 Долгое время все большие проекты, связанные с сетью, будь то web-проект или ДЦ крупного предприятия представляли собой одну и ту же структуру. Это была характерная древовидная архитектура, различающаяся лишь размером дерева и плотностью «ветвей», обусловленных разными требованиями к надежности и производительности. Но цифровой мир не стоит на месте, а стремительно растет и развивается, при чем не только в увеличиваясь объемах и скоростях, но и меняя свою структуру. Всевозможные Big Data, облака и распределенные вычисления привели к тому, что по сети стало необходимым передавать огромные объемы данных между большим количеством конечных узлов, причем, желательно, с минимальной задержкой.
Долгое время все большие проекты, связанные с сетью, будь то web-проект или ДЦ крупного предприятия представляли собой одну и ту же структуру. Это была характерная древовидная архитектура, различающаяся лишь размером дерева и плотностью «ветвей», обусловленных разными требованиями к надежности и производительности. Но цифровой мир не стоит на месте, а стремительно растет и развивается, при чем не только в увеличиваясь объемах и скоростях, но и меняя свою структуру. Всевозможные Big Data, облака и распределенные вычисления привели к тому, что по сети стало необходимым передавать огромные объемы данных между большим количеством конечных узлов, причем, желательно, с минимальной задержкой.Все это привело к тому, что традиционная древовидная архитектура, состоящая из уровней доступа, агрегации трафика и ядра, стала откровенно буксовать и давать сбои. Назрела необходимость ее заменить. На что?
Для начала давайте попробуем охарактеризовать сетевую структуру в так называемых «традиционных» Enterprise-проектах:
- от сотен до нескольких тысяч узлов;
- статическая маршрутизация;
- структура VLAN'ов без виртуализации серверов;
- вертикально ориентированная (north-south) архитектура
- 1G-интерконнекты с 10G аплинками.
А вот такие же характеристики для сетей современных дата-центров, работающих с такими проектами Web 2.0 как облака, Big Data, распределенные вычисления и аналогичные современные большие проекты:
- от тысяч до миллионов узлов;
- динамическая маршрутизация;
- облачная структура с виртуальными серверами;
- преимущественно горизонтальная (west-east) архитектура;
- быстрое (часы, а не недели) разворачивание сетей и добавление стоек;
- в основном 10G соединения с 40G аплинками.

Потребности нового мира
Налицо существенное различие, требующее организационных изменений.
Если обобщить разнообразные требования к современной сетевой инфраструктуре, то они станут такими:
- хорошая масштабируемость производительности;
- устойчивость к сбоям на всех уровнях;
- высокая взаимозаменяемость для снижения издержек;
- предсказуемая латентность;
- высокая доступность оборудования;
- удобство обслуживания.
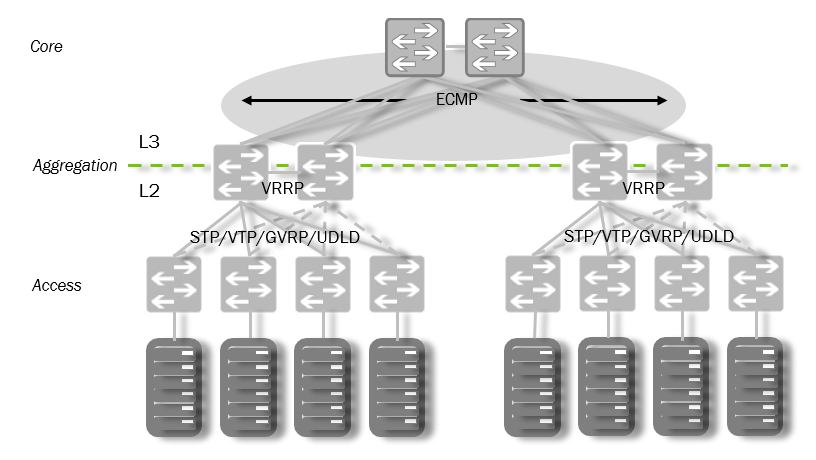
Традиционная сетевая инфраструктура
Что при этом категорически не устраивает в традиционной схеме?
- Резкое снижение производительности при отказе на уровне агрегации;
- Недостаточная масштабируемость, вызываемая уровнем агрегации:
- MAC / ARP
- VLAN'ы
- перегруженность точек обмена горизонтальным трафиком;
- резкое возрастание сложности структуры при увеличении надежности;
- Множество проприетарных вариантов используемых протоколов (MLAG, vPC, варианты STP, UDLD, Bridge Assurance, LACP, FHRP, VRRP, HSRP, GLBP, VTP, MVRP...)
Решение? Как только мы начинаем говорить о масштабах, когда стоимость обслуживания начинает превосходить стоимость оборудования (да-да, столь любимые бухгалтерами и маркетологами, и нелюбимые остальными CAPEX и OPEX), как на сцену выходит давно известное решение в виде сетей Клоза (Clos fabric), известное также как архитектура Leaf-Spine.
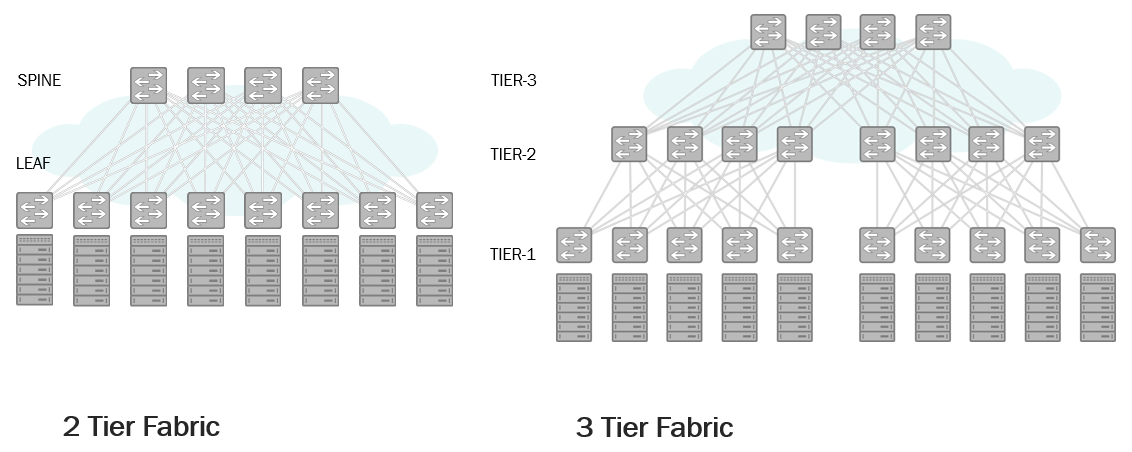
Leaf-Spine
Важное примечание для невнимательных: уровень Spine вовсе не идентичен уровню агрегации. На этом уровне нет и не предполагается горизонтальных связей между коммутаторами и уж тем более не предполагается, что весь трафик через этот уровень собирается и уходит в сторону ядра или, допустим, интернета.
Сама по себе это архитектура известна уже полвека и успешно применяется в телефонных сетях, но сейчас сложились все предпосылки для ее активного внедрения в с сети ЦОД. С одной стороны, оборудование стало одновременно достаточно производительным и недорогим, при этом обеспечивая крайне малые задержки (сотни наносекунд — это уже не фантастика, а вполне реальность). Ну а с другой сами задачи стали такими, когда централизованная архитектура становится неоптимальной.
Что же обеспечивает Leaf-Spine в приложении к рассматриваемым нами структурам?
- Возможность опереться на ECMP (_который с марта 2014 однозначно определен и признан в качестве стандарта IEEE 802.1Qbp_) в условиях сплошной IP-фабрики;
- Облегчение устранения отказов оборудования за счет его однородности;
- Предсказуемая латентность;
- Отличая масштабируемость;
- Простота автоматизации управления;
- Меньшее падение пропускной способности сети при отказе оборудования;
- TOR (Top of Rack) вместо EOR (End of Row). О специфике TOR и EOR можно почитать вот в этой довольно старой, но по-прежнему актуальной статье)
Хочется бонусов? Пожалуйста:
- Схема по умолчанию защищена от появления петель и не требует для этого STP;
- Если порт не отвечает — протокол маршрутизации считает его выпавшим и не рассматривает возможность его участия в маршрутах, в отличие от STP.
До каких масштабов можно увеличивать подобные сети? Двухуровневая сеть на распространенных и недорогих коммутаторах с сорока восемью 10G портами и шестью 40G аплинками (Overprovisioning Ratio 1,6 при размещении сорока серверов на стойку) позволяет подключать до 1920 серверов. Ввод третьего уровня увеличивает эту цифру до 180 тысяч. Если вам мало и этого — уровни можно наращивать и дальше.
Можно ли и стоит использовать эту архитектуру на сетях сильно меньших размеров? Почему бы и нет, если, конечно, у вашего проекта нет каких-то специфичных требований именно по L2 маршрутизации. Посчитайте стоимость классического решения и Leaf-Spine на BMS-коммутаторах. И если последнее оказывается для вас явно выигрышным — это же весомый повод задуматься, правда? :)
Конечно, помимо этого должно выполняться и еще одно условие, которое было основоположным, когда мы говорили о необходимости смены концепции сети: трафик в ней должен быть преимущественно горизонтальным, узлы сравнительно равноправны с точки зрения потребления трафика, нет явно выделенного направления, в котором движется подавляющая часть объема данных. Это вовсе не обозначает, что у такой сети не должно быть внешних подключений, но трафик в их сторону должен быть соразмерим с потоками между узлами, а не быть основной составляющей.
Мы же, в свою очередь, готовы предложить вам для этого все необходимое.

Eos 420

Eos 520
Например, весьма привлекательные с точки зрения стоимости коммутаторы без
предустановленной ОС (Bare Metal Switch) на матрицах Trident II, цена 10G порта на которых составляет менее 100 долларов: ETegro Eos 420 (48 10G + 6 40G) для уровня Leaf и Eos 520 (32 40G) для Spine уровня.
Ну и при необходимости обеспечить их сетевой ОС Cumulus Linux, о возможностях которой мы писали чуть раньше.
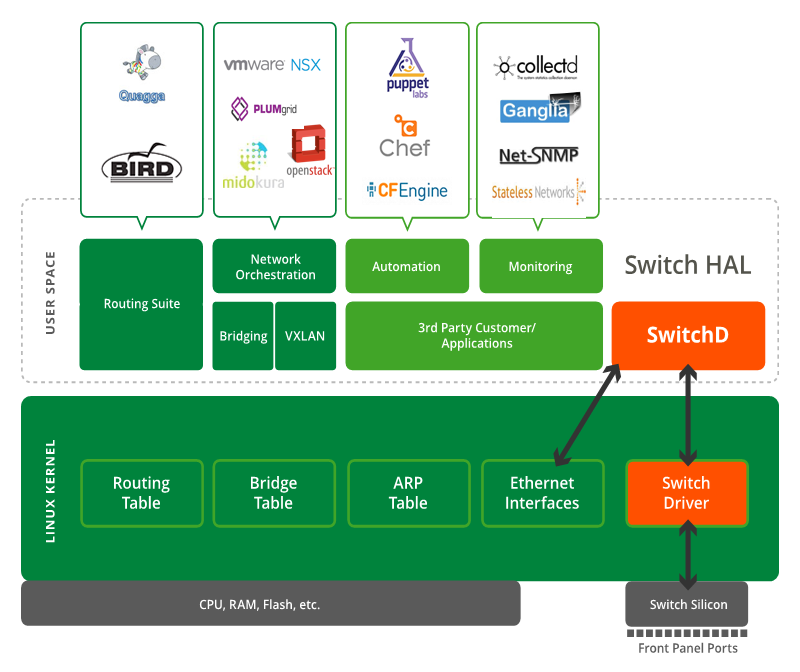
Bare Metal Switch
Почему мы выступаем именно за BMS-версии сетевого оборудования? Да просто потому, что на наш взгляд, только оно способно обеспечить одновременно и необходимую современным проектам гибкость за счет выбора ОС с необходимым набором функций, и малую стоимость владения за счет отказа от оплачивания порой крайне дорогих, но абсолютно ненужных vendor-specific особенностей. Вряд ли кто-то будет оспаривать удобность того, что можно купить сервер одного производителя, поставить на него ОС другого, и дополнить ее программным обеспечением третьего. На наш взгляд, настало время принести эту идеологию открытых систем и в мир сетевого оборудования.
Если есть желание «потрогать» такие коммутаторы и посмотреть, на что способны открытые сетевые ОС — пишите, у нас есть возможность организовать тестирование.
