки данных. Apache Spark обычно использует компоненты Hadoop, такие как HDFS и YARN для своей работы, при этом сам в последнее время стал популярнее, чем Hadoop:
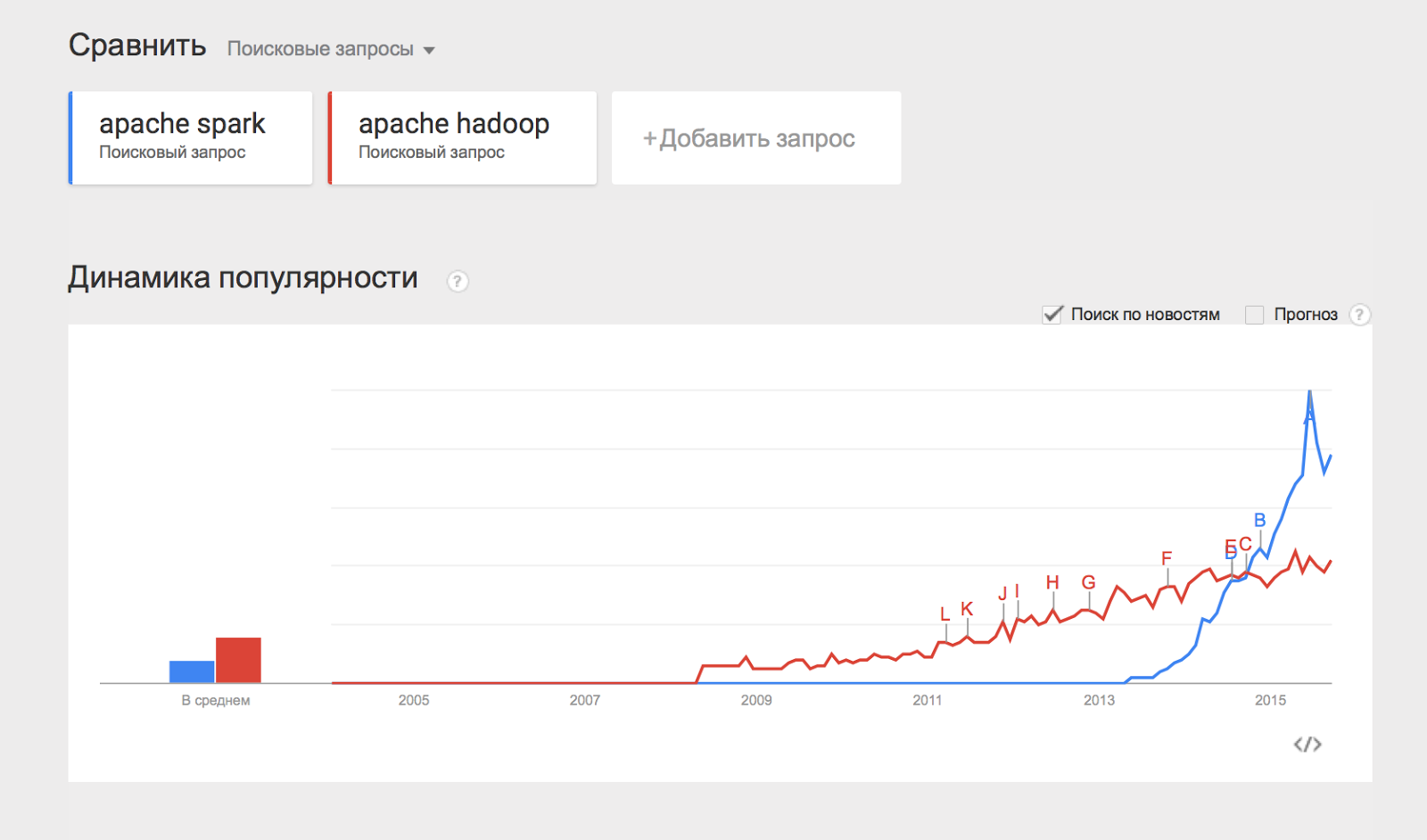
Некоторым из перечисленных компонент будут посвящены отдельные статьи этого цикла материалов, а пока разберём, каким образом можно начать работать с Hadoop и применять его на практике.
Установка Hadoop на кластер при помощи Cloudera Manager
Раньше установка Hadoop представляла собой достаточно тяжёлое занятие – нужно было по отдельности конфигурировать каждую машину в кластере, следить за тем, что ничего не забыто, аккуратно настраивать мониторинги. С ростом популярности Hadoop появились компании (такие как Cloudera, Hortonworks, MapR), которые предоставляют собственные сборки Hadoop и мощные средства для управления Hadoop-кластером. В нашем цикле материалов мы будем пользоваться сборкой Hadoop от компании Cloudera.
Для того чтобы установить Hadoop на свой кластер, нужно проделать несколько простых шагов:
- Скачать Cloudera Manager Express на одну из машин своего кластера отсюда;
- Присвоить права на выполнение и запустить;
- Следовать инструкциям установки.
Кластер должен работать на одной из поддерживаемых операционных систем семейства linux: RHEL, Oracle Enterprise linux, SLES, Debian, Ubuntu.
После установки вы получите консоль управления кластером, где можно смотреть установленные сервисы, добавлять/удалять сервисы, следить за состоянием кластера, редактировать конфигурацию кластера:
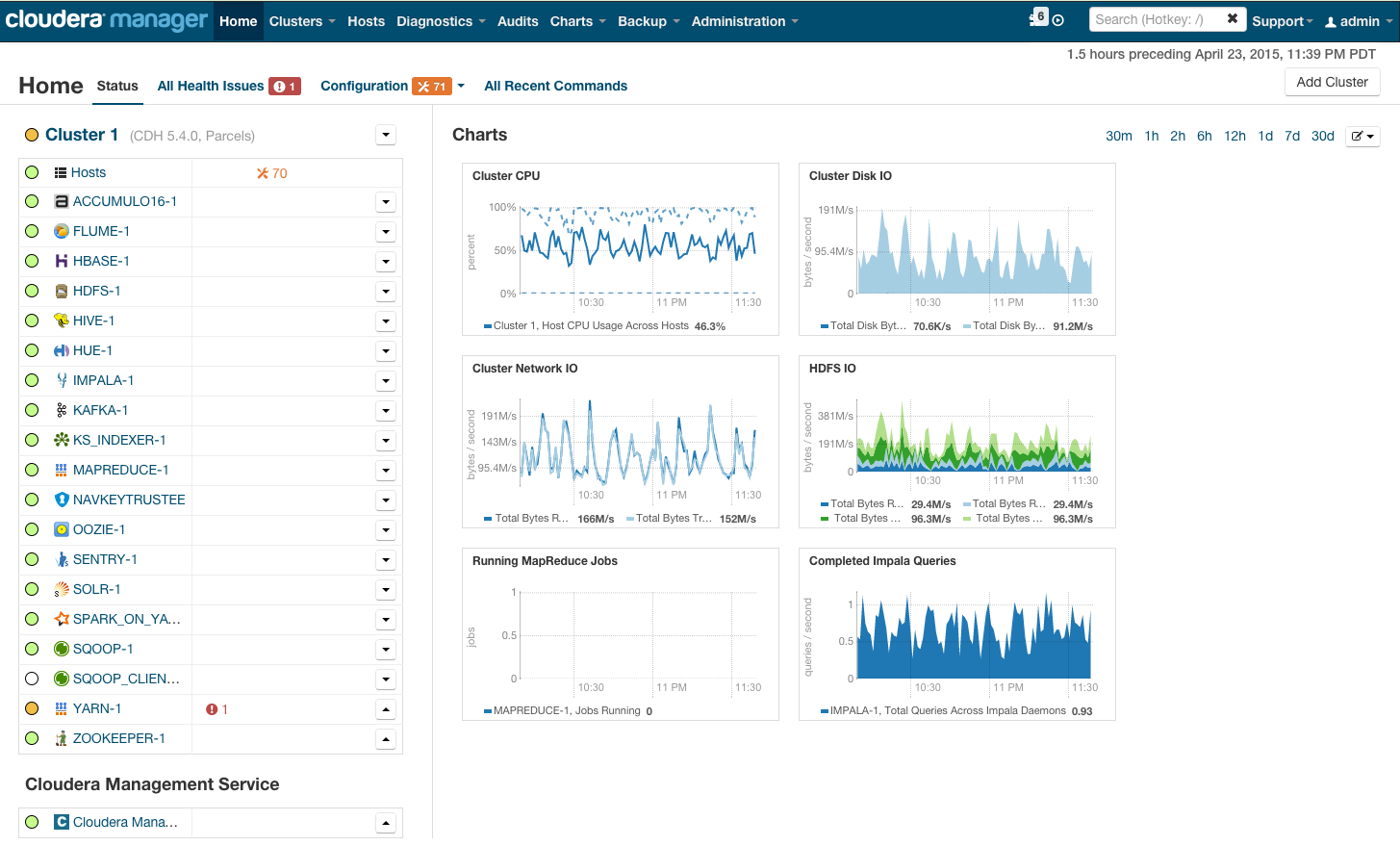
Более подробно с процессом установки Hadoop на кластер при помощи cloudera manager можно ознакомиться по ссылке в разделе Quick Start.
Если же Hadoop планируется использовать для «попробовать» – можно не заморачиваться с приобретением дорогого железа и настройкой Hadoop на нём, а просто скачать преднастроенную виртуальную машину по ссылке и пользоваться настроенным hadoop’ом.
Запуск MapReduce программ на Hadoop
Теперь покажем как запустить MapReduce-задачу на Hadoop. В качестве задачи воспользуемся классическим примером WordCount, который был разобран в предыдущей статье цикла. Для того, чтобы экспериментировать на реальных данных, я подготовил архив из случайных новостей с сайта lenta.ru. Скачать архив можно по ссылке.
Напомню формулировку задачи: имеется набор документов. Необходимо для каждого слова, встречающегося в наборе документов, посчитать, сколько раз встречается слово в наборе.
Решение:
Map разбивает документ на слова и возвращает множество пар (word, 1).
Reduce суммирует вхождения каждого слова:
|
|
Теперь задача запрограммировать это решение в виде кода, который можно будет исполнить на Hadoop и запустить.
Способ №1. Hadoop Streaming
Самый простой способ запустить MapReduce-программу на Hadoop – воспользоваться streaming-интерфейсом Hadoop. Streaming-интерфейс предполагает, что map и reduce реализованы в виде программ, которые принимают данные с stdin и выдают результат на stdout.
Программа, которая исполняет функцию map называется mapper. Программа, которая выполняет reduce, называется, соответственно, reducer.
Streaming интерфейс предполагает по умолчанию, что одна входящая строка в mapper или reducer соответствует одной входящей записи для map.
Вывод mapper’a попадает на вход reducer’у в виде пар (ключ, значение), при этом все пары соответствующие одному ключу:
- Гарантированно будут обработаны одним запуском reducer’a;
- Будут поданы на вход подряд (то есть если один reducer обрабатывает несколько разных ключей – вход будет сгруппирован по ключу).
Итак, реализуем mapper и reducer на python:
#mapper.py
import sys
def do_map(doc):
for word in doc.split():
yield word.lower(), 1
for line in sys.stdin:
for key, value in do_map(line):
print(key + "\t" + str(value)) #reducer.py
import sys
def do_reduce(word, values):
return word, sum(values)
prev_key = None
values = []
for line in sys.stdin:
key, value = line.split("\t")
if key != prev_key and prev_key is not None:
result_key, result_value = do_reduce(prev_key, values)
print(result_key + "\t" + str(result_value))
values = []
prev_key = key
values.append(int(value))
if prev_key is not None:
result_key, result_value = do_reduce(prev_key, values)
print(result_key + "\t" + str(result_value)) Данные, которые будет обрабатывать Hadoop должны храниться на HDFS. Загрузим наши статьи и положим на HDFS. Для этого нужно воспользоваться командой hadoop fs:
wget https://www.dropbox.com/s/opp5psid1x3jt41/lenta_articles.tar.gz
tar xzvf lenta_articles.tar.gz
hadoop fs -put lenta_articlesУтилита hadoop fs поддерживает большое количество методов для манипуляций с файловой системой, многие из которых один в один повторяют стандартные утилиты linux. Подробнее с её возможностями можно ознакомиться по ссылке.
Теперь запустим streaming-задачу:
yarn jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar\
-input lenta_articles\
-output lenta_wordcount\
-file mapper.py\
-file reducer.py\
-mapper "python mapper.py"\
-reducer "python reducer.py"Утилита yarn служит для запуска и управления различными приложениями (в том числе map-reduce based) на кластере. Hadoop-streaming.jar – это как раз один из примеров такого yarn-приложения.
Дальше идут параметры запуска:
- input – папка с исходными данными на hdfs;
- output – папка на hdfs, куда нужно положить результат;
- file – файлы, которые нужны в процессе работы map-reduce задачи;
- mapper – консольная команда, которая будет использоваться для map-стадии;
- reduce – консольная команда которая будет использоваться для reduce-стадии.
После запуска в консоли можно будет увидеть прогресс выполнения задачи и URL для просмотра более детальной информации о задаче.
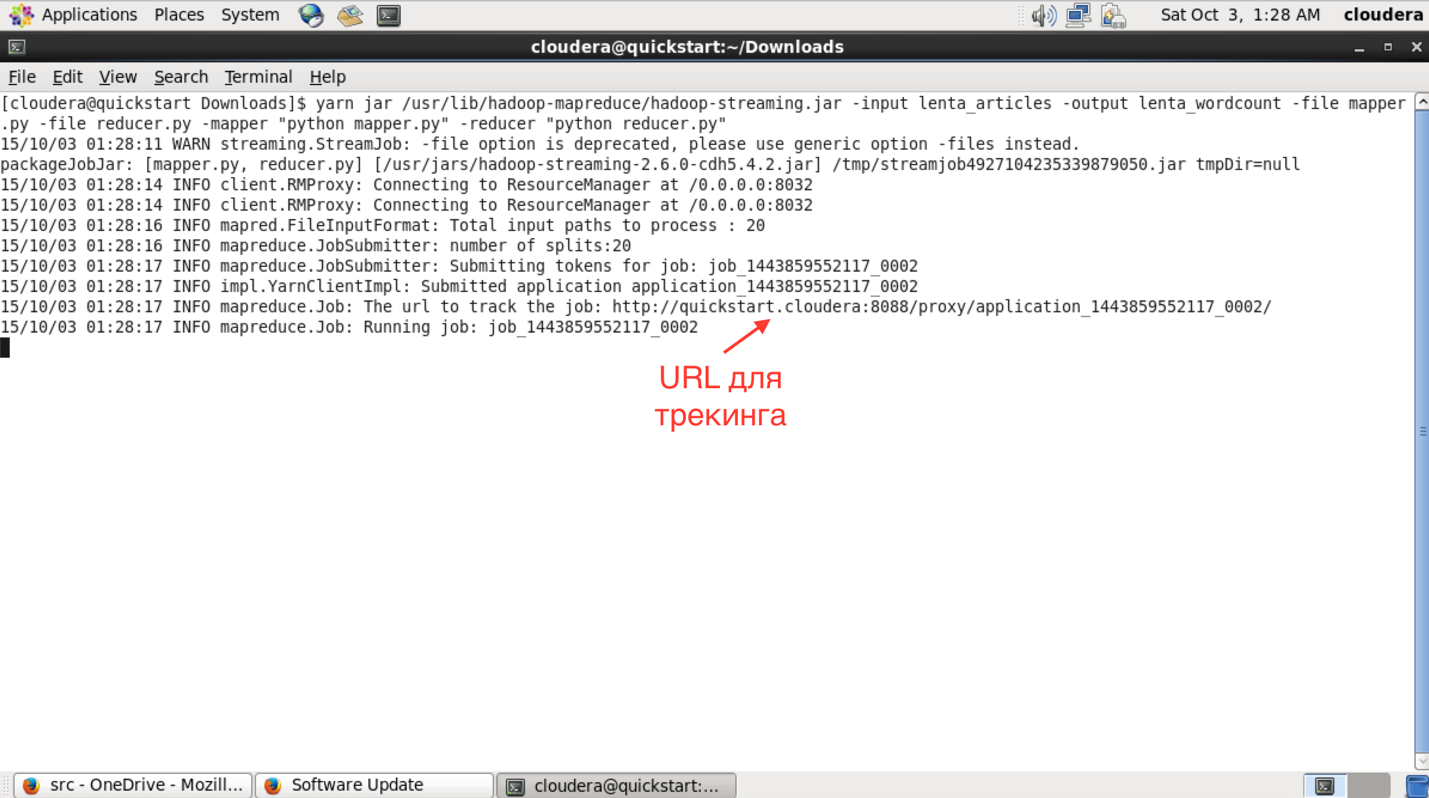
В интерфейсе доступном по этому URL можно узнать более детальный статус выполнения задачи, посмотреть логи каждого маппера и редьюсера (что очень полезно в случае упавших задач).
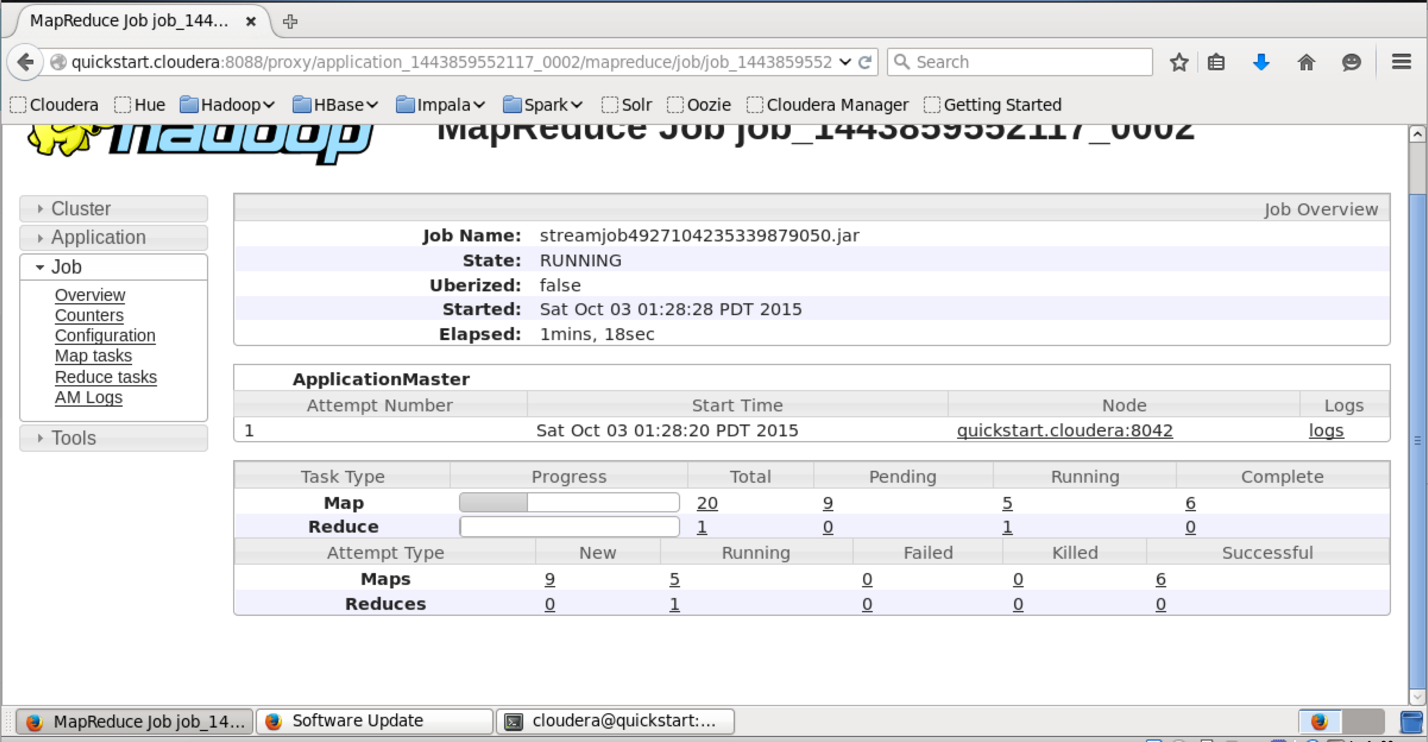
Результат работы после успешного выполнения складывается на HDFS в папку, которую мы указали в поле output. Просмотреть её содержание можно при помощи команды «hadoop fs -ls lenta_wordcount».
Сам результат можно получить следующим образом:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5
с 41
что 43
на 82
и 111
в 194Команда «hadoop fs -text» выдаёт содержимое папки в текстовом виде. Я отсортировал результат по количеству вхождений слов. Как и ожидалось, самые частые слова в языке – предлоги.
Способ №2
Сам по себе hadoop написан на java, и нативный интерфейс у hadoop-a тоже java-based. Покажем, как выглядит нативное java-приложение для wordcount:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://localhost/user/cloudera/lenta_articles"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost/user/cloudera/lenta_wordcount"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Этот класс делает абсолютно то же самое, что наш пример на Python. Мы создаём классы TokenizerMapper и IntSumReducer, наследуя их от классов Mapper и Reducer соответсвенно. Классы, передаваемые в качестве параметров шаблона, указывают типы входных и выходных значений. Нативный API подразумевает, что функции map на вход подаётся пара ключ-значение. Поскольку в нашем случае ключ пустой – в качестве типа ключа мы определяем просто Object.
В методе Main мы заводим mapreduce-задачу и определяем её параметры – имя, mapper и reducer, путь в HDFS, где находятся входные данные и куда положить результат.
Для компиляции нам потребуются hadoop-овские библиотеки. Я использую для сборки Maven, для которого у cloudera есть репозиторий. Инструкции по его настройке можно найти по ссылке. В итоге файл pom.xmp (который используется maven’ом для описания сборки проекта) у меня получился следующий):
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.6.0-cdh5.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-app</artifactId>
<version>2.6.0-cdh5.4.2</version>
</dependency>
</dependencies>
<groupId>org.dca.examples</groupId>
<artifactId>wordcount</artifactId>
<version>1.0-SNAPSHOT</version>
</project>Соберём проект в jar-пакет:
mvn clean packageПосле сборки проекта в jar-файл запуск происходит похожим образом, как и в случае streaming-интерфейса:
yarn jar wordcount-1.0-SNAPSHOT.jar WordCountДожидаемся выполнения и проверяем результат:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5
с 41
что 43
на 82
и 111
в 194Как нетрудно догадаться, результат выполнения нашего нативного приложения совпадает с результатом streaming-приложения, которое мы запустили предыдущим способом.
Резюме
В статье мы рассмотрели Hadoop – программный стек для работы с большими данными, описали процесс установки Hadoop на примере дистрибутива cloudera, показали, как писать mapreduce-программы, используя streaming-интерфейс и нативный API Hadoop’a.
В следующих статьях цикла мы рассмотрим более детально архитектуру отдельных компонент Hadoop и Hadoop-related ПО, покажем более сложные варианты MapReduce-программ, разберём способы упрощения работы с MapReduce, а также ограничения MapReduce и как эти ограничения обходить.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Ссылки на другие статьи цикла:
Часть 1: Принципы работы с большими данными, парадигма MapReduce
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
