Обратите внимание, что данная статья подходит только для версии Directum RX ниже 4.1. Не используйте эту статью для более новых версий Directum RX. Информация и рекомендации, приведенные в этой статье, предоставлена только для ознакомительных целей и не может служить заменой профессиональных консультации Службы поддержки DIRECTUM.
Redis – это система управления базами данных класса NoSQL (не реляционные СУБД), размещаемых целиком в оперативной памяти. Для доступа к данным используется модель «ключ» — «значение». Такая СУБД используется зачастую для хранения кэшей в масштабируемых сервисах, для хранения изображений и данных небольшого размера.
Широкое распространение СУБД Redis получила за счет:
- высокой скорости работы, т.к. все данные хранятся в оперативной памяти;
- кроссплатформенности;
- распространению по BSD лицензии (относится к СПО).
Широту распространения и применимость Redis можно оценить по огромному количеству документации со всевозможными кейсами на официальном сайте проекта.
В случае применения горизонтального масштабирования сервисных служб DirectumRX необходимо использовать отказоустойчивую инсталляцию Redis для корректной работы с сервисом хранилищ DirectumRX и сервисом веб-доступа DirectumRX.
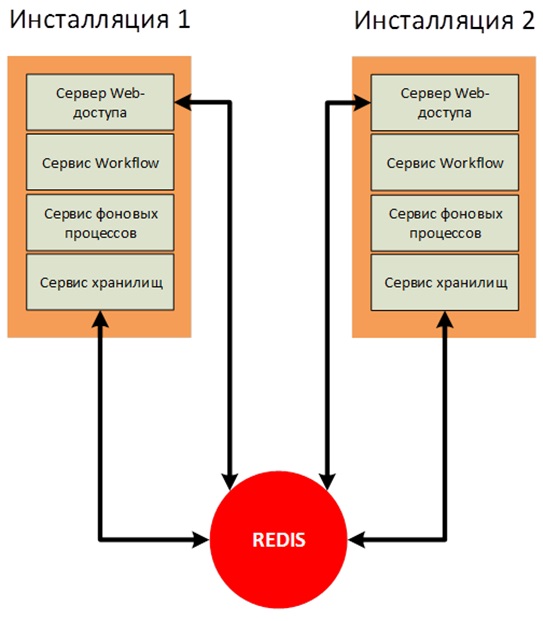
В Redis будут храниться оперативные данные, кэши и прочая информация, которая необходима для работы служб, находящихся в режиме масштабирования, чтобы процесс взаимодействия пользователя с системой не зависел от инсталляции, с который в текущий момент он работает.
Redis не будет хранить важные данные и не будет находиться под высокой нагрузкой. Но в случае выхода из строя Redis работа пользователей при переключении между инсталляциями будет сопровождаться множеством ошибок.
На официальном сайте Redis выделяется 2 способа обеспечения горизонтального масштабирования и отказоустойчивости:
- Использование Redis Sentiel.
- Использование Redis Cluster.
Рассмотрим настройку этих вариантов.
Настройка Redis Sentiel
Вариант с использованием Redis Sentiel (Следящий узел Redis) был реализован в версии Redis 2.4 и состоит в том, что для мониторинга доступности мастера используется дополнительный сервис Redis Sentiel. Он же выполняет настройку узлов реплик, в случае выхода из строя мастера. Определяет какой из SLAVE узлов станет MASTER и выполнит перенастройку на ходу.
Реализует классическую схему:

SLAVE-узлов может быть множество (до 1000 по данным с официального сайта), для продуктивной работы рекомендуется использовать не менее двух SLAVE-узлов.
Обычно схема настраивается таким образом, что на MASTER- и на SLAVE-узлах настраивается сервис Redis Sentiel, и при выходе из строя MASTER-узла, оставшиеся следящие узлы принимают решение о введении в работу нового MASTER.
Актуальная версия Redis доступна для скачивания с официального сайта разработчика продукта. Однако на сайте доступен дистрибутив только для ОС Linux. В своё время, развивался проект Microsoft по портированию Redis на ОС Windows, однако в настоящее время проект остановил развитие на версии 3.2.100, поэтому в данной статье будем рассматривать наиболее актуальный вариант разворачивания – на ОС Linux.
В качестве тестовых узлов будем использовать два виртуальных хоста redis1 и redis2 с установленным дистрибутивом Linux Debian 10.
Первым делом актуализируем списки пакетов из репозитория по умолчанию и устанавливаем Redis:
apt-get update && apt-get upgrade
apt install redis-serverПроверим версию:
root@redis1:/home/user# redis-server -v
Redis server v=5.0.3 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=afa0decbb6de285fПусть redis1 будет выступать в качестве MASTER-узла, а redis2 – в качестве SLAVE-узла.
Для этого в конфигурационных файлах Redis пропишем необходимые параметры, которые позволят создать реплику (пока не отказоустойчивую).
Для redis1 в конфигурационном файле /etc/redis/redis.conf указываем:
#указываем пароль, по которому MASTER будет разрешать работать с ним.
requirepass TestPass Для redis2 в конфигурационном файле /etc/redis/redis.conf указываем:
# Указываем адрес MASTER и порт.
slaveof redis1 6379
# Указываем пароль для работы с мастером.
masterauth TestPass
# Также указываем пароль, чтобы с узлом можно было работать только по паролю.
requirepass TestPass Выполним перезапуск сервисов redis-server на обоих узлах:
root@redis1:/etc/redis# /etc/init.d/redis-server stop
[ ok ] Stopping redis-server (via systemctl): redis-server.service.
root@redis1:/etc/redis# /etc/init.d/redis-server start
[ ok ] Starting redis-server (via systemctl): redis-server.service.
root@redis2:/etc/redis# /etc/init.d/redis-server stop
[ ok ] Stopping redis-server (via systemctl): redis-server.service.
root@redis2:/etc/redis# /etc/init.d/redis-server start
[ ok ] Starting redis-server (via systemctl): redis-server.service.Проверяем на стороне MASTER, что узлы стали репликами и получили необходимые роли:
root@redis1:/etc/redis# redis-cli -a TestPass info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.9.96,port=6379,state=online,offset=28,lag=0
master_replid:56b0a702d5823d107b0ca1ca2c80f8ef650a4b28
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:28
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28На стороне SLAVE видим такую же ситуацию:
root@redis2:/etc/redis# redis-cli -a TestPass info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:slave
master_host:redis1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:14
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:56b0a702d5823d107b0ca1ca2c80f8ef650a4b28
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14Теперь необходимо настроить реплику таким образом, чтобы она автоматически восстанавливалась в случае выхода из строя одного из узлов. Для этого нам понадобится следящий сервис Redis Sentinel.
Исходя из документации, следящий сервис Redis Sentinel умеет выполнять следующие операции:
- Проверяет доступность MASTER и SLAVE узлов и способен оправлять оповещения о недоступности узлов.
- Если MASTER-узел вышел из строя, следящий узел может перевести SLAVE-узел в режим MASTER, а также перенастраивает остальные SLAVE-узлы, и они начинают работать с новым MASTER.
- Вносит изменения в конфигурационные файлы узлов MASTER и SLAVE.
Разместим для чистоты эксперимента следящий сервис на отдельную ВМ redis3.
Подключаем аналогичным способом репозиторий Redis и устанавливаем пакет redis-sentinel:
apt install redis-sentinelПосле установки необходимо внести настройки в конфигурационный файл следящего узла /etc/redis/sentinel.conf:
# Настраиваем мониторинг узла redis1 по порту 6379.
# Последняя цифра 1 - означает количество следящих узлов в кворуме,
# мнение которых учитывается в случае необходимости изменить MASTER-узел.
# То есть можно поднять несколько следящих узлов,
# которые будут выполнять мониторинг MASTER-узла.
sentinel monitor master01 redis1 6379 1
# Ждем 3 секунды, прежде чем принимать решение о сбое узла.
sentinel down-after-milliseconds master01 3000
# Зададим таймаут восстановления MASTER-узла
sentinel failover-timeout master01 6000
# Указываем, сколько SLAVE-узлов необходимо перенастраивать одновременно.
# Необходимо указывать минимальное количество, чтобы не получилось так,
# что все реплики станут недоступны одновременно.
sentinel parallel-syncs master01 1
# Обязательно прописываем прослушиваемые адреса.
bind 192.168.9.97 127.0.0.1 ::1
# И прописываем пароль MASTER-узла.
sentinel auth-pass master01 TestPass
Перезапустим сервис после внесения настроек:
root@redis3:/etc/redis# /etc/init.d/redis-sentinel restart
[ ok ] Restarting redis-sentinel (via systemctl): redis-sentinel.service.Проверим, что следящий сервис увидел MASTER и SLAVE:
root@redis3:/etc/redis# redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=master01,status=ok,address=192.168.9.95:6379,slaves=1,sentinels=1Начинаем эксперименты.
Сымитируем сбой, остановим сервис redis-server на узле redis1 и получим текущую информацию следящего узла:
root@redis3:/etc/redis# redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=master01,status=ok,address=192.168.9.96:6379,slaves=1,sentinels=1Видим, MASTER поменялся.
Восстановим работу узла redis1 и проверим его состояние:
root@redis3:/var/log/redis# redis-cli -h redis1 -p 6379 -a TestPass info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:slave
master_host:192.168.9.96
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:15977
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:6c0c7d0eedccede56f211f2db74a98c4d0ff6d56
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:15977
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:15977Видим, что узел получил роль SLAVE, а узел redis2 является MASTER-узлом.
Сымитируем сбой узла redis2 и проверим состояние следящего узла:
root@redis3:/var/log/redis# redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=master01,status=ok,address=192.168.9.95:6379,slaves=1,sentinels=1И состояние узла redis1:
root@redis3:/var/log/redis# redis-cli -h redis1 -p 6379 -a TestPass info replication
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Replication
role:master
connected_slaves:0
master_replid:6e9d67d6460815b925319c2bafb58bf2c435cffb
master_replid2:6c0c7d0eedccede56f211f2db74a98c4d0ff6d56
master_repl_offset:33610
second_repl_offset:26483
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:33610Отлично, механизм работает. Но теперь возник вопрос, как мы будем подключать наши сервисы DirectumRX, ведь для них нужен адрес единственного узла. Решим ситуацию с помощью сервисной службы HAProxy.
Проксирование обращения к узлам Redis
В качестве reverse-прокси для узлов Redis может выступать любой проксирующий tcp-сервис. В данной статье рассмотрим использование HAProxy, поскольку это специализированный инструмент, предназначенный для обеспечения высокой доступности и балансировки нагрузки, и используется повсеместно известными онлайн сервисами. Подробнее о HAProxy можно почитать на странице разработчика.
Установим HAProxy на узел redis3:
root@redis3:/var/log/redis# apt install haproxyВ конфигурационный файл HAProxy /etc/haproxy/haproxy.cfg, добавим настройки для проксирования запросов к узлам Redis:
…
frontend ft_redis
bind *:6379 name redis
mode tcp
default_backend bk_redis
backend bk_redis
mode tcp
option tcp-check
tcp-check connect
# Не забываем, что все узлы принимают запросы только при наличии пароля.
tcp-check send AUTH\ TestPass\r\n
tcp-check expect string +OK
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send info\ replication\r\n
# Работаем только с MASTER, т.к. SLAVE по умолчанию работает только на чтение.
tcp-check expect string role:master
tcp-check send QUIT\r\n
tcp-check expect string +OK
server Redis1 redis1:6379 check inter 3s
server Redis2 redis2:6379 check inter 3s
В данной конфигурации указано, что проксировать будем любые запросы, приходящие на все интерфейсы текущей виртуальной машины по адресу на порт 6379. Запросы будем передавать на узел, который ответит, что он имеет роль MASTER.
Перезапустим сервис haproxy:
root@redis3:/etc/haproxy# /etc/init.d/haproxy restartПопробуем подключиться с помощью клиента redis-cli и создадим тестовый ключ:
root@redis3:/etc/haproxy# redis-cli -p 6379 -a TestPass
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> SET TestKey "Some test string"
OK
127.0.0.1:6379> GET TestKey
"Some test string"
127.0.0.1:6379> info keyspace
# Keyspace
db0:keys=1,expires=0,avg_ttl=0Остановим узел redis1 и запросим снова список ключей:
127.0.0.1:6379> info keyspace
Error: Server closed the connection
(3.01s)
127.0.0.1:6379> info keyspace
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
(2.01s)
127.0.0.1:6379> GET TestKey
"Some test string"
Видим, что на некоторое время соединение оборвалось, но затем подключение снова восстановилось и все данные остались на месте.
Теперь достаточно прописать в конфигурационных файлах сервисов DirectumRX адрес reverse-прокси для подключения к Redis.
Настройка Redis Cluster
Вариант кластеризации Redis Cluster реализован для версии redis 3.0 и выше, является решением для создания и управления кластером с сегментацией и репликацией данных. Выполняет задачи управления узлами, репликации, синхронизации данных на узлах и обеспечения доступа клиентского приложения к MASTER-узлу в случае выхода из строя одного из нескольких MASTER-узлов.

Redis Cluster работает в режиме мультимастера, у каждого MASTER-узла может быть один или более SLAVE-узлов (до 1000).
Масштабирование является основной из функций кластера. Помимо этого, кластер может гарантировать отказоустойчивость сервиса Redis:
- если некоторые узлы не работают, кластер перераспределяет с них нагрузку на другие узлы;
- если не работают ключевые узлы, то весь кластер заканчивает работу.
Может возникнуть ситуация, когда Клиент 2 выполняет запись в узел М2. М2 отвечает «ОК» и пытается выполнить запись в S2. В то же время М2 не ждет корректного завершения обмена данными с S2, а отвечает клиенту сразу. В этом случае реплика S2 может иметь не все данные. Поэтому рекомендуется использовать несколько SLAVE-реплик.
Также может возникнуть ситуация, когда М1, М3 перестают «видеть» М2, а клиент всё еще продолжает записывать данные в М2. Если недоступность будет продолжаться довольно долго (параметр cluster-node-timeout), то в этом случае S2 будет переведен в режим MASTER, а M2 самостоятельно перестанет работать.
Официальная документация рекомендует использовать 6 узлов — по одному экземпляру Redis на узле, что позволяет обеспечить большую надежность, но никто не запрещает использовать три узла со следующей топологией соединения:
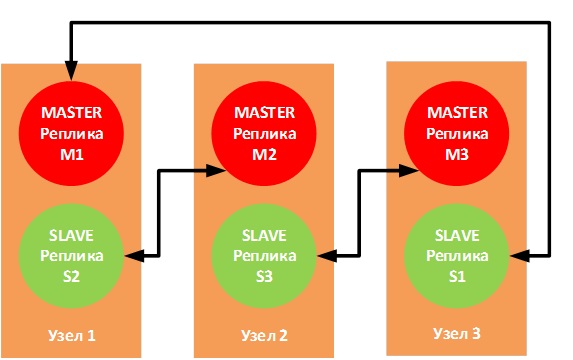
В случае выхода из строя одного из физических узлов соответствующие SLAVE-реплики перейдут в режим MASTER, и работа не будет нарушена.
На тестовом стенде реализуем 3 виртуальных машины (redis1, redis2 и redis3), на каждой из которых будет запущено по 2 экземпляра Redis.
Клиентское приложение будет выполнять подключение к конкретному порту, прописанному в конфигурационном файле клиента, поэтому пары MASTER – SLAVE должны работать на одних и тех же портах.
Для пары M1 – S1 будем использовать порт 6381
Для пары M2 – S2 будем использовать порт 6382
Для пары M3 – S3 будем использовать порт 6383
Подготовим конфигурационные файлы
На redis1:
cp /etc/redis/redis.conf /etc/redis/m1_redis.conf
cp /etc/redis/redis.conf /etc/redis/s2_redis.conf
mv /etc/redis/redis.conf /etc/redis/redis.bak На redis2:
cp /etc/redis/redis.conf /etc/redis/m2_redis.conf
cp /etc/redis/redis.conf /etc/redis/s3_redis.conf
mv /etc/redis/redis.conf /etc/redis/redis.bak На redis3:
cp /etc/redis/redis.conf /etc/redis/m3_redis.conf
cp /etc/redis/redis.conf /etc/redis/s1_redis.conf
mv /etc/redis/redis.conf /etc/redis/redis.bakЗаполним конфигурационные файлы по шаблону:
bind <IP-адрес ВМ>
protected-mode no # либо можно использовать пароль для доступа, как в предыдущем варианте.
port <порт>
pidfile /var/run/redis_<порт>.pid
# <yes/no> - флаг включение Redis Cluster
cluster-enabled yes
# Файл, в который будет писаться системная информация:
# другие узлы, их состояние, глобальные переменные и прочее.
# Данная информация необходима для восстановления работы узла в кластере.
cluster-config-file nodes-<порт>.conf
# Максимальное время, которое master-узел может быть недоступен,
# по истечению этого времени он помечается как нерабочий и slaves
# начинают его аварийное переключение.
cluster-node-timeout 15000Выполним запуск Redis-узлов:
Узел redis1:
root@redis1:/etc/redis# redis-server /etc/redis/m1_redis.conf
root@redis1:/etc/redis# redis-server /etc/redis/s2_redis.confУзел redis2:
root@redis2:/etc/redis# redis-server /etc/redis/m2_redis.conf
root@redis2:/etc/redis# redis-server /etc/redis/s3_redis.confУзел redis3:
root@redis3:/etc/redis# redis-server /etc/redis/m3_redis.conf
root@redis3:/etc/redis# redis-server /etc/redis/s1_redis.confДля настройки кластера необходимо использовать клиентскую утилиту redis-cli, передав ей на вход список пар ip:port серверов, которые будут играть роль MASTER и SLAVE:
redis-cli --cluster create redis1-ip:6381 redis2-ip:6382 redis3-ip:6383 redis1-ip:6382 redis2-ip:6383 redis3-ip:6381 --cluster-replicas 1, где опция --cluster-replicas 1 сообщает, сколько SLAVE будет у каждого мастера, и они выбираются автоматически из переданного списка реплик.
root@redis1:~/redis/src# redis-cli --cluster create 192.168.9.51:6381 192.168.9.52:6382 192.168.9.53:6383 192.168.9.51:6382 192.168.9.52:6383 192.168.9.53:6381 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.9.52:6383 to 192.168.9.51:6381
Adding replica 192.168.9.51:6382 to 192.168.9.52:6382
Adding replica 192.168.9.53:6381 to 192.168.9.53:6383
>>> Trying to optimize slaves allocation for anti-affinity
[OK] Perfect anti-affinity obtained!
M: e92cb96fd6c20db7509662a248902e3751ebe95f 192.168.9.51:6381
slots:[0-5460] (5461 slots) master
M: d499af3672b3063c7239572ec311ad3160f280ae 192.168.9.52:6382
slots:[5461-10922] (5462 slots) master
M: 3a41475e1613519c3ecdec695736a898262a24a5 192.168.9.53:6383
slots:[10923-16383] (5461 slots) master
S: 182e5cffc9c31c231de69ddbaf507ec1fe17bb09 192.168.9.51:6382
replicates d499af3672b3063c7239572ec311ad3160f280ae
S: 44f656062259005adea58bc5ad024071a050e192 192.168.9.52:6383
replicates 3a41475e1613519c3ecdec695736a898262a24a5
S: 485ffb786e9763955e6f10ffc59247690ad9bc11 192.168.9.53:6381
replicates e92cb96fd6c20db7509662a248902e3751ebe95f
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.....
>>> Performing Cluster Check (using node 192.168.9.51:6381)
M: e92cb96fd6c20db7509662a248902e3751ebe95f 192.168.9.51:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: d499af3672b3063c7239572ec311ad3160f280ae 192.168.9.52:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 485ffb786e9763955e6f10ffc59247690ad9bc11 192.168.9.53:6381
slots: (0 slots) slave
replicates e92cb96fd6c20db7509662a248902e3751ebe95f
S: 182e5cffc9c31c231de69ddbaf507ec1fe17bb09 192.168.9.51:6382
slots: (0 slots) slave
replicates d499af3672b3063c7239572ec311ad3160f280ae
S: 44f656062259005adea58bc5ad024071a050e192 192.168.9.52:6383
slots: (0 slots) slave
replicates 3a41475e1613519c3ecdec695736a898262a24a5
M: 3a41475e1613519c3ecdec695736a898262a24a5 192.168.9.53:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.Кластер корректно построен. Выведем информацию о кластере:
root@redis1:~/redis/src# redis-cli -c -h 192.168.9.51 -p 6381
192.168.9.51:6381> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1254
cluster_stats_messages_pong_sent:1243
cluster_stats_messages_sent:2497
cluster_stats_messages_ping_received:1238
cluster_stats_messages_pong_received:1254
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:2497
192.168.9.51:6381>Для проверки конкретной реплики, как и в случае с Redis Sentiel, можно использовать команду INFO replication:
root@redis1:~/redis/src# redis-cli -c -h 192.168.9.51 -p 6381
192.168.9.51:6381> INFO replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.9.53,port=6381,state=online,offset=1946,lag=0
master_replid:59cd95d394dad9d0e49042637fdfd5290db4abfe
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1946
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1946
192.168.9.51:6381>Попробуем создать несколько ключей и проверить, что эти ключи появились на репликах:
192.168.9.51:6381> SET key1 test1
-> Redirected to slot [9189] located at 192.168.9.52:6382
OK
192.168.9.52:6382> SET key2 test2
-> Redirected to slot [4998] located at 192.168.9.51:6381
OK
192.168.9.51:6381> SET key3 test3
OK
192.168.9.51:6381>Проверим на M2:
root@redis2:/home/user# redis-cli -c -h 192.168.9.52 -p 6382
192.168.9.52:6382> GET key1
"test1"
192.168.9.52:6382> GET key2
-> Redirected to slot [4998] located at 192.168.9.51:6381
"test2"
192.168.9.51:6381> GET key3
"test3"
192.168.9.51:6381>И на М3:
root@redis3:/home/user# redis-cli -c -h 192.168.9.53 -p 6383
192.168.9.53:6383> GET key1
-> Redirected to slot [9189] located at 192.168.9.52:6382
"test1"
192.168.9.52:6382> GET key2
-> Redirected to slot [4998] located at 192.168.9.51:6381
"test2"
192.168.9.51:6381> GET key3
"test3"
192.168.9.51:6381>Выведем из строя узел redis1 и проверим, как отработает S1:
192.168.9.52:6382> CLUSTER NODES
<b>182e5cffc9c31c231de69ddbaf507ec1fe17bb09 192.168.9.51:6382@16382 slave,fail d499af3672b3063c7239572ec311ad3160f280ae 1569509904727 1569509900000 4 connected</b>
485ffb786e9763955e6f10ffc59247690ad9bc11 <i>192.168.9.53:6381@16381 master</i> - 0 1569510017272 7 connected 0-5460
44f656062259005adea58bc5ad024071a050e192 192.168.9.52:6383@16383 slave 3a41475e1613519c3ecdec695736a898262a24a5 0 1569510018274 5 connected
<b>e92cb96fd6c20db7509662a248902e3751ebe95f 192.168.9.51:6381@16381 master,fail - 1569509906731 1569509901721 1 connected</b>
3a41475e1613519c3ecdec695736a898262a24a5 192.168.9.53:6383@16383 master - 0 1569510019275 3 connected 10923-16383
d499af3672b3063c7239572ec311ad3160f280ae 192.168.9.52:6382@16382 myself,master - 0 1569510017000 2 connected 5461-10922Видим информацию о сбое M1 и S2 и о том, что S3 перешел в режим MASTER.
Проверяем, где хранятся ключи:
192.168.9.52:6382> GET key1
"test1"
192.168.9.52:6382> GET key2
-> Redirected to slot [4998] located at 192.168.9.53:6381
"test2"
192.168.9.53:6381> GET key3
"test3"
192.168.9.53:6381>
Ключи, которые ранее хранились на узле redis1 теперь доступны на узле redis3.
Восстановим работу узла redis1 и проверим состояние узлов M1 и S2:
192.168.9.53:6381> CLUSTER NODES
<i>e92cb96fd6c20db7509662a248902e3751ebe95f 192.168.9.51:6381@16381 slave 485ffb786e9763955e6f10ffc59247690ad9bc11 0 1569511658217 7 connected
182e5cffc9c31c231de69ddbaf507ec1fe17bb09 192.168.9.51:6382@16382 slave d499af3672b3063c7239572ec311ad3160f280ae 0 1569511657000 4 connected</i>
d499af3672b3063c7239572ec311ad3160f280ae 192.168.9.52:6382@16382 master - 0 1569511656000 2 connected 5461-10922
3a41475e1613519c3ecdec695736a898262a24a5 192.168.9.53:6383@16383 master - 0 1569511656000 3 connected 10923-16383
485ffb786e9763955e6f10ffc59247690ad9bc11 192.168.9.53:6381@16381 myself,master - 0 1569511656000 7 connected 0-5460
44f656062259005adea58bc5ad024071a050e192 192.168.9.52:6383@16383 slave 3a41475e1613519c3ecdec695736a898262a24a5 0 1569511657216 5 connectedРаботоспособность M1 и S2 восстановилась, но теперь M1 находится в режиме SLAVE.
И ключи также находятся на узле redis3:
192.168.9.53:6383> GET key1
-> Redirected to slot [9189] located at 192.168.9.52:6382
"test1"
192.168.9.52:6382> GET key2
-> Redirected to slot [4998] located at 192.168.9.53:6381
"test2"
192.168.9.53:6383> GET key3
-> Redirected to slot [935] located at 192.168.9.53:6381
"test3"Кластер настроен и восстановление работоспособности Redis протестировано.
Для доступа сервисных служб DirectumRX также потребуется настроить реверс-прокси, как и в случае настройки Redis Sentiel.
Вместо заключения
В данной статье не был рассмотрен еще один способ повышения отказоустойчивости Redis – использование стороннего менеджера ресурсов кластера, к примеру, Pacemaker. В этом случае удастся обойтись двумя узлами, однако велика вероятность потери данных в случае возникновения нештатной ситуации.
Для реверс-прокси (в данном случае HAProxy) также желательно обеспечить отказоустойчивость, но данный вопрос также был за рамками данной статьи. В случае интереса к теме, данные варианты развертывания также могут быть рассмотрены в рамках отдельных статей с пошаговой настройкой и тестированием результатов.
Возможно, вам будут полезны ссылки ниже для получения более подробной информации по теме:
Redis cluster tutorial
Redis Sentinel Documentation
HAProxy Configuration Manual.







