Привет!
На связи Гончик, любитель APM (application performance monitoring) инструментов, в частности Glowroot.
Сегодня расскажу о том, как за кратчайшее время найти узкие места в Confluence On-Prem на основе одной промышленной инсталляции.
Мы столкнулись с ситуацией, когда большое количество людей одновременно ломится в базу знаний на Confluence On-Prem (во время сдачи аттестации), и конфлюенс умирает на какое-то время.
Сразу подумали, что проблема именно в одновременном количестве посетителей и сразу можно затюнить JVM, но оказалось, что не все так однозначно.
Ниже расскажу, как мы нашли реальную причину тормозов и как с ней справились.
Основная задача: провести аудит и на его основе добиться улучшения производительности, особенно в моменты большого количества активных пользователей в системе.
Конечно, в первую очередь были проверены аппаратные ресурсы, конфигурации ОС, где никаких проблем не выявлено.
Однако, отсутствовали access логи nginx, поскольку конфигурацией была отключена запись логов посредством директивы access log off. Из полезного подтюнил терминацию ssl, также подключил http2. Не стал фокусироваться на тонких настройках nginx, поскольку стало ясно, что надо идти в сторону Tomcat (рекомендации вендора).
Далее у меня был один рестарт для настройки системы, где установил приложение-агент Glowroot и пошел смотреть графики, сгенеренные посредством APM агента (о том, как установить писал тут).
Предлагаю три разбора на разных уровнях управления и обслуживания приложением, которые мне показались полезными и могут оказаться интересными для вас.
Разбор первый (На старт)
Проведя все вышеуказанные проверки, я продолжил анализ соединения СУБД и Confluence, поскольку Confluence - nginx, работал отлично.
Первым делом Glowroot показал, что на каждый запрос в БД, Confluence делает проверки состояния соединения, следующим образом:

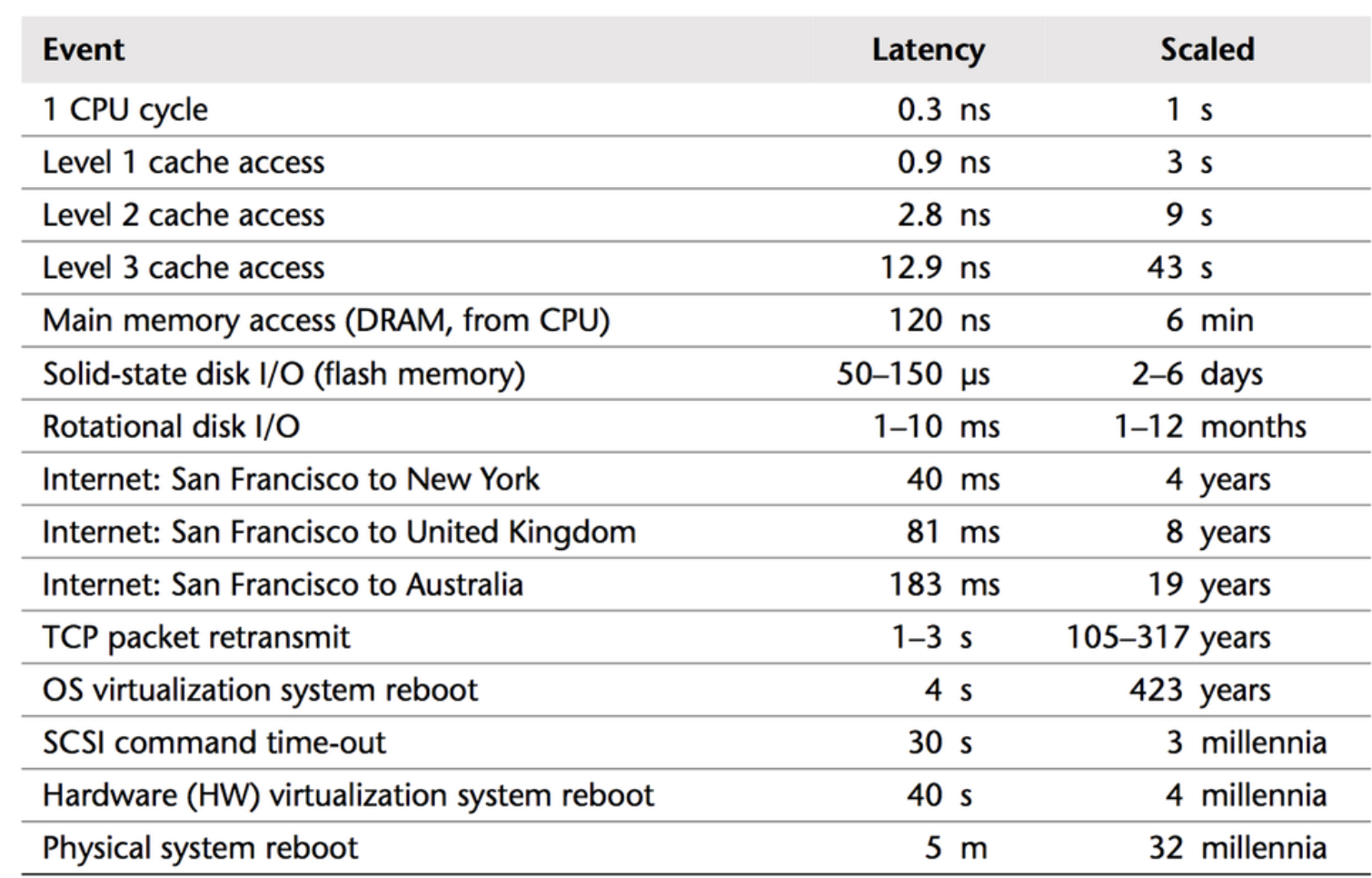
Но количество проверок состояния равняется 11 на 1 полезный запрос, и тратится от 0,20 мс до 0,32 мс на каждую проверку. То есть в среднем от 2 до 3 миллисекунд уходит на вспомогательные запросы. И если у нас не будет кэширования на уровне приложения или при инвалидации кэширования то это - узкое место.
Далее, уточнив версию СУБД и версию драйвера с помощью следующей ссылки https:////{CONFLUENCE_URL}/admin/systeminfo.action , появился простор для размышления. Особенно благодаря старой доброй табличке по задержкам, так как она мне всегда помогает примерно на глаз определить узкие места.
Вендор Atlassian активно использует у себя PostgreSQL, что подтверждается страницей по поддерживаемым СУБД.
Так как я пока использую MySQL, то обновление драйвера традиционно снизило симптомы. Понять причины мне помогла статья “После обновления онлайн-базы данных возникает проблема чрезмерного отката транзакций базы данных”, где решением фактически был переход на другой пуллер (https://github.com/alibaba/druid/wiki/FAQ). В моем же случае - переход на PostgreSQL.
Если нужно посмотреть, как устроен параметр useSessionStatus, можно скачать коннектор и проверить использование метода isReadOnly.
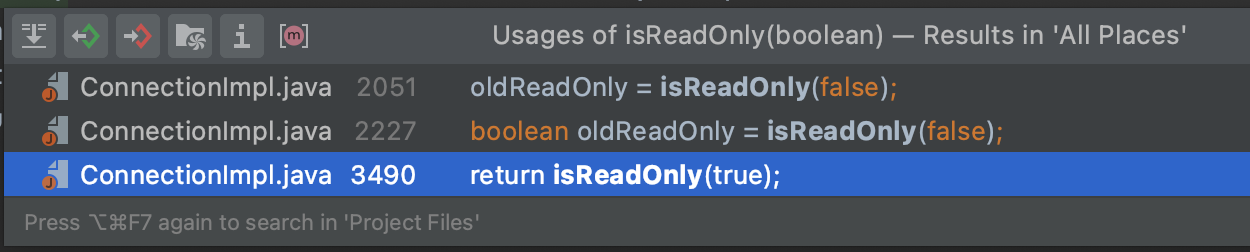
Зависимость версии легко проверить, посмотрев первое условие в методе.

Резюмируя, краткосрочное решение - принятие рисков и обновление драйвера коннектора СУБД, а долгосрочное решение - переход на PostgreSQL 11.
Разбор второй (Внимание)
Часто в анализе помогает поиск паттернов, таких как время жалоб и корреляция с графиками времени ответа приложения, особенно в процентилях, что дает понимание и наглядность, что происходит с небольшим объемом запросов.
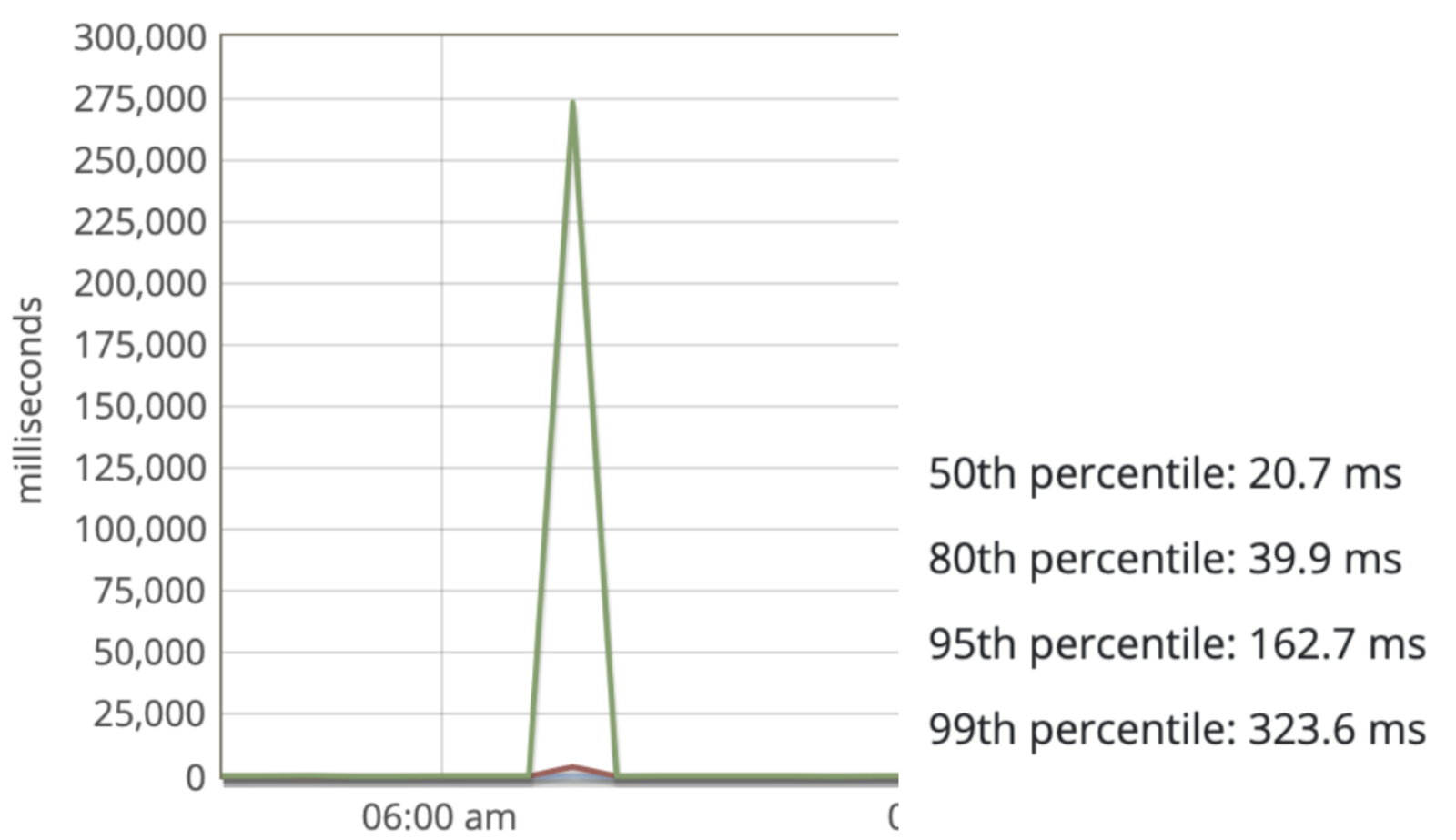
Перейдя в режим slow traces в панели мониторинга Glowroot, можно детальнее посмотреть на поведение системы.
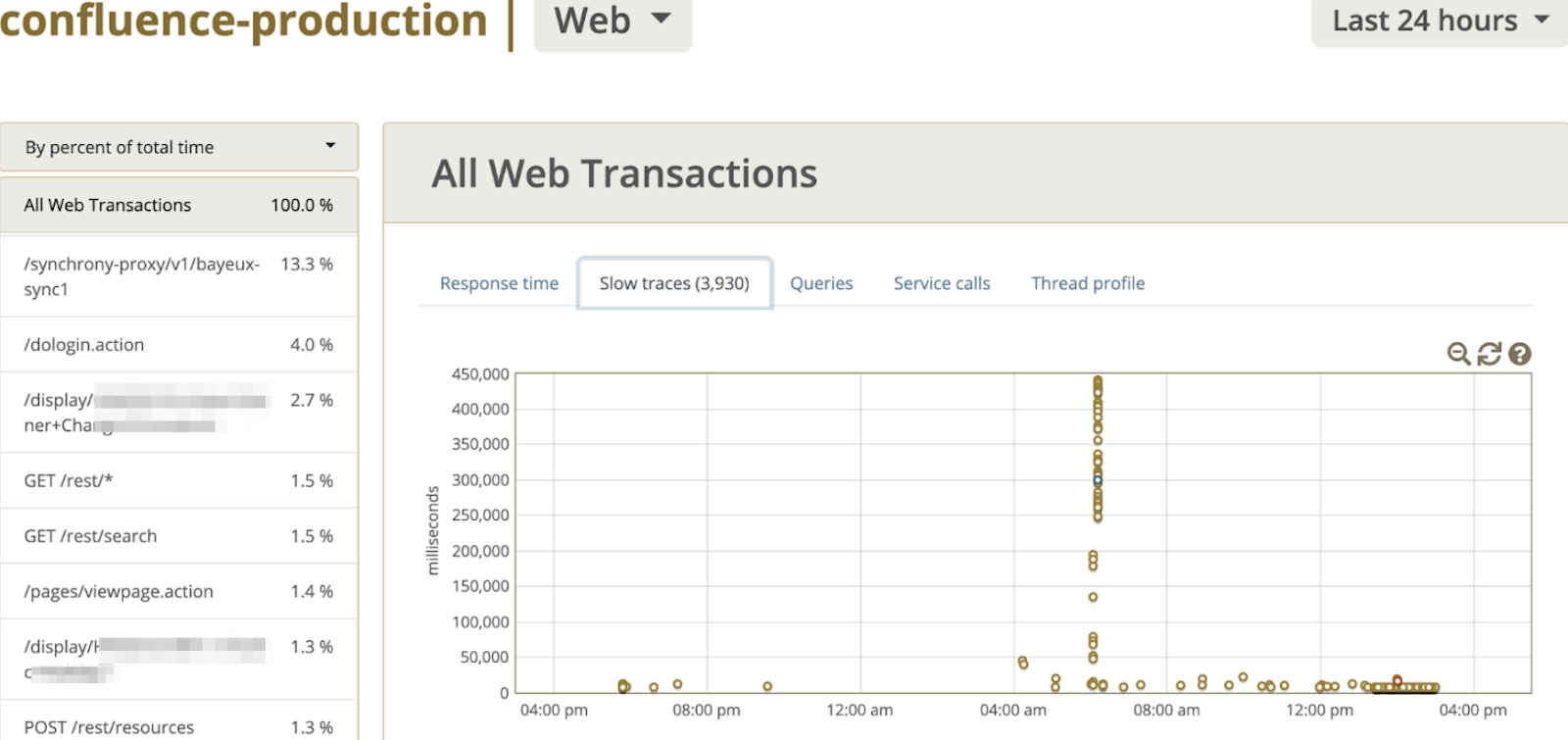
а также на указанном скриншоте наблюдал следующее поведение:
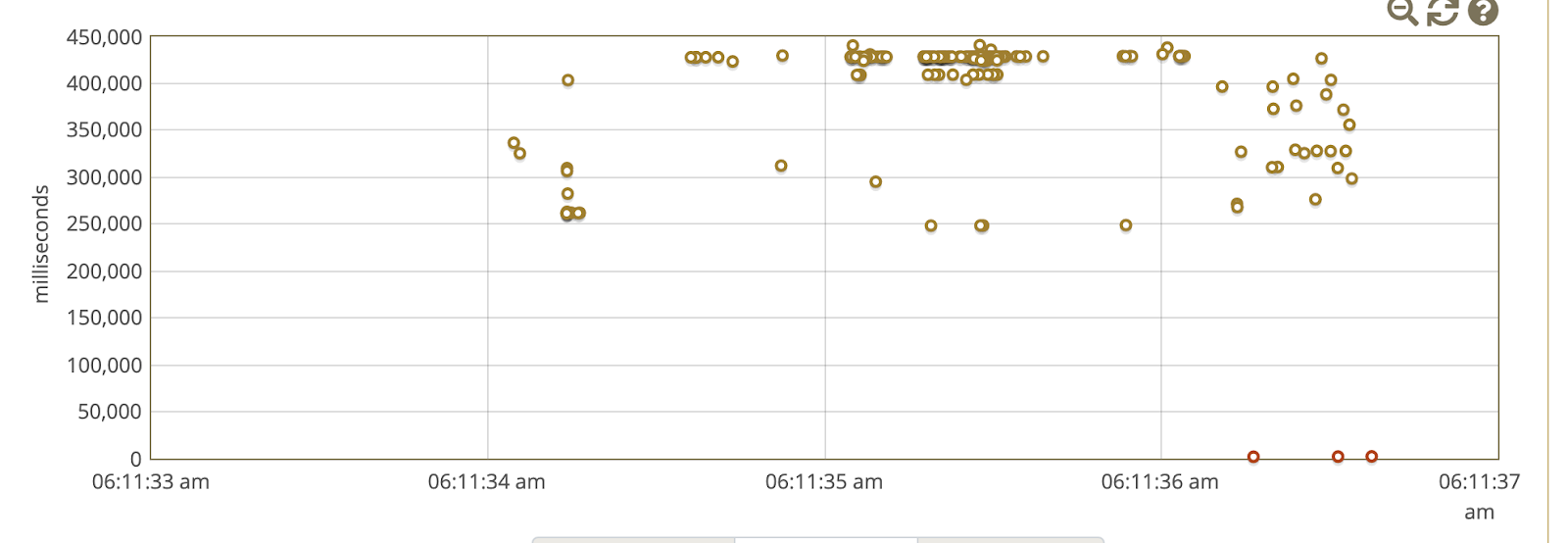
Все это меня натолкнуло на просмотр расписания пакетных операций, например - время запуска процесса создания резервных копий.
Первым делом проверил в веб интерфейсе ({CONFLUENCE_URL}/admin/scheduledjobs/viewscheduledjobs.action) и отключил бэкапы в xml на уровне приложения. Так же можно увидеть историю запусков, и в принципе понять, что как раз к 6:30 утра заканчивается пакетное задание Back Up Confluence.

Но как только, зайдя в систему с правами root, проверил crontab, где также увидел, что скрипт по резервному копированию запускается с 5 утра и заканчивается около 6:15 утра по времени моего ПК. Так как это классическое узкое место, то выход - просто отключение в силу ненадобности. Ввиду того, что на уровне виртуализации производится резервное копирование раз в час, и СУБД находится на другом сервере, то самое основное - это домашняя директория Confluence.
Подытожим. Простые причины всегда надо проверять. Расписание создания бэкапов - это первое, что нужно проверить, если поведение системы должно как-то коррелировать с проблемой.
Разбор третий (Марш)
Так как разбор не был ограничен работой между СУБД и приложением, то перейдя во вкладку Queries и выполнив сортировку по колонке “Среднее время выполнения”, увидел интересный паттерн, который представлен на скриншоте ниже.
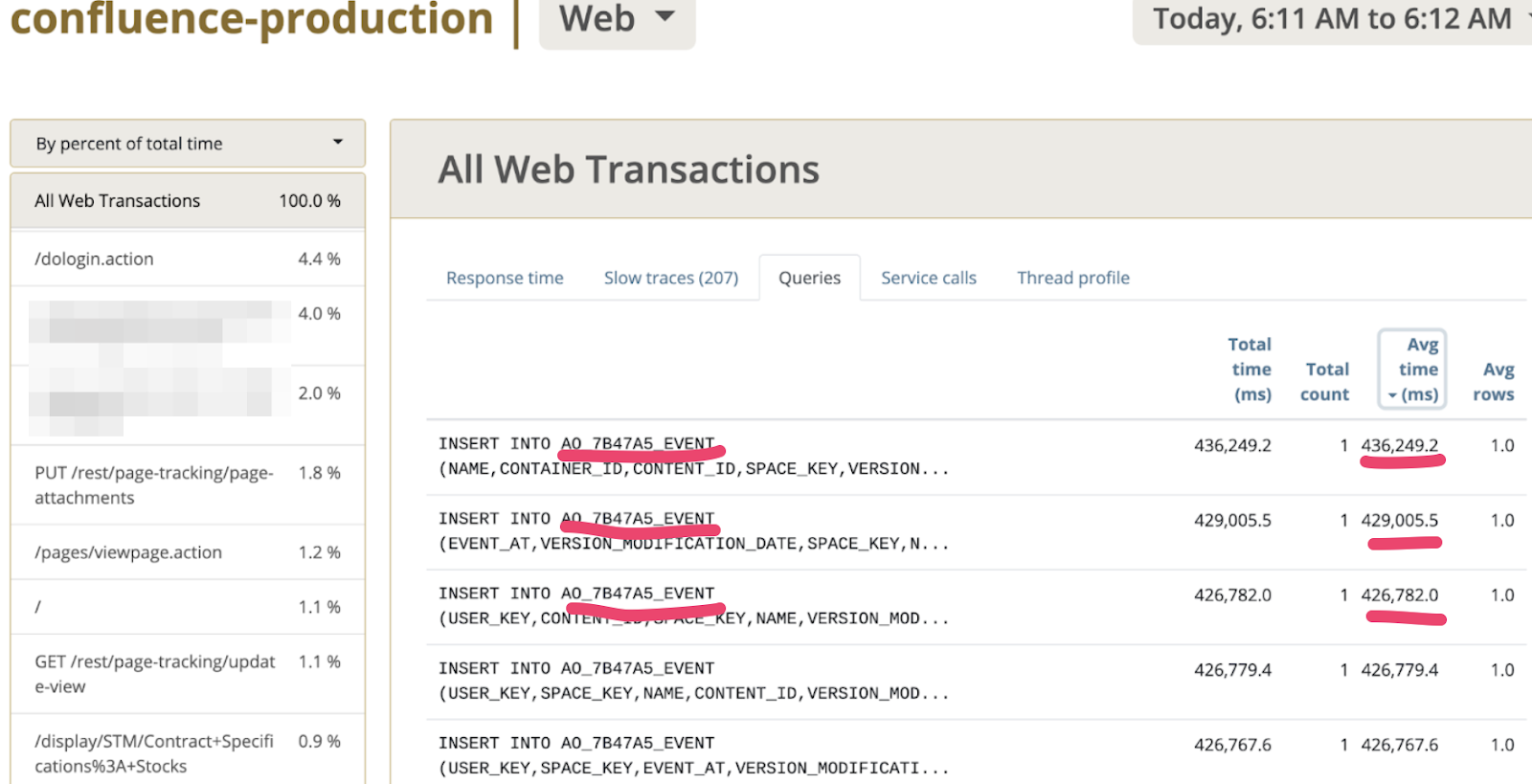
Да, именно в таблицу AO_7B47A5_EVENT эпизодически INSERT проходит медленно, когда большое количество пользователей открывает странички в Confluence. А так как есть префикс AO_*, то он является индикатором таблиц, созданных посредством ORM Active Objects. Как правило, это плагины, устанавливаемые в платформу. Тут Гугл быстро навел на следующий тикет https://jira.atlassian.com/browse/CONFSERVER-69474, который указал, что виновник - приложение Confluence Analytics. Поискав в Managed Apps находим его, предварительно выставив All Apps в скоупе поиска. Вуаля! Найдя приложение, видим, что оно не лицензировано, согласно скриншоту.
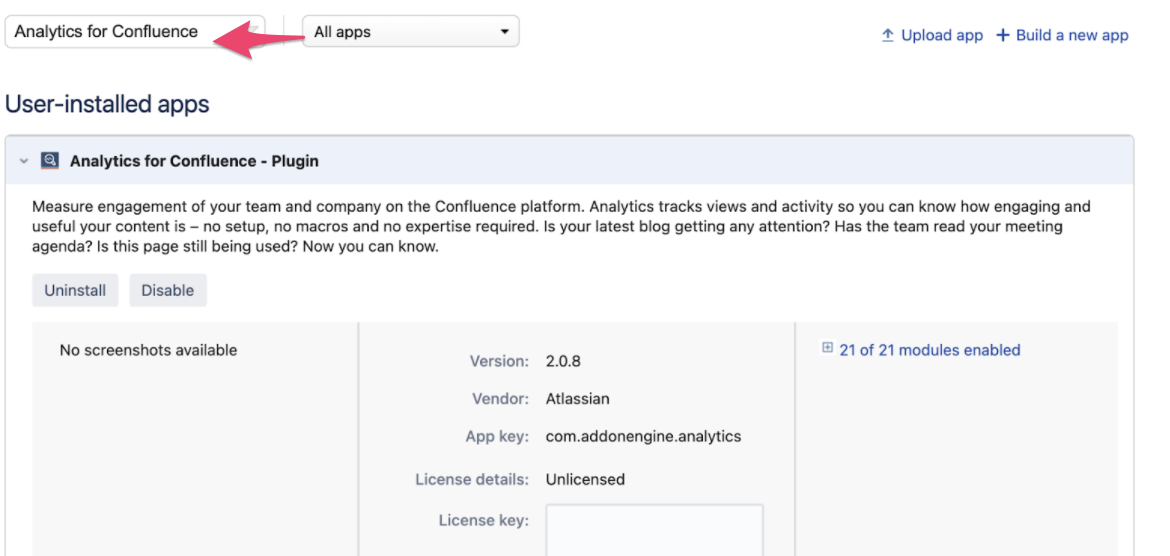
Так как наша инсталляция имеет лицензию Server, а не Datacenter, можно смело отключать приложение, так как оно не несет полезной нагрузки в связи с отсутствием соответствующей лицензии.
Ситуация не очень приемлема, поэтому отправил запрос вендору о необходимости представления метрик и правил по retention policy логов аналитики в БД, полной асинхронной работы по аналитике. В результате - после очистки записей в таблице, отдача контента на глазах ускорилась.
Делаем вывод, что важно верифицировать медленные запросы и смотреть их логи (на момент аудита их не было для анализа). Это сильно помогает предоставлять информацию вендорам, чтобы происходили улучшения. Например, расширение по аналитике в последней версии Confluence намного лучше работает и не так аффектит систему, хотя есть проблема при работе с вложениями.
Подводя итог, анализируем основную бизнес-метрику, а именно пользовательское ощущение, получаем обратную связь от бизнес-заказчика: “Жалоб не было”. Однако у нас есть, чем заняться, так как собрался довольно большой бэклог изменений по улучшению системы.
Спасибо, что прочитали до конца, буду рад если данные ситуации были интересные, то я продолжу делиться подобными историями использования инструментов трассировки и поисков.
Всегда рад вашим вопросам, а также видеть вас в Телеграм чатике сообщества Atlassian.
Хорошего дня, Гончик.
