PostgreSQL хранит данные на каких-то носителях. И между PostgreSQL и, например, магнитной поверхностью диска находится несколько кешей: кеш самого винчестера, кеш RAID-контроллера или винчестерной полки, кеш файловой системы на уровне операционной системы и кеш самого PostgreSQL. Если первыми перечисленными кешами мы практический не можем управлять, то последними, находящимися в ОЗУ сервера, управлять можем: например, выделяя больше ОЗУ под кеш PostgreSQL в ущерб кешу ОС, или наоборот. В официальной документации можно прочитать ничем не подтвержденные рекомендации, типа выделять под PostgreSQL четверть ОЗУ. Это вызывает сомнения. PostgreSQL в виде Postgres95 впервые появился в 1995 году и, кто знает, быть может и эти рекомендации относятся к тому же году. Поэтому появилась идея эксперимента с целью разобраться, как лучше распределять ОЗУ.
Сразу оговорюсь, что речь пойдет про выделенный под БД сервер, на котором помимо самого PostgreSQL и обслуживающей его инфраструктуры ничего нет. Если рассмотреть эту задачу умозрительно, то интуитивно понятно, что «своя рубашка ближе к телу», то есть со своим собственным кешем PostgreSQL должен работать оптимальнее. Например, в своем кеше PostgreSQL хранит информацию постранично, а размер страницы в PostgreSQL по умолчанию 8 Кб. В кеше ОС информация хранится тоже постранично, но размер страницы в памяти ОС и, обычно, файловой системы равен 4 Кб, то есть возможна фрагментация страницы PostgreSQL. Но на практике такие различия, связанные с тем, что в собственном кеше данные хранятся в более оптимальном виде, малозаметны. Другое отличие кешей заключается в том, как выбирается для удаления страница, чтобы записать новую. Кеш ОС работает просто: он удаляет ту страницу, к которой дольше всего не обращались. А кеш PostgreSQL пытается вести себя умнее, ведь данные бывают разными — более или менее полезными. Например, индексы или данные за последний месяц, к которым обращаются чаще, более полезны, чем данные, скажем, годичной давности, к которым обращаются редко. Поэтому PostgreSQL выставляет данным своеобразную оценку полезности и в первую очередь высвобождает наименее полезную информацию. А если PostgreSQL видит, что намечается последовательное чтение большой таблицы, которое может «вымыть» остальные данные из кеша, то он принимает меры, чтобы этого не случилось. Вот такую оптимизацию, связанную с интеллектуальным анализом полезности кеша, и должен был продемонстрировать эксперимент. Также с его помощью решался вопрос о том, насколько влияют на производительность PostgreSQL HugePages.
Довольно сложно найти документацию, описывающую алгоритмы работа кеша PostgreSQL. Для желающих изучить этот вопрос более углубленно, привожу ссылку: Inside the PostgreSQL Shared Buffer Cache
Описание эксперимента
Идея проста. Создаю одну таблицу, размер которой больше ОЗУ сервера, и индекс к этой таблице, который занимает где-то 10% от размера таблицы. Мне показалось, что такая пропорция реалистична. Cначала «прогреваю» таблицу, потом индекс, чтобы они по максимуму находились в кеше. Измеряю время индексированного поиска. Запускаю неиндексированный поиск, который выполняет последовательное чтение всей таблицы, измеряю длительность его работы. А после этого повторяю эксперимент по индексированному поиску. Предполагаю, что в случае работы кеша PostgreSQL разница между поисками по индексу до и после поиска последовательным чтением таблицы будет минимальна, а в случае кеша ОС — заметна. Эксперимент буду повторять с различными пропорциями кешей ОС и PostgreSQL, а также с использованием HugePages и без них.
Описание стенда
Стенд сделал из того, что было: ноут MSI, операционка сообщает о 8 ядрах процессора, 16 Гб ОЗУ (HugePages 2 Мб на 14 Гб), 0 swap. К тому же Linux ругался о том, что процессор перегревается и приходится сбрасывать частоту, что наверняка сказалось на повторяемости эксперимента. Софт: CentOS 8 и PostgreSQL 13.0.
Подробно опишу эксперимент, чтобы любой желающий мог его повторить в своих условиях. «Прогревание» выполняется с помощью функции pg_prewarm(), но поскольку в результате эксперимента выяснилось, что pg_prewarm хоть и заполняет кеш, но «прогревает» недостаточно, после неё дополнительно прогреваю с помощью pgbench. Потом через тот же pgbench замеряю длительность индексированного поиска, поиска через последовательное чтение и снова индексированного. Результаты складываю в CSV-файлы, которые потом импортирую в Exсel, там обрабатываю и строю графики. Видимо, из-за фрагментирования памяти иногда невозможно выделять память под HugePages большого размера. Поэтому цикл тестирования выглядит так: перезагружаю машину, из rc.local вызываю тестирующий скрипт, он прогоняет тесты с включенными HugePages от максимального размера кеша PostgreSQL к минимальному, потом скрипт повторяет то же самое с выключенными HugePages, после чего перезагружает машину. Размер HugePage равен 2 Мб.
Все файлы лежат в одной директории, вот их список:
include = 'shared_buffers.conf'
# при max_parallel_workers_per_gather>6 ошибка выполнения при размере кеша PostgreSQL 128 Кб
max_parallel_workers_per_gather=6Этот файл «инклюдится» в postgresql.conf базы данных с помощью директивы include. Он нужен для проведения эксперимента с разными настройками PostgreSQL.
shared_buffers=128kBСкриптом, который выполняет тестирование, в этот файл записывается размер кеша PostgreSQL.
-- Размер таблицы, которую нужно создать. Подбирается методом проб и ошибок так, чтобы таблица имела размер, равный ОЗУ.
\set table_size 75000000
-- Создаю таблицу с именем random, там лежат случайные данные. :)
drop table if exists random;
create table random(random real, data float[]);
insert into random select random,array_fill(random,ARRAY[20]) from (select random() as random, generate_series(1,:table_size)) as subselect;
-- И индекс к ней.
create index on random(random);
-- Дальнейшие операции требуют роль суперпользователя, мой пользователь имеет эту роль, поэтому переключиться несложно.
set role postgres;
-- Модуль для функции pg_prewarm
create extension if not exists pg_prewarm;
-- Модуль, в котором можно наблюдать структуру кеша PostgreSQL
create extension if not exists pg_buffercache;
-- View на базе предыдущего модуля для наблюдением за кешем. Для эксперимента не используется, и во время эксперимента лучше не использовать, т.к. pg_buffercache вел себя нестабильно и иногда рушил процесс PostgreSQL.
create or replace view cache as SELECT n.nspname AS schema,
c.relname,
pg_size_pretty(count(*) * 8192) AS buffered,
count(*) * 8 AS buffered_KiB,
round(100.0 * count(*)::numeric / ((( SELECT pg_settings.setting
FROM pg_settings
WHERE pg_settings.name = 'shared_buffers'::text))::integer)::numeric, 1) AS buffer_percent,
round(100.0 * count(*)::numeric * 8192::numeric / pg_table_size(c.oid::regclass)::numeric, 1) AS percent_of_relation
FROM pg_class c
JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
JOIN pg_database d ON b.reldatabase = d.oid AND d.datname = current_database()
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
GROUP BY c.oid, n.nspname, c.relname
ORDER BY (round(100.0 * count(*)::numeric / ((( SELECT pg_settings.setting
FROM pg_settings
WHERE pg_settings.name = 'shared_buffers'::text))::integer)::numeric, 1)) DESC
LIMIT 5;
-- View, в котором можно посмотреть размер таблицы на диске, использовался для подгона размера таблицы под ОЗУ.
create or replace view disk as SELECT n.nspname AS schema,
c.relname,
pg_size_pretty(pg_relation_size(c.oid::regclass)) AS size,
pg_relation_size(c.oid::regclass)/1024 AS size_KiB
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
ORDER BY (pg_relation_size(c.oid::regclass)) DESC
LIMIT 5;
vacuum full freeze analyze;SQL-скрипт, который создает окружение в БД, выполняется перед экспериментом. Запускается с помощью psql база -f init.sql.
select random from random where random=(select random()::real);select count(data) from random;Здесь находятся SQL-запросы, которые выполняет pgbench во время тестирования.
# database connection parameters
export PGDATABASE='pgcache'
# Добавляю путь к бинарникам PostgreSQL, это было нужно на CentOS и, возможно, других редхатоподобных дистрибутивах.
PATH=$PATH:/usr/pgsql-13/bin
# Через пробел указаны значения для конфигурационной переменной PostgreSQL shared_buffers, т.е. собственно размеры кеша на которых будет производится тестирование. Порядок по уменьшению величин важен. Дело в том, что HugePages уменьшить можно всегда, а вот увеличить — не всегда, видимо, из-за фрагментации памяти. Поэтому тестирование ведется при уменьшении размера кеша.
readonly shared_buffers='14GB 13GB 12GB 11GB 10GB 9GB 8GB 7GB 6GB 5GB 4GB 3GB 2GB 1GB 512MB 256MB 128MB 64MB 32MB 16MB 8MB 4MB 2MB 1MB 512kB 256kB 128kB';#!/bin/bash
. config.sh
readonly postgresql_service='postgresql-13' postgresql_pid='/var/lib/pgsql/13/data/postmaster.pid'
readonly huge_pages_sh='huge_pages.sh' shared_buffers_conf='shared_buffers.conf'
sudo systemctl start "$postgresql_service"
echo 'declare -r -A huge_pages_size=( \' >"$huge_pages_sh"
for s_b in $shared_buffers
do
echo "shared_buffers=$s_b" >"$shared_buffers_conf"
sleep 5
sudo systemctl restart "$postgresql_service"
pid=$(sudo head -1 "$postgresql_pid")
echo -n ' [' >>"$huge_pages_sh"
psql --expanded --quiet --tuples-only -c "show shared_buffers" | awk '/^shared_buffers \|/{printf "%s", $3}' >>"$huge_pages_sh"
echo -n ']=' >>"$huge_pages_sh"
sudo awk '/^VmPeak:/ {printf "%i", $2/2048+1}' /proc/"$pid"/status >>"$huge_pages_sh"
echo ' \' >>"$huge_pages_sh"
done
echo ')' >>"$huge_pages_sh"
sudo systemctl stop "$postgresql_service"Вспомогательный скрипт. Он берет из config.sh значения для shared_buffers, запускает с этими настройками PostgreSQL, замеряет, сколько нужно HugePages для его работы в данной конфигурации, и записывает результат работы в файл huge_pages.sh.
declare -r -A huge_pages_size=( \
[14GB]=7416 \
[13GB]=6893 \
[12GB]=6370 \
[11GB]=5847 \
[10GB]=5323 \
[9GB]=4800 \
[8GB]=4277 \
[7GB]=3750 \
[6GB]=3226 \
[5GB]=2703 \
[4GB]=2180 \
[3GB]=1655 \
[2GB]=1131 \
[1GB]=607 \
[512MB]=345 \
[256MB]=209 \
[128MB]=142 \
[64MB]=108 \
[32MB]=91 \
[16MB]=82 \
[8MB]=78 \
[4MB]=76 \
[2MB]=75 \
[1MB]=74 \
[512kB]=74 \
[256kB]=74 \
[128kB]=74 \
)Здесь лежат результаты работы get_huge_pages, они используются в скрипте test.
dataHP.csv и dataNHP.csv
Результаты работы скрипта test, используются потом в Excel.
output.log
Вывод из скрипта test полезен, если там содержатся ошибки, а если их нет — он пустой.
Пример запуска тестирующего скрипта. Отредактировал файл, который уже был в CentOS:
#!/bin/bash
# THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES
#
# It is highly advisable to create own systemd services or udev rules
# to run scripts during boot instead of using this file.
#
# In contrast to previous versions due to parallel execution during boot
# this script will NOT be run after all other services.
#
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# that this script will be executed during boot.
sudo -u myuser /home/myuser/experiment/pgcache/test &>/home/myuser/experiment/pgcache/output.log &
touch /var/lock/subsys/localСобственно, тестирующий скрипт:
#!/bin/bash
set -eCu -o pipefail
postgresql_service="postgresql-13"
# перехожу в директорию, где лежит этот скрипт
cd "$( dirname "${BASH_SOURCE[0]}" )" || exit $?
# настроечные опции
. config.sh
# ассоциативный массив, связывающий размер кеша PostgreSQL и количество нужных ему hugepages
. huge_pages.sh
# заголовок для CSV-файлов
readonly header='huge_pages(2MiB),pg_cache,pg_cache(KiB),idx1(ms),seq(ms),idx2(ms),heap_blks_read,heap_blks_hit,idx_blks_read,idx_blks_hit,finish'
date --iso-8601=seconds
# цикл по включенным и отключенным hugepages
for hp in 'HP' 'NHP'
do
# Цикл по всем "ступенькам" размера кеша, по которым надо пройтись
for s_b in $shared_buffers
do
data_csv="data${hp}.csv"
if [ ! -s "$data_csv" ]
then
echo "$header" >|"$data_csv"
fi
echo "shared_buffers=$s_b" >|'shared_buffers.conf'
if [ "$hp" = 'HP' ]
then
set_huge_pages=${huge_pages_size["$s_b"]}
else
set_huge_pages=0
fi
huge_pages=$(awk '/^HugePages_Total:/ {print $2}' /proc/meminfo)
if [ $huge_pages -ne $set_huge_pages ]
then
sudo sysctl --quiet --write vm.nr_hugepages="$set_huge_pages"
while [ $(awk '/^HugePages_Total:/ {print $2}' /proc/meminfo) -gt $set_huge_pages ]
do
sleep 1
done
fi
huge_pages=$(awk '/^HugePages_Total:/ {print $2}' /proc/meminfo)
if [ $set_huge_pages -ne $huge_pages ]
then
echo -n 'hugepage_error,' >>"$data_csv"
echo "$(date --iso-8601=seconds)" >>"$data_csv"
continue
fi
echo -n "$huge_pages," >>"$data_csv"
sudo systemctl start "$postgresql_service"
psql --expanded --quiet --tuples-only -c "show shared_buffers" | awk '/^shared_buffers \|/ {printf "%s,", $3}' >>"$data_csv"
psql --expanded --quiet --tuples-only -c "select setting::int*8 as shared_buffers from pg_settings where name='shared_buffers'" | awk '/^shared_buffers \|/ {printf "%s,", $3}' >>"$data_csv"
# prewarm to the cache
psql --quiet -c "select pg_prewarm('random')" -c "select pg_prewarm('random_random_idx')" >/dev/null
# more prewarm
pgbench --no-vacuum --time 100 --file test_idx.sql >/dev/null
# reset stats
psql --quiet -c "select pg_stat_reset_single_table_counters('random'::regclass),pg_stat_reset_single_table_counters('random_random_idx'::regclass)" >/dev/null
# first test index search
pgbench --no-vacuum --transaction 100 --report-latencies --file test_idx.sql | awk '/select random from random where random=\(select random\(\)::real\);$/ {printf "%s,", $1 >>"'"$data_csv"'";}'
# test sequence scan
pgbench --no-vacuum --transaction 1 --report-latencies --file test_seq.sql | awk '/select count\(data\) from random;$/ {printf "%s,", $1 >>"'"$data_csv"'"}'
# second test index search
pgbench --no-vacuum --transaction 100 --report-latencies --file test_idx.sql | awk '/select random from random where random=\(select random\(\)::real\);$/ {printf "%s,", $1 >>"'"$data_csv"'";}'
# get stats
sleep 10
psql --quiet --tuples-only --field-separator=' ' --no-align -c "select heap_blks_read,heap_blks_hit,idx_blks_read,idx_blks_hit from pg_statio_user_tables where relname='random'"| head -1 | awk '{printf "%s,", $1 >>"'"$data_csv"'";printf "%s,", $2 >>"'"$data_csv"'";printf "%s,", $3 >>"'"$data_csv"'";printf "%s,", $4 >>"'"$data_csv"'";}'
sudo systemctl stop "$postgresql_service"
echo "$(date --iso-8601=seconds)" >>"$data_csv"
done
done
sudo systemctl rebootТестирование
Сначала создаю базу данных скриптом init.sql, потом скриптом get_huge_pages я собираю информацию о том сколько нужно HugePages для различных размеров кэша PostgreSQL, после этого добавляю вызов скрипта test в /etc/rc.local и перезагружаю машину. За каждую перезагрузку проходит один цикл тестирования.
Результаты
Здесь и далее по оси X отложены значения кеша PostgreSQL, ОЗУ около 16 Гб, вся неиспользуемая память используется, разумеется, как файловый кеш ОС. По оси Y отложено время выполнения запроса в миллисекундах. Синим цветом — без использования HugePages, оранжевым — с HugePages. Вид графика — коробочки с усиками, подробно про них можно прочитать в документации Excel; удобны тем, что показывают не только усредненные значения, но и разброс, и распределение данных. В каждой итерации было 27 тестов с HugePages и 27 без, итераций было 251, всего было 13554 тестов.
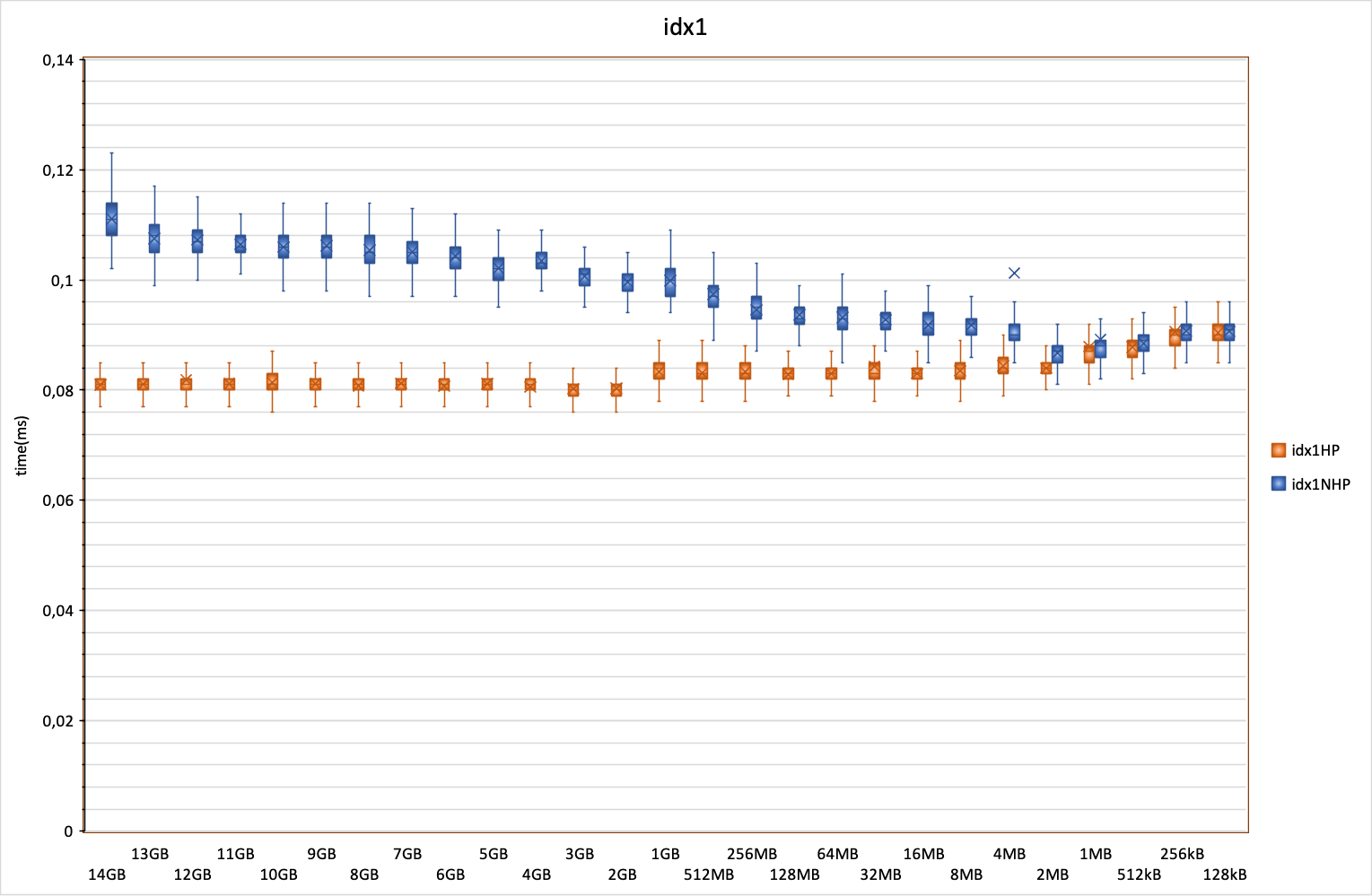
С увеличением кеша PostgreSQL график раздваивается. Без HugePages скорость выполнения запроса — а это простой поиск с использованием индекса — падает. С увеличением кеша PostgreSQL только с использованием HugePages PostgreSQL кеш начинает незначительно выигрывать у кеша файловой системы. Когда я тестировал два года назад на CentOS 7 и PostgreSQL 10, кеш файловой системы работал примерно с такой же скоростью, что и кеш PostgreSQL без HugePages, а добавление HugePages давало значимый выигрыш над кешем файловой системы. Из чего я могу сделать вывод, что за последние годы Linux научился гораздо эффективнее использовать свой файловый кеш.
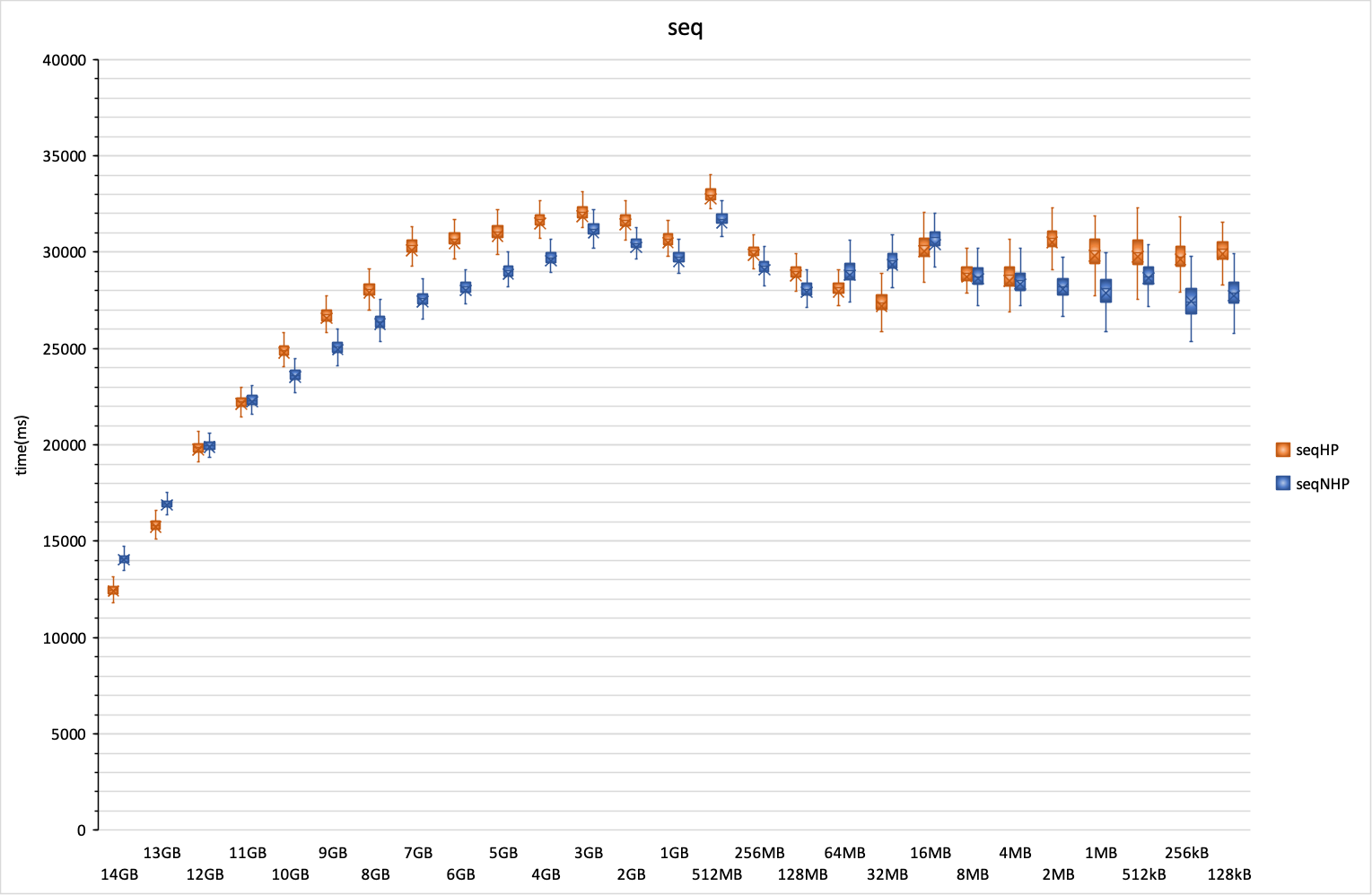
Последовательное чтение таблицы. Тут заметно ускорение запроса, если кеш PostgreSQL больше кеша файловой системы. Что интересно (и для меня непонятно), на большей части графика использование HugePages замедляет выполнение запроса, и только при очень больших значениях кеша PostgreSQL выигрыш становится заметен. Не знаю, с чем это связано, наверное, разработчикам PostgreSQL есть еще над чем подумать.
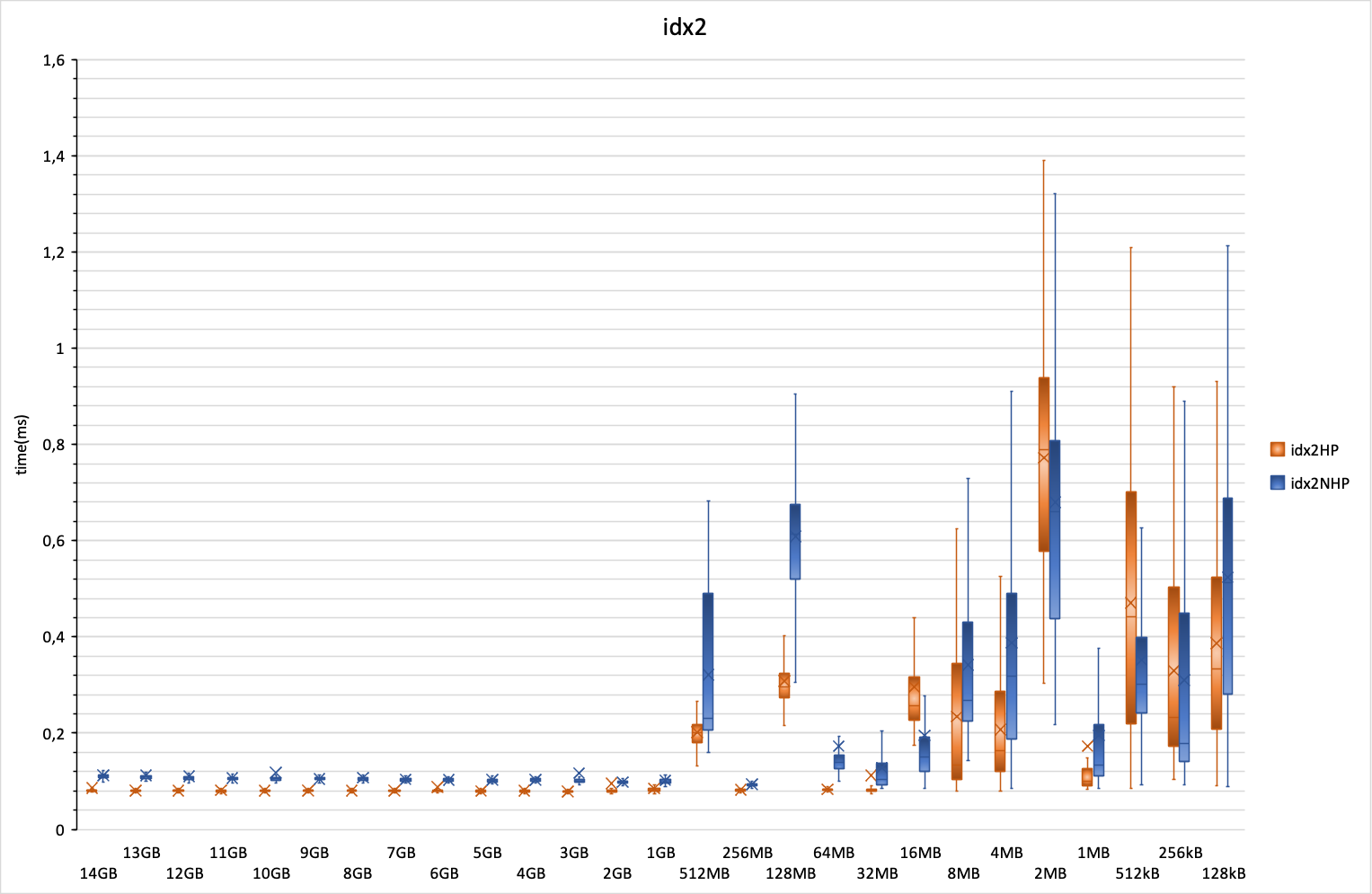
Повторный поиск по индексу. Здесь и демонстрируется тот эффект, который я описывал в самом начале. Если использовать кеш файловой системы (задан небольшой размер кеша PostgreSQL), то при последовательном чтении таблицы индекс вымывается из кеша, что демонстрирует длительный повторный поиск по индексу. Этот эффект пропадает примерно тогда, когда кеш PostgreSQL становится достаточно большим, чтобы индекс хранился в нём, а не в кеше файловой системы, и график становится похож на график, который был до последовательного чтения таблицы: примерно 0,08 мс с HugePages и 0,12 мс без HugePages.
Выводы
Выводы каждый сделает сам :) Я считаю, что не стоит верить ничем не подтвержденным древним рекомендациям каких-то мохнатых годов о том, что кеш PostgreSQL должен быть равен четверти ОЗУ. Со своим кешем он работает заметно лучше.
