Сегодня речь пойдет об интересной технологии, реализованной в СХД Unity/Unity XT, – FAST VP. Если вы впервые услышали о Unity, то по ссылке в конце статьи можно ознакомиться с характеристиками системы. В проектной команде Dell EMC я работал над FAST VP более года. Сегодня хочу рассказать об этой технологии подробнее и раскрыть некоторые детали ее реализации. Разумеется, только те, которые позволено раскрыть. Если вы интересуетесь вопросами эффективного хранения данных или просто не до конца разобрались с документацией, то эта статья наверняка будет полезна и интересна.

Сразу скажу о том, чего в материале не будет. Не будет поиска конкурентов и сравнения с ними. Также не планирую рассказывать о похожих технологиях из open source, потому что любопытствующий читатель и так о них знает. И, конечно, я не собираюсь ничего рекламировать.
FAST VP расшифровывается как Fully Automated Storage Tiering for Virtual Pool. Сложновато? Ничего, сейчас разберемся. Tiering – это способ организации хранения данных, при котором есть несколько уровней (tiers), где эти данные хранятся. Каждый обладает своими характеристиками. Самые важные: производительность, объем и цена хранения единицы информации. Разумеется, между ними есть взаимосвязь.
Важная особенность tiering заключается в том, что доступ к данным предоставляется единообразно вне зависимости от того, на каком уровне хранения в данный момент они находятся, а размер пула равен сумме размеров ресурсов, входящих в него. Тут кроются отличия от кэша: размер кэша не прибавляется к общему объему ресурса (пула в данном случае), а данные кэша дублируют какой-либо фрагмент данных основного носителя (или будут дублировать, если данные из кэша еще не записаны). Также распределение данных по уровням скрыто от пользователя. То есть он не видит какие именно данные расположены на каждом уровне, хотя и может влиять на это опосредованно, путем задания политик (о них позже).
Теперь посмотрим на особенности реализации storage tiering’а в Unity. В Unity выделяют 3 уровня, или tier’а:
Они представлены в порядке убывания производительности и цены. В Extreme performance входят исключительно твердотельные накопители (SSD). В два других tier’а – накопители на магнитных дисках, отличающиеся скоростью вращения и, соответственно, производительностью.
Носители информации из одного уровня и одного размера объединяются в RAID-массив, образуя RAID-группу (RAID group, сокращенно – RG); про доступные и рекомендуемые уровни RAID можно прочитать в официальной документации. Из RAID-групп из одного или нескольких уровней формируются пулы хранения данных (Storage pool), из которых потом и распределяется свободное место. А уже из пула выделяется место под файловые системы и LUN’ы.

Если коротко и абстрактно: чтобы достичь большего результата, используя минимум ресурсов. Если более конкретно, то под результатом обычно понимают совокупность характеристик СХД – скорость и время доступа, стоимость хранения и прочих. Под минимумом ресурсов подразумеваются наименьшие затраты: денег, энергии и так далее. FAST VP как раз реализует механизмы перераспределения данных по разным уровням в СХД Unity/Unity XT. Если вы мне верите, то можно пропустить следующий абзац. Для остальных расскажу чуть подробнее.
Правильное распределение данных по уровням хранения позволяет сэкономить на общей стоимости СХД, пожертвовав скоростью доступа к некоторой редко используемой информации, и повысить производительность, перемещая часто используемые данные на более быстрые носители. Тут кто-то может возразить, что и без tiering’а нормальный админ знает, куда какие данные поместить, какие желательны характеристики СХД под его задачу и т.п. Несомненно, это так, но распределение данных «вручную» имеет свои недостатки:
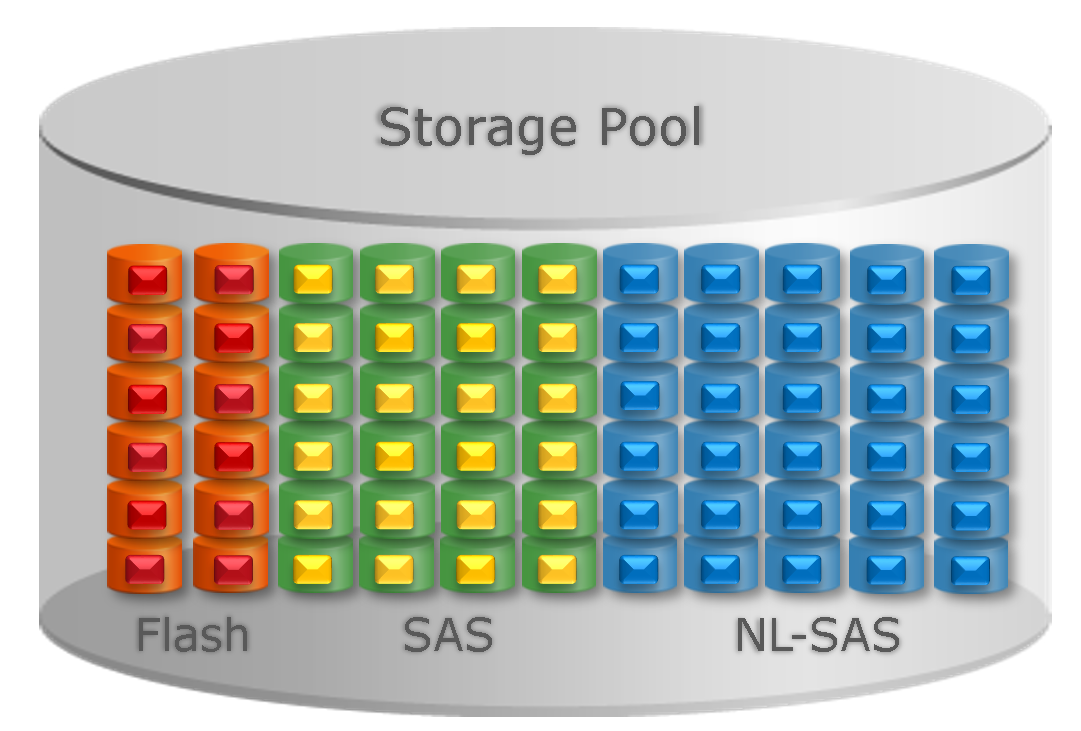
Чтобы storage-админы меньше беспокоились о job security, добавлю, что грамотное планирование ресурсов и тут необходимо. Теперь, когда задачи tiering’а кратко обрисованы, давайте посмотрим, чего можно ожидать от FAST VP. Здесь самое время вернуться к определению. Первые два слова – Fully Automated – дословно переводятся как «полностью автоматизированный» и означают, что распределение по уровням происходит автоматически. Ну а Virtual Pool – это пул данных, в который входят ресурсы из разных уровней хранения. Вот как это выглядит:

Забегая вперед, скажу, что FAST VP перемещает данные только внутри одного пула, а не между несколькими пулами.
Сначала поговорим абстрактно. У нас есть пул и некий механизм, который может перераспределять данные внутри этого пула. Помня, что наша задача – достижение максимальной производительности, зададимся вопросом: какими способами ее можно достичь? Их может быть несколько, и тут FAST VP есть что предложить пользователю, так как технология представляет из себя нечто большее, чем просто storage tiering. Вот какими способами FAST VP может увеличить производительность пула:
Прежде чем разбирать то, как эти задачи решаются, нам нужно знать некоторые необходимые факты о работе FAST VP. FAST VP оперирует блоками определённого размера – 256 мегабайт. Это минимальный непрерывный «кусок» данных, который может быть перемещен. В документации его так и называют: slice. С точки зрения FAST VP все RAID-группы состоят из набора таких «кусков». Соответственно, вся статистика ввода-вывода накапливается для таких блоков данных. Почему выбран именно такой размер блока и будет ли он уменьшен? Блок достаточно крупный, но это компромисс между гранулярностью данных (меньше размер блока – точнее распределение) и имеющимися вычислительными ресурсами: при существующих жестких ограничениях на оперативную память и большом количестве блоков данные статистик могут занимать слишком много, и количество расчетов вырастет пропорционально.
Чтобы управлять размещением данных в пуле с включенным FAST VP существуют такие политики:
Они влияют как на первоначальное размещение блока (данные впервые записаны), так и на последующее перераспределение. Когда же данные уже размещены на дисках, перераспределение будет инициировано по расписанию или вручную.
Highest Available Tier пытается разместить новый блок на наиболее производительном уровне. При недостатке места на нем – на следующем по производительности, но потом данные могут быть перемещены на более производительный уровень (при наличии места или вытеснив другие данные). Auto-Tier размещает новые данные на разных уровнях в зависимости от размера доступного пространства, а перераспределяются они в зависимости от востребованности и свободного места. Start High then Auto-Tier – политика по умолчанию и также рекомендуемая. При первоначальном размещении работает как Highest Available Tier, а далее происходит перемещение данных в зависимости от их статистики использования. Политика Lowest Available Tier стремится разместить данные на наименее производительном уровне.
Перенос данных идет с низким приоритетом чтобы не мешать полезной работе СХД, однако есть настройка «Data relocation rate», которая меняет приоритет. Тут есть особенность: не все блоки данных имеют одинаковую очередность перераспределения. Например, блоки, помеченные как метаданные, будут перемещены на более быстрый уровень в первую очередь. Метаданные – это, если можно так выразиться, «данные о данных», некая дополнительная информация, не являющаяся пользовательскими данными, но хранящая их описание. Например, информация в файловой системе о том, в каком блоке находится конкретный файл. Значит, скорость доступа к данным зависит от скорости доступа к метаданным. Учитывая, что метаданные обычно гораздо меньше по размеру, выигрыш от их перемещения на более производительные диски ожидается больше.
Основной критерий для каждого блока, если очень грубо, – характеристика «востребованности» данных, которая зависит от количества операций чтения и записи фрагмента данных. Эта характеристика у нас называется «Температура». Есть востребованные (hot) данные, которые «горячее» невостребованных. Вычисляется она периодически, по умолчанию с интервалом в один час.
Функция вычисления температуры обладает такими свойствами:
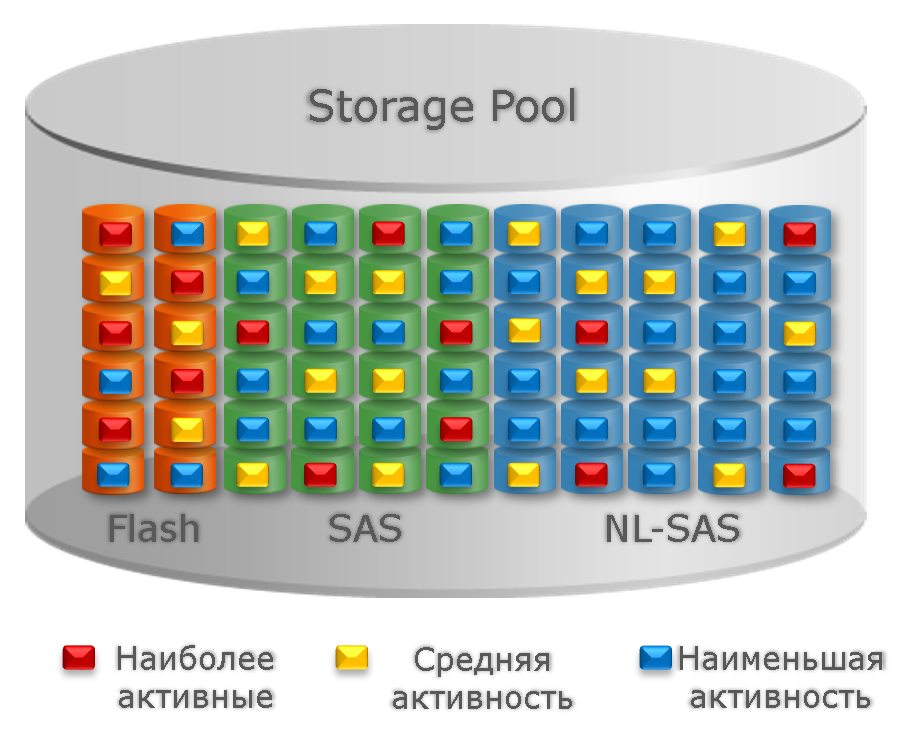
Далее учитываются политики, описанные выше, и свободное место на каждом tier’е. Для наглядности приведу картинку из документации. Тут красным, желтым и синим цветами обозначены блоки с высокой, средней и низкой температурой соответственно.

Но вернемся к задачам. Итак, можно приступать к разбору того, что делается для решения задач FAST VP.
Собственно, это основная задача FAST VP. Остальные, в каком-то смысле, являются производными от нее. В зависимости от выбранной политики данные будут распределяться по разным уровням хранения. Прежде всего учитывается политика размещения, затем температура блоков и размер/скорость RAID-групп.
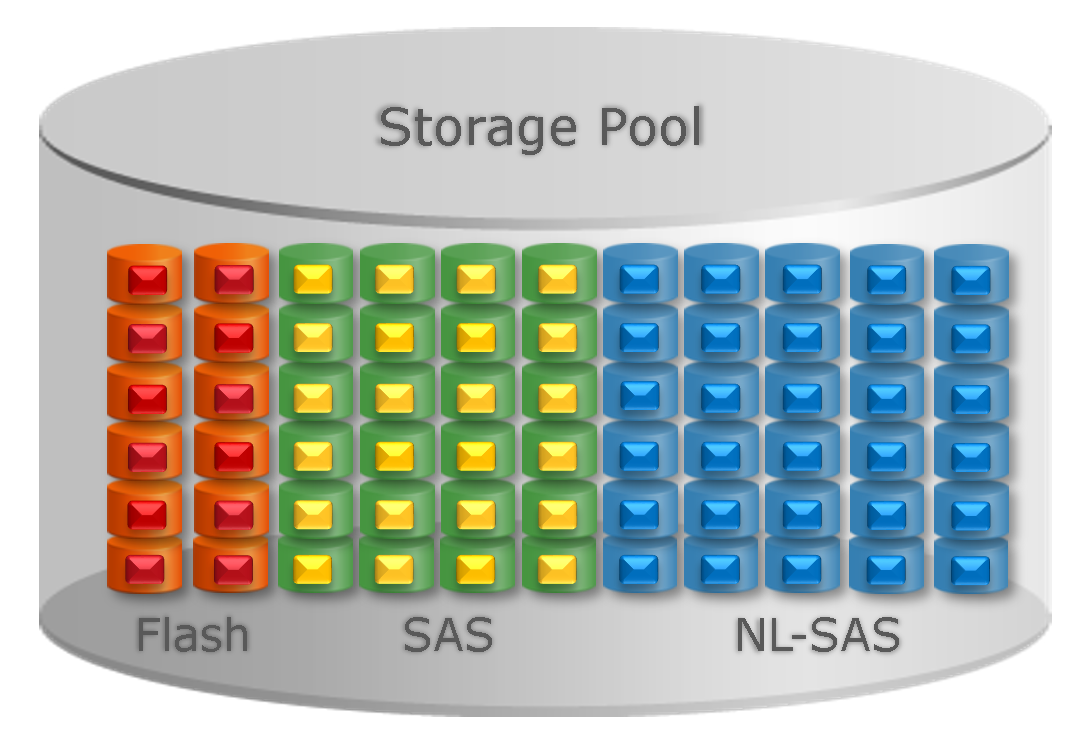
Для политик Highest/Lowest Available Tier все достаточно просто. Для остальных двух дело обстоит так. По разным уровням данные распределяются с учетом размера и производительности RAID-групп: так, чтобы отношение суммарной «температуры» блоков к «условной максимальной производительности» каждой RAID-группы было примерно одинаковым. Таким образом, нагрузка распределяется более-менее равномерно. Более востребованные данные перемещаются на быстрые носители, редко используемые – на более медленные. В идеале распределение должно получиться примерно таким:
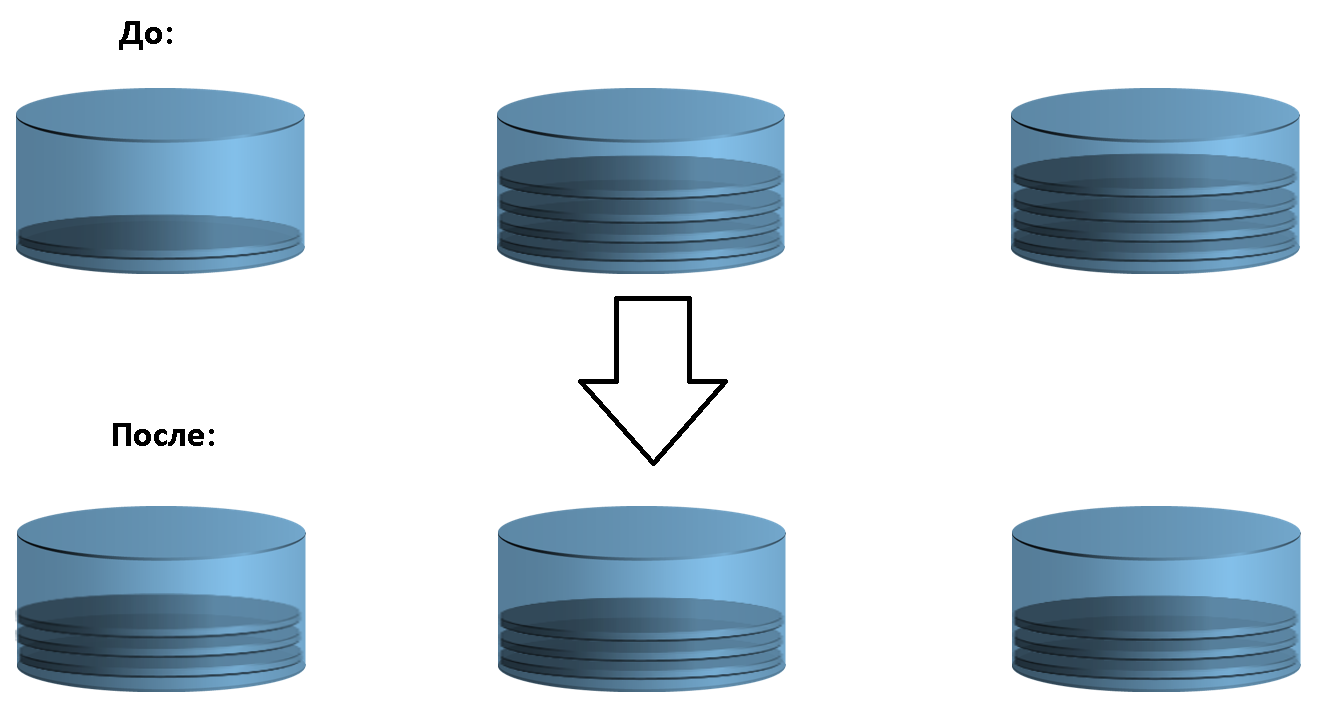
Помните, в начале я писал, что носители информации из одного или нескольких уровней объединяются в один пул? В случае с единственным уровнем для FAST VP тоже есть работа. Чтобы производительность какого-либо уровня была максимальной, желательно распределить данные равномерно между дисками. Это позволит (в теории) получить максимальное количество IOPS. Данные внутри RAID-группы можно считать распределенными равномерно по дискам, а вот между RAID-группами это далеко не всегда так. В случае дисбаланса FAST VP будет перемещать данные между RAID-группами пропорционально их объему и «условной производительности» (в числовом выражении). Для наглядности покажу схему ребалансировки среди трех RAID-групп:

Эта задача является частным случаем предыдущей и выполняется, когда в пул добавляют RAID-группу. Чтобы вновь добавленная RAID-группа не простаивала, часть данных будет перенесена на нее, а значит и нагрузка на все RAID-группы перераспределится.
С помощью выравнивания износа FAST VP может продлить жизнь SSD, хотя эта функция и не относится напрямую к Storage Tiering. Так как данные о температуре уже есть, количество операций записи также учитывается, блоки данных мы перемещать умеем, то логично было бы для FAST VP решить и эту задачу.
В случае, если количество записей в одну RAID-группу значительно превосходит количество записей в другую, то FAST VP перераспределит данные в соответствии с количеством операций записи. С одной стороны, это снимает нагрузку и сохраняет ресурс одних дисков, с другой стороны, добавляет «работы» для менее нагруженных, повышая общую производительность.
Таким образом, FAST VP берет на себя традиционные задачи Storage Tiering и делает еще немного сверх того. Все это позволяет достаточно эффективно хранить данные в СХД семейства Unity.
Если Вы присматриваетесь к данному продукту, то попробовать Unity в деле можно и бесплатно, скачав Unity VSA virtual appliance.

В завершении материала делюсь несколькими полезными ссылками:
Хочется написать о многом, но я понимаю, что не все подробности будут интересны читателю. Например, можно подробнее рассказать про критерии, по которым FAST VP принимает решение о переносе данных, о процессах анализа статистики ввода-вывода. Также совсем не затронута тема взаимодействия с Dynamic Pools, а это тянет на отдельную статью. Можно даже пофантазировать на тему развития этой технологии. Надеюсь, было не скучно, и я вас не утомил. До новых встреч!

Сразу скажу о том, чего в материале не будет. Не будет поиска конкурентов и сравнения с ними. Также не планирую рассказывать о похожих технологиях из open source, потому что любопытствующий читатель и так о них знает. И, конечно, я не собираюсь ничего рекламировать.
Storage Tiering. Цели и задачи FAST VP
FAST VP расшифровывается как Fully Automated Storage Tiering for Virtual Pool. Сложновато? Ничего, сейчас разберемся. Tiering – это способ организации хранения данных, при котором есть несколько уровней (tiers), где эти данные хранятся. Каждый обладает своими характеристиками. Самые важные: производительность, объем и цена хранения единицы информации. Разумеется, между ними есть взаимосвязь.
Важная особенность tiering заключается в том, что доступ к данным предоставляется единообразно вне зависимости от того, на каком уровне хранения в данный момент они находятся, а размер пула равен сумме размеров ресурсов, входящих в него. Тут кроются отличия от кэша: размер кэша не прибавляется к общему объему ресурса (пула в данном случае), а данные кэша дублируют какой-либо фрагмент данных основного носителя (или будут дублировать, если данные из кэша еще не записаны). Также распределение данных по уровням скрыто от пользователя. То есть он не видит какие именно данные расположены на каждом уровне, хотя и может влиять на это опосредованно, путем задания политик (о них позже).
Теперь посмотрим на особенности реализации storage tiering’а в Unity. В Unity выделяют 3 уровня, или tier’а:
- Extreme performance (SSDs)
- Performance (SAS HDD 10k/15k RPM)
- Capacity (NL-SAS HDD 7200 RPM)
Они представлены в порядке убывания производительности и цены. В Extreme performance входят исключительно твердотельные накопители (SSD). В два других tier’а – накопители на магнитных дисках, отличающиеся скоростью вращения и, соответственно, производительностью.
Носители информации из одного уровня и одного размера объединяются в RAID-массив, образуя RAID-группу (RAID group, сокращенно – RG); про доступные и рекомендуемые уровни RAID можно прочитать в официальной документации. Из RAID-групп из одного или нескольких уровней формируются пулы хранения данных (Storage pool), из которых потом и распределяется свободное место. А уже из пула выделяется место под файловые системы и LUN’ы.

А зачем мне Tiering?
Если коротко и абстрактно: чтобы достичь большего результата, используя минимум ресурсов. Если более конкретно, то под результатом обычно понимают совокупность характеристик СХД – скорость и время доступа, стоимость хранения и прочих. Под минимумом ресурсов подразумеваются наименьшие затраты: денег, энергии и так далее. FAST VP как раз реализует механизмы перераспределения данных по разным уровням в СХД Unity/Unity XT. Если вы мне верите, то можно пропустить следующий абзац. Для остальных расскажу чуть подробнее.
Правильное распределение данных по уровням хранения позволяет сэкономить на общей стоимости СХД, пожертвовав скоростью доступа к некоторой редко используемой информации, и повысить производительность, перемещая часто используемые данные на более быстрые носители. Тут кто-то может возразить, что и без tiering’а нормальный админ знает, куда какие данные поместить, какие желательны характеристики СХД под его задачу и т.п. Несомненно, это так, но распределение данных «вручную» имеет свои недостатки:
- требует времени и внимания администратора;
- не всегда удается «перекроить» ресурсы СХД под изменившиеся условия;
- исчезает важное преимущество: унифицированный доступ к ресурсам, находящихся на разных уровнях хранения.
Чтобы storage-админы меньше беспокоились о job security, добавлю, что грамотное планирование ресурсов и тут необходимо. Теперь, когда задачи tiering’а кратко обрисованы, давайте посмотрим, чего можно ожидать от FAST VP. Здесь самое время вернуться к определению. Первые два слова – Fully Automated – дословно переводятся как «полностью автоматизированный» и означают, что распределение по уровням происходит автоматически. Ну а Virtual Pool – это пул данных, в который входят ресурсы из разных уровней хранения. Вот как это выглядит:

Забегая вперед, скажу, что FAST VP перемещает данные только внутри одного пула, а не между несколькими пулами.
Задачи, решаемые FAST VP
Сначала поговорим абстрактно. У нас есть пул и некий механизм, который может перераспределять данные внутри этого пула. Помня, что наша задача – достижение максимальной производительности, зададимся вопросом: какими способами ее можно достичь? Их может быть несколько, и тут FAST VP есть что предложить пользователю, так как технология представляет из себя нечто большее, чем просто storage tiering. Вот какими способами FAST VP может увеличить производительность пула:
- Распределение данных по разным типам дисков, уровням
- Распределение данных среди дисков одного типа
- Распределение данных при расширении пула
Прежде чем разбирать то, как эти задачи решаются, нам нужно знать некоторые необходимые факты о работе FAST VP. FAST VP оперирует блоками определённого размера – 256 мегабайт. Это минимальный непрерывный «кусок» данных, который может быть перемещен. В документации его так и называют: slice. С точки зрения FAST VP все RAID-группы состоят из набора таких «кусков». Соответственно, вся статистика ввода-вывода накапливается для таких блоков данных. Почему выбран именно такой размер блока и будет ли он уменьшен? Блок достаточно крупный, но это компромисс между гранулярностью данных (меньше размер блока – точнее распределение) и имеющимися вычислительными ресурсами: при существующих жестких ограничениях на оперативную память и большом количестве блоков данные статистик могут занимать слишком много, и количество расчетов вырастет пропорционально.
Как FAST VP размещает данные в пуле. Политики
Чтобы управлять размещением данных в пуле с включенным FAST VP существуют такие политики:
- Highest Available Tier
- Auto-Tier
- Start High then Auto-Tier (по умолчанию)
- Lowest Available Tier
Они влияют как на первоначальное размещение блока (данные впервые записаны), так и на последующее перераспределение. Когда же данные уже размещены на дисках, перераспределение будет инициировано по расписанию или вручную.
Highest Available Tier пытается разместить новый блок на наиболее производительном уровне. При недостатке места на нем – на следующем по производительности, но потом данные могут быть перемещены на более производительный уровень (при наличии места или вытеснив другие данные). Auto-Tier размещает новые данные на разных уровнях в зависимости от размера доступного пространства, а перераспределяются они в зависимости от востребованности и свободного места. Start High then Auto-Tier – политика по умолчанию и также рекомендуемая. При первоначальном размещении работает как Highest Available Tier, а далее происходит перемещение данных в зависимости от их статистики использования. Политика Lowest Available Tier стремится разместить данные на наименее производительном уровне.
Перенос данных идет с низким приоритетом чтобы не мешать полезной работе СХД, однако есть настройка «Data relocation rate», которая меняет приоритет. Тут есть особенность: не все блоки данных имеют одинаковую очередность перераспределения. Например, блоки, помеченные как метаданные, будут перемещены на более быстрый уровень в первую очередь. Метаданные – это, если можно так выразиться, «данные о данных», некая дополнительная информация, не являющаяся пользовательскими данными, но хранящая их описание. Например, информация в файловой системе о том, в каком блоке находится конкретный файл. Значит, скорость доступа к данным зависит от скорости доступа к метаданным. Учитывая, что метаданные обычно гораздо меньше по размеру, выигрыш от их перемещения на более производительные диски ожидается больше.
Критерии, которые Fast VP использует в работе
Основной критерий для каждого блока, если очень грубо, – характеристика «востребованности» данных, которая зависит от количества операций чтения и записи фрагмента данных. Эта характеристика у нас называется «Температура». Есть востребованные (hot) данные, которые «горячее» невостребованных. Вычисляется она периодически, по умолчанию с интервалом в один час.
Функция вычисления температуры обладает такими свойствами:
- При отсутствии ввода-вывода данные со временем «остывают».
- При более-менее одинаковой во времени нагрузке температура сначала возрастает и затем стабилизируется в определенном диапазоне.
Далее учитываются политики, описанные выше, и свободное место на каждом tier’е. Для наглядности приведу картинку из документации. Тут красным, желтым и синим цветами обозначены блоки с высокой, средней и низкой температурой соответственно.
Но вернемся к задачам. Итак, можно приступать к разбору того, что делается для решения задач FAST VP.
А. Распределение данных по разным типам дисков, уровням
Собственно, это основная задача FAST VP. Остальные, в каком-то смысле, являются производными от нее. В зависимости от выбранной политики данные будут распределяться по разным уровням хранения. Прежде всего учитывается политика размещения, затем температура блоков и размер/скорость RAID-групп.
Для политик Highest/Lowest Available Tier все достаточно просто. Для остальных двух дело обстоит так. По разным уровням данные распределяются с учетом размера и производительности RAID-групп: так, чтобы отношение суммарной «температуры» блоков к «условной максимальной производительности» каждой RAID-группы было примерно одинаковым. Таким образом, нагрузка распределяется более-менее равномерно. Более востребованные данные перемещаются на быстрые носители, редко используемые – на более медленные. В идеале распределение должно получиться примерно таким:
Б. Распределение данных среди дисков одного типа
Помните, в начале я писал, что носители информации из одного или нескольких уровней объединяются в один пул? В случае с единственным уровнем для FAST VP тоже есть работа. Чтобы производительность какого-либо уровня была максимальной, желательно распределить данные равномерно между дисками. Это позволит (в теории) получить максимальное количество IOPS. Данные внутри RAID-группы можно считать распределенными равномерно по дискам, а вот между RAID-группами это далеко не всегда так. В случае дисбаланса FAST VP будет перемещать данные между RAID-группами пропорционально их объему и «условной производительности» (в числовом выражении). Для наглядности покажу схему ребалансировки среди трех RAID-групп:
В. Распределение данных при расширении пула
Эта задача является частным случаем предыдущей и выполняется, когда в пул добавляют RAID-группу. Чтобы вновь добавленная RAID-группа не простаивала, часть данных будет перенесена на нее, а значит и нагрузка на все RAID-группы перераспределится.
Выравнивание износа SSD
С помощью выравнивания износа FAST VP может продлить жизнь SSD, хотя эта функция и не относится напрямую к Storage Tiering. Так как данные о температуре уже есть, количество операций записи также учитывается, блоки данных мы перемещать умеем, то логично было бы для FAST VP решить и эту задачу.
В случае, если количество записей в одну RAID-группу значительно превосходит количество записей в другую, то FAST VP перераспределит данные в соответствии с количеством операций записи. С одной стороны, это снимает нагрузку и сохраняет ресурс одних дисков, с другой стороны, добавляет «работы» для менее нагруженных, повышая общую производительность.
Таким образом, FAST VP берет на себя традиционные задачи Storage Tiering и делает еще немного сверх того. Все это позволяет достаточно эффективно хранить данные в СХД семейства Unity.
Несколько советов
- Не пренебрегайте чтением документации. Есть best practices, и они работают довольно хорошо. Если им следовать, то серьезных проблем, как правило, не возникает. Остальные советы в основном повторяют или дополняют их.
- Если вы настроили и включили FAST VP, то лучше оставьте включенным. Пусть распределяет данные в отведенное для него время и понемногу, чем раз в год и оказывая серьезное влияние на производительность других задач. В таких случаях перераспределение данных может затянуться надолго.
- Внимательно отнестись к выбору окна релокации. Хоть это и очевидно, но постарайтесь выбрать время с наименьшей нагрузкой на Unity и выделите достаточный промежуток времени.
- Планируйте расширение СХД, делайте это вовремя. Это общая рекомендация, которая важна и для FAST VP тоже. Если объем свободного места очень мал, то и перемещение данных замедлится или станет невозможным. Особенно, если вы пренебрегли пунктом 2.
- Расширяя пул с включенным FAST VP, не следует начинать с самых медленных дисков. То есть либо добавляем все запланированные RAID-группы сразу, либо сначала добавляем самые быстрые диски. В этом случае перераспределение данных на новые «быстрые» диски поднимет общую скорость пула. В противном случае, начав с «медленных» дисков, можно получить очень неприятную ситуацию. Сначала произойдет перенос данных на новые, относительно медленные диски, а после, при добавлении более быстрых, в обратном направлении. Тут есть нюансы, связанные с разными политиками FAST VP, но в общем случае подобная ситуация возможна.
Если Вы присматриваетесь к данному продукту, то попробовать Unity в деле можно и бесплатно, скачав Unity VSA virtual appliance.

В завершении материала делюсь несколькими полезными ссылками:
- Страница СХД Unity
- Dell EMC Unity: FAST VP Theory of Operation – краткое описание функции
- Более полное и подробное описание, формат pdf
- Unity VSA/Cloud edition
Заключение
Хочется написать о многом, но я понимаю, что не все подробности будут интересны читателю. Например, можно подробнее рассказать про критерии, по которым FAST VP принимает решение о переносе данных, о процессах анализа статистики ввода-вывода. Также совсем не затронута тема взаимодействия с Dynamic Pools, а это тянет на отдельную статью. Можно даже пофантазировать на тему развития этой технологии. Надеюсь, было не скучно, и я вас не утомил. До новых встреч!
