
SLA, оно же «service-level agreement» —соглашение-гарантия между заказчиком и поставщиком услуг о том, что получит клиент в плане обслуживания. Также в нем оговариваются компенсации в случае простоев по вине поставщика и так далее. По сути SLA — это верительная грамота, с помощью которой дата-центр или хостинг-провайдер убеждает потенциального клиента в том, что он будет всячески обласкан и вообще. Вопрос в том, что в SLA можно написать все что угодно, да и события, прописанные в этом документе, наступают не слишком часто. SLA — это далеко не ориентир в подборе дата-центра и надеяться на него уж точно не стоит.
Все мы привыкли подписывать какие-то договоры, которые возлагают определенные обязательства. Не исключением является и SLA — обычно самый оторванный от реалий документ, который можно вообразить. Более бесполезен, наверное, только NDA в юрисдикциях, где понятия «коммерческой тайны» толком не существует. А вся проблема в том, что SLA никак не помогает клиенту в правильном выборе поставщика, а только пускает пыль в глаза.
Что чаще всего пишут в публичной версии SLA хостеры, которую показывают публике? Ну, первой строкой идет такой термин, как «надежность» хостера — это обычно цифры от 98 до 99,999%. По сути, эти цифры — лишь красивая выдумка маркетологов. Когда-то, когда хостинг был молодым и дорогим, а облака только снились специалистам (как и широкополосный доступ для всех и каждого), показатель аптайма хостинга был крайне и крайне важен. Сейчас же, когда все поставщики используют плюс-минус одно и тоже оборудование, сидят на один и тех же магистральных сетях и предлагают одни и те же пакеты услуг, показатель аптайма абсолютно непоказателен.
Бывает ли вообще «правильный» SLA
Конечно существуют и идеальные версии SLA, но все они являются нетиповыми документами и прописываются и заключаются между клиентом и поставщиком в ручном режиме. При этом именно этот тип SLA чаще всего касается каких-то подрядных работ, нежели услуг.
Что должно быть в хорошем SLA? Если дать TLDR, то хороший SLA — это регулирующий отношения двух субъектов документ, который дает одной из сторон (заказчику) максимум контроля над процессом. То есть, как это работает в реальном мире: есть документ, который описывает глобальные процессы взаимодействия и регулирует взаимоотношения сторон. Он устанавливает границы, правила и сам по себе становится рычагом воздействия, которым могут пользоваться обе стороны в полной мере. Так, благодаря правильному SLA заказчик просто может заставить исполнителя работать так, как договаривались, а исполнителю — помогает отбиваться от необоснованных договором «хотелок» слишком уж активного клиента. Выглядит так: «У нас в SLA написано так и так, идите отсюда, мы все делаем как оговорено».
То есть «правильный SLA» = «адекватный договор на оказание услуг» и дает контроль над ситуацией. А возможно это только при работе «на равных».
То, что пишут на сайте и то, что ждет в реальности — разные вещи
Вообще, все, что мы будем обсуждать дальше — типичные маркетинговые уловки и проверка на внимательность.
Если взять популярных отечественных хостеров, то одно предложение краше другого: поддержка 25/8, аптайм серверов 99,9999999% времени, куча своих дата-центров минимум по России. Запомните, пожалуйста, момент про дата-центры, мы к нему вернемся чуть позже. А пока поговорим про идеальную статистику отказоустойчивости и с чем сталкивается человек, когда его сервер все же попадает в «0,0000001% падений».
При показателях от 98% и выше, любое падение — событие на грани статистической погрешности. Рабочее оборудование и коннект либо есть, либо их нет. Вы можете годами пользоваться хостером с показателем «надежности» в 50% (согласно его же SLA) без единой проблемы или «падать» раз в месяц на пару дней у ребят, где заявлено 99,99%.
Когда момент падения все же настает (а падают, напоминаем, когда-нибудь все), то тут клиент сталкивается с внутренней корпоративной машиной под названием «поддержка», а на свет достается договор на оказание услуг и SLA. Что это значит:
- скорее всего, за первые четыре часа простоя вы вообще ничего предъявить не сможете, хотя некоторые хостеры начинают пересчет тарифа (выплату компенсации) с момента падения.
- Если сервер недоступен большее время, возможно, вы сможете подать требование на пересчет тарифа.
- И это при условии, что проблема возникла по вине поставщика.
- Если ваша проблема возникла по причине третьей стороны (на магистрали), то вроде как «никто не виноват» и когда решится проблема — вопрос вашей удачливости.
При этом важно понимать, что вы никогда не получаете доступ к инженерной команде, чаще всего вас останавливает первая линия поддержки, которая ведет с вами переписку, пока настоящие инженеры пытаются исправить ситуацию. Знакомый сценарий?
Тут многие надеются на SLA, которое, вроде как, должно защищать вас от подобных ситуаций. Но, по факту, компании редко когда выходят за границы своего собственного документа либо умеют повернуть ситуацию так, чтобы минимизировать собственные расходы. Первоочередная задача SLA — усыпить бдительность и убедить, что даже в случае непредвиденной ситуации «все будет хорошо». Вторая задача SLA — проговорить основные критические моменты и дать поставщику услуг пространство для маневра, то есть возможность списать сбой на что-нибудь, за что поставщик «не несет ответственности».
При этом крупным клиентам, по факту, вообще плевать на компенсации в рамках SLA. «Компенсация по SLA» — это возврат денег в рамках тарифа пропорционально простою оборудования, которая никогда не покроет даже 1% потенциальных денежных и репутационных потерь. В этом случае клиенту намного важнее, чтобы неполадки были устранены в кратчайшие сроки, нежели какой-то там «пересчет тарифа».
«Множество дата-центров по всему миру» — повод для беспокойства
Ситуацию с большим количеством дата-центров у поставщика услуг мы вынесли в отдельную категорию, потому что кроме очевидных вышеописанных проблем с коммуникацией всплывают проблемы и неочевидные. Например, ваш поставщик услуг не имеет доступа к «своим» дата-центрам.
В нашей прошлой статье мы писали о видах партнерских программ и упомянули модель «White Label», суть которой заключается в перепродаже чужих мощностей под своей вывеской. Подавляющее большинство современных хостеров, которые заявляют о наличии «своих дата-центров» во множестве регионов, являются перекупщиками по модели White Label. То есть, физически они не имеют никакого отношения к условному дата-центру в Швейцарии, Германии или Нидерландах.
Тут возникают крайне интересные коллизии. Ваше SLA с поставщиком услуг все еще работает и является действующим, но как-то кардинально повлиять на ситуацию в случае аварии поставщик не способен. Он сам находится в зависимом положении от своего собственного поставщика — дата-центра, у которого и были куплены стойки-мощности для перепродажи.
Таким образом, если вам важны не только красивые формулировки в договоре и SLA о надежности и сервисе, но и способность поставщика услуг оперативно решать проблемы — стоит напрямую работать с владельцем мощностей. На самом деле, это подразумевает прямое взаимодействие непосредственно с дата-центром.
Почему мы не рассматриваем варианты, когда множество ДЦ на самом деле может принадлежать одной компании? Ну, таких компаний очень и очень немного. Один, два, три небольших дата-центра или один крупный — это реально. Но десяток ДЦ, половина из которых в РФ, а вторая на территории Европы — практически невозможно. А это значит, что компаний-перекупщиков намного больше, чем можно себе представить. Вот простой пример:
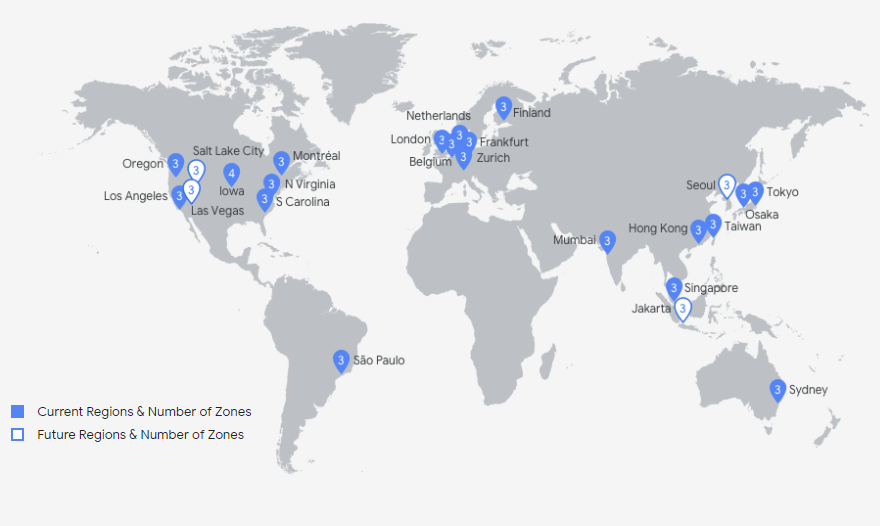
Оцените количество дата-центров сервиса Google Cloud. В Европе их всего шесть. В Лондоне, Амстердаме, Брюсселе, Хельсинки, Франкфурте и Цюрихе. То есть на всех основных магистральных точках. Потому что дата-центр — это дорого, сложно и очень большой проект. А теперь вспомните хостинговые компании откуда-то из Москвы с «десятком дата-центров по всей России и Европе».
Нет, конечно, хороших поставщиков, имеющих партнеров по программе White Label, достаточно, и они оказывают услуги по высшему разряду. Они дают возможность арендовать мощности в ЕС и РФ одновременно через одно и то же окно браузера, принимают оплату в рублях, а не в валюте, и так далее. Но при наступлении случаев, описанных в SLA, они становятся точно такими же заложниками ситуации, как и вы.
Это еще раз напоминает нам, что SLA бесполезен, если вы не имеете понятия о структуре организации и мощностей поставщика.
Что в итоге
Падение серверов — это всегда неприятное событие и случиться оно может с кем угодно и где угодно. Вопрос в том, какую степень контроля за ситуацией вы хотите. Сейчас на рынке не слишком много прямых поставщиков мощностей, а если говорить о крупных игроках, то им принадлежит, условно, только один ДЦ где-нибудь в Москве из десятка по всей Европе, к которым вы можете получить доступ.
Тут каждый клиент должен сам для себя решать: я выбираю комфорт прямо сейчас или трачу время и силы на поиск дата-центра в приемлемой точке России или Европы, где смогу разместить свое оборудование или купить мощности. В первом случае подойдут стандартные решения, которые сейчас есть на рынке. Во втором — придется попотеть.
В первую очередь нужно выявить, является ли продавец услуг непосредственным владельцем мощностей/дата-центра. Очень многие перекупщики по модели White Label изо всех сил маскируют свой статус и в этом случае надо смотреть на какие-то косвенные признаки. Например, если «их европейские ДЦ» имеют какие-то специфические названия и логотипы, отличающиеся от названия компании-поставщика. Или если где-то мелькает слово «партнеры». Партнеры = White Label в 95% случаев.
Далее необходимо ознакомиться с самой структурой компании, а лучше вживую посмотреть на оборудование. Среди дата-центров не нова практика экскурсий или как минимум экскурсионных статей на собственном сайте или в блоге (мы такие писали, раз и два), где они рассказывают о своем дата-центре с фотографиями и подробными описаниями.
Со многими дата-центрами можно договориться о личном визите в офис и мини-экскурсии в сам ДЦ. Там можно оценить степень порядка, возможно, удастся пообщаться с кем-нибудь из инженеров. Понятно, что никто не будет устраивать вам экскурс на производство, если вам нужен один сервер за 300 RUB/месяц, но если вам требуются серьезные мощности, то отдел продаж вполне может пойти вам на встречу. Мы, например, такие экскурсии проводим.
В любом случае следует руководствоваться здравым смыслом и потребностями бизнеса. Например, при необходимости распределенной инфраструктуры (часть серверов в РФ, вторая — в ЕС), проще и выгоднее будет воспользоваться услугами хостеров, имеющих партнерские отношения с европейскими ДЦ по модели White Label. Если же вся ваша инфраструктура будет сконцентрирована в одной точке, то есть в одном дата-центре, то стоит уделить вопросу поиска поставщика некоторое время.
Потому что типовое SLA вам, скорее всего, не поможет. А вот работа с собственником мощностей, а не перекупщиком — значительно ускорит решение возможных проблем.
