Первая часть: Основы работы с видео и изображениями
Что? Видеокодек — это часть программного/аппаратного обеспечения, сжимающая и/или распаковывающая цифровое видео.
Для чего? Невзирая на определённые ограничения как по пропускной способности так
и по количеству места для хранения данных, рынок требует всё более качественного видео. Припоминаете, как в прошлом посте мы подсчитали необходимый минимум для 30 кадров в секунду, 24 бита на пиксель, с разрешение 480x240? Получили 82,944 Мбит/с без сжатия. Сжатие — это пока единственный способ вообще передавать HD/FullHD/4K на телевизионные экраны и в Интернет. Как это достигается? Сейчас кратко рассмотрим основные методы.
Перевод сделан при поддержке компании EDISON Software.
Мы занимаемся интеграцией систем видеонаблюдения, а также разрабатываем микротомограф.

Кодек vs Контейнер
Распространенная ошибка новичков — путать кодек цифрового видео и контейнер цифрового видео. Контейнер это некий формат. Обёртка, содержащая метаданные видео (и, возможно, аудио). Сжатое видео можно рассматривать как полезную нагрузку контейнера.
Обычно расширение видеофайла указывает на разновидность контейнера. Например, файл video.mp4, вероятно всего, является контейнером MPEG-4 Part 14, а файл с именем video.mkv — это, скорее всего, матрёшка. Чтобы быть полностью уверенным в кодеке и формате контейнера, можно воспользоваться FFmpeg или MediaInfo.
Немного истории
Прежде чем перейдем к Как?, давайте слегка погрузимся в историю, чтобы немного лучше понимать некоторые старые кодеки.
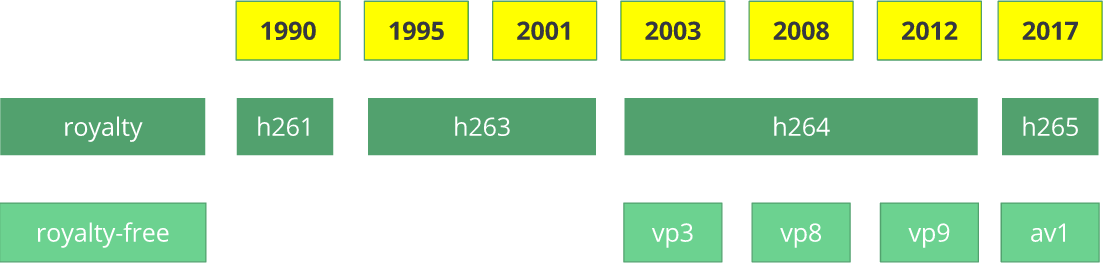
Видеокодек H.261 появился в 1990 году (технически — в 1988) и был создан для работы со скоростью передачи данных 64 Кбит/с. В нём уже использовались такие идеи, как цветовая субдискретизация, макроблоки и т.п. В 1995 году был опубликован стандарт видеокодека H.263, который развивался до 2001 года.
В 2003 году была завершена первая версия H.264/AVC. В том же году компания «TrueMotion» выпустила свой бесплатный видеокодек, сжимающий видео с потерями под названием VP3. В 2008 году Google купил эту компанию, выпустив VP8 в том же году. В декабре 2012 года Google выпустил VP9, и он поддерживается примерно на ¾ рынка браузеров (включая мобильные устройства).
AV1 — это новый бесплатный видеокодек с открытым исходным кодом, разработанный Альянсом за открытые медиа (AOMedia), в состав которого входят известнейшие компании, как-то: Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel и Cisco. Первая версия кодека 0.1.0 была опубликована 7 апреля 2016 года.
Рождение AV1
В начале 2015 года Google работал над VP10, Xiph (который принадлежит Mozilla) работал над Daala, а Cisco сделала свой бесплатный видеокодек под названием Thor.
Затем MPEG LA сначала объявила годовые лимиты для HEVC (H.265) и плату, в 8 раз выше, чем за H.264, но вскоре они снова изменили правила:
без годового лимита,
плата за контент (0,5% от выручки) и
плата за единицу продукции примерно в 10 раз выше, чем за H.264.
Альянс за открытые медиа был создан компаниями из разных сфер: производителями оборудования (Intel, AMD, ARM, Nvidia, Cisco), поставщиками контента (Google, Netflix, Amazon), создателями браузеров (Google, Mozilla) и другими.
У компаний была общая цель — видеокодек без лицензионных отчислений. Затем появляется AV1 с гораздо более простой патентной лицензией. Тимоти Б. Терриберри сделал сногсшибательную презентацию, ставшей источником текущей концепции AV1 и её модели лицензии.
Вы будете удивлены, узнав, что можно анализировать кодек AV1 через браузер (заинтересовавшиеся могут перейти по адресу aomanalyzer.org).

Универсальный кодек
Разберём основные механизмы, лежащие в основе универсального видеокодека. Большинство из этих концепций полезны и используются в современных кодеках, таких как VP9, AV1 и HEVC. Предупреждаю, что многие объясняемые вещи будут упрощены. Иногда будут использоваться реальные примеры (как в случае с H.264) для демонстрации технологий.
1-й шаг — разбиение изображения
Первым шагом является разделение кадра на несколько разделов, подразделов и далее.

Для чего? Есть множество причин. Когда дробим картинку, можно точнее прогнозировать вектор движения, используя небольшие разделы для маленьких движущихся частей. В то время как для статического фона можно ограничиться и более крупными разделами.
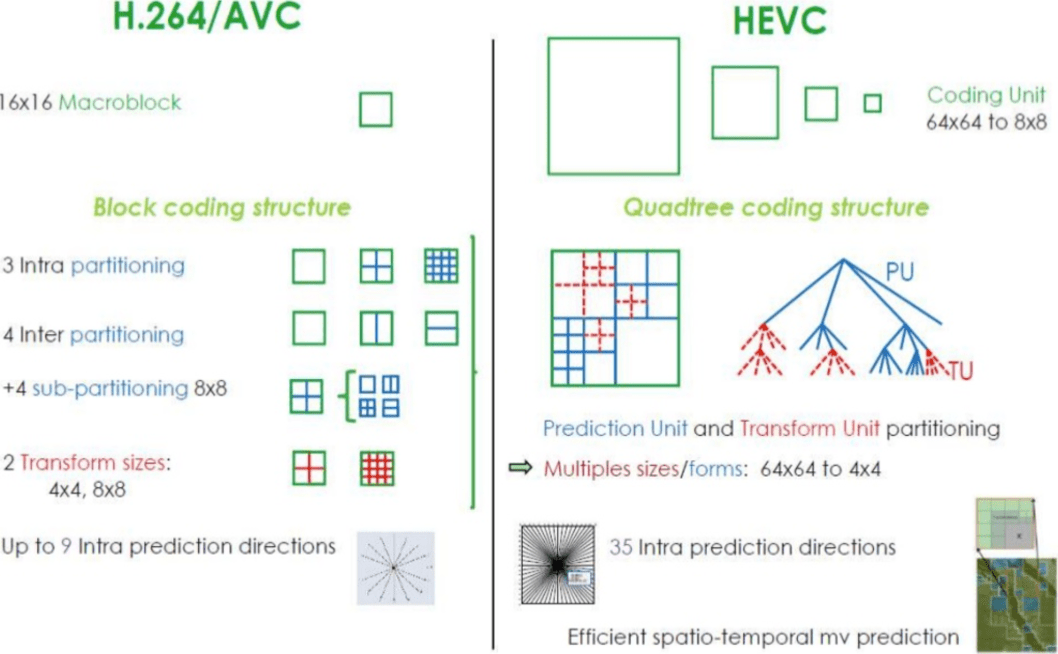
Обычно кодеки организуют эти разделы в секции (или фрагменты), макроблоки (или блоки дерева кодирования) и множество подразделов. Максимальный размер этих разделов варьируется, HEVC устанавливает 64x64, в то время как AVC использует 16x16, а подразделы могут дробиться до размеров 4x4.
Припоминаете разновидности кадров из прошлой статьи?! Это же можно применить и к блокам, так что, у нас могут быть I-фрагмент, B-блок, P-макроблок и т.п.
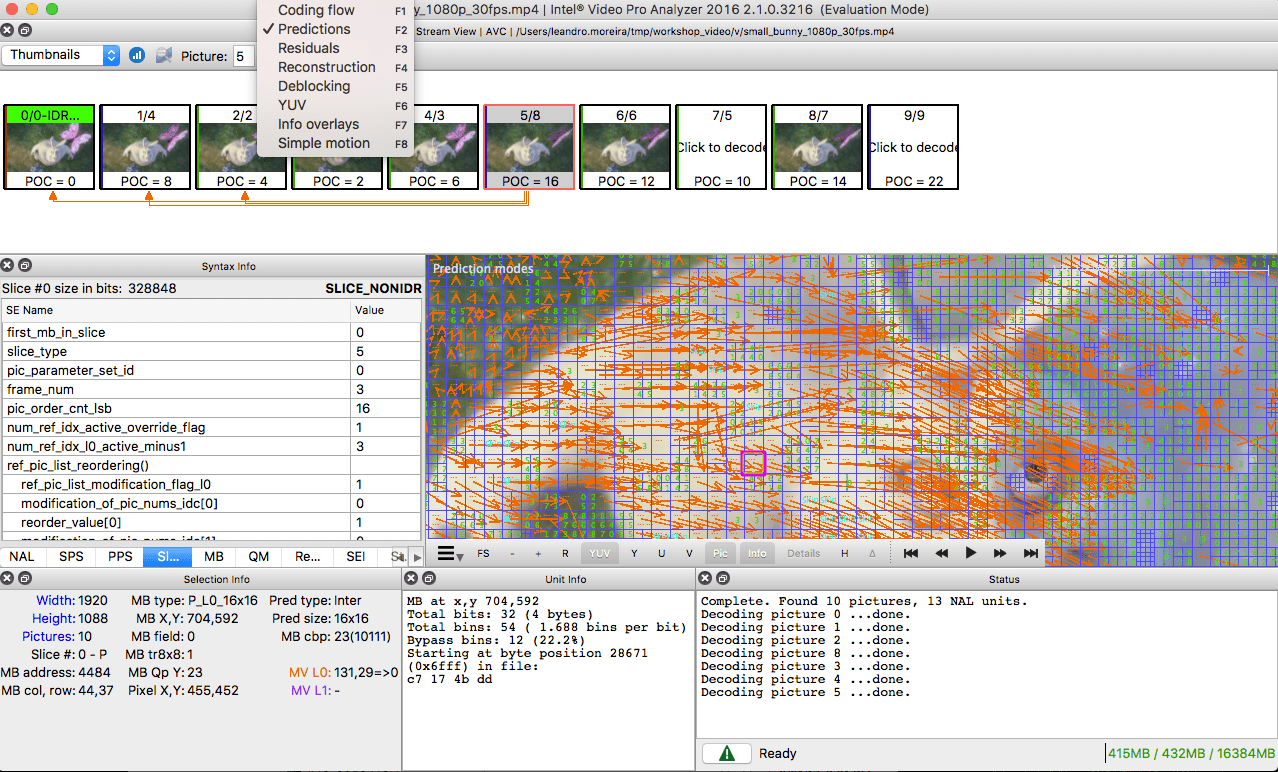
Для желающих попрактиковаться — посмотрите как изображение разобъётся на разделы и подразделы. Для этого можно воспользоваться уже упоминаемой в прошлой статье Intel Video Pro Analyzer (тот, что платный, но с бесплатный пробной версией, имеющей ограничение на первые 10 кадров). Здесь проанализированы разделы VP9:

2-й шаг — прогнозирование
Как только у нас появились разделы, мы можем составлять
3-й шаг — преобразование
После того, как получим остаточный блок (предсказанный раздел → реальный раздел), возможно преобразовать его таким образом, чтобы знать, какие пиксели можно отбросить, сохраняя при этом общее качество. Есть некоторые преобразования, обеспечивающие точное поведение.
Хотя есть и другие методы, рассмотрим более подробно дискретное косинусное преобразование (DCT — от discrete cosine transform). Основные функции DCT:
- Преобразует блоки пикселей в одинаковые по размеру блоки частотных коэффициентов.
- Уплотняет мощность, помогая устранять пространственную избыточность.
- Обеспечивает обратимость.
2 февраля 2017 года Синттра Р.Дж. (Cintra, R.J.) и Байер Ф.М. (Bayer F.M.) опубликовали статью про DCT-подобное преобразование для сжатия изображений, требующее только 14 дополнений.
Не переживайте, если не поняли преимуществ каждого пункта. Сейчас на конкретных примерах убедимся в их реальной ценности.
Давайте возьмем такой блок пикселей 8x8:
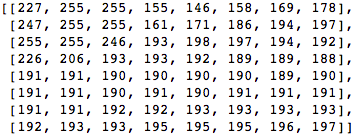
Этот блок рендерится в следующее изображение 8 на 8 пискелей:
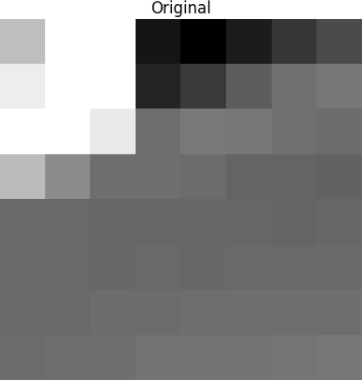
Применим DCT к этому блоку пикселей и получаем блок коэффициентов размером 8x8:
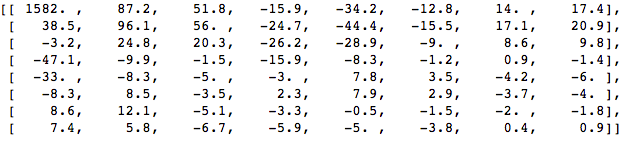
И если отрендерим этот блок коэффициентов, получим такое изображение:
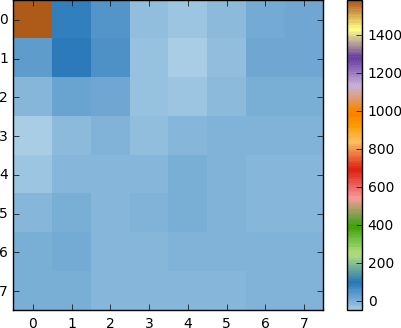
Как видим, это не похоже на исходное изображение. Можно заметить, что первый коэффициент сильно отличается от всех остальных. Этот первый коэффициент известен как DC-коэффициент, представляющий все выборки во входном массиве, нечто похожее на среднее значение.
У этого блока коэффициентов есть интересное свойство: он отделяет высокочастотные компоненты от низкочастотных.
В изображении большая часть мощности сконцентрирована на более низких частотах, поэтому, если преобразовать изображение в его частотные компоненты и отбросить более высокие частотные коэффициенты, можно уменьшить количество данных, необходимых для описания изображения, не слишком жертвуя качеством картинки.
Частота означает, насколько быстро меняется сигнал.Давайте попробуем применить знания, полученные в тестовом примере, преобразовав исходное изображение в его частоту (блок коэффициентов), используя DCT, а затем отбросив часть наименее важных коэффициентов.
Сначала конвертируем его в частотную область.
Далее отбрасываем часть (67%) коэффициентов, в основном нижнюю правую часть.
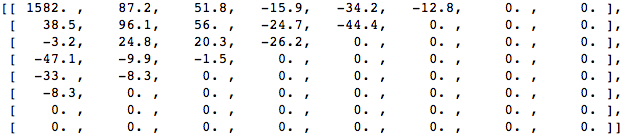
Наконец, восстанавливаем изображение из этого отброшенного блока коэффициентов (помните, оно должно быть обратимым) и сравниваем с оригиналом.
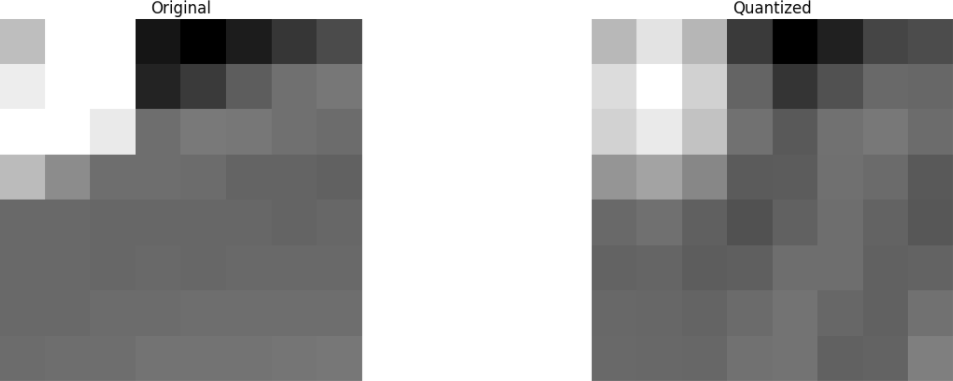
Видим, что оно напоминает исходное изображение, но есть много отличий от оригинала. Мы выбросили 67,1875% и все же получили что-то, напоминающее первоисточник. Можно было более продуманно отбросить коэффициенты, чтобы получить изображение ещё лучшего качества, но это уже следующая тема.
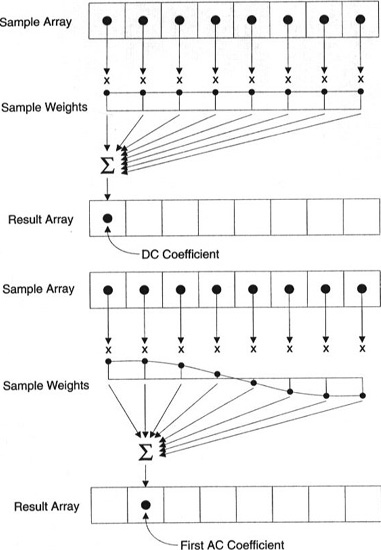
Каждый коэффициент формируется с использованием всех пикселей
Важно: каждый коэффициент напрямую не отображается на один пиксель, а представляет собой взвешенную сумму всех пикселей. Этот удивительный график показывает, как рассчитывается первый и второй коэффициент с использованием весов, уникальных для каждого индекса.
Вы также можете попытаться визуализировать DCT, взглянув на простое формирование изображения на его основе. Например, вот символ A, формируемый с использованием каждого веса коэффициента:

4-й шаг — квантование
После того как на предыдущем шаге выбрасываем некоторые коэффициенты, на последнем шаге (преобразование), производим особую форму квантования. На этом этапе допустимо терять информацию. Или, проще говоря, будем квантовать коэффициенты для достижения сжатия.
Как можно квантовать блок коэффициентов? Одним из самых простых методов будет равномерное квантование, когда берём блок, делим его на одно значение (на 10) и округляем то что получилось.
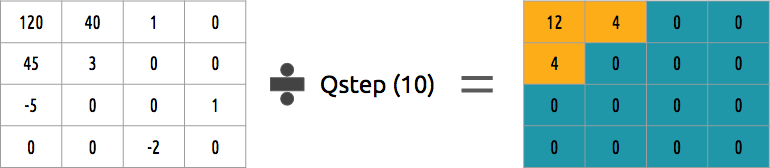
Можем ли обратить этот блок коэффициентов? Да, можем, умножив на то же значение, на которые делили.
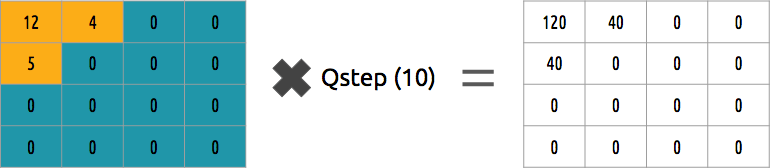
Этот подход не самый лучший, поскольку он не учитывает важность каждого коэффициента. Можно было бы использовать матрицу квантователей вместо одного значения, а эта матрица может использовать свойство DCT, квантуя большинство нижних правых и меньшинство верхних левых.
5 шаг — энтропийное кодирование
После того, как мы квантовали данные (блоки изображений, фрагменты, кадры), все еще можем сжимать их без потерь. Существует много алгоритмических способов сжатия данных. Мы собираемся кратко познакомиться с некоторыми из них, для более глубокого понимания вы можете прочитать книгу «Разбираемся со сжатием: сжатие данных для современных разработчиков» («Understanding Compression: Data Compression for Modern Developers»).
Кодирование видео с помощью VLC
Предположим, у нас есть поток символов: a, e, r и t. Вероятность (в пределах от 0 до 1) того, как часто встречается каждый символ в потоке, представлена в этой таблице.
| a | e | r | t | |
|---|---|---|---|---|
| Вероятность | 0,3 | 0,3 | 0,2 | 0,2 |
| a | e | r | t | |
|---|---|---|---|---|
| Вероятность | 0,3 | 0,3 | 0,2 | 0,2 |
| Бинарный код | 0 | 10 | 110 | 1110 |
Первый шаг заключается в кодировании символа e, который равен 10, а второй символ — это a, который добавляется (не математическим способом): [10] [0], и, наконец, третий символ t, который делает наш финальный сжатый битовый поток равным [10] [0] [1110] или же 1001110, для чего требуется всего 7 бит (в 3,4 раза меньше места, чем в оригинале).
Обратите внимание, что каждый код должен быть уникальным кодом с префиксом. Алгоритм Хаффмана поможет найти эти цифры. Хотя данный способ не без изъянов, существуют видеокодеки, которые всё ещё предлагают этот алгоритмический метод для сжатия.
И кодер, и декодер должны иметь доступ к таблице символов со своими бинарными кодами. Поэтому также необходимо отправить во входных данных и таблицу.
Арифметическое кодирование
Предположим, у нас есть поток символов: a, e, r, s и t, и их вероятность представлена этой таблицей.
| a | e | r | s | t | |
|---|---|---|---|---|---|
| Вероятность | 0,3 | 0,3 | 0,15 | 0,05 | 0,2 |

Теперь давайте закодируем поток из трёх символов: eat.
Сначала выбираем первый символ e, который находится в поддиапазоне от 0,3 до 0,6 (не включая). Берём этот поддиапазон и снова делим его в тех же пропорциях, что и ранее, но уже для этого нового диапазона.

Давайте продолжим кодировать наш поток eat. Теперь берём второй символ a, который находится в новом поддиапазоне от 0,3 до 0,39, а затем берём наш последний символ t и, повторяя тот же процесс снова, получаем последний поддиапазон от 0,354 до 0,372.
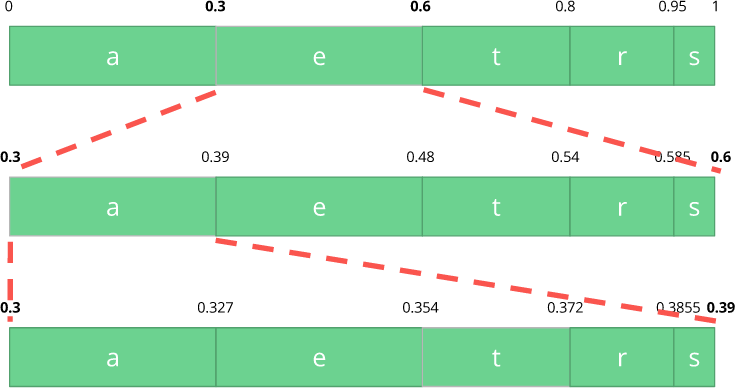
Нам просто нужно выбрать число в последнем поддиапазоне от 0,354 до 0,372. Давайте выберем 0,36 (но можно выбрать и любое другое число в этом поддиапазоне). Только с этим числом сможем восстановить наш оригинальный поток. Это как если бы мы рисовали линию в пределах диапазонов для кодирования нашего потока.
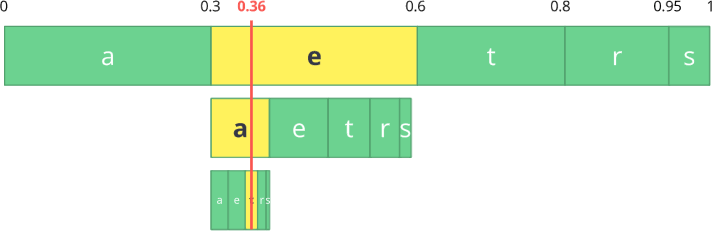
Обратная операция (то бишь декодирование) так же проста: с нашим числом 0,36 и нашим исходным диапазоном можем запустить тот же процесс. Но теперь, используя это число, выявляем поток, закодированный с помощью этого числа.
С первым диапазоном замечаем, что наше число соответствует срезу, следовательно, это наш первый символ. Теперь снова разделяем этот поддиапазон, выполняя тот же процесс, что и раньше. Тут можно заметить, что 0,36 соответствует символу a, и после повторения процесса мы пришли к последнему символу t (формируя наш исходный кодированный поток eat).
И для кодера и для декодера должна быть в наличии таблица вероятностей символов, поэтому необходимо во входных данных отправить и её.
Довольно элегантно, не так ли? Кто-то, придумавший это решение, был чертовски умён. Некоторые видеокодеки используют эту технику (или, во всяком случае, предлагают её в качестве опции).
Идея состоит в том, чтобы сжать без потерь квантованный битовый поток. Наверняка в этой статье отсутствуют тонны деталей, причин, компромиссов и т.д. Но вы, если являетесь разработчиком, должны знать больше. Новые кодеки пытаются использовать разные алгоритмы энтропийного кодирования, такие как ANS.
6 шаг — формат битового потока
После того, как сделали всё это, осталось распаковать сжатые кадры в контексте выполненных шагов. Необходимо явно информировать декодер о решениях, принятых кодером. Декодеру должна быть предоставлена вся необходимая информация: битовая глубина, цветовое пространство, разрешение, информация о прогнозах (векторы движения, направленное INTER-прогнозирование), профиль, уровень, частота кадров, тип кадра, номер кадра и многое другое.
Мы поверхностно ознакомимся с битовым потоком H.264. Нашим первым шагом является создание минимального битового потока H.264 (FFmpeg по умолчанию добавляет все параметры кодирования, такие как SEI NAL — чуть дальше узнаем, что это такое). Можем сделать это, используя наш собственный репозиторий и FFmpeg.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264Данная команда сгенерирует необработанный битовый поток H.264 с одним кадром, разрешением 64x64, с цветовым пространством YUV420. При этом используется в качестве кадра следующее изображение.

Битовый поток H.264
Стандарт AVC (H.264) определяет, что информация будет отправляться в макрокадрах (в понимании сети), называемых NAL (это такой уровень абстракции сети). Основной целью NAL является предоставление «дружественного к сети» представления видео. Этот стандарт должен работать на телевизорах (на основе потоков), в Интернете (на основе пакетов).
Существует маркер синхронизации для определения границ элементов NAL. Каждый маркер синхронизации содержит значение
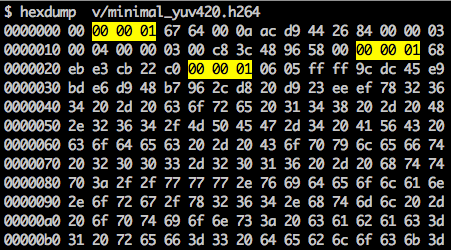
Как говорилось, декодер должен знать не только данные изображения, но также и детали видео, кадра, цвета, используемые параметры и многое другое. Первый байт каждого NAL определяет его категорию и тип.
| Идентификатор типа NAL | Описание |
|---|---|
| 0 | Неизвестный тип |
| 1 | Кодированный фрагмент изображения без IDR |
| 2 | Кодированный раздел данных среза A |
| 3 | Кодированный раздел данных среза B |
| 4 | Кодированный раздел данных среза C |
| 5 | Кодированный IDR-фрагмент IDR-изображения |
| 6 | Дополнительная информация о расширении SEI |
| 7 | Набор параметров SPS-последовательности |
| 8 | Набор параметров PPS-изображения |
| 9 | Разделитель доступа |
| 10 | Конец последовательности |
| 11 | Конец потока |
| ... | ... |
Если пропустить первый маркер синхронизации, то можем декодировать первый байт, чтобы узнать, какой тип NAL является первым.
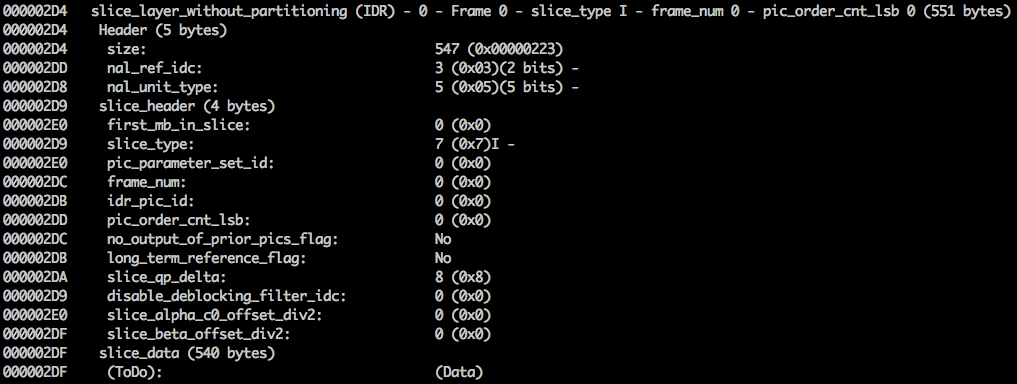
Например, первый байт после маркера синхронизации равен 01100111, где первый бит (0) находится в поле forbidden_zero_bit. Следующие 2 бита (11) сообщает нам поле nal_ref_idc, которое указывает, является ли этот NAL ссылочным полем или нет. И остальные 5 бит (00111) сообщает нам поле nal_unit_type, в данном случае это блок SPS (7) NAL.
Второй байт (binary=01100100, hex=0x64, dec=100) в SPS NAL — это поле profile_idc, которое показывает профиль, который использовал кодер. В данном случае использовался ограниченный высокий профиль (т.е. высокий профиль без поддержки двунаправленного B-сегмента).

Если ознакомиться со спецификацией битового потока H.264 для SPS NAL, то обнаружим много значений для имени параметра, категории и описания. Например, давайте посмотрим на поля pic_width_in_mbs_minus_1 и pic_height_in_map_units_minus_1.
| Название параметра | Категория | Описание |
|---|---|---|
| pic_width_in_mbs_minus_1 | 0 | ue(v) |
| pic_height_in_map_units_minus_1 | 0 | ue(v) |
Если продолжить проверку нашего созданного видео в двоичном виде (например:

Здесь видим его первые 6 байтовых значений: 01100101 10001000 10000100 00000000 00100001 11111111. Поскольку известно, что первый байт указывает на тип NAL, в данном случае (00101) это IDR фрагмент (5), и тогда получится дополнительно исследовать его:

Используя информацию спецификации, получится декодировать тип фрагмента (slice_type) и номер кадра (frame_num) среди других важных полей.
Чтобы получить значения некоторых полей (ue(v), me(v), se(v) или te(v)), нам нужно декодировать фрагмент, используя специальный декодер, основанный на экспоненциальном коде Голомба. Этот метод очень эффективен для кодирования значений переменных, особенно, когда если есть много значений по умолчанию.
Значения slice_type и frame_num этого видео равны 7 (I-фрагмент) и 0 (первый кадр).
Битовый поток можно рассматривать как протокол. Если желаете узнать больше о битовом потоке, стоит обратиться к спецификации ITU H.264. Вот макросхема, показывающая, где находятся данные изображения (YUV в сжатом виде).
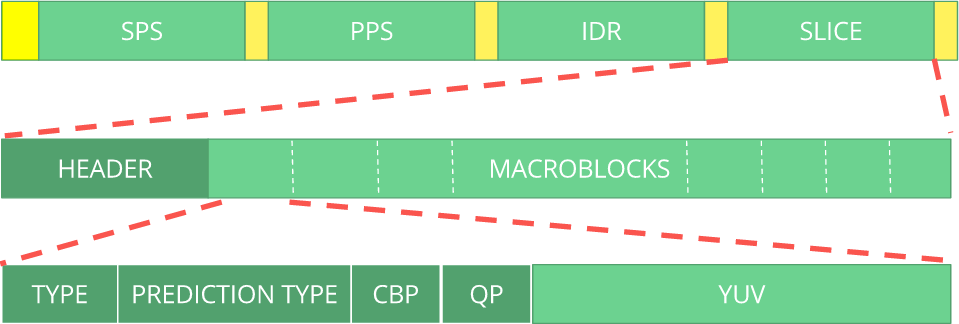
Можно исследовать и другие битовые потоки, такие как VP9, H.265 (HEVC) или даже наш новый лучший битовый поток AV1. Все ли они похожи? Нет, но разобравшись хотя бы с одним — гораздо проще понять остальные.
Хотите попрактиковаться? Исследуйте поток битов H.264
Можно сгенерировать однокадровое видео и использовать MediaInfo для исследования потока битов H.264. Фактически, ничто не мешает даже поглядеть исходный код, который анализирует поток битов H.264 (AVC).
Для практики можно использовать Intel Video Pro Analyzer (я уже вроде говорил, что программа платная, но есть бесплатная пробная версия, с ограничением на 10 кадров?).
Обзор
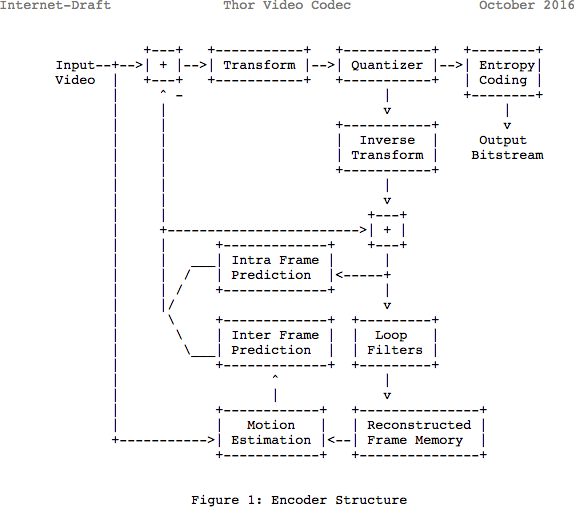
Отметим, что многие современные кодеки используют ту же самую модель, которую только что изучили. Вот, давайте взглянем на блок-схему видеокодека Thor. Она содержит все шаги, нами пройденные. Весь смысл этой заметки в том, чтобы вы, по крайней мере, лучше понимали инновации и документацию из этой области.
Ранее рассчитали, что потребуется 139 Гб дискового пространства для хранения видеофайла длительностью один час при качестве 720p и 30 fps. Если использовать методы, которые разобрали в этой статье (межкадровые и внутренние прогнозы, преобразование, квантование, энтропийное кодирование и т.п.), то можно достичь (исходя из того, что тратим 0,031 бит на пиксель), видео вполне удовлетворительного качества, занимающее всего 367,82 Мб, а не 139 Гб памяти.
Как H.265 достигает лучшей степени сжатия, чем H.264?
Теперь, когда известно больше о том, как работают кодеки, проще разбираться, как новые кодеки способны обеспечивать более высокое разрешение с меньшим количеством битов.
Если сравнивать AVC и HEVC, стоит не забывать, что это почти всегда выбор между большей нагрузкой на CPU и степенью сжатия.
HEVC имеет больше вариантов разделов (и подразделов), чем AVC, больше направлений внутреннего прогнозирования, улучшенное энтропийное кодирование и многое другое. Все эти улучшения сделали H.265 способным сжимать на 50% больше, чем H.264.